
热门标签
热门文章
- 1AI去水印神器轻松一键去除图片水印,还原高清完美画面!_在线 图片ai去字
- 2AppReview 奇葩问题1_during review, your app installed or launched exec
- 3c语言学习笔记(9)AT指令时经常用到 -c语言库函数_at指令通常用什么函数
- 4linux MongoDB 安装与配置
- 5centos7安装 postgresql postgis pgrouting_centos7 安装postgre
- 6【GitHub项目推荐--开源工业机器人手臂项目】【转载】_开源机械臂系统
- 7MySql 分库分表问题_分库分表后的聚合查询
- 8git submodule 子模块的基本使用_git包含子模块引用仓库,拉代码只拉到主仓库部分
- 9PostgreSQL存储过程(六):结构控制和循环_pg 存储过程 循环
- 10python旅游大数据分析可视化大屏 游客分析+商家分析+舆情分析 计算机毕业设计(附源码)Flask框架✅_旅游景点大屏可视化可以做什么图分析
当前位置: article > 正文
使用yolov8实现自动车牌识别(教程+代码)_yolov8身份证识别
作者:你好赵伟 | 2024-04-24 06:18:28
赞
踩
yolov8身份证识别
该项目利用了一个被标记为“YOLOv8”的目标检测模型,专门针对车牌识别任务进行训练和优化。整个系统通常分为以下几个核心步骤:
-
数据准备:
- 收集包含车牌的大量图片,并精确地标记车牌的位置和文本信息。
- 数据集可能包含各种环境下的车牌,如不同光照条件、角度、遮挡情况等,以确保模型泛化能力。
-
模型训练:
- 使用改进或假设的YOLOv8架构加载预训练权重(如果有),并在此基础上微调模型以适应车牌检测任务。
- 训练过程涉及调整超参数、优化器设置,以及迭代训练至模型在验证集上达到满意的性能。
-
车牌检测:
- 将训练好的YOLOv8模型应用于输入的图像或视频流,以实时或批量模式进行车牌区域检测。
- 通过模型的输出解析出车牌的边界框坐标。
-
车牌字符识别(OCR):
- 对检测到的车牌区域进行裁剪并做进一步预处理(如灰度化、二值化、平滑、倾斜校正等)。
- 使用单独的OCR模型(如LPRNet或其他专门的车牌字符识别网络)识别出车牌上的每一个字符。
-
结果输出:
- 根据字符识别的结果拼接出完整的车牌号码,并显示或记录在系统中。
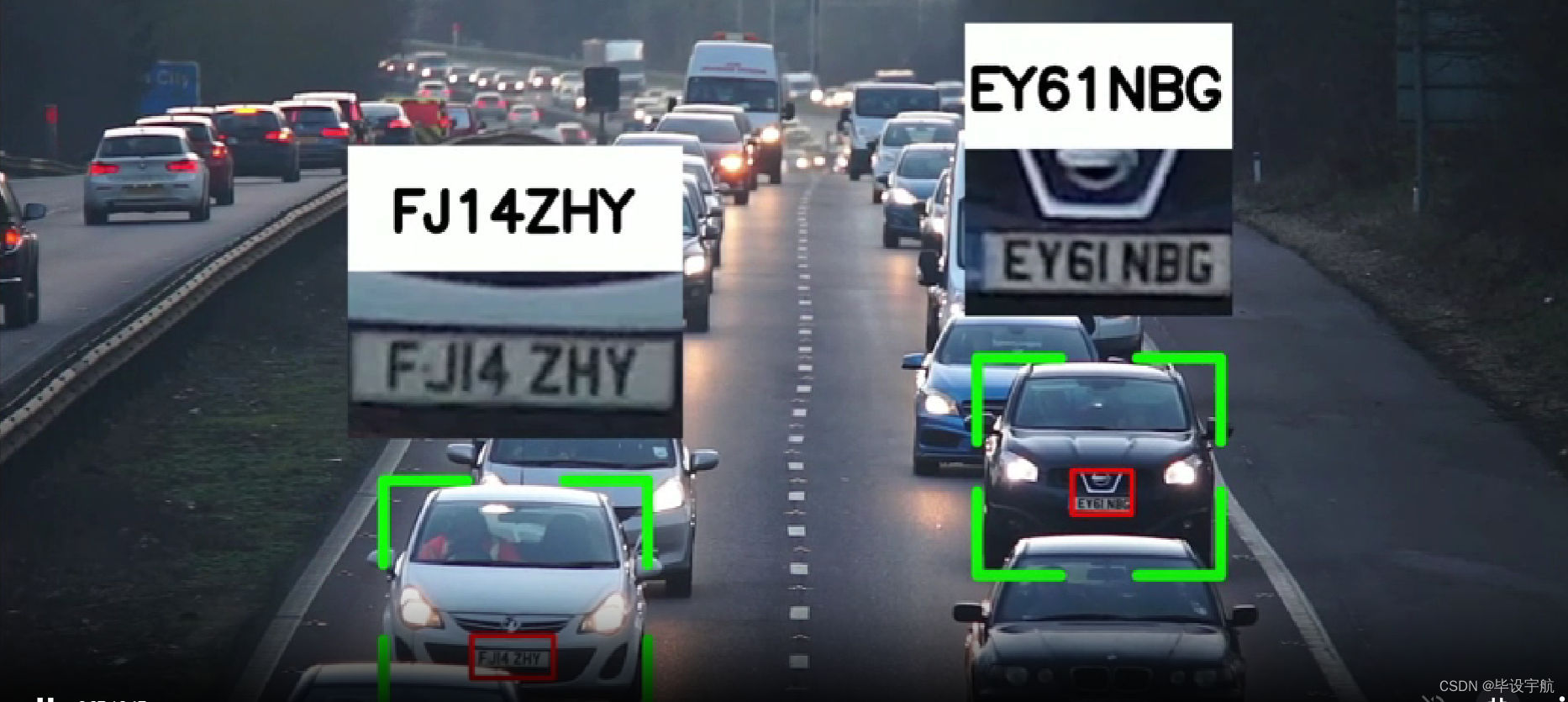
