
- 1Redis Desktop Manager安装和使用_redisdesktopmanager
- 2【Redis系列】Redis安装与使用_redis怎么安装使用
- 3【转】深度学习在生物医学领域的应用 进展述评_深度学习在医疗与生物界的应用概述
- 4编译原理(一)——词法分析
- 5TCP三次握手与四次挥手_lished
- 6【快递100】快递时效接口获取快递预计到达时间_快递100博客
- 7Pytorch简单实现seq2seq+Attention机器人问答_pytorch seq2seq实现问答
- 8【git】idea撤销commit,回到本地更改LocalChange_idea git commit撤回到本地
- 9【开源免费】Vue+SpringBoot打造假日旅社管理系统,初学者入门实战项目
- 10深入探索C语言技术世界:全面学习路径与关键知识点
机器学习的两种典型任务
赞
踩
机器学习中的典型任务类型可以分为分类任务(Classification)和回归任务(Regression)
分类任务

回归任务
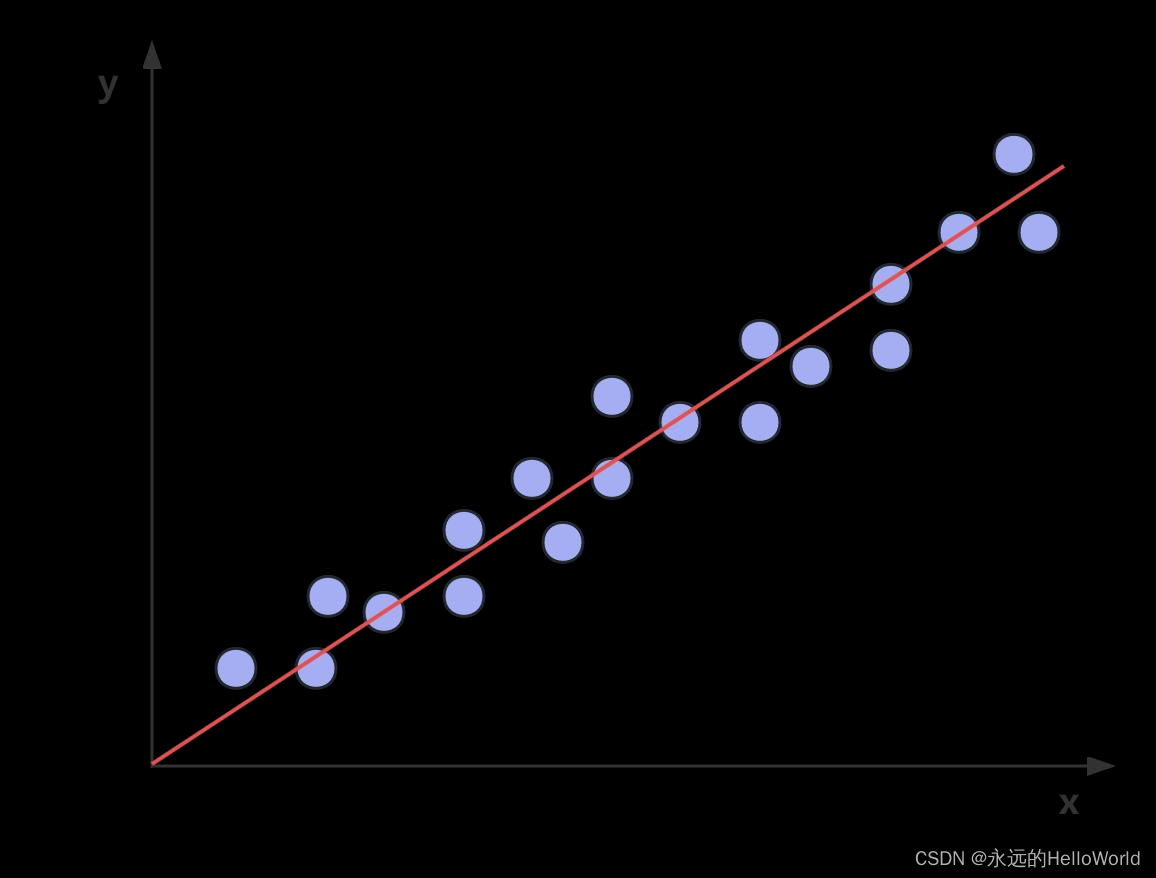
简单的理解,分类任务是对离散值进行预测,根据每个样本的值/特征预测该样本属于类 型A、类型B 还是类型C,例如情感分类、内容审核,相当于学习了一个分类边界(决策 边界),用分类边界把不同类别的数据区分开来。 回归任务是对连续值进行预测,根据每个样本的值/特征预测该样本的具体数值,例如房 价预测,股票预测等,相当于学习到了这一组数据背后的分布,能够根据数据的输入预 测该数据的取值。
有监督学习:监督学习利用大量的标注数据来训练模型,对模型的预测值和数据的真实 标签计算损失,然后将误差进行反向传播(计算梯度、更新参数),通过不断的学习, 最终可以获得识别新样本的能力。
每条数据都有正确答案,通过模型预测结果与正确答案的误差不断优化模型参数
无监督学习:无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间 的关系,比如聚类相关的任务。有监督和无监督最主要的区别在于模型在训练时是否需 要人工标注的标签信息。
只有数据没有答案,常见的是聚类算法,通过衡量样本之间的距离来划分类别
半监督学习:利用有标签数据和无标签数据来训练模型。一般假设无标签数据远多于有 标签数据。例如使用有标签数据训练模型,然后对无标签数据进行分类,再使用正确分 类的无标签数据训练模型;
利用大量的无标注数据和少量有标注数据进行模型训练
自监督学习:机器学习的标注数据源于数据本身,而不是由人工标注。目前主流大模型 的预训练过程都是采用自监督学习,将数据构建成完型填空形式,让模型预测对应内容, 实现自监督学习。
通过对数据进行处理,让数据的一部分成为标签,由此构成大规模数据进行模型训练
远程监督学习:主要用于关系抽取任务,采用bootstrap的思想通过已知三元组在文本 中寻找共现句,自动构成有标签数据,进行有监督学习。
基于现有的三元组收集训练数据,进行有监督学习
强化学习:强化学习是智能体根据已有的经验,采取系统或随机的方式,去尝试各种可 能答案的方式进行学习,并且智能体会通过环境反馈的奖赏来决定下一步的行为,并为 了获得更好的奖赏来进一步强化学习。
以获取更高的环境奖励为目标优化模型

