
- 1SUSAN角点检测算法,及其Matlab实现_susan算子检测角点的步骤
- 2SQLAlchemy_sqlalchemy.query with_entities
- 3英特尔携手浪潮信息构建端到端的隐私保护机器学习方案_spark隐私保护
- 4STM32 单片机 导盲杖 超声波 18650电池 光强GY-30 程序_18650 stm32
- 5算法题 石子合并(Python)_python代码实现石子合并中最大得分和最小得分运行结果
- 6绑定Open AI api-key获取token要怎么操作?_openai token
- 7C语言自定义类型_c语言用户自定义类型名称有几个
- 8你必须要知道的软件测试3个主流方式_软件测试的最后一步是什么测试
- 9什么是STC89C52单片机
- 10R语言配置jupter亲测可用_配置r进入jupyter
【开源语音项目OpenVoice](一)——实操演示_openvoice怎么用
赞
踩
目录
一、前菜
开始之前,前菜是必备的,需要先设置好。
1、Python选择
本项目使用的python版本是3.9版,因此,实操之前需要安装python3.9.
这里简单说明即可。
官网Python Release Python 3.9.0 | Python.orgDownload Python | Python.org,系统为Windows版,点击如图windowsPython Release Python 3.9.0 | Python.org

这里就不纠结了,直接3.9.0版本即可。
安装时以管理员身份运行,选择自定义安装。以3.12.2为例,其实是一样的。

注意勾选将python加入环境变量,就不需要手动添加环境变量了。
另外,选择自定义安装位置。其他默认即可。
2、pip源切换
勾选显示隐藏的项目

切到路径C:\Users\whyafer\AppData\Roaming\pip,其中,whyafer为自己的电脑用户名。记事本打开pip.ini文件,删除原有的代码,覆盖如下代码即可。
- [global]
- index-url = https://pypi.tuna.tsinghua.edu.cn/simple
- [install]
- trusted-host=pypi.tuna.tsinghua.edu.cn
这样可以一劳永逸地解决安装插件时网络问题。
3、ffmpeg配置问题
使用的python虚拟环境会用到ffmpeg,但需要环境变量的配置。
官网Builds - CODEX FFMPEG @ gyan.dev下载6.1.1即可

