
- 1【python】调整图像大小_自定义调整、等高宽调整
- 2Python中函数的详解_def func( ): print('hello') 问:type(func),type(func
- 3队列的顺序存储结构_队列的顺序存储结构源代码
- 4linux-----------串口设置缓冲器的大小_xmit_fifo_size
- 5让模型畅所欲言不再Say No丨专访Dolphin开源模型作者Eric Hartford
- 6散列表(哈希表)
- 7Flink Task、Sub-Task、task slot和parallelism_flink subtask
- 8Spark MLlib快速入门(1)逻辑回归、Kmeans、决策树、Pipeline、交叉验证_sparkmlib入门
- 9OpenCV如何模板匹配(59)
- 10大语言模型与知识图谱的融合在心理学领域的应用_语言模型与知识图谱在心理学领域的应用
实体抽取全解析:技术与实战
赞
踩
深入探讨实体抽取技术的各个方面,从基于规则的方法到先进的基于神经网络的深度学习方法,提供了一系列详细的技术介绍和实战案例。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
一、前言
实体抽取(Named Entity Recognition, NER)技术,在自然语言处理(NLP)领域中占据着不可或缺的地位。它的主要任务是从文本中识别出具有特定意义的实体,例如人名、地点、组织机构名等,这对于理解和分析大量未结构化的文本数据至关重要。深入理解实体抽取技术不仅仅是掌握其基本原理和应用方法,更是要深挖其技术细节、挑战以及面对这些挑战时的创新解决方案。
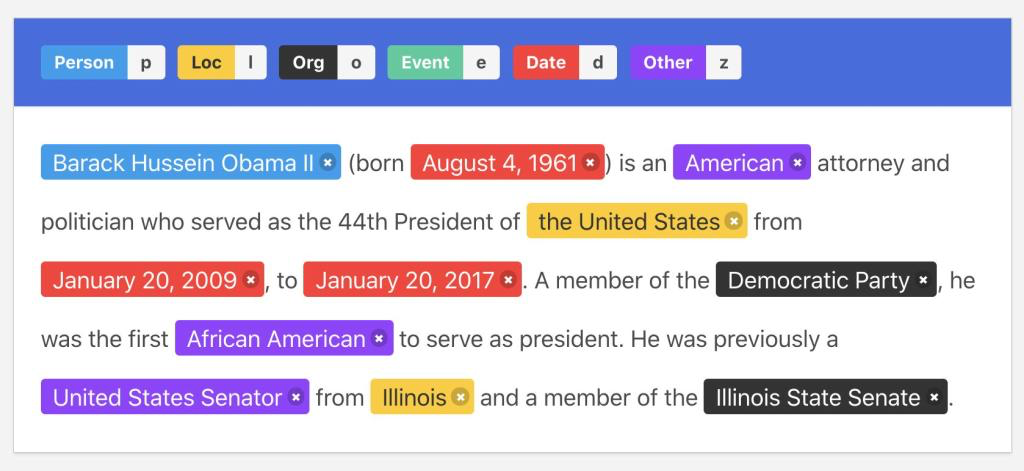
二、实体抽取技术概览
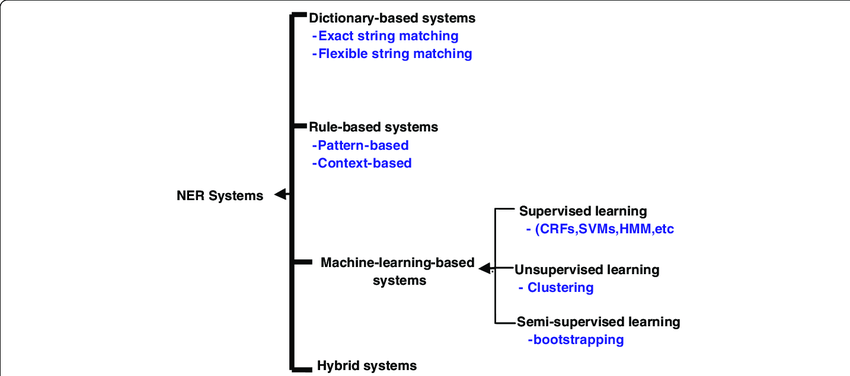
实体抽取,作为自然语言处理(NLP)的一个基础任务,旨在从文本中识别出具有特定意义的信息片段,并将其归类为预定义的类别,如人名、地点、组织名等。这一过程通常涉及两个主要步骤:实体识别和实体分类。实体识别是指定位文本中的实体边界,实体分类则是将识别出的实体分配到相应的类别中。实体抽取的技术方法大致可以分为三类:基于规则的方法、基于统计的方法和基于深度学习的方法。
基于规则的实体抽取
基于规则的实体抽取方法主要依赖于手工编写的规则来识别文本中的实体。这些规则可能包括词性标注、语法模式、关键词列表等。虽然这种方法在特定领域内可以达到较高的准确率,但其扩展性和适应性较差,需要大量的人工投入来维护和更新规则。
基于统计的实体抽取
