
热门标签
热门文章
- 1IOS开发中获取对于scrollView拖动距离
- 2vmware安装android系统_vmware安装安卓平板系统
- 3初体验通义灵码-JS篇_webstorm 通义灵码
- 4python头歌-python第五章作业_头歌python作业答案第五章
- 5用 AI 给向量检索加 buff!Milvus 亮相数据库顶会 VLDB_milvus insight
- 6在前端用JSON.stringify()将数组转换为字符串后,后端再重新转为数组或集合(“[“1“,“2“,“3“]“转成 [1,2,3])_json.stringify转义后join(',') 为什么变成了数组
- 7redis修改默认存储数据目录_redis修改存储目录
- 8Emacs里面的Python mode(python.el)_emacs python.el:native completion setup loaded
- 9如何导出本地的Docker镜像?_docker导出镜像
- 10crossover软件干嘛的 mac电脑怎么使用crossover 打开window exe文件 crossover软件使用教程方法
当前位置: article > 正文
【学习笔记】生成式AI(ChatGPT原理,大型语言模型)
作者:你好赵伟 | 2024-04-30 09:20:16
赞
踩
【学习笔记】生成式AI(ChatGPT原理,大型语言模型)
ChatGPT原理剖析
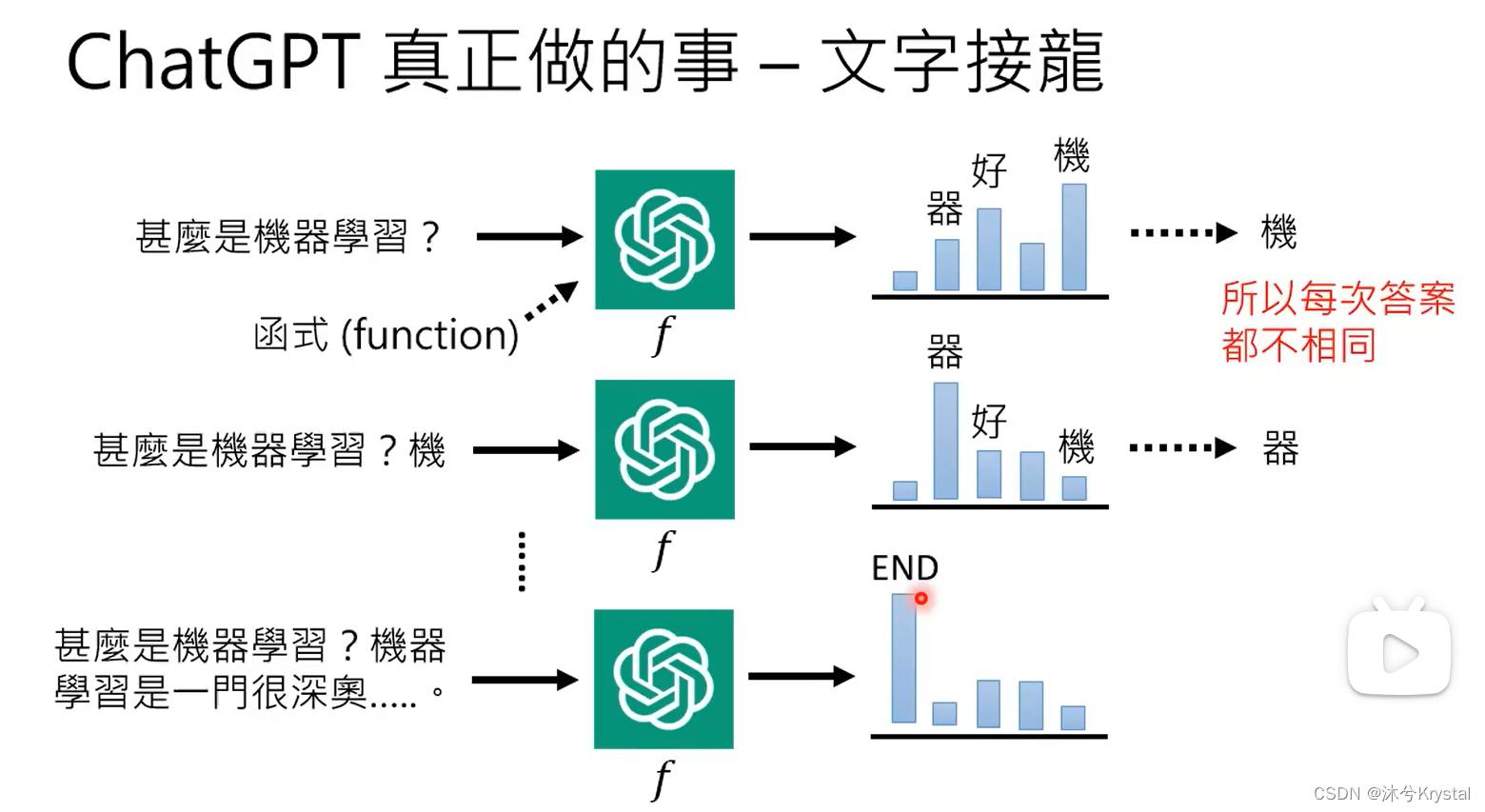
- 语言模型 == 文字接龙
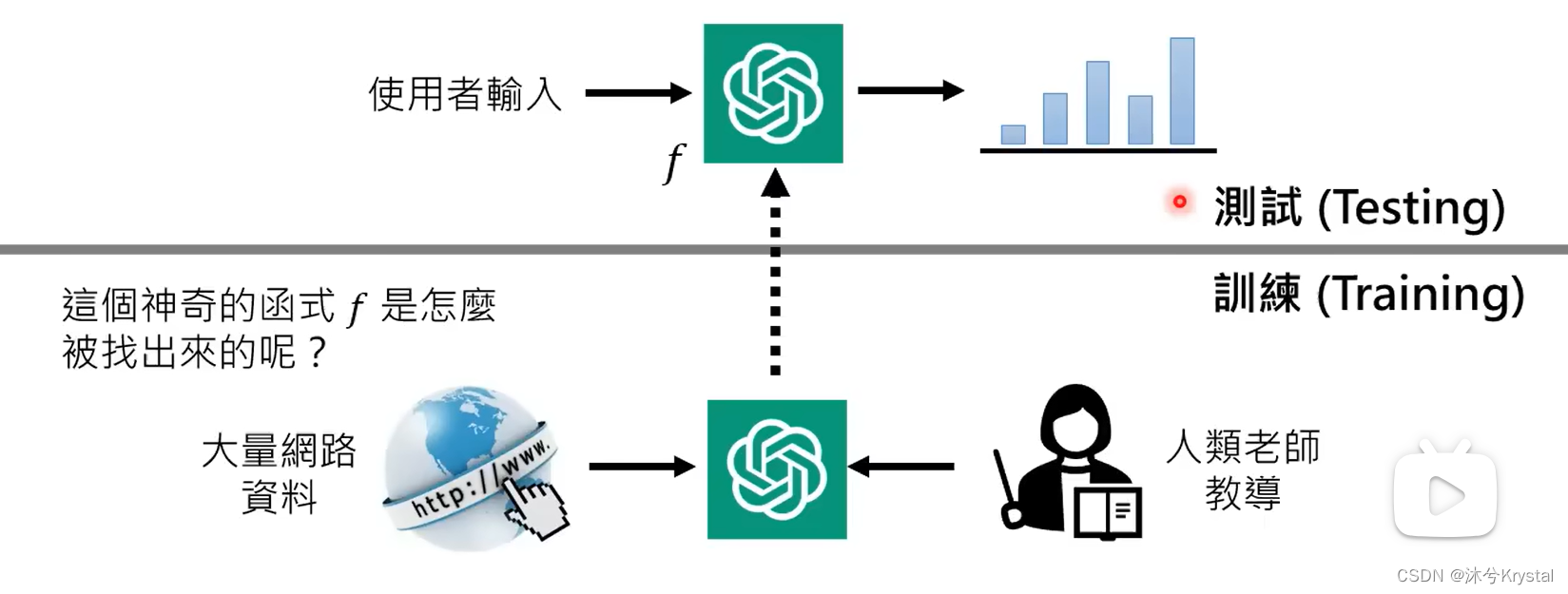