选择一个位置,解压,然后打开环境变量设置。
按win键,输入环境变量

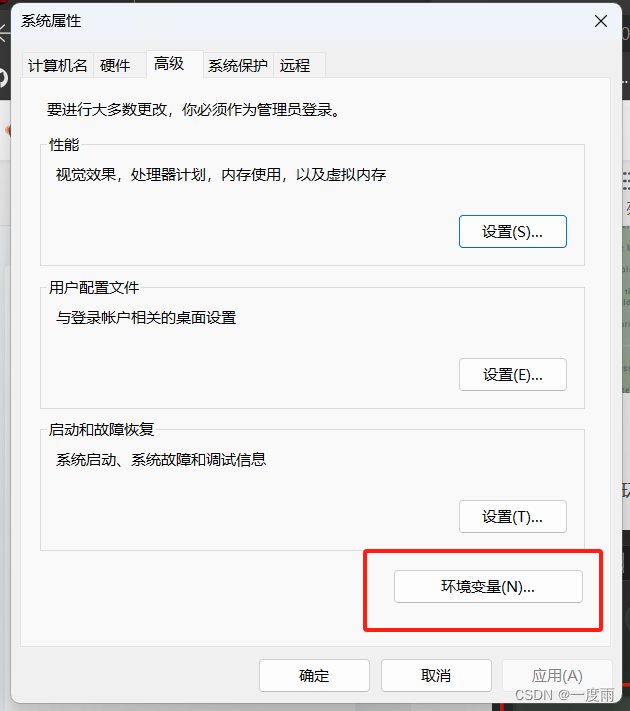
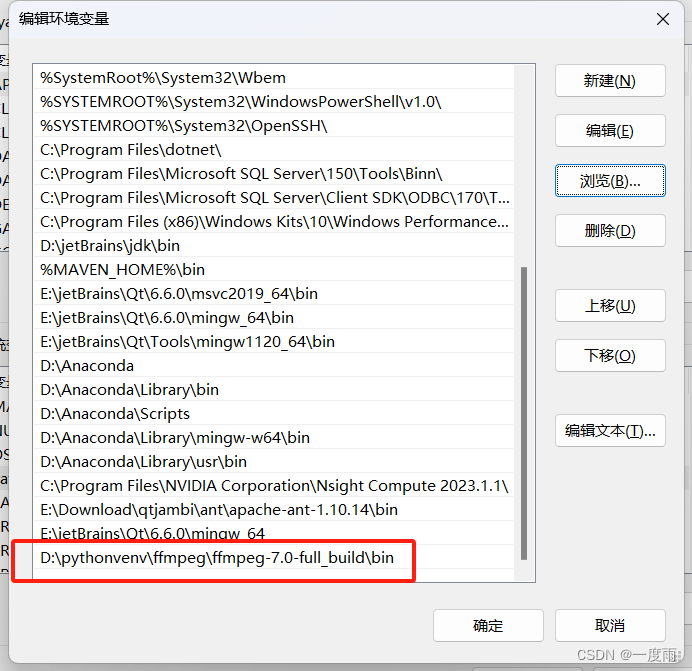
双击系统变量,path
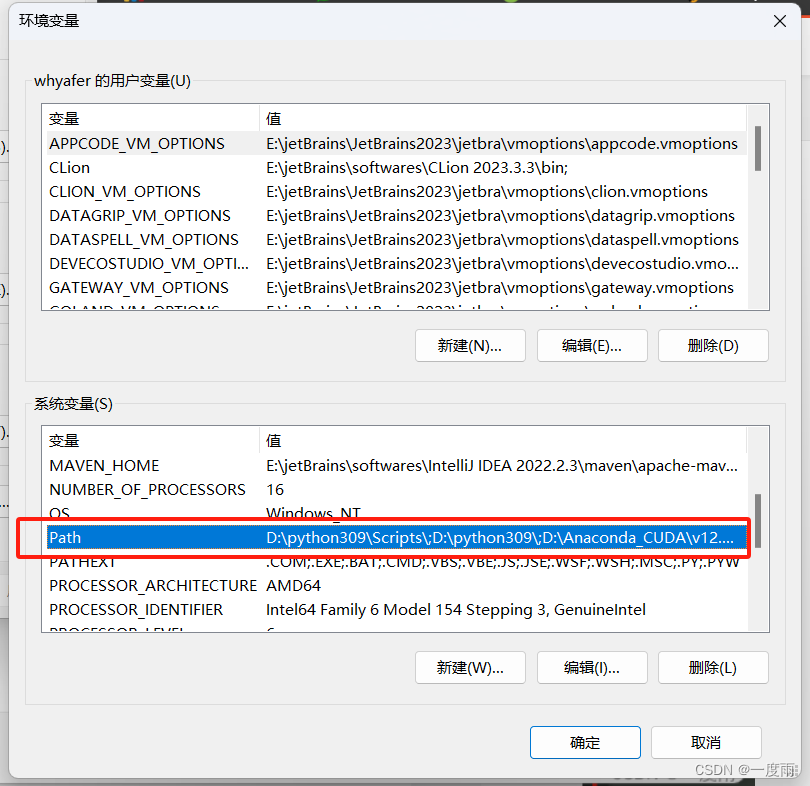 依次选择
依次选择
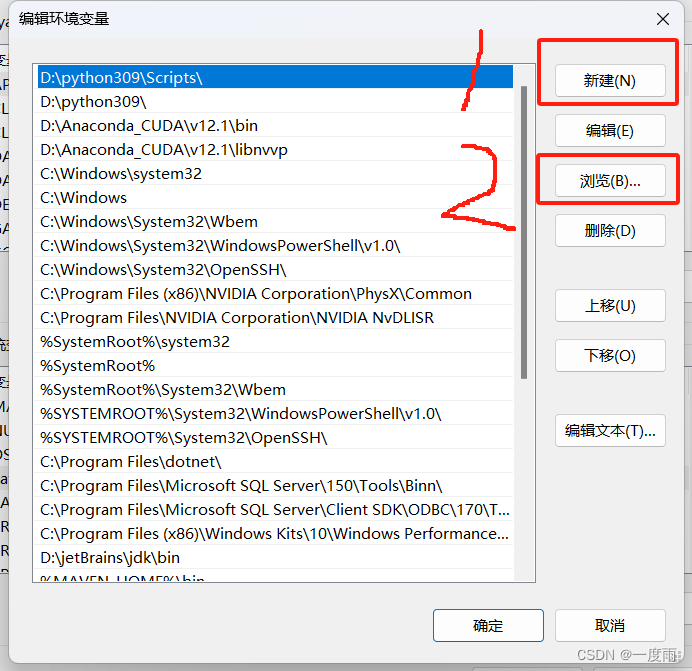
点击到ffmpeg解压的bin文件夹下
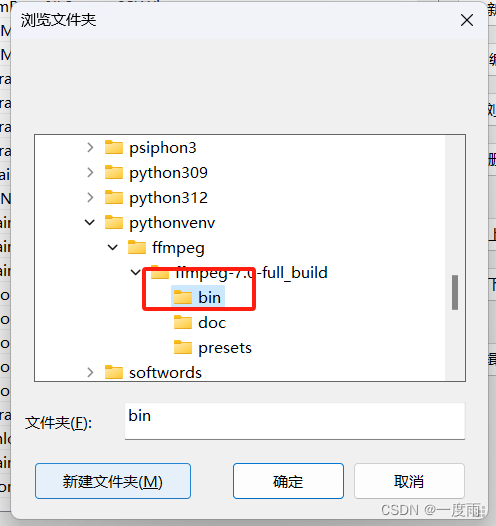
确定即可
 按win键,cmd,输入如下代码
按win键,cmd,输入如下代码
ffmpeg -version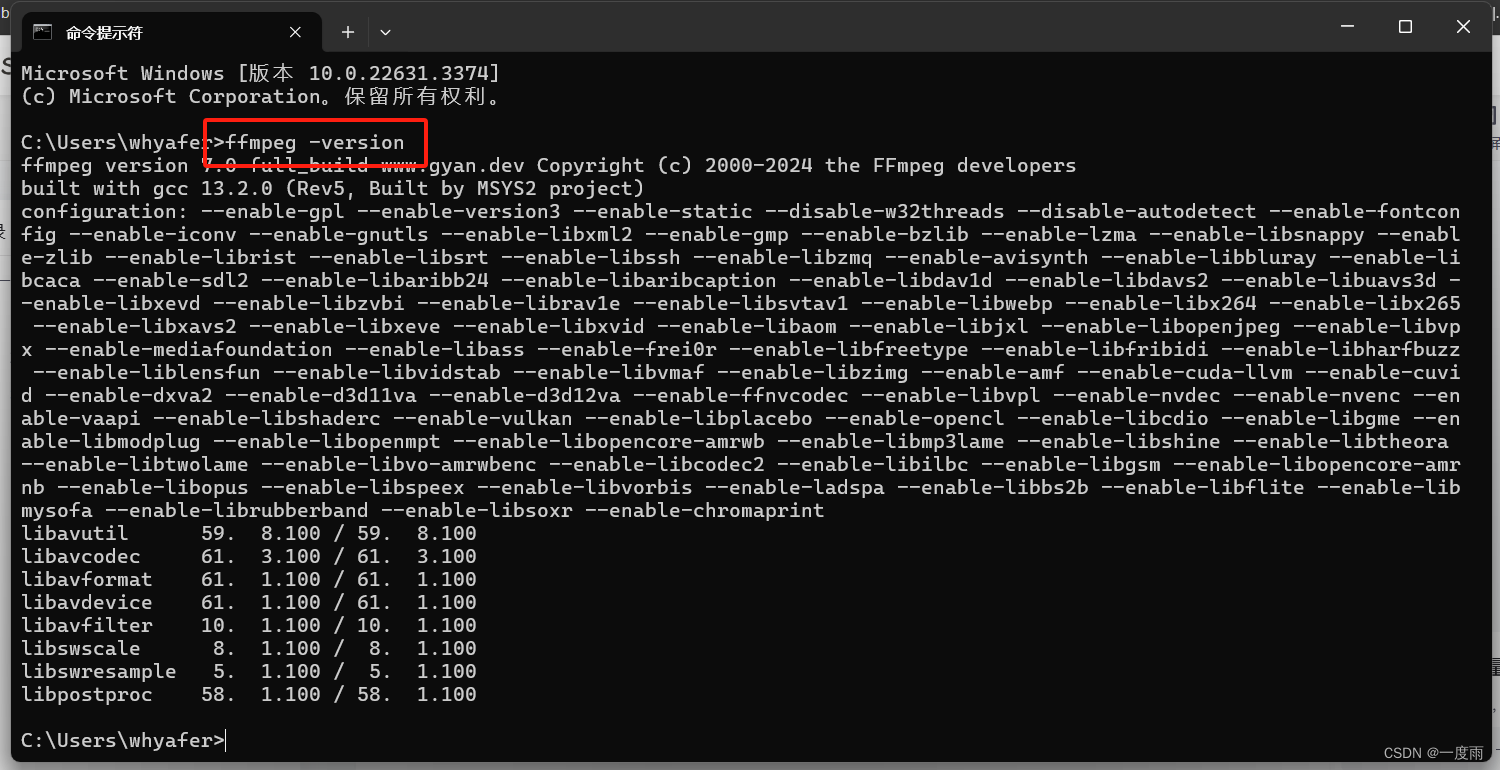
说明配置完成。
若还是不行,则需要另外的操作。
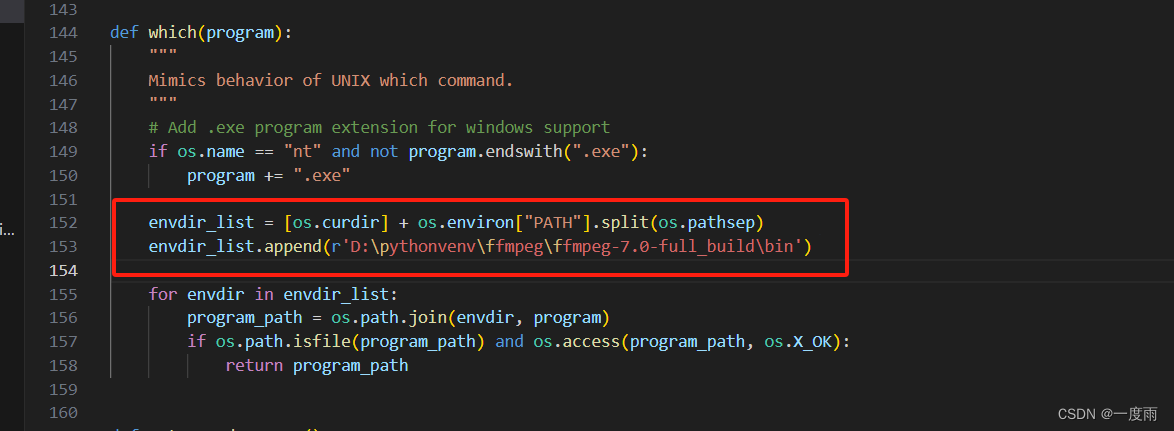
配合创建的python虚拟环境使用。找到路径:.venv\Lib\pydub\utils.py,找到which()函数下如下代码
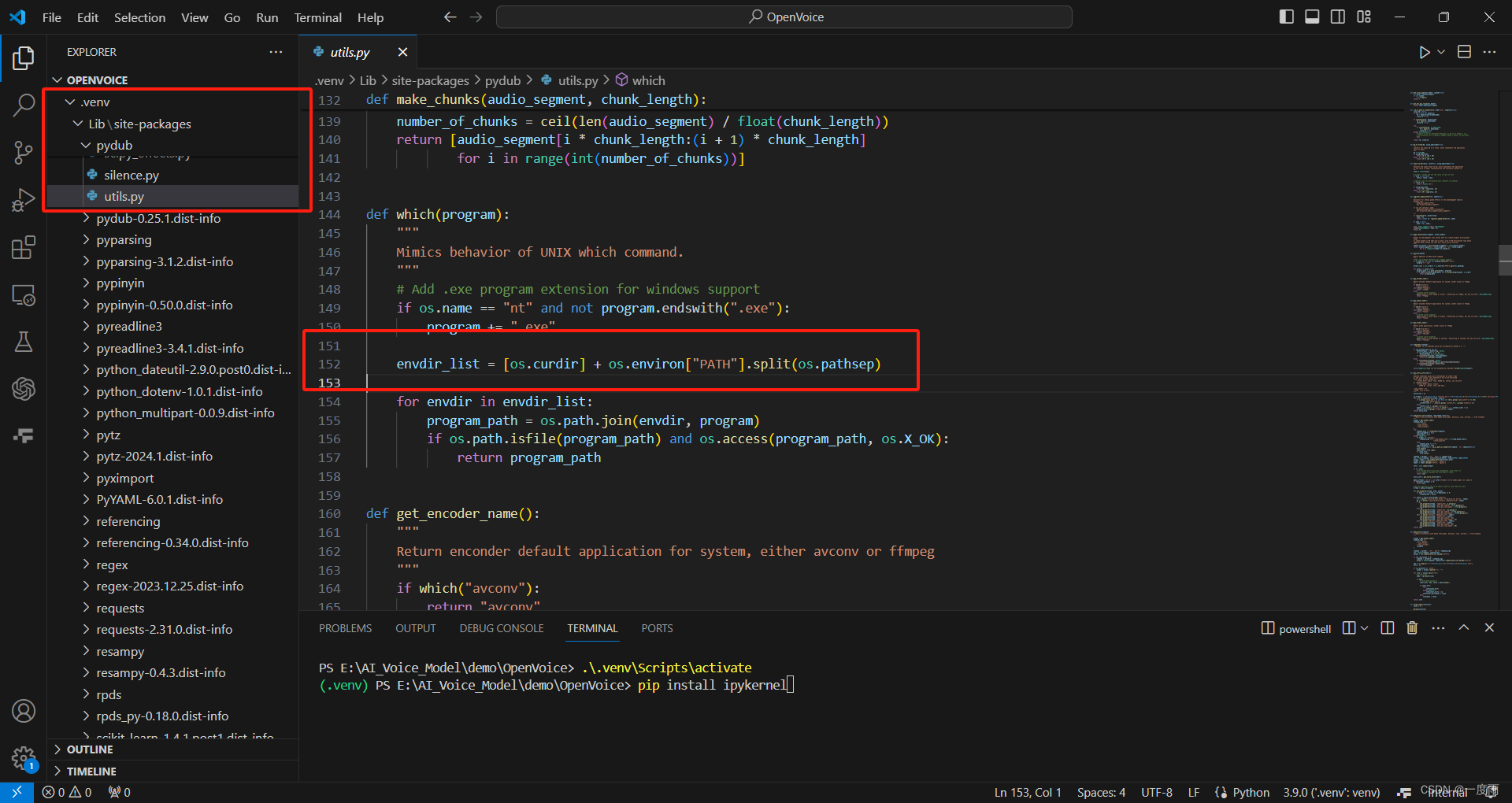
下一行添加:路径为自己解压路径。保存ctrl+s即可。
envdir_list.append(r'D:\pythonvenv\ffmpeg\ffmpeg-7.0-full_build\bin')
4、VSCode添加Jupyter扩展
点击F1,选择Extensions:Install Extensions