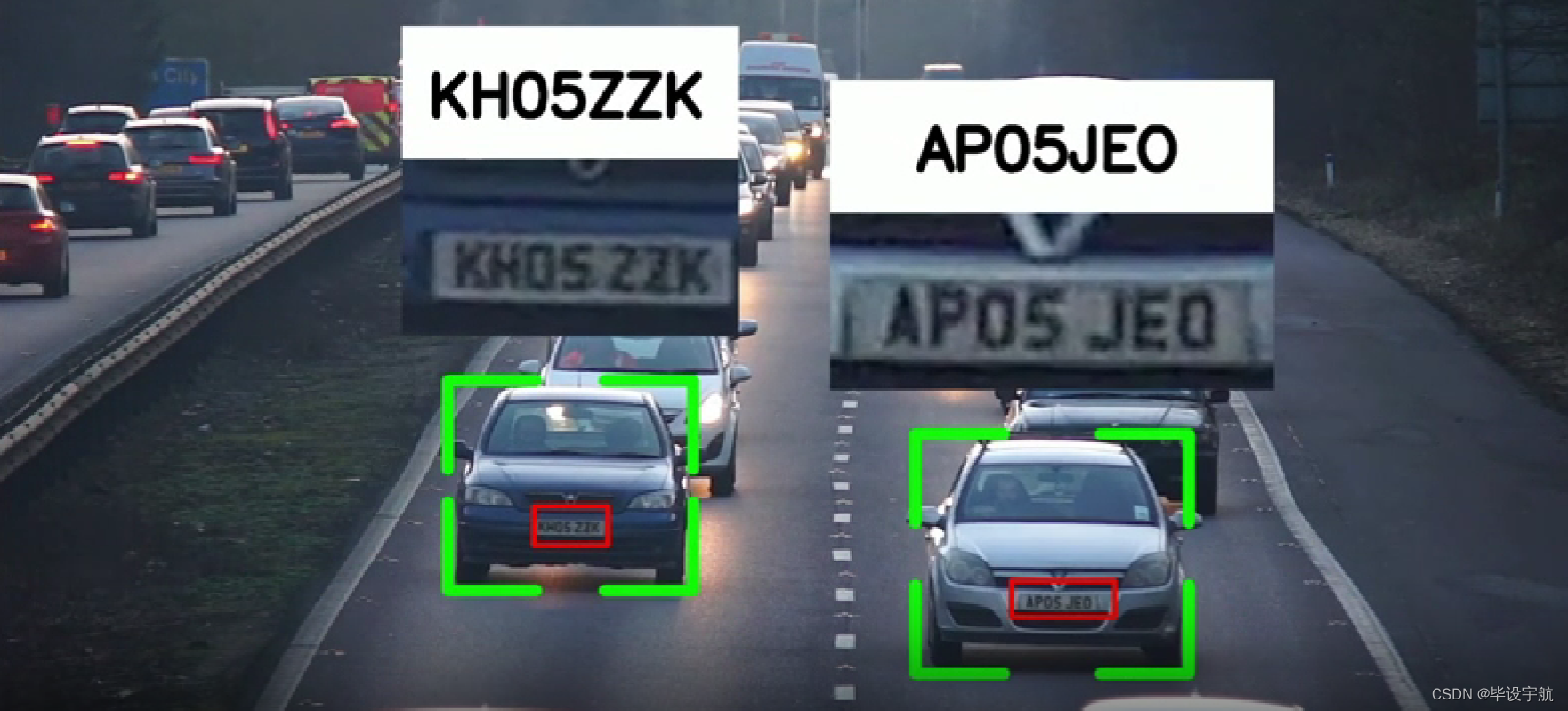
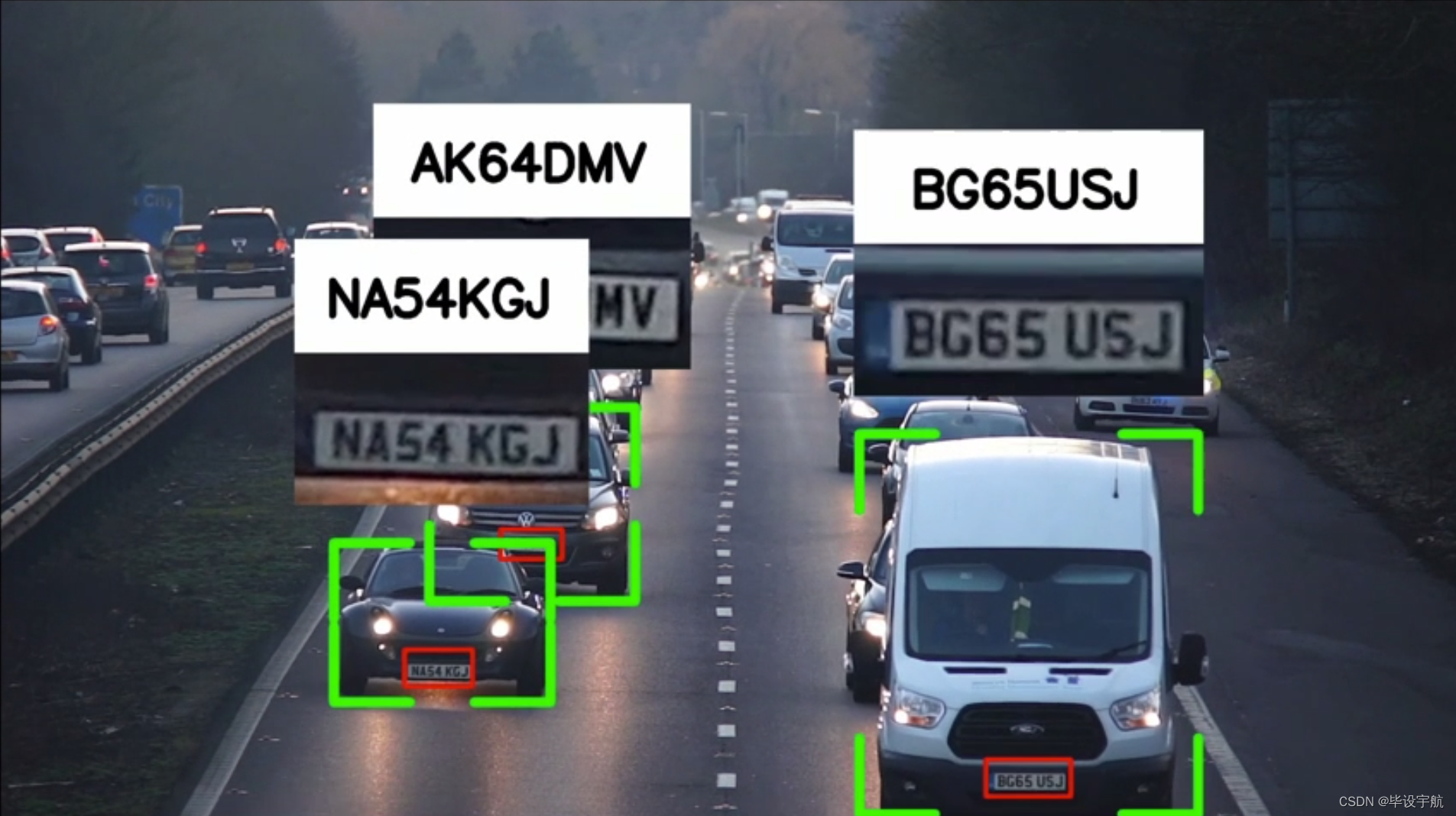
使用Yolov8预训练模型(YOLOv8n)检测车辆。
使用有执照的车牌检测器来检测车牌。该模型使用该数据集使用 Yolov8 进行训练。
项目设置
- 使用以下命令使用 python=3.8 创建环境
conda create --prefix ./env python==3.8 -y- 激活环境
conda activate ./env- 使用以下命令安装项目依赖项
pip install -r requirements.txt- 使用示例视频文件运行 main.py 以生成test.csv文件
python main.py- 运行 add_missing_data.py 文件以插入值以匹配缺失的帧和平滑输出。
python add_missing_data.py- 最后运行 visualize.py 传入插值的 csv 文件,从而获得用于车牌检测的平滑输出。
python visualize.py效果如图:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/477959
推荐阅读
相关标签

