
分类算法常用的评价指标_分类评价指标
赞
踩
该博文内容大部分是参考自Poll的笔记和dzl_ML两位博主的写作内容,再经过自己的学习,理解和整理后形成该文。参考资料的链接在最后部分给出。
1,评价指标列表
2,基本概念
针对一个二分类问题,即将实例分成正类(positive)或负类(negative),在实际分类中会出现以下四种情况:
(1)若一个实例是正类,并且被预测为正类,即为真正类(True Positive TP)
(2)若一个实例是正类,但是被预测为负类,即为假负类(False Negative FN)
(3)若一个实例是负类,但是被预测为正类,即为假正类(False Positive FP)
(4)若一个实例是负类,并且被预测为负类,即为真负类(True Negative TN)
3,准确率(Accuracy)
- 定义:对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。
- 计算公式: A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy = \frac{TP+TN}{TP+TN+FP+FN} Accuracy=TP+TN+FP+FNTP+TN
- 缺点:在正负样本不平衡的情况下,这个指标有很大的缺陷。例如:给定一组测试样本共1100个实例,其中1000个是负类,剩余100个是正类。即使分类模型将所有实例均预测为负类,Accuracy也有90%以上,这样就没什么意义了。
4,精确率(Precision)、召回率(Recall)和F1值
精确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中:
- 精确率是检索出相关文档数与检索出的文档总数的比率(正确分类的正例个数占分类为正例的实例个数的比例),衡量的是检索系统的查准率。 p r e c i s i o n = T P T P + F P precision = \frac{TP}{TP+FP} precision=TP+FPTP
- 召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率(正确分类的正例个数占实际正例个数的比例),衡量的是检索系统的查全率。 r e c a l l = T P T P + F N recall = \frac{TP}{TP+FN} recall=TP+FNTP
为了能够评价不同算法优劣,在Precision和Recall的基础上提出了F1值的概念,来对Precision和Recall进行整体评价。F1的定义如下:
F
1
=
精确率
∗
召回率
∗
2
精确率
+
召回率
F1 = \frac{精确率*召回率*2}{精确率+召回率}
F1=精确率+召回率精确率∗召回率∗2
我们当然希望检索结果(分类结果)的Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的(分类后的正确实例只有一个,且该实例原本就是正实例),那么Precision就是100%,但是Recall就会很低;而如果我们把所有结果都返回(所有的结果都被分类为正实例),那么Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高还是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
5,综合评价指标F-Measure
Precision和Recall指标有时候会出现矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。F-Score是Precision和Recall的加权调和平均:
F
=
(
a
2
+
1
)
P
∗
R
a
2
(
P
+
R
)
F=\frac{(a^2+1)P*R}{a^2(P+R)}
F=a2(P+R)(a2+1)P∗R
当参数
a
=
1
a=1
a=1时,就是最常见的F1.因此,F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
6,ROC曲线和AUC
6.1,TPR、FPR&TNR
在介绍ROC和AUC之前,我们需要明确以下几个概念:
- 真正类率(true positive rate, TPR),也称为sensitivity,刻画的是被分类器正确分类的正实例占所有正实例的比例。 T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
- 负正类率(false positive rate, FPR),也称为1-specificity,计算的是被分类器错认为正类的负实例占所有负实例的比例。 F P R = F P F P + T N FPR =\frac{FP}{FP+TN} FPR=FP+TNFP
- 真负类率(true negative rate, TNR),也称为specificity,刻画的是被分类器正确分类的负实例占所有负实例的比例。 T N R = 1 − F P R = T N F P + T N TNR = 1 - FPR = \frac{TN}{FP+TN} TNR=1−FPR=FP+TNTN
6.2 ,为什么引入ROC曲线?
- Motivation1:在一个二分类模型中,对于所得到的连续结果,假设已确定一个阈值,比如说0.6,大于这个值的实例为正类,小于这个值则为负类。如果减小阈值,比如减到0.5,固然能之别出更多的正类,也就是提高了识别出的正例占所有正例的比例,即TPR值变大;但同时也将更多的负实例当作了正实例,即,提高了FPR。为了形象化这一变化,引入了ROC,ROC可以用于评价一个分类器。
- Motivation2:在类不平衡的情况下,如正样本90个,负样本10个,直接把所有样本分类为正样本,得到识别率为90%。但这显然是没有意义的。单纯根据Precision和Rcall来衡量算法的优劣已经不能表征这种病态问题。
6.3 ,什么是ROC曲线?
ROC曲线:接收者操作特征(receiver operating characteristic),ROC曲线上每个点反映着对同一信号刺激的感受性。
- 横轴:负正类率(FPR,特异度);
- 纵轴:真正类率(TPR,灵敏度)。
以逻辑回归分类器(LR)举例,LR给出了针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类汇中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。如下这幅图,图(a)中实线为ROC曲线,线上每个点对应一个阈值。
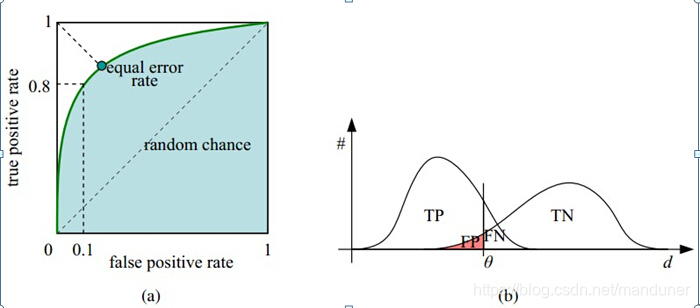
理想目标: TPR=1, FPR=0,即图中(0,1)点。故ROC曲线越靠拢(0,1)点,即,越偏离45度对角线越好。
6.4,如何画ROC曲线
假设已经得出一系列被划分为正类的概率,然后按照大小排序,下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。