- ChatGPT在测试阶段是不联网的。
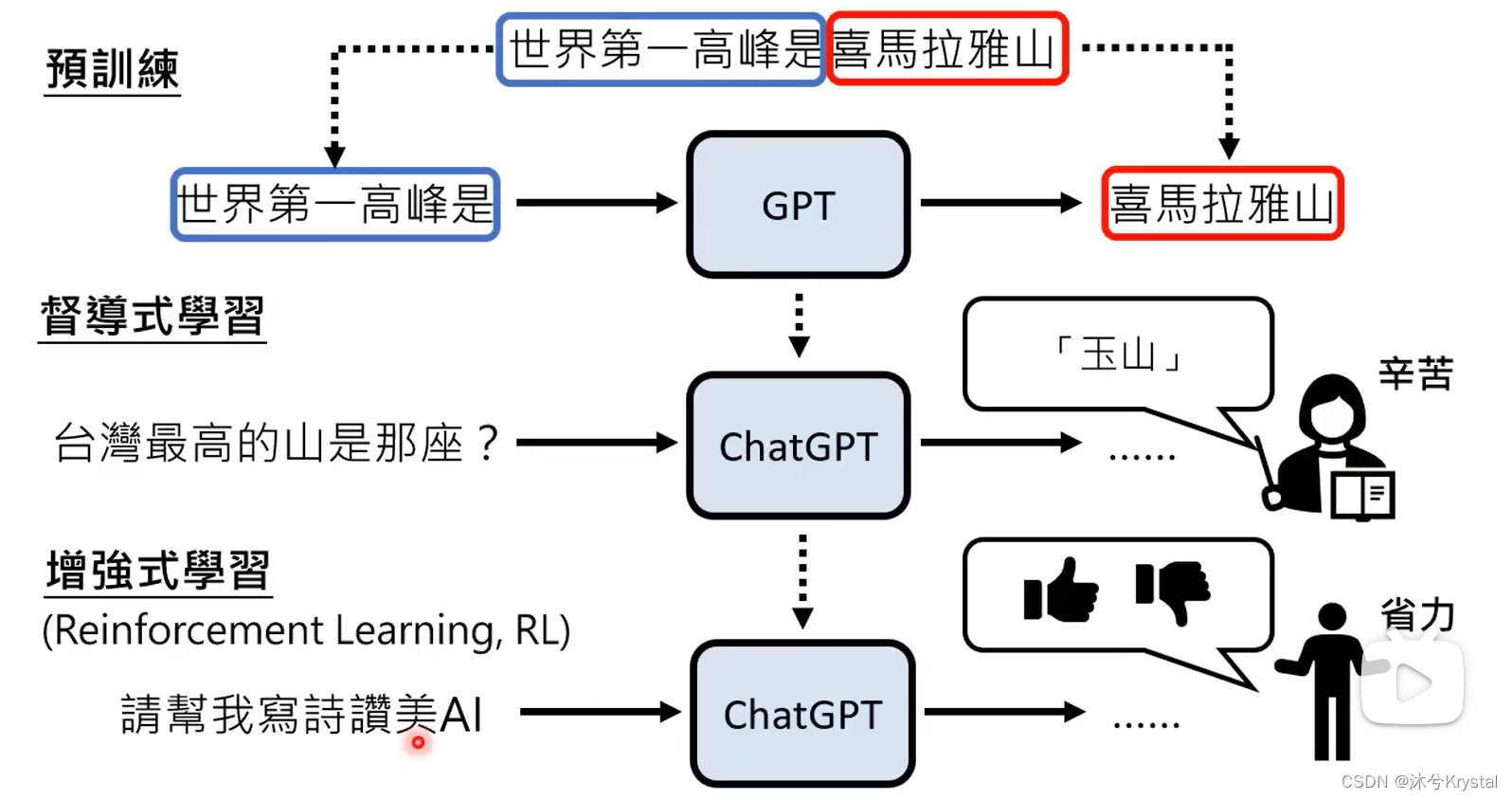
ChatGPT背后的关键技术:预训练(Pre-train)
- 又叫自监督式学习(Self-supervised Learning),得到的模型叫做基石模型(Foundation Model)。在自监督学习中,用一些方式“无痛”生成成对的学习资料。
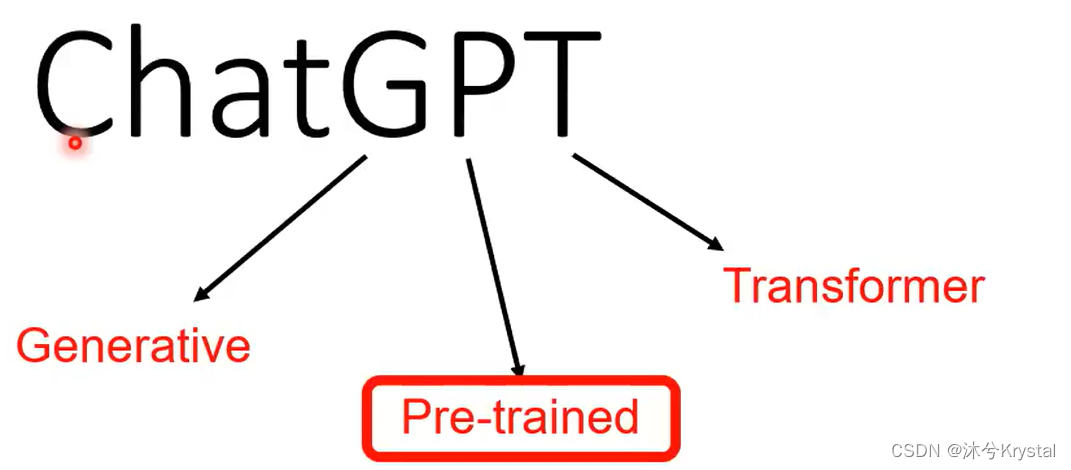