基于统计的方法通过从标注好的训练数据中学习实体的特征来识别文本中的实体。这类方法包括隐马尔可夫模型(HMM)、最大熵模型、支持向量机(SVM)和条件随机场(CRF)等。这些方法能够自动从数据中学习规律,减少了对人工规则的依赖。其中,条件随机场(CRF)由于其在序列标注问题中表现出的高效性,成为了实体抽取中广泛使用的技术之一。
基于深度学习的实体抽取
近年来,深度学习的发展为实体抽取带来了新的突破。卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)和Transformer等深度神经网络被广泛应用于实体抽取任务。这些模型能够捕捉文本中的深层语义关系和复杂的上下文信息,显著提高了实体抽取的性能。特别是预训练模型,如BERT和GPT,通过在大规模文本语料库上进行预训练,可以有效地捕捉丰富的语言特征,进一步提升了实体抽取的准确率和效率。
基于深度学习的方法不仅提高了实体抽取的性能,也大幅度提升了模型处理复杂文本的能力,使得实体抽取技术能够更好地应用于多种语言和领域。然而,这些方法通常需要大量的标注数据来训练模型,并且模型的解释性相对较差。
三、实体抽取的发展历程
实体抽取技术的发展历程是对自然语言处理领域技术进步的一个缩影。从早期的规则和词典驱动方法到现代的基于深度学习的自动学习方法,实体抽取技术的进步不仅展现了NLP技术的演化,也反映了计算能力、数据可用性和算法理论的进步。为了给专业的研究员提供一个全面的技术发展综述,我们将从早期技术开始,逐步探索至最新的研究成果和技术趋势。
早期的实体抽取方法
基于规则和词典的方法
早期的实体抽取系统大多依赖于手工编写的规则和词典。这些方法通过定义特定的语言规则和词汇列表来识别和分类文本中的实体。尽管这些方法在特定领域和有限的数据集上表现良好,但它们缺乏通用性,对于规模扩展和领域适应性面临巨大挑战。
基于特征的机器学习方法
随着机器学习技术的发展,基于特征的方法开始被应用于实体抽取任务中。这一阶段的方法通常需要手工设计特征,如词性标注、前后文信息、语法依存关系等,然后利用这些特征训练分类模型(如支持向量机SVM、决策树等)来识别文本中的实体。这类方法相比于纯规则和词典的方法有了显著的改进,但仍然依赖于耗时的特征工程和大量的领域知识。
深度学习时代的实体抽取
从传统模型到神经网络
随着深度学习技术的兴起,实体抽取任务的研究重点开始转向使用神经网络模型。与传统方法相比,深度学习方法能够自动从数据中学习复杂的特征表示,减少了对手工特征工程的依赖。初期的神经网络模型,如卷积神经网络(CNN)和循环神经网络(RNN),已经在实体抽取任务上显示出了较好的性能。
序列标注模型的兴起
特别是长短期记忆网络(LSTM)和条件随机场(CRF)的结合,为实体抽取任务带来了显著的性能提升。这种结合利用了LSTM的强大序列建模能力和CRF在序列标注任务中的高效性能,成为了一段时间内实体抽取任务的标准做法。
预训练语言模型的革命