输入Jupyter搜索,安装第一个即可,会自动安装附带扩展。

二、配置虚拟环境
1、下载源码
源码地址:myshell-ai/OpenVoice: Instant voice cloning by MyShell. (github.com)
两种方法
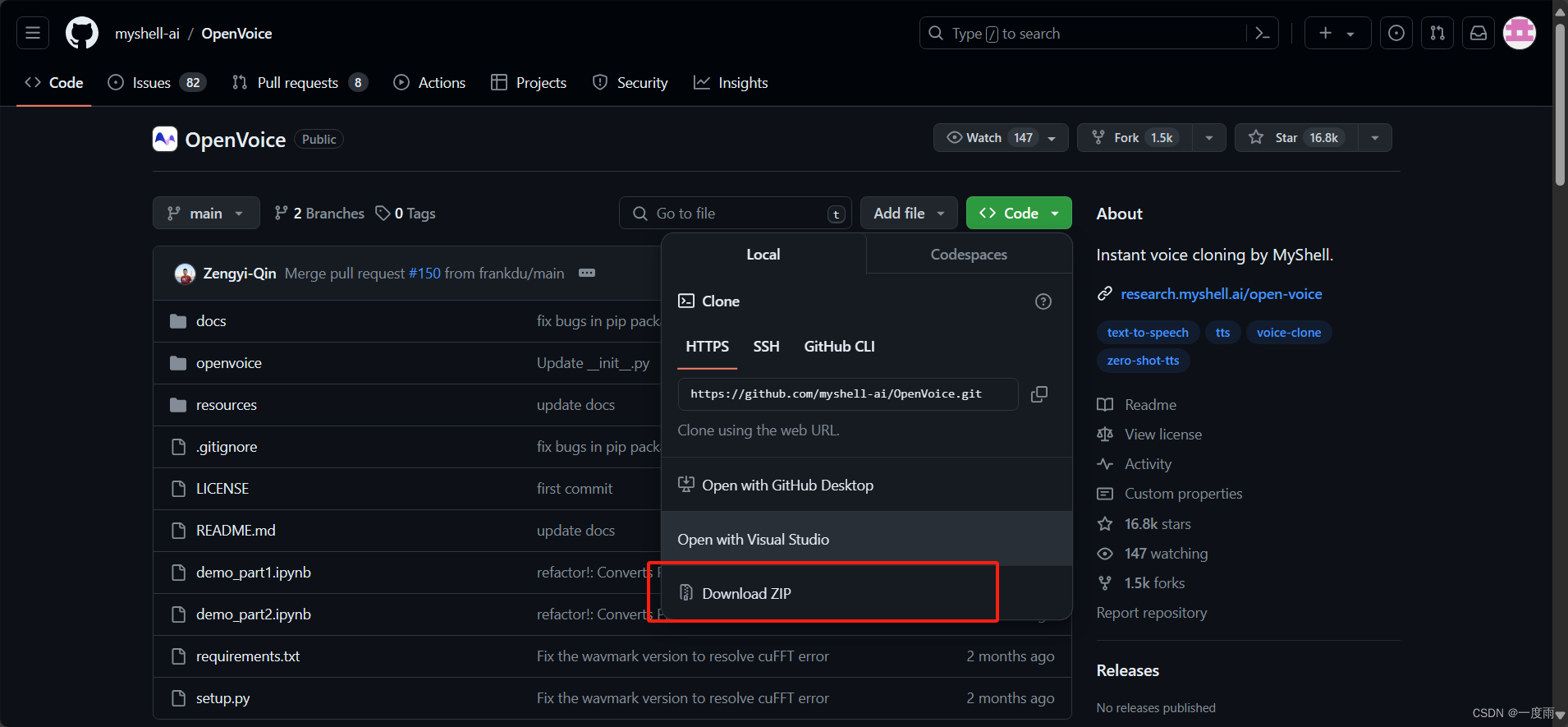
方法一 直接下载源码压缩包
建议使用此方法。如图下载压缩包,解压到你新建的空白项目文件夹下即可。
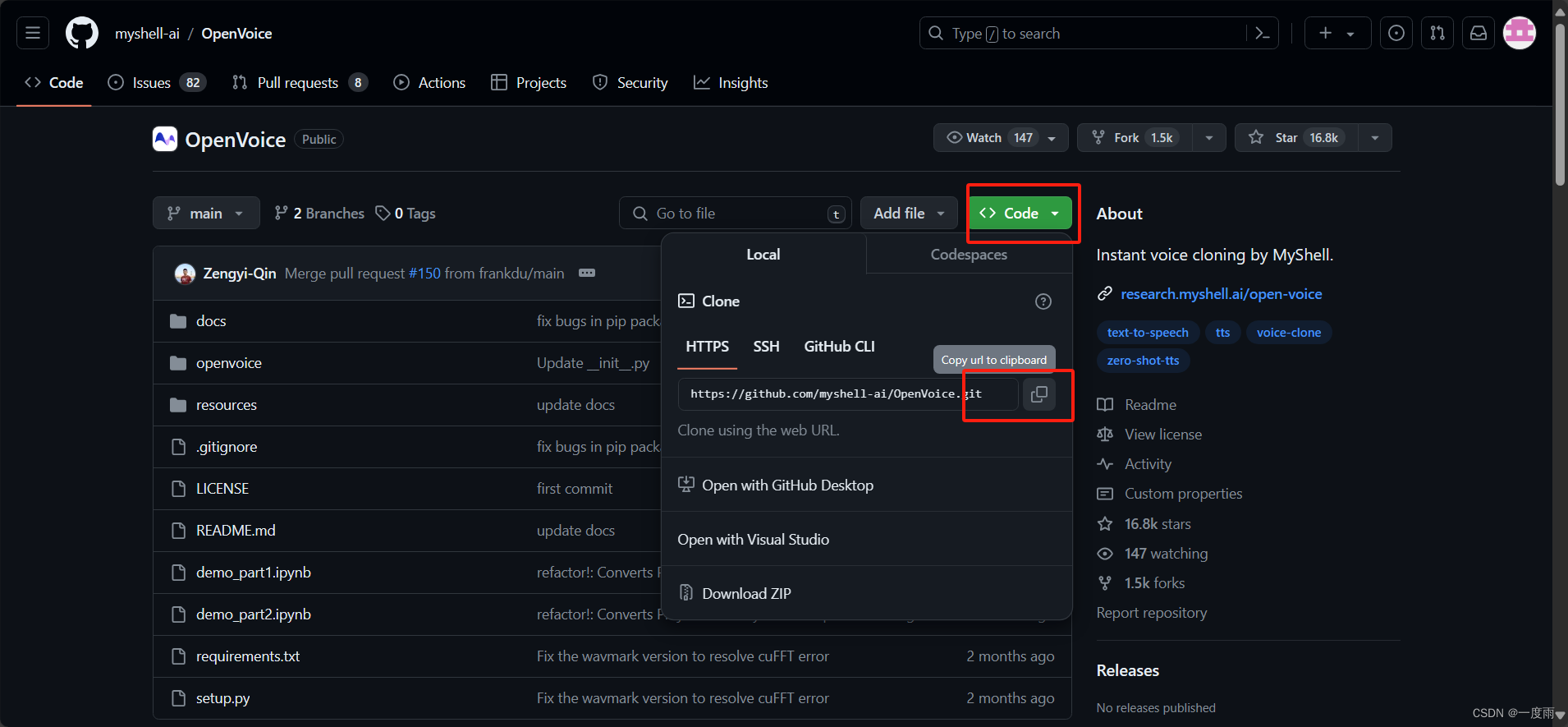
方法二 使用git
如果你电脑里有git,可以使用
首先,新建文件夹
在空文件夹下,右键鼠标选择Git Bash Here,前提是你已经将git加入鼠标右键了。如果没有的话,请将git加入鼠标右键。
1)git加入鼠标右键
win+R,输入regedit,打开注册表,收起计算机项目
在地址栏输入如下代码,回车enter
\HKEY_CLASSES_ROOT\Directory\Background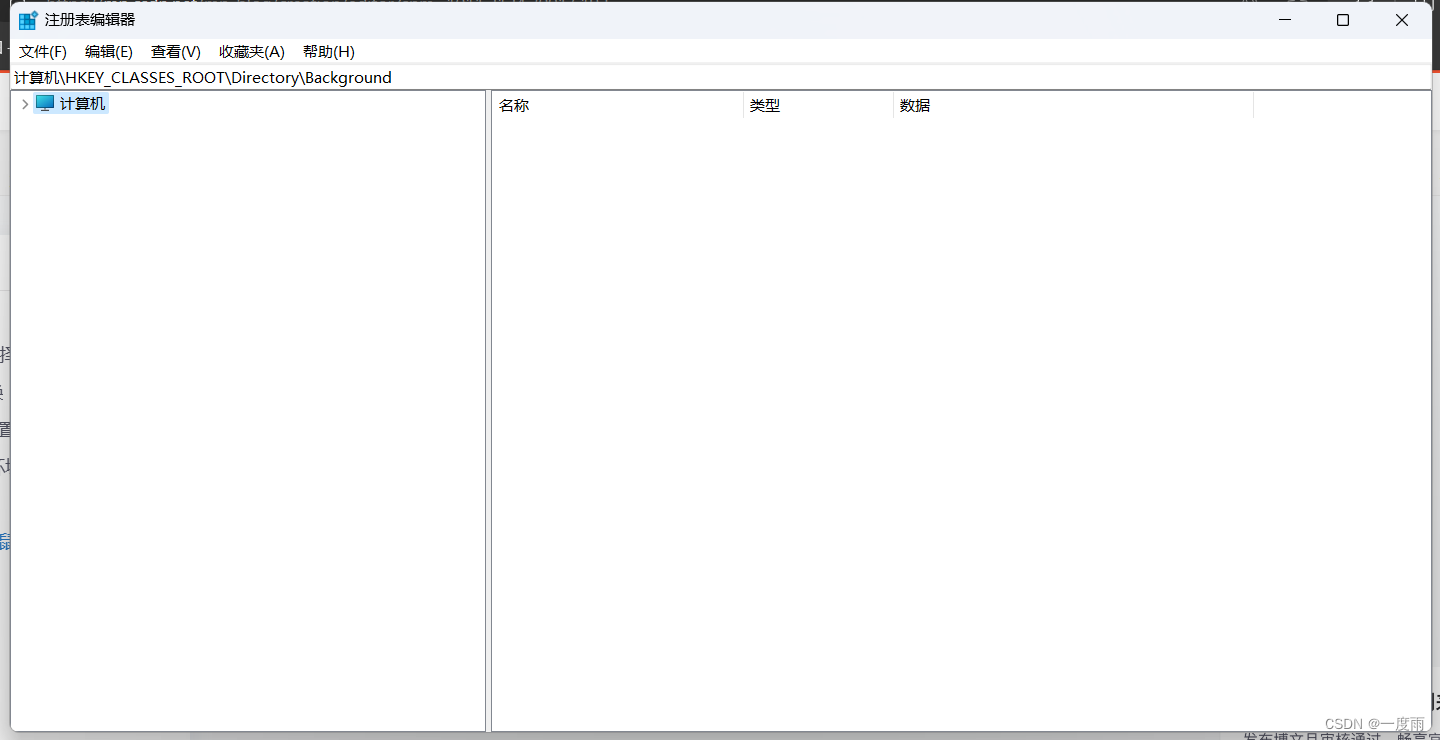
在Background\shell下,新建项“Git Bash Here”,名称随意。然后,在新建项下,新建项“command",我是已经新建好的。

