
- 1阿里云ECS开放80端口方法_阿里云开启80端口
- 2HT66F018定时器0(STM)定时器/计数器功能使用教程_合泰定时器如何设置
- 3微信小游戏云开发——云函数创建、应用、相关问题_微信云函数creatematchrule
- 4栈的基本操作_栈先进后出,单链表
- 5OpenCV实现物体识别和追踪_opencv识别物体
- 6Element ui 的组件弹窗 el-dialog点击的时候全屏变灰问题解决_el-dialog显示的时候背景置灰
- 7docker安装_docker安装qq
- 8解决GitHub无法访问的问题:手动修改hosts文件与使用SwitchHosts工具_github host
- 9统治扩散模型的U-Net要被取代了,谢赛宁等引入Transformer提出DiT_dits算法
- 10一文带你了解MySQL之Log Buffer_mysql log buffer
SAP技术总结_sap有效变元只能8个字符长
赞
踩
1. 基础
1.1. 基本数据类型
C、N、D、T、I、F、P、X、string、Xstring
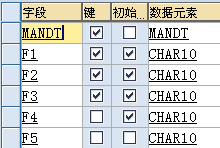
P:默认为8字节,最大允许16字节。最大整数位:16*2 = 32 - 1 = 31 -14(允许最大小数位数) = 17位整数位
| 类型 | 最大长度(字符数) | 默认长度 | 说明 |
| C | 1~262143个字符 | 1 字符 |
|
| N | 1~262143个字符 | 1 字符 | 0到9之间字符组成的数字字符串 |
| D | 8 个字符 |
| 日期格式必须为 YYYYMMDD |
| T | 6 个字符 |
| 格式为 24-hour的 HHMMSS |
| I | 4 bytes |
| -2.147.483.648 to +2.147.483.647 |
| F | 8 bytes |
| 小数位最大可以到17位,即可精确到小数点后17位 |
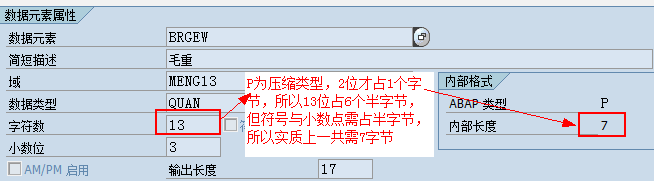
| P | 1 to 16 bytes | 8 bytes | 两个数字位压缩后才占一个字节,由于0-9的数字只需要4Bit位,所以一个字节实质上允许存储二位数字,这就是P数据类型为压缩数据类型的由来。并借用半个字节来存储小数点位置、正号、负号相关信息 |
| X | 1~524,287 bytes | 1 byte | 十六进制字符 0-9, A-F具体的范围为:00~FF 类型X是十六进制类型,可表示内存字节实际内容,使用两个十六制字符表示一个字节中所存储的内容。但直接打印输出时,输出的还是赋值时字面意义上的值,而不是Unicode解码后的字符 如果未在 DATA 语句中指定参数<length>,则创建长度为 1 注:如果值是字母,则一定要大写 |
1.1.1.P类型(压缩型)数据
是一种压缩的定点数,其数据对象占据内存字节数和数值范围取定义时指定的整个数据大小和小数点后位数,如果不指定小数位,则将视为I类型。其有效数字位大小可以是从1~31位数字(小数点与正负号占用一个位置,半个字节),小数点后最多允许14个数字。
P类型的数据,可用于精确运算(这里的精确指的是存储中所存储的数据与定义时字面上所看到的大小相同,而不存在精度丢失问题——看到的就是内存中实实在在的大小)。在使用P类型时,要先选择程序属性中的选项 Fixed point arithmetic(即定点算法,一般默认选中),否则系统将P类型看用整型。其效率低于I或F类型。
"16 * 2 = 32表示了整个字面意义上允许的最大字面个数,而14表示的是字面上小数点后面允许的最大小数位,而不是指14个字节,只有这里定义时的16才表示16个字节
DATA: p(16) TYPE p DECIMALS 14 VALUE '12345678901234567.89012345678901'.
"正负符号与小数点固定要占用半个字节,一个字面上位置,并包括在这16个字节里面。
"16 * 2 = 32位包括了小数点与在正负号在内
"在定义时字面上允许最长可以达到32位,除去小数点与符号需占半个字节以后
"有效数字位可允许31位,这31位中包括了整数位与小数位,再除去定义时小
"数位为14位外,整数位最多还可达到17位,所以下面最多只能是17个9
DATA: p1(16) TYPE p DECIMALS 14 VALUE '-99999999999999999'.
"P类型是以字符串来表示一个数的,与字符串不一样的是,P类型中的每个数字位只会占用4Bit位,所以两个数字位才会占用一个字节。另外,如果定义时没有指定小数位,表示是整型,但小数点固定要占用半个字节,所以不带小数位与符号的最大与最小整数如下(最多允许31个9,而不是32个)
DATA: p1(16) TYPE p VALUE '+9999999999999999999999999999999'.
DATA: p2(16) TYPE p VALUE '-9999999999999999999999999999999'.
其实P类型是以字符串形式来表示一个小数,这样才可以作到精确,就像Java中要表示一个精确的小数要使用BigDecimal一样,否则会丢失精度。
DATA: p(9) TYPE p DECIMALS 2 VALUE '-123456789012345.12'.
WRITE: / p."123456789012345.12-
DATA: f1 TYPE f VALUE '2.0',
f2 TYPE f VALUE '1.1',
f3 TYPE f.
f3 = f1 - f2."不能精确计算
"2.0000000000000000E+00 1.1000000000000001E+00 8.9999999999999991E-01
WRITE: / f1 , f2 , f3.
DATA: p1 TYPE p DECIMALS 1 VALUE '2.0',
p2 TYPE p DECIMALS 1 VALUE '1.1',
p3 TYPE p DECIMALS 1.
p3 = p1 - p2."能精确计算
WRITE: / p1 , p2 , p3. "2.0 1.1 0.9
Java中精确计算:
publicstaticvoid main(String[] args) {
System.out.println(2.0 - 1.1);// 0.8999999999999999
System.out.println(sub(2.0, 0.1));// 1.9
}
publicstaticdouble sub(double v1, double v2) {
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.subtract(b2).doubleValue();
}
1.2.TYPE、LIKE
透明表(还有其它数据词典中的类型,如结构)即可看作是一种类型,也可看作是对象,所以即可使用TYPE,也可以使用LIKE:
TYPES type6 TYPE mara-matnr.
TYPES type7 LIKE mara-matnr.
DATA obj6 TYPE mara-matnr.
DATA obj7 LIKE mara-matnr.
"SFLIGHT为表类型
DATA plane LIKE sflight-planetype.
DATA plane2 TYPE sflight-planetype.
DATA plane3 LIKE sflight.
DATA plane4 TYPE sflight.
"syst为结构类型
DATA sy1 TYPE syst.
DATA sy2 LIKE syst.
DATA sy3 TYPE syst-index.
DATA sy4 LIKE syst-index.
注:定义的变量名千万别与词典中的类型相同,否则表面上即可使用TYPE也可使用LIKE,就会出现这两个关键字(Type、Like)都可用的奇怪现像,下面是定义一个变量时与词典中的结构同名的后果(导致)
DATA : BEGIN OF address2,
street(20) TYPE c,
city(20) TYPE c,
END OF address2.
DATA obj4 TYPE STANDARD TABLE OF address2."这里使用的实质上是词典中的类型address2
DATA obj5 LIKE STANDARD TABLE OF address2."这里使用是的上面定义的变量address2
上面程序编译通过,按理obj4定义是通过不过的(只能使用LIKE来引用另一定义变量的类型,TYPE是不可以的),但由于address2是数字词典中定义的结构类型,所以obj4使用的是数字词典中的结构类型,而obj5使用的是LIKE,所以使用的是address2变量的类型
1.3. DESCRIBE
DESCRIBE FIELD dobj
[TYPE typ [COMPONENTS com]]
[LENGTH ilen IN {BYTE|CHARACTER} MODE]
[DECIMALS dec]
[OUTPUT-LENGTH olen]
[HELP-ID hlp]
[EDIT MASK mask].
DESCRIBE TABLE itab [KIND knd] [LINES lin] [OCCURS n].
1.4.字符串表达式
可以使用&或&&将多个字符模板串链接起来,可以突破255个字符的限制,下面两个是等效的:
|...| & |...|
|...| && |...|
如果内容只有字面常量文本(没有变量表达式或控制字符\r \n \t),则不需要使用字符模板,可这样(如果包含了这些控制字符时,会原样输出,所以有这些控制字符时,请使用 |...|将字符包起来):
`...` && `...`
但是上面3个与下面3个是不一样的:
`...` & `...`
'...' & '...'
'...' && '...'
上面前两个还是会受255个字符长度限制,最后一个虽然不受255限制,但尾部空格会被忽略
字面常量文本(literal text)部分,使用 ||括起来,不能含有控制字符(如 \r \n \t这些控制字符),特殊字符 |{ } \需要使用 \进行转义:
txt = |Characters \|, \{, and \} have to be escaped by \\ in literal text.|.
字符串表达式:
str = |{ ( 1 + 1 ) * 2 }|."算术计算表达式
str = |{ |aa| && 'bb' }|."字符串表达式
str = |{ str }|."变量名
str = |{ strlen( str ) }|."内置函数
1.5. Data element、Domain
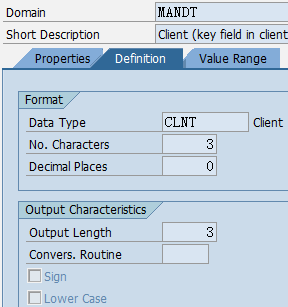
数据元素是构成结构、表的基本组件,域又定义了数据元素的技术属性。Data element主要附带Search Help、Parameter ID、以及标签描述,而类型是由Domain域来决定的。Domain主要从技术方面描述了Data element,如Data Type数据类型、Output Length输出长度、Convers. Routine转换规则、以及Value Range取值范围
将技术信息从Data element提取出来为Domain域的好处:技术信息形成的Domain可以共用,而每个表字段的业务含意不一样,会导致其描述标签、搜索帮助不一样,所以牵涉到业务部分的信息直接Data element中进行描述,而与业务无关的技术信息部分则分离出来形成Domain

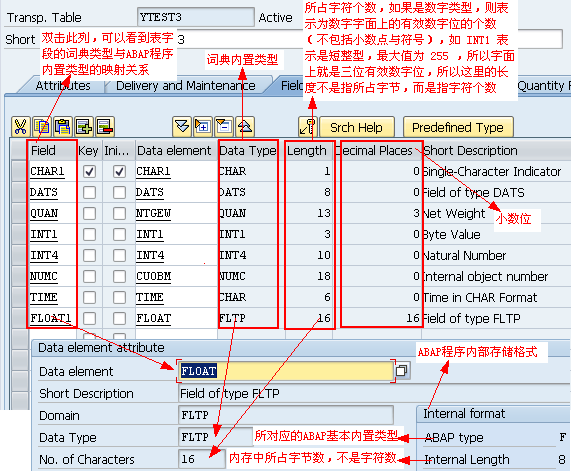
1.6. 词典预定义类型与ABAP类型映射
当你在ABAP程序中引用了ABAPDictionary,则预置Dictionary类型则会转换为相应的ABAP类型,预置的Dictionary类型转换规则表如下:
| Dictionarytype | Meaning | Maximumlengthn | ABAPtype |
| DEC | Calculation/amountfield | 1-31, 1-17intables | P((n+1)/2) |
| INT1 | Single-byte integer | 3 | Internalonly |
| INT2 | Two-byteinteger | 5 | Internalonly |
| INT4 | Four-byteinteger | 10 | I |
| CURR | Currencyfield货币字段 | 1-17 | P((n+1)/2) |
| CUKY | Currencykey货币代码 | 5 | C(5) |
| QUAN | Amount金额 | 1-17 | P((n+1)/2) |
| UNIT | Unit单位 | 2-3 | C(n) |
| PREC | Accuracy | 2 | X(2) |
| FLTP | Floating pointnumber | 16 | F(8) |
| NUMC | Numeric text数字字符 | 1-255 | N(n) |
| CHAR | Character字符 | 1-255 | C(n) |
| LCHR | Long character | 256-max | C(n) |
| STRING | Stringofvariable length | 1-max | STRING. |
| RAWSTRING | Byte sequence of variable length | 1-max | XSTRING |
| DATS | Date | 8 | D |
| ACCP | Accounting period YYYYMM | 6 | N(6) |
| TIMS | Time HHMMSS | 6 | T |
| RAW | Byte sequence | 1-255 | X(n) |
| LRAW | Long byte sequence | 256-max | X(n) |
| CLNT | Client | 3 | C(3) |
| LANG | Language | internal 1, external 2 | C(1) |
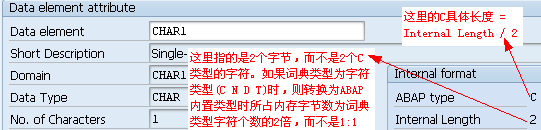
这里的“允许最大长度m”表示的是字面上允许的字符位数,而不是指底层所占内存字节数,如
int1的取值为0~255,所以是3位(不包括符号位)
int2的取值为-32768~32767,所以是5位
lLCHR and LRAW类型允许的最大值为INT2 最大值
lRAWSTRING and STRING 具有可变长度,最大值可以指定,但没有上限
lSSTRING 长度是可变的,其最大值必须指定且上限为255。与CHAR类型相比其优势是它与ABAP type string进行映射。
这些预置的Dictionary类型在创建Data element、Domain时可以引用
在Unicode系统中,一个字符占两个字节
1.7.字符串处理
SPLIT dobj AT sep INTO { {result1 result2 ...} | {TABLE result_tab} }必须指定足够目标字段。否则,用字段dobj的剩余部分填充最后目标字段并包含分界符;或者使用内表动态接收
SHIFT dobj {[{BY num PLACES}|{UP TO sub_string}][[LEFT|RIGHT][CIRCULAR]]}
| { {LEFT DELETING LEADING}|{RIGHT DELETING TRAILING} } pattern
对于固定长度字符串类型,shift产生的空位会使用空格或十六进制的0(如果为X类型串时)来填充
向右移动时前面会补空格,固定长度类型字符串与String结果是不一样:String类型右移后不会被截断,只是字串前面补相应数量的空格,但如果是C类型时,则会截断;左移后后面是否被空格要看是否是固定长度类型的字符串还是变长的String类型串,左移后C类型会补空格,String类型串不会(会缩短)
CIRCULAR:将移出的字符串放在左边或者左边
pattern:只要前导或尾部字符在指定的pattern字符集里就会被去掉,直到第一个不在模式pattern的字符止
CONDENSE <c> [NO-GAPS].如果是C类型只去掉前面的空格(因为是定长,即使后面空格去掉了,左对齐时后面会补上空格),如果是String类型,则后面空格也会被去掉;字符串中间的多个连续的空格使用一个空格替换(String类型也是这样);NO-GAPS:字符串中间的所有空格都也都会去除(String类型也是这样);空格去掉后会左对齐[kənˈdens]
CONCATENATE {dobj1 dobj2 ...}|{LINES OF itab}[kənˈkatɪneɪt]
INTO result
[SEPARATED BY sep]
[RESPECTING BLANKS].
CDNT类型的前导空格会保留,尾部空格都会被去掉,但对String类型所有空格都会保留;对于c, d, n, t类型的字符串有一个RESPECTING BLANKS选项可使用,表示尾部空格也会保留。注:使用 `` 对String类型进行赋值时才会保留尾部空格 字符串连接可以使用 && 来操作,具体请参考这里
strlen(arg)、Xstrlen(arg)String类型的尾部空格会计入字符个数中,但C类型的变量尾部空格不会计算入
substring( val = TEXT [off = off] [len = len] )
count( val = TEXT {sub = substring}|{regex = regex} )匹配指定字符串substring或正则式regex出现的子串次数,返回的类型为i整型类型
contains( val = TEXT REGEX = REGEX)是否包含。返回布尔值,注:只能用在if、While等条件表达式中
matches( val = TEXT REGEX = REGEX)regex表达式要与text完全匹配,这与contains是不一样的。返回布尔值,也只能用在if、While等条件表达式中
match( val = TEXT REGEX = REGEX occ = occ)返回的为匹配到的字符串。注:每次只匹配一个。occ:表示需匹配到第几次出现的子串。如果为正,则从头往后开始计算,如果为负,则从尾部向前计算
find( val = TEXT {sub = substring}|{regex = regex}[occ = occ] )查找substring或者匹配regex的子串的位置。如果未找到,则返回-1,返回的为offset,所以从0开始
FIND ALL OCCURRENCES OF REGEX regex IN dobj
[MATCH COUNT mcnt] 成功匹配的次数
{ {[MATCH OFFSET moff][MATCH LENGTH mlen]}最后一次整体匹配到的串(整体串,最外层分组,而不是指正则式最内最后一个分组)起始位置与长度
| [RESULTS result_tab|result_wa] } result_tab接收所有匹配结果,result_wa只能接收最后一次匹配结果
[SUBMATCHES s1 s2 ...].通常与前面的MATCH OFFSET/ LENGTH一起使用。只会接收使用括号进行分组的子组。如果变量s1 s2 ...比分组的数量多,则多余的变量被initial;如果变量s1 s2 ...比分组的数量少,则多余的分组将被忽略;且只存储第一次或最后一次匹配到的结果
replace( val = TEXT REGEX = REGEX WITH = NEW)使用new替换指定的子符串,返回String类型
REPLACE ALL OCCURRENCES OF REGEX regex IN dobj WITH new
1.7.1. count、match结合
DATA: text TYPE string VALUE `Cathy's cat with the hat sat on Matt's mat.`,
regx TYPE string VALUE `\<.at\>`."\< 单词开头,\> 单词结尾
DATA: counts TYPE i,
index TYPE i,
substr TYPE string.
WRITE / text.
NEW-LINE.
counts = count( val = text regex = regx )."返回匹配次数
DO counts TIMES.
index = find( val = text regex = regx occ = sy-index )."返回匹配到的的起始位置索引
substr = match( val = text regex = regx occ = sy-index )."返回匹配到的串
index = index + 1.
WRITE AT index substr.
ENDDO.
![]()
1.7.2.FIND …SUBMATCHES
DATA: moff TYPE i,
mlen TYPE i,
s1 TYPE string,
s2 TYPE string,
s3 TYPE string,
s4 TYPE string.
FIND ALL OCCURRENCES OF REGEX `((\w+)\W+\2\W+(\w+)\W+\3)`"\2 \3 表示反向引用前面匹配到的第二与第三个子串
IN `Hey hey, my my, Rock and roll can never die Hey hey, my my`"会匹配二次,但只会返回第二次匹配到的结果,第一次匹配到的子串不会存储到s1、s2、s3中去
IGNORING CASE
MATCH OFFSET moff
MATCH LENGTH mlen
SUBMATCHES s1 s2 s3 s4."根据从外到内,从左到右的括号顺序依次存储到s1 s2…中,注:只取出使用括号括起来的子串,如想取整体子串则也要括起来,这与Java不同
WRITE: / s1, / s2,/ s3 ,/ s4,/ moff ,/ mlen."s4会被忽略

1.7.3. FIND …RESULTS itab
DATA: result TYPE STANDARD TABLE OF string WITH HEADER LINE .
"与Java不同,只要是括号括起来的都称为子匹配(即使用整体也用括号括起来了),
"不管括号嵌套多少层,统称为子匹配,且匹配到的所有子串都会存储到,
"MATCH_RESULT-SUBMATCHES中,即使最外层的括号匹配到的子串也会存储到SUBMATCHES
"内表中。括号解析的顺序为:从外到内,从左到右的优先级顺序来解析匹配结构。
"Java中的group(0)存储的是整体匹配串,即使整体未(或使用)使用括号括起来
PERFORM get_match TABLES result
USING '2011092131221032' '(((\d{2})(\d{2}))(\d{2})(\d{2}))'.
LOOP AT result .
WRITE: / result.
ENDLOOP.
FORM get_match TABLES p_result"返回所有分组匹配(括号括起来的表达式)
USING p_str
p_reg.
DATA: result_tab TYPE match_result_tab WITH HEADER LINE.
DATA: subresult_tab TYPE submatch_result_tab WITH HEADER LINE.
"注意:带表头时 result_tab 后面一定要带上中括号,否则激活时出现奇怪的问题
FIND ALL OCCURRENCES OF REGEX p_reg IN p_str RESULTS result_tab[].
"result_tab中存储了匹配到的子串本身(与Regex整体匹配的串,存储在
"result_tab-offset、result_tab-length中)以及所子分组(括号部分,存储在
"result_tab-submatches中)
LOOP AT result_tab .
"如需取整体匹配到的子串(与Regex整体匹配的串),则使用括号将整体Regex括起来
"来即可,括起来后也会自动存储到result_tab-submatches,而不需要在这里像这样读取
* p_result = p_str+result_tab-offset(result_tab-length).
* APPEND p_result.
subresult_tab[] = result_tab-submatches.
LOOP AT subresult_tab.
p_result = p_str+subresult_tab-offset(subresult_tab-length).
APPEND p_result.
ENDLOOP.
ENDLOOP.
ENDFORM.


1.7.4.正则式类
regex = Regular expression [ˈreɡjulə]
cl_abap_regex:与Java中的 java.util.regex.Pattern的类对应
cl_abap_matcher:与Java中的 java.util.regex.Matcher的类对应
1.7.4.1.matches、match
是否完全匹配(正则式中不必使用 ^ 与 $);matches为静态方法,而match为实例方法,作用都是一样
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result,
match_line TYPE submatch_result.
"^$可以省略,因为matches方法本身就是完全匹配整个Regex
IF cl_abap_matcher=>matches( pattern = '^(db(ai).*)$' text = 'dbaiabd' ) = 'X'.
matcher = cl_abap_matcher=>get_object( )."获取最后一次匹配到的 Matcher 实例
match = matcher->get_match( ). "获取最近一次匹配的结果(注:是整体匹配的结果)
WRITE / matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDIF.
![]()
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result,
match_line TYPE submatch_result.
"^$可以省略,因为matche方法本身就是完全匹配整个Regex
matcher = cl_abap_matcher=>create( pattern = '^(db(ai).*)$' text = 'dbaiabd' ).
IF matcher->match( ) = 'X'.
match = matcher->get_match( ). "获取最近一次匹配的结果
WRITE / matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDIF.
![]()
1.7.4.2.contains
是否包含(也可在正则式中使用 ^ 与 $ 用于完全匹配检查,或者使用 ^ 检查是否匹配开头,或者使用 $ 匹配结尾)
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result,
match_line TYPE submatch_result.
IF cl_abap_matcher=>contains( pattern = '(db(ai).{2}b)' text = 'dbaiabddbaiabb' ) = 'X'.
matcher = cl_abap_matcher=>get_object( ). "获取最后一次匹配到的 Matcher 实例
match = matcher->get_match( ). "获取最近一次匹配的结果
WRITE / matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDIF.
![]()
1.7.4.3.find_all
DATA: matcher TYPE REF TO cl_abap_matcher,
match_line TYPE submatch_result,
itab TYPE match_result_tab WITH HEADER LINE.
matcher = cl_abap_matcher=>create( pattern = '<[^<>]*(ml)>' text = '<html>hello</html>' )."创建 matcher 实例
"注:子分组存储在itab-submatches字段里
itab[] = matcher->find_all( ).
LOOP AT itab .
WRITE: / matcher->text, itab-offset, itab-length,matcher->text+itab-offset(itab-length).
LOOP AT itab-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDLOOP.

1.7.4.4.find_next
逐个找出匹配的子串,包括子分组(括号括起的部分)
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result, match_line TYPE submatch_result,
itab TYPE match_result_tab WITH HEADER LINE.
matcher = cl_abap_matcher=>create( pattern = '<[^<>]*(ml)>' text = '<html>hello</html>' ).
WHILE matcher->find_next( ) = 'X'.
match = matcher->get_match( )."获取最近一次匹配的结果
WRITE: / matcher->text, match-offset, match-length,matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDWHILE.

1.7.4.5.get_length、get_offset、get_submatch
DATA: matcher TYPE REF TO cl_abap_matcher,
length TYPE i,offset TYPE i,
submatch TYPE string.
matcher = cl_abap_matcher=>create( pattern = '(<[^<>]*(ml)>)' text = '<html>hello</html>' ).
WHILE matcher->find_next( ) = 'X'. "循环2次
"为0时,表示取整个Regex匹配到的子串,这与Java一样,但如果整个Regex使用括号括起来后,
"则分组索引为1,这又与Java不一样(Java不管是否使用括号将整个Regex括起来,分组索引号都为0)
"上面Regex中共有两个子分组,再加上整个Regex为隐含分组,所以一共为3组
DO 3 TIMES.
"在当前匹配到的串(整个Regex相匹配的串)中返回指定子分组的匹配到的字符串长度
length = matcher->get_length( sy-index - 1 ).
"在当前匹配到的串(整个Regex相匹配的串)中返回指定子分组的匹配到的字符串起始位置
offset = matcher->get_offset( sy-index - 1 ).
"在当前匹配到的串(整个Regex相匹配的串)中返回指定子分组的匹配到的字符串
submatch = matcher->get_submatch( sy-index - 1 ).
WRITE:/ length , offset,matcher->text+offset(length),submatch.
ENDDO.
SKIP.
ENDWHILE.

1.7.4.6.replace_all
DATA: matcher TYPE REF TO cl_abap_matcher,
count TYPE i,
repstr TYPE string.
matcher = cl_abap_matcher=>create( pattern = '<[^<>]*>' text = '<html>hello</html>' ).
count = matcher->replace_all( ``)."返回替换的次数
repstr = matcher->text. "获取被替换后的新串
WRITE: / count , repstr.
![]()
1.8.CLEAR、REFRESH、FREE
内表:如果使用有表头行的内表,CLEAR 仅清除表格工作区域。要重置整个内表而不清除表格工作区域,使用REFRESH语句或 CLEAR 语句CLEAR <itab>[].;REFRESH加不加中括号都是只清内表,另外REFRESH是专为清内表的,不能清基本类型变量,但CLEAR可以
以上都不会释放掉内表所占用的空间,如果想初始化内表的同时还要释放所占用的空间,请使用:FREE <itab>.
1.9.ABAP程序中的局部与全局变量
报表程序中选择屏幕事件块(AT SELECTION-SCREEN)与逻辑数据库事件块、以及methods(类中的方法)、subroutines(FORM子过程)、function modules(Function函数)中声明的变量为局部的,即在这些块里声明的变量不能在其他块里使用,但这些局部变量可以覆盖同名的全局变量;除这些处理块外,其他块里声明的变量都属于全局的(如报表事件块、列表事件块、对话Module),效果与在程序最开头定义的变量效果是一样的,所以可以在其他处理块直接使用(但要注意的是,需遵守先定义后使用的原则,这种先后关系是从语句书写顺序来说的,与事件块的本身运行顺序没有关系);另外,局部变量声明时,不管在处理块的任何地方,其效果都是相当于处理块里的全局变量,而不像其他语言如Java那样:局部变量的作用域可以存在于任何花括号{}之间(这就意味着局部变量在处理过程范围内是全局的),如下面的i,在ABAP语言中还是会累加输出,而不会永远是1(在Java语言中会是1):
FORM aa.
DO 10 TIMES.
DATA: i TYPE i VALUE 0.
i = i + 1.
WRITE: / i.
ENDDO.
ENDFORM.
1.10.Form、Function
Form、Function中的TABLES参数,TYPE与LIKE后面只能接标准内表类型或标准内表对象,如果要使用排序内表或者哈希内表,则只能使用USING(Form)与CHANGING方式来代替。当把一个带表头的实参通过TABLES参数传递时,表头也会传递过去,如果实参不带表头或者只传递了表体(使用了[]时),系统会自动为内表参数变量创建一个局部空的表头
不管是以TABLES还是以USING(Form)非值、CHANGE非值方式传递时,都是以引用方式(即别名,不是指地址,注意与Java中的传引用区别:Java实为传值,但传递的值为地址的值,而ABAP中传递的是否为地址,则要看实参是否是通过Type ref to定义的)传递;但如果USING值传递,则对形参数的修改不会改变实参,因为此时不是引用传递;但如果CHANGE值传递,对形参数的修改还是会改变实参,只是修改的时机在Form执行或Function执行完后,才去修改
Form中通过引用传递时,USING与CHANGING完全一样;但CHANGING为值传递方式时,需要在Form执行完后,才去真正修改实参变量的内容,所以CHANGING传值与传引用其结果都是一样:结果都修改了实参内容,只是修改的时机不太一样而已
1.10.1.FORM
FORM subr [TABLES t1 [{TYPE itab_type}|{LIKE itab}|{STRUCTURE struc}]
t2 […]]
[USING { VALUE(p1)|p1 } [ { TYPE generic_type }
| { LIKE <generic_fs>|generic_para }
| { TYPE {[LINE OF] complete_type}|{REF TO type} }
| { LIKE {[LINE OF] dobj} | {REF TO dobj} }
| STRUCTURE struc]
{ VALUE(p2)|p2 } […]]
[CHANGING{ VALUE(p1)|p1 } [ { TYPE generic_type }
| { LIKE <generic_fs>|generic_para }
| { TYPE {[LINE OF] complete_type} | {REF TO type} }
| { LIKE {[LINE OF] dobj} | {REF TO dobj} }
| STRUCTURE struc]
{ VALUE(p2)|p2 } […]]
[RAISING {exc1|RESUMABLE(exc1)} {exc2|RESUMABLE(exc2)} ...].
generic_type:为通用类型
complete_type:为完全限制类型
<generic_fs>:为字段符号变量类型,如下面的 fs 形式参数
generic_para:为另一个形式参数类型,如下面的 b 形式参数
DATA: d(10) VALUE'11'.
FIELD-SYMBOLS: <fs> LIKE d.
ASSIGN d TO <fs>.
PERFORM aa USING <fs> d d.
FORM aa USING fs like <fs> a like d b like a.
WRITE:fs,/ a , / b.
ENDFORM.
如果没有给形式参数指定类,则为ANY类型
如果TABLES与USING、CHANGING一起使用时,则一定要按照TABLES、USING、CHANGING顺序声明
值传递中的VALUE关键字只是在FORM定义时出现,在调用时PERFORM语句中无需出现,也就是说,调用时值传递和引用传递不存在语法格式差别
DATA : i TYPE i VALUE 100.
WRITE: / 'frm_ref===='.
PERFORM frm_ref USING i .
WRITE: / i."200
WRITE: / 'frm_val===='.
i = 100.
PERFORM frm_val USING i .
WRITE: / i."100
WRITE: / 'frm_ref2===='.
"不能将下面的变量定义到frm_ref2过程中,如果这样,下面的dref指针在调用frm_ref2 后,指向的是Form中局部变量内存,为不安全发布,运行会抛异常,因为From结束后,它所拥有的所有变量内存空间会释放掉
DATA: i_frm_ref2 TYPE i VALUE 400.
i = 100.
DATA: dref TYPE REF TO i .
get REFERENCE OF i INTO dref.
PERFORM frm_ref2 USING dref ."传递的内容为地址,属于别名引用传递
WRITE: / i."4000
field-SYMBOLS : <fs> TYPE i .
ASSIGN dref->* to <fs>."由于frm_ref2过程中已修改了dref的指向,现指向了i_frm_ref2 变量的内存空间
WRITE: / <fs>."400
WRITE: / 'frm_val2===='.
i = 100.
DATA: dref2 TYPE REF TO i .
get REFERENCE OF i INTO dref2.
PERFORM frm_val2 USING dref2 .
WRITE: / i."4000
ASSIGN dref2->* to <fs>.
WRITE: / <fs>."4000
FORM frm_ref USING p_i TYPE i ."C++中的引用参数传递:p_i为实参i的别名
WRITE: / p_i."100
p_i = 200."p_i为参数i的别名,所以可以直接修改实参
ENDFORM.
FORM frm_val USING value(p_i)."传值:p_i为实参i的拷贝
WRITE: / p_i."100
p_i = 300."由于是传值,所以不会修改主调程序中的实参的值
ENDFORM.
FORM frm_ref2 USING p_i TYPE REF TO i ."p_i为实参dref的别名,类似C++中的引用参数传递(传递的内容为地址,并且属于别名引用传递)
field-SYMBOLS : <fs> TYPE i .
"现在<fs>就是实参所指向的内存内容的别名,代表实参所指向的实际内容
ASSIGN p_i->* to <fs>.
WRITE: / <fs>."100
<fs> = 4000."直接修改实参所指向的实际内存
DATA: dref TYPE REF TO i .
get REFERENCE OF i_frm_ref2 INTO dref.
"由于USING为C++的引用参数,所以这里修改的直接是实参所存储的地址内容,这里的p_i为传进来的dref的别名,是同一个变量,所以实参的指向也发生了改变(这与Java中传递引用是不一样的,Java中传递引用时为地址的拷贝,即Java中永远也只有传值,但C/C++/ABAP中可以传递真正引用——别名)
p_i = dref."此处会修改实参的指向
ENDFORM.
FORM frm_val2 USING VALUE(p_i) TYPE REF TO i ."p_i为实参dref2的拷贝,类似Java中的引用传递(虽然传递的内容为地址,但传递的方式属于地址拷贝——值传递)
field-SYMBOLS : <fs> TYPE i .
"现在<fs>就是实参所指向的内存内容的别名,代表实参所指向的实际内容
ASSIGN p_i->* to <fs>.
WRITE: / <fs>."100
<fs> = 4000."但这里还是可以直接修改实参所指向的实际内容
DATA: dref TYPE REF TO i .
get REFERENCE OF i_frm_ref2 INTO dref.
"这里与过程 frm_ref2 不一样,该过程 frm_val2 参数的传递方式与java中的引用传递是原理是一样的:传递的是地址拷贝,所以下面不会修改主调程序中实参dref2的指向,它所改变的只是拷贝过来的Form中局部形式参数的指向
p_i = dref.
ENDFORM.
1.10.2.FUNCTION

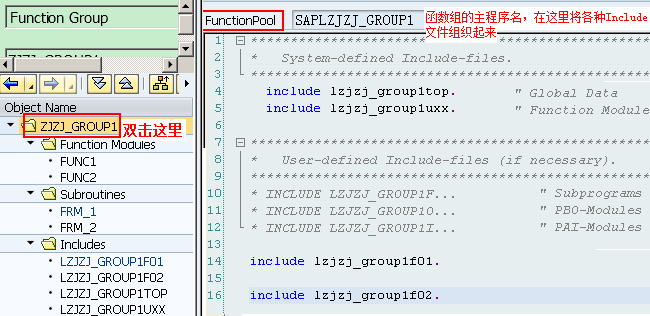
1.10.2.1. Function Group结构
当使用Function Builder创建函数组时,系统会自动创建main program与相应的include程序:

l<fgrp>为Function Group的名称
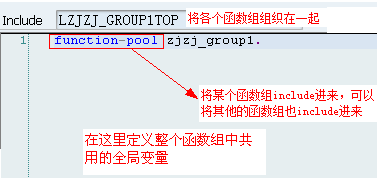
lSAPL<fgrp>为主程序名,它将Function Group里的所有Include文件包括进来,除了INCLUDE语句之外,没有其他语句了
lL<fgrp>TOP,里面有FUNCTION-POOL语句,以及所有Function Module都可以使用的全局数据定义
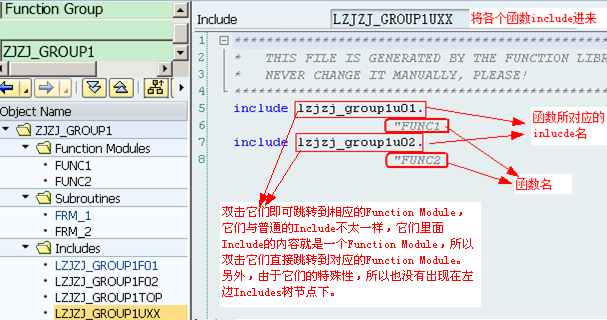
lL<fgrp>UXX,也只有INCLUDE语句,它所包括的Include文件为相应具体Function Module所对应Include文件名:L<fgrp>U01、L<fgrp>U02、...这些Include文件实际上包含了所对应的Function Module代码(即双击它们进去就是对应的Function,而显示的不是真正Include文件所对应的代码)
lL<fgrp>U01和L<fgrp>U02中的01、02编号对应L<fgrp>UXX中的“XX”,代表其创建先后的序号,例如L<fgrp>U01和L<fgrp>U02是头两个被创建的函数,在函数组中创建出的函数代码就放在相应的L<fgrp>UXX(这里的XX代表某个数字,而不是字面上的XX)Include头文件中
lL<fgrg>FXX,用来存一些Form子过程,并且可以被所有的Function Modules所使用(不是针对某个Function Module的,但一般在设计时会针对每个Function Module设计这样单独的Include文件,这是一个好习惯),并且在使用时不需要在Function Module中使用INCLUDE语句包含它们(因为这些文件在主程序SAPL<fgrp>里就已经被Include进来了)。另外,L<fgrg>FXX中的F是指Form的意思,这是一种名称约束而已,在创建时我们可以随便指定,一般还有IXX(表示些类Include文件包括的是一些PAI事件中调用的Module,有时干脆直接使用L<fgrg>PAI或者L<fgrg>PAIXX),OXX(表示些类Include文件包括的是一些PBO事件中调用的Module,有时干脆直接使用L<fgrg>PBO或者L<fgrg>PBOXX)。注:如果Form只被某一函数单独使用,实质上还可直接将这些Form定义在Function Module里的ENDFUNCTION语句后面
当你调用一个function module时,系统加将整个function group(包括Function Module、Include文件等)加载到主调程序所在的internal session中,然后该Function Module得到执行,该Function Group一直保留在内存中,直到internal session结束。Function Group中的所定义的Include文件中的变量是全局,被所有Function Module共享,所以Function Group好比Java中的类,而Function Module则好比类中的方法,所以Function Group中的Include文件中定义的东西是全局型的,能被所有Function Module所共享使用