近年来,预训练语言模型(如BERT、GPT等)的出现,进一步推动了实体抽取技术的发展。这些模型通过在大规模语料库上预训练,学习到了丰富的语言特征和知识,然后通过微调(Fine-tuning)的方式适应下游的NLP任务,包括实体抽取。预训练模型的应用,不仅在实体抽取任务上取得了前所未有的准确率,也大大降低了模型训练的难度和复杂度。
四、基于规则的方法
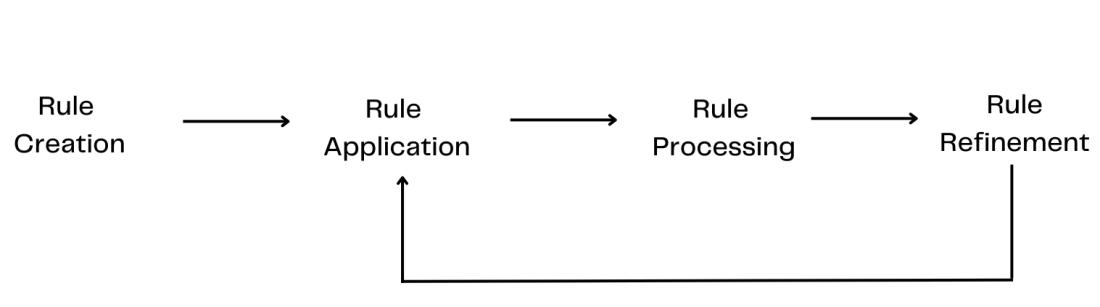
基于规则的方法是实体抽取技术中最早期的一种,它依靠预定义的语言规则和词典来识别文本中的特定实体。尽管随着机器学习和深度学习技术的发展,基于规则的方法可能看起来较为原始和局限,但在特定场景和应用中,这种方法因其透明度高、易于理解和实施等特点,仍然具有一定的应用价值。本节将详细介绍基于规则的实体抽取方法的工作原理、优缺点,并提供实战案例以供参考。
基于规则的方法工作原理
规则定义
基于规则的实体抽取方法主要依赖于手工编写的规则。这些规则可以是正则表达式、词性标记模式、词汇匹配列表或它们的组合。例如,通过正则表达式匹配电话号码、电子邮件地址,或者通过词性标记模式来识别名词短语作为潜在的实体。
词典匹配
除了规则,基于规则的方法还经常使用词典(或称为实体列表)来进行实体匹配。这些词典包含了大量特定类型实体的名称,如人名、地名、机构名等。通过词典匹配,系统能够识别出文本中出现的已知实体。
规则应用
在实践中,规则和词典通常被整合到一个处理流程中,以识别和提取文本中的实体。这个流程可能会包括文本预处理、词性标注、句法分析等步骤,以辅助规则匹配和实体识别。
基于规则的方法的优缺点
优点
- 透明度高:规则是人工定义的,易于理解和验证。
- 定制性强:可以针对特定领域或任务定制规则和词典。
- 响应速度快:相比于复杂的机器学习模型,规则匹配通常计算量小,速度快。
缺点
- 可扩展性差:手工编写规则和维护词典耗时耗力,且难以适应语言变化和领域扩展。
- 泛化能力弱:基于规则的方法很难处理未见过的实体或新的表达方式。
- 维护成本高:随着应用领域的扩大,规则和词典的维护成本会急剧增加。
实战案例
场景描述
假设我们需要从金融新闻文章中抽取公司名称。金融新闻的语言比较规范,公司名称出现的模式相对固定,这为基于规则的方法提供了适用场景。
规则和词典的定义
- 规则定义:利用正则表达式识别典型的公司后缀,如“Inc.”、“Ltd.”等。
- 词典构建:构建一个包含常见金融机构名称的词典。
实现示例
import re
# 定义公司名称的正则表达式规则
company_pattern = re.compile(r'\b(?:\w+\s){0,2}\w*?(?:Inc|Ltd|Corporation|Group)\b')
# 示例文本
text = "GlobalTech
Inc. announced a merger with Innovate Ltd. today."
