
- 1C# 桌面应用添加启动等待画面(SplashScreen)_c# splashscreen
- 2安卓开发软件培训!带你一步一步深入Handler源码,重难点整理_安卓源码学习难点
- 3随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比_批量梯度下降公式
- 4数组清空函数memset使用方法_memset清空数组
- 5OpenSSL之十一:非对称加密算法指令_openssl11
- 6计算机网络复习资料_通过网络链路和交换机移动数据有两种基本方法
- 7向量与矩阵 导数和偏导数 特征值与特征向量 概率分布 期望方差 相关系数_求导变换的特征值和特征向量
- 8org.apache.commons.io.IOUtils工具类快速读取文件内容_org/apache/commons/io/ioutils
- 9vant 2 :Picker 选择器 自定义时间选择器(年+月)_vue2移动端 van-picker 年月日选择
- 10实时监听input值的改变_jqmigrate: logging is active
词袋模型(Bag-of-words model)
赞
踩
词袋模型
简介
词袋模型(Bag-of-words model)是用于自然语言处理和信息检索中的一种简单的文档表示方法。通过这一模型,一篇文档可以通过统计所有单词的数目来表示,这种方法不考虑语法和单词出现的先后顺序。这一模型在文档分类里广为应用,通过统计每个单词的出现次数(频率)作为分类器的特征。
示例
如下两篇简单的文本文档:
Jane wants to go to Shenzhen.
Bob wants to go to Shanghai.
基于这两篇文档我们可以构建一个字典:
{‘Jane’:1, ‘wants’:2, ‘to’:4, ‘go’:2, ‘Shenzhen’:1, ‘Bob’:1, ‘Shanghai’:1}
我们可将两篇文档表示为如下的向量:
例句1:[1,1,2,1,1,0,0]
例句2:[0,1,2,1,0,1,1]
词袋模型实际就是把文档表示成向量,其中向量的维数就是字典所含词的个数,在上例中,向量中的第i个元素就是统计该文档中对应字典中的第i个单词出现的个数,因此可认为词袋模型就是统计词频直方图的简单文档表示方法。
计算机视觉中的词袋模型
对于一副图像,我们可以看作文档——若干个“词汇”的集合,同样的,视觉词汇之间没有顺序。将文档中的单词类比到图像,图像中的单词是图像特征。
大概过程:首先提取图像集特征的集合,然后通过聚类的方法聚出若干类,将这些类作为dictionary,即相当于words,最后每个图像统计字典中words出现的频数作为输出向量,我们便可将一幅图表示成基于图像特征的统计直方图,用于后续的分类、检索等操作。
具体步骤如下:
-
利用SIFT算法从图像集的所有图像中提取SIFT特征形成视觉词汇向量。假如有自行车、人脸、吉他,我们提取词汇如下:

-
利用聚类方法(如k-means)对上一步提取的SIFT特征即视觉词汇进行聚类,得到k个聚类中心,利用这些聚类中心构建词典(码本)。假设对上面自行车、人脸、吉他得到的视觉词汇进行k-means聚类(如k=4),形成码本的过程如下:
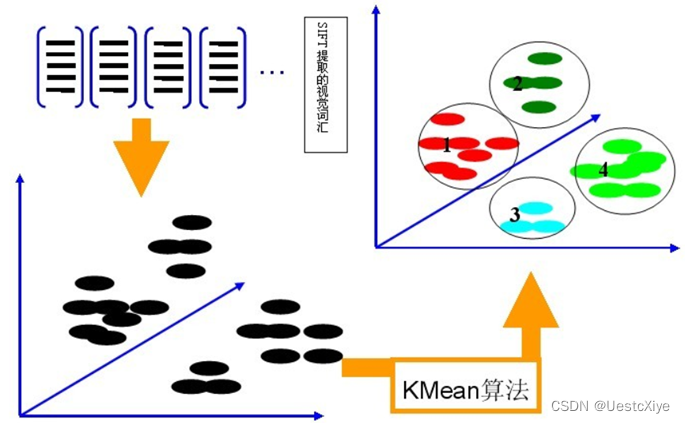
-
在每一幅图片中统计码本的每个单词对应SIFT特征的数量,这样一幅图就可用k维向量或者说是统计直方图的形式表示出来。对于我们的例子,我们将图像用统计直方图的形式可表示如下:
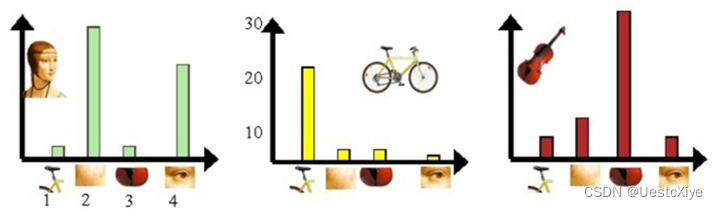
综上,我们把图像用词袋模型表示成了一个向量,这样我们便可以利用其代表图像进行检索、分类等操作。
我们可以通过下图更加整体的理解用词袋模型表示一幅图的方法:
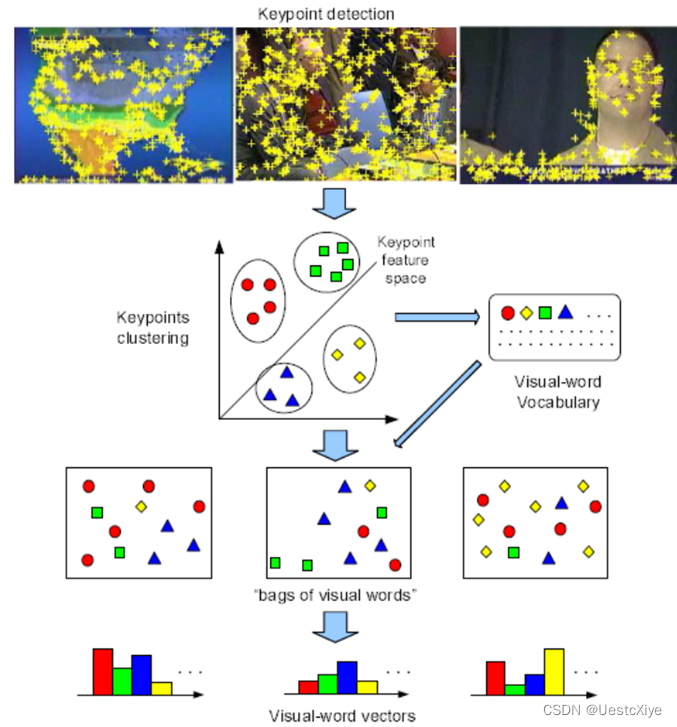
图1 基于矢量量化关键点特征的视词图像表示