1.10.2.2.Function参数传值、传址
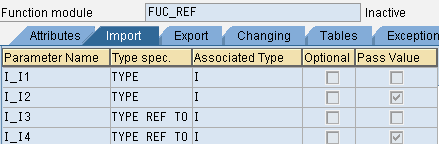
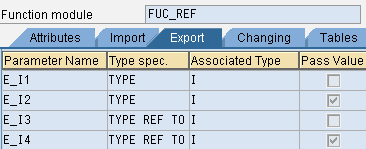
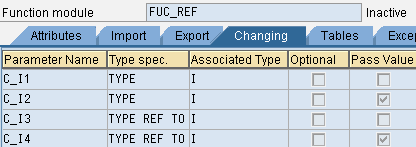
function fuc_ref .
*"-------------------------------------------------------------------
*"*"Local Interface:
*" IMPORTING
*" REFERENCE(I_I1) TYPE IREFERENCE(别名)为参数的默认传递类型
*" VALUE(I_I2) TYPE I 定义时勾选了Pass Value选项才会是 VALUE类型
*" REFERENCE(I_I3) TYPE REF TO I
*" VALUE(I_I4) TYPE REF TO I
*" EXPORTING
*" REFERENCE(E_I1) TYPE I
*" VALUE(E_I2) TYPE I
*" REFERENCE(E_I3) TYPE REF TO I
*" VALUE(E_I4) TYPE REF TO I
*" TABLES
*" T_1 TYPE ZJZJ_ITAB
*" CHANGING
*" REFERENCE(C_I1) TYPE I
*" VALUE(C_I2) TYPE I
*" REFERENCE(C_I3) TYPE REF TO I
*" VALUE(C_I4) TYPE REF TO I
*"-------------------------------------------------------------------
write: / i_i1."1
"由于i_i1为输入类型参数,且又是引用类型,实参不能被修改。这里i_i1是以C++中的引用(别名)参数方式传递参数,所以如果修改了i_i1就会修改实际参数,所以函数中不能修改REFERENCE 的 IMPORTING类型的参数,如果去掉下面注释则编译出错
"i_i1 = 10.
write: / i_i2."2
"虽然i_i2是输入类型的参数,但不是引用类型,所以可以修改,编译能通过但不会修改外面实参的值,只是修改了该函数局部变量的值
i_i2 = 20.
field-symbols: <fs> type i .
assign i_i3->* to <fs>.
"由于i_i3存储的是地址,所以先要解引用再能使用
write: / <fs>.
"同上面,REFERENCE的IMPORTING类型的参数不能被修改:这里即不能修改实参的指向"GET REFERENCE OF 30 INTO i_i3."虽然不可以修改实参的指向,但可以修改实参所指向的实际内容
<fs> = 30.
assign i_i4->* to <fs>.
"i_i4存储也的是地址,所以先要解引用再能使用
write: / <fs>.
"虽然i_i4是输入类型的参数,但不是引用类型,所以可以修改,只会修改函数中的局部参数i_i4的指向,但并不会修改实参的指向
get reference of 40 into i_i4.
"虽然不能修改实参的指向,但可以直接修改实参的所指向的实际内容
<fs> = 400.
WRITE: / c_i1."111
"c_i1为实参的别名,修改形参就等于修改实参内容
c_i1 = 1110.
WRITE: / c_i2."222
"c_i2为实参的副本,所以不会影响实参的内容,但是,由于是CHANGING类型的参数,且为值传递,在函数正常执行完后,还是会将该副本再次拷贝给实参,所以最终实参还是会被修改
c_i2 = 2220.
ENDFUNCTION.
调用程序:
DATA: i_i1 TYPE i VALUE 1,
i_i2 TYPE i VALUE 2,
i_i3 TYPE REF TO i ,
i_i4 TYPE REF TO i ,
c_i1 TYPE i VALUE 111,
c_i2 TYPE i VALUE 222,
c_i3 TYPE REF TO i ,
c_i4 TYPE REF TO i ,
t_1 TYPE zjzj_itab WITH HEADER LINE.
DATA: i_i3_ TYPE i VALUE 3.
GET REFERENCE OF i_i3_ INTO i_i3.
DATA: i_i4_ TYPE i VALUE 4.
GET REFERENCE OF i_i4_ INTO i_i4.
DATA: c_i3_ TYPE i VALUE 333.
GET REFERENCE OF c_i3_ INTO c_i3.
DATA: c_i4_ TYPE i VALUE 444.
GET REFERENCE OF c_i4_ INTO c_i4.
CALL FUNCTION 'FUC_REF'
EXPORTING
i_i1 = i_i1
i_i2 = i_i2
i_i3 = i_i3
i_i4 = i_i4
TABLES
t_1 = t_1
CHANGING
c_i1 = c_i1
c_i2 = c_i2
c_i3 = c_i3
c_i4 = c_i4.
WRITE: / i_i2."2
WRITE: / i_i3_."30
WRITE: / i_i4_."400
WRITE: / c_i1."1110
WRITE: / c_i2."2220
1.11. 字段符号FIELD-SYMBOLS
字段符号可以看作仅是已经被解引用的指针(类似于C语言中带有解引用操作符 * 的指针),但更像是C++中的引用类型(int i ;&ii= i;),即某个变量的别名,它与真正的指针还是有很大的区别的,在ABAP中引用变量(通过TYPE REF TO定义的变量)才好比C语言中的指针
ASSIGN ... TO <fs>:将某个内存区域分配给字段符号,这样字段符号就代表了该内存区域,即该内存区域别名
1.11.1.ASSIGN隐式强转
TYPES: BEGIN OF t_date,
year(4) TYPE n,
month(2) TYPE n,
day(2) TYPE n,
END OF t_date.
FIELD-SYMBOLS <fs> TYPE t_date."将<fs>定义成了具体限定类型
ASSIGN sy-datum TO <fs> CASTING. "后面没有指定具体类型,所以使用定义时的类型进行隐式转换
1.11.2.ASSIGN显示强转
DATA txt(8) TYPE c VALUE '19980606'.
FIELD-SYMBOLS <fs>.
ASSIGN txt TO <fs> CASTING TYPE d."由于定义时未指定具体的类型,所以这里需要显示强转
1.11.3.ASSIGN 动态分配
1.11.4.UNASSIGN、CLEAR
UNASSIGN:该语句是初始化<FS>字段符号,执行后字段符号将不再引用内存区域,<fs> is assigned返回假
CLEAR:与UNASSIGN不同的是,只有一个作用就是初始化它所指向的内存区域,而不是解除分配
1.12.数据引用、对象引用
TYPE REF TO data 数据引用data references
TYPE REF TO object 对象引用object references
除了object,所有的通用类型都能直接用TYPE后面(如TYPE data,但没有TYPE object,object不能直接跟在TYPE后面,只能跟在TYPE REF TO后面)
TYPE REF TO 后面可接的通用类型只能是data(数据引用)或者是object(对象引用)通用类型,其他通用类型不行
1.12.1.数据引用Data References
DATA: dref TYPE REF TO i ."dref即为数据引用,即数据指针,指向某个变量或常量,存储变量地址
CREATE DATA dref.
dref->* = 2147483647."可直接解引用使用,不需要先通过分配给字段符号后再使用
DATA: BEGIN OF strct,
c,
END OF strct.
DATA: dref LIKE REF TO strct .
CREATE DATA dref .
dref->*-c = 'A'.
TYPES: tpy TYPE c.
DATA: c1 TYPE REF TO tpy.
DATA: c2 LIKE REF TO c1."二级指针
GET REFERENCE OF 'a' INTO c1.
GET REFERENCE OF c1 INTO c2.
WRITE: c2->*->*."a
1.12.2.对象引用Object references
CLASS cl DEFINITION.
PUBLIC SECTION.
DATA: i VALUE 1.
ENDCLASS.
CLASS cl IMPLEMENTATION.
ENDCLASS.
DATA: obj TYPE REF TO cl.
CREATE OBJECT obj. "创建对象
DATA: oref LIKE REF TO obj. "oref即为对象引用,即对象指针,指向某个对象,存储对象地址
GET REFERENCE OF obj INTO oref. "获取对象地址
WRITE: oref->*->i."1
1.12.3.GET REFERENCE OF获取变量/对象/常量地址
DATA: e_i3 TYPE REF TO i .
GET REFERENCE OF 33 INTO e_i3.
WRITE: e_i3->*."33
"但不能修改常量的值
"e_i3->* = 44.
DATA: i TYPE i VALUE 33,
dref LIKE REF TO i."存储普通变量的地址
GET REFERENCE OF i INTO dref.
dref->* = 44.
WRITE: i. "44
1.13.动态语句
1.13.1.内表动态访问
SORT itab BY (comp1)...(compn)
READ TABLE itab WITH KEY(k1)=v1...(kn)=vn
READ TABLE itab...INTOwaCOMPARING(comp1)...(compn) TRANSPORTING(comp1)...
MODIFY [TABLE] itab TRANSPORTING(comp1)...(compn)
DELETE TABLEitabWITH TABLE KEY(comp1)...(compn)
DELETE ADJACENT DUPLICATES FROM itab COMPARING(comp1)...(compn)
AT NEW/END OF (comp)
1.13.2.动态类型
CREATE DATA ... TYPE (type)...
DATA: a TYPE REF TO i.
CREATE DATA a TYPE ('I').
a->* = 1.
CREATE OBJECT ... TYPE (type)...请参考类对象反射章节
1.13.3.动态SQL
MODIFY/UPDATE(dbtab)...
1.13.4.动态调用类的方法
CALL METHOD (meth_name)
| cref->(meth_name)
| iref->(meth_name)
| (class_name)=>(meth_name)
| class=>(meth_name)
| (class_name)=>meth
实例请参考类对象反射章节
1.13.5.ASSIGN 动态分配
FIELD-SYMBOLS:<fs>.
DATA:str(20) TYPE c VALUE 'Output String',
name(20) TYPE c VALUE 'STR'.
"静态分配:编译时就知道要分配的对象名
ASSIGN name TO <fs>."结果是<fs>与name变量等同
"通过变量名动态访问变量
ASSIGN (name) TO <fs>."结果是是<fs>的值为str变量值
DATA: BEGIN OF line,
col1 TYPE i VALUE '11',
col2 TYPE i VALUE '22',
col3 TYPE i VALUE '33',
END OF line.
DATA comp(5) VALUE 'COL3'.
FIELD-SYMBOLS: <f1>, <f2>, <f3>.
ASSIGN line TO <f1>.
ASSIGN comp TO <f2>.
"还可以直接使用以下的语法访问其他程序中的变量
ASSIGN ('(ZJDEMO)SBOOK-FLDATE') TO <fs>.
"通过索引动态的访问结构成员
ASSIGN COMPONENT sy-index OF STRUCTURE <f1> TO <f3>.
"通过字段名动态的访问结构成员
ASSIGN COMPONENT <f2>OF STRUCTURE <f1> TO <f3>.
"如果定义的内表没有组件名时,可以使用索引为0的组件来访问这个无名字段(注:不是1)
ASSIGN COMPONENT 0 OF STRUCTURE itab TO <fs>.
1.13.5.1.动态访问类的属性成员
ASSIGN oref->('attr') TO <attr>.
ASSIGN oref->('static_attr') TO <attr>.
ASSIGN ('C1')=>('static_attr') TO <attr>.
ASSIGN c1=>('static_attr') TO <attr>.
ASSIGN ('C1')=>static_attr TO <attr>.
实例请参考类对象反射章节
1.14.反射
|--CL_ABAP_DATADESCR
| |--CL_ABAP_REFDESCR
| |--CL_ABAP_COMPLEXDESCR
|--CL_ABAP_INTFDESCR
DATA: structtype TYPE REF TO cl_abap_structdescr.
structtype ?= cl_abap_typedescr=>describe_by_name( 'spfli' ).
*COMPDESC-TYPE ?= CL_ABAP_DATADESCR=>DESCRIBE_BY_NAME( 'EKPO-MATNR' ).
DATA: datatype TYPE REF TO cl_abap_datadescr,
field(5) TYPE c.
datatype ?= cl_abap_typedescr=>describe_by_data( field ).
DATA: elemtype TYPE REF TO cl_abap_elemdescr.
elemtype = cl_abap_elemdescr=>get_i( ).
elemtype = cl_abap_elemdescr=>get_c( 20 ).
DATA: oref1 TYPE REF TO object.
DATA: descr_ref1 TYPE REF TO cl_abap_typedescr.
CREATE OBJECT oref1 TYPE ('C1'). "C1为类名
descr_ref1 = cl_abap_typedescr=>describe_by_object_ref( oref1 ).
还有一种:describe_by_data_ref
1.14.1.TYPE HANDLE
handle只能是CL_ABAP_DATADESCR或其子类的引用变量,注:只能用于Data类型,不能用于Object类型,即不能用于CL_ABAP_ OBJECTDESCR,所以没有:
CREATE OBJECT dref TYPE HANDLE objectDescr.
DATA: dref TYPE REF TO data,
c10type TYPE REF TO cl_abap_elemdescr.
c10type = cl_abap_elemdescr=>get_c( 10 ).
CREATE DATA dref TYPE HANDLE c10type.
DATA: x20type TYPE REF TO cl_abap_elemdescr.
x20type = cl_abap_elemdescr=>get_x( 20 ).
FIELD-SYMBOLS: <fs> TYPE any.
ASSIGN dref->* TO <fs> CASTING TYPE HANDLE x20type.
1.14.2.动态创建数据Data或对象Object
TYPES: ty_i TYPE i.
DATA: dref TYPE REF TO ty_i .
CREATE DATA dref TYPE ('I')."根据基本类型名动态创建数据
dref->* = 1.
WRITE: / dref->*." 1
CREATE OBJECT oref TYPE ('C1')."根据类名动态创建实例对象
1.14.3.动态创建基本类型变量、结构、内表
DATA: dref_str TYPE REF TO data,
dref_tab TYPE REF TO data,
dref_i TYPE REF TO data,
itab_type TYPE REF TO cl_abap_tabledescr,
struct_type TYPE REF TO cl_abap_structdescr,
elem_type TYPE REF TO cl_abap_elemdescr,
table_type TYPE REF TO cl_abap_tabledescr,
comp_tab TYPE cl_abap_structdescr=>component_table WITH HEADER LINE.
FIELD-SYMBOLS :<fs_itab> TYPE ANY TABLE.
**=========动态创建基本类型
elem_type ?= cl_abap_elemdescr=>get_i( ).
CREATE DATA dref_i TYPE HANDLE elem_type ."动态的创建基本类型数据对象
**=========动态创建结构类型
struct_type ?= cl_abap_typedescr=>describe_by_name( 'SFLIGHT' )."结构类型
comp_tab[] = struct_type->get_components( )."组成结构体的各个字段组件
* 向结构中动态的新增一个成员
comp_tab-name = 'L_COUNT'."为结构新增一个成员
comp_tab-type = elem_type."新增成员的类型对象
INSERT comp_tab INTO comp_tab INDEX 1.
* 动态创建结构类型对象
struct_type = cl_abap_structdescr=>create( comp_tab[] ).
CREATE DATA dref_str TYPE HANDLE struct_type."使用结构类型对象来创建结构对象
**=========动态创建内表
* 基于结构类型对象创建内表类型对象
itab_type = cl_abap_tabledescr=>create( struct_type ).
CREATE DATA dref_tab TYPE HANDLE itab_type."使用内表类型对象来创建内表类型
ASSIGN dref_tab->* TO <fs_itab>."将字段符号指向新创建出来的内表对象
"**========给现有的内表动态的加一列
table_type ?= cl_abap_tabledescr=>describe_by_data( itab ).
struct_type ?= table_type->get_table_line_type( ).
comp_tab[] = struct_type->get_components( ).
comp_tab-name = 'FIDESC'.
comp_tab-type = cl_abap_elemdescr=>get_c( 120 ).
INSERT comp_tab INTO comp_tab INDEX 2.
struct_type = cl_abap_structdescr=>create( comp_tab[] ).
itab_type = cl_abap_tabledescr=>create( struct_type ).
CREATE DATA dref_tab TYPE HANDLE itab_type.
1.14.4.类对象反射
CLASS c1 DEFINITION.
PUBLIC SECTION.
DATA: c VALUE 'C'.
METHODS: test.
ENDCLASS.
CLASS c1 IMPLEMENTATION.
METHOD:test.
WRITE:/ 'test'.
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
TYPES: ty_c.
DATA: oref TYPE REF TO object .
DATA: oref_classdescr TYPE REF TO cl_abap_classdescr .
CREATE OBJECT oref TYPE ('C1')."根据类名动态创建实例对象
"相当于Java中的Class类对象
oref_classdescr ?= cl_abap_classdescr=>describe_by_object_ref( oref ).
DATA: t_attrdescr_tab TYPE abap_attrdescr_tab WITH HEADER LINE,"类中的属性列表
t_methdescr_tab TYPE abap_methdescr_tab WITH HEADER LINE."类中的方法列表
FIELD-SYMBOLS <fs_attr> TYPE any.
t_attrdescr_tab[] = oref_classdescr->attributes.
t_methdescr_tab[] = oref_classdescr->methods.
LOOP AT t_attrdescr_tab."动态访问类中的属性
ASSIGN oref->(t_attrdescr_tab-name) TO <fs_attr>.
WRITE: / <fs_attr>.
ENDLOOP.
LOOP AT t_methdescr_tab."动态访问类中的方法
CALL METHOD oref->(t_methdescr_tab-name).
ENDLOOP.
![]()
2.面向对象
2.1. 类与接口定义
CLASS class DEFINITION [ABSTRACT][FINAL].
[PUBLIC SECTION.
[components]]
[PROTECTED SECTION.
[components]]
[PRIVATE SECTION.
[components]]
ENDCLASS.
INTERFACE intf.
[components]
ENDINTERFACE.
2.1.1. components
²TYPES, DATA, CLASS-DATA, CONSTANTS for data types and data objects
²METHODS, CLASS-METHODS, EVENTS, CLASS-EVENTS for methods and events
² INTERFACES(如果在类中,表示需要实现哪个接口;如果是在接口中,表示继承哪个接口) for implementing interfaces
² ALIASESfor alias names for interface components给接口组件取别名
2.2.类定义、实现
CLASS math DEFINITION.
PUBLIC SECTION.
METHODS divide_1_by
IMPORTING operand TYPE i
EXPORTING result TYPE f
RAISING cx_sy_arithmetic_error.
ENDCLASS.
CLASS math IMPLEMENTATION.
METHOD divide_1_by.
result = 1 / operand.
ENDMETHOD.
ENDCLASS.
2.3.接口定义、实现
INTERFACEint1.
ENDINTERFACE.
CLASSclass DEFINITION. [ˌdefiˈniʃən]
PUBLICSECTION.
INTERFACES: int1,int2."可实现多个接口
ENDCLASS.
CLASS class IMPLEMENTATION. [ˌɪmplɪmənˈteɪ-ʃən]
METHOD intf1~imeth1.
ENDMETHOD.
ENDCLASS.
2.4.类、接口继承
CLASS<subclass> DEFINITIONINHERITINGFROM<superclass>.[inˈherit]
INTERFACE i0.
METHODS m0.
ENDINTERFACE.
INTERFACE i1.
INTERFACES i0.
"可以有相同的成员名,因为继承过来后,成员还是具有各自的命名空间,在实现时
"被继承过来的叫 i0~m0,在这里的名为i1~m0,所以是不同的两个方法
METHODS m0.
METHODS m1.
ENDINTERFACE.
2.5. 向下强转型 ?=
CLASS person DEFINITION.
ENDCLASS.
CLASS stud DEFINITION INHERITING FROMperson.
ENDCLASS.
START-OF-SELECTION.
DATA p TYPE REF TO person.
DATA s TYPE REF TO stud.
CREATE OBJECT s.
p = s. "向上自动转型
"拿开注释运行时抛异常,因为P此时指向的对象不是Student,而是Person所以能强转的前提是P指向的是Student
"CREATE OBJECT p.
2.6. 方法
METHODS/CLASS-METHODS meth [ABSTRACT|FINAL]
[IMPORTING parameters [PREFERRED PARAMETER p]]
[EXPORTING parameters]
[CHANGING parameters]
[{RAISING|EXCEPTIONS} exc1 exc2 ...].
应该还有一个Returning选项,且RETURNING不能与EXPORTING、CHANGING同时使用:

2.6.1.parameters
... { VALUE(p1) | REFERENCE(p1) | p1 }
{ TYPE generic_type }
|{TYPE{[LINE OF] complete_type}|{REF TO {data|object|complete_type |class|intf}}}
|{LIKE{[LINE OF] dobj}|{REF TO dobj} }
[OPTIONAL|{DEFAULT def1}]
{ VALUE(p2) | REFERENCE(p2) | p2 }...
²data、object:表示是通用数据类型data、object
²complete_type:为完全限定类型
²OPTIONAL与DEFAULT两个选项不能同时使用,且对于EXPORTING类型的输入参数不能使用
²如果参数名p1前没有使用VALUE、REFERENCE,则默认为还是REFERENCE,即引用传递
²方法中的输入输出参数是否能修改,请参考Form、Function参数的传值传址
2.6.2. PREFERRED PARAMETER首选参数
设置多个IMPORTING类型参数中的某一个参数为首选参数。
首选参数的意义在于:当所有IMPORTING类型都为可选optional时,我们可以通过PREFERRED PARAMETER选项来指定某一个可选输入参数为首选参数,则在以下简单方式调用时:[CALL METHOD] meth( a ). 实参a的值就会传递给设置的首选参数,而其他不是首参数的可选输入参数则留空或使用DEFAULT设置的默认值
注:此选项只能用于IMPORTING类型的参数;如果有必选的IMPORTING输入参数,则没有意义了
2.6.3. 普通调用
[CALL METHOD] meth|me->meth|oref->meth|super->meth|class=>meth[(]
[EXPORTING p1 = a1 p2 = a2 ...]
{ {[IMPORTING p1=a1 p2=a2 ...][CHANGING p1 = a1 p2 = a2 ...]}
|[RECEIVING r = a ] } RECEIVING不能与EXPORTING、CHANGING同时使用
[EXCEPTIONS [exc1 = n1 exc2 = n2 ...]
[OTHERS = n_others] ] [)].
如果省略CALL METHOD,则一定要加上括号形式;如果通过CALL METHOD来调用,则括号可加可不加
RECEIVING:用来接收METHODS /CLASS-METHODS 中RETURNING选项返回的值
如果EXPORTING、IMPORTING、CHANGING、RECEIVING、EXCEPTIONS、OTHERS同时出现时,应该按此顺序来编写
注:使用此种方式调用(使用 EXPORTING、IMPORTING等这些选项)时,如果原方法声明时带了返回值RETURNING,只能使用RECEIVING来接受,而不能使用等号来接收返回值,下面用法是错误的:
num2 = o1->m1( EXPORTING p1 = num1 ).
2.6.4. 简单调用
此方式下输入的参数都只能是IMPORTING类型的参数,如果要传CHANGING、EXPORTING、RAISING、EXCEPTIONS类型的参数时,只能使用上面通用调用方式。
²meth( )
此种方式仅适用于没有输入参数(IMPORTING)、输入\输出参数(CHANGING)、或者有但都是可选的、或者不是可选时但有默认值也可
²meth( a )
此种方式仅适用于只有一个必选输入参数(IMPORTING)(如果还有其他输入参数,则其他都为可选,或者不是可选时但有默认值也可),或者是有多个可选输入参数(IMPORTING)(此时没有必选输入参数情况下)的情况下但方法声明时通过使用PREFERRED PARAMETER选项指定了其中某个可选参数为首选参数(首选参数即在使用meth( a )方式传递一个参数进行调用时,通过实参a传递给设置为首选的参数)
²meth( p1 = a1 p2 = a2 ... )
此种方式适用于有多个必选的输入参数(IMPORTING)方法的调用(其它如CHANGING、EXPORTING没有,或者有但可选),如果输入参数(IMPORTING)为可选,则也可以不必传
2.6.5.函数方法
Return唯一返回值
METHODS meth
[IMPORTING parameters [PREFERRED PARAMETER p]]
RETURNINGVALUE(r) typing
[{RAISING|EXCEPTIONS} exc1 exc2 ...].
RETURNING :用来替换EXPORTING、CHANGING,不能同时使用。定义了一个形式参数 r 来接收返回值,并且只能是值传递
具有唯一返回值的函数方法可以直接用在以下语句中:逻辑表达式(IF、ELSEIF、WHILE、CHECK、WAIT)、CASE、LOOP、算术表达式、赋值语句
函数方法可以采用上面简单调用方式来调用:meth( )、meth( a )、meth( p1 = a1 P2 = a2 ... )
ref->m( RECEIVING r = i ).
CALL METHOD ref->m( RECEIVING r = i ).
CALL METHOD ref->m RECEIVING r = i.
2.7.me、super
等效于Java中的 this、super
2.8. 事件
2.8.1. 事件定义
EVENTS|CLASS-EVENTS evt [EXPORTING VALUE(p1)
{ TYPE generic_type }
|{TYPE {[LINE OF] complete_type} |
{ REF TO {data|object|complete_type|class|intf}} }
| {LIKE{[LINE OF] dobj} | {REF TO dobj} }
[OPTIONAL|{DEFAULT def1}]
VALUE(p2) ...].
²data、object:表示是通用数据类型data、object
²complete_type:为完全限定类型
² OPTIONAL与DEFAULT两个选项不能同时使用
²EXPORTING:定义了事件的输出参数,并且事件定义时只能有输出参数,且只能是传值
非静态事件声明中除了明确使用EXPORTING定义的输出外,每个实例事件其实还有一个隐含的输出参数sender,它指向了事件源对象,当使用RAISE EVENT语句触发一个事件时,事件源的对象就会分配给这个sender引用,但是静态事件没有隐含参数sender
事件evt的定义也是在类或接口的定义部分进行定义的
非静态事件只能在非静态方法中触发,而不能在静态方法中触发;而静态事件即可在静态也可在非静态方法中进行触发,或者反过来说:实例方法既可触发静态事件,也可触发非静态事件,但静态方法就只能触发静态事件
2.8.2. 事件触发
RAISE EVENT evt [EXPORTING p1 = a1 p2 = a2 ...].
该语句只能在定义evt事件的同一类或子类,或接口实现方法中进行调用
当实例事件触发时,如果在event handler事件处理器声明语句中指定了形式参数sender,则会自动接收事件源,但不能在RAISE EVENT …EXPORTING语句中明确指定,它会自动传递(如果是静态事件,则不会传递sender参数)
CLASS c1 DEFINITION.
PUBLIC SECTION.
EVENTS e1 EXPORTING value(p1) TYPE string value(p2) TYPE i OPTIONAL. "定义
METHODS m1.
ENDCLASS.
CLASS c1 IMPLEMENTATION.
METHOD m1.
RAISE EVENT e1 EXPORTING p1 = '...'."触发
ENDMETHOD.
ENDCLASS.
2.8.3.事件处理器Event Handler
静态或非静态事件处理方法都可以处理静态或非静态事件,与事件的静态与否没有直接的关系
INTERFACE window. "窗口事件接口
EVENTS: minimize EXPORTINGVALUE(status) TYPE i."最小化事件
ENDINTERFACE.
CLASS dialog_window DEFINITION. "窗口事件实现
PUBLIC SECTION.
INTERFACES window.
ENDCLASS.
INTERFACE window_handler. "窗口事件处理器接口
METHODS: minimize_window FOR EVENT window~minimize OF dialog_window
IMPORTING status sender. "事件处理器方法参数要与事件接口定义中的一致
ENDINTERFACE.
2.8.4. 注册事件处理器
实例事件处理器(方法)注册(注:被注册的方法只能是用来处理非静态事件的方法):
SET HANDLER handler1 handler2 ... FOR oref|{ALL INSTANCES}[ACTIVATION act].
静态事件处理器(方法)注册(注:被注册的方法只能是用来处理静态事件的方法):
SET HANDLER handler1 handler2 ... [ACTIVATION act].
oref:只将事件处理方法handler1 handler2注册到 oref 这一个事件源对象
ALL INSTANCES:将事件处理方法注册到所有的事件源实例中
ACTIVATION act:表示是注册还是注销
2.8.5. 示例
CLASS c1 DEFINITION."事件源
PUBLIC SECTION.
EVENTS: e1 EXPORTING value(p1) TYPE c,e2.
CLASS-EVENTS ce1 EXPORTING value(p2) TYPE i.
METHODS:trigger."事件触发方法
ENDCLASS.
CLASS c1 IMPLEMENTATION.
METHOD trigger.
RAISE EVENT: e1 EXPORTING p1 = 'A',e2,ce1 EXPORTING p2 = 1.
ENDMETHOD.
ENDCLASS.
静态(如下面的h1方法)或非静(如下面的h2方法)态事件处理方法都可以处理静态或非静态事件,事件的处理方法是否只能处理静态的还是非静态事件与事件的静态与否没有关系,但事件的触发方法与事件的静态与否有关系(实例方法既可触发静态事件,也可触发非静态事件,但静态方法就只能触发静态事件);但是,事件处理方法虽然能处理的事件与事件的静态与否没有关系,但如果处理的是静态事件,那此处理方法就成为了静态处理器,只能采用静态注册方式对此处理方法进行注册。如果处理的是非静态事件,那此处理方法就是非静态处理器,只能采用非静态注册方式对此处理方法进行注册
处理器的静态与否与处理方法本身是否静态没有关系,只与处理的事件是否静态有关
CLASS c2 DEFINITION."监听器:即事件处理器
PUBLIC SECTION.
"静态方法也可以处理非静态事件,此方法属于非静态处理器,只能采用非静态注册方式
CLASS-METHODS h1 FOR EVENT e1 OF c1 IMPORTING p1 sender.
"非静态方法处理非静态事件,此方法属于非静态处理器,只能采用非静态注册方式
METHODS: h2 FOR EVENT e2 OF c1 IMPORTING sender,
"非静态方法当然更可以处理静态事件,此方法属于静态处理器,只能采用静态注册方式
h3 FOR EVENT ce1 OF c1 IMPORTING p2.
ENDCLASS.
CLASS c2 IMPLEMENTATION.
METHOD h1 .
WRITE: 'c2=>h1'.
ENDMETHOD.
METHOD: h2.
WRITE: 'c2->h2'.
ENDMETHOD.
METHOD: h3.
WRITE: 'c2->h3'.
ENDMETHOD.
ENDCLASS.
DATA: trigger TYPE REF TO c1,
trigger2 TYPE REF TO c1,
handler TYPE REF TO c2.
START-OF-SELECTION.
CREATE OBJECT trigger.
CREATE OBJECT trigger2.
CREATE OBJECT handler.
"由于h1、h2两个处理方法分别是用来处理非静态事件e1、e2的,所以只能采用实例注册方式
SET HANDLER: c2=>h1 handler->h2 FOR trigger,
"h3处理方法是用来处理静态事件ce1的,属于静态处理器,所以只能采用静态注册方式
handler->h3.
trigger->trigger( ).
"虽然trigger( )方法会触发 e1,e2,ce1 三种事件,但h1、h2未向实例trigger2注册,而h3属于静态处理器,与实例无关,即好比向所有实例注册过了一样
trigger2->trigger( ).

3. 内表
3.1.LOOP AT循环内表
LOOP AT itab {INTO wa}|{ASSIGNING <fs> [CASTING]}|{TRANSPORTING NO FILDS}
[[USING KEY key_name|(name)] [FROM idx1] [TO idx2] [WHERE log_exp|(cond_syntax)]].
ENDLOOP.
FROM … TO: 只适用于标准表与排序表 WHERE … : 适用于所有类型的内表
如果没有通过USING KEY选项的key_name,则循环读取的顺序与表的类型相关:
l标准表与排序表:会按照primary table index索引的顺序一条条的循环,且在循环里SY-TABIX为当前正在处理行的索引号
l 哈希表:由于表没有排序,所以按照插入的顺序来循环处理,注,此时SY-TABIX 总是0
可以在循环内表时增加与删除当前行:If you insert or delete lines in the statement block of a LOOP , this will have the following effects:
- If you insert lines behind(后面) the current line, these new lines will be processed in the subsequent loop(新行会在下一次循环时被处理) passes. An endless loop(可能会引起死循环)can result
- If you delete lines behind the current line, the deleted lines will no longer be processed in the subsequent loop passes
- If you insert lines in front(前面) of the current line, the internal loop counter is increased by one with each inserted line. This affects sy-tabix in the subsequent loop pass(这会影响在随后的循环过程SY-TABIX)
- If you delete lines in front of the current line, the internal loop counter is decreased by one with each deleted line. This affects sy-tabix in the subsequent loop pass
3.1.1.循环中删除行
DATA : BEGIN OF gt_table OCCURS 0,
c,
END OF gt_table.
APPEND 'a' TO gt_table.
APPEND 'b' TO gt_table.
APPEND 'c' TO gt_table.
APPEND 'd' TO gt_table.
APPEND 'e' TO gt_table.
APPEND 'f' TO gt_table.
APPEND 'g' TO gt_table.
APPEND 'h' TO gt_table.
LOOP AT gt_table .
IF gt_table-c = 'b' OR gt_table-c = 'c' OR gt_table-c = 'e'.
WRITE : / sy-tabix COLOR = 6 INTENSIFIED ON INVERSE OFF ,
gt_table COLOR = 6 INTENSIFIED ON INVERSE OFF .
ELSE.
WRITE : / sy-tabix, gt_table.
ENDIF.
ENDLOOP.
SKIP 2.
DATA count TYPE i .
LOOP AT gt_table .
count = count + 1.
"当循环到第三次时删除,即循环到 C 时进行删除
IF count = 3.
DELETE gt_table WHERE c = 'b' OR c = 'c' OR c = 'e'.
ENDIF.
"删除之后sy-tabix会重新开始对内表现有的行进行编号
WRITE :/ sy-tabix, gt_table.
ENDLOOP.
SKIP 2.
LOOP AT gt_table .
WRITE : / sy-tabix, gt_table.
ENDLOOP.