# 应用规则
matches = company_pattern.findall(text)
print("Identified Companies:", matches)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出
Identified Companies: ['GlobalTech Inc.', 'Innovate Ltd.']
- 1
通过这个简单的实战案例,我们可以看到基于规则的方法在特定场景下的有效性。然而,要注意的是,在更复杂或多样化的文本环境中,基于规则的方法可能需要与其他技术相结合,以提高实体抽取的准确性和覆盖范围。
五、基于特征的机器学习方法
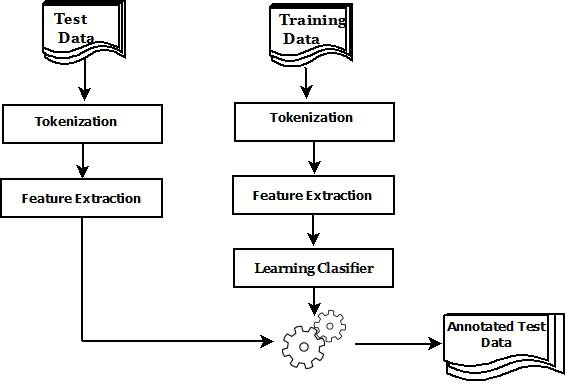
随着自然语言处理技术的进步,实体抽取任务开始采用基于特征的机器学习方法。这些方法通过从文本数据中手工提取特征,然后使用这些特征训练机器学习模型来识别和分类实体。这一转变标志着从静态规则向动态学习的重要步骤,为实体抽取技术的发展提供了新的动力。本节将详细介绍基于特征的机器学习方法的核心概念、特征提取技术,以及通过一个实战案例来展示这类方法的应用。
核心概念
特征提取
特征提取是基于特征的机器学习方法中的关键步骤,它涉及从原始文本数据中提取出能够代表实体特征的信息。这些特征通常包括词性标注、命名实体类型、词前缀和后缀、词根、上下文信息、依存关系等。
模型训练
利用提取出的特征,可以训练不同类型的机器学习模型来进行实体识别和分类,包括决策树、随机森林、支持向量机(SVM)、逻辑回归等。这些模型学习特征与实体类型之间的关系,以便对新的文本数据进行有效的实体识别。
特征提取技术
在基于特征的方法中,如何选择和提取特征对模型性能有着直接的影响。常见的特征提取技术包括:
- 词性标注(POS):标记单词在句中的语法角色,如名词、动词等。
- 句法依存分析:提取词与词之间的依存关系,用于捕捉句子结构信息。
- 上下文信息:考虑目标词前后的词汇,用于捕捉语境相关性。
- 词形特征:如词根、前缀、后缀等,用于识别词汇的形态变化。
实战案例
场景描述
考虑一个场景,我们需要从社交媒体文本中抽取提到的产品名称。这类文本通常非常非正式,且充满网络用语和缩写,给实体抽取带来了额外的挑战。
特征定义和模型选择
- 特征定义:为了应对非正式文本,我们选择词性标注、前后词信息、以及词形特征作为主要特征。
- 模型选择:考虑到任务的复杂性,我们选择支持向量机(SVM)作为分类器,因为它在处理高维稀疏数据时表现良好。
实现示例
假设我们已经完成了数据的预处理和特征提取步骤,下面是一个使用Scikit-learn库中的SVM进行训练的简化示例:
from sklearn.svm import LinearSVC from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.pipeline import Pipeline from sklearn.datasets import load_files # 加载训练数据 data = load_files('data/product_names', encoding='utf-8') X, y = data.data, data.target # 创建一个简单的管道,包括TF-IDF向量化和SVM分类器 pipeline = Pipeline([ ('tfidf', TfidfVectorizer()), ('clf', Linear SVC()), ]) # 训练模型 pipeline.fit(X, y) # 示例预测 predictions = pipeline.predict(["Check out the new smartphone from TechCo!"]) print("Predicted entity:", predictions[0])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
输出
Predicted entity: PRODUCT_NAME
- 1
通过这个实战案例,我们可以看到基于特征的机器学习方法在处理实体抽取任务时的灵活性和有效性。然而,特征选择和模型调优过程往往需要大量的专业知识和实验,这也是这类方法面临的一大挑战。随着深度学习方法的兴起,自动特征提取成为可能,为实体抽取技术的发展开辟了新的路径。
六、基于神经网络的深度学习方法
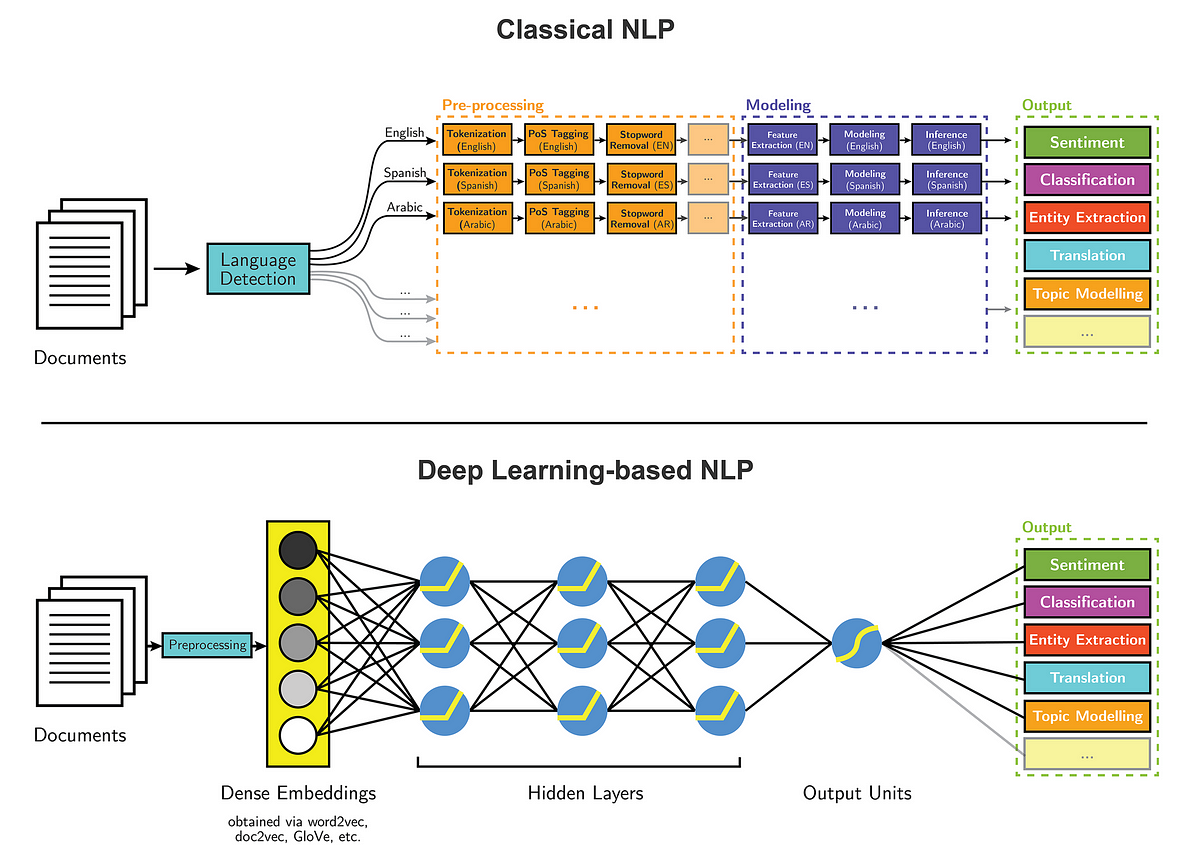
随着深度学习技术的迅猛发展,基于神经网络的方法已经成为实体抽取领域的主流。这些方法通过自动从大量数据中学习复杂的特征表示,显著提高了实体抽取的性能。本节将深入探讨基于神经网络的深度学习方法在实体抽取中的应用,并通过一个实战案例展示如何使用这些方法来提取文本中的实体。
基于神经网络的方法概述
神经网络模型
在实体抽取任务中,最常用的神经网络模型包括卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)和门控循环单元(GRU)。这些模型能够捕捉文本数据中的局部特征(CNN)和长距离依赖关系(RNN、LSTM、GRU),对于处理自然语言的复杂性极为有效。
预训练语言模型
近年来,预训练语言模型如BERT、GPT和RoBERTa等,通过在大规模语料库上预训练,学习到了丰富的语言特征和知识,然后通过微调(Fine-tuning)的方式适应特定的NLP任务,包括实体抽取。这些模型的出现进一步推动了实体抽取技术的性能提升。
实战案例
场景描述
考虑到社交媒体平台上的用户评论中包含大量未经处理的文本数据,这些数据中蕴含着丰富的用户情感和观点,我们的目标是从这些评论中自动抽取提及的品牌和产品名称。
使用预训练语言模型进行实体抽取
为了实现这一目标,我们选择使用BERT模型进行微调。BERT(Bidirectional Encoder Representations from Transformers)是一个基于Transformer的预训练模型,它通过双向训练语言模型来理解文本语义,非常适合实体抽取等NLP任务。
数据准备
我们首先需要准备一个标注好的数据集,其中包含文本和对应的实体标注。为了简化说明,我们假设已经有了这样一个数据集。
模型微调