 然后,点击新建项"Git Bash Here",随后注册表右侧空白处右键新建字符串值,命名为"Icon"。
然后,点击新建项"Git Bash Here",随后注册表右侧空白处右键新建字符串值,命名为"Icon"。
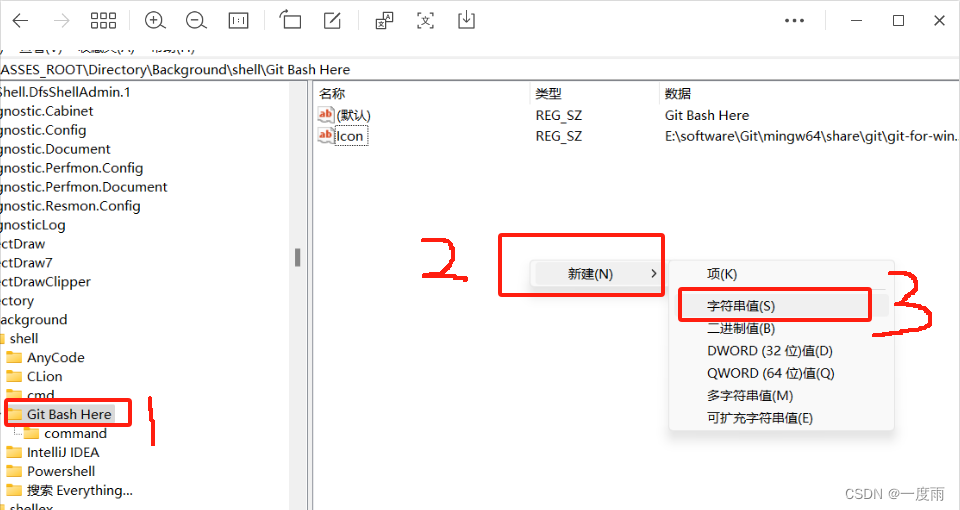
还是在鼠标点击"Git Bash Here"的情况下,即上图1,双击右侧默认项,值为”Git Bash Here",即显示在鼠标右键的名称。

双击"Icon",值为"E:\software\Git\mingw64\share\git\git-for-windows.ico",为鼠标右键的图标。

然后,鼠标点击"commond",双击右侧默认项,值为:" E:\software\Git\git-bash.exe"

2)git clone源码
在新建的空白项目文件夹下,右键鼠标,选择"Git Bash Here",若没有这个选择,可能需要点击"显示更多选项",在控制台输入如下代码,回车即可。
git clone https://github.com/myshell-ai/OpenVoice.git
2、VSCode出场
1)创建python虚拟环境
使用VSCode打开项目,按F1按钮,选择如图选项,Python:Select Interpreter

选择新建虚拟环境
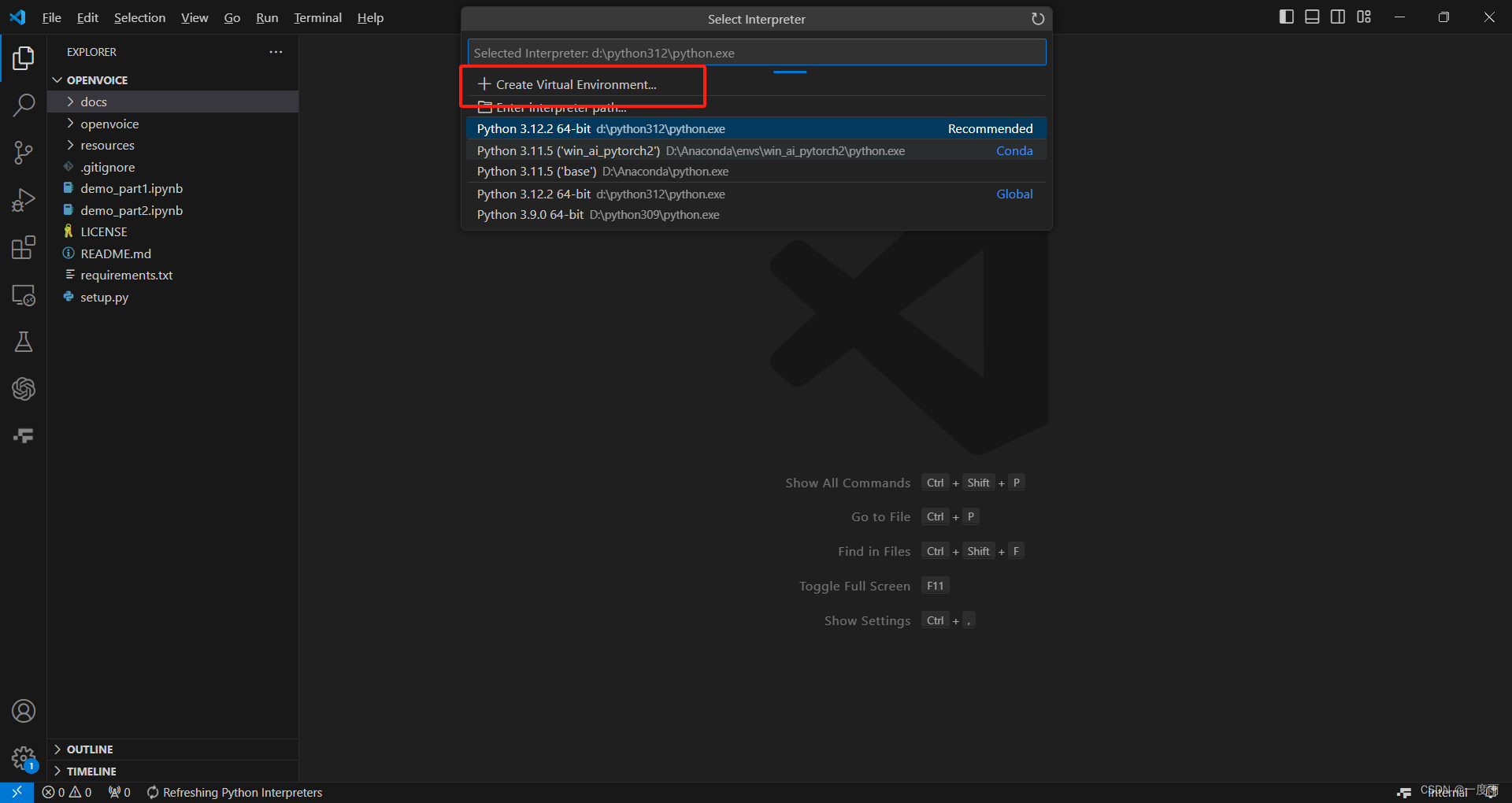
选择"Venv"