3.1.2.SUM
如果在 AT - ENDAT 块中使用 SUM,则系统计算当前行组中所有行的数字字段之和并将其写入工作区域中相应的字段中
3.1.3. AT...ENDAT
| <line> | 含义 |
| FIRST | 内表的第一行时触发 |
| LAST | 内表的最后一行时触发 |
| NEW <f> | 相邻数据行中相同<f>字段构成一组,在循环到该组的开头时触发 |
| END Of <f> | 相邻数据行中相同<f>字段构成一组,在循环到该组的最末时触发 |
在使用AT...... ENDAT之前,一这要先按照这些语句中的组件名进行排序,且排序的顺序要与在AT...... ENDAT语句中使用顺序一致,排序与声明的顺序决定了先按哪个分组,接着再按哪个进行分组,最后再按哪个进行分组,这与SQL中的Group By 相似
用在AT...... ENDAT语句中的中的组件名不一定要是结构中的关键字段,但这些字段一定要按照出现在AT关键字后面的使用顺序在结构最前面进行声明,且这些组件字段的声明之间不能插入其他组件的声明。如现在需要按照<f1>, <f2>, ....多个字段的顺序来使用在AT...... ENDAT语句中,则首先需要在结构中按照<f1>, <f2>, ....,多字段的顺序在结构最前面都声明,然后按照<f1>, <f2>, ....,多字段来排序的,最后在循环中按如下的顺序块书写程序(请注意书写AT END OF的顺序与AT NEW 是相反的,像下面这样):
LOOP AT <itab>.
AT FIRST. ... ENDAT.
AT NEW <f1>. ...... ENDAT.
AT NEW <f2>. ...... ENDAT.
.......
<single line processing>
.......
AT END OF <f2>.... ENDAT.
AT END OF <f1>. ... ENDAT.
AT LAST. .... ENDAT.
ENDLOOP.
一旦进入到 AT...<f1>...ENDAT 块中时,当前工作区(或表头)中的从<f1>往后,但不包括<f1>(按照在结构中声明的次序)所有字段的字符类型字段会以星号(*)号来填充,而数字字设置为初始值(注:在测试过程中发现String类型不会使用*来填充,而是设置成empty String,所以只有固定长度类型的非数字基本类型才设置为*)。如果在 AT 块中使用了SUM,则会将所有数字类型字段统计出来将存入当前工作区(或表头);但一旦离开AT....ENDAT块后,又会将当前遍历的行恢复到工作区(或表头)中
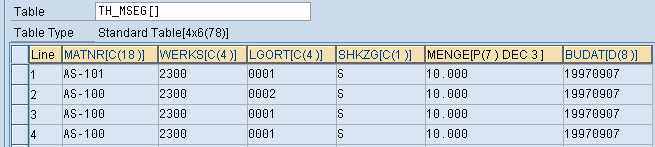
DATA: BEGIN OF th_mseg OCCURS 10,
matnr TYPE mard-matnr, werks TYPE mard-werks,
lgort TYPE mard-lgort, shkzg TYPE mseg-shkzg,
menge TYPE mseg-menge, budat TYPE mkpf-budat,
LOOP AT th_mseg.
AT END OF shkzg."会根据shkzg及前面所有字段来进行分组
sum.
WRITE: / th_mseg-matnr, th_mseg-werks,th_mseg-lgort,
th_mseg-shkzg,th_mseg-menge,th_mseg-budat.
ENDAT.
ENDLOOP.
AS-101 2300 0001 S 10.000 ****.**.**
AS-100 2300 0002 S 10.000 ****.**.**
AS-100 2300 0001 S 20.000 ****.**.**
上面由于没有根据matnr + werks + lgort + shkzg 进行排序,所以结果中的第三行其实应该与第一行合并。其实这个统计与SQL里的分组(Group By)统计原理是一样的,Group By 后面需要明确指定分组的字段,如上面程序使用SQL分组写法应该为 Group Bymatnr werks lgort shkzg,但在ABAP里你只需要按照 matnr werks lgort shkzg按照先后顺序在结构定义的最前面进行声明就可表达了Group By那种意义,而且不一定要将matnr werks lgort shkzg这四个字段全部用在AT语句块中AT NEW、AT END OF shkzg 才正确,其实像上面程序一样,只写AT END OF shkzg这一个语句,前面三个字段matnr werks lgort都可以不用在AT语句中出现,因为ABAP默认会按照结构中声明的顺序将shkzg前面的字段也全都用在了分组中了
DATA: BEGIN OF line,
"C2、C3组件名声明的顺序一定要与在AT...... ENDAT块中使用的次序一致,即这里不能将C3声明在C2之前,且不能在C2与C3之间插入其他字段的声明
c2(5) TYPE c,
c3(5) TYPE c,
c4(5) TYPE c,
i1 TYPE i,
i2 TYPE i,
c1(5) TYPE c,
END OF line.
"使用在AT...... ENDAT语句中的字段不一定要是关键字段
DATA: itab LIKE TABLE OF line WITH HEADER LINE WITH NON-UNIQUE KEY i1.
PERFORM append USING 2 'b' 'bb' 'bbb' '2222' 22.PERFORM append USING 3 'c' 'aa' 'aaa' '3333' 33.
PERFORM append USING 4 'd' 'aa' 'bbb' '4444' 44.PERFORM append USING 5 'e' 'bb' 'aaa' '5555' 55.
PERFORM append USING 6 'f' 'bb' 'bbb' '6666' 66.PERFORM append USING 7 'g' 'aa' 'aaa' '7777' 77.
PERFORM append USING 8 'h' 'aa' 'bbb' '8888' 88.
SORT itab ASCENDING BY c2 c3.
LOOP AT itab.
WRITE: / itab-c2,itab-c3,itab-c1,itab-c4,itab-i1,itab-i2.
ENDLOOP.
SKIP.
LOOP AT itab.
AT FIRST.
WRITE:/ '>>>> AT FIRST'.
ENDAT.
AT NEW c2.
WRITE: / ' >>>> Start of' , itab-c2.
ENDAT.
AT NEW c3.
WRITE: / ' >>>> Start of' , itab-c2, itab-c3.
ENDAT.
"只要一出 AT 块,则表头的数据又会恢复成当前被遍历行的内容
WRITE: / itab-c2,itab-c3,itab-c1,itab-c4,itab-i1,itab-i2.
AT END OF c3.
SUM.
WRITE: / itab-c2,itab-c3,itab-c1,itab-c4,itab-i1,itab-i2.
WRITE: / ' <<<< End of' , itab-c2, itab-c3.
ENDAT.
AT END OF c2.
SUM.
WRITE: / itab-c2,itab-c3,itab-c1,itab-c4,itab-i1,itab-i2.
WRITE: / ' <<<< End of' , itab-c2.
ENDAT.
AT LAST.
SUM.
WRITE: / itab-c2,itab-c3,itab-c1,itab-c4,itab-i1,itab-i2.
WRITE:/ '<<<< AT LAST'.
ENDAT.
ENDLOOP.
TYPES: c5(5) TYPE c.
FORM append USING value(p_i1) TYPE Ivalue(p_c1) TYPE c5 value(p_c2) TYPE c5
value(p_c3) TYPE c5 value(p_c4) TYPE c5 value(p_i2) TYPE i.
itab-i1 = p_i1. itab-c1 = p_c1. itab-c2 = p_c2.
itab-c3 = p_c3. itab-c4 = p_c4. itab-i2 = p_i2.
APPEND itab.
ENDFORM.
aa aaa c 3333 3 33
aa aaa g 7777 7 77
aa bbb d 4444 4 44
aa bbb h 8888 8 88
bb aaa a 1111 1 11
bb aaa e 5555 5 55
bb bbb b 2222 2 22
bb bbb f 6666 6 66
>>>> AT FIRST
>>>> Start of aa
>>>> Start of aa aaa
aa aaa c 3333 3 33
aa aaa g 7777 7 77
aa aaa ***** ***** 10 110
<<<< End of aa aaa
>>>> Start of aa bbb
aa bbb d 4444 4 44
aa bbb h 8888 8 88
aa bbb ***** ***** 12 132
<<<< End of aa bbb
aa ***** ***** ***** 22 242
<<<< End of aa
>>>> Start of bb
>>>> Start of bb aaa
bb aaa a 1111 1 11
bb aaa e 5555 5 55
bb aaa ***** ***** 6 66
<<<< End of bb aaa
>>>> Start of bb bbb
bb bbb b 2222 2 22
bb bbb f 6666 6 66
bb bbb ***** ***** 8 88
<<<< End of bb bbb
bb ***** ***** ***** 14 154
<<<< End of bb
***** ***** ***** ***** 36 396
<<<< AT LAST
3.1.4.自已实现AT...ENDAT
如果循环的内表不是自己定义的,有时无法将分组的字段按顺序声明在一起,所以需要自己实现这些功能,下面是自己实现AT NEW与AT END OF(另一好处是在循环内表时可以使用Where条件语句)(注:使用这种只需要按照分组的顺序排序即可,如要分成bukrs与bukrs anlkl两组时,需要按照BY bukrs anlkl排序,而不能是BYanlkl bukrs):
DATA: lp_bukrs TYPE bukrs, "上一行bukrs字段的值
lp_anlkl TYPE anlkl. "上一行anlkl字段的值
"下面假设按bukrs,bukrs anlkl分成两组
SORT itab_data BY bukrs anlkl.
DATA: i_indx TYPE i .
DATA: lwa_data Like itab_data
LOOP AT itab_data where flg = 'X'.
i_indx = sy-tabix.
"**********AT NEW 对当前分组首行进行处理
IF itab_data-bukrs <> lp_bukrs. "Bukrs组
".........
ENDIF.
IF itab_data-bukrs <> lp_bukrs OR itab_data-anlkl <> lp_anlkl. "bukrs anlkl 分组
".........
ENDIF.
IF itab_data-bukrs <> lp_bukrs OR itab_data-anlkl <> lp_anlkl OR itab_data-.. <> lp_.. . "bukrs anlkl .. 分组
".........
ENDIF.
"**********普通循环处理
".........
"**********AT END OF 对当前分组末行进行处理
DATA : l_nolast1,l_nolast12 . "不是分组中最末行
"这里还是要清一下,以防该代码直接写在报表程序的事件里,而不是Form里(直接放在Report程序事件里时,l_nolast1,l_nolast12将会成为全局变量)
CLEAR: l_nolast1,l_nolast12,l_nolast...
DO.
i_indx = i_indx + 1.
READ TABLE itab_data INTO lwa_data INDEX i_indx."尝试读取下一行
IF sy-subrc <> 0."当前行已是内表中最后一行
EXIT.
"如果第一分组字段都发生了变化,则意味着当前行为所有分组中的最后行
"注:即使有N 个分组,这里也只需要判断第一分组字段是否发生变化,不
"需要对其他分组进行判断,即这里不需要添加其他 ELSEIF 分支
ELSEIF lwa_data-bukrs <> itab_data-bukrs.
EXIT.
ENDIF.
********断定满足条件的下一行不是分组最的一行
"如果Loop循环中没有Where条件,则可以将下面条件 lwa_data-flg = 'X' 删除即可
IF sy-subrc = 0 AND lwa_data-flg = 'X' .
IF lwa_data-bukrs = itab_data-bukrs ."判断当前行是否是 bukrs 分组最后行
l_nolast1 = '1'.
IF lwa_data-nanlkl = itab_data-nanlkl ."判断当前行是否是 bukrs nanlkl 分组最后行
l_nolast2 = '1'.
IF lwa_data-.. = itab_data-..."判断当前行是否是 bukrs nanlkl ..分组最后行
l_nolast.. = '1'.
ENDIF.
ENDIF.
EXIT."只要进到此句所在外层If,表示找到了一条满Where条件的下一行数据,因此,只要找到这样的数据就可以判断当前分组是否已完,即一旦找到这样的数据就不用再往后面找了,则退出以防继续往下找
ENDIF.
ENDIF.
ENDDO.
IF l_nolast..IS INITIAL"处理 bukrs nanlkl ..分组
......
ENDIF.
IF l_nolast2 IS INITIAL ."处理 bukrs nanlkl 分组
......
ENDIF.
IF l_nolast1 IS INITIAL ."处理 bukrs 分组
......
ENDIF.
lp_bukrs = itab_data-bukrs.
lp_anlkl = itab_data-anlkl.
lp_.. = itab_data-.. .
ENDLOOP.
3.2. 在LOOP AT中修改当前内表行
3.2.1.循环中修改索引表
TYPES: BEGIN OF line ,
key ,
val TYPE i ,
END OF line .
DATA: itab1 TYPE line OCCURS 0 WITH HEADER LINE .
DATA: itab2 TYPE line OCCURS 0 WITH HEADER LINE .
itab1-key = 1.
itab1-val = 1.
APPEND itab1.
itab2 = itab1.
APPEND itab2.
itab1-key = 2.
itab1-val = 2.
APPEND itab1.
itab2 = itab1.
APPEND itab2.
LOOP AT itab1.
WRITE: / 'itab1 index: ' , sy-tabix.
READ TABLE itab2 INDEX 1 TRANSPORTING NO FIELDS."试着读取其他内表
"READ TABLE itab1 INDEX 1 TRANSPORTING NO FIELDS."读取本身也不会影响后面的 MODIFY 语句
WRITE: / 'itab2 index: ', sy-tabix.
itab1-val = itab1-val + 1.
"在循环中可以使用下面简洁方法来修改内表,修改的内表行为当前正被循环的行,即使循环中使用了
"READ TABLE语句读取了其他内表(读取本身也没有关系)而导致了sy-tabix 发生了改变,因为以下
"语句不是根据sy-tabix来修改的(如果在前面读取内表导致sy-tabix 发生了改变发生改变后,再使用
"MODIFY itab1 INDEX sy-tabix语句进行修改时,反而不正确。而且该语句还适用于Hash内表,需在
"MODIFY后面加上TABLE关键字后再适用于Hash表——请参见后面章节示例)
MODIFY itab1.
ENDLOOP.
LOOP AT itab1.
WRITE: / itab1-key,itab1-val.
ENDLOOP.

3.2.2. 循环中修改HASH表
TYPES: BEGIN OF line ,
key ,
val TYPE i ,
END OF line .
DATA: itab1 TYPE HASHED TABLE OF line WITH HEADER LINE WITH UNIQUE KEY key.
DATA: itab2 TYPE line OCCURS 0 WITH HEADER LINE .
itab1-key = 1.
itab1-val = 1.
INSERT itab1 INTO TABLE itab1.
itab2 = itab1.
APPEND itab2.
itab1-key = 2.
itab1-val = 2.
INSERT itab1 INTO TABLE itab1.
itab2 = itab1.
APPEND itab2.
LOOP AT itab1.
WRITE: / 'itab1 index: ' , sy-tabix."循环哈希表时,sy-tabix永远是0
READ TABLE itab2 INDEX 1 TRANSPORTING NO FIELDS.
WRITE: / 'itab2 index: ', sy-tabix.
itab1-val = itab1-val + 1.
MODIFY TABLE itab1."注:该语句不一定在要放在循环里才能使用——循环外修改Hash也是一样的,这与上面的索引表循环修改是不一样的,并且修改的条件就是itab1表头工作区,itab1即是条件,也是待修改的值,修改时会根据内表设置的主键来修改,而不是索引号
ENDLOOP.
LOOP AT itab1.
WRITE: / itab1-key,itab1-val.
ENDLOOP.

3.3. 第二索引
三种类型第二索引:
²UNIQUE HASHED: 哈希算法第二索引
²UNIQUE SORTED: 唯一升序第二索引
²NON-UNIQUE SORTED:非唯一升序第二索引
TYPES sbook_tab TYPE STANDARD TABLEOF sbook
"主索引:如果要为主索引指定名称,则只能使用预置的 primary_key,但可以通过后面的 ALIAS 选项来修改(注:ALIAS选项只能用于排序与哈希表)
WITH NON-UNIQUE KEY primary_key "ALIAS my_primary_key
COMPONENTS carrid connid fldate bookid
"第一个第二索引:唯一哈希算法
WITH UNIQUE HASHED KEY hash_key
COMPONENTS carrid connid
"第二第二索引:唯一升序排序索引
WITH UNIQUE SORTED KEY sort_key1
COMPONENTS carrid bookid
"第三第二索引:非唯一升序排序索引
WITH NON-UNIQUE SORTED KEY sort_key2
COMPONENTS customid.
3.3.1. 使用第二索引
1、 可以在READ TABLE itab、MODIFY itab、DELETE itab、LOOP AT itab内表操作语句中通过WITH [TABLE] KEYkey_nameCOMPONENTSK1=V1 ...或者USING KEY key_name,语句中的key_name为第二索引名:
READ TABLE itab WITH TABLE KEY[key_nameCOMPONENTS] {K1|(K1)} = V1... INTO wa
READ TABLE itab WITH KEY key_nameCOMPONENTS {K1|(K1)} = V1... INTO wa
READ TABLE itab FROM wa [USING KEY key_name] INTO wa
READ TABLE itab INDEX idx [USING KEY key_name] INTO wa
MODIFY TABLE itab [USING KEY key_name] FROM wa
MODIFY itab [USINGKEY loop_key] FROM wa此语句只能用在LOOP AT内表循环语句中,并且此时 USING KEY loop_key 选项也可以省略(其实默认就是省略的),其中loop_key是预定义的,不能写成其他名称
MODIFY itab INDEX idx [USING KEY key_name] FROM wa
MODIFY itab FROM wa [USING KEY key_name] ...WHERE ...
DELETE TABLE itab FROM wa [USING KEY key_name]
DELETE TABLE itab WITH TABLE KEY [key_nameCOMPONENTS] {K1|(K1)} = V1...
DELETE itab INDEX idx [USING KEY key_name|(name)]
DELETE itab [USING KEY loop_key]
DELETE itab [USING KEY key_name ] ...WHERE ...
DELETE ADJACENT DUPLICATES FROM itab [USING KEY key_name] [COMPARING K1 K2...]
LOOP AT itab USING KEY key_name WHERE... .
ENDLOOP.
2、 可以在INSERTitab与APPEND语句中通过USING KEY选项来使用第二索引
INSERT wa [USING KEY key_name] INTO TABLE itab
APPEND wa [USING KEY key_name] TO itab
3.3.2.示例
DATA itab TYPE HASHED TABLE OF dbtab WITH UNIQUE KEY col1 col2 ...
"向内表itab中添加大量的数据 ...
READ TABLE itab "使用非主键进行搜索,搜索速度将会很慢
WITH KEY col3 = ... col4 = ...
ASSIGNING ...
上面定义了一个哈希内表,在读取时未使用主键,在大数据量的情况下速度会慢,所以在搜索字段上创建第二索引:
DATA itab TYPE HASHED TABLE OF dbtab
WITH UNIQUE KEY col1 col2 ...
"为非主键创建第二索引
WITH NON-UNIQUE SORTED KEY second_key
COMPONENTS col3 col4 ...
"向内表itab中添加大量的数据 ...
READ TABLE itab "根据第二索引进行搜索,会比上面程序快
WITH TABLE KEY second_key
COMPONENTS col3 = ... col4 = ...
ASSIGNING ...
"在循环内表的Where条件中,如果内表不是排序内表,则不会使用二分搜索,如果使用SORTED KEY,则循环时,会用到二分搜索?
LOOP AT itab USING KEY second_key where col3 = ... col4 = ... .
ENDLOOP.
3.4. 向Unique Key的Sort、Hash表中插入重得数据
TYPES: BEGIN OF typ_tab,
mandt TYPE t001-mandt,
bukrs TYPE t001-bukrs,
END OF typ_tab.
DATA: lt_hash TYPE HASHED TABLE OF typ_tab WITH UNIQUE KEY mandt WITH HEADER LINE.
DATA: lt_sort TYPE SORTED TABLE OF typ_tab WITH UNIQUE KEY mandt WITH HEADER LINE.
lt_hash-mandt = '200'.lt_hash-bukrs = '200'.
INSERT lt_hash INTO TABLE lt_hash.
WRITE:/ 'sy-subrc:',sy-subrc.
lt_hash-mandt = '100'.lt_hash-bukrs = '300'.
INSERT lt_hash INTO TABLE lt_hash.
WRITE:/ 'sy-subrc:',sy-subrc.
lt_hash-mandt = '200'.lt_hash-bukrs = '400'.
"重复的无法插入,也不会覆盖,也不会抛异常
INSERT lt_hash INTO TABLE lt_hash.
WRITE:/ 'sy-subrc:',sy-subrc.
SKIP.
LOOP AT lt_hash.
WRITE: / lt_hash-mandt,lt_hash-bukrs.
ENDLOOP.
WRITE:/ '-----------------------'.
lt_sort-mandt = '200'.lt_sort-bukrs = '200'.
INSERT lt_sort INTO TABLE lt_sort.
WRITE:/ 'sy-subrc:',sy-subrc.
lt_sort-mandt = '100'.lt_sort-bukrs = '300'.
INSERT lt_sort INTO TABLE lt_sort.
WRITE:/ 'sy-subrc:',sy-subrc.
lt_sort-mandt = '200'.lt_sort-bukrs = '400'.
"与HASH一样,重复的无法插入,也不会覆盖,也不会抛异常
INSERT lt_sort INTO TABLE lt_sort.
WRITE:/ 'sy-subrc:',sy-subrc.
SKIP.
LOOP AT lt_sort.
WRITE: / lt_sort-mandt,lt_sort-bukrs.
ENDLOOP.
WRITE:/ '-----------------------'.
"不管是Sort,还是Hash 表,只要是 Unique Key,且从数据库查出来的数据存在重复,则会Dump掉
*SELECT mandt bukrs INTO TABLE lt_hash FROM t001 CLIENT SPECIFIED WHERE mandt BETWEEN '100' AND'999'.
*SELECT mandt bukrs INTO TABLE lt_sort FROM t001 CLIENT SPECIFIED WHERE mandt BETWEEN '100' AND'999'.
另:针对Unique的Sort、Hash内表,可以使用Collect语句进行汇总统计
另外:对于排序内表,不要使用APPEND 、APPEND LINES附加数据,要使用INSERT、INSERT LINES向排序内表中插入数据,因为如果附加的数据不按排序内表排序规则来的话,会Dump,但使用INSERT就不会了

3.5. 适合所有类型的内表操作
COLLECT [<wa>INTO] <itab> 将具有相同关键字段值的行中同名的数字字段的值累计到一条记录上,只有非表关键字段被累加;当在内表中找不到指定的被累加行时,COLLECT语句的功能与APPEND语句是一样的,即将一个工作区的内容附加到itab内表中。使用COLLECT操作的内表有一个限制,即该的行结构中,除了表键字段以外的所有字段都必须是数字型(i、p、f)
INSERT <wa> INTOTABLE <itab>."单条插入
INSERT LINES OF <itab1> [FROM <n1>] [TO <n2>] INTO TABLE<itab2>"批量插入
向UNIQUE 的排序表或哈希表插入重复的数据时,不会抛异常,但数据不会被插入进去,这与APPEND是不一样的
Hash内表的KEY设置只能是开头前部分定义的连续的组件字段,不能只将中间或先后几个字段设置为KEY,否则在查找时会出问题,数据无法查到
"只要根据关键字或索引在内表中读取到相应数据,不管该数据行是否与COMPARING 指定的字段相符,都会存储到工作区
READ TABLE <itab> WITH KEY{<k1> = <f1> ... <kn> = <fn>...[BINARY SEARCH]}
INTO <wa> [COMPARING <f1><f2> ...|ALL FIELDS]
[TRANSPORTING <f1><f2> ...|ALL FIELDS|NO FIELDS]
READ TABLE <itab> FROM <wa>…以表关键字为查找条件,条件值来自<wa>
COMPARING:系统根据<k1>...<kn>(关键字段)读取指定的单行与工作区<wa>中的相应组件进行比较。
如果系统找根据指定<k1>...<kn>找到了对应的条目,且进行比较的字段内容相同,则将 SY-SUBRC 设置为0,如果进行比较的字段内容不同,则返回值 2;如果系统根据<k1>...<kn>找不到条目,则包含 4。如果系统找到条目,则无论比较结果如何,都将其读入wa中
MODIFY TABLE<itab> FROM <wa> [TRANSPORTING <f1> <f2> ...]"修改单条(MODIFY TABLE <itab> 一般用在循环中修改哈希表,且itab内表带表头)。这里的<wa>扮演双重身份,不仅指定了要修改的行(条件),还包括要修改的新的值。系统以整个表的所有关键字段来搜索要修改的行;USING KEY:如果未使用此选项,则会使用默认的主键primary table key来修改相应的行;如果找到要修改的行,则将<wa>中所有非关键字段的内容拷贝到对应的数据行中对应的字段上;如果有多行满足条件时只修改第一条
MODIFY <itab> FROM <wa> TRANSPORTING<f1><f2>...WHERE<cond>"修改多条
DELETE TABLE<itab> FROM <wa> "删除单条。多条时,只会删除第一条。条件为所有表关键字段,值来自<wa>
DELETE TABLE <itab> WITH TABLE KEY <k1> = <f1> ..."删除单条。多条时只会删除第一条,条件为所有表关键字
DELETE itab WHERE ( col2 > 1 ) AND ( col1 < 4 )"删除多行
DELETE ADJACENT DUPLICATESFROM <itab> [COMPARING<f1><f2> ... | ALL FIELDS]
注,在未使用COMPARING 选项时,要删除重复数据之前,一定要按照内表关键字声明的顺序来进行排序,才能删除重复数据,否则不会删除掉;如果指定了COMPARING 选项,则需要根据指定的比较字段顺序进行排序(如COMPARING <F1><F2>时,则需要sort by <F1><F2>,而不能是sort by <F2><F1>),才能删除所有重复数据 [əˈdʒeisənt] 邻近的 [ˈdju:plikit] 完全一样的,复制的
3.6.适合索引内表操作
APPEND <wa> TO <itab>
APPEND LINES OF <itab1> [FROM<n1>] [TO<n2>] TO<itab2>
INSERT <wa> INTO <itab> INDEX<idx>"如果不使用 INDEX 选项,则将新的行插入到当前行的前面,一般在Loop中可省略INDEX 选项
INSERT LINES OF <itab1> [FROM <n1>] [TO <n2>] INTO <itab2> INDEX <idx>
APPEND/INSERT…INDEX 操作不能用于Hash表
APPEND/INSERT…INDEX用于排序表时条件:附加/插入时一定要按照Key的升序来附加;如果是Unique排序表,则不能附加/插入重附的数据,这与INSERT…INTO TABLE是不一样的
READ TABLE <itab> INDEX <idx>
INTO <wa> [COMPARING <f1><f2> ...|ALL FIELDS]
[TRANSPORTING <f1><f2> ...|ALL FIELDS|NO FIELDS]
| ASSIGNING <fs>
MODIFY <itab> [INDEX<idx> ] FROM <wa> [TRANSPORTING <f1> <f2> ... ]"如果没有 INDEX 选项,只能在循环中使用该语句
DELETE <itab> [INDEX<idx>]"删除单条。如果省略<index>选项,则DELETE <itab>语句只能用在循环语句中
DELETE<itab> [FROM<n1>] [TO<n2>] WHERE<condition> "删除多条
4. OPEN SQL
4.1. SELECT 、INSERT、UPDATE、DELETE、MODIFY
如果从数据库读出来的数据存在重复时,不能存储到Unique内表中去——如Unique的排序表与哈希表
SELECT SINGLE...INTO [CORRESPONDING FIELDS OF] wa WHERE...
SELECT SINGLE <cols> ... INTO (dobj1, dobj2, ...) WHERE...
SELECT ... FROM <tables> UP TO <n> ROWS ...
SELECT...INTO|APPENDING CORRESPONDING FIELDS OF TABLE <itab>...
单条插入:在插入时是按照数据库表结构来解析<wa>结构,与<wa>中的字段名无关,所以<wa>的长度只少要等于或大于所对应表结构总长度
INSERT INTO <tabname> VALUES <wa>
INSERT <tabname> FROM <wa>
多条插入:itab内表的行结构也必须和数据库表的行结构一致;ACCEPTING DUPLICATE KEYS:如果现出关键字相同条目,系统将SY-SUBRC返回4,并跳过该条目,但其他数据会插入进去
INSERT <tabname> FROM TABLE <itab> [ACCEPTING DUPLICATE KEYS]
单条更新:会根据数据库表关键字来更新其他非关键字段。如果WA工作区是自己定义的且未参照数据库表,则WA的结构需要与数据库表相一致,且不能短于数据库表结构,但字段名可任意取
UPDATE dbtab FROM wa
多条更新:主键不会被更新,即使在SET后面指定后也不会被更改
UPDATEdbtab SETf1 = g1 … fi = gi WHERE <conditions>
UPDATE dbtab FROMTABLE itab 与从WA工作区单条更新原理一样,根据数据表库关键字段来更新,且行结构要与数据库表结构一致,并且不能短于数据库表结构,一样内表行结构组件名可任意
单条删除:下面的WA与Itab原理与Update是一样的
DELETE dbtab FROM wa
多条删除:
DELETE dbtab FROMTABLE itab
DELETEFROM dbtab WHERE <conditions>
插入或更新:下面的WA与Itab原理与Update是一样的
MODIFY dbtab FROM wa 单行
MODIFY dbtab FROMTABLE itab多行,有就修改,没有就插入
4.2.条件操作符
=、<>、<、<=、>、>=
[NOT] BETWEEN ...AND
[NOT] LIKE
[NOT] IN
IS [NOT] NULL
4.3.RANG条件内表
两种定义方式:
RANGES seltab FOR dobj [OCCURS n].其中dobj为自定义变量或者是参照某个表字段
SELECT-OPTIONSselcritFOR {dobj|(name)}
上面两个语句会生成如下结构的内表,该条件内表的每一行都代表一个逻辑条件:
DATA: BEGIN OF seltab OCCURS 0,
sign TYPE c LENGTH 1, 允许值为I和E,I表示包含 Include,E表示排除Exclude
option TYPE c LENGTH 2, OPTION表示选择运算符,
low LIKE dobj, 下界,相当于前面文本框中的值
high LIKE dobj, 上界,相当于后面文本框中的值
END OF rtab.
option: HIGH字段为空,则取值可以为:EQ(=)、NE(<>)、GT(>)、GE(>=)、LE(<=)、LT(<)、CP、NP,CP(集合之内的数据)和NP(集合之外数据)只有当在输入字段中使用了通配符(“*”或“+”)时它们才是有效的
SELECT ... WHERE ... field [NOT] IN seltab ...
如果RANG条件内表为空,则IN seltab逻辑表达试恒为真,XX NOT IN seltab恒为假
注:不会像FOR ALL ENTRIES那样,忽略其他的条件表达式,其他条件还是起作用
4.4. FOR ALL ENTRIES
1、使用该选项后,对于最后得出的结果集系统会自动删除重复行。因此如果你要保留重复行记录时,记得在SELECT语句中添加足够字段
2、FOR ALL ENTRIES IN后面使用的内部表itab如果为空,将查出当前CLIENT端所有数据(即忽略整个WHERE语句,其他条件都会被忽略)
3、内表中的条件字段不能使用BETWEEN、LIKE、IN比较操作符
4、使用该语句时,ORDER BY语句和HAVING语句将不能使用
5、使用该语句时,除COUNT( * )(并且如果有了COUNT函数,则不能再选择其他字段,只能使用在Select ... ENDSelect语句中了)以外的所有合计函数(MAX,MIN,AVG,SUM)都不能使用
SELECT vbeln posnr pstyv werks matnr arktx lgort waerk kwmeng
FROM vbap INTO TABLE gt_so FOR ALL ENTRIES IN lt_matnr
WHERE matnr = lt_matnr-matnr AND vbeln IN s_vbeln AND posnr IN s_posnr.
如果上面的lt_matnr为空,则“AND vbeln IN s_vbeln AND posnr IN s_posnr”条件也会忽略掉,即整个Where都会被忽略掉。
SELECT matnr FROM mara INTO CORRESPONDING FIELDS OF TABLE strc
FOR ALL ENTRIES IN strc WHERE matnr = strc-matnr .
生成的SQL语句:SELECT "MATNR" FROM "MARA" WHERE "MANDT" = '210' AND "MATNR" IN ( '000000000000000101' , '000000000000000103' , '000000000000000104' )
注:这里看上去FOR ALL ENTRIES使用 IN 表达式来代替了,这是只有使用到内表中一个条件是这样的,如果使用多个条件时,不会使用In表达式,而是使用OR连接,像这样:
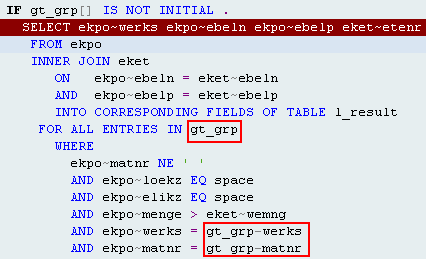
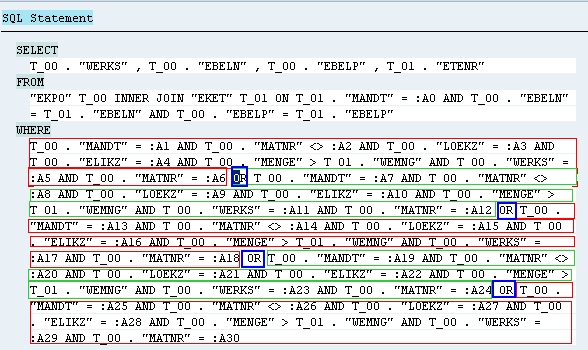
另外,在使用FOR ALL ENTRIES时,不管使用了条件内表中的一个还是多个条件字段,都会以5个值为单位进行SQL发送
4.5.INNER JOIN、LEFT OUTER JOIN使用限制
ON后面的条件与Where条件类似,但有以下不同:
²每个条件表达式中两个操作数之中必须有一个字段是来自于JOIN右表
²如果是LEFT OUTER JOIN,则至少有一个条件表达式的两个操作数一个是来自于左表,另一个来自右表
²不能使用NOT、LIKE、IN(但如果是 INNER JOIN,则>、<、BETWEEN …AND、<>都可用)
²如果是LEFT OUTER JOIN,则只能使用等号操作符:(=、EQ)
²如果是LEFT OUTER JOIN,同一右表不能多次出现在不同的LEFT OUTER JOIN的ON条件表达式中
²LEFT OUTER JOIN的右表所有字段不能出现在WHERE中
²如果是LEFT OUTER JOIN,则在同一个ON条件语句中只能与同一个左表进行关联
4.6. 动态SQL
SELECT (column_syntax) FROM...
column:可以是内表,也可以是字符串
TYPES: line_type TYPE c LENGTH 72.
DATA: column_syntax TYPE TABLE OF line_type .
APPEND 'CARRID' TO column_syntax.
APPEND 'CITYFROM CITYTO' TO column_syntax.
SELECT ... FROM (dbtab_syntax)...
PARAMETERS: p_cityfr TYPE spfli-cityfrom,
p_cityto TYPE spfli-cityto.
DATA: BEGIN OF wa,
fldate TYPE sflight-fldate,
carrname TYPE scarr-carrname,
connid TYPE spfli-connid,
END OF wa.
DATA itab LIKE SORTED TABLE OF wa
WITH UNIQUE KEY fldate carrname connid.
DATA: column_syntax TYPE string,
dbtab_syntax TYPE string.
column_syntax = `c~carrname p~connid f~fldate`.
dbtab_syntax = `( ( scarr AS c `
& ` INNER JOIN spfli AS p ON p~carrid = c~carrid`
& ` AND p~cityfrom = p_cityfr`
& ` AND p~cityto = p_cityto )`
& ` INNER JOIN sflight AS f ON f~carrid = p~carrid `
& ` AND f~connid = p~connid )`.
SELECT (column_syntax) FROM (dbtab_syntax)
INTO CORRESPONDING FIELDS OF TABLE itab.
SELECT ... WHERE (cond_syntax) ...
SELECT ... WHERE <cond> AND/OR (cond_syntax) ...
DATA: cond(72) TYPE c,
itab LIKE TABLE OF cond.
APPEND 'cityfrom = ''NEW YORK''' TO itab.
APPEND 'or cityfrom = ''SAN FRANCISCO''' TO itab.
SELECT * INTO TABLE itab_spfli FROM spfli WHERE (itab).
DATA:cond1(72) TYPE c VALUE 'cityfrom = ''NEW YORK''',
cond2(72) TYPE c VALUE 'cityfrom = ''SAN FRANCISCO'''.
SELECT * INTO TABLE itab_spfli FROM spfli WHERE (cond1) OR (cond2).
DATA: cond(72) TYPE c,
cond1(72) TYPE c VALUE 'cityfrom = ''NEW YORK''',
itab LIKE TABLE OF cond.
APPEND 'cityfrom = ''SAN FRANCISCO''' TO itab.
SELECT * INTO TABLE itab_spfli FROM spfli WHERE (itab) OR (cond1).
DATA: cond(72) TYPE c,
itab LIKE TABLE OF cond.
APPEND 'cityfrom = ''SAN FRANCISCO''' TO itab.
SELECT * INTO TABLE itab_spfli FROM spfli WHERE (itab)OR cityfrom ='NEW YORK'
4.7.子查询
colum operator[ALL|ANY|SOME]、[NOT] EXISTS、[NOT] IN连接至WHERE从句与HAVING从句中
4.7.1.=、<>、<、<=、>、>=子查询
子查询的SELECT中只有一个表字段或者是一个统计列,并且只能返回一条数据
SELECT * FROM sflight INTO wa_sflight
WHERE seatsocc = ( SELECT MAX( seatsocc ) FROM sflight ).
ENDSELECT.
操作符可以是:=、<>、<、<=、>、>=
4.7.1.1.ALL、ANY、SOME
如果子查询返回的是多条,则使用ALL、ANY、SOME来修饰
SELECT customid COUNT( * ) FROM sbook INTO (id, cnt) GROUP BY customid
HAVING COUNT( * ) >= ALL ( SELECT COUNT( * ) FROM sbook GROUP BY customid ).
ENDSELECT.
² ALL:主查询数据大于所有子查询返回的行数据时,才为真
² ANY|SOME:主查询数据只要大于任何一条子查询返回的行数据时,才为真
² = ANY|SOME:等效IN子查询
4.7.2.[NOT] IN子查询
此类子查询SELECT中也只有单独的一列选择列,但查询出的结果可能有多条
SELECT SINGLE city latitude longitude INTO (city, lati, longi) FROM sgeocity
WHERE city IN ( SELECT cityfrom FROM spfli
WHERE carrid = carr_id AND connid = conn_id ).
4.7.3.[NOT] EXISTS子查询
这类子查询没有返回值,也不要求SELECT从句中只有一个选择列,选择列可以任意个数,WHERE 或者 HAVING从句根据该子查询的是否查询到数据来决定外层主查询语句来选择相应数据
SELECT carrname INTO TABLE name_tab FROM scarr
WHERE EXISTS ( SELECT * FROM spfli
WHERE carrid = scarr~carridAND cityfrom = 'NEW YORK' ).
4.7.4. 相关子查询
上面的示例子查询即为相关子查询
如果某个子查的WHERE条件中引用了外层查询语句的列,则称此子查询为相关子查询。相关子查询对外层查询结果集中的每条记录都会执行一次,所以尽量少用相关子查询
4.8.统计函数
MAX、MIN、AVG、SUM、COUNT,聚合函数都可以加上DISTINCT选项
4.9.分组过滤
如果将统计函数与GROUP BY子句一起使用,那么Select语句中未出现在统计函数的数据库字段都必须在GROUP BY子句中出现。如果使用INTO CORRESPONDING FIELDS项,则需要在Select语句中通过AS后面的别名将统计结果存放到与之相应同名的内表字段中:
SELECT MIN( price ) AS mINTO price FROM sflight GROUP BY carrid
HAVING MAX(price)>10. Having从句中比较统计结果时,需要将统计函数重写一遍,而不能使用Select中定义的别名
ENDSELECT.
4.10.游标
DATA: c TYPE cursor.[ˈkɜ:sə]
DATA: wa TYPE spfli.
"1、打开游标
OPEN CURSOR: c FOR SELECT carrid connid FROM spfli WHERE carrid = 'LH'.
DO.
"2、读取数据
FETCH NEXT CURSOR c INTO CORRESPONDING FIELDS OF wa.
IF sy-subrc <> 0.
"3、关闭游标
CLOSE CURSOR c.
EXIT.
ELSE.
WRITE: / wa-carrid, wa-connid.
ENDIF.
ENDDO.
4.11.三种缓存
l 单记录缓存:从数据库中仅读取一条数据并存储到table buffer 中。此缓存只对SELECT SINGLE…语句起作用
l 部分缓存:需要在指定generic key(即关键字段组合,根据哪些关键字段来缓存,可以是部分或全部关键字段)。如果主键是由一个字段构成,则不能选择此类型缓存。当你使用generic key进行数据访问时,则属于此条件范围的整片数据都会被加载到table buffer中
1、查询时如果使用BYPASSING BUFFER 选项,除了绕过缓存直接到数据库查询外,查出的数据不会放入缓存
2、只要查询条件中出现了用作缓存区域的所有关键字段,则查询出所有满足条件全部数据进行缓存
3、如果查询条件中generic key只出现某个或者某部分,则不会进行缓存操作
4、如果主键是只由一个字段组成,则不能设定为此种缓存
5、如果有MANDT字段,则为generic key的第一个字段