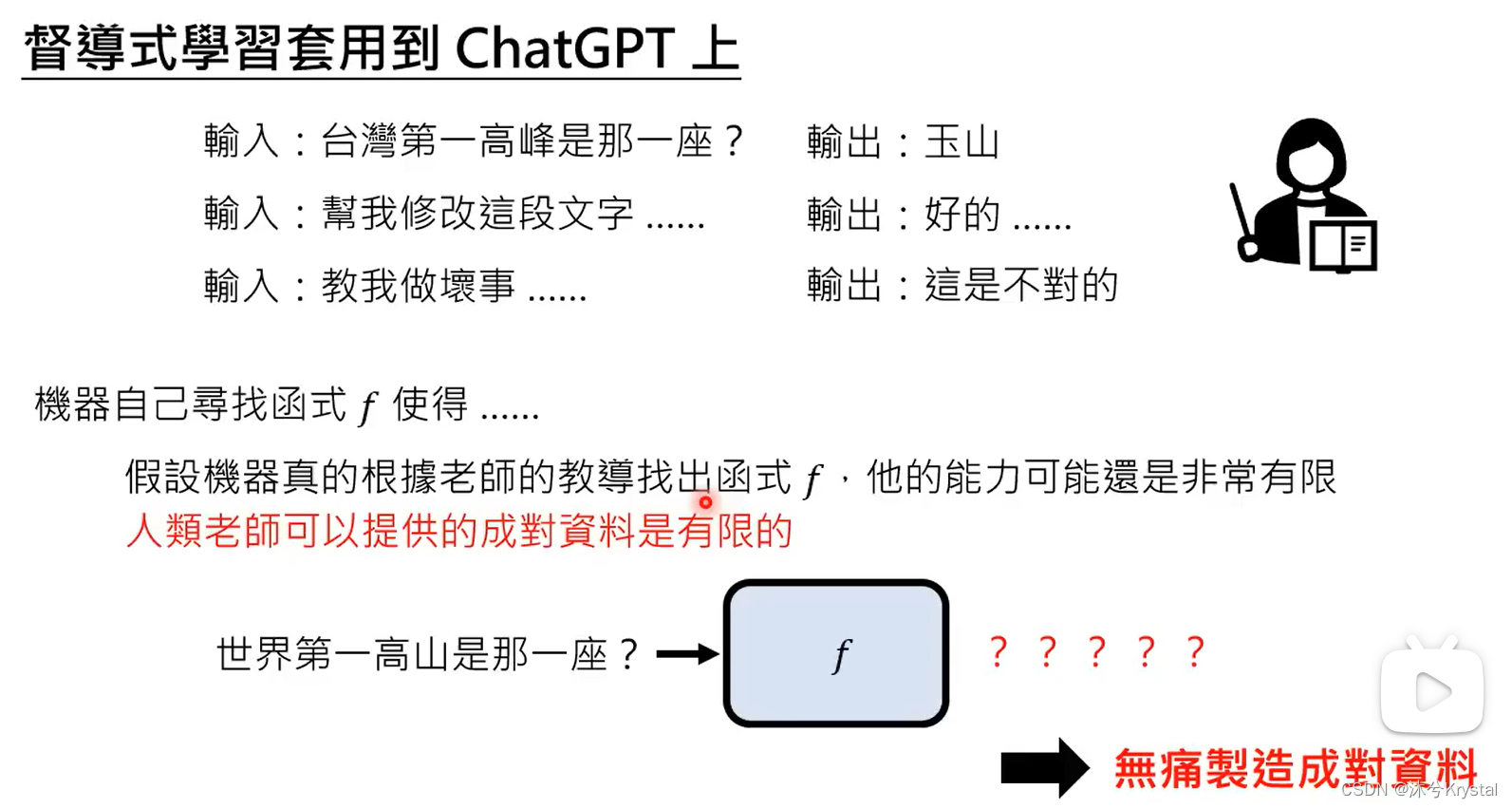
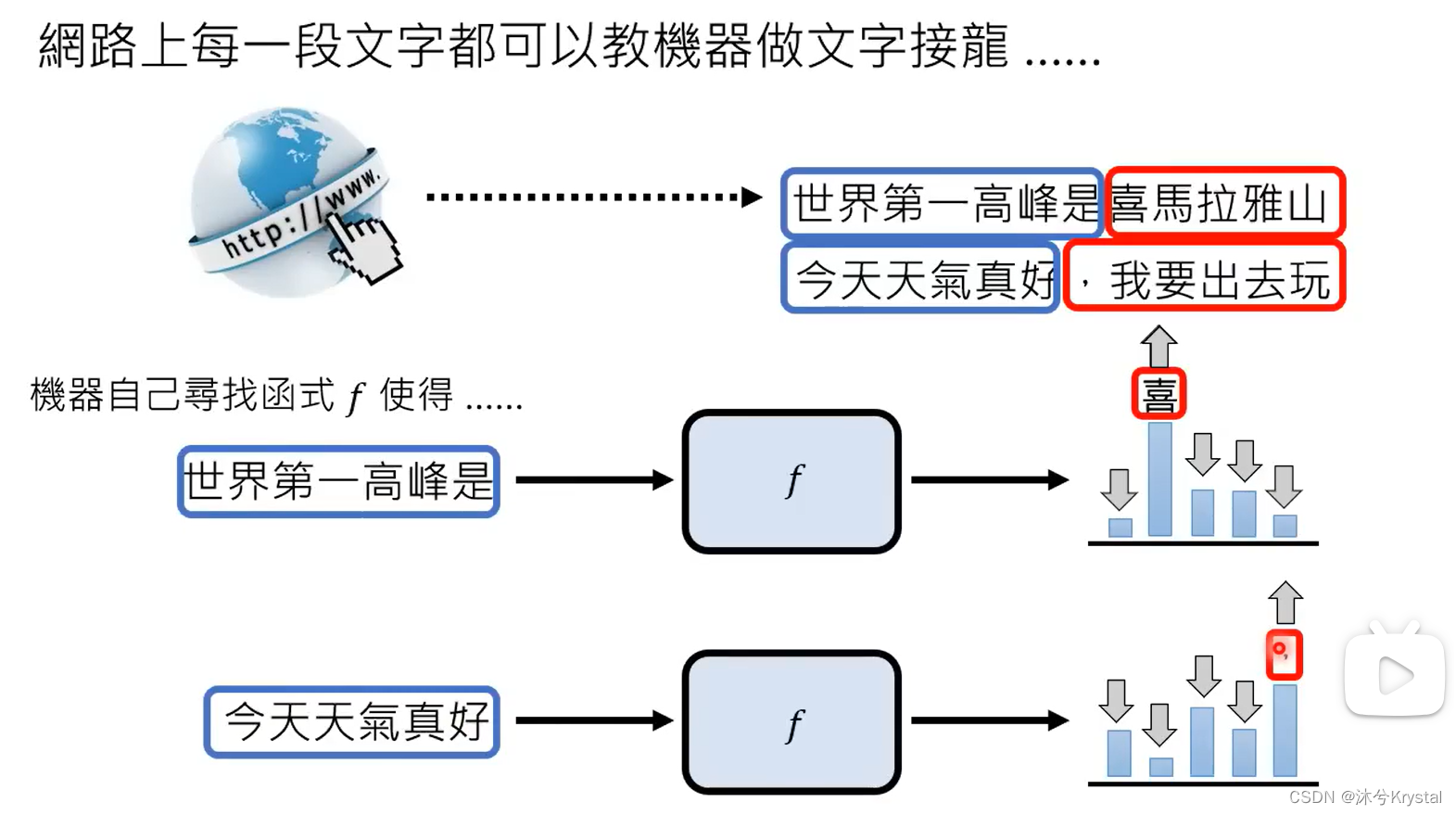
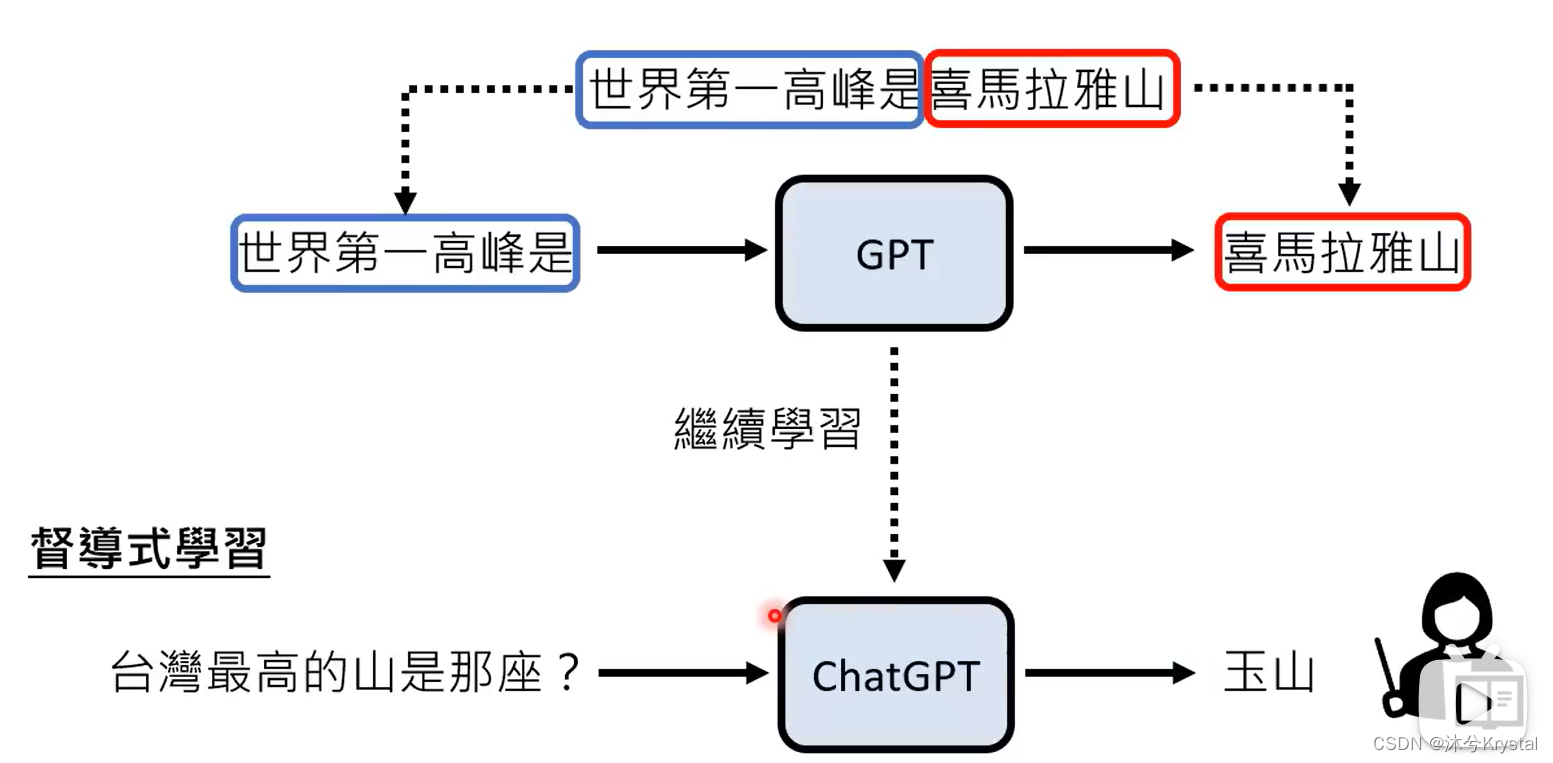
- GPT1 -> GPT2 -> GPT3 (参数量增加,通过大量网络资料学习,这一过程称为预训练),GPT -> ChatGPT (增加人类老师提供的资料学习),GPT到ChatGPT增加的继续学习的过程就叫做 微调 (finetune)。
预训练多有帮助呢?
