
- 1Android Studio 导入及关联framework源码_androidstudio 打开android framework
- 2交换机进行读写rtl8306.c驱动源码_rtl836 驱动
- 3【Matlab算法】梯度下降法(Gradient Descent)(附MATLAB完整代码)_matlab 梯度下降法
- 4如何用python编辑 一个偶数总能表示为两个素数之和_python偶数拆成两个素数之和
- 5鸿蒙系统(HarmonyOS)理论基础合集(六):创建鸿蒙工程_鸿蒙系统指令代码大全
- 6电话拨键号码(DTMF信号)识别_dtmf拨号判读 csdn
- 7使用Git下载Android源代码_app源码 git下载
- 8vue 监听滚动条行为 | 判断滚动条是向上滚动还是向下滚动_vue 判断滚动条滚动方向
- 9ArcGIS批量裁剪栅格数据(ArcPy方法)
- 10Android中kernel内核模块编译执行_安卓kernel编译
EMNLP 2023 Best Paper公布啦!_emnlp23 papers
赞
踩
EMNLP 2023 大会昨日在新加坡落幕,最佳长论文、最佳短论文、杰出论文等大奖全部揭晓。
北大&微信团队获得了最佳长论文奖,剑桥大学收获了最佳短论文奖,多个团队获得了杰出论文奖,最佳论文 Demo 由艾伦人工智能实验室(AI2)领衔摘得。
下面是具体介绍。
最佳长论文介绍

最佳长论文花落北京大学&微信AI团队,这篇论文聚焦于理解上下文情境学习(ICL),从信息流(Information Flow)的视角出发揭示了ICL的工作机制——ICL 示例中的标签为大模型的预测起到了Anchor的作用。作者将执行 ICL 的GPT模型中信息流的可视如下图所示,可以看到示例中的标签词在浅层中进行信息收集,并在深层处完成信息提取进行最终预测:

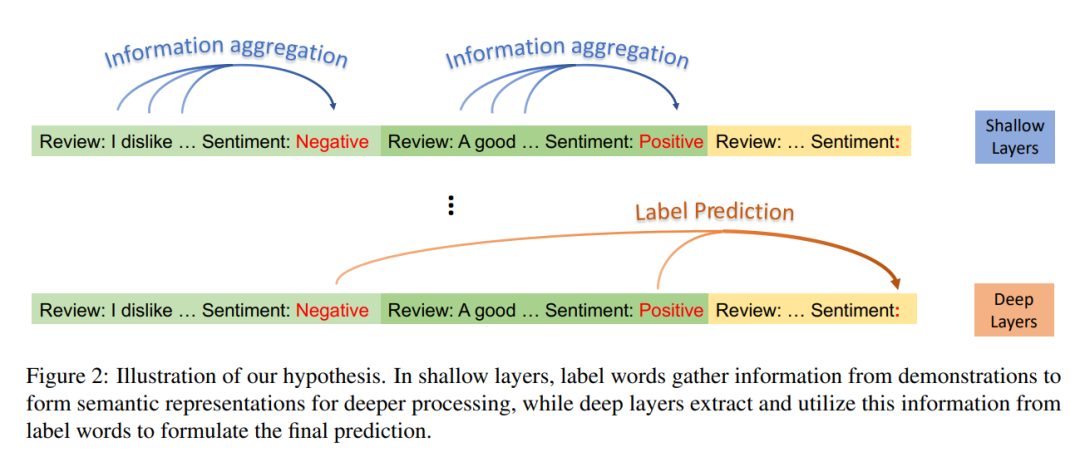
论文题目:Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning
作者:Lean Wang, Lei Li, Damai Dai, Deli Chen, Hao Zhou, Fandong Meng, Jie Zhou, Xu Sun
机构:北京大学,微信AI
论文链接:https://aclanthology.org/2023.emnlp-main.609.pdf
论文摘要: 上下文情景学习(ICL)通过为大语言模型(LLMs)提供执行不同任务的示例,成为其很有潜力的一种能力。然而,LLMs 如何从 ICL 提供的语境中进行学习的内在机制目前尚未得到充分的探索。在本文中,我们从信息流的角度研究了 ICL 的工作机制,研究结构表明,ICL 提供的示例中的标签词起到了锚(Anchors)的作用:(1)在浅层计算层的处理过程中,语义信息聚集到标签词的表征中;(2)标签词中的综合信息可以作为 LLMs 最终预测的参考。基于这些观点,我们引入了一种Anchor重加权的方法来提高 ICL 的性能,并且使用了示例压缩技术以加快推理速度,以及一种用于诊断 GPT2-XL 中 ICL 错误的分析框架,我们研究成果的可能应用再一次验证了我们所揭示的 ICL 的工作机制,并为未来的研究奠定了基础。
最佳短论文介绍