l 全部缓存:在第一次读取表数据时,会将整个表的数据都会缓存下来,不管WHERE条件
4.12.Native SQL
4.12.1.查询
DATA: BEGIN OF wa,
connid TYPE spfli-connid,
cityfrom TYPE spfli-cityfrom,
cityto TYPE spfli-cityto,
END OF wa.
DATA c1 TYPE spfli-carrid VALUE 'LH'.
"Native SQL语句不能以句点号结尾;
"不能在EXEC SQL…ENDEXEC间有注释,即不能有星号与双引号的出现;
"参数占位符使用冒号,而不是问号;
EXEC SQL PERFORMING loop_output.
SELECT connid, cityfrom, cityto
INTO :wa
"或使用:INTO :wa-connid ,:wa-cityfrom ,:wa-cityto
FROM spfli
WHERE carrid = :c1
ENDEXEC.
FORM loop_output.
WRITE: / wa-connid, wa-cityfrom, wa-cityto.
ENDFORM
4.12.2.存储过程
EXEC SQL.
EXECUTE PROCEDURE proc1 ( IN:x,OUT:y,INOUT:z )
ENDEXEC.
4.12.3.游标
DATA: arg1 TYPE string VALUE '800'.
TABLES: t001.
EXEC SQL.
OPEN c1 FOR SELECT MANDT, BUKRS FROM T001 "打开游标
WHERE MANDT = :arg1 AND BUKRS >= 'ZA01'
ENDEXEC.
DO.
EXEC SQL.
FETCH NEXT c1 INTO :t001-mandt, :t001-bukrs "读取游标
ENDEXEC.
IF sy-subrc <> 0.
EXIT.
ELSE.
WRITE: / t001-mandt, t001-bukrs.
ENDIF.
ENDDO.
EXEC SQL.
CLOSE c1 "关闭游标
ENDEXEC.
4.13.SAP锁
通用数据库表锁函数:ENQUEUE_E_TABLE、DEQUEUE_E_TABLE、DEQUEUE_ALL(解锁所有)[kju:]
特定数据库表锁函数:ENQUEUE_<LOCK OBJECT>、DENQUEUE_<LOCK OBJECT>
自定义的锁对象都必须以EZ_ 或者EY_ 开头来命名
|
| 允许第二次加锁模式 | ||
| 第一次加锁模式 | S | E | X |
| S 共享锁 | 是(是) | 否(是) | 否(否) |
| E 可重入的排他锁 | 否(是) | 否(是) | 否(否) |
| X 排他锁 | 否(否) | 否(否) | 否(否) |
括号内为同一程序(即同一事务内)内,括号外为非同一程序内
CALL FUNCTION 'ENQUEUE_EZ_ZSPFLI'"加锁
EXPORTING
mode_zspfli = 'E'
mandt = sy-mandt
carrid = 'AA'
connid = '0011'
* X_CARRID = ' '"设置字段初始值(Initial Value),若为X,则当遇到与CARRID的初始值Initial Value相同值时才会设置锁对象。CARRID的初始值只需在数据库表字段中选择Initial Value选项(SE11中设置)。当没有设置X时,则会用该锁函数所设置的Default Value指定初始值
* X_CONNID = ' '
* _SCOPE = '2'"该选项只有在UPDATE函数(CALL FUNCTION FM IN UPDATE TASK)中才起作用,用来控制锁的传递。一般当调用解锁函数DEQUEUE或程序结束时(LEAVE PROGRAM或者LEAVE TO TRANSACTION)锁就会被自动解除,另外,遇到A、X消息时或用户在命令框中输入/n 时锁也会被解除,但是,当事务码正在执行UPDATE函数时就不一样了,函数结束时是否自动解除锁则要看该选项 _SCOPE 了:
1-表示程序内有效 2-表示update module 内有效 3-全部
* _WAIT = ' '"表示如果对象已经被锁定,是否等待后再尝试加锁
* _COLLECT = ' '"参数表示是否收集后进行统一提交
程序锁定:ENQUEUE_ES_PROG和DEQUEUE_ES_PROG
5.SAP/DB LUW
5.1.DB LUW
DB LUW(Logic Unit Work)是确保数据库更新一致性的机制,是数据库级别的,和底层DBMS有关,和SAP系统无关。如下图,从一致性状态A到B,中间有一系列的数据库操作,一个BD luw以数据库提交commit结束,这些操作要么全都执行,要么全都不执行。当全部执行成功,则数据库进入一致性状态B,如果在此DB luw中发生错误,则将从DB luw开始的所有操作进行回滚,数据库还是在A状态。
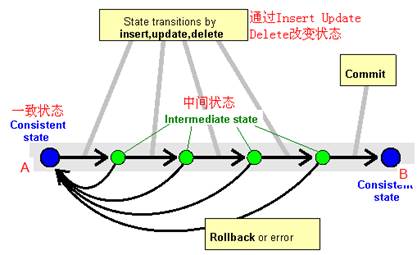
这是在数据库级别实现的,和SAP系统无关。
在SAP系统中,DB luw commit and rollback 可以被显式或隐式的触发。
不管是commit还是rollback,结束了一个DB luw,也即是开始了一个新的DB luw。
5.1.1.显式提交
·Native SQL提交语句
·Calling the function module DB_COMMIT.
·COMMIT WORK语句
5.1.2.隐式提交
·对话屏幕结束时(跳转另一屏幕)
CALL FUNCTION func DESTINATION dest
CALL FUNCTION func STARTING NEW TASK DESTINATION dest taskname
但RFC事务调用不会触发隐式提交:CALL FUNCTION func IN BACKGROUND TASK DESTINATION dest
·取RFC异步执行结果回调Form中RECEIVE 语句:CALL FUNCTION rfm_name STARTING NEW TASK DESTINATION dest tasknamePERFORMING return_form ON END OF TASK中的RECEIVE RESULTS FROM FUNCTION rfm_name语句会触发
·WAIT UNTIL log_exp [UP TO sec SECONDS]语句
·Sending error messages(E), information messages(I), and warnings(W).
5.1.3. 显示回滚
·使用Native-SQL进行回滚
·使用ROLLBACK WORK.进行回滚
5.1.4. 隐式回滚
·runtime error:在程序执行过程中未捕获的异常以及message type X的消息,因为runtime error会导致程序的termination
·因为发送的Message而导致程序的termination(除了A、X类型的消息会导致程序终止外,其他类型的消息在特定的情况下也会导致程序终止,具体请参见《User Dialogs.docx》中的消息显示及处理章节)
Runtime Error:系统不能继续运行,并且ABAP程序终止,以下情况会发生运行时错误:
²未处理的异常(当一个能够被处理的异常却未被处理时;抛出了一个不能够处理的异常)
²X类型消息
² ASSERT断言语句不成立时
5.2.SAP LUW
sap系统中一个业务操作会有多个对话屏幕,只到save操作成功,才算完成了一个业务。那么仅使用DB luw是不能保证SAP 系统数据一致性的。如下图,如果只是最后屏幕300保存时的DB luw发生错误,那么在数据库级一致性机制作用下只能回滚这一个db luw使数据库处于g状态,而前几个db luw在屏幕结束时已经提交,进行的数据库更新会全部生效,从业务层面上讲,这是不合理的,因为这个业务并没有保存成功,我们需要回滚到A或a状态。SAP luw就是sap在DB luw基础上保证数据库一致性的一种机制。
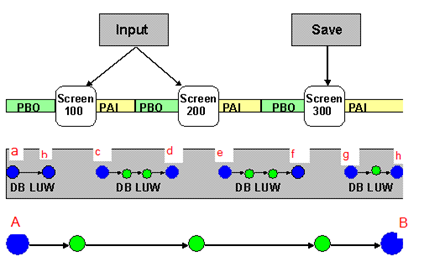
上图(未使用SAP LUW),绿色表示数据库更新操作。每个dialog steps都会形成一个单独的DB LUW。默认情况下(未通过SAP LUW的绑定方式来实现延迟执行数据库更新操作),每个DB LUW都会提交事务
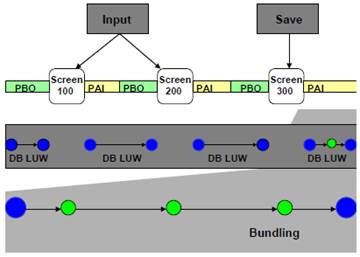
上图(将多个DB LUW绑定成一个SAP LUW),将每个dialog steps(即DB LUW)中的数据库操作“移”到最后一个dialog steps(即DB LUW)中执行,这里的“移”实质上是一种延迟执行的方式,即先将前面每个dialog steps中的数据库更新操作记录下来,待最后统一由COMMIT来提交。
SAP LUW可以跨多个DB LUW,是一个业务逻辑上的概念,可人为的去定义开始与结束,而DB LUW是不能人为控制的
SAP LUW是DB LUW的一个增强,受体系结构限制,SAP程序每次屏幕切换时(控制权从后台DIALOG进程转移到前台GUI的Session),都会触发一个隐式的数据库提交,一个程序在运行是会产生多个DB 的LUW,这样无法做到全部提交或全部回滚,在某些业务场景下,这种事务的提交机制不足以保证数据的一致性,为此有了SAP LUW机制。
SAP LUW是一种延迟执行的技术,它将本来需要执行的程序块,记录下来(通过特定的方式来调用来实现SAP LUW的绑定:perform XXX on commit、update Funciton module),待系统在执行COMMIT WORK的时候会查询记录,真正执行需要运行的代码。COMMIT WORK一般在最后一个屏幕执行,这样就实现了将跨屏幕的数据更新逻辑绑定到一个DBLUW中(在后台会自动将这一系列的数据操作绑定在同一个数据事务DBLUW里,这样当提交出问题后,数据库事务DBLUW会自动回滚,这样就保证了数据的一致性),实现复杂情况数据更新的一致性
5.2.1.SAP LUW的绑定方式
5.2.1.1.Function
可以使用CALL FUNCTION update_function IN UPDATE TASK将多个数据更新绑定到一个database LUW中
此类型的更新函数Update Function中主要实现对数据库数据进行更新操作
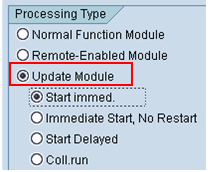
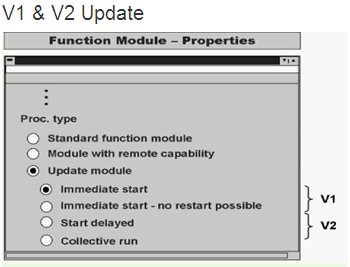
² Immediate start:表示V1方式,将此更新函数设置为高优先级V1并运行在同一个SAP LUW中。更新出错后,可以在SM13里重新执行
² Immediate start -no restrat possible:V1方式,将此更新函数设置为高优先级V1并运行在同一个SAP LUW中。出错后不可以在SM13里重新执行
² Start delayed:V2方式,将此更新函数设置为低优先级V2并run in their own update transactions。V1方式更新完成后触发。出错后更新函数可以重启
² Collective run:V2方式,将此更新函数设置为低优先级V2并run in their own update transactions。需使用Collective(RSM13005)程序手动或JOB方式执行
V1与V2区别:
² V1优先级高于V2,V2被设计为依赖于V1,适合执行需要在V1完成后进行的操作
² V1更新使用V1进程处理,V1进程名字一般为UPD,V1进程绑定独立的数据库进程。在V1进程中调度的更新函数如果更新失败,回滚,不再进行V2操作。成功则提交更改到数据库,同时删除所有的SAP锁
² V2更新使用V2进程处理,如果没有配置V2进程则共用V1进程,V2进程名字为UP2,V2更新在独立DB LUW中,V2更新回滚后不会影响到V1更新提交的数据,由于V1更新结束后会删除SAP的锁,所以V2更新是在没有逻辑锁的情况下进行的,V2更新出错后可以在SM13中重新执行
² V1 的执行模式可以为异步、同步或本地;V2只能为异步执行
CALL FUNCTION ... IN UPDATE TASK的Function并不会立即执行,这只是先将它记录到内存(本地方式)或数据库表中(非本地方式),等到COMMIT WORK语句执行时才真正执行。如果在程序执行过程中,没有在Update Function 后面执行COMMIT WORK,则function module不会执行
此种类型的输入参数只能是值传递方式,不允许为引用传递,所以输入参数对应的“传递值”要钩上,并且传递的内容还不能是地址,即不允许为TYP EREF TO方式,只能是TYPE方式
5.2.1.2.subroutine
PERFORM subr ON { {COMMIT [LEVEL idx]} | ROLLBACK }.
子过程subr不会被马上执行,而是直到COMMIT WORK 或者是ROLLBACK WORK。可以使用LEVEL参数指定优先级,优先级按升序进行排列,较小的会优先执行。如果同样名字的subroutine被注册了多次,在COMMIT WORK时只执行一次,IN UPDATE TASK方式执行的Funciton没有这个限制
由于子过程绑定不需要写数据库表,所以比较更新函数绑定,性能上要高一些,缺点是你不能传递任何参数,它们所使用的必须是global data object,或可通过ABAP memory来共享参数
5.2.2.开启新的SAP LUW
没有专门类似开启数据库事务的语句(Begin trasaction),SAP LUW会在以下情况自动开启:
²提交COMMIT或回滚ROLLBACK后会开启另一个新的SAP LUW事务
²事务调用会重新开启一个新的SAP LUW
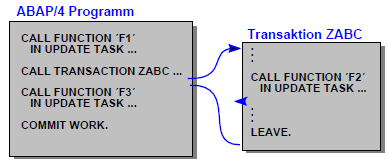
上图中F2不会被执行,因为它处于另一个事务中执行,但没有使用COMMIT WORK,而F1、F3会被执行,因为主调程序中使用了COMMIT WORK。所以事务调用会重新开启一个新的SAP LUW。
dialog modules与上面调用事务(CALL transaction)、调用executable programs (reports)不同的是:dialog modules中不会开启新的SAP LUW,如果dialog modules中调用了update function modules(CALL FUNCTION ... IN UPDATE TASK),则要等到主调程序中的COMMIT WORK时才会真正执行,哪怕在dialog modules中调用了COMMIT WORK也是没有用(不会启动update task)。
另外,由于数据共享问题,尽量不要在dialog modules中使用PERFORM XXX ON COMMIT。
5.2.3. 同步或异步更新(提交)
COMMIT WORK 异步更新,该语句执行后不会等待所有更新函数都执行完后才继续执行后面的代码
COMMIT WORK AND WAIT同步更新,该语句执行后会等待所有更新函数都执行完后才继续执行后面的代码,执行结果可以通过sy-subrc来判断事务提交是否成功
5.2.4.本地、非本地方式提交
本地方式:如果在调用UPDATE FUNCTION之前,先调用SET UPDATE TASK LOCAL.语句,这样所有在该语句后使用CALL FUNCTION...IN UPDATE TASK注册的更新函数不会记录到数据库中,而是记录在内存中,在Commit work之后,会从内存取得待执行的函数。在默认情况下,local update不会被设置,在使用COMMIT WORK之后 SET UPDATE TASK LOCAL的效果会被清除掉
本地方式更新只能采用同步方式,即使没有在Commit work后指定了and wait参数,仍然是同步执行
非本地方式:未使用SET UPDATE TASK LOCAL.语句。此方式下,注册的Update Function的名字以及接口实参都会以日志的形式记录到特殊的表。非本地方式即可同步也可异步COMMIT
² 本地方式不将待执行的更新函数写到数据表中,减少了I/O操作,效率上较高,但由于采用的是同步方式,程序需等待更新结果,用户交互时的会感觉程序运行较慢
² 非本地方式会将更新结果记录到数据表中,可以通过SM13查看更新情况,同时由于可以进行异步更新,用户交互时感觉会比较快
6. 逻辑数据库
6.1.组成
SLDB
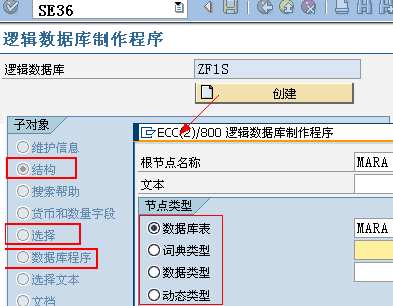
6.2. 结构
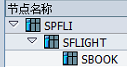
决定了数据从哪些数据库表、视图中提取数据,以及这些表、视图之间的层次关系(层次将决定数据读取的顺序)
数据库表(T类型节点)、词典类型(S类型节点),比如节点类型为S的节点:root_node,数据类型为INT4:
![]()
LDB的数据库程序的最TOP Include文件包括以下语句:
NODES root_node.
另外,在LDB数据库程序包括了以下过程:
FORM put_root_node.
DO 10 TIMES.
root_node = sy-index.
PUT root_node."会去调用报表程序中的 GET root_node. 事件块
ENDDO.
ENDFORM.
在与此LDB关连的可执行程序:
![]()
REPORT demo_nodes.
NODES root_node.
GET root_node.
WRITE root_node.
6.3.选择屏幕(Selections)
定义了LDB的选择屏幕,该选择屏幕的布局由LDB的结构决定,一旦将LDB链接到报表程序后,该选择屏幕会自动嵌入到默认选择屏幕1000中
第一次进入选择屏幕程序时,系统会为每个LDB生成一个名为DB<LDB_Name>SELInclude选择屏幕包含文件:


而且,所有表(T类型的节点)的主键都会出现在SELECT-OPTIONS语句中,成为屏幕选择字段(自动生成的需要去掉注释,并设置屏幕选择字段名):
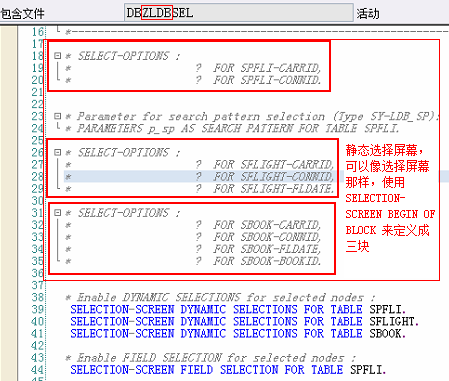
除了上面自动生成的LDB屏幕字段外,还可以使用以下面语句来扩展LDB选择屏幕:
6.3.1.PARAMETERS屏幕参数扩充
增加一个单值输入条件框(PARAMETERS语句一般在LDB中只用于除节点表外的非表字段屏幕参数),在PARAMETERS语句中必须使用选项FOR NODE XXX 或者 FOR TABLE XXX 来指定这些扩展参数属性哪个节点的:PARAMETERS CITYTO LIKE SPFLI-CITYTO FOR NODE SPFLI.
注:SELECT-OPTIONS没有FOR NODE这样的用法
具体请参数后面的LDB选择屏幕章节
6.3.2.SELECTION-SCREEN格式化屏幕
使用SELECTION-SCREEN语句来格式化屏幕
具体请参数后面的LDB选择屏幕章节
6.3.3.DYNAMIC SELECTIONS动态选择条件
SELECTION-SCREEN DYNAMIC SELECTIONS FOR NODE|TABLE <node>.用来开启<node>节点的LDB dynamic selections功能,即可以在WHERE从句中使用动态选择条件(形如:…WHERE field1 = value1 AND (条件内表) …只有开启了动态选择条件功能的表,才可以在LDB数据库程序中对表进行动态选择条件处理。下面是数据库程序中如何使用动态选择条件示例:

上面LDB数据库程序中的RSDS_WHERE条件内表来自RSDS类型组,相应源码如下:

另外,上面LDB数据库程序中要能从DYN_SEL-CLAUSES内表读取数据,则必须在LDB选择屏幕里开启相应节点的动态选择条件:
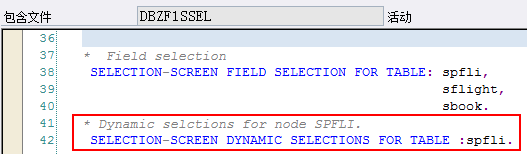
其中,DYN_SEL-CLAUSES内表行结构如下:

6.3.3.1.DYN_SEL
PUT_<node> Form中的SELECT语句中Where从句如果要使用 DYNAMIC SELECTIONS 动态选择条件时,需要用到变量DYN_SEL,该数据对象是在LDB数据库程序中自动生成的,其类型如下(注:不必在LDB程序中加入下面代码行就可以直接使用DYN_SEL):
TYPE-POOLS RSDS.
DATA DYN_SEL TYPE RSDS_TYPE.
你不必在程序中定义它就可以直接使用,但它只能在LDB数据库程序中使用,而不能用在报表程序中。RSDS_TYPE数据类型是在类型组RSDS中定义的:
TYPE-POOL RSDS .
TYPES: RSDS_WHERE_TAB LIKE RSDSWHERE OCCURS 5."RSDSWHERE 类型为C(72)
TYPES: BEGIN OF RSDS_WHERE,
TABLENAME LIKE RSDSTABS-PRIM_TAB,
WHERE_TAB TYPE RSDS_WHERE_TAB,
END OF RSDS_WHERE.
TYPES: RSDS_TWHERE TYPE RSDS_WHERE OCCURS 5.
TYPES: BEGIN OF RSDS_TYPE,
CLAUSES TYPE RSDS_TWHERE,
TEXPR TYPE RSDS_TEXPR,
TRANGE TYPE RSDS_TRANGE,
END OF RSDS_TYPE.
RSDS_TYPE是一个深层结构的结构体,里面三个字段都是内表类型,其中以下两个字段重要:
6.3.3.1.1.RSDS_TYPE-CLAUSES
为Where从句部分,实则存储了可直接用在WHERE从句中的动态Where条件内表,可以在Where动态语句中直接使用,该组件为内表,存储了用户在选择屏幕上选择的LDB动态选择字段
每个被选择的LDB屏幕动态选择字段都会形成一个条件,并存储到RSDS_TYPE-CLAUSES-WHERE_TAB内表中,WHERE_TAB内表中存储的就是直接可以用在Where从句中的动态选择条件中
每个表(节点)都会有自己的CLAUSES-WHERE_TAB动态条件内表,这是通过CLAUSES-TABLENAME区别的
现假设有名为 ZHK 的LDB,SCARR为该LDB的根节点,且仅有SPFLI一个子节点。LDB选择屏幕 Include文件DBZHKSEL内容如下:
SELECT-OPTIONS S_CARRID FOR SCARR-CARRID.
SELECT-OPTIONS S_CONNID FOR SPFLI-CONNID.
"需要先开始动态选择条件功能
SELECTION-SCREEN DYNAMIC SELECTIONS FOR TABLE SCARR.
LDB数据库程序SAPDBZHK中,PUT_SCARR过程中使用dynamic selection的过程如下:
FORM PUT_SCARR.
STATICS: DYNAMIC_SELECTIONS TYPE RSDS_WHERE,FLAG_READ. "定义成静态类型的是防止再次进入此Form时,再次初始化DYNAMIC_SELECTIONS结构,即只执行一次初始化代码
IF FLAG_READ = SPACE.
DYNAMIC_SELECTIONS-TABLENAME = 'SCARR'.
READ TABLE DYN_SEL-CLAUSES WITH KEY DYNAMIC_SELECTIONS-TABLENAME INTO DYNAMIC_SELECTIONS.
FLAG_READ = 'X'.
ENDIF.
SELECT * FROM SCARR WHERE CARRID IN S_CARRID AND (DYNAMIC_SELECTIONS-WHERE_TAB). "使用动态Where条件
PUT SCARR.
ENDSELECT.
ENDFORM.
6.3.3.1.2.RSDS_TYPE-TRANGE
该字段是一个内表,存储了CLAUSES的原数据,CLAUSES内表里的数据实质就是来源于TRANGE内表,只是CLAUSES已经将每个表字段的条件拼接成了一个或多个条件串了(形如:“XXX字段 = XXX条件”),但是TRANGE内表与RANGES tables相同,存储的是字段最原始的条件值,使用时,在WHERE从句中使用 IN 关键字来使用这些条件值(这与SELECT-OPTIONS类型的屏幕参数用户是完全一样的)。
但是,使用TRANGE没有直接使用CLAUSES灵活,因为使用TRANGE时,WHERE从句里的条件表字段需要事先写好,这实质上不是动态条件了,可以参考以下实例,与上面CLAUSES用法相比就更清楚了:现修改上面的示例:
SELECT-OPTIONS S_CARRID FOR SCARR-CARRID.
SELECT-OPTIONS S_CONNID FOR SPFLI-CONNID.
"需要先开始动态选择条件功能
SELECTION-SCREEN DYNAMIC SELECTIONS FOR TABLE SCARR.
LDB数据库程序SAPDBZHK中,PUT_SCARR过程中使用dynamic selection的过程如下:
FORM PUT_SCARR.
STATICS: DYNAMIC_RANGES TYPE RSDS_RANGE, "存储某个表的所有屏幕字段的Ranges
DYNAMIC_RANGE1 TYPE RSDS_FRANGE,"存储某个屏幕字段的Ranges
DYNAMIC_RANGE2 TYPE RSDS_FRANGE,
FLAG_READ."确保DYN_SEL只读取一次
IF FLAG_READ = SPACE.
DYNAMIC_RANGES-TABLENAME = 'SCARR'.
"先取出 SCARR 表的所有屏幕字段的Ranges
READ TABLE DYN_SEL-TRANGE WITH KEY DYNAMIC_RANGES-TABLENAME INTO DYNAMIC_RANGES.
"再读取出属于某个字段的Ranges
DYNAMIC_RANGE1-FIELDNAME = 'CARRNAME'.
READ TABLE DYNAMIC_RANGES-FRANGE_T WITH KEY DYNAMIC_RANGE1-FIELDNAME
INTO DYNAMIC_RANGE1.
DYNAMIC_RANGE2-FIELDNAME = 'CURRCODE'.
READ TABLE DYNAMIC_RANGES-FRANGE_T WITH KEY DYNAMIC_RANGE2-FIELDNAME
INTO DYNAMIC_RANGE2.
FLAG_READ = 'X'.
ENDIF.
SELECT * FROM SCARR
WHERE CARRID IN S_CARRID
AND CARRNAME IN DYNAMIC_RANGE1-SELOPT_T"使用IN 关键字使用Ranges内表
AND CURRCODE IN DYNAMIC_RANGE2-SELOPT_T."(与select-options屏幕参数是一样的用法)
PUT SCARR.
ENDSELECT.
ENDFORM.
6.3.4.FIELD SELECTION动态选择字段
SELECTION-SCREEN FIELD SELECTION FOR NODE|TABLE <node>.语句的作用是开启节点<node>的动态字段选择的功能(形如:SELECT (选择字段内表) FROM…,而不是SELECT * FROM …,即选择了哪些字段,就只查询哪些字段,而不是将所有字段查询出来,进而可以提高性能)。
在可执行报表程序里,可以通过GET node [FIELDS f1 f2 ...] 语句中的 FIELDS选项来指定要读取字段;
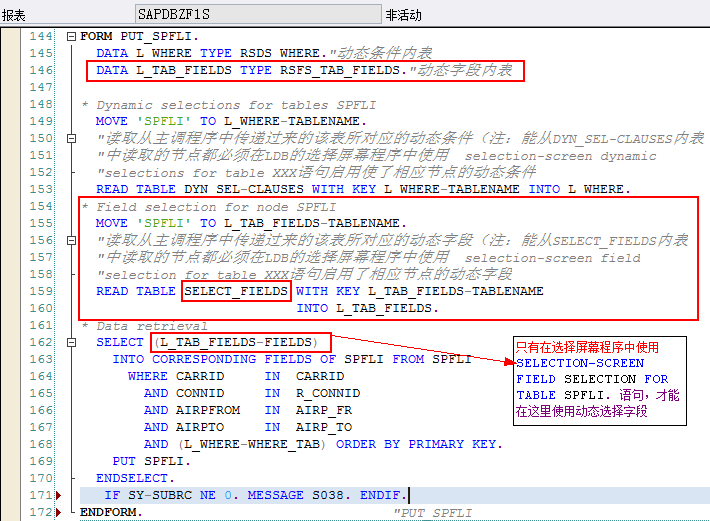
另外,上面LDB数据库程序中要能从SELECT_FIELDS内表读取数据,则必须在LDB选择屏幕里开启相应节点的动态选择字段:
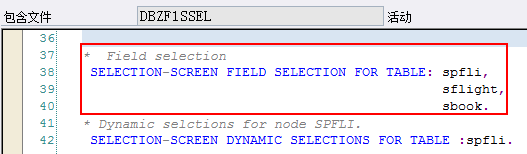
其中,SELECT_FIELDS内表行结构如下:
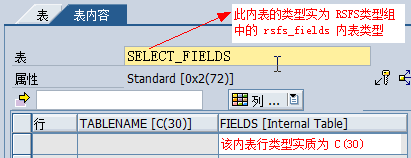
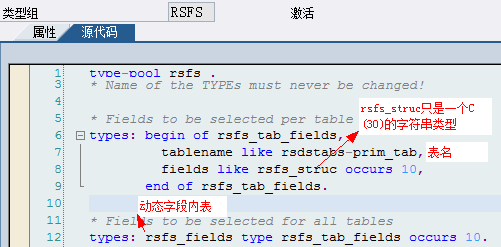
6.3.4.1.SELECT_FIELDS
PUT_<node> Form中的SELECT语句中Where从句如果要使用 FIELD SELECTION 动态选择字段时,需要用到数据对象SELECT_FIELDS,在LDB数据库程序中,通过从SELECT_FIELDS内表中就可以读取GET node [FIELDS f1 f2 ...] 语句传递进来的选择字段,SELECT_FIELDS是LDB数据库程序自动生成的,其类型如下(不必在LDB程序中加入下面代码行,直接就可以使用SELECT_FIELDS内表,另外在相连的报表程序中也可以使用,这与DYN_SEL不同):
TYPE-POOLS RSFS.
DATA SELECT_FIELDS TYPE RSFS_FIELDS.
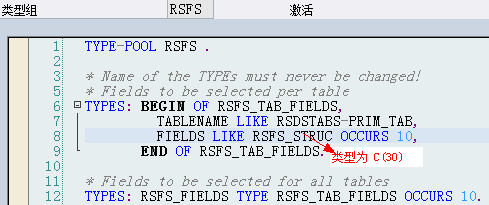
RSDS_FIELDS中的FIELDS里存储的就是GET…FIELDS…语句传递过来的用户指定的查询字段,FIELDS内表可以直接使用在 SELECT…从句中。
现假设有名为 ZHK 的LDB,SCARR为该LDB的根节点,且仅有SPFLI一个子节点。LDB选择屏幕 Include文件 DBZHKSEL内容如下:
SELECT-OPTIONS S_CARRID FOR SCARR-CARRID.
SELECT-OPTIONS S_CONNID FOR SPFLI-CONNID.
"需要先开始动态选择字段功能
SELECTION-SCREEN FIELD SELECTION FOR TABLE SPFLI.
LDB数据库程序SAPDBZHK中,PUT_SCARR过程中使用dynamic selection的过程如下:
FORM PUT_SPFLI.
STATICS: FIELDLISTS TYPE RSFS_TAB_FIELDS,
FLAG_READ."确保SELECT_FIELDS只读取一次
IF FLAG_READ = SPACE.
FIELDLISTS-TABLENAME = 'SPFLI'.
"读取相应表的动态选择字段
READ TABLE SELECT_FIELDS WITH KEY FIELDLISTS-TABLENAME INTO FIELDLISTS.
FLAG_READ = 'X'.
ENDIF.
SELECT (FIELDLISTS-FIELDS)"动态选择字段
INTO CORRESPONDING FIELDS OF SPFLI FROM SPFLI
WHERE CARRID = SCARR-CARRID AND CONNID IN S_CONNID.
PUT SPFLI.
ENDSELECT.
ENDFORM.
在相应的可执行报表程序里,相应的代码可能会是这样的:
TABLES SPFLI.
GET SPFLI FIELDS CITYFROM CITYTO.
...
GET语句中的FIELDS选项指定了除主键外需要查询来的字段,主键不管是否选择都会被从数据库表中读取出来,可以由下面报表程序中的代码来证明:
DATA: ITAB LIKE SELECT_FIELDS,
ITAB_L LIKE LINE OF ITAB,
JTAB LIKE ITAB_L-FIELDS,
JTAB_L LIKE LINE OF JTAB.
START-OF-SELECTION.
ITAB = SELECT_FIELDS. "在报表程序中也可以直接使用LDB程序中的全局变量!
LOOP AT ITAB INTO ITAB_L.
IF ITAB_L-TABLENAME = 'SPFLI'.
JTAB = ITAB_L-FIELDS.
LOOP AT JTAB INTO JTAB_L.
WRITE / JTAB_L.
ENDLOOP.
ENDIF.
ENDLOOP.
如果报表程序中的GET语句是这样的:GET SPFLI FIELDS CITYFROM CITYTO.,则输入结果为:
CITYTO
CITYFROM
MANDT
CARRID
CONNID
可以从输出结果看出,主键MANDT、CARRID、CONNID会自动的加入到SELECT_FIELDS内表中,一并会从数据库中读取出来
6.4.数据库程序中重要FORM
• FORM INIT
在选择屏幕处理前仅调用一次(在PBO之前调用)
• FORM PBO
在选择屏幕每次显示之前调用,即LDB选择屏幕的PBO事件块
• FORM PAI
用户在选择屏幕上输入之后调用,即LDB选择屏幕的PAI事件块(之后?)。
该FORM带两个接口参数FNAME and MARK将会传到subroutine 中。FNAME存储了选择屏幕中用户所选择SELECT-OPTION与PARAMETERS的屏幕字段名,MARK标示了用户选择的是单值还是多值条件:MARK = SPACE意味着用户输入了一个简单单值或者范围取值,MARK = '*'意味着用户在Multiple Selection screen 的输入(即多个条件值);FNAME = '*' 和 MARK = 'ANY',表示所有的屏幕参数都已检验完成,即可以对屏幕整体参数做一个整体的检测了(这里的意思应该就是相当于AT SELECTION-SCREEN)。
• FORM PUT_<node>
最顶层节点<node>所对应的FORM PUT_<node>会在START-OF-SELECTION事件结束后自动被调用,而其他下层节点所对应的FORM会由它的上层节点所对应的FORM中的PUT <node>语句来触发(在上层节点所对应的可执行程序中的相应GET事件块执行之后触发)
PUT <node>.
此语句用是PUT_<node>子过程中的特定语句,它是与PUT_<node> Form一起使用的,通常是放在循环处理数据循环过程中。PUT语句根据LDB的结构指引了报表程序的逻辑。该语句会触发相应的报表程序的GET <node>事件。当GET事件块执行完后,如果有下层节点,则还会调用下层节点所对应的FORM PUT_<node>。
PUT语句是该Form(PUT_<node>)中最主要的语句:此语句仅仅只能在LDB数据库程序的Form中使用。
当PUT_<node>调用结束后,报表程序中相应GET <node> LATE事件块也会自动调用。
首先,根节点所对应的PUT_<root>会自动执行,此Form中的PUT <node>会以下面的先后顺序来执行程序:
1. 如果LDB数据库程序包含了AUTHORITY_CHECK_<table>语句,则PUT语句的第一件事就是调用它
2. 然后,PUT语句会触发报表程序相应的GET事件
3. 再后,PUT语句会去调用LDB程序中下一节点的PUT_<node>子过程(此过程又会按照这里的三步来运行),直到下层所有子孙节点PUT_<node>过程处理完成(深度遍历),才会回到最上一层节点的PUT语句
4. 当控制权从下层节点的PUT_<node>返回时,PUT语句还会触发当前节点的GET <node> LATE报表事件

GET事件块会在LDB程序从数据库表中读取到一行数据时被触发。
6.5. LDB选择屏幕:静(动)态选择屏幕、动态选择视图

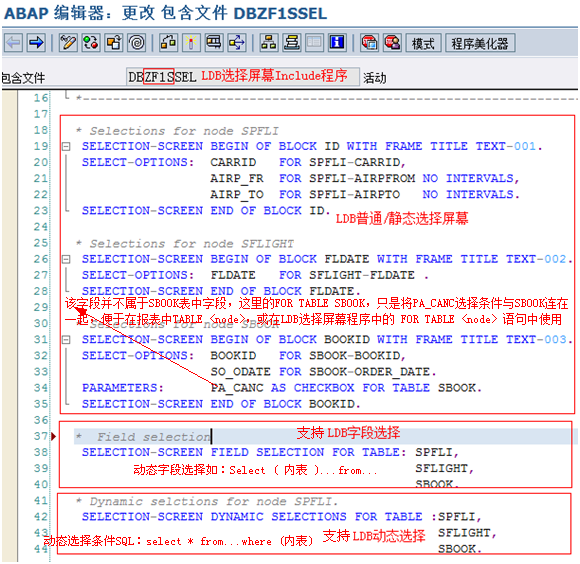
在报表选择屏幕上是否显示LDB的普通选择条件(即静态的,与动态选择条件相对应),则要看报表程序中是否使用了对应的 TABLE <node>语句,如果有,则与<node>节点相关的所有LDB选择条件都会显示在报表程序的选择屏幕上,如果没有此语句,则与<node>节点相关的所有LDB选择条件都会不会显示(但如果某个节点没有在TABLE语句中进行定义,但其子节点,或子孙节点在TABLE语句中进行了定义,则这些子孙节点所对应的父节点所对应LDB屏幕选择条件还是会嵌入到报表选择屏幕中)。有几种情况:
则报表程序的选择屏幕只会将spfli节点相关的普通选择条件内嵌进来,子孙节点不会显示出来:

l 如果报表程序只有子孙节点定义语句:
则报表程序的选择屏幕中,会将sbook的父节点SFLIGHT以及爷节点SPFLI相关的LDB静态选择内嵌进来:

如果LDB的选择屏幕在没有创建选择视图的情况下:动态选择是否显示在报表程序的选择屏幕中,首先要看报表程序中是否使用了 TABLE <node>对需要动态显示的节点进行了定义(如果这个节点是上层节点,则此节点为本身也可以不在TABLE语句定义,而是对其子孙节点进行定义也是可以的),再者,还需要相应的<node>节点在LDB屏幕选择Include程序中的SELECTION-SCREEN DYNAMIC SELECTIONS FOR TABLE <node>语句中进行定义,注:要显示,则对应节点一定要在此语句中定义过,而不是像报表程序中的节点只对其子孙节点进行定义即可,而是谁需要动态显示,则谁就得要在动态定义语句中进行定义,如下面在LDB选择屏幕Include程序中只对SBOOK的上层节点SPFLI,SFLIGHT进行了定义,并没有对SBOOK进行定义:

而在报表程序中只能SBOOK进行了定义:
但最后在报表动态选择屏幕中,只有SPFLI,SFLIGHT两个表的条件(需使用SELECTION-SCREEN DYNAMIC SELECTIONS语句对SPFLI,SFLIGHT节点进行定义),而SBOOK并没有:

在没有创建选择视图的情况下,以表名来建小分类,且动态条件字段为整个表的所有字段
如果LDB的选择屏幕在有选择视图的情况下:只要存在选择视图,则只显示选择视图里被选择的字段,其他任何字段一概不显示。下面只将SPFLI-CARRID与SFLIGHT-CONNID两个字段已分别纳入到了01与02分组中,而SBOOK节点中没有字段纳入:
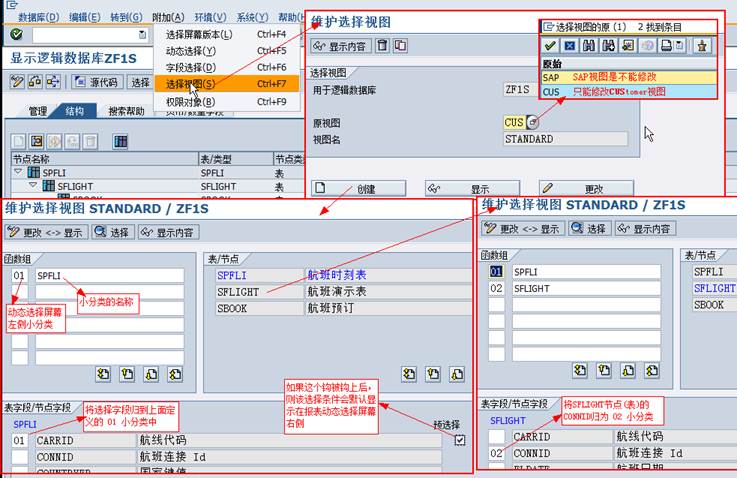
![]()
报表程序里将SBOOK节点定义在了TABLES语句中,所以,从SBOOK这一级开始(包括)向上所有节点的所对应的字段,如果纳入了选择视图中,则选择屏幕显示如下:
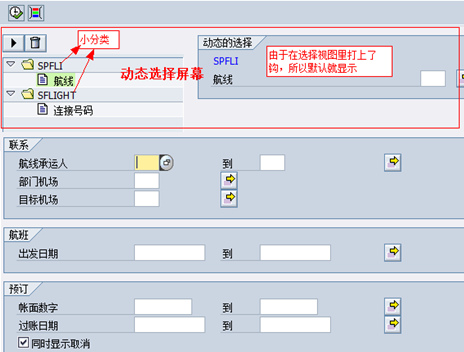
7. ALV
7.1.Layout重要字段
zebra(1) type c, " striped pattern斑马线显示,颜色隔行交替显示
edit(1) type c, " for grid only ALV是否可编辑,注意只对Grid模式有效,对List模式无效
f2code like sy-ucomm, "gs_layout-f2code='&ETA'.双击时触发的Funcode,这里为弹出详情窗口
colwidth_optimize(1) type c, ALV网格(单元格)宽度设置为自动最优化,按输出内容宽度自动调整[ˈɔptəˌmaɪz]
lights_fieldname type slis_fieldname," fieldname for exception列显示为红绿灯
box_fieldname type slis_fieldname, " fieldname for checkbox指定数据内表中哪列以选择按钮形式显示(首列前可按下或弹上来的按钮),ALV最左上角会出现全选按钮![]()
key_hotspot(1) type c, " keys as hotspot " K_KEYHOT设置关键字段是否是热点,可单击
info_fieldname type slis_fieldname, " infofield for listoutput指定数据输出内表中哪列存储的是颜色,用来设置ALV每行数据的颜色。注:使用属性需要同时在数据内表中定义一个与该参数所定义字段名相同的栏位,如:LAYOUT-INFO_FIELDNAME=’COLOR’,假设数据内表名为LT_OUT,则需要在该内表增加一个栏位“COLOR”,颜色范围 C000~C999
coltab_fieldname type slis_fieldname, "colors 指单元格式颜色,每行的单元格颜色就需一个单独的内表
7.2.FIELDCATALOG重要字段
[ˈkætəlɔɡ]
key(1) type c, " column with key-color指定字段是否是关键字段,如果是则单元格显示的颜色会不同,并会靠前显示
col_pos like sy-cucol, " position of the column列的输出位置字段在表中第几列
fieldname type slis_fieldname,"针对输出内表哪列进行设置,只有设置了的列才会显示,如果没有设置,则不会显示在ALV中。如果此字段是CURR金额(currency field) ,QUAN数量(Quantity field) 需要指定所参照的CUKY货币单位、UNIT字段名,需设置Cfieldname Ctabname 和Qfieldname Qtabname
cfieldname type slis_fieldname, "field with currency unit金额字段所参照的货币单位字段名
ctabname type slis_tabname, " and table
qfieldname type slis_fieldname, " field with quantity unit数量字段所参照的数量单位字段名
qtabname type slis_tabname, " and table
just(1) type c, " (R)ight (L)eft (C)ent.单元格中内容显示时对齐方式。不设置时按钮数据类型默认对齐方式来对齐
lzero(1) type c, " leading zero 为X时输出前导零
no_sign(1) type c, " write no-sign 不显示数字符号
no_zero(1) type c, " write no-zero 只输出有意义的值,空值不输出。为X时全为零(如:00000)时不输出,所以不输出零时应该最好同时设置lzero = sapce与no_zero = X,相反如果要输出,则应同时设置lzero = X 与no_zero = space
fix_column(1) type c, " Spalte fixieren列固定不滚动,与Key属性相似,但颜色不会发生变化
do_sum(1) type c, " sum up该列是否进行小计,需与gt_sort-subtot一起使用(即需要参考排序),否则只对整列进行一个合计
seltext_l like dd03p-scrtext_l, " long key word标题字段显示的名称(长)
seltext_m like dd03p-scrtext_m, " middle key word标题字段显示的名称(中)
seltext_slike dd03p-scrtext_s, " short key word标题字段显示的名称(短)
ddictxt(1) type c, " (S)hort (M)iddle (L)ong设置以长、中还是短名称来显示,取值分别为 S、M、L。直接指定文本显示为长文本、中、还是短文本, 指定这个字段后则会固定下来,不会随着用户的宽度调整变化.
如果是金额或P小数(数量)类型时,需要对下面两个属性进行设置,否则,如果不设置时,在修改对应ALV单元格内容时,会自动将你所输入的数除100,即小数点提前两位;并且如果是数量类型,除了设置datatype外,inttype也需要进行设置,且为C:
datatype like dd03p-datatype,数据类型
inttype like dd03p-inttype, 内部类型
ref_fieldname like dd03p-fieldname,"如需单元格显示F4输入帮助,则需要指定字段所参照的表名
ref_tabname like dd03p-tabname,"如需单元格显示F4输入帮助,则需要指定字段所参照的表中的字段名
另外,以上两个字段还可以解决ALV中形如参照VBELN、MATNR词典类型的列导出(自带的导出功能)Excel时被截断的问题,具体请参照:ALV自带导出文件时字段数据末尾被截断问题
CONVEXIT:设置转换规则,对应于Domain中的转换规则,也可用于解决导出Excel数据前导0被截断的问题
edit(1) type c, " internal use only是否可编辑
hotspot(1) type c, " hotspot设置字段内容下面是否有热点(有下划线,可点击,单击即可触发相应事件)
7.3. 指定双击触发的FunCode
gs_layout-f2code = '&ETA':设置ALV数据行双击触发的Tcode,这里为弹出详情窗口
7.4.相关函数
REUSE_ALV_FIELDCATALOG_MERGE [mə:dʒ] 混合, (使)合并
7.5.重要参数接口
I_CALLBACK_PF_STATUS_SET 设置工具条
I_CALLBACK_USER_COMMAND用户点击工具栏中自定义按钮、预置按钮(需通过IT_EVENT_EXIT参数指定预置FunCode才会回调指定的Form)、数据行双击、单元格热点等时,会回调此参数指定的Form
IT_SORT排序、分类汇总
I_SAVE保存表格布局:'X' 只能保存为全局标准变式,'U' 只能保存特定用户变式,'A'都可以保存,SPACE不能保存变式
I_DEFAULT用户是否可以设置默认的布局变式(即是否可以将某个布局变式设置为默认的布局)
IS_VARIANT指定布局变式
IT_EVENTS事件回调,可以用来代替I_CALLBACK_USER_COMMAND参数
IT_EVENT_EXIT 预置FunCode回调I_CALLBACK_USER_COMMAND指定的Form
IS_LAYOUT
IT_FIELDCAT
T_OUTTAB需要显示的数据内表
i_grid_settings
7.6. 让预置按钮回调I_CALLBACK_USER_COMMAND
IT_EVENT_EXIT:让预置按钮回调I_CALLBACK_USER_COMMAND 指定的Form。可以向IT_EVENT_EXIT参数内表填充需要被拦截的保留Funcode,及在是执行对应功能代码之前还是之后调用:
DATA: event_exit TYPE slis_t_event_exit WITH HEADER LINE.
event_exit-ucomm = '&OAD'."此Funcode为点击AlV工具栏上的选择布局按钮![]() 所对应的FunCode,会被USER_COMMAND 指定的Form拦截
所对应的FunCode,会被USER_COMMAND 指定的Form拦截
event_exit-after = 'X'."在执行完预置功能代码之前还是之后调用
APPEND event_exit.
CALL FUNCTION 'REUSE_ALV_GRID_DISPLAY'
EXPORTING
i_callback_program = sy-repid
it_fieldcat = fieldcat[]
i_callback_user_command = 'USER_COMMAND'
IT_EVENT_EXIT = event_exit[]
TABLES
t_outtab = gt_result.
FORM user_command USING r_ucomm LIKE sy-ucomm rs_selfield TYPE slis_selfield.
ENDFORM.
7.7.颜色
行颜色:gs_layout-info_fieldname = 'COLOR'."指定数据内表中的哪一列用来作为行颜色的列,颜色值与下面列颜色取值格式是一样的,也是4位,不同的是此种方式下的颜色值是与显示数据内表存放在一起,而下面的颜色值则是与gt_fieldcat存放在一起
列颜色:gt_fieldcat-emphasize(['emfəsaɪz]强调) = 'C510'."此种方式下的颜色值定义为4位字符,各位含意:
第1位:固定取值为C
第2位COL:颜色值,取值为0~7
第3位INT:高亮,即颜色是否加深,取值为0、1。1表示加深显示
第4位INV:颜色是否反转,即颜色是作用在背景上,还是作用在输出字符上,取值上为0、1。为1时表示设置的是前景色,即输出字符本身的颜色(好像只有在第3位为0时才有效?)
单元格颜色:gs_layout-coltab_fieldname = 'COLORTABLE'."数据内表中哪列为颜色内表,颜色内表结构如下:
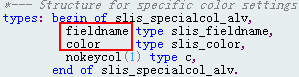

slis_color颜色结构类型各字体对应于上面颜色值串'C510'后三位,意义也是一样,只是没有第一位固定字符C
7.8.可编辑
整体可编辑:gs_layout-edit = 'X'.
某列可编辑:gt_fieldcat-edit = 'X'.
单元格可编辑:只能使用REUSE_ALV_GRID_DISPLAY_LVC,并且还作以下一些设置:
cellstab TYPE lvc_t_styl,"在输出内表中加上这一类型的列
"先将所有单元格设置为可编辑状态
gt_fieldcat-edit = 'X'.
DATA: gt_cellstab TYPE lvc_t_styl WITH HEADER LINE.
"再将原本可编辑的单元格切换到不可编辑样式。注:这里只是样式的切换,不能仅仅使用cl_gui_alv_grid=>mc_style_enabled来将单元格设置为可编辑状态,单元格真正是否可编辑是由fieldcat-edit或layout-edit来决定的,而仅设置为cl_gui_alv_grid=>mc_style_enabled是不可编辑的
gt_cellstab-style = cl_gui_alv_grid=>mc_style_disabled.
APPEND gt_cellstab.
gt_data-cellstab = gt_cellstab[].
gs_layout-stylefname = 'CELLSTAB'."数据内表中哪列为可编辑信息内表
7.9.单元格数据修改后立即自动刷新
单元格中的数据被修改后,将ALV单元格中的数据立即刷新到ABAP对应的内表中:
法一:通过对REUSE_ALV_GRID_DISPLAY函数参数i_grid_settings-edt_cll_cb进行设置:
i_grid_settings-edt_cll_cb = 'X' .
CALL FUNCTION 'REUSE_ALV_GRID_DISPLAY'
EXPORTING i_grid_settings = i_grid_settings
法二:通过函数参数I_CALLBACK_USER_COMMAND指定的回调Form的参数slis_selfield进行设置:
FORM user_command USING ucomm LIKE sy-ucommselfield selfield TYPE slis_selfield.
selfield-refresh = 'X'.
CASE ucomm.
WHEN 'UPDATE'.
PERFORM frm_update.
ENDCASE.
ENDFORM.
7.10.数据有效性验证事件:data_changed
通过REUSE_ALV_GRID_DISPLAY函数的it_events参数设置DATA_CHANGE事件及事件回调Form:
t_events-name = slis_ev_data_changed.
t_events-form = 'ALV_DATA_CHANGED'.
APPEND t_events.
CALL FUNCTION 'REUSE_ALV_GRID_DISPLAY'
EXPORTING
it_events = t_events[]
"注:如果没有设置REUSE_ALV_GRID_DISPLAY 函数的参数i_grid_settings-edt_cll_cb = 'X',在单元格数据被修改后,此Form不会自动调用(即不触发data_changed事件),直到点击了保存或刷新按钮后才会被调用,另外 cl_gui_alv_grid 的CHECK_CHANGED_DATA方法也会触发data_changed事件;另外,如果是通过OO实现的ALV,要让DATA_CHANGE事件触发,则还需要注册回车或焦点失去动作,具体参看后面
FORM alv_data_changed USING pel_data TYPE REF TO cl_alv_changed_data_protocol.
DATA: l_name(20),ls_cells TYPE lvc_s_modi.
FIELD-SYMBOLS <fs_value>.
LOOP AT pel_data->mt_mod_cells INTO ls_cells."读取被修改了的单元格
CLEAR gt_data.
READ TABLE gt_data INDEX ls_cells-row_id."被修改了的单元格所对应输出内表行数据
CONCATENATE 'GT_DATA-' ls_cells-fieldname INTO l_name. "读取被单元格所对应的输出内表中的相应列数据,注:读取出来是的单元格修改之前的数据
ASSIGN (l_name) TO <fs_value>."<fs_value>即为修改前的值
<fs_value> = ls_cells-value. "ls_cells-value单元格中修改后的新值?
"实际上不需要此句来修改输出内表中的数据,因为只要在该Form中不弹出 E MSG,则该Form执行完后会也会自动更新输出内表
"MODIFY gt_data INDEX ls_cells-row_id.
ENDLOOP.
注:如果是通过CL_GUI_ALV_GRID来实现ALV,则在ALV单元格中修改数据后,要在失去焦点或回车时自动触发DATA_CHANGE事件,则还需要通过CL_GUI_ALV_GRID类的REGISTER_EDIT_EVENT方法来设置发数据改变事件在何时触发,2 种方式:
²按回车触发: i_event_id = cl_gui_alv_grid=>mc_event_enter
²单元格失去焦点: i_event_id = cl_gui_alv_grid=>mc_event_modifies
必须设置一种方式,要不然数据变化事件不会被触发事件
7.11. 金额、数字类型输入问题
对于货币与P类型小数(如数量)类型字段,需要对gt_fieldcat-datatype属性进行设置,才能将输入的数字保持原样大小,否则输入的数据会自动将小数点提前2位;对于数量类型,好像还需要对gt_fieldcat-INTTYPE属性进行设置才好使,并且只能设置为C类型:
if &1 = 'CURR'.
"对于金额字段,需要设置为 CURR 数据库字典类型
gt_fieldcat-datatype = 'CURR'.
endif.
if &1 = 'P'.
"对于小数,需要设置为 QUAN 数据库字典类型
gt_fieldcat-datatype = 'QUAN'.
"除此之外,还需要将inttype类型设置为C类型。另外,按理来说要设置为P类型的,但发现不行,QUAN类型映射为 C类型??
gt_fieldcat-inttype = 'C'.
endif.
7.12.排序、分类汇总
"决定此列是否进行分类汇总与大汇总。注:如果不设置gt_sort-subtot,则只有大汇总,不会进行分类小汇总
gt_fieldcat-do_sum = 'X'. "设置了gt_fieldcat-do_sum就会有大汇总,分类小汇总要出现的前提之一也是必须要设置此属性,另外还需对gt_sort-subtot进行设置;如果此参数(gt_fieldcat-do_sum)不设置的话,则大汇总与小汇总都没有
gt_sort-spos = '1'."排序的顺序,如果根据多个字段来排时,决定哪个先排
gt_sort-fieldname = 'KEY1'.
gt_sort-up = 'X'."升序,如果不指定排序(即gt_sort-up、gt_sort-down都没设置时),默认为升序。只要某字段参设置了gt_sort-down/up,则在展示时,排序以后垂直网格中相邻相同的单元格就会合并起来(即分类合并,如果要避免合并,请在布局中设置"no_merging"为"X")
"是否需要以此字段进行分类小计(小计汇总)
gt_sort-subtot= 'X'."是否需要以此字段进行分类合并、并进行小计(注:与本列是否参与排序无关系,只要设置此属性就进行分类合并且小计——但前提是要对gt_fieldcat-do_sum也进行了设置)
APPEND gt_sort.
CALL FUNCTION 'REUSE_ALV_GRID_DISPLAY'
EXPORTING it_sort = gt_sort[]

7.13.可打印的表头输出
t_events-name = slis_ev_top_of_page.
t_events-form = 'alv_top_of_page '.
APPEND t_events.
CALL FUNCTION 'REUSE_ALV_GRID_DISPLAY'
EXPORTINGit_events = t_events[]
"页眉触发时所回调Form
FORM alv_top_of_page.
DATA:lr_rows TYPE REF TO cl_salv_form_layout_grid,
lr_grid_rows LIKE lr_rows,
lr_row TYPE REF TO cl_salv_form_layout_flow,
lr_logo TYPE REF TO cl_salv_form_layout_logo.
DATA: l_row TYPE i VALUE '1'.
CREATE OBJECT lr_rows.
CREATE OBJECT lr_logo.
...
ENDFORM.
7.14.布局变式读取、切换、根据布局格式导出数据
INITIALIZATION.
CALL FUNCTION 'REUSE_ALV_VARIANT_DEFAULT_GET'获取默认的布局 [ˈveəri:ənt]
EXPORTING
i_save = 'A'
CHANGING
cs_variant = gx_variant
p_varit = gx_variant-variant.
AT SELECTION-SCREEN ON VALUE-REQUEST FOR p_varit.
CALL FUNCTION 'REUSE_ALV_VARIANT_F4'选择布局
EXPORTING
is_variant = g_variant
i_save = 'A'
p_varit = gx_variant-variant.
START-OF-SELECTION.
DATA: event_exit TYPE slis_t_event_exit WITH HEADER LINE.
event_exit-ucomm = '&OAD'."此Funcode为点击AlV工具栏上的选择布局按钮时 会被USER_COMMAND Form拦截
event_exit-after = 'X'.
APPEND event_exit.
CALL FUNCTION 'REUSE_ALV_GRID_DISPLAY'
EXPORTING
i_save = 'A'
i_callback_user_command = 'USER_COMMAND1'
it_event_exit = event_exit[]
is_variant = g_variant "ALV展示时,所使用的布局变式名。如果不存在,按默认来
FORM user_command1 USING r_ucomm LIKE sy-ucomm rs_selfield TYPE slis_selfield.
CASE r_ucomm.
WHEN '&OAD'."当点击选择布局按钮时执行
DATA l_ref1 TYPE REF TO cl_gui_alv_grid.
CALL FUNCTION 'GET_GLOBALS_FROM_SLVC_FULLSCR'获取当前ALV所对应的OO Grid
IMPORTING e_grid = l_ref1.
l_ref1->get_variant( IMPORTING es_variant = l_variant )
DATA:p_fieldcat_tab TYPE slis_t_fieldcat_alv.
"当知道当前用户所选择的布局变式后,再通过函数 REUSE_ALV_VARIANT_SELECT 可以
"得到布局变式所对应的布局具体信息,如哪些字段显示、字段显示的顺序如何等,当得到这些
"布局信息后,可以用在用户在导出ALV数据到文件时使用,这样可以保持ALV显示的布局与
"导出去的文件显示的哪些内容及字段顺序体质一致
CALL FUNCTION 'REUSE_ALV_VARIANT_SELECT'读取布局信息
IMPORTING
"可以根据返回的p_fieldcat_tab,得到当前ALV所使用的布局变式所对应的Layout情况,如
"将ALV数据下载成文件时需要与当前Layout布局一样:输出相同的字段与顺序,可以根据
"p_fieldcat_tab 的 NO_OUT(控制是否输出)、COL_POS(控制顺序)来控制,文件表头可取
"seltext_l、seltext_m或seltext_s。可用于导出文件布局
et_fieldcat = p_fieldcat_tab[]
CHANGING
cs_variant = l_variant."传入的布局布局变式名
"""""""下面就是对 p_fieldcat_tab[] 内表字段结构进行分析及应用了
....
ENDCASE.
ENDFORM.
7.15.动态内表
另外,在ALV中可以根据FieldCat来动态创建内表:
rt_fieldcatalog type lvc_t_fcat.
CALL METHOD cl_alv_table_create=>create_dynamic_table [daiˈnæmik]
EXPORTING
it_fieldcatalog = rt_fieldcatalog[]
IMPORTING
ep_table = g_table.
8.OO ALV
8.1.相关类
8.2.控制区域、容器、Grid关系
先在屏幕上绘制一个用户自定义控件区域,然后该用户以自定义控件区域为基础来创建CL_GUI_CUSTOM_CONTAINER容器实例,最后以此容器实例来创建CL_GUI_ALV_GRID实例
8.3. CL_GUI_ALV_GRID重要方法
set_table_for_first_dispaly
REFRESH_TABLE_DISPLAY
IS_STABLE: 刷新的稳定性,就是滚动条保持不动
I_SOFT_REFRESH: 软刷新,如果设置了这个参数,临时给ALV创建的合计、排序、数据过滤都将保持不变。这个是非常有意义的,例如:当你没有修改数据内表里的数据,但因布局修改了想刷新ALV时可使用
8.4.set_table_for_first_dispaly()方法重要参数
8.5. 事件绑定、触发、回调处理
CLASS cl_event_handle DEFINITION. "定义事件处理类
PUBLIC SECTION.
"ALV工具栏初始化事件,如增加按钮并设定属性
METHODS handle_toolbar FOR EVENT toolbar OF cl_gui_alv_grid
IMPORTING e_object e_interactive.
"ALV工具栏按钮点击事件
METHODS handle_user_command FOR EVENT user_command OF cl_gui_alv_grid
IMPORTING e_ucomm.
"ALV表格双击事件
METHODS handle_double_click FOR EVENT double_click OF cl_gui_alv_grid
IMPORTING e_row e_column es_row_no.
ENDCLASS.
CLASS cl_event_handle IMPLEMENTATION."事件处理类实现部分
METHOD handle_toolbar.
gs_toolbar-function = 'B_SUM'."按钮的FunctionCode
gs_toolbar-icon = icon_display."按钮图标
gs_toolbar-text = '总行数'."按钮标签
gs_toolbar-butn_type = '0'."定义按钮类型,0为标准按钮
APPEND gs_toolbar TO e_object->mt_toolbar."添加按钮到工具栏中
ENDMETHOD.
METHOD handle_user_command.
DATA: sum TYPE i .
IF e_ucomm = 'B_SUM'.
...
ENDIF.
ENDMETHOD.
METHOD handle_double_click.
....
ENDMETHOD.
ENDCLASS.
CREATE OBJECT container_r EXPORTING container_name = 'CONTAINER_1'."创建ALV容器对象
CREATE OBJECT grid_r EXPORTING i_parent = container_r. "创建ALV控件
CALL METHOD grid_r->set_table_for_first_displayCHANGING it_outtab = gt_sflight[].
SET HANDLER :event_handle->handle_toolbar FOR grid_r, "注册处理器
event_handle->handle_user_command FOR grid_r,
event_handle->handle_double_click FOR grid_r.
CALL METHOD grid_r->set_toolbar_interactive. "调用此方法才能激活工具栏上增加的自定义按钮
8.6. CL_GUI_DOCKING_CONTAINER容器
Docking容器最大特点是在代码中可以动态创建容器,不需要像创建自定义容器CL_GUI_CUSTOM_CONTAINER那样,在创建时需要将其绑定到一个预先绘制好的用户自定义控件区域中
8.7.覆盖(拦截)预设按钮的功能FunCode:BEFORE_USER_COMMAND
在before_user_command事件中截取标准的功能,完成其他功能,然后使用方法set_user_command将功能代码修改为空(如何拦截事件,则参考事件绑定、触发、回调处理章节)
FORM handle_before_user_command USING i_ucomm TYPE syucomm .
CASE e_ucomm .
WHEN '&INFO' .
CALL FUNCTION 'ZSFLIGHT_PROG_INFO'.
CALL METHOD gr_alvgrid->set_user_commandEXPORTING i_ucomm = space.
ENDCASE .
ENDFORM .
8.8. 数据改变事件data_changed、data_changed_finished
Alv grid有两个事件:data_changed和ata_changed_finished.第一个事件在可编辑字段的数据发生变化时触发,可用来检查数据的输入正确性,第二个事件是当数据修改完成后触发
如果数据没有被修改,当失去焦点或回车时,那么它不会走data change,而是直接触发data change finish事件
可以通过CL_GUI_ALV_GRID类的REGISTER_EDIT_EVENT方法来设置在失去焦点或回车时,触发数据改变事件:
²按回车触发: i_event_id = cl_gui_alv_grid=>mc_event_enter
²单元格失去焦点: i_event_id = cl_gui_alv_grid=>mc_event_modifies
必须设置一种方式,要不然数据变化事件不会被触发事件
然后注册CL_GUI_ALV_GRID的data_changed、data_changed_finished事件,实现事件处理器方法,在数据发生改变时就会触发这两上事件
8.9.单元格可编辑
9. 问题
9.1. ALV自带导出文件时字段数据末尾被截断问题
发现有前导0时,导出会被截断:现发现VBAK-VBELN 与 MARA-MFRNR都有这个问题,可能原因是他们带有转换输出与输入规则所导致
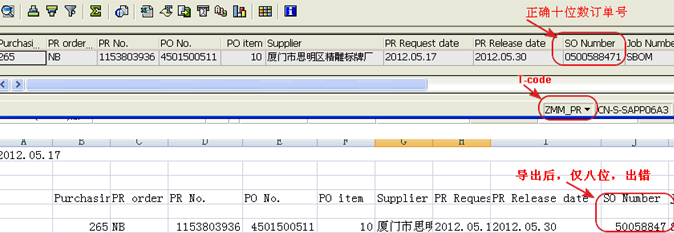
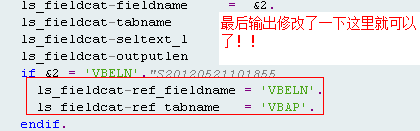
另一种解决办法:
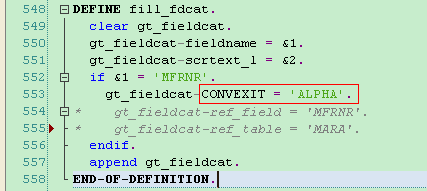
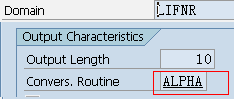
9.2. Smartform 中Template无法显示减号后面内容
在Smartform中的Template里,如果输入的变量内容含有减号,则减号后面的内容会被丢掉

问题原因:输出的内容超出了Template单元格的长度
解决办法:更改TEMPLATE的长度,或者换成 TABLE
9.3. Smartform金额或者数量字段显示不出来