- 在多种语言上做预训练后,只要教某一个语言的某一个任务,自动学会其他语言的同样任务。

- 当在104种语言上预训练,在英语数据上微调后在中文数据上测试的结果(78.8的F1值),和在中文数据上微调并在中文数据上测试的结果(78.1的F1值)相当。
ChatGPT带来的研究问题
- 1.如何精准提出需求
- 2.如何更正错误【Neural Editing】
- 3.侦测AI生成的物件
- 怎么用模型侦测一段文字是不是AI生成的
- 4.不小心泄露秘密?【Machine Unlearning】
对于大型语言模型的两种不同期待 Finetune vs. Prompt
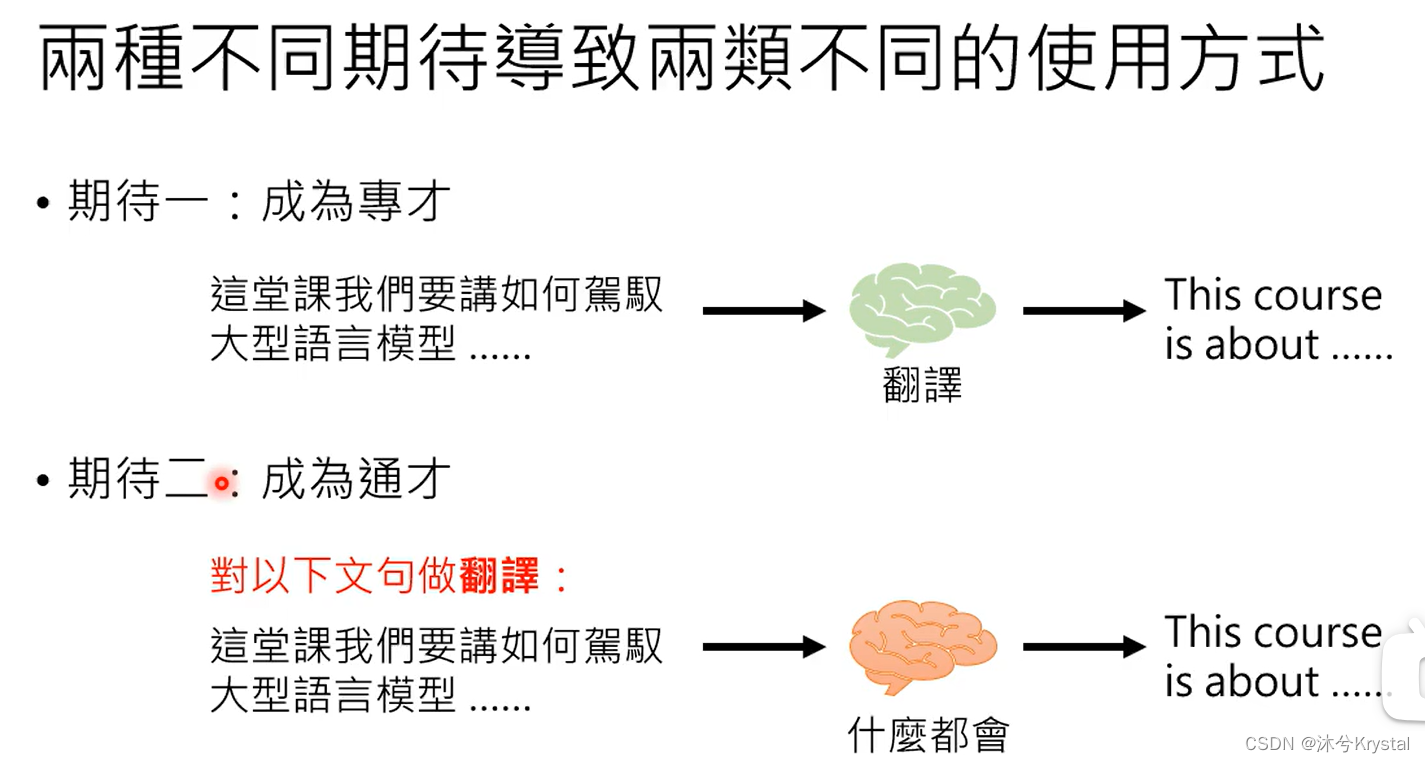
- 成为专才,对预训练模型做改造,加外挂和微调参数。
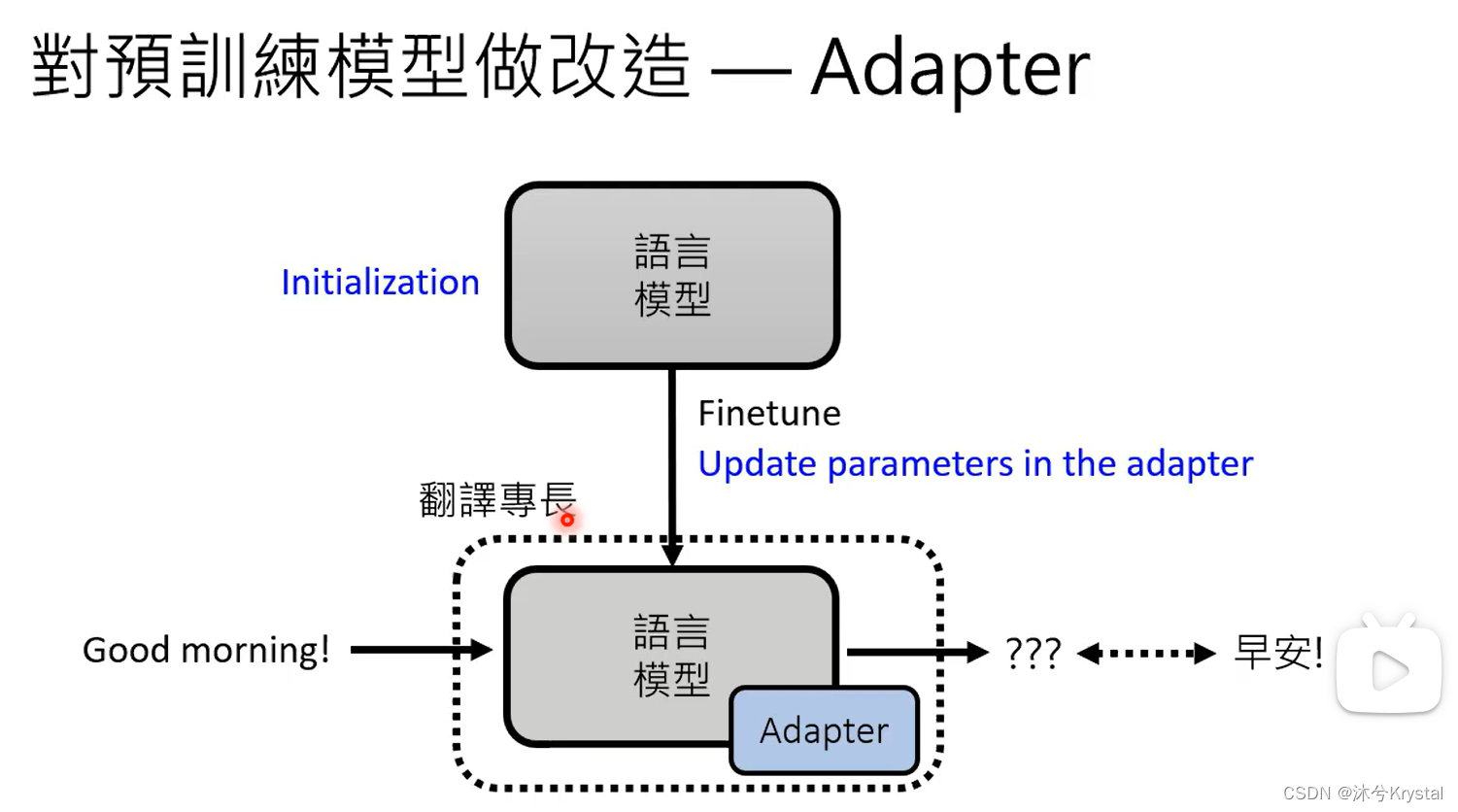
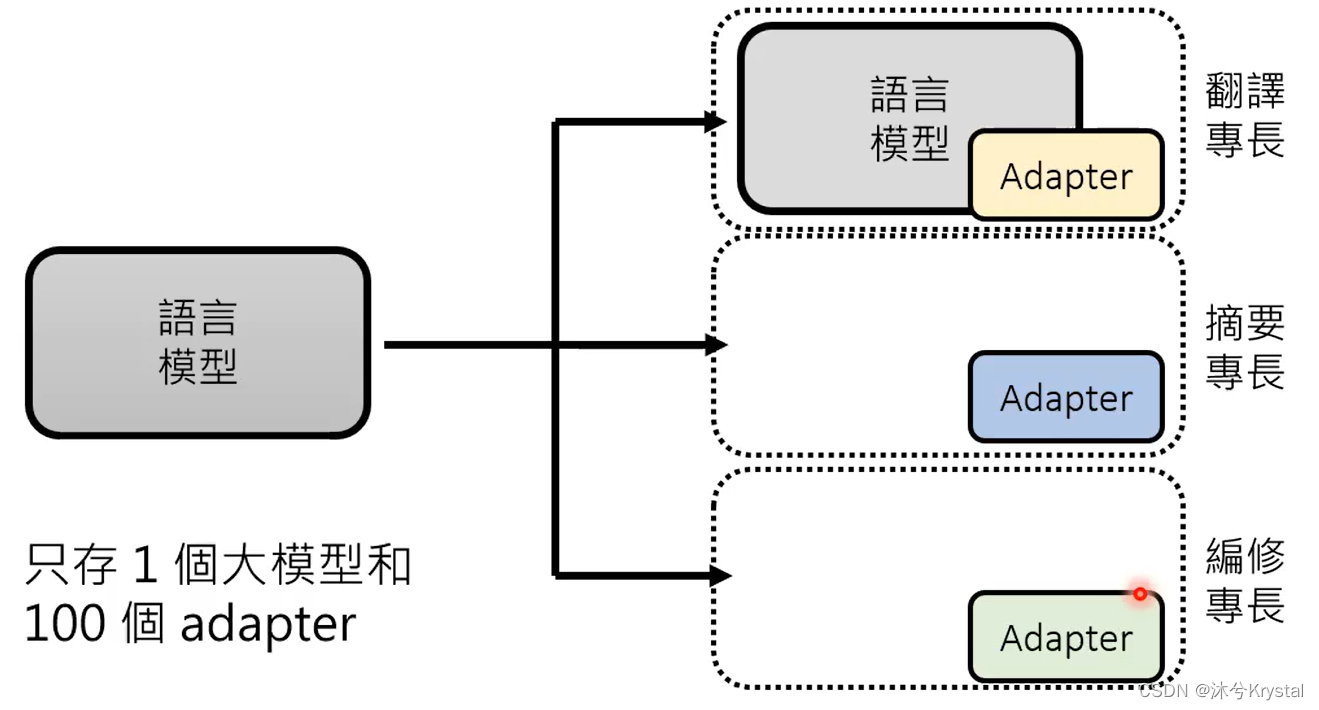
- 成为通才,机器要学会读题目描述或者题目范例
- 题目叙述–Instruction Learning
- 范例–In-context Learning
- In-context Learning