使用Python和PyTorch库,我们可以轻松地对BERT模型进行微调,以适应我们的实体抽取任务。以下是一个简化的微调过程示例:
from transformers import BertTokenizer, BertForTokenClassification, Trainer, TrainingArguments from torch.utils.data import DataLoader import torch # 初始化BERT分词器 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') # 加载预训练的BERT模型,用于token分类(实体抽取) model = BertForTokenClassification.from_pretrained('bert-base-uncased', num_labels=number_of_entity_types) # 准备数据和训练参数(假设数据已经准备好) train_dataset = ... # 你的训练数据集 training_args = TrainingArguments( output_dir='./models', num_train_epochs=3, per_device_train_batch_size=16, warmup_steps=500, weight_decay=0.01, logging_dir='./logs', ) # 初始化Trainer trainer = Trainer( model=model, args=training_args, train_dataset=train_dataset, ) # 开始训练 trainer.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
这段代码展示了如何使用Hugging Face的Transformers库来加载BERT模型,然后对其进行微调以适应特定的实体抽取任务。
需要注意的是,这里的number_of_entity_types应该根据你的任务中实体的类型数量来设置。
实体抽取
模型训练完成后,我们可以使用训练好的模型对新的文本数据进行实体抽取:
# 示例文本
text = "I love the new iPhone that was released by Apple last week."
# 分词并转换为模型输入格式
input_ids = tokenizer.encode(text, return_tensors="pt")
# 使用模型进行预测
with torch.no_grad():
output = model(input_ids)[0]
predictions = torch.argmax(output, dim=2)
# 将预测结果转换为实体标签(这里省略了转换逻辑)
# ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
通过这个简化的实战案例,我们可以看到基于预训练语言模型的深度学习方法在实体抽取任务上的应用。这类方法通过从大量数据中自动学习特征表示,大大减少了手工特征工程的需求,同时提供了更高的准确性和灵活性。