数据是数量时候要在全局定义-货币/数量页签里面把要打印的数量定义成QUAN如下图
在SMARTFORM中,数量和金额类型的字段在显示的时候会和其他字段不在同一个水平面上,解决的方法:&ITAB-MENGE(C)& ,下面是SMARTFORM字段参数设置的几个注意事项:
1、使用SFSY-FORMPAGES显示总页数的时候,如果页数大于9,,将会在前10页显示成星号。解决办法:可以添加 3ZC,&SFSY-PAGE(3ZC)&/&SFSY-FORMPAGES(3ZC)&,不过可能会出现字体颠倒或者 重叠的现象,用一个单独的窗口来存放显示页码的文本,并且把窗口的类型设置为L(最终窗口)就OK了。
2、如果金额或者数量字段显示不出来的话,可以在“货币/数量字段”标签中指定相应的数据类型。
3、Field not outputting more than 255 characters in a loop. This is happening because when you send a string to smartform with length >255 characters then it takes only first 255 characters. I overcomed this problem by splitting the string which was of around 500 char into two and then sending it to smartform as individual vairables and displaying the two variables one after the other in the smartform.
将文本字段拆分成几个字符变量再连接在一起显示。
9.4. 更新数据库表时,工作区或内表的结构需参考数据库表来定义
使用使用MODIFY更新数据库表时,工作区或内表的行结构与数据库表结构中各字段声明顺序要相同,否则更新会错位,该内表最好参照数据库词典结构类型来声明,这样就不会有问题。
9.5. DELETE ADJACENT DUPLICATES…去重复
DELETE ADJACENT DUPLICATES FROM <itab> [COMPARING<f1><f2> ... | ALL FIELDS]
注,在未使用COMPARING 选项时,要删除重复数据之前,一定要按照内表关键字声明的顺序来进行排序,才能删除重复数据,否则不会删除掉;如果指定了COMPARING 选项,则需要根据指定的比较字段顺序进行排序(如COMPARING <F1><F2>时,则需要sort by <F1><F2>,而不能是sort by <F2><F1>),才能删除所有重复数据
9.6.Text使用Excel打开乱码问题
如果使用GUI_DOWNLOAD函数下载文本文件,或者是发送邮件的附件,在英文XP操作系统中使用英文Excel软件打开时,请使用 UTF-16LE编码,否则可能出现乱码情况。
data: l_codepage(4) type n .
data: l_encoding(20).
"根据编码名获取对应的CodePage
callfunction'SCP_CODEPAGE_BY_EXTERNAL_NAME'
EXPORTING
external_name = 'UTF-16LE'
IMPORTING
sap_codepage = l_codepage.
l_encoding = l_codepage.
data: convout type ref to cl_abap_conv_out_ce.
convout = cl_abap_conv_out_ce=>create( encoding = l_encoding ).
convout->write( data = lv_content )."将字符按照l_encoding编码格式转换为X类型(二进制)
xstr = convout->get_buffer( ).
"在码流最前面加上编码信息,该编码由文本编辑软件在打开文件时使用
concatenate cl_abap_char_utilities=>byte_order_mark_little
xstr into xstr in byte mode.
9.7. VBFA与EKPO联合查询问题
由于VBFA-POSNN 与 EKPO-EBELP字段的类型相同,但长度不一样(VBFA-POSNN是6位的数字类型,而EKPO-EBELP为5位数字类型,但VBAP-POSNR行项目号是6位数字类型,不会出现此类问题),所以它们不能进行关联查询,相似的还有VBFA- POSNV也是6位的。下面这个关联查询是查不出数据的,只能分两次查询:
SELECT SINGLE vbeln posnn txz01 menge
INTO (it_result-ebeln, it_result-ebelp, it_result-txz01 , it_result-menge_2)
FROM vbfa AS v INNER JOIN ekpo AS e ON v~vbeln = e~ebeln AND v~posnn = e~ebelp AND e~knttp = 'E'"Where条件是根据销售单查找前置单据——采购单,V为采购单凭证类型
WHERE vbelv = it_result-vbeln AND posnv = it_result-posnr AND vbtyp_n = 'V'.
HNTTP:采购凭证中的帐户设置类型,E——生产/销售所需物料的采购
分成两个可以正常查询:
SELECT SINGLE vbeln posnn
INTO (it_result-ebeln, it_result-ebelp)
FROM vbfa AS v"Where条件是:先根据销售单查找到前置采购单的单号与行项目号
WHERE vbelv = it_result-vbeln AND posnv = it_result-posnr AND vbtyp_n = 'V'.
SELECT SINGLE txz01 menge
INTO (it_result-txz01, it_result-menge_2)
FROM ekpo"Where条件是:再根据前面查出来的采购单号与行项目号,查出EKPO其他详细信息
WHERE ebeln = it_result-ebeln AND ebelp = it_result-ebelp AND knttp = 'E'.
10.技巧
10.1.让READ TABLE...WITH KEY可使用OR条件或其他非“=”操作符
READ TABLE...WITH KEY... 后面不能接OR条件操作符,也不能使用其他非等于的比较操作符,因原是该语句即使在查询出多条时也只取第一条,所以限制了 WITH KEY 后面条件使用。下面是错误的语法:
READ TABLE it_tab WITH KEY k1 = 'C' OR k2 = 'C'.
可以使用下面方式代替:
LOOP AT il_item_status WHERE k1 = 'C' OR k2 = 'C'.
...
EXIT.
ENDLOOP.
10.2.SELECT SINGLE ... WHERE...无法排序问题
SELECT SINGLE ... WHERE ...
使用SINGLE是表示根据表的关键字来查询,这样才能确保只有一条数据,所以当使用SINGLE时,语法上不能再使用ORDER BY语句(因为没有必要了),如果查询时不是根据关键字来查询,且查询时先排序再取一条时,我们只能使用另一种语法:
SELECT * FROM tj02t INTO CORRESPONDING FIELDS OF TABLE gt_result UP TO 1 ROWS
WHERE SPRAS = 'E' ORDER BY ISTAT.
如果是取某个最大值或最小值,则可以使用聚合函数更简洁:
SELECT MIN( edatu ) INTO (g_tabcon_mps_wa-edatu)FROM vbep
WHERE vbeln = ztab_mps-vbeln AND posnr = ztab_mps-posnr.
10.3.当心Where后的条件内表为空时
在Select、If、Delete 内表、read、look at内表语句中的Where条件中,如果使用的Range是一个空的条件内表,则 xx IN range恒为真,那么xx NOT IN range则恒为假。
注:不会像FOR ALL ENTRIES那样,忽略其他的条件表达式,其他条件还是起作用
10.4.快速查找SO所对应的交货单DN及PO
快速查找SO(VBAP)所对应的DN(LIPS):虽然可以通过vbap-vbeln = lips-vgbel AND vbap-posnr = lips-vgpos来关联查找,但LIPS-VGBEL、LIPS-VGPOS非主键,查找起来非常慢(但根据DN来查找所的SO是很快的,因为此时为主键查找)但可以通过VBFA单据流表来查找DN,这样会非常快,因为这是根据主键来查找的:
vbfa~vbelv = vbap-vbeln AND vbfa~posnv = vbap-posnr AND vbfa~vbtyp_v ='C' AND vbfa~vbtyp_n = 'J'
另外,根据SO查找PO时,可以根据EKKN-VBELN= VBAP-VBELN AND EKKN-VBELP=VBAP-POSNR到SO与PO中间表EKKN里去找,但查找条件为非主键也非索引,所以找起来时很慢,可以通过VBFA单据流表进行查找,因为VBFA在vbeln、posnn 字段上创建了索引(虽然查询时WHERE从句条件字段不是按主键字段顺序——使用的是后半部分主键,所以用不到主键索引,但是是按非主键索引字段顺序书写,所以还是可以用到索引):vbfa~vbeln = vbap-vbeln AND vbfa~posnn = vbap-posnr AND vbfa~vbtyp_v ='V' AND vbfa~vbtyp_n = 'C'
10.5.X类型的C类型视图
"江 <--> 6C5F
"正 <--> 6B63
*DATA: x(4) TYPE x VALUE '6C5F'.
DATA: x(2) TYPE x VALUE '6C5F'.
FIELD-SYMBOLS: <c> TYPE c.
"有时将X类型分配给C类型时会出错(长度需要是4的倍数,所以定义成4的倍数
"即可解决这个问题,但有时定义的长度只能是某个特定数,所以此时只能使用后面这种方式)
"编译时报错误:The length of "X" in bytes must be a multiple of the size of
"a Unicode character, regardless of the size of the Unicode character.
*ASSIGN x to <c> CASTING.
"只能先定义一个C类型变量,再将这个C类型变量分配给X类型字段符号,这样就可
"以随便在x类型之间捣腾了,但此时C变量不是X变量的真正视图了(经过了拷贝)
DATA: c(1) .
FIELD-SYMBOLS: <x> TYPE x.
ASSIGN c to <x> CASTING.
<x> = x.
"江 6C5F注:如果输出的是乱码,则是字节序的问题,需写成5F6C(如Windows操作系统中)
WRITE: /(2) c, <x>.
"正 6B63注:如果输出的是乱码,则是字节序的问题,需写成636B(如Windows操作系统中)
x = '6B63'.
<x> = x.
WRITE: /(2) c, <x>.
10.6.字符串连接:&& 替代 CONCATENATE
有如将整型(I)与一个字符串(String)进行连接,此时不能直接使用CONCATENATE进行连接,因为CONCATENATE 操作的是字符类型,所以需要将整型转换为字符型后才能使用CONCATENATE 进行连接,但这里需要注意的,当正整型变量转换为字符类型时,符号位会转换为空格,这时使用CONCATENATE 接连得到的字符串可能会多出一个空格;当将整型变量与字符串进行连接时,最好使用 && 操作符,除了直接能连接外,还不会出现多余空格的问题:
DATA: i TYPE i VALUE '10'.
DATA: str TYPE string VALUE 'string'.
DATA: tmp TYPE string.
str = i && str.
WRITE: / str.
tmp = i.
CONCATENATE tmp str INTO str.
WRITE: / str.
![]()
10.7. Variant变式中动态日期
报表程序的选择屏幕中,输出条件后可以点击保存按钮,会弹出创建变式的屏幕,如果条件中有日期字段,日期字段可以随着时间变化,日期字段的值也可以动态的变化,如对于每天都要跑的Job报表很有用,每天查询当天。当然也可以通过报表程序的INIT事件里动态获取当前日期,但可能需要修改程序
除用在中Job外,变式还可以用在Tcode中
11.优化
降低CPU负荷(减少循环次数)、降低DB负荷(减少IO操作)、降低内存使用(减少内表大小)
11.1.数据库
1. 不要使用 SELECT * ...,选择需要的字段, SELECT * 既浪费CPU,又浪费网络带宽资源,还需占用大量的ABAP内存
2. 不要使用SELECT DISTINCT ...,会绕过缓存,可使用 SORT BY + DELETE ADJACENT DUPLICATES 代替
3. 少用相关子查询,因为子查询对外层查询结果集中的每条记录都会执行一次
4. 少用嵌套SELECT … ENDSELECT,可以使用联合查询或FOR ALL ENTRIES来替换,减少循环次数
5. 如果确定只查一条数据时,使用 SELECT SINGLE... 或者是 SELECT ...UP TO 1 ROWS ...
6. 统计时,直接使用SQL聚合函数,而不是将数据读取出来后在程序里再进行统计
7. 使用游标读取数据,这样省掉了将从数据库中的取记录放入内表的INTO语句这一过程开销
8. 多使用inner join,必要时才使用left join
9. inner join获取数据时,尽量不要用太多的表关联,特别是大表关联,关联顺序为:小表-大表
10.where 条件里面多用索引、主键,顺序也要遵循小表-大表
11.inner join条件放置的位置应该按照 On、Where、Having的顺序放,因为SQL条件的的执行一般是按这个顺序来执行的,将条件放在最开始执行,则可过滤掉大部数据;但要注意Left Outer Join,是否可以将ON中的条件移动到Where从句则要考虑(如果真能放在Where从句中,则应该使用Inner Join,而非Left Outer Join,因为Where条件会过滤掉那些包括在右表中不存在的左表数据),因为此时条件放在On后面与放在Where语句后面结果是不一样的(因为不管on中的条件是否为真,左表中在右边表不存在的数据也会被返回,但如放在where条件中,则会对On产生的数据再次过滤的条件,会滤掉不满足条件的记录——包括左表在右表中找不到的记录,这时已经没有left join的含义)
12. 要根据主键或索引字段查找数据,且WHERE从句中的条件字段需按INDEX字段顺序书写,且将索引字段条件靠前(左边),如:在VBFA表中查找SO所对应的交货单DN,因为如果直接到LIPS中找时,SO的订单中号与行号在LIPS中非主键,但在VBFA是部分主键(VBFA中根据部分主键查找 SO -> DN; 根据索引查找 SO -> PO,VBFA-VBELN+VBFA-POSNN组合字段上创建了索引,即根据SO找PO时,不要从EKKN关联表中查找,而是通过VBFA中查找。后来查看EKKN,发现在VBELN+VBELP字段上创建了索引,所以从VBFA与EKKO查找应该差不多,主要看哪个表数据量少的问题了)
检查条件组合字段是否是主键,或者是上在上面创建了索引,避免条件组合字段即不是主键又没有索引
13. SELECT语句WHERE条件,应该先将主键相关条件放在前面 然后按照比较符 = 、< 、>、 <> 、LIKE IN 的顺序排列WHERE条件
14.使用部分索引字段问题:如果一个索引是由多个字段组成的,只使用一部分关键字段来进行查询时,也是可以使用到索引,但使用时要注意要按照索引定义的顺序且取其前面部分
15. 请根据索引字段进行ORDER BY,否则通过程序进行SORT BY。与其在数据库在通过非索引字段进行排序,不如在程序中使用SORT BY语句进行排序,因为此情况下应用服务器上的执行速度要比数据库服务器快(应用服务器上采用的是内存排序)
16.避免在索引字段上使用:
l not、<>、!=、IS NULL、IS NOT NULL,可以用> 与 < 来替代
l 避免使用 LIKE,但LIKE '销售组1000'和LIKE '销售组1000%'可以用到,而LIKE '%销售组1000'(百分号前置)则用不到索引
l 不要使用OR来连接多个索引字段(但同一字段多个值之间可以使用OR);对于同一索引字段,可以使用IN来替代OR:
![]()
![]()
l带有BETWEEN 的WHERE 条件不能通过索引来搜索?也可使用IN代替
17.避免使用以下语句,因为使用这些语句时,不能使用 Table Buffer:
l Aggregate expressions
l Select … for update
l Order by、group by、having从句
l Joins,使用JOIN时,会绕过SAP缓存,可以使用FOR ALL ENTRIES来代替
l WHERE从句中使用Sub queries(子查询)
l WHERE从句中使用IS NULL条件
18.在下面情况下使用FOR ALL ENTRIES IN:
l在循环内表 LOOP...AT Itab中循环访问数据库时
l簇表是禁止JOIN的表类型, 当需要联接簇表查询数据时,如:BSEG(会计凭证)、KONV(条件表)
簇表一般是由多个表组成,簇表中的数据来自于多个表,有点像视图,但不能直接通过簇表进行数据维护
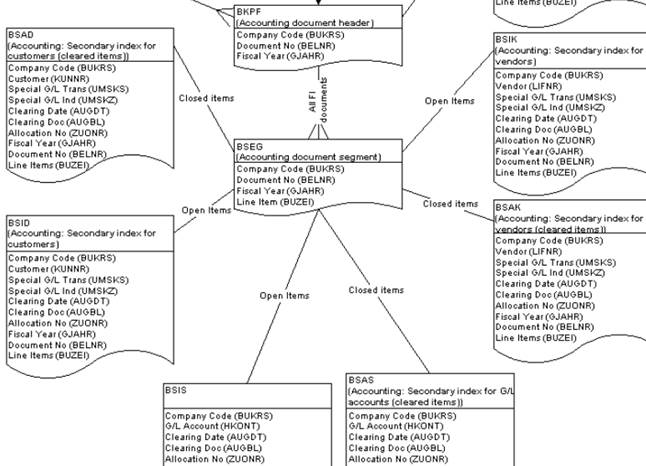
lJOIN超过3个表会出现性能问题, 当使用JOIN联接的表超过3个时
l如果两个表的数据非常大时(上百万),使用JOIN进行联合查询会很慢,此时改用FOR ALL ENTRIES IN
19.使用内表批量操作数据库,而不要使用工作区一条条操作,如:
SELECT ... INTO TABLE itab
INSERT dbtab FROM TABLE itab
DELETE dbtab FROM TABLE itab
UPDATE/MODIFY dbtab FROM TABLE itab
20.如果你使用 CLIENT SPECIFIED,需在WHERE从句第一个位置上指明 MANDT条件,否则使用不到索引
11.2.程序
1. READ TABLE ...WITH [TABLE] KEY...BINARY SEARCH读取标准内表使用二分查找
2. 在循环(LOOP AT ...WHERE..)或查询(READ TABLE ...)某内表时,如果未使用索引(排序表、哈希表)或二分查找,则在查询组合字段创建第二索引,查询时通过USE KEY或WITH [TABLE] KEY选项使用第二索引,这样在查询时会自动进行二分查找或哈希找查
在没有用二分查找的情况下,可在查询组合字段上创建第二索引(哈希或排序索引),则在读取或循环内表时会自动使用二分查找或哈希查找算法
3. 查找时,优先考虑使用哈希表进行查找,再考虑使用排序表进行二分查找,因为哈希查找的时间复杂度为(O (1)),不会因数据的增加而受到影响;而二分查找虽然比顺序搜索快很多,但随着数据的增加会慢下来,其时间复杂度为(O (log2n));标准内表的时间复杂度为O(n)。注:如果只使用到部分关键字为搜索条件,哈希表则会全表扫描,此时应该使用二分找查
4. FOR ALL ENTRIES:需要判断内表是否为空,否则会查询出所有数据
5. LOOP AT itab... ASSIGNING ...、READTABLE ...ASSIGNING ... 在循环或读取内表时,使用字段符号来替换表工作区,将数据分配给字段符号Field Symbols,减少数据来回传递
6. 尽量避免嵌套循环,如必须时,将循环次数少的放在外层,次数多的放在内层,这样可以减少在不同循环层之间的频繁地切换及内部循环次数
7. 条件语句中多使用短路与或,“与”连接时将为假的机率大的条件放在前面,“或”连接时将为真的机率大的条件放在前面
8. 少使用递归算法,递归时会增加调用栈层次,降低了性能,可使用队列或栈来避免递归
9. 尽量不要使用通用类型(如FIELD-SYMBOLS、及形式参数),使用具体限定类型;比较时尽量使用同一数据类型:IF c = c.比IF i = c.快,原因是未发生类型转换
10.不要使用混合类型进行计算与比较,除非有必须
11.尽量使用静态语句,少用动态编程,动态编辑虽然灵活,但性能有所下降
12.在对字符进行操作进,尽量使用String代替C固定长度类型,如:concatenate[kənˈkatɪneɪt]语句对固定长度的C连接时,会去扫描那些非空字符出来再进行连接,速度没有String快
13.READ/MODIFY TABLE时使用TRANSPORTING只读取或修改必要的字段 [trænsˈpɔ:t]
14.尽量避免使用MOVE-CORRESPONDING和 SELECT...INTO CORRESPONDING FIELDS OF [TABLE] (SELECT时,查询几个字段就定义具有这几个字段的内表,而不是直接使用基于数据库表类型创建的内表,否则如果直接使用 INTO TABLE语法检查时会警告,但结果是没有问题的)。CORRESPONDING语句在系统内部存在隐式操作: 逐个字段的检查元素名称匹配; 检查元素类型匹配;元素类型转换;[ˌkɔrisˈpɔndiŋ]
15.最好不要向排序内表中插入(INSERT ... INTO TABLE ...)数据,因为在插入时会进行排序,速度会随着数据量的增加而慢下来,所以最好只向标准内表或哈希表中插入数据
16.将某个内表中的全部记录或部分记录追加到另一内表时,使用INSERT/APPEND LINES OF … 代替循环逐条追加;如果是全新赋值,直接对内表使用“=”进行赋值操作即可
17.调用类方法要快于Function:
Calling Methods of global Classes: call method CL_PERFORMANCE_TEST=>M1.
Calling Function Modules: call function 'FUNCTION1'.
18.通过运行事务代码SLIN(或者直接通过SE38的菜单),进行代码静态检查,根据SAP提供的反馈信息,优化代码
19.通过老式方式定义内表时,使用OCCURS 0 而非OCCURS n :[əˈkə:s] 重现
lOCCURS n 代表初始化内表的空间大小为n(空间固定),当内表存储记录条数超出n时,系统将依靠页面文件存放超出部分的数据。 当系统内存资源十分紧缺的时候,我们可以使用OCCURS n的初始化方法, 但是这样的效率稍微慢
lOCCURS 0 代表初始化内表的空间大小为无限,当内表存储记录条数不断增加时, 内表所使用的内存空间不断扩大, 直到系统无法分配为止。使用内存比使用页面交换更快一些, 但是要考虑系统的资源状态
20.使用完成后及时清空释放内表所占用的空间:FREE <itab>.
21.使用CASE…WHEN语句代替 IF…ELSEIF…;使用WHILE…ENDWHILE 代替 DO…ENDDO
22.LOOP循环内表时加上Where条件减少CPU负荷,而不是在循环里通过IF语句来过滤数据
12.屏幕
12.1.AT SELECTION-SCREEN、PAI、AT USER-COMMAND触发时机
当点击屏幕上元素(包括按钮、单选复选按钮、下拉列表、菜单、工具条)时,选择屏幕触发的是AT SELECTION-SCREEN(不是AT USER-COMMAND 事件),对话屏幕触发的PAI事件,列表屏幕触发的才是AT USER-COMMAND事件
12.2.SELECTION-SCREEN格式化屏幕、激活预设按钮
SELECTION-SCREEN SKIP 空行
SELECTION-SCREEN ULINE 水平线
SELECTION-SCREEN COMMENT text FOR FIELD sel 文本标签
SELECTION-SCREEN PUSHBUTTONbt_text USER-COMMAND fcode 按钮
SELECTION-SCREEN BEGIN OF LINE 多元素行
SELECTION-SCREEN BEGIN OF BLOCK block 屏幕块
SELECTION-SCREEN BEGIN OF TABBED BLOCK tblock Tabstrip
SELECTION-SCREEN FUNCTION KEY n 激活工具栏中预设按钮
SELECTION-SCREEN BEGIN OF SCREEN dynnr [AS SUBSCREEN] 定义屏幕或子屏幕
12.3. PARAMETERS
PARAMETERS {para[(len)]}|{para [LENGTH len]}
type_options [{ TYPE type [DECIMALS dec] }| { LIKE dobj }| { LIKE (name) }]
screen_options[{ {[OBLIGATORY|NO-DISPLAY] [VISIBLE LENGTH vlen]}
| {AS CHECKBOX [USER-COMMAND fcode]}
| {RADIOBUTTON GROUP group [USER-COMMAND fcode]}
| {AS LISTBOX VISIBLE LENGTH vlen [USER-COMMAND fcode][OBLIGATORY]}}
[MODIF ID modid]]
value_options[DEFAULT val][LOWER CASE][MATCHCODE OBJECT hp][MEMORY ID pid][VALUE CHECK]
OBLIGATORY:如果某个屏幕输入元素处于隐藏状态,即使它是必输入的,则在提交时也不会提示你必输入(但如果是必须的,在隐藏前一要输入,否则会出错并要求重新输入),只有在显示状态时且不输入时才会提示
MODIF ID key:设置修改组代码,方便屏幕的元素的批量修改,key中设定的代码将被赋给系统内表SCREEN-GROUP1字段
MATCHCODE OBJECT:指定一个search_help
MEMORY ID pid:通过SAP Memory进行同一用户会话不同窗口间的参数传递
VALUE CHECK:开启系统自动检验(如果屏幕元素参照的数据元素所对应的Domain设置了fixed Values、Value Table)
PARAMETERS: p_check as CHECKBOX USER-COMMAND chk
PARAMETERS: p_radio1 TYPE c RADIOBUTTON GROUP g1 USER-COMMAND rbt,
p_radio2 TYPE c RADIOBUTTON GROUP g1.
PARAMETERS p_carri2 LIKE spfli-carrid
AS LISTBOX VISIBLE LENGTH 20
USER-COMMAND lst
12.4. SELECT-OPTIONS
SELECT-OPTIONS selcrit FOR {dobj|(name)}
screen_options[OBLIGATORY|NO-DISPLAY][VISIBLE LENGTH vlen][NO-EXTENSION][NO INTERVALS][MODIF ID id]
value_options [DEFAULT val1 [TO val2] [OPTION opt] [SIGN sgn]][LOWER CASE]
[MATCHCODE OBJECT search_help][MEMORY ID pid]
该语句会生成一个名为selcrit选择条件内表,具体请参数OPEN SQL章节中的 RANG条件内表
NO-EXTENSION:限制选择表为单行,元素输入后面不会出现![]() 按钮 [iksˈtenʃən]
按钮 [iksˈtenʃən]
NO INTERVALS:只会出现LOW字段,To后面的HIGH字段不出现在选择屏幕上,但是用户仍然可以在Mutiple Selection窗口中输入范围选择。也就是说:只要有![]() 按钮,就可以选择多个条件与范围值 [ˈintəvəl]
按钮,就可以选择多个条件与范围值 [ˈintəvəl]
OBLIGATORY:只有前面一个框框中出现钩,第二个框没有,也就是说该选项只能LOW字段有效 [əˈblɪgəˌtɔ:ri:]
DEFAULT:
TABLES: mara,marc.
SELECT-OPTIONS:werks FOR marc-werks OBLIGATORY DEFAULT 1001 TO 1007 SIGN I OPTION BT.
SELECT-OPTIONS:p2 FOR mara-matnr MODIF.
AT SELECTION-SCREEN OUTPUT.
p2-low = 'aaaa'.
APPEND p2 .
MEMORY ID:将第一个输入框中的数据存放到SAP MEMORY中共享
12.4.1.输入ABAP程序默认值时,需要加上“=”
![]()
如果输入框中输入的值恰为ABAP程序中相应字段所对应的初始值时(如字符类型为空串,时间与数字类型为“0”串时),需要在第一个框前面选择![]() 操作符,否则程序将会忽略这个值的输入,即查询所有的
操作符,否则程序将会忽略这个值的输入,即查询所有的
12.4.2.选择条件内表多条件组合规则
((Select Single Values OR…) OR(Select Intervals OR…))( AND NOT Exclude Single Values) … ( AND NOT Exclude Intervals) …


("MATNR" = '1' OR "MATNR" >= '2' OR "MATNR" <= '3' OR "MATNR" > '4' OR "MATNR" < '5' OR "MATNR" <> '6' OR "MATNR" <> '7' OR "MATNR" LIKE '23%' OR NOT ( "MATNR" LIKE '24_' ) OR "MATNR" BETWEEN '8' AND '9' OR NOT ( "MATNR" BETWEEN '10' AND '11' )) AND "MATNR" <> '12' AND "MATNR" < '13' AND "MATNR" > '14' AND "MATNR" <= '15' AND "MATNR" >= '16' AND "MATNR" = '17' AND "MATNR" = '18' AND NOT ( "MATNR" LIKE '25%' ) AND "MATNR" LIKE '26_'AND NOT ("MATNR" BETWEEN '19' AND '20' ) AND "MATNR" BETWEEN '21' AND '22'
12.4.3.使用SELECT-OPTIONS替代PARAMETERS
实际上PARAMETERS 类型的参数完全可以使用SELECT-OPTIONS来替代,下面就是使用这种替换方式,外表看上去与PARAMETERS是一样的,但双击后可以出现操作符选择界面,所以唯一不同点就是这个可以选择操作符,而且这样做的好处是:当不输入值时,查询所有的,但PARAMETERS值为空是查询就是为空(或0)的值(如果此时要忽略这个条件,则要将单值转换为Rang或者是分两种情况来写SQL条件):
TABLES: marc.
SELECT-OPTIONS: s_werks FOR marc-werks NO INTERVALS NO-EXTENSION.

12.5.各种屏幕元素演示
TABLES: mara,marc.
DATA: g_pg(24).
SELECTION-SCREEN BEGIN OF BLOCK bk1 WITH FRAME TITLE text-001.
PARAMETERS: p_bukrs LIKE t001-bukrs OBLIGATORY."Company code
SELECT-OPTIONS:
s_werks FOR marc-werks OBLIGATORY NO INTERVALS,
s_matnr FOR mara-matnr NO-EXTENSION ,
s_segme FOR g_pg."参照普通变量
PARAMETERS: p_line(6).
SELECTION-SCREEN SKIP 1.
PARAMETERS: p_x1 RADIOBUTTON GROUP gp1 DEFAULT 'X',
p_x2 RADIOBUTTON GROUP gp1.
PARAMETERS: p_old TYPE c AS CHECKBOX.
PARAMETERS: p_oldhir LIKE grpdynp-name_coall MODIF ID m1 DEFAULT 'ABB_CHINA.XXXX'.
SELECTION-SCREEN:SKIP 1.
SELECTION-SCREEN BEGIN OF LINE.
PARAMETERS: p_dwload AS CHECKBOX.
SELECTION-SCREEN COMMENT 5(29) text-001.
PARAMETERS: p_file TYPE string.
SELECTION-SCREEN END OF LINE.
SELECTION-SCREEN END OF BLOCK bk1.
12.6. 按钮、单选复选框、下拉框的FunCode
如果复选框与单选按钮没有设置Function Code,则它们就会像普通的输入框一样,即使状态发生了改变,也不会触发PAI事件
对话屏幕中的按钮、复选框、单选按钮、下拉框的Function Code都是通过屏幕元素 attributes来设置的;选择屏幕中的FunCode则通过USER-COMMAND选项来设置
12.6.1.选择屏幕中的按钮
SELECTION-SCREEN:PUSHBUTTON 2(12) but1 USER-COMMAND cli1.
INITIALIZATION.
but1 = 'Button 1'."可直接设置按钮上的标签文本
AT SELECTION-SCREEN.
CASE sy-ucomm.
WHEN 'CLI1'.
ENDCASE.
12.6.2.选择屏幕中的单选/复选按钮:点击时显示、隐藏其他屏幕元素
更多请参考动态修改屏幕章节
PARAMETERS show_all AS CHECKBOX USER-COMMAND flag.
PARAMETERS hide RADIOBUTTON GROUP rd USER-COMMAND flag2 DEFAULT 'X'.
PARAMETERS show RADIOBUTTON GROUP rd .
SELECTION-SCREEN BEGIN OF BLOCK b1 WITH FRAME .
PARAMETERS: p1 TYPE c LENGTH 10 ,
p2 TYPE c LENGTH 10.
SELECTION-SCREEN END OF BLOCK b1.
SELECTION-SCREEN BEGIN OF BLOCK b2 WITH FRAME TITLE t.
PARAMETERS: p3 TYPE c LENGTH 10 MODIF ID bl2,
p4 TYPE c LENGTH 10 MODIF ID bl2.
SELECTION-SCREEN END OF BLOCK b2.
SELECTION-SCREEN BEGIN OF BLOCK b3 WITH FRAME .
PARAMETERS: p5 TYPE c LENGTH 10 MODIF ID bl3,
p6 TYPE c LENGTH 10 MODIF ID bl3.
SELECTION-SCREEN END OF BLOCK b3.
INITIALIZATION.
t = '----ALL----'.
"单先与复选框、下拉列表项点击触发PAI后,接下来还会触发屏幕的PBO(回车也是这样),但如果点击的是执行按钮,则不会接着触发屏幕的PBO,除非没有输出或在Basic List列表页面上点击返回按钮时,才会触发PBO
AT SELECTION-SCREEN OUTPUT.
LOOP AT SCREEN.
IF show_all = 'X' AND screen-group1 = 'BL2'.
screen-active = '1'."显示
MODIFY SCREEN.
ELSEIF screen-group1 = 'BL2'.
screen-active = '0'."隐藏
MODIFY SCREEN.
ENDIF.
IF show = 'X' AND screen-group1 = 'BL3'.
screen-active = '1'.
MODIFY SCREEN.
ELSEIF screen-group1 = 'BL3'.
screen-active = '0'.
MODIFY SCREEN.
ENDIF.
ENDLOOP.
12.6.3.选择屏幕中下拉列表:AS LISTBOX
如果参照的字段只有检查表,没有搜索帮助时,且检查表有对应的T表,则Value为T表第一个文本字段值?
下拉框基本上与F4搜索帮助数据一致,但发现参照某些表字段时(如spfli-cityfrom)下拉框中没有值:
PARAMETERS p_carri1 LIKE SPFLI-CARRID.
PARAMETERS p_carri2 LIKE spfli-carrid
AS LISTBOX VISIBLE LENGTH 20
USER-COMMAND onli
DEFAULT 'LH'.

除了通过参数表字段外,还可以通过VRM_SET_VALUES函数为下拉框初始化列表项
12.7. 屏幕流逻辑
PROCESS BEFORE OUTPUT.
PROCESS AFTER INPUT.
PROCESS ON HELP-REQUEST.
PROCESS ON VALUE-REQUEST.
12.7.1.FIELD
使用FIELD语句后,屏幕字段<f>需要在该语句处理完后才传递到ABAP程序相应的字段中,在后没有带module选项时,仅仅只是控制屏幕字段传输到ABAP程序中的时间点,如需对屏幕字段进行检验,通过以下语句来实现检验:
FIELD<field_name> MODULE<module_name>.
仅只有未出现在FIELD语句中的屏幕字段才会在PAI事件块处理前传输到ABAP程序中去。所以当某个屏幕字段出现在FIELD语句中,并且在该 FIELD语句未执行完之前,不要在PAI dialog modules中使用该屏幕字段(该屏幕字段相关的FIELD语句执行完成之后才可以在后续的PAI dialog modules调用中使用),否则,ABAP程序同名字段中的值使用的是前一次对话屏幕中所设置的值。
12.7.2.MODULE
FIELD dynp_field MODULE mod [ {ON INPUT}
| {ON REQUEST}
| {ON *-INPUT}
| {ON {CHAIN-INPUT|CHAIN-REQUEST}}
| {AT CURSOR-SELECTION}.
• ON INPUT:只要该字段不为初始值就会触发module
• ON REQUEST:该字段发生变化后触发module
FIELD <f> MODULE <mod> ON INPUT|REQUEST|*-INPUT. 相当于选择屏幕的 AT SELECTION-SCREEN ON field
CHAIN.
FIELD: <f1>, <f2>,<fi...>.
MODULE <mod1> ON CHAIN-INPUT|CHAIN-REQUEST.
FIELD: <g1>, <g2>,<gi...>.
MODULE <mod2> ON CHAIN-INPUT|CHAIN-REQUEST.
...
ENDCHAIN.
只要<fi>中某个字段满足条件(<mod1>后面的CHAIN-INPUT与CHAIN-REQUEST条件),<mod1>就会被调用,而只要<fi>或<gi>中的某个字段满足条件,则<mod2>就会被调用。如果在module中检测不通过(如MESSAGE… E类消息时),则CHAIN…ENDCHAIN之外的所有其他屏幕字段将会被锁定且置灰,这与选择屏幕的AT SELECTION-SCREEN ON BLOCK校验是一样的
CHAIN.
FIELD: <f1>, <f2>,<fi...>.
FIELD <f> MODULE <mod1> ON INPUT|REQUEST|*-INPUT|CHAIN-INPUT|CHAIN-REQUEST.
MODULE <mod2> ON CHAIN-INPUT|CHAIN-REQUEST.
ENDCHAIN.
<mod1>被调用的条件是所对应字段<f>满足ON后面指定的条件即可执行。<mod2>被调用的条件是只要<fi>或<f>中的某个字段满足条件即可执行。
12.7.3.ON INPUT与ON CHAIN-INPUT区别
CHAIN.
FIELD: f1,f2.
FIELD: f3 MODULE mod1 ON INPUT. 只有f3为非初始值时才调用mod1
ENDCHAIN.
CHAIN.
FIELD:f1,f2.
FIELD:f3 MODULE mod1 ON CHAIN-INPUT. f1,f2,f3中任一字段包含非初始值时都调用mod1
ENDCHAIN
如果不在 CHAIN中时,不能像下面这样写:
FIELD a. "FIELD与MODULE只能写在同一语句当中
MODULE check_a ON INPUT.
只有在CHAIN中时,MODULE语句才可以单独出现(不与FIELD在同一语句中),且只能是CHAIN-INPUT:
MODULE mod1 ON CHAIN-INPUT.
12.8.EXIT-COMMAND
12.8.1.MODULE <mod> AT EXIT-COMMAND
对话屏幕中,对于E类型的Function Code,可以使用如下语句在PAI事件块中来触发:
不管该语句在screen flow logic的PAI事件块里的什么地方,都会在字段的约束自动检测之前执行,因此,此时其他的屏幕字段的值不会被传递到ABAP程序中去,当该MODULE执行完后,如果未退出该屏幕,则会进行正常PAI(即PAI事件块里没有带EXIT-COMMAND选项的MODULE语句)事件块。
该语句在字段约束自动检测之前会被执行,一般用来正常退屏幕来使用,如果未使用LEAVE语句退出屏幕,则会在这之后还会继续进行字段的自动检测,检测完后还会继续PAI的处理(即执行PAI事件块中不带EXIT-COMMAND选项的MODULE语句)
12.8.2.AT SELECTION-SCREEN ON EXIT-COMMAND
在选择屏幕上,对于E类型的FunCode(如点击![]() )会触发AT SELECTION-SCREEN ON EXIT-COMMAND事件
)会触发AT SELECTION-SCREEN ON EXIT-COMMAND事件
12.9.OK_CODE
如果是回车(命令行中未输入内容时回车)时,由于FunctionCode为空,所以SYST-UCOMM 、SY-UCOMM、OK_CODE都不会被重置;如果非回车,但FunctionCode也是空时,SYST-UCOMM、SY-UCOMM会被重置,但OK_CODE还是不会被重置,所以OK_CODE只有在FunCode非空时才会被重置
12.9.1.ok_code使用前需拷贝
如果一个屏幕中的某个按钮未设置Function Code时也是可以触发PAI事件时,并且由于其Function Code此时为空而不会去设置OK_CODE(但此时SYST-UCOMM 或 SY-UCOMM还是会被重新设置为空),这样的话OK_CODE中的值还为上一次触发PAI时所设置的Function Code。所以一般情况下在使用OK_CODE之前,先将OK_CODE拷贝到SAVE_OK变量中(在后面的程序使用SAVE_OK而不是OK_CODE),并随后将OK_CODE清空,以便为下一次PAI事件所使用做准备
其实还有一种方案可能替换这种使用前拷贝方案:就是还是针对OK_CODE编程,不另外定义save_ok,而是在每个屏幕的 PBO 里将ABAP中的OK_CODE清空。
12.10.Search help (F4)
12.10.1. VALUE CHECK、fixed Values、Value Table
PARAMETERS p_1 TYPE zmy_dm_200 VALUE CHECK."注:SELECT-OPTIONS没有此选项
如果选择屏幕字段参考数据元素所对应的Domaim设置了固定值(fixed Values)或值表(Value Table)时,使用VALUE CHECK选项后,会验证输入值是否在固定值或值表范围之内
若要使值表检查生效,则首先需要将此Domain引用到表字段,再对此表字段通过![]() 按钮进行外键分配,并且外键一定是来自的值表的主键,最后使用PARAMETERS定义屏幕参数时要参照此表(从表)字段(类型参照了该DataElement的字段),否则如果只是直接参照所对应的DataElement是不起作用,即Value Table一定要经过转换为Check Table后再起作用,并且PARAMETERS要参照此表字段。比如这上面PARAMETERS示例语句中直接使用的是zmy_dm_200这个DataElement,这样即使该DataElement所对应的Domain设置了ValueTable,ValueCheck不会起使用,也不会显示F4帮助(但如果设置了Fixed Value则会显示F4帮助)
按钮进行外键分配,并且外键一定是来自的值表的主键,最后使用PARAMETERS定义屏幕参数时要参照此表(从表)字段(类型参照了该DataElement的字段),否则如果只是直接参照所对应的DataElement是不起作用,即Value Table一定要经过转换为Check Table后再起作用,并且PARAMETERS要参照此表字段。比如这上面PARAMETERS示例语句中直接使用的是zmy_dm_200这个DataElement,这样即使该DataElement所对应的Domain设置了ValueTable,ValueCheck不会起使用,也不会显示F4帮助(但如果设置了Fixed Value则会显示F4帮助)
注:如果要使用VALUE CHECK选项,则Domain的类型只能是C或者N类型,否则运行会抛异常。

PARAMETERS c TYPE sflight-carrid VALUE CHECK."应该是这样,参照的是从表字段(主表为值表)
PARAMETERS c TYPE s_conn_id VALUE CHECK."而不应该直接参照DataElement,不会出现F4帮助,也不会进行Value Check
12.10.2.检查表Check Table --- Value Table
也可以在Domain中指定一个值表(Value Table)作为字段取值范围的限制,但是与指定固定值的方式不同的是:为一个Domain简单地指定一个取值表不会导致用户的输入被自动校验,也不会自动出现F4 Help。只有通过表外键![]() 按钮将该Value Table指定为主表之后,一个值表才能真正成为Check Table。所以要想成为真正有效的Check Table,必须要做两个操作:
按钮将该Value Table指定为主表之后,一个值表才能真正成为Check Table。所以要想成为真正有效的Check Table,必须要做两个操作:
一是要为字段对应的Domain设置Value Table(即主表,其实这一步不是必须的,在通过![]() 按钮指定主表时,可以不用指定为字段所参照的元素所对应Domain所设置的Value Table,而是指定其他的主表也是可以的——但最好不要这样做,Value Check时会出其他问题),二是要为表字段通过
按钮指定主表时,可以不用指定为字段所参照的元素所对应Domain所设置的Value Table,而是指定其他的主表也是可以的——但最好不要这样做,Value Check时会出其他问题),二是要为表字段通过![]() 为它设置外键。
为它设置外键。
实质上Domain上设置的 Value Table的作用,就是在创建透明表时,字段如果参照了该Domain,则这个Value Table默认可以成为Check Table:
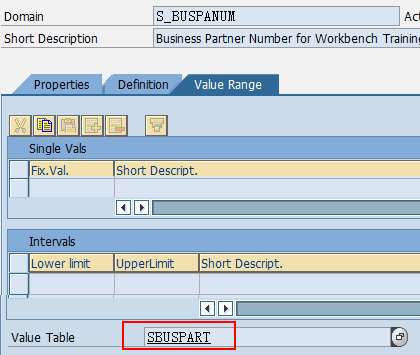
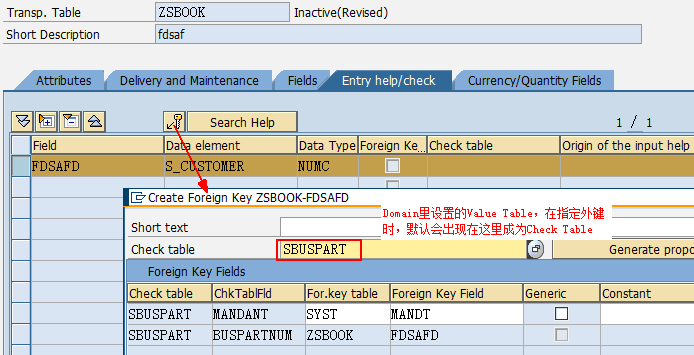
这是个默认建议,在指定外键关键时,可以指定另外的表作为Check Table
12.10.3.SE11检查表与搜索帮助关系
当某个表字段有检查表,并且又有搜索帮助,则数据一般来自源于检查表,而F4的输入输出格式则由搜索帮助来决定!
PARAMETERS p_carid TYPE sbook-carrid VALUE CHECK.
PARAMETERS p_cuter TYPE sbook-counter VALUE CHECK.
命中清单中的ID列即CARRID背景色不是蓝色,所以选择一条时,不会自动填充屏幕字段P_CARID,原因是对应的Search Help中的CARRID参数对应的EXP没有打上钩:

如果将这个钩打上,则会相应列背景色会为蓝色,且会自动填充,达到联动效果。
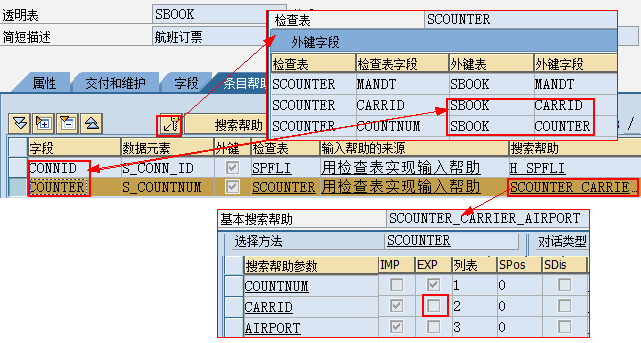
一般当某个外键所参照主表的主键上如果设置了搜索帮助(如上面COUNTER外键所引用的主表主键字段SCOUNTER-COUNTNUM已分配搜索帮助“SCOUNTER_CARRIER_AIRPORT”: ),则这个主表主键上的搜帮助会自动带到从表中相应外键上来,请看上面的SBOOK-COUNTER外键字段的搜索帮助也为“SCOUNTER_CARRIER_AIRPORT”,该搜索帮助决定了整个F4 Help处理及显示过程(如哪些列将作为联动查询条件、哪些列将显示在F4列表中、F4列表中的哪些列会输出到相应屏幕字段中)。另外,虽然主表主键上的搜索帮助会带到相应外键上来,但带过来后还可以修改,比如上面示例中带过来的搜索帮助中,CARRID参数所对应的EXP没有钩上,所以不能使用命中清单中的ID列来自动填充示例中的屏幕字段P_CARID,所以我们可以新建一个搜索帮助,并将CARRID搜索参数所对应的EXP钩上,则可达到自动上屏幕的效果;
),则这个主表主键上的搜帮助会自动带到从表中相应外键上来,请看上面的SBOOK-COUNTER外键字段的搜索帮助也为“SCOUNTER_CARRIER_AIRPORT”,该搜索帮助决定了整个F4 Help处理及显示过程(如哪些列将作为联动查询条件、哪些列将显示在F4列表中、F4列表中的哪些列会输出到相应屏幕字段中)。另外,虽然主表主键上的搜索帮助会带到相应外键上来,但带过来后还可以修改,比如上面示例中带过来的搜索帮助中,CARRID参数所对应的EXP没有钩上,所以不能使用命中清单中的ID列来自动填充示例中的屏幕字段P_CARID,所以我们可以新建一个搜索帮助,并将CARRID搜索参数所对应的EXP钩上,则可达到自动上屏幕的效果;
另外,有些外键所参照的主表主键没有指定搜索帮助,此时参照从表的屏幕字段的F4 Help就只有简单的一列了(如何让检查表SCURX中的CURRDEC字段也显示出来,请看后面的F4搜索帮助联动的决定因素),如下面SBOOK-LOCCURKEY字段:
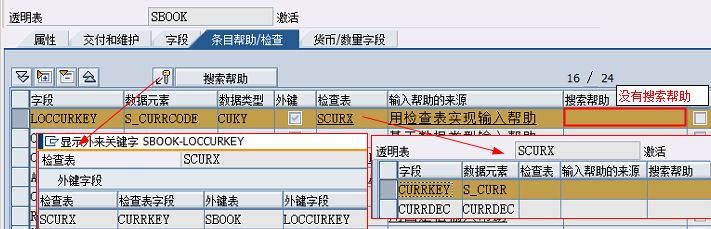
PARAMETERS p_cur TYPE sbook-LOCCURKEYVALUE CHECK.
12.10.4.F4搜索帮助联动的决定因素
上节SE11检查表与搜索帮助关系中,屏幕字段参考sbook-LOCCURKEY时,搜索帮助输出列表只有简单一列,如果要让主表中的SCURX-CURRDEC列也显示出来,则需要为sbook-LOCCURKEY字段绑定一个搜索帮助,该搜索帮助数据来源于主表(或检查表)SCURX,搜索参数包括CURRKEY、CURRDEC两列,并且让这两列在F4输出列表中显示(即在搜索参数“列表”栏位编号):
由于SBOOK不能直接修改,ZSBOOK从SBOOK拷贝过来,将搜索帮助ZSCURX_JZJ绑定到ZSBOOK-LOCCURKEY:

PARAMETERS p_cur TYPE zsbook-LOCCURKEYVALUE CHECK.
上面检查表中的SCURX-CURRDEC列(即F4中的小数位)已显示来了,但如何让其背景色为蓝色(虽然上面已将搜索参数CURRDEC的EXP打上了钩,但底色还是白色的),即选择时自动填充到屏幕上去?由于上面在将搜索帮助ZSCURX_JZJ绑定到从表字段zsbook-LOCCURKEY字段上时,搜索帮助中的搜索参数CURRDEC(即主表中的字段SCURX-CURRDEC)在从表ZSBOOK找不到相应的外键,所以上图绑定过程中,搜索参数CURRDEC为空。但在这里可以手动分配一个,由于在从表ZSBOOK中找不到此字段,所以就暂时参照自己(主表SCURX-CURRDEC)吧:
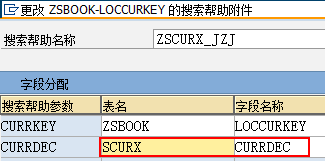
如果此时选择屏幕的代码还是上面那样:
PARAMETERS p_cur TYPE zsbook-LOCCURKEY VALUE CHECK.
则F4搜索输出列表中的“小数位”列底色还是白色,但如果加上以下屏幕参数,但会变以蓝色,并可联动(如果搜索帮助的CURRDEC参数的IMP打上钩,还可以实现联动查询):
PARAMETERS p_cur2 TYPE SCURX-CURRDEC VALUE CHECK
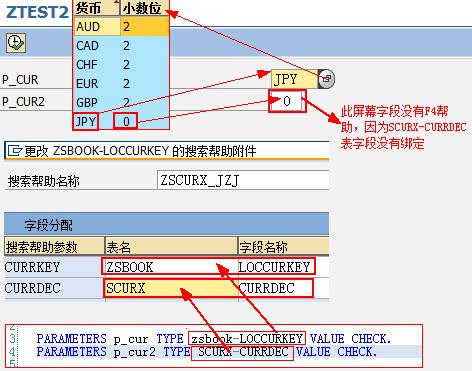
此时的下拉框也会只有两列:
PARAMETERS p_cur3 TYPE zsbook-LOCCURKEY as LISTBOX VISIBLE LENGTH 20.
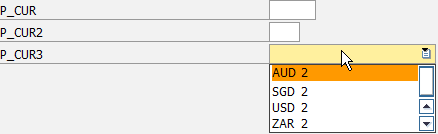
所以,联动的决定性条件是要求选择屏幕上的字段要参照SE11为表字段所绑定搜索帮助过程中所分配的表字段,如下图中的zsbook-loccurkey、scurx-currdec,这两个字段分别与搜索帮助的CURRKEY、CURRDEC参数绑定了,所以屏幕上参照这两个表字段时,就会具有联动效果了:
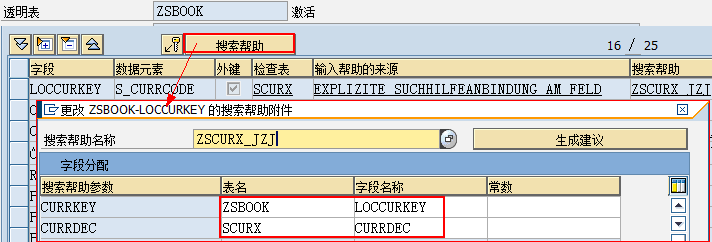
12.11.搜索帮助参数说明

² IMP:输入参数。表示屏幕上相应字段是否作为搜索帮助的过滤条件(即报表选择屏幕上的字段的值是否从报表选择屏幕上传递到搜索帮助中去)
如果是F4字段时,屏幕字段中的值包含“*”时,才会将F4字段传递到Search Help中。除开F4屏幕字段外,而其他只要是Link到了相应的Search Help参数的屏幕字段,只要相应屏幕字段中有值,则会传入到搜索中作为过滤条件(而其他非F4屏幕字段所对应的Help参数不管是否钩上IMP都会传递?)
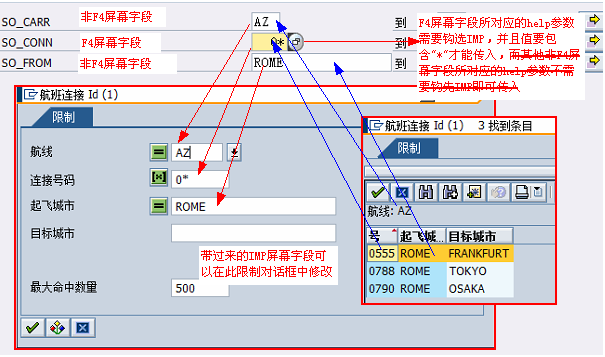
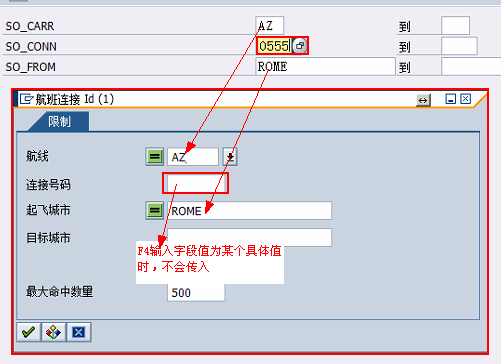
² EXP:输出参数,表示搜索帮助的此列会从搜索帮助中传递到报表选择屏幕上(表示F4选中一条记录后显示到屏幕上文本框中的值——背景字段为浅蓝色的列的数据会被输出,输出的数据可能是多列。注:只有当EXP钩上且相应字段出现在了屏幕上,才会自动填充到相应屏幕字段,如果没有钩上——没钩上的字段背景色为白色,即使相应参数字段出现在了屏幕上,选择命中清单时也不会自动填充),且F4字段一定要将EXP钩上(否则选择后F4字段不能上屏)。
² LPOS(列表):F4输出命中清单中各列的显示顺序,如果为0或留空的列则不会显示
² SPOS:相应的字段是否在搜索帮助选择屏幕上显示出来,在命中清单显示之前,如果弹出限制对话框,则可以进一步修改那些从选择屏幕上带过来的条件值。此数字就是限制搜索帮助选择条件屏幕字段摆放顺序,如果为0或留空的列则不会出在限制条件页中
² SDis:如果勾选了,则在弹出的限制对话框中对应的字段用户不可输入,是只读的。
12.12.F4IF_SHLP_EXIT_EXAMPLE帮助出口
12.12.1.修改数据源
FUNCTION zfvbeln_find_exit.
*"----------------------------------------------------------------------
*"*"Local Interface:
*" TABLES
*" SHLP_TAB TYPE SHLP_DESCT
*" RECORD_TAB STRUCTURE SEAHLPRES
*" CHANGING
*" VALUE(SHLP) TYPE SHLP_DESCR
*" VALUE(CALLCONTROL) LIKE DDSHF4CTRL STRUCTURE DDSHF4CTRL
*"----------------------------------------------------------------------
"此内表用于存储命中清单数据.注:字段的名称一定要与搜索参数名一样,但顺序可以不同,
DATA: BEGIN OF lt_tab OCCURS 0,
wbstk TYPE wbstk,
lfdat TYPE lfdat_v,
vbeln TYPE vbeln_vl,
END OF lt_tab.
"用于存储从选择屏幕上传进的屏幕字段的选择条件值
DATA: r_vbeln TYPE RANGE OF vbeln_vl WITH HEADER LINE,
r_lfdat TYPE RANGE OF lfdat_v WITH HEADER LINE,
r_wbstk TYPE RANGE OF wbstk WITH HEADER LINE,
wa_selopt LIKE LINE OF shlp-selopt."
"callcontrol-step该字段的值是由系统设置,并且你可以在程序中进行修改它。出口函数会在处理的每一步(时间点)都会调用一次
IF callcontrol-step = 'SELECT'."如果有弹出限制对话框,则会在弹出限制对话框中点击确认按钮后step值才为SELECT
"shlp-selopt存储的是经过映射转换后选择屏幕上字段的值,而不是直接为
"选择屏幕字段名,而是转映射为Help参数名后再存储到 selopt 内表中,
"屏幕字段到Help参数映射是通过 shlp-interface 来映射的
LOOP AT shlp-selopt INTO wa_selopt.
CASE wa_selopt-shlpfield.
WHEN 'VBELN'."由于屏幕字段已映射为了Help相应参数,所以这里不是S_VBELN
MOVE-CORRESPONDING wa_selopt TO r_vbeln.
APPEND r_vbeln.
WHEN 'LFDAT'.
MOVE-CORRESPONDING wa_selopt TO r_lfdat.
APPEND r_lfdat.
WHEN 'WBSTK'.
MOVE-CORRESPONDING wa_selopt TO r_wbstk.
APPEND r_wbstk.
ENDCASE.
ENDLOOP.
"根据屏幕上传进的条件查询数据
SELECT likp~vbeln likp~lfdat vbuk~wbstk INTO CORRESPONDING FIELDS OF TABLE lt_tab
FROM likp INNER JOIN vbuk ON likp~vbeln = vbuk~vbeln
WHERE likp~vbeln IN r_vbeln AND
likp~lfdat IN r_lfdat AND
vbuk~wbstk IN r_wbstk.
"该函数的作用是将内表 lt_tab 中的数据转换成record_tab,即将某内表中的数据显示在命中清单中
CALL FUNCTION 'F4UT_RESULTS_MAP'
TABLES
shlp_tab = shlp_tab
record_tab = record_tab
source_tab = lt_tab
CHANGING
shlp = shlp
callcontrol = callcontrol.
"注:下一个时间点一定要直接设置为 DISP,否则命中清单不会有值,也不显示出来
"从表面上看,SELECT时间点下一个就是DISP时间点,按理是不需要设置为DISP,
"但如果不设置为DISP,出口函数在执行完后,系统会转入DISP时间点执行(即再次调用此出口函数)
",但再次进入此出口函数时,record_tab内表已经被清空了(是否可以通过判断callcontrol-step的值来决定走什么新的逻辑代码来解决此问题?)。如果这里直接设置为DISP,就好比欺骗了系统一样,告诉系统当前执行的正是DISP时间点,而不是SELECT,系统就不会再转到DISP时间点了而是直接显示
callcontrol-step = 'DISP'. "DISP:在命中清单显示之前调用,表示数据已经查出,下一步就该显示了。该时间用于控制搜索帮助的输出结果。例如,在输出搜索结果时对用户检查权限,删除未授权的数据
ENDIF.
ENDFUNCTION.
12.12.2.删除重复
FUNCTION zeh_lxsecond.
IF callcontrol-step = 'DISP'.
SORT RECORD_TAB.
DELETE ADJACENT DUPLICATES FROM RECORD_TAB COMPARING ALL FIELDS."zsecond.
EXIT.
ENDIF.
ENDFUNCTION.
12.13.搜索帮助优先级
先PROCESS ON VALUE-REQUEST,AT SELECTION-SCREEN ON VALUE-REQUEST
再PARAMETERS/ SELECT-OPTIONS MATCHCODE OBJECT
先检查表Check Table,再表(或结构)字段是否绑定了搜索帮助
先data element是否绑定了帮助,再domain是否存在fixed values
最后才是DATS、TIMS
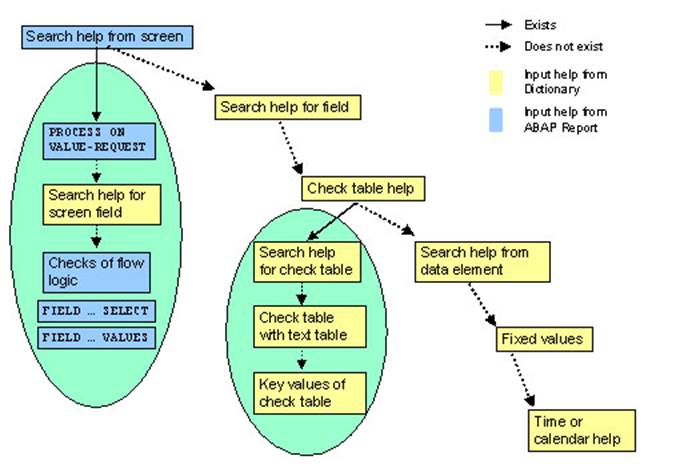
Domain只设置Value Table也可以出F4,同时Data Element绑定了搜索帮助,则DataElement上绑定的搜索帮助优先于Domain上的Value Table????????
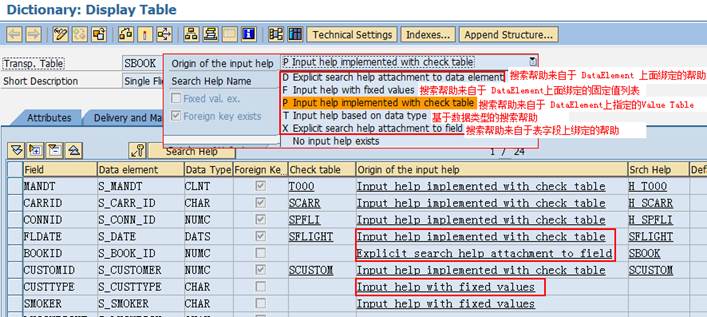
12.14.搜索帮助创建函数
在屏幕的ON VALUE-REQUEST事件里可以通过下面几个函数来创建搜索帮助:
F4IF_FIELD_VALUE_REQUEST:函数的作用是在运行时,可以动态的为某个屏幕字段指定Search Help,这个被引用的Help来自某个表(或结构)字段上绑定的Help
F4IF_INT_TABLE_VALUE_REQUEST:在程序运行时,将某个内表动态的用作Search help的数据来源,即使用该函数可以将某个内表转换为Search help,可实现联动效果
TR_F4_HELP:简单实现Search Help,数据来源于内表
12.15.在POV事件里读取屏幕字段中的值函数
在POV(包括选择屏幕上 AT SELECTION-SCREEN ON VALUE-REQUEST事件)事件中,屏幕上的字段的值不像PAI里那样可以直接读取到,所以使用以下两个函数来读写:
DYNP_VALUES_READ、DYNP_VALUES_UPDATE
12.16.动态修改屏幕
选择屏幕、对话屏幕都有对应的SCREEN内表,下面是几个重要属性:
NAME:Name of the screen field。如果参数是select-options类型参数,则参数名以LOW与HIGH后缀来区分。
GROUP1:选择屏幕元素通过MODIF ID选项设置GROUP1(对话屏幕通过属性设置),将屏幕元素分为一组,方便屏幕的元素的批量修改
REQUIRED:控制文本框、下拉列表屏幕元素的必输性,使用此属性后会忽略OBLIGATORY选项。取值如下:
0:不必输,框中前面也没有钩
1:必输,框中前面有钩,系统会自动检验是否已输入,相当于OBLIGATORY选项
2:不必输,但框中前面有钩,系统不会检查是否已输入,此时需要手动检验
INPUT:控制屏幕元素(包括复选框、单选框、文本框)的可输性
ACTIVE:控制屏幕元素的可见性
REQUIRED选项的应用:该选项可以解决这个问题:在点击某个单选框(p_rd1)后显示某个必输字段(p_lclfil),但当这个必输框显示出来后,如果点击p_rd2想隐藏它时,此时输入框中必须有值,否则系统会自动检验要求重新输入。现要求输入框没有输入值的情况下,也可在点击p_rd2时隐藏它,则解决的办法是:将输入框的这个属性设置为2(显示必须的钩,但系统不会自动进行必输验证),去掉OBLIGATORY选项(不去掉也会被忽略),并在AT SELECTION-SCREEN ON field事件里时手动进行为空验证
"一定要设置 USER-COMMAND ,否则点击之后,不会触发屏幕PAI事件,PAI事件不触发则会导致
"屏幕的AT SELECTION-SCREEN OUTPUT也就不会被触发(非执行按钮的FunCode触发时都会刷新
"屏幕,所以再次显示屏幕时再次执行PBO)
PARAMETERS p_rd1 RADIOBUTTON GROUP gp1 USER-COMMAND mxx."用来隐藏 p_lclfil
PARAMETERS p_rd2 RADIOBUTTON GROUP gp1 DEFAULT 'X'."用来显示 p_lclfil
"当通过程序动态修改屏幕元素属性 required 后,会忽略掉这里的 OBLIGATORY 选项
*PARAMETERS p_lclfil(128) AS LISTBOX VISIBLE LENGTH 20 MODIF ID mxy OBLIGATORY .
PARAMETERS p_lclfil(128) MODIF ID mxy OBLIGATORY .
PARAMETERS: c AS CHECKBOX."没什么作用,用来测试 CHECKBOX 的可输入性
"当 C2 被钩选时,屏幕上的其他输入元素均不可输入
PARAMETERS: c2 AS CHECKBOX USER-COMMAND ddd DEFAULT 'X'.
AT SELECTION-SCREEN OUTPUT.
LOOP AT SCREEN .
"当 C2 没有钩选时,其他元素都设置为可输入
IF screen-name <> 'C2' AND c2 IS INITIAL .
screen-input = 1.
MODIFY SCREEN.
ELSEIF screen-name <> 'C2' AND c2 IS NOT INITIAL .
screen-input = 0."C2钩选时,所以屏幕输入元素禁止输入
MODIFY SCREEN.
ENDIF.
"控制下拉列表(文本框也是一样)的必输性:外观上打钩,但不自动校验
IF p_rd2 = 'X' AND screen-group1 = 'MXY'.
"显示
screen-active = '1'.
* screen-input = '1'."显示前设为可输入
screen-required = '2'."外观上打钩,但不自动校验
MODIFY SCREEN.
ELSEIF screen-group1 = 'MXY'. "
"隐藏
screen-active = '0'.
screen-required = '2'.
MODIFY SCREEN.
ENDIF.
ENDLOOP.
AT SELECTION-SCREEN ON p_lclfil.
IF p_rd2 IS NOT INITIAL"手动检验:但当点击单选按钮与复选框 C2 时,不校验
AND sy-ucomm <> 'MXX' AND sy-ucomm <> 'DDD' AND p_lclfil IS INITIAL.
MESSAGE e055(00).
ENDIF.
12.17.子屏幕
除通过屏幕的属性将某个屏幕设置为子屏幕外,还可以通过程序创建一个子屏幕:
SELECTION-SCREEN BEGIN OF SCREEN dynnr AS SUBSCREEN.
...
SELECTION-SCREEN END OF SCREEN dynnr.
l子屏幕可以嵌入到Tabstrip中使用:
SELECTION-SCREEN BEGIN OF TABBED BLOCK tblock FOR n LINES.
SELECTION-SCREEN TAB (len) tab USER-COMMAND fcode DEFAULT SCREEN dynnr.
... tab:Tab的标题;len:Tab标题显示的宽度;Tab页签内容的行数由n来决定;DEFAULT SCREEN:给Tab静态分配子屏幕
SELECTION-SCREEN END OF BLOCK tblock.
l通过CALL SUBSCREEN语句将子屏幕嵌入到对话屏幕中:
PROCESS BEFORE OUTPUT.
CALL SUBSCREEN <area> INCLUDING [<prog>] <dynp>.
...子屏幕都需要放在主屏幕中的某个指定的<area>区域元素中
为了调用子屏幕的PAI事件,需要在主屏幕的PAI flow logic里如下调用:
PROCESS AFTER INPUT.
CALL SUBSCREEN <area>.
...
普通选择屏幕,可以使用CALL SELECTION-SCREEN来单独调用
12.18.屏幕跳转
LEAVE SCREEN.
or
LEAVE TO SCREEN <next screen>.
LEAVE SCREEN语句会结束当前屏幕并调用下一屏幕,next scree可以是static next screen,或者是dynamic next screen,如果是动态的,你必须在使用LEAVE SCREEN语句前使用SET SCREEN语句来重写static next screen
LEAVE TO SCREEN语句会结束当前屏幕并跳转到指定的下一屏幕<next screen>,其作用等效于下面两条语句:
SET SCREEN <next screen>.
LEAVE SCREEN.
这两个语句不会结束屏幕序列,它们仅仅是转向同一屏幕序列中的另一屏幕。屏幕序列是否结束要看<next screen>是否为0或者屏幕的next screen属性是否设置为0
可以用LEAVE TO SCREEN 0来结束当前SCREEN SEQUENCE
12.18.1.CALL SCREEN误用
每次碰到CALL SCREEN语句就会产生新的SCREEN SEQUENCE,而且SAP系统设置了SCREEN SEQUENCE堆栈不能超过50个,一旦超过就会出溢出错误,所以不要使用 CALL SCREEN 进行屏幕的切换
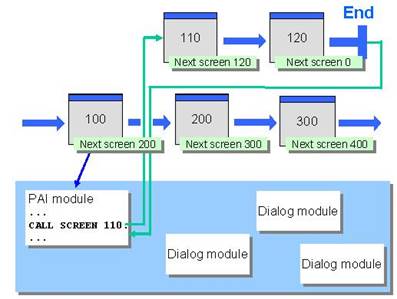
为了避免产生新的SCREEN SEQUENCE,针对上图,可以使用LEAVE...SCREEN进行屏幕切换,而不是CALL SCREEN:
SET SCREEN 110."该语句只是动态制定下一个屏幕,但不结束当前屏幕处理(即不立即跳转下一屏幕),只有LEAVE SCREEN才会结束屏幕的处理(后面的语句才不会执行)
LEAVE SCREEN.
或者使用:LEAVE TO SCREEN 110.相当于上面两包的组合:SET SCREEN 110. LEAVE SCREEN.
请使用SET SCREEN XXX / LEAVE SCREEN,LEAVE TO SCREEN XXX来在同一屏幕序列里动态的进行屏幕切换跳转,而不要使用CALL SCREEN XXX进行屏幕序列的跳转与切换
12.18.2.CALL SCREEN/SET SCREEN/LEAVE TO SCREEN区别
CALL SCREEN XXXX将在Screen调用栈(CALL STACK)上面添加一层调用(进栈,即重新开启一个新的屏幕序列),调用XXXX的PBO和PAI,如果XXXX的Next Screen不为0,那么将继续其Next Screen的PBO和PAI,如此继续~~~当最后碰到Next Screen为0时,该层调用将从调用栈中退出(出栈),然后系统将继续执行CALL SCREEN XXXX之后的语句。
SET SCREEN XXXX设置调用栈当前层次的Next Screen为XXXX,它并不影响调用栈的层数(即不会重新开启一个新的屏幕序列,只做屏幕之间的切换,而不是屏幕序列之间的切换),除非XXXX为0,那将导致调用栈退掉一层(出栈)。要注意的是,PAI中SET SCREEN XXXX后的语句,系统将照样执行,只有执行完毕该PAI整个逻辑后,才考虑Next Screen的PBO和PAI。
LEAVE TO SCREEN XXX与SET SCREEN XXX比较类似(也不会重新开启一个新的屏幕序列,只做屏幕之间的切换,而不是屏幕序列之间的切换),所不同的是,LEAVE TO SCREEN XXXX将强行中断当前SCREEN的PAI,直接执行XXXX的PBO和PAI。换言之,PAI中LEAVE TO SCREEN XXXX后面的语句,系统将不会执行到。
LEAVE SCREEN.后面的语句也不会执行
注:上面语句的XXX也可以是选择屏幕的屏幕号,而不只是对话屏幕号
CALL SCREEN是将正在运行的画面挂起,进入所调用的画面,当使用LEAVE TO SCREEN 0时,能够返回原主调画面,可理解为嵌套调用;而LEAVE TO SCREEN是立即结束本画面的执行,调用所指定的画面,在调用画面中,无法再返回原主调画面。
12.19.修改标准选择屏幕的GUI Status
选择屏幕的GUI status是由系统自动生成的,标准选择屏幕的PBO事件里(即AT SELECTION-SCREEN OUTPUT)的SETPF-STATUS语句将不会再起作用。如果想修改标准选择屏幕的GUIstatus(或去激活标准选择屏幕上的GUI Status上预设的功能),则可以在选择屏幕的PBO(AT SELECTION-SCREEN OUTPUT)事件里调用RS_SET_SELSCREEN_STATUS函数来实现。
12.20.事件分类
12.20.1.报表事件
INITIALIZATION.
START-OF-SELECTION.
END-OF-SELECTION.
12.20.2.选择屏幕事件
在INITIALIZATION和START-OF-SELECTION之间触发,对应于对话屏幕的 PBO、PAI、POH、POV事件
AT SELECTION-SCREEN { OUTPUT }
| { ON {para|selcrit} }
| { ON END OF selcrit }
| { ON BLOCK block }
| { ON RADIOBUTTON GROUP radi }
| { ON {HELP-REQUEST|VALUE-REQUEST}
{ FOR {para|selcrit-low|selcrit-high} }
| { ON EXIT-COMMAND }
| { }.
12.20.3.逻辑数据库事件
GET node [LATE] [FIELDS f1 f2 ...].
12.20.4.列表事件
TOP-OF-PAGE.
END-OF-PAGE.
AT LINE-SELECTION.
AT USER-COMMAND.
AT pf<nn>.
12.20.5.事件流图
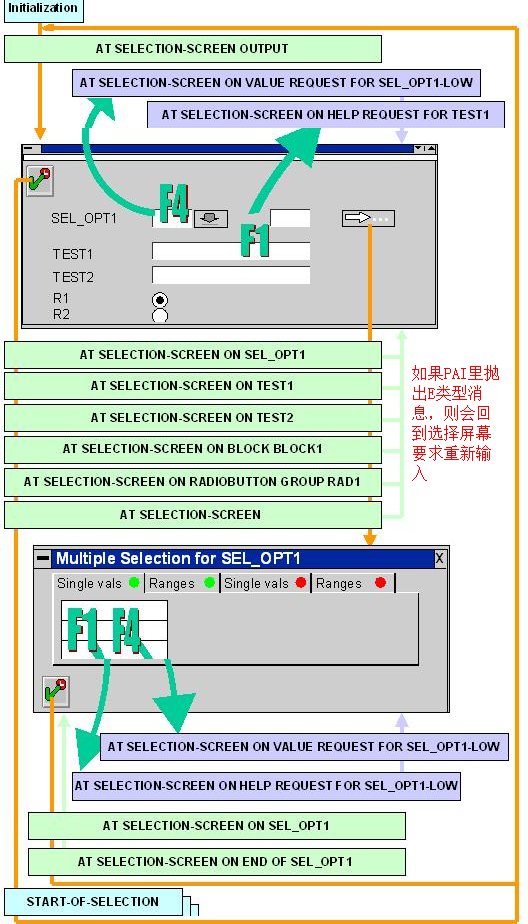
12.21.事件终止
12.21.1.RETURN
RETURN用来退出当前执行的程序块,例如一个FORM、METHOD、报表事件块,不管是否出现在循环(LOOP)中,RETURN都会退出当前执行的程序块,而不仅仅是退出循环(如果是在Form、METHOD中,只会退出Form、METHOD,不会退出Form、METHOD被调用所在的报表事件块,即退Form、METHOD后继续向被调用点后面执行)
12.21.2.STOP
l INITIALIZATION中的STOP会导致跳转到AT SELECTION-SCREEN OUTPUT事件块;
l 如果STOP在AT SELECTION-SCREEN OUTPUT块里,则只是退出当前块(STOP后面语句不执行而已),仅接着是显示选择屏幕;
l AT SELECTION-SCREEN [ON]…选择屏幕事件块中的STOP也只是退出当前事件块,继续后面的事件块;
l 另外,即使STOP在循环中,还是在FORM,METHOD,也是直接从被调用的点退出所在事件块,而不仅仅只退出当前循环、FORM、METHOD,这与直接在事件块中的效果是一样的;
RETURN用来退出当前执行的程序块(processing block),例如一个FORM,METHOD,或EVENT,不管是否出现在循环(LOOP)中,RETURN都会退出当前执行的程序块,而不仅仅是退出循环。
虽然ABAP中EXIT 和RETURN都可以用来实现退出当前执行的语句块,但SAP的帮助文件建议只在循环中使用EXIT ,其他情况下要退出当前执行进程,使用RETURN 。
12.21.3.EXIT
l INITIALIZATION中的EXIT会导致跳转到AT SELECTION-SCREEN OUTPUT事件块;
l 如果EXIT在AT SELECTION-SCREEN OUTPUT块里,则只是退出当前块(EXIT后面语句不执行而已),仅接着是显示选择屏幕;
l AT SELECTION-SCREEN [ON]…选择屏幕事件块中的EXIT也只是退出当前事件块,继续后面的事件块;
l 从START-OF-SELECTION开始往后的事件块,如果出现EXIT,则会开始listprocessor(列表处理),并跳转到相应的List输出界面(前提条件是要在退出前已经向屏幕输出内容了,否则也不会跳转);注:END-OF-SELECTION事件块也会被跳过
l 另外,如果EXIT在循环(DO、WHILE、LOOP)里,只是跳出当前循环而已;
l 如果是在FORM,METHOD中,而非循环中,则退出当前的FORM、METHOD,其作用与RETURN类似
1) EXIT如果出现在循环中,退出的是整个循环操作,.程序会从循环结束处开始继续执行,其作用相当于Java与C++中的break。
2)EXIT如果出现在循环之外,退出的是当前执行的程序块(processing block),例如一个FORM,METHOD,或EVENT,其作用与RETURN类似。
12.21.4.CHECK
CHECK跳转的前提是<expr>为假时。
l CHECK只是跳出当前事件块,继续下一个事件块的处理,相当于方法的return;
l 另外,如果CHECK在循环(DO、WHILE、LOOP)里,只是跳出当前循环而已;
l 如果CHECK出现在循环以外,退出的是当前执行的程序块(processing block),例如一个FORM,METHOD,或EVENT。
1)CHECK 后面要跟一个表达式,当表达式值为假(false)时,CHECK发生作用,退出循环(LOOP)或处理程序(Processing Block)。
2)如果CHECK出现在循环中,则发生作用时,退出的是当前一次循环操作,程序会继续执行下一次循环操作,其作用类似于Continue (Java 或C++中continue也是如此).
3)如果CHECK出现在循环以外,则发生作用时,退出的是当前执行的程序块(processing block),例如一个FORM,METHOD,或EVENT。
12.21.5.LEAVE
LEAVE PROGRAM. 退出整个程序
LEAVE TO TRANSACTION ta
LEAVE LIST-PROCESSING. 从list processor回到dialog processor
LEAVE TO LIST-PROCESSING 控制权从dialog processor转交给list processor
LEAVE { SCREEN | {TO SCREEN dynnr} }
12.21.5.1.REJECT
REJECT是用在逻辑数据库GET event blocks中,与EXIT和CHECK不一样的是(EXIT和CHECK如果是在循环中时,只是退出循环;如果是在FORM中,则只是退出当前FORM),REJECT可以从循环或者一个FORM中直接跳出所在的GET事件块:
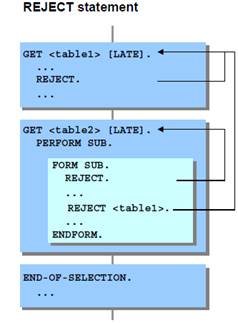
REJECT [<dbtab>].
终结逻辑数据库当前节点数据行的处理
如果省略选项<dbtab>, 则逻辑数据库会自动读取同一节点的下一行数据,即同一节点的GET事件块会被触发。如果使用了<dbtab>选项,则逻辑数据库会读取节点<dbtab>的下一行数据,此时的<dbtab>节点必须是REJECT所在当前节点的上级节点。
13.列表屏幕
在START/END-OF-SELECTION事件处理块中,用WRITE语句向列表缓冲区(List Buffer)输出要显示的内容,当该事件结束的时候,所有在列表缓冲区中的内容将被显示到一个基本列表屏幕(Basic List)上
当用户在基础列表屏幕上双击一行或按功能键“F2”时,将会触发ABAP事件AT LINE-SELECTION,如果还想进一步显示该行数据的详细信息,则可以继续使用WRITE语句输出要显示的内容,这次生成另外一个详细列表屏幕(Details List Screen)。此详细列表屏幕将覆盖其上一层的基础列表屏幕,若在其界面的工具条上点“返回”或按功能键F3,将返回到基础列表屏幕。
在详细列表屏幕上,当用户双击一行数据或按功能键F2,AT LINE-SELECTION事件将会再次触发,因此还可以继续生成下一级的详细列表屏幕
ABAP提供了全屏变量sy-lsind来区别屏幕的层次,sy-lsind的值主要用于在 AT LINE-SELECTION事件处理块中进行程序流程控。0表示为基础列表屏幕,1表示第一级详细列表屏幕,依次类推,最多可以有20个详细列表
13.1.标准LIST

至少包括二行standard header,第一行standard header包括了listheader和pagenumber,第二行standard header是一条水平线。当程序是可执行报表程序时,listheader存储在SY-TITLE中。如果有必要,可以给standardheader添加最多四行的columnheaders与一条水平线。在水平或垂直滚动时standardheader是不会动的。

13.2.自定义LIST
TOP-OF-PAGE.
REPORT <rep> NO STANDARD PAGE HEADING.
REPORT <rep> LINE-SIZE <width> 当前页面宽度存储在SY-LINSZ系统变量中
REPORT <rep> LINE-COUNT <length>[(<n>)] 如果指定了<n>参数,系统会保留<n>行给page footer,页面的实际可输出正本行数为<length>减去page header length,再减去<n>。每页的行数包含了列表头(headings)、列表内容与列表脚注行(footer lines);系统变量SY-LINCT会存储页面行数<length>,注意:如果REPORT语句没有设置该值,则该系统变量值为0,除非使用NEW-PAGE语句进行了设置。
SY-PAGNO系统变量存储了当前页码
END-OF-PAGE. 触发的条件是数据要满一页时才触发,否则不会被触发
NEW-PAGE
RESERVE <n> LINES 在调用此语句时,如果最后一次输出到Page Footer之间所剩行小于(注意:等于时不会分页)<n>时会进行分页,在开始新页之前会触发END-OF-PAGE事件(如果最后一页数据不足一页,还是不会显示页脚)
NEW-PAGE [NO-TITLE|WITH-TITLE] [NO-HEADING|WITH-HEADING] WITH-TITLE、NO-TITLE:控制NEW-PAGE新开启的页面以及后面使用NEW-PAGE开启的页面是否使用标准的list header
NO-HEADING、WITH-HEADING:控制NEW-PAGE新开启的页面以及后面使用NEW-PAGE开启的页面是否使用标准的column header
NEW-PAGE LINE-COUNT <length> 系统变量SY-LINCT会存储页面行数(即<length>)。该选项决定了随后的所有(除非又重新通过该语句的这个选项重新指定了)使用NEW-PAGE语句分出的页面的允许的最大数据行数
NEW-PAGE LINE-SIZE <width> SY-SCOLS:存储了当前窗口在没有滚动条的情况下允许的最大字符数(或叫Column),而LINE-SIZE选项指的是列表本身最大允许的字符数,与窗口大小没有关系(如果LIST列表的宽度LINE-SIZE大于了窗口允许的最大字符数SY-SCOLS,则会出现滚动条,否则窗口不会出现滚动条)
13.3.LIST事件
AT PF<nn>(obsolete)已过时
键盘上的F<nn>(01 到 24)键不再具有系统预置功能,它们都将与function codes PF<nn>关联
AT LINE-SELECTION
当用户在LIST屏幕上的某行上按F2或者鼠标双击时,就会触发该事件块,并且此时的function code默认名为PICK
AT USER-COMMAND
除上面PF<nn>与PICK两个Function code以外,其他的function codes将被runtime environment(预置按钮的FunCode会被运行时环境捕获)拦截或者是触发AT USER-COMMAND事件。
除了通过手动触发LIST屏幕事件之外,还可以直接通过编程的方式来触发:
SET USER-COMMAND <fc>.
该语句会在当前列表事件块里的所有输出结束后生效(这意味着该语句放在输出语句的前后都没有关系),并在列表显示之前触发与<fc>对应的事件。其作用与用户手动选择了相应的Function Code是一样的
13.4.Detail Lists 创建
凡事在AT PF<nn>、AT LINE-SELECTION、AT USER-COMMAND三个事件块里输出的内容,都会创建一个新的detail lists
13.5. 标准的 List Status
如果在报表程序中没有设置(Basic List与Detail List都未设置时)GUI status,则系统会将list screen的Status设置为系统内置的default list status;在其他类型的程序中(如当你在Screen中创建一个list时),你可以明确的调用下面语句来设置成系统内置的default list status:
该语句定义了Standard List所拥有的默认functions,系统所提供的内置default list status如下(这些功能都已实现,可直接使用):