选择3.9python
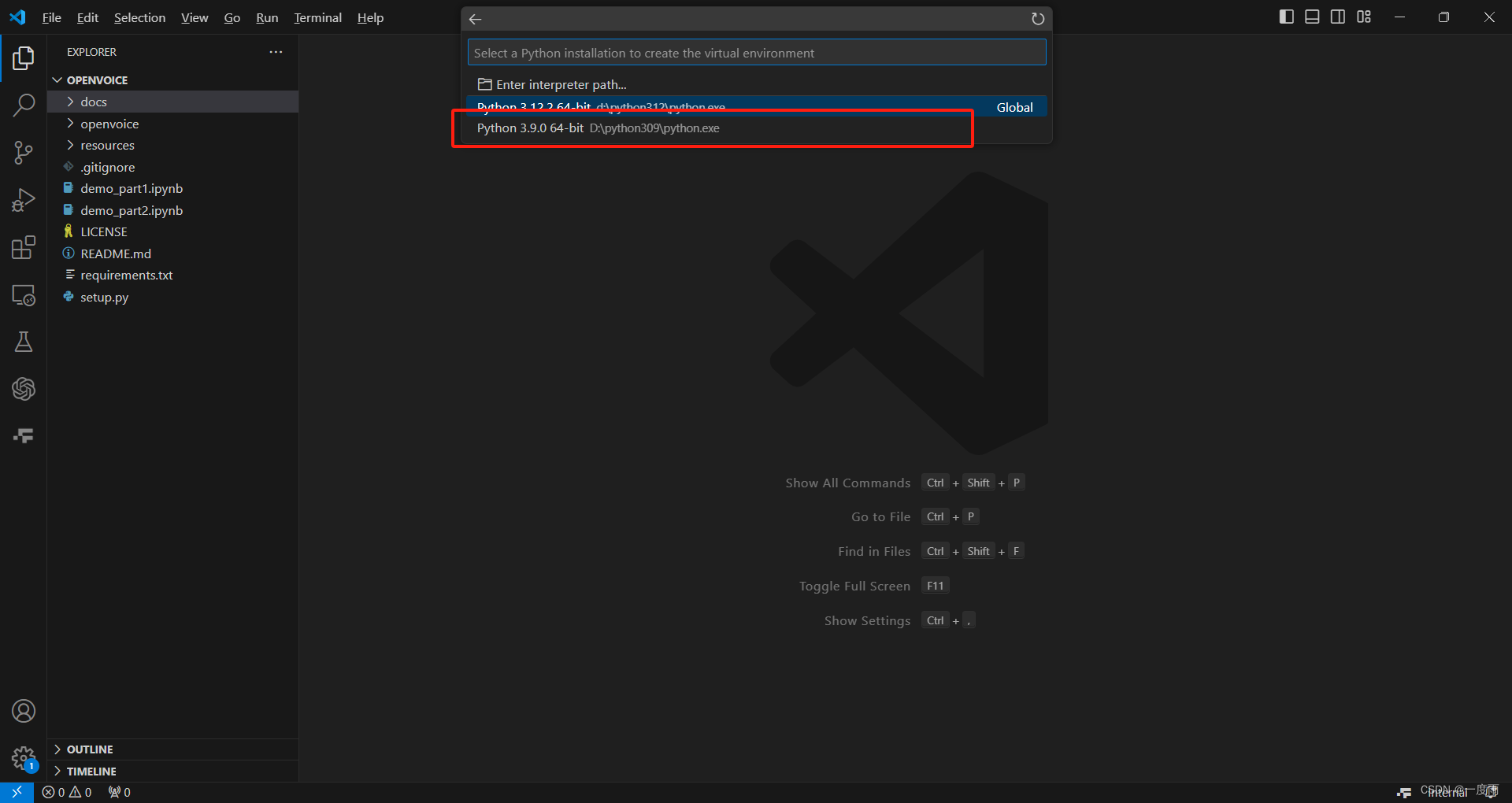
若没有3.9python选项,选择第一个"Enter interpreter path"
 点击"Find",选到你按照python3.9的文件夹下的python.exe即可。
点击"Find",选到你按照python3.9的文件夹下的python.exe即可。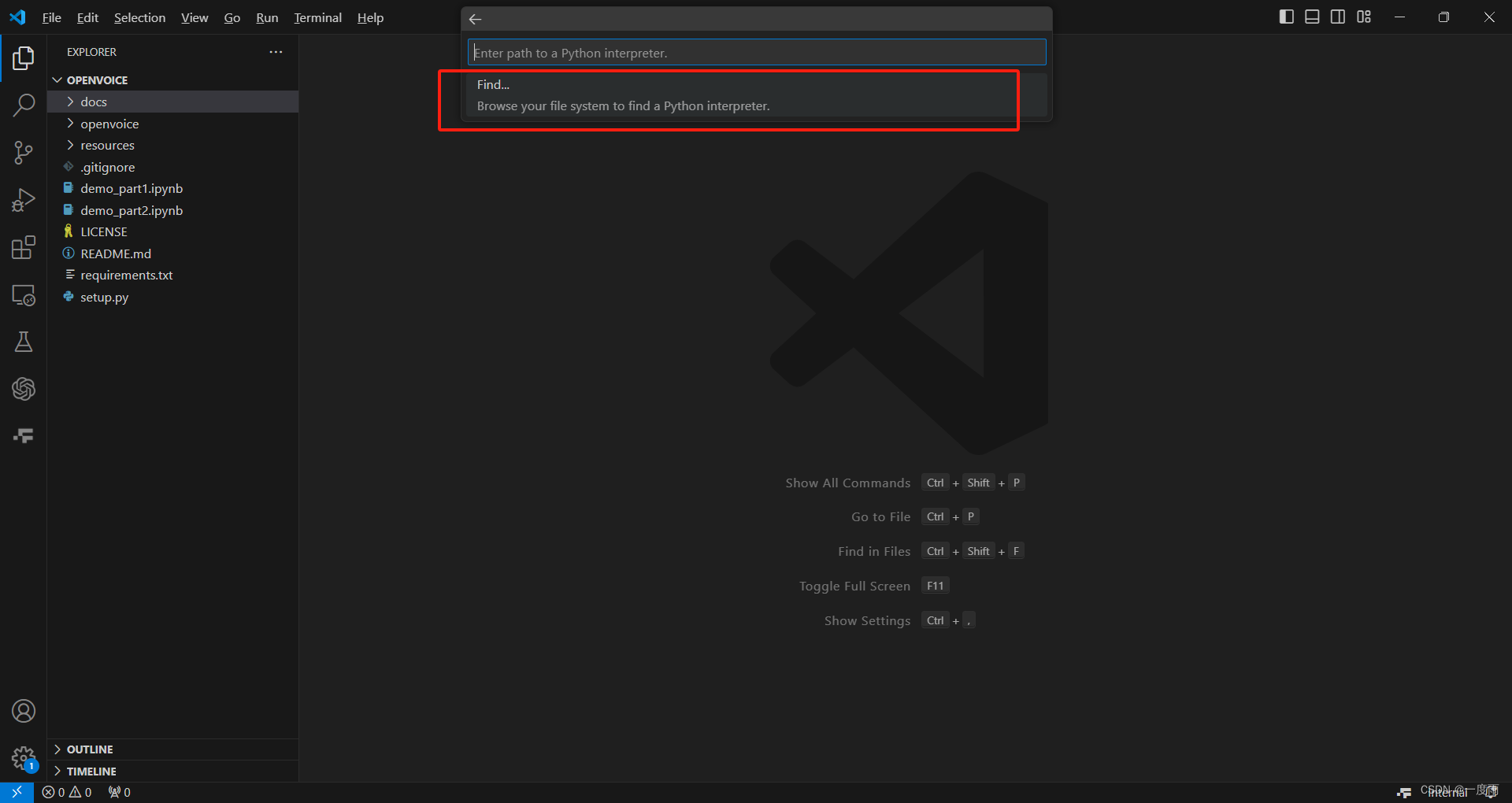
2)安装所需插件
A、没有意外
正确切换pip源之后,一般是不会出现意外的。
选好python编译器之后,勾选如图项,然后点击ok。过程需要些时间,耐心等待VSCode安装完成。
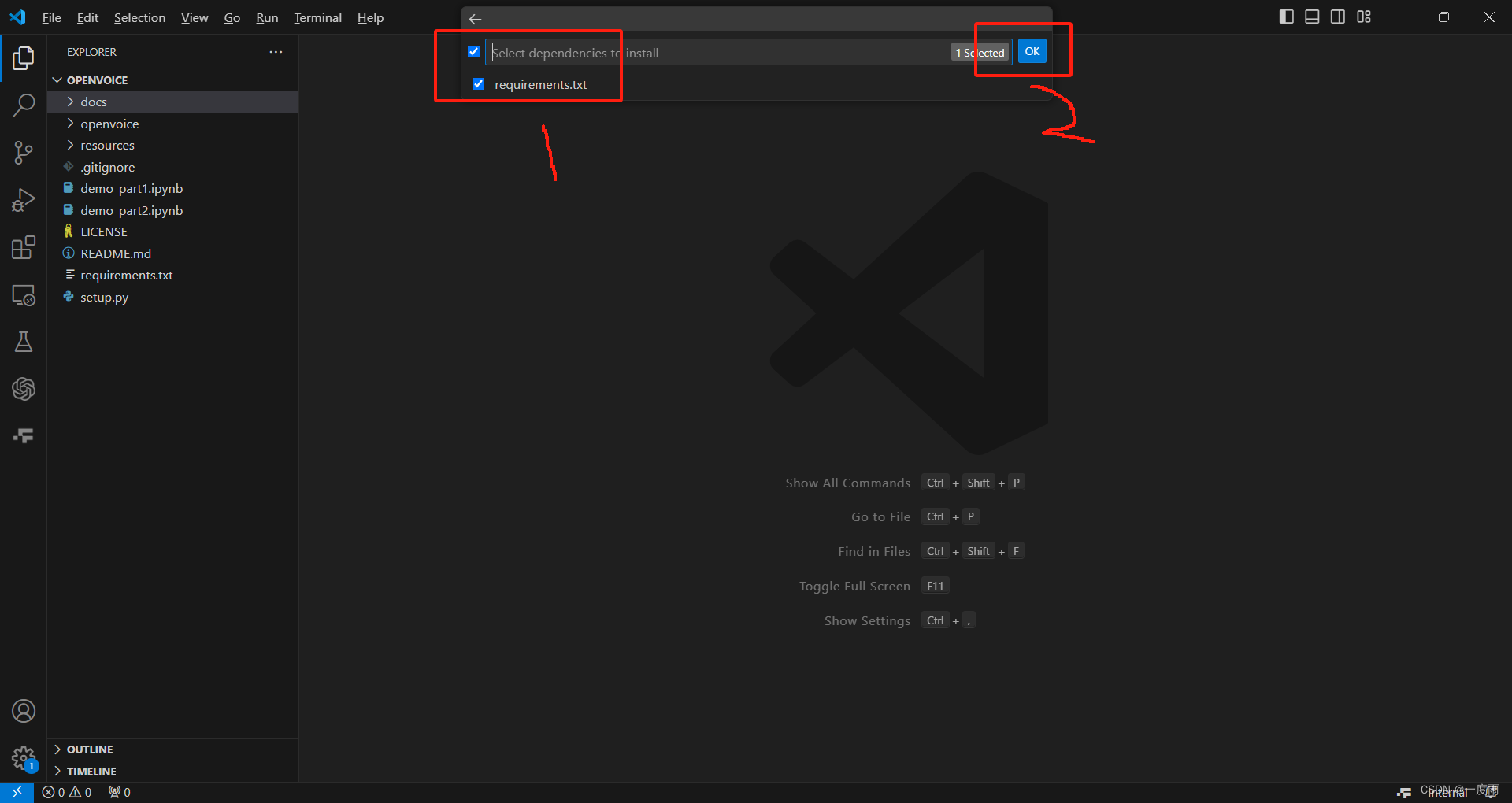
不要动,等待就好。

