
- 1【Linux】基于 Jenkins+shell 实现更新服务所需文件 -->两种方式:ssh/Ansible
- 2vue中一维数组的全选、全不选、反选(图文示例)_数组全选
- 3Android课设简单实现远程数据库操作——图书管理的增删改查。
- 4Windows 10和Linux Mint 18 双系统安装心得_win10下安装linux mint18
- 5##20 实现图像风格迁移:使用PyTorch深入学习的艺术之旅
- 6macOS Sonoma 14.2 (23C64) 正式版 Boot ISO 原版可引导镜像下载_macos 14.2 iso
- 7pytorch安装报错:ERROR: torch has an invalid wheel, .dist-info directory not found
- 8我让gpt写了一段正则表达式代码,可是运行报错,可以帮忙看看哪里出了问题?...
- 9windows更改主机名称映射_远程桌面映射本地电脑磁盘后如何改名称
- 10Stable Diffusion关键插件ControlNet_提取并生成线稿,通过线稿进行二次绘制
bilstm+crf中文分词_基于Bert-NER构建特定领域的中文信息抽取框架(上)
赞
踩
导语:
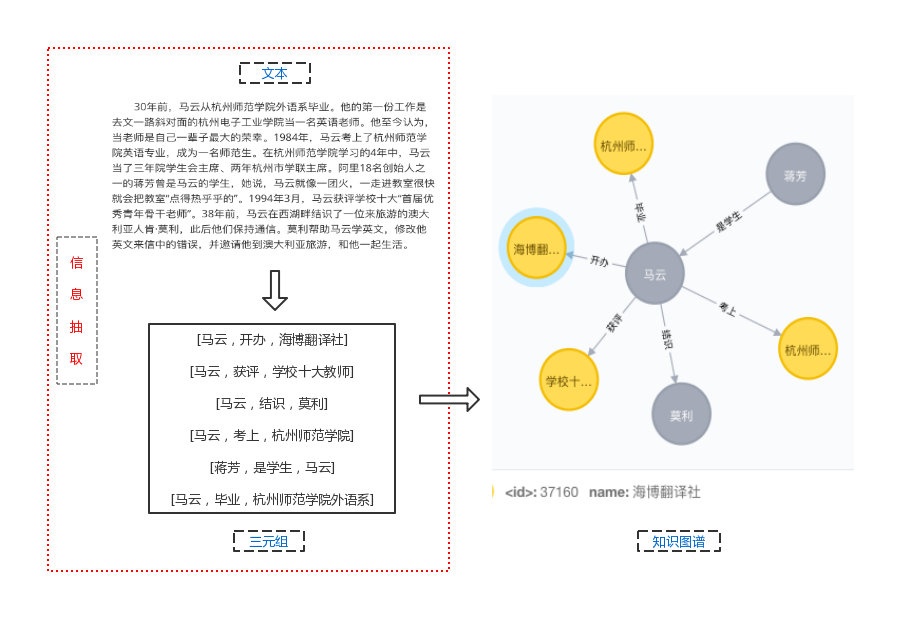
知识图谱(Knowledge Graph)主要由实体、关系和属性构成,而信息抽取(Information Extraction)作为构建知识图谱最重要的一个环节,目的就是从文本当中抽取出三元组信息,包括“实体-关系-实体”以及“实体-属性-实体”两类。然后将抽取后的多个三元组信息储存到关系型数据库(neo4j)中,便可得到一个简单的知识图谱。
本文通过多个实验的对比发现,结合Bert-NER和特定的分词、词性标注等中文语言处理方式,获得更高的准确率和更好的效果,能在特定领域的中文信息抽取任务中取得优异的效果。
目录
1 命名实体识别
Bert-BiLSTM-CRF命名实体识别模型
NeuroNER和BertNER的中文NER对比
Bert-NER在小数据集下训练的表现 2 中文分词与词性标注
(Jieba、Pyltp、PkuSeg、THULAC)中文分词和词性标注工具性能对比
分词工具与BertNER结合使用的性能 3 中文指代消解
基于Stanford coreNLP的指代消解模型
基于BertNER的中文指代消解框架 4 中文信息提取系统
中文信息抽取框架测试结果
一、命名实体识别
1.1 综述:
命名实体识别(Name Entity Recognition)是获取三元组中的实体的关键。命名实体指的是文本中具有特定意义或者指代性强的实体,常见的包括人名、地名、组织名、时间、专有名词等。就目前来说,使用序列标注的方法能够在NER任务中获得比较优异的效果,相对来说比较成熟。
序列标注任务,即在给定的文本序列上预测序列中需要作出标注的标签。处理方式可简单概括为:先将token从离散one-hot表示映射到低维空间中成为稠密的embedding,随后将句子的embedding序列输入到RNN中,使用神经网络自动提取特征以及Softmax来预测每个token的标签。
本文对比了基于Bert的命名实体识别框架和普通的序列标注框架在模型训练、实体预测等方面的效果,并对基于小数据集的训练效果做出实验验证。
1.2模型:
1.2.1 Word Embedding-BiLSTM-CRF:
众多实验表明,该结构属于命名实体识别中最主流的模型,代表的工具有:[NeuroNER](https://github.com/Franck-Dernoncourt/NeuroNER)。它主要由Embedding层(主要有词向量,字向量以及一些额外特征)、双向LSTM层、以及最后的CRF层构成,而本文将分析该模型在中文NER任务中的表现。
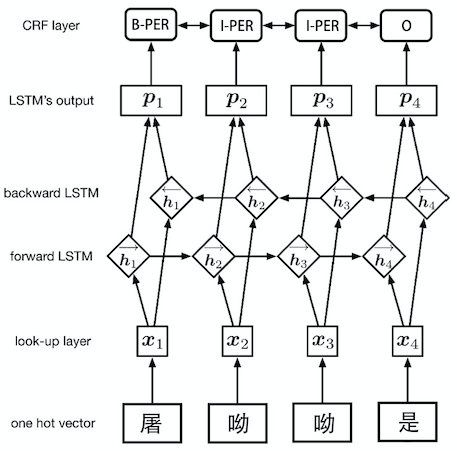
注:NER任务需要得到实体词的输出,所以使用字向量作为输入。
1.2.2 Bert-BiLSTM-CRF:
随着Bert语言模型在NLP领域横扫了11项任务的最优结果,将其在中文命名实体识别中Fine-tune必然成为趋势。它主要是使用bert模型替换了原来网络的word2vec部分,从而构成Embedding层,同样使用双向LSTM层以及最后的CRF层来完成序列预测。详细的使用方法可参考:[基于BERT预训练的中文NER](https://blog.csdn.net/macanv/article/details/85684284)
1.3 NeuroNER和BertNER的中文NER实验
1.3.1实验数据