接下来,我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:

6.5,什么是AUC曲线?
AUC(Area Under Curve):ROC曲线下的面积,介于0.1和1之间。AUC作为数值可以直观的评价分类器的好坏,值越大越好。
AUC的物理意义:首先AUC值是一个概率值。假设分类器的输出是样本属于正类的Score(置信度),则AUC的物理意义为,任取一对(正、负)样本,正样本的Score大于负样本的Score的概率。
6.6,怎样计算AUC?
-
方法一:AUC为ROC曲线下的面积,那我们直接极端面积可得。面积为一个个小的梯形面积之和。计算的精度与阈值的精度有关。
-
方法二:根据AUC的物理意义,我们计算正样本Score大于负样本Score的概率。取 N ∗ M ( N 为正样本数, M 为负样本数 ) N*M(N为正样本数,M为负样本数) N∗M(N为正样本数,M为负样本数)个二元组,比较Score,最后得到AUC。时间复杂度为 O ( N ∗ M ) O(N*M) O(N∗M)。
具体的计算方法详见AUC的计算方法 -
方法三:我们首先把所有样本按照score排序(从小到大或从大到小),依次用rank表示他们,如,按从大到小排序的时候,最大score的样本序号值 r a n k = n rank=n rank=n,其中 n = M + N n=M+N n=M+N,其次是 n − 1 n-1 n−1。然后利用下面的公式计算AUC,
A U C = ∑ 所有正样本 r a n k − M ∗ ( M − 1 ) 2 M ∗ N AUC = \frac{\sum_{所有正样本}rank-\frac{M*(M-1)}{2}}{M*N} AUC=M∗N∑所有正样本rank−2M∗(M−1)
其中, ∑ 所有正样本 r a n k \sum_{所有正样本}rank ∑所有正样本rank 表示所有正样本的序号值 r a n k rank rank之和;时间复杂度是 O ( M + N ) O(M+N) O(M+N)。
具体的计算案例详见AUC的计算方法
7,为什么使用ROC和AUC评价分类器呢?
既然已经这么多标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。下图是ROC曲线和Presision-Recall曲线的对比:

在上图中,(a)和©为Roc曲线,(b)和(d)为Precision-Recall曲线。
(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,©(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果,可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线变化较大。
8,参考资料
https://www.cnblogs.com/maybe2030/p/5375175.html#_label3
https://www.cnblogs.com/dlml/p/4403482.html
https://blog.csdn.net/qq_22238533/article/details/78666436