B、若有意外
如果你没有勾选上一步,那么就需要手动操作安装了。
此步骤在激活python虚拟环境的情况下,在控制台,输入代码
pip install -r requirements.txt
3)激活python虚拟环境
选择Terminal->New Terminal

下方输入代码,回车enter即可。
.\.venv\Scripts\activate
4)安装ipykernel
激活虚拟环境的情况下,控制台输入代码
pip install ipykernel
5) 安装ipywidgets
激活虚拟环境的情况下,控制台输入代码
pip install ipywidgets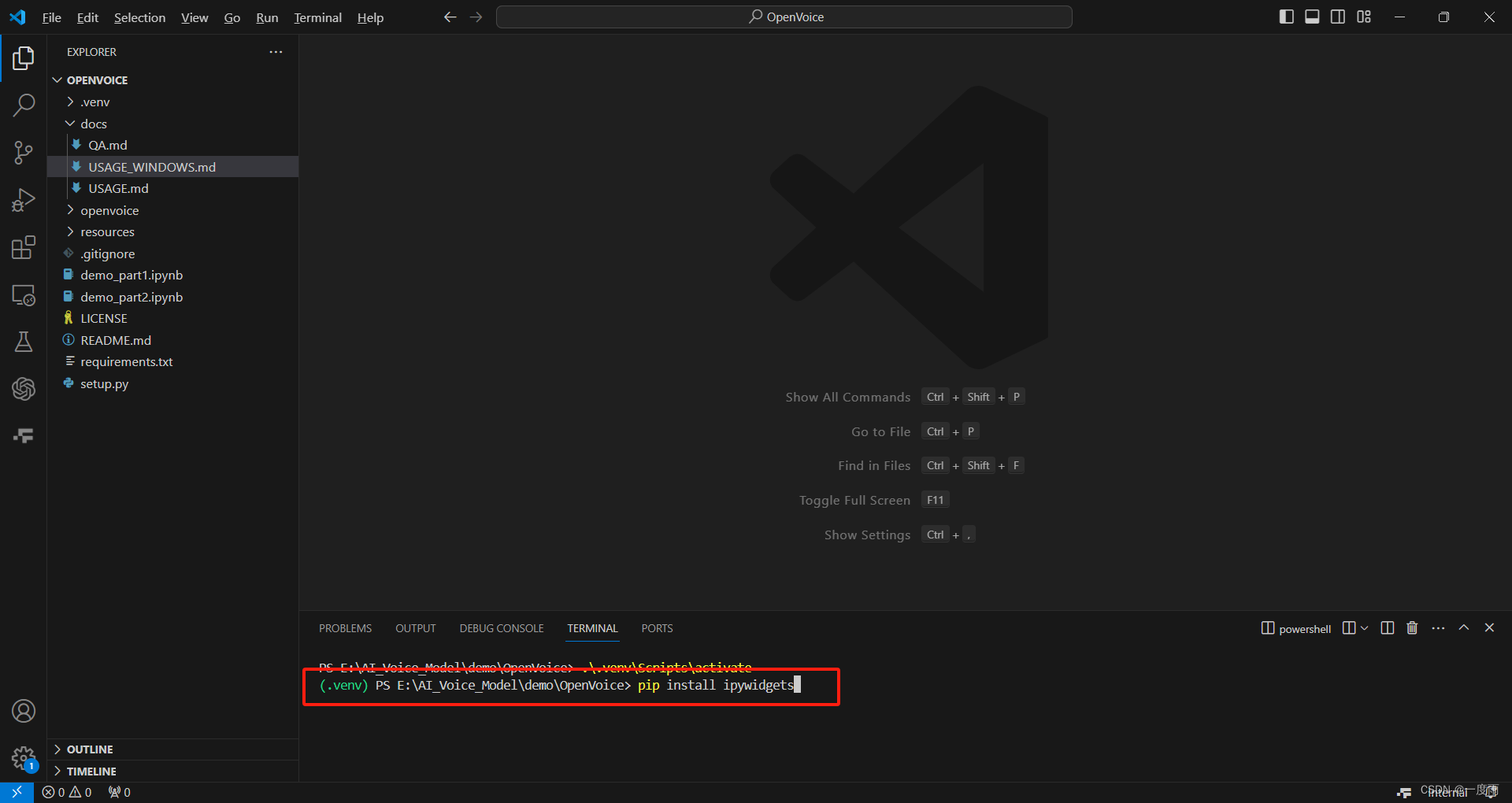
6)下载checkpoints
网址:
https://myshell-public-repo-hosting.s3.amazonaws.com/checkpoints_1226.zip
直接下载压缩包,解压之后放在项目根目录下。

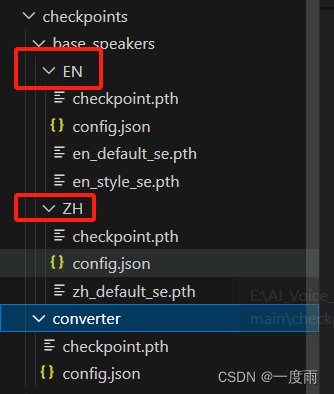
checkpoints包含中文ZH和英文EN两种语言的模型处理文件。
3、操作模型
A、操作demo_part1.ipynb
点击左侧文件demo_part1.ipynb,然后点击右侧红框部分选择虚拟环境。