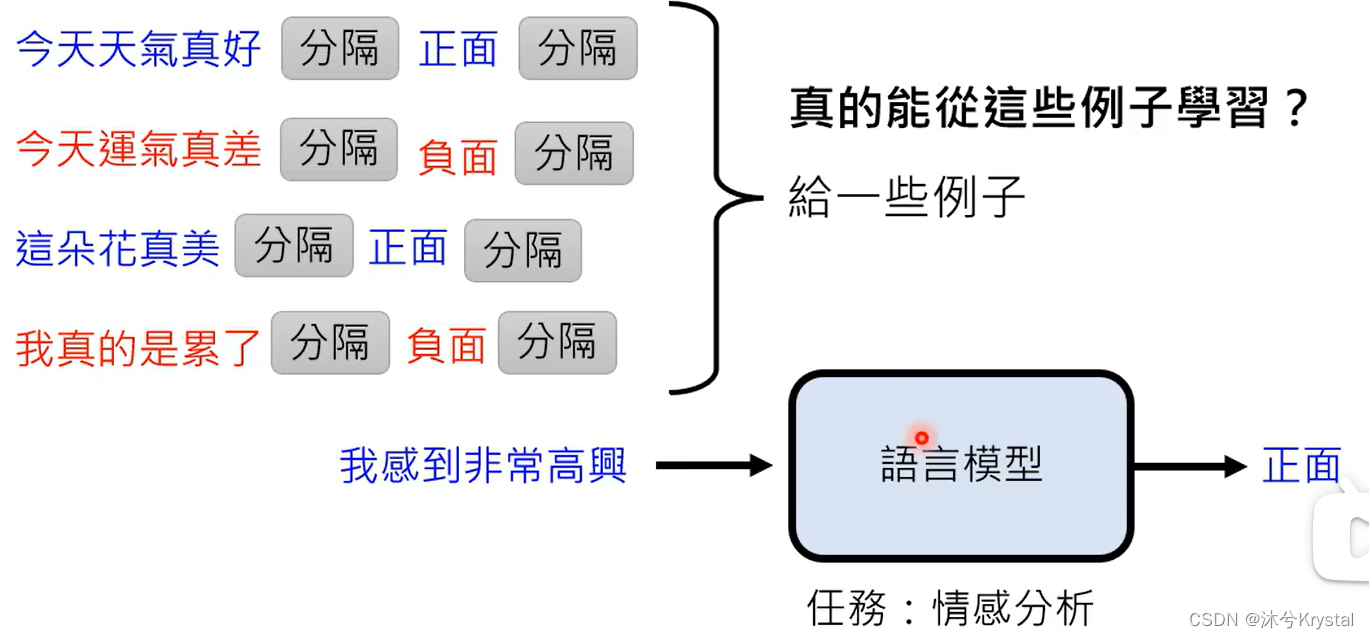
- 给机器的范例的domain是很重要的;范例的数量并不需要很多,并不是通过范例进行学习,范例的作用只是唤醒模型的记忆;也就是说,语言模型本来就会做情感分析,只是需要被指出需要做情感任务。
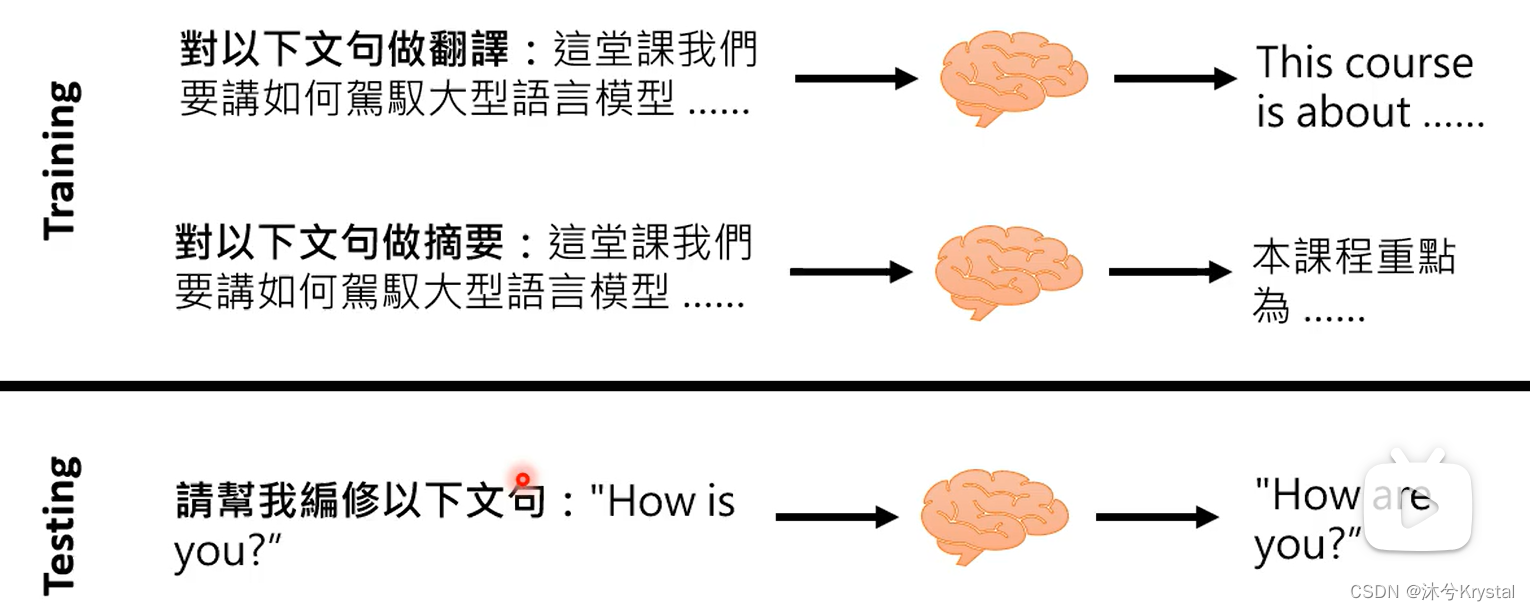
- Instruction-tuning
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/512630
推荐阅读

相关标签