最佳短论文被剑桥大学收入囊中,这篇论文改进了最小贝叶斯风险(MBR)算法作为模型 Decoder 的解码策略,在标准 MBR 的基础上提出了一种使用置信度进行剪枝的迭代算法,在维持了准确率的基础上大大降低了采样所需的样本数量与效用函数的调用次数。
论文题目:Faster Minimum Bayes Risk Decoding with Confidence-based Pruning
作者:Julius Cheng, Andreas Vlachos
机构:剑桥大学
论文链接:https://aclanthology.org/2023.emnlp-main.767.pdf
论文摘要: 最小贝叶斯风险(MBR)解码输出在某些效用函数的模型分布上具有最高期望效用的假设。在条件语言生成问题,特别是神经机器翻译中,MBR 的准确性显著高于 Beam search。然而,由于需要大量样本与对效用函数的二次调用,基于采样的标准 MBR 算法的计算成本却远高于 Beam search,大大限制了其适用性。因此,我们提出了一种逐渐增加估计效用样本的数量并根据置信度对剪枝效用不可能最高的假设的算法。与标准的 MBR 相比,我们的方法在统计准确率上与标准 MBR 无异,但所需的样本更少,对调用效用函数的次数更低。我们在使用 chrF++ 与 COMET 作为评估指标,在三种语言的实验上证明了我们方法的有效性。
杰出论文奖
今年一共有多个团队分别获得了EMNLP 2023杰出论文奖。
杰出论文奖一:

论文题目:Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
论文链接:https://arxiv.org/abs/2304.09542
论文摘要:
大语言模型(LLMs)已在各种语言相关任务中展示了卓越的零样本学习泛化能力。然而,现有工作仅利用LLMs的生成能力进行信息检索(IR),而不是直接的段落排名。LLMs的预训练目标与排名目标之间的差异带来了另一个挑战。在这篇论文中,我们首次研究了如ChatGPT和GPT-4这样的生成式LLMs在信息检索中的相关性排名。出乎意料的是,我们的实验表明,经过适当指导的LLMs可以在流行的IR基准测试上提供与最先进的监督方法相当乃至更优的结果。此外,为了解决关于LLMs数据污染的担忧,我们收集了一个名为NovelEval的新测试集,基于最新知识,旨在验证模型对未知知识的排名能力。最后,为了提高实际应用中的效率,我们深入研究了将ChatGPT的排名能力通过排列蒸馏方案蒸馏到小型专门模型的潜力。我们的评估结果表明,一个蒸馏后的440M模型在BEIR基准测试上的表现超过了一个3B的监督模型。
开源链接:https://github.com/sunnweiwei/RankGPT
杰出论文奖二:

论文题目:SODA: Million-scale Dialogue Distillation with Social Commonsense Contextualization
论文链接:https://arxiv.org/abs/2212.10465
论文摘要:
在开放社交对话领域,数据稀缺一直是一个长期存在的问题。为了解决这个问题,我们推出了首个公开可用的百万级高质量社交对话数据集SODA。通过从知识图谱中提取社交常识知识,我们能够从大语言模型中提炼出极其广泛的社交互动类型。人类评估显示,与之前人类编写的数据集相比,SODA中的对话更加一致、具体,而且更自然。
使用SODA,我们训练了一个在未见数据集上更自然、更一致的通用对话模型COSMO:它的性能表现超过了目前表现最好的对话模型(例如GODEL、BlenderBot-1、Koala、Vicuna)。实验表明,COSMO有时甚至比原始的人类编写的优质回复更受青睐。此外,我们的结果也揭示了知识丰富的对话和自然社交闲聊之间的区别。我们计划公开我们的数据、模型和代码。
杰出论文奖三:

论文题目:LINC: A Neurosymbolic Approach for Logical Reasoning by Combining Language Models with First-Order Logic Provers
论文链接:https://arxiv.org/pdf/2310.15164v1.pdf
论文摘要:
逻辑推理是人工智能的一个重要任务,对科学、数学和社会有着广泛的潜在影响。虽然业界已经提出了许多基于prompt的策略来使大语言模型(LLMs)更有效地进行此类推理,但它们效果不佳,经常以不可预测的方式失败。在这项工作中,我们探讨了将此类任务改为模块化的神经符号编程的有效性,我们称之为LINC:通过神经符号计算逻辑推理。
在LINC中,LLM充当语义解析器,将前提和结论从自然语言翻译成一阶逻辑表达式。这些表达式随后被转移到外部定理证明器,该证明器以符号方式进行演绎推理。利用这种方法,我们在几乎所有评估的实验条件下,对于FOLIO和ProofWriter的平衡子集,观察到三种不同模型的显著性能提升。在ProofWriter上,使用LINC增强的相对较小的开源StarCoder+(15.5B参数)甚至比GPT-3.5和GPT-4的思维链(CoT)提示分别提高了38%和10%。与GPT-4一起使用时,LINC在ProofWriter上的得分比CoT高出26%,而在FOLIO上表现相当。进一步分析显示,尽管这两种方法在此数据集上的平均成功率大致相等,但它们展示了不同且互补的失败模式。因此,我们提供了相关证据,展示了如何通过联合利用LLMs和符号证明器来处理自然语言上的逻辑推理。
开源链接:https://github.com/benlipkin/linc
最佳论文 Demo 介绍