选择Python Environments
 选择我们创建的虚拟环境.venv
选择我们创建的虚拟环境.venv 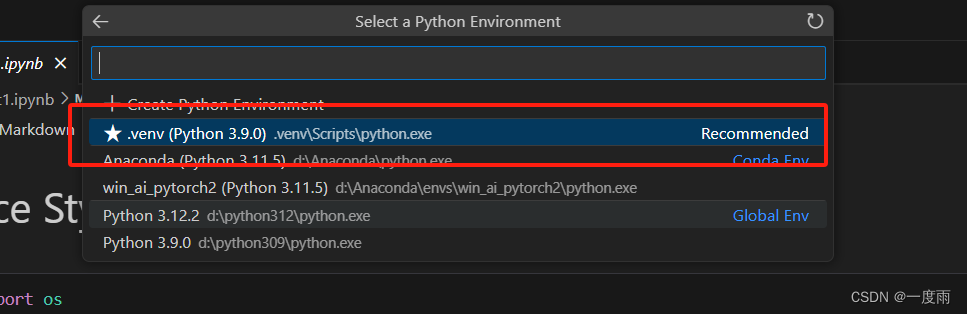
注意:每次关闭项目或者demo_part1.ipynb文件,要依次重新执行。每个都可多次点击,以消除警告信息。
1)第一步
点击下面的三角按钮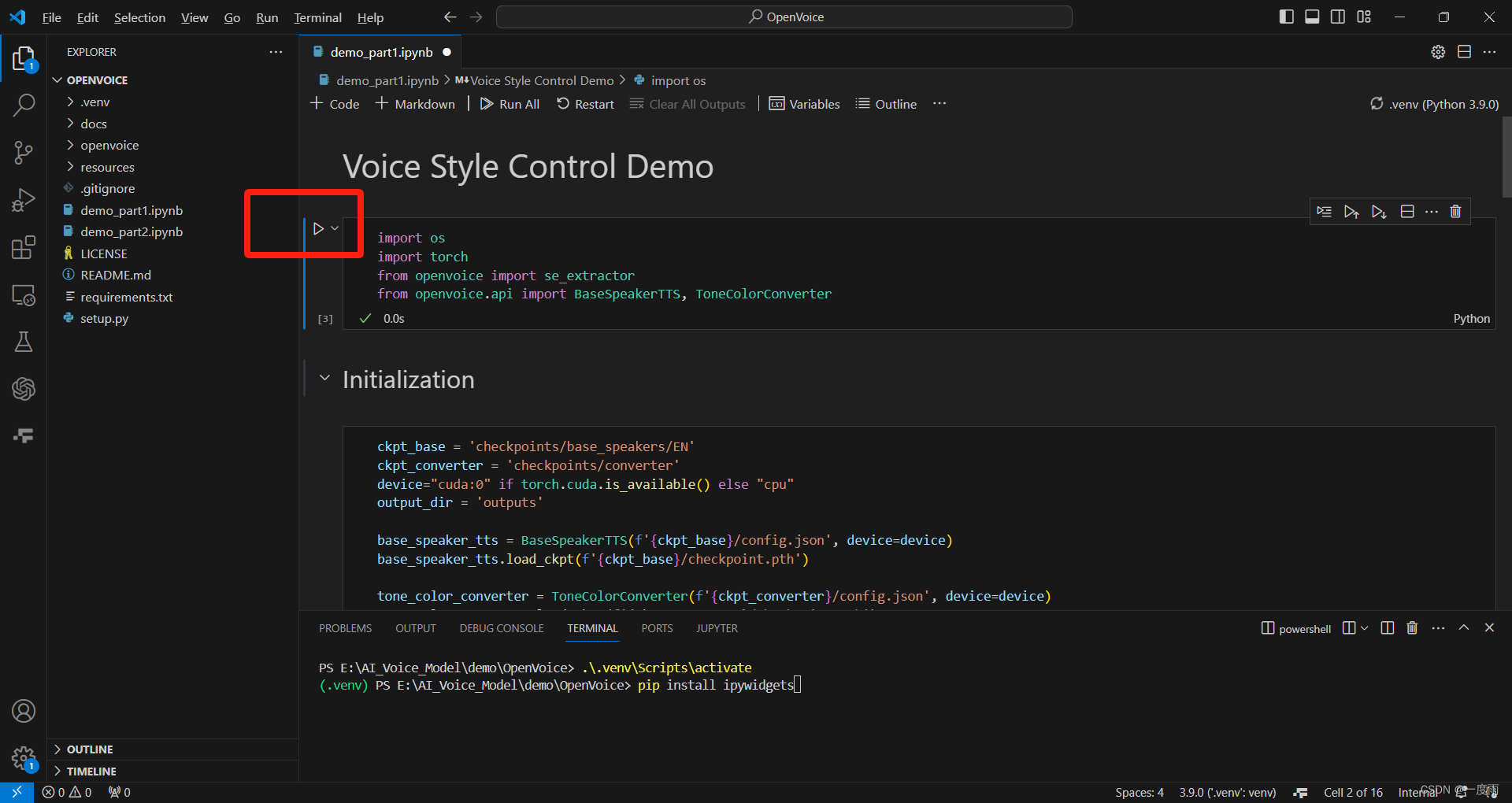
2)第二步
点击Initialization下的三角按钮。
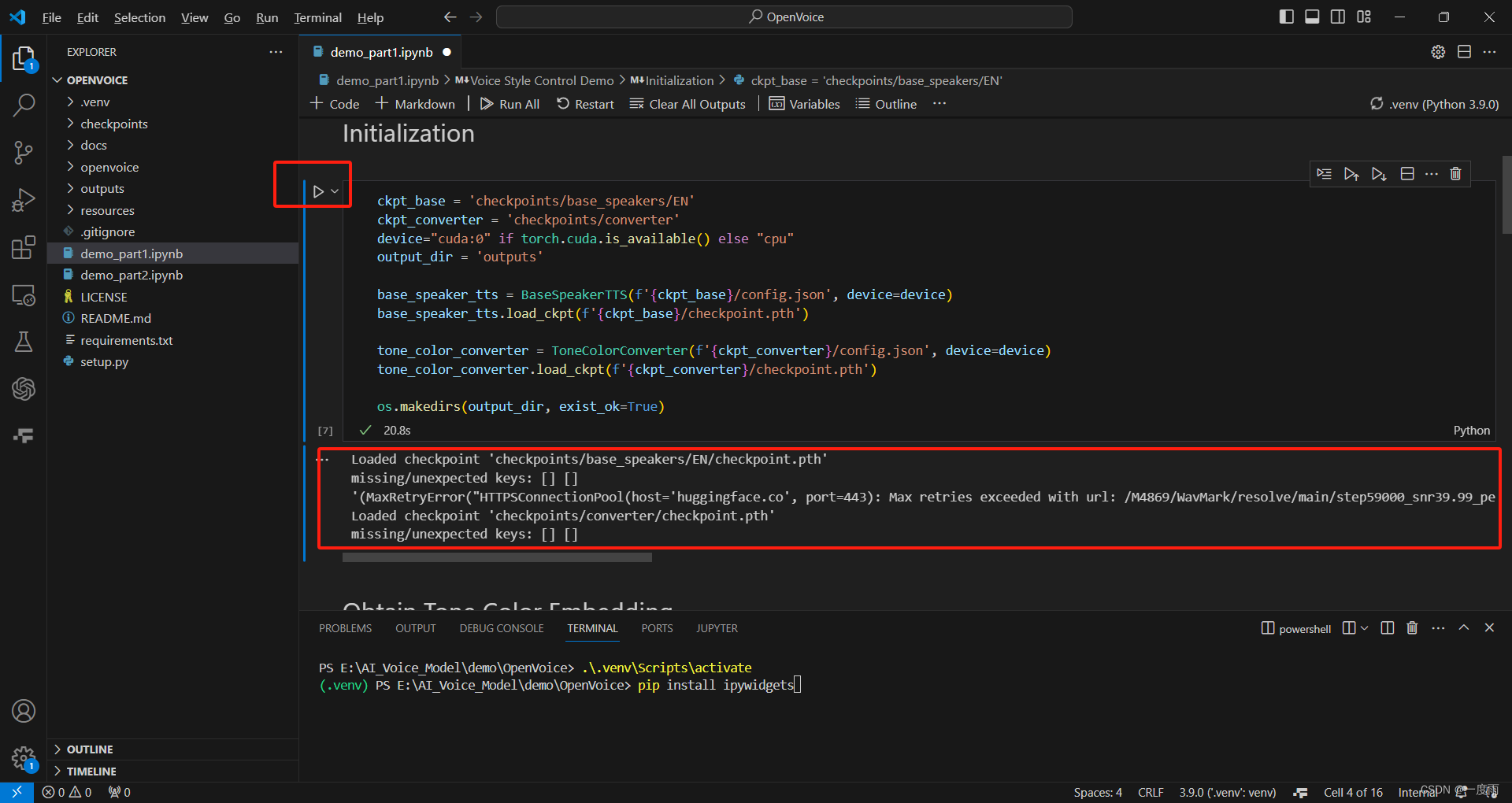
3)第三步
执行source_se,可省略。
4)第四步
执行reference_speaker,可多点击几次,便不会出现问题。

5)第五步
执行Inference,挑选一个执行即可。默认情况下,选择英文例子。
注意:运行英文代码最好加一句,避免出错中英文checkpoints不对应。
ckpt_base = 'checkpoints/base_speakers/EN'
第一个是默认英文例子。
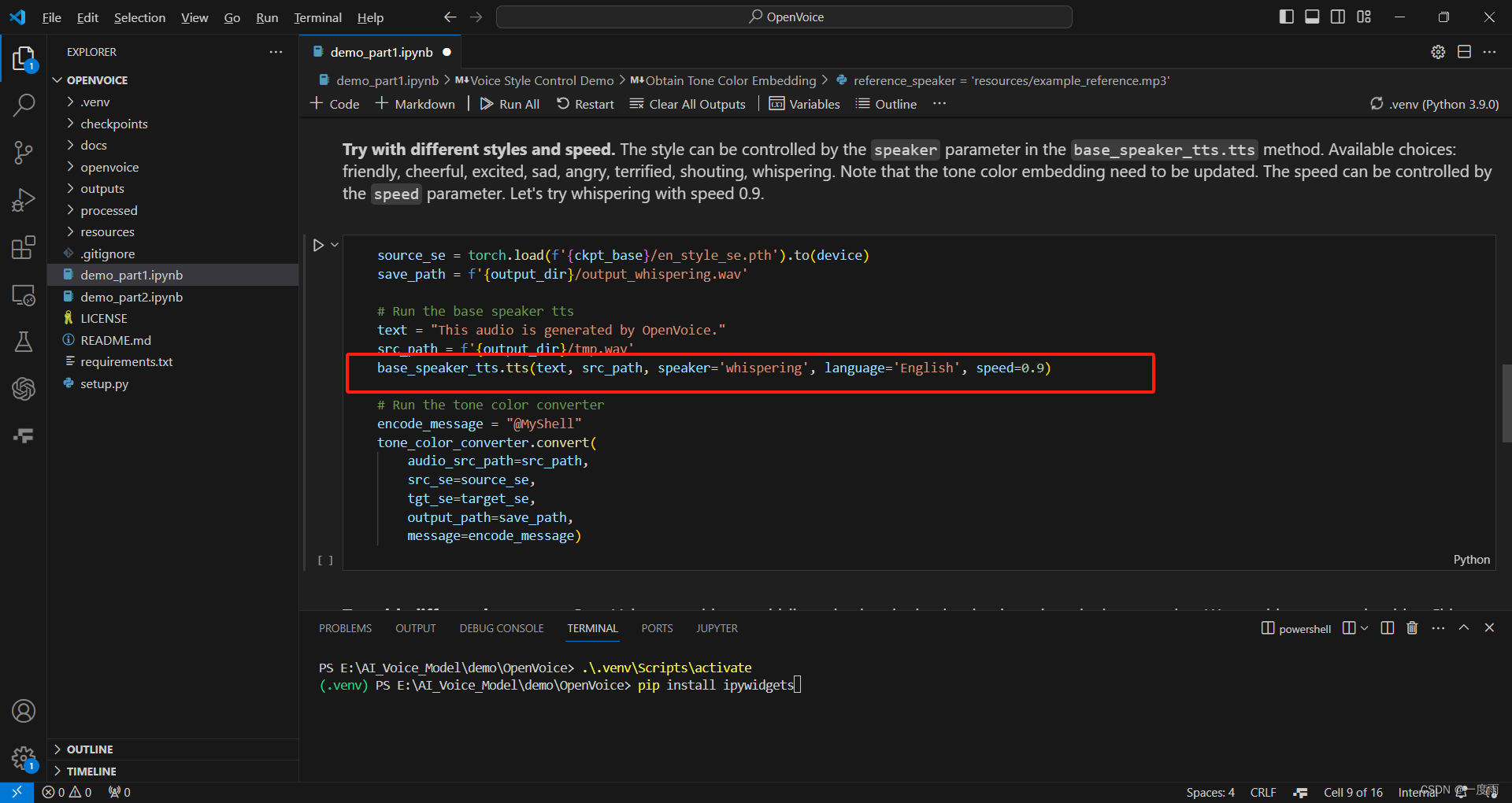
第二个也是英文,修改了语气与语速。
语气speaker="whispering",其余可选friendly, cheerful, excited, sad, angry, terrified, shouting
语速speed=0.9,可尝试自己。
语言language='English',为英文,切换中文为'Chinese’。
base_speaker_tts.tts(text, src_path, speaker='whispering', language='English', speed=0.9)
第三个是中文,只有默认语气。
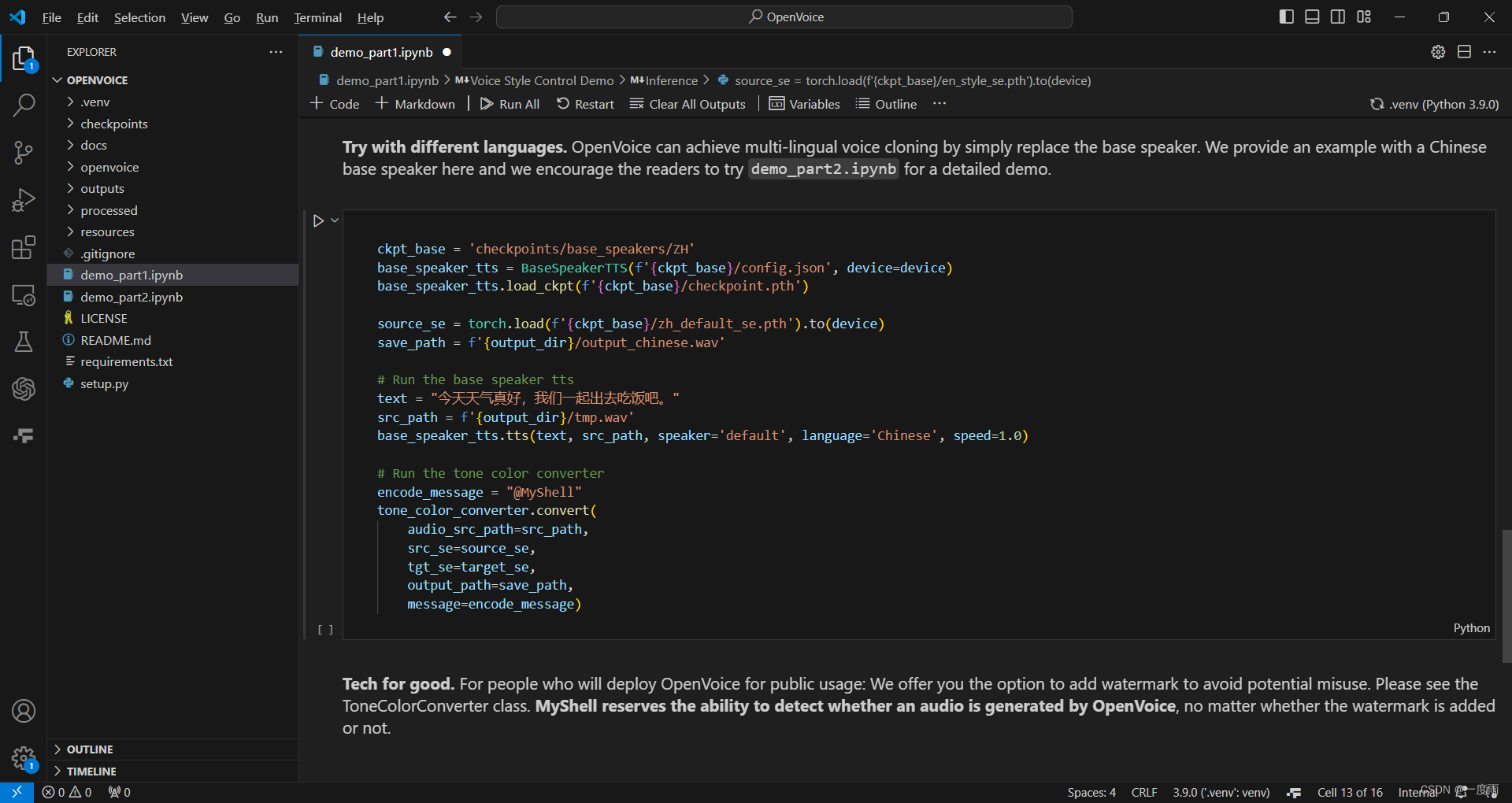
B、操作demo_part2.ipynb
这个要使用OPENAI_API_KEY,如果你有的话,那么,应该就不需要我来实操演示了,请根据demo_part2.ipynb说明操作即可。
4、简单讲解
要使用的训练语音为:
reference_speaker = 'resources/example_reference.mp3'
更改自己的语音,将自己的语音文件,如"ky_kk.mp3",放在项目路径resources文件夹下,注意,为mp3后缀文件。将example_reference更改为自己语音的名称即可。刚更改好,最好重启VSCode,以防报错找不到文件。更改完毕,然后执行这一步。


以中文为例 ,但是中文不能选择语气,只有默认的。
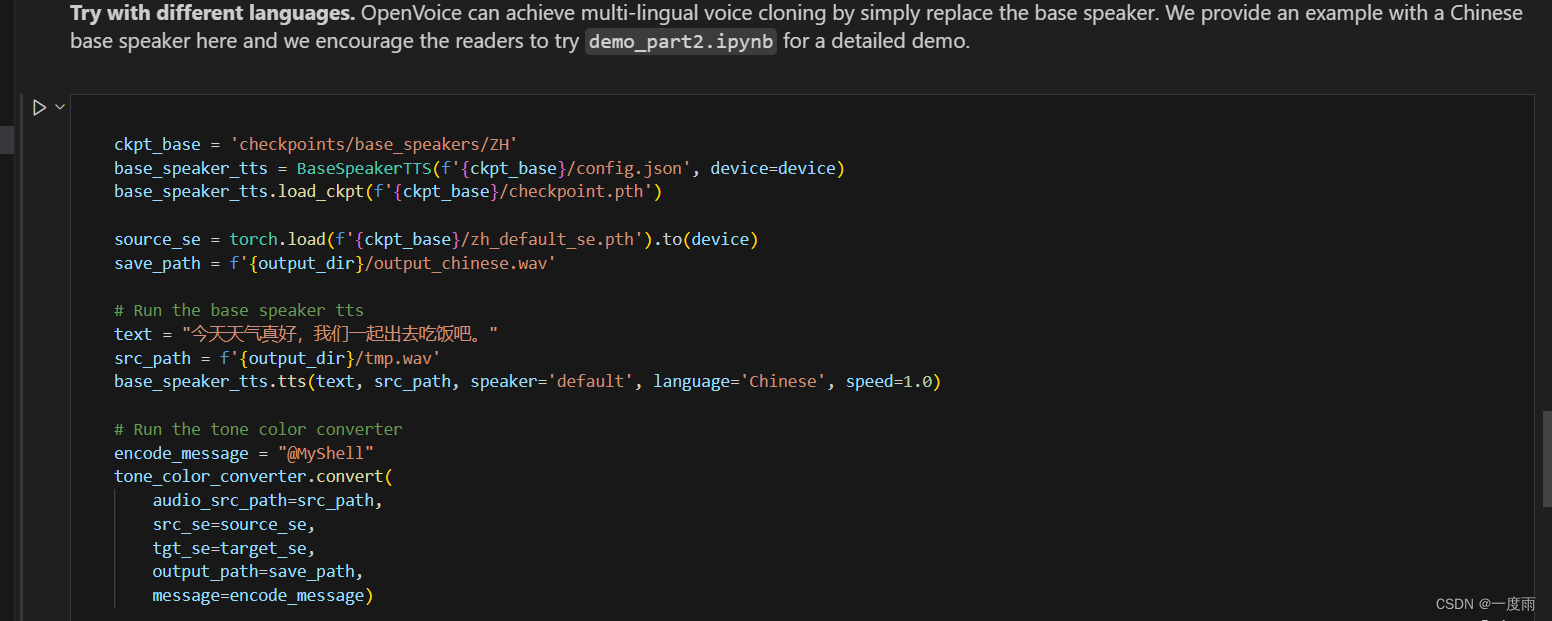
变量ckpt_base表示语音模仿对象语种模型处理的文件夹位置。中文ZH,英文则为EN。
ckpt_base = 'checkpoints/base_speakers/ZH'
变量source_se用于模仿语音语调的提取训练,区分中英文。中文为zh_default_se.pth,英文为en_default_se.pth。
source_se = torch.load(f'{ckpt_base}/zh_default_se.pth').to(device)
变量save_path表示输出的语音文件存档位置,output_chinese.wav为输出文件名,每次运行可更改,即可不断生成不同语音文件。
save_path = f'{output_dir}/output_chinese.wav'
变量text表示要输出的语音内容。
text = "今天天气真好,我们一起出去吃饭吧。"
变量src_path与变量save_path作用相同,使用语调为默认。默认音色输出为tmp.wav。
src_path = f'{output_dir}/tmp.wav'
因此,对于输出的语音文件,你有两个选择
output_chinese.wav和tmp.wav,随自己选择。
三、模型深度解析
敬请期待。