最佳论文 Demo 给到了艾伦人工智能研究所(Allen Institute for AI)、UC Berkeley、MIT、华盛顿大学与西北大学组成的联合团队,这项工作开发了一个开源的用于分析和处理视觉信息丰富的结构化的科学文档的 Python 工具包,通过将各种 NLP 和 CV 领域的模型集成到一个统一的框架之中为常见的科学文档处理提供了一站式的解决方案:

论文题目:PaperMage: A Unified Toolkit for Processing, Representing, and Manipulating Visually-Rich Scientific Documents
作者:Kyle Lo, Zejiang Shen, Benjamin Newman, Joseph Chee Chang, Russell Authur, Erin Bransom, Stefan Candra, Yoganand Chandrasekhar, Regan Huff, Bailey Kuehl, Amanpreet Singh, Chris Wilhelm, Angele Zamarron, Marti A. Hearst, Daniel S. Weld, Doug Downey, Luca Soldaini
机构:艾伦人工智能研究所,UC Berkeley,MIT,华盛顿大学,西北大学
论文链接:https://aclanthology.org/2023.emnlp-demo.45.pdf
项目地址:https://github.com/allenai/papermage
论文摘要:尽管目前人们对将自然语言处理和计算机视觉领域的模型应用于学术领域的兴趣与日俱增,但科学文档的处理仍然充满挑战。它们通常是难以使用的 PDF 格式,并且处理它们的模型生态也是零散与不完整的。我们介绍的 papermage 是一款开源 Python 工具包,用于分析和处理视觉丰富的结构化科学文档。papermage 通过将各种最先进的 NLP 和 CV 模型集成到一个统一的框架中来对科学文档进行处理,并为常见的科学文档提供了一站式解决方案。papermage 已经赋能了多个科学文档上的 AI 应用研究,并且为 Semantic Scholar 处理数百万 PDF 的系统提供了支持。
最佳主题论文介绍

论文题目:“Ignore This Title and HackAPrompt...”

论文链接:https://aclanthology.org/2023.emnlp-main.302/
论文摘要:
大语言模型(LLMs)正越来越多地应用于需要直接与用户互动的场景,比如聊天机器人和写作助手。但这些应用越来越多地遭受到提示注入和越狱问题(统称为“提示黑客”),即模型被操纵忽略原本的指令,转而执行可能具有恶意的指令。虽然这被广泛认为是一个重大的安全威胁,但关于提示黑客攻击的大规模资源和定量研究却非常匮乏。为了解决这个问题,我们发起了一个全球性的 prompt黑客竞赛,允许参与者自由形式地输入攻击指令。我们收集了超过60万个针对三种最先进大语言模型的对抗性提示。本文介绍了这个数据集,它实际上证实了当前的大语言模型确实可以通过prompt黑客被操纵。我们还展示了一套关于对抗性提示类型的全面分类体系。
最佳行业论文

论文题目:Personalized Dense Retrieval on Global Index for Voice-enabled Conversational Systems
论文链接:https://aclanthology.org/2023.emnlp-industry.9/
论文摘要:语音控制的AI对话系统容易受到语音变化的干扰,且常常无法解决模糊实体的问题。通常,我们会采用个性化实体解析(ER)和/或查询重写(QR)来克服这些错误模式。以往在这一领域的工作,是通过限制检索空间到用户与设备历史互动构建的个性化索引来实现个性化。虽然这种受限检索可以实现高精度,但其预测只限于用户近期历史中的实体,这对未来请求的覆盖度较低。
此外,为数百万用户维护各自的索引在内存上的需求巨大,且难以扩展。在这项工作中,我们提出了一个鲁棒的个性化实体检索系统,它不仅能抵御语音噪音和歧义,而且不局限于个性化索引。我们通过将用户的听觉偏好嵌入到用于检索的上下文查询嵌入中来实现这一点。我们展示了我们的模型在纠正多种错误模式上的能力,并在实体检索任务上比基线水平提高了91%。最后,我们优化了端到端的方法,使其符合在线延迟限制,同时保持性能提升。
大会花絮
有参会人员表示,在现场找到了最佳海报:

最佳海报+1 :

最省钱的海报?

还有参会人员表示,有时我们使用“变形金刚”(transformer),有时则需要骑变形金刚。

最后,EMNLP 2024将于24年11月12-16日在佛罗里达州迈阿密举行。