13.6.列表屏幕上的数据与程序间的传递
13.6.1.SY-LISEL
SY-LISEL类型为C(255),它是将整行的内容都存储下来了,所以要取得每个Field,则需要通过offset方式来截取
13.6.2.HIDE
HIDE <f>.
变量<f>可以是整行或部分输出列的变量,甚至是其他与行内容无关的变量。
当单击List屏幕中的行时,如果对应的行设置了隐藏字段,则HIDE隐藏字段变量<f>会自动被存储值填充,当然也可以使用READ LINE来手动控制读取填充隐藏域
注:局部变量不能存储到HIDE区域中
语句要在数据行被WRITE语句输出到列表缓冲区后,在后面紧着编写(为了隐藏的数据与当前输入的数据一致),并且当被双击时,保存在隐藏域中的字段的值将自动被传回到原始字段中
隐藏域实质上是一个内表,其行结构包含了三个字段:被选中行的行号、字段名、字段值,当保存数据时,每个被保存的字段在隐藏域中形成一行:
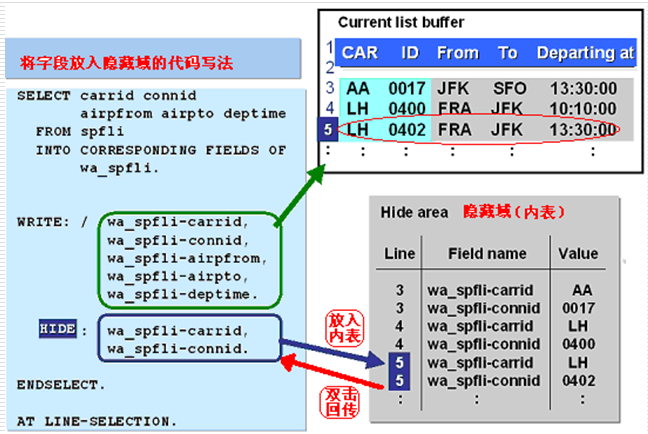
上图中已将wa_spfli-carrid、wa_spfli-connid存入了隐藏域中了,所以在双击行后,可以直接使用AT LINE-SELECTION.事件中使用
13.6.3.READ LINE
READ LINE <lin> [INDEX <idx>]
[FIELD VALUE <f1>[INTO <g1>]...<fn>[INTO <gn>]] [OF CURRENT PAGE|OF PAGE <p>].
该语句会将事件触发所在的List((index SY-LILLI))中的第<lin>行的内容存储到SY-LISEL系统变量中,并且随之将<lin>行所对应的HIDE字段也进行相应填充。另外会将Write显示输出的名为<fn>字段的值存储到<gn>全局变量中
13.7. 从Screen Processing 屏幕处理切换到Lists列表输出
为了将dialog processor控制权转交给list processor,你可在PBO dialog modules 中调用下面这样的语句:
LEAVE TO LIST-PROCESSING[AND RETURN TO SCREEN<nnnn>]
该语句可以使用在PBO 或者PAI event中,它的作用是在当前屏幕的PAI processing(一般在PBO块里使用SUPPRESS DIALOG.或LEAVE SCREEN.语句后不会显示这个屏幕,此时在PBO事件块结束后立即显示Basic List)结束后开始list processor并显示Basic List。调用该语句所在屏幕的PBO and PAI modules中的list output都会被输出到Basic List中缓存起来,待该屏幕处理完后显示(如果没有在PBO中使用SUPPRESS DIALOG.或LEAVE SCREEN.语句,则在PAI结束后显示;如果使用了这两个语句,则会在PBO块结束后就会显示)
可以使用以下两种方式来离开list processing:
• 在basiclist中点击Back,Exit,orCancel
• 在list processing程序中使用:LEAVE LIST-PROCESSING.
以上两种方式都会使控制权从list processor转交到dialog processor。
在默认的情况下,不带AND RETURN TO SCREEN选项的LEAVE TO LIST-PROCESSING语句在当list processor 处理结束后(如关闭list列表输出窗体时),dialog processor将会又会返回到LEAVE TO LIST-PROCESSING语句调用所在屏幕的PBO事件块,并重新执行PBO事件块(所以这样使用会出现死循环:关不掉List列表输出窗口);选项AND RETURN TO SCREEN允许你指定当前屏幕序列(即LEAVE TO LIST-PROCESSING语句调用所在屏幕所在的屏幕序列)中的某个屏幕,当list processor 处理结束后,dialog processor将会回到指定的屏幕并执行其相应的PBO事件块
13.8.LIST 打印输出
打印参数设置:
SET_PRINT_PARAMETERS
GET_PRINT_PARAMETERS
从程序中启动打印:NEW-PAGEPRINTON
14.Messages
14.1.00消息ID中的通用消息
00消息ID中的001消息本身未设置任何消息串,这条消息可以传递8个参数,在用于拼接消息时很有用

MESSAGE e001(00) WITH 'No local currecny maintained for company:' p_bukrs.
14.2.消息常量
直接显示消息常量,不引用消息ID与消息号
MESSAGE 'aaaa' TYPE 'S'.
14.3.静态指定
MESSAGE <t><nnn>(<id>) [with<f1>... <f4>][raising <exc>].
MESSAGE s002(00).
14.4.动态指定
MESSAGE ID <id> TYPE <t> NUMBER <n> [with<f1>...<f4>] [raising <exc>].
DATA: t(1) VALUE 'S',
id(2) VALUE '00',
num(3) VALUE '002'.
MESSAGE ID id TYPE t NUMBER num.
14.5.消息拼接MESSAGE …INTO
DATA mtext TYPE string.
CALL FUNCTION ... EXCEPTIONS error_message = 4.
IF sy-subrc = 4.
MESSAGE ID sy-msgid TYPE sy-msgty NUMBER sy-msgno
INTO msgtext
WITH sy-msgv1 sy-msgv2 sy-msgv3 sy-msgv4.
ENDIF.
14.6.修改消息显示性为…DISPLAY LIKE…
此种方式不会影响到消息本身的处理性为,只是改变了消息的显示图标类型,如下面只是改变了S类型消息在状态栏中以错误图标来显示(本来是绿色状态图标):
MESSAGE msg TYPE 'S' DISPLAY LIKE 'E'.
14.7. RAISING <exc>:消息以异常形式抛出
MESSAGE ID 'SABAPDEMOS' TYPE MESSAGE_TYPE NUMBER '777'
WITH MESSAGE_TYPE MESSAGE_PLACE MESSAGE_EVENT
RAISING MESS.
当使用该选项后,并且如果在调用的地方(CALL FUNCTION或者是 CALL METHOD的地方)使用了EXCEPTION选项来捕获RAISING抛出的异常,则不再以MESSAGE的原有形式来显示消息,而是被主调捕获后进一步处理或者是程序Dump(A、E、W、I、S类型都能被捕获到,但X类型的Message不会走到被主调者捕获这一步,因为在被调程序中就宕掉了);反过来,当主调者未使用EXCEPTION选项(或者使用了但未捕获到所抛出的异常),则RAISING选项会被忽略,MESSAGE语句会按照无RAISING选项时那样运行(弹框还是在状态栏中显示、以及程序是否终止等性为、还是转换为error_message抛出)
如果加了选项RAISING时:MESSAGE... RAISING <exc>,此时的Message 的处理方式与是否显示,就要依赖于主调者在调用时,是否加上了exception <exc>选项:
1、如果调用时没有带exception <exc>选项,此时Message语包中的RAISING <exc>选项抛出的异常将会被忽略,Message语句会当作正常消息来处理
2、如果调用时加上了exception <exc>选项对exc 异常进行了捕获,则不会再显示消息(但如果即使加上了exception选项,但没有捕获到exc异常,则此时会忽略RAISING选项),并设置sy-subrc。只要异常被捕获,相关消息内容将会入存入到SY-MSGID,SY-MSGTY, SY-MSGNO, and SY-MSGV1 to SY-MSGV4有关系统变量中。
下面程序中,第一次调用时中会弹出消息框(因为没有使用EXCEPTIONS选项捕获),而第二次不会弹出消息框,也不会在状态栏中显示,而是被后继程序捕获后输出:
CLASS c1 DEFINITION.
PUBLIC SECTION.
CLASS-METHODS m1 EXCEPTIONS exc1.
ENDCLASS.
CLASS c1 IMPLEMENTATION.
METHOD m1.
MESSAGE 'Message in a Method' TYPE 'I' RAISING exc1.
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
c1=>m1( )."第一次调用
c1=>m1( EXCEPTIONS exc1 = 4 )."第二次调用
IF sy-subrc = 4.
write: / '被捕获'.
ENDIF.
14.8.CALL FUNCTION…EXCEPTIONS
CALL FUNCTION func [EXCEPTIONS
[exc1= n1 exc2= n2]
[others= n_others] ]
[ERROR_MESSAGE = n_error].
exc1,exc2...与OTHERS异常只能捕获到MESSAGE...RAISING选项或RAISE语句抛出的异常,而error_message是无法捕获MESSAGE...RAISING与RAISE抛出的异常的
MESSAGE中的RAISING <exc1...exci>抛出异常时,如果在Call Function的Exception列表中有exc1...exci或others异常,则异常会优先被exc1...exci或others捕获到;否则RAISING选项将直接被忽略掉,MESSAGE会被error_message所捕获(在使用error_message捕获的前提下)
CALL FUNCTION 'ZJZJ_FUNC1'
EXCEPTIONS
error_message = 5
"被e捕获,如果注释掉下面E类型异常捕获列表,则会被error_message捕获
e = 4
d = 6.
14.8.1.error_message = n_error捕获消息
可以在Message语句没有使用RAISING选项的情况下(或使用exc1...exci或others但未捕获到),在主调程序中的CALL FUNCTION ...Exception参数列表中使用隐式异常error_message选项来捕获Message,但error_message是否能捕获到Message(实为是否设置sy-subrc = n_error),与消息类型有关:
1、对于W、I、S类型的消息,将不显示消息(本来是要显示的),也不会去设置 sy-subrc = n_error,但此时还是会将消息的相关信息存储到SY-MSGID, SYMSGTY,SY-MSGNO, and SY-MSGV1 to SY-MSGV4这些系统变量中
2、对于A、E类型消息,也将不显示提示消息,但会抛出ERROR_MESSAGE异常,即这两类型的消息会自动被转换为error_message异常抛出,并终最被CALL FUNCTION 中Exception异常列表中的error_message异常所捕获,并设置sy-subrc = n_error。此时还会将消息的相关信息存储到SY-MSGID, SYMSGTY,SY-MSGNO, and SY-MSGV1 to SY-MSGV4这些系统变量中
此时,对于A类型消息而言,ROLLBACK WORK语句将会隐式执行
3、对于X类型消息将会抛出runtime error,并且程序会dump
14.9.各种消息的显示及处理
| 消息类型 | 非屏幕PAI事件 PBO、 AT SELECTION-SCREEN OUTPUT、INITIALIZATION、START-OF-SELECTION、 GET、 END-OF-SELECTION、 TOP-OF-PAGE、 END-OF-PAGE | 对话/选择屏幕 PAI、 AT SELECTION-SCREEN [ON] | List列表事件 AT LINE-SELECTION、 AT USER-COMMAND、 AT PF<nn>、 | |||
| 显示 显示在对话框中还是状态栏中 | 处理 是终止程序还是继续 | 显示 | 处理 | 显示 | 处理 | |
| X | 不显示信息 | 触发运行时错误并伴随着dump | 不显示信息 | 触发运行时错误并伴随着dump | 不显示信息 | 触发运行时错误并伴随着dump |
| A | Dialogbox以对话框形式显示 | 程序终止 | Dialogbox以对话框形式显示 | 程序终止 | Dialogbox以对话框形式显示 | 程序终止 |
| PBO:与A相同,否则显示在状态栏中 | 程序终止 | 在状态栏中显示 | PAI处理结束,并且控制权返回到当前对话/选择屏幕继续输入 | 在状态栏中显示 | ||
| W | PBO:与S相同,否则显示在状态栏中 | 程序终止 | 在状态栏中显示 | PAI处理结束,并且控制权返回到当前对话/选择屏幕可继续输入,但可按回车键继来忽略警告继续运行后面程序而不必输入 | 在状态栏中显示 | 事件块处理终止,返回上一级别的List |
| I | PBO:与S相同,否则以对话框的形式显示 | 程序会继续向下执行 | Dialog box对话框中显示 | 程序会继续向下执行 | Dialog box对话框中显示 | 程序会继续向下执行 |
| S | 消息会显示在下一屏幕的状态栏中,如果没有下一屏幕,则显示在当前屏幕的状态栏中 | 程序会继续向下执行 | 消息会显示在下一屏幕的状态栏中,如果没有下一屏幕,则显示在当前屏幕的状态栏中 | 程序会继续向下执行 | 消息会显示在下一屏幕的状态栏中,如果没有下一屏幕,则显示在当前屏幕的状态栏中 | 程序会继续向下执行 |
14.10.异常处理
14.10.1.RAISE [EXCEPTION]…触发异常
两种方式触发异常:
lRAISE <except>. 只在函数中使用
一旦主调程序捕获了异常,以上两种触发异常的方式都会返回到主调程序,并且不会返回值(Function Module参数输出)。MESSAGE ..... RAISING语句也不会再显示消息,而是将相关的信息填充到SY-MSGID, SY-MSGTY,SY-MSGNO, and SY-MSGV1 to SY-MSGV4这些系统变量中(即使是I,S,W三种消息类型也会设置这些系统变量)
14.10.1.1.触发类异常
RAISE [RESUMABLE] EXCEPTION { { TYPE cx_class [EXPORTING p1 = a1 p2 = a2 ...]} | oref }.
cx_class为异常Class,EXPORTING为构造此异常类的构造参数,oref可以是已存在的异常Class引用。
RAISE EXCEPTION语句一般用来抛出基于Class的异常类class-based exceptions,而RAISE一般是直接用来抛出 non-class-based exceptions(在函数中使用)
DATA result TYPE p DECIMALS 2.
DATA oref TYPE REF TO cx_root.
DATA text TYPE string.
DATA i TYPE i.
TRY .
i = 1 / 0.
CATCH cx_root INTO oref.
text = oref->get_text( ).
WRITE: '---' , text.
RAISE EXCEPTION oref.
ENDTRY.
DATA: exc TYPE REF TO cx_sy_dynamic_osql_semantics,
text TYPE string.
TRY.
RAISE EXCEPTION TYPE cx_sy_dynamic_osql_semantics
EXPORTING textid = cx_sy_dynamic_osql_semantics=>unknown_table_name token = 'Test'.
CATCH cx_sy_dynamic_osql_semantics INTO exc.
text = exc->get_text( ).
MESSAGE text TYPE 'I'.
ENDTRY.


14.10.1.2.RESUMABLE选项
表示可恢复的异常,可以在CATCH块里使用RESUME语句直接跳到抛出异常语句后面继续执行,RESUME后面语句不再被执,CLEANUP块也不会被执行。该选项只能用于BEFORE UNWIND类型的CATCH块中:
DATA oref TYPE REF TO cx_root.
DATA text TYPE string.
DATA i TYPE i.
TRY .
RAISE RESUMABLE EXCEPTION TYPE cx_demo_constructor
EXPORTING
my_text = sy-repid.
i = i + 1.
WRITE: / i.
CATCH BEFORE UNWIND cx_demo_constructor INTO oref .
text = oref->get_text( ).
IF i < 1.
RESUME.
ENDIF.
WRITE:/ '--'.
ENDTRY.
结果只输出 1
14.10.2.捕获异常
14.10.2.1.类异常捕获TRY…CATCH
DATA myref TYPE REF TO cx_sy_arithmetic_error.
DATA err_text TYPE string.
DATA result TYPE i.
TRY.
result = 1 / 0.
CATCH cx_sy_arithmetic_error INTO myref.
err_text = myref->get_text( ).
ENDTRY.
14.10.2.2.老式方式捕获runtime errors(运行时异常)
CATCH SYSTEM-EXCEPTIONS [exc1 = n1 exc2 = n2 ...][OTHERS = n_others].
…
ENDCATCH.
DATA: result TYPE i.
CATCH SYSTEM-EXCEPTIONS arithmetic_errors = 5.
result = 1 / 0.
ENDCATCH.
IF sy-subrc = 5.
WRITE / 'Division by zero!'.
ENDIF.
14.10.3.向上抛出异常
如果Form中出现了运行时错误,但Form签名又没有使用RAISING向上抛,则程序会直接挂掉,所以最好是向上抛
FORM subform RAISING cx_static_check cx_dynamic_check.
...
ENDFORM.
Funcion函数不会主动向外抛出运行时错误,所以要先在Function手动CATCH,再手动向外抛,如果出现运行时错误不抛出,则Function与会直接宕掉
14.10.4.类异常
l CX_STATIC_CHECK
l CX_DYNAMIC_CHECK
l CX_NO_CHECK

CX_NO_CHECK类似于Java中的Error,CX_DYNAMIC_CHECK类似于Java中的RuntimeException,CX_STATIC_CHECK类似于Java检测性异常Exception [daiˈnæmik]
自己定义的异常一般继承CX_STATIC_CHECK、CX_DYNAMIC_CHECK,但CX_NO_CHECK也可以创建,不像Java
CX_STATIC_CHECK是一个抽象类。在程序中使用RAISE EXCEPTION 手动抛出这类异常时,方法或过程接口上一定要显示的通过RAISING 来向上层抛出异常、或者直接在方法或过程中进行处理也可以,否则静态编译时就会出现警告。
CX_NO_CHECK类型的异常一般表示系统资源不足引起的,不能在方法或过程接口后面抛出CX_NO_CHECK类型的异常,它会被隐含的抛出与传递。系统中已有预定义这类异常。
如果程序逻辑能够排除可能性的潜在性错,相应的异常就可能不用处理或继续抛出,此类情况下可以使用CX_DYNAMIC_CHECK类型的异常,这与Java中的运行时异常相似,一旦发生也该类异常,表示问题出现在程序的本身设计上,程序设计不严谨(如没有判断空指针问题)。ABAP大多数的系统预定义的异类都是属于该类型异常,这就意味着不需要处理或抛出ABAP语句可能出现的每一种异常,但一旦发生了该类异常,则表示程序的出现了问题,程序执行的结果将不会在正确。
自定义的全局异常类名以ZCX_ 作为前缀
如果是通过Class Builder创建的全局异常类时,由于构造器是默认创建好的(异常相关参数已经固定下来了),不能传递自定义参数,所以异常文本ID只能通过TEXTID传递(参考触发类异常),但局部异常类没有这个限制。
15.数据格式化、转换
15.1.数据输入输出转换
15.1.1.输出时自动转换
如果某个变量参照的数据元素所对应的Domain具有转换规则,那么在输出时(如Write输出、ALV展示、文本框中显示),最后显示的结果会自动发生转换,如参照 ekpo-meins 表字段的变量赋值时就会发生转换,因为 ekpo-meins 所对应的元素Doamin设置了转换规则:
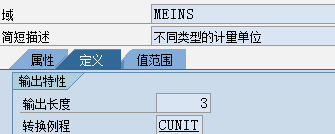
所以,在显示输出这样的数据时要注意,如果要显示原始数据,则不能参照该表字段来定义变量,而是自己定义。
DATA:i_meins LIKE ekpo-meins,
i_meins2 TYPE c LENGTH 3.
START-OF-SELECTION.
SELECT meins meins FROM ekpo INTO (i_meins,i_meins2) WHERE ebeln = '4500012164'.
"输出时, i_meins会自动发生转换,但 i_meins2 不会
WRITE: i_meins,i_meins2.
ENDSELECT.
SKIP.
DATA: i_meins3 LIKE ekpo-meins.
"注:这里只能是内部单位ST,而不是PC,因为Write时是输出转换(即内->外的转换)
i_meins3 = 'ST'.
"只要是参考过 ekpo-meins 的变量,Write输出时自动转换
WRITE:/ i_meins3.

在调试过程中发现都是原始数据,自动转换发生在Write输出时:
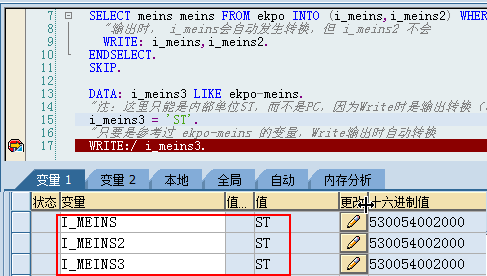
15.1.2.输入时自动转换
输出时会发生自动转换,那么,在输入时,如从选择屏幕上录入的数据是参照带有规则转换的Domain的数据元素创建的选择屏幕字段时,从界面录入到ABAP程序中时,会自动按照转换规则进行转换,如下面从界面上输入的是 PC (外部格式的单位),但录入到ABAP程序中时,自动转换为ST(内部格式的部位),但再次Write输出时,又将 ST转换为PC输出(从内部转换为外部格式):
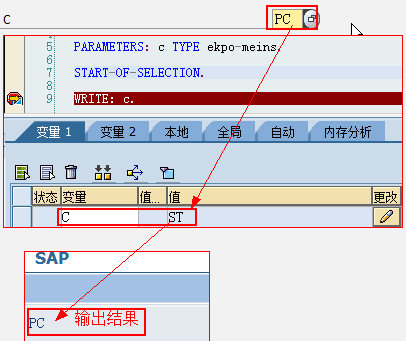
15.1.3.通过转换规则输入输出函数手动转换
除了上面通过借助于参照带有转换规则的表字段进行自动转换外,实质上可以通过转换规则对应的输入输出函数进行手动转换,如VBAK-vbeln的转换规则:
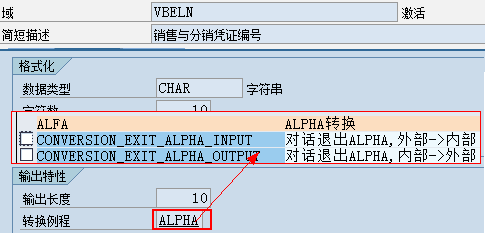
CONVERSION_EXIT_ALPHA_INPUT:输入转换,前面补齐零
此函数将字符类型的变量转换成SAP数据库中内部格式数据,如定单号vbeln的类型为 Char 10,如果输入的vbeln为6位,则会在前面补4个零(注:该函数的转换规则为:如果含有其他非数字,则不会补零,只有全部是数字时才补,这可以通过VBELN查看到),Number类型的不需要,因为在ABAP程序中N类型不足时长度时默认就会在前面补零(如 POSNR),而且Number类型的默认值就是全为零,而C类型不足时会以后面全补空格
CONVERSION_EXIT_ALPHA_OUTPUT:输出转换,去掉前导零
DATA: vbeln TYPE vbak-vbeln.
DATA: str TYPE string VALUE '600000'.
CALL FUNCTION 'CONVERSION_EXIT_ALPHA_INPUT'
EXPORTING input = str
IMPORTING output = vbeln.
"自动输出转换,输出最初始数据,但程序内部已发生变化
WRITE: / vbeln."600000

15.2.数量小位数格式化
该语句根据Unit <u>来设置<f>的小数位数(即保留小数点多少位,或精确到小数点后多少位),<u>为<f>的单位。<u>必须要在T006中进行过配置,并且<u>的值(单位KEY值)就是T006-MSEHI字段值,而T006-DECAN字段值决定<f>显示的小数位数,如果<u>在表T006中没有找到,将会忽略该UNIT选项
该选项的使用限制如下:
• 如果<f>本身的小数位比<u>所配置的小数位少时,系统会忽略该选项
• 如果<f>本身的小数位比<u>所配置的要多时,并且多余的小数位全部是零时,会被截断;如果多余的小数部分不是零时,也会直接忽略该选项
从上面的限制条件来看,该格式化输出只针对<f>的小数位超过了其单位<u>设置的小数位,且超过的小数要全是零才会起作用(去掉多余的零),如果<f>的小数位短于<u>设置的小数位,也不会再补后输出
"必须是P类型
DATA: p1 TYPE p LENGTH 8 DECIMALS 2.
p1 = '1.10'.
"如果<f>本身的小数位比<u>所配置的小数位小时,系统会忽略该选项
WRITE:/ p1 UNIT 'D10'."1.10
DATA: p3 TYPE p LENGTH 8.
p3 = '1'.
WRITE:/ p3 UNIT 'D10'."1
DATA:p2 TYPE p LENGTH 8 DECIMALS 4.
p2 = '1.1000'.
"多余的小数位全部是零时,会被截断
WRITE:/ p2 UNIT 'D10'."1.100
p2 = '1.1001'.
"多余的小数部分不是零时,也会直接忽略该选项
WRITE:/ p2 UNIT 'D10'."1.1001
DATA: i_menge LIKE ekpo-menge VALUE '1.000'.
"注:UNIT选项后面一定要是内部单位ST,而不是外部单位PC,因为这里是WRITE输出,
"即内部转换外部,将数据库表存储的原数据格式化输出显示
WRITE: / i_menge UNIT 'ST'."1
WRITE: / i_menge."1.000
15.2.1.案例
问:通过se11 我们可以看到ekpo中menge的数据元素是BSTMG,BSTMG的域是长度13小数位3位。在程序中我参照ekpo-menge定义的变量显示的时候后面都有3位小数,而我希望输出时与me23n一样,即去掉小数点后面多余的零,请问大侠们有没有比较好的办法。为什么me23n中“PO数量”显示的时候没有多余的零,而他们的数据元素是一样的。
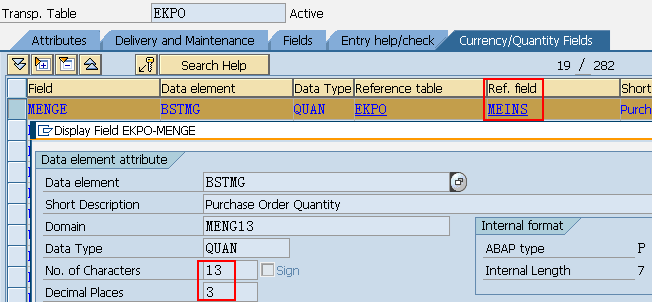
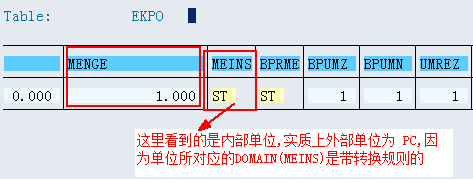
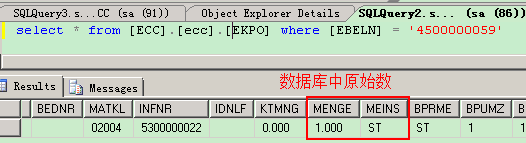
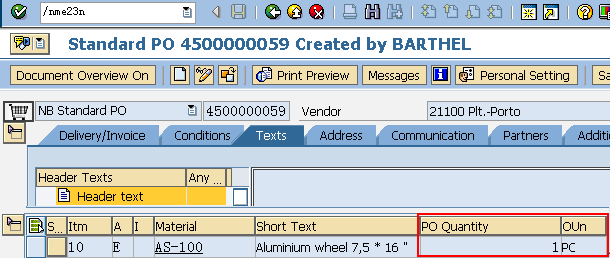
答:MENGE实际上是个存储度量衡值的字段,他的基本数据类型是QUAN,他的小数位数并不是你看到的3,而是由这个字段关联的度量衡单位决定的,以MENGE为例,你可以在SE11的最右边一个Tab页,Currency/Quantity Fields里看到,他关联的单位是EKPO-MEINS
DATA: i_menge LIKE ekpo-menge,
i_meins LIKE ekpo-meins,
i_meins2 TYPE c LENGTH 3. "没有参照表字段ekpo-meins,所以Write输出时不会自动输出转换
SELECT menge meins meins FROM ekpo INTO(i_menge,i_meins,i_meins2) WHERE ebeln = '4500012164'.
"带单位的数量需要根据单位进行格式化输出,这样才与ME23N 中显示的数据一样
WRITE: / i_menge UNIT i_meins,i_meins, i_menge,i_meins2.
ENDSELECT.
![]()
在ALV中显示时,如果是金额或数量时,需通过Fieldcat设置cfieldname 、ctabname ;qfieldname、qtabname这样在显示时才会正确
也可直接使用Domain所配置的转换规则所对应的输入输出转换函数CONVERSION_EXIT_CUNIT_INPUT、 CONVERSION_EXIT_CUNIT_OUTPUT来手动对单位进行转换:

15.3.单位换算:UNIT_CONVERSION_SIMPLE
PARAMETERS: p_in TYPE p DECIMALS 3,
unit_in LIKE t006-msehi DEFAULT 'M',"米
unit_out LIKE t006-msehi DEFAULT 'MM',"毫米
round(1) TYPE c DEFAULT 'X'.
DATA: result TYPE p DECIMALS 3.
CALL FUNCTION 'UNIT_CONVERSION_SIMPLE'
EXPORTING
input = p_in
round_sign = round"舍入方式(+ up, - down, X comm, SPACE.)
unit_in = unit_in
unit_out = unit_out
IMPORTING
output = result.
WRITE: 'Result: ',result.
![]()
15.4. 货币格式化
WRITE <f> CURRENCY <c>.
输出金额<f>时,会根据该语句设置的货币代码<C>来决定其小数位置,如果货币代码<c>在表TCURX(CURRKEY)表中存在,则系统将根据TCURX-CURRDEC字段的值来设置<f>的小数点的位置,否则将<f>转换成具有2位小数的数字。这就意味着除非<f>本身就是类型为P(.2)(即货币的最大单位与最小单位换算为100时,如CNY人民币、USD美元)的金额字段,否则需要在TCURX表中配置所对应币种的小数位(因为不配置时会采用默认的2位)。
注意:这里的<f>一般是从数据库里读取出来的金额数据才需要这样格式化输出的,如果<f>本身存储的就是真实的金额,则不需要格式再输出,而是直接输出;另外,这里的格式化只是简单机械的根据TCURX-CURRDEC所配置的小数位置来设置金额的小数点位置(而并不是乘以或除以某个转换率),并与金额变量<f>类型本身的具有多少小数位有关:如果<f>的类型为P(6.5),值为<f> = 1.234时,且TCURX表里配置的小数位为2时,最后输出的是 1234.00 ,而不是12.34(如果是根据转换率来除,则结果会正确),因为在格式化前,会将小数末的0(1.23400)也参与处理,并不理会<f>本身原来的小位数,而是将所有的数字位(抛开小数点,但包括末尾的0)看作是待格式会的数字字符串:
DATA: p(6) TYPE p DECIMALS 5.
p = '1.234'.
WRITE: p CURRENCY 'aa'."1,234.00
TCURX:货币小数位表
TCURC:货币代码表
TCURR:汇率表
SAP表里存储的并不是货币的最小单位,一般是以货币最大单位(也是常用计量单元)来存储,不过在存储之前会使用经过转换:比如存储的金额是 100,则存储到表之前会除以一个转换因子后再存入数据表中(该转换因子是通过CURRENCY_CONVERTING_FACTOR函数获得的,如比CNY的转换因子为1,JPY为100),所以如果要读取出来自已进行展示,则需要再次乘以这个因子才能得到真正的金额数。另外,数据库中存储的虽然不是最小单位,但取出来后都是放在P类型的变量中的,所以取出来在内存中统计是不会有精度丢失的(P类型相当于Java中的BigDecimal类类型)。
TCURX-CURRDEC中存储的小数位实质上是根据同种币种的最大单位与最小的换算率= 10X来计算得到的,式中的X即TCURX-CURRDEC表字段中的小数位,如CNY中的最大单位元与最小单位分相差100倍,所以100 = 10X,X就为2,最后TCURX-CURRDEC存储的就是2(但如果值为2是可以不需要在TCURX表中配置的,所以查不到CNY的配置数据,因为不配置时默认值也是2);另外,JPY日元没有最小单位,所以最大单位与最小单位的换算率就是1(1 = 10X),所以X就为0,所以TCURX-CURRDEC存储的就是0。而转换因子计算式为:转换因子 = 100/10X,(CNY人民币:100/10X=100/102 =1,JPY日元:100/10X=100/100 =100),即转换因子 = 100/货币的最大单位与最小单位换算率,金额入库时需要除以这个转换因子,读取出来展示前需要乘以这个转换因子
数据库中用来存储金额的字段的类型都是P(.2),即带两位小数,因为转换因子最大也就是100(除以100后,即为小数点后2位),有的是零点几(在存入之前会将真实金额除以这个转换因子后再存入),所以存储类型为两位小数的数字类型即可。ABAP程序中用来存储从表中读取出来的内部金额的变量类型一定要具有两位类型的,否则在使用诸如CONVERT_TO_LOCAL_CURRENCY、CONVERT_TO_FOREIGN_CURRENCY转换函数或者是格式化输出时,都会有问题,所以在ABAP程序中定义这些用来存储数据库表中所存内部金额变量时,最好参照相应词典类型。
15.4.1.从表中读取日元并正确的格式化输出


DATA: netpr LIKE vbap-netpr,"实际的类型为p(6.2)
waers LIKE vbap-waerk,
jpy_netpr TYPE i,
netpr1(6) TYPE p DECIMALS 3.
"通过SQL从数据库查询出来的是真实存储在表里的数据,没有经过其他转换,日元存到数据库中时缩小了100倍,所以要还原操作界面上输入的日元金额,则需要使用后面的格式化输出
SELECT SINGLE netpr waerk INTO (netpr,waers) FROM vbap WHERE waerk = 'JPY' AND vbeln = '0500001326'.
WRITE: waers,netpr."数据库中的值,被缩小了100倍
"第一种还原方式
WRITE: / 'Format:', netpr CURRENCY waers.
"第二种转换方式:也可以通过以下函数先获取JPY货币代码的转换因子,再直乘以这个因子也可
DATA: isoc_factor TYPE p DECIMALS 3.
CALL FUNCTION 'CURRENCY_CONVERTING_FACTOR'
EXPORTING
currency = waers
IMPORTING
factor = isoc_factor.
jpy_netpr = netpr * isoc_factor."乘以100倍,因为在存入表中时缩小了100倍
WRITE: / 'Calc factor:', jpy_netpr.
"格式化输出实质上是与存储金额的变量本身的类型小数位有关:上面将从表中读出的金额(小数两位)赋值给变量netpr1(小数三位),格式化后会扩大10倍(因为多了一位小数位)。所以格式化正确输出的前提是要用来接收从表中读取的金额变量的类型要与数据表相应金额字段类型相同,否则格式化输出会出错
netpr1 = netpr.
WRITE: / netpr1, netpr1 CURRENCY waers."格式化的结果是错误的
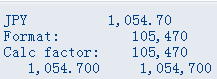
15.4.2.SAP 货币转换因子
一般而言,币种的小数位为2,所以系统默认的位数也是2,但是有一些特殊币种如日元JPY,没有小数位。只要小数位不等于2,需要在系统中特殊处理(通过转换因子进行转换,具体请参看后面SAP提供的函数 currency_converting_factor 实现过程)。在编程中
lList中,当输出CURR字段时,记得指定对应的货币:
如: WRITE: vbap-netwr CURRENCY vbap-waerk.
lScreen中,对于CURR字段,需要设置对应的货币字段:
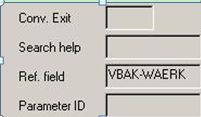
lALV中,需要对FIELD CATALOG进行设置
如:ls_cfieldname = 'WAERS'. "这里的WAERS是内表中的另一货币字段,里面存储了相应金额的货币代码
货币的是:fieldcat-cfieldname、fieldcat-ctabname(内表名,可以不设置)
顺便数量也是相似的方法来处理的:
数量的是:fieldcat-qfieldname、fieldcat-qtabname(内表名,可以不设置)
下面是SAP转换因子函数,在金额存储与在ALV展示时都会自动除以与乘以这个转换因子:
FUNCTION currency_converting_factor.
*"----------------------------------------------------------------------
*"*"Lokale Schnittstelle:
* IMPORTING
*" VALUE(CURRENCY) LIKE TCURR-TCURR
*" EXPORTING
*" VALUE(FACTOR) TYPE ISOC_FACTOR
*" EXCEPTIONS
*" TOO_MANY_DECIMALS
*"----------------------------------------------------------------------
DATA: cur_factor TYPE isoc_factor.
*- determine Decimal place in currency from TCURX
CLEAR tcurx.
"首先根据币种到db表tcurx中读取相应的小数位数currdec
SELECT SINGLE * FROM tcurx WHERE currkey EQ currency.
"如果没有维护相应币别信息则默认currdec = 2
IF sy-subrc NE 0.
tcurx-currdec = 2.
ENDIF.
"如果currdec 大于了 5就报错
IF tcurx-currdec GT 5.
*- entry in tcurx with more than 5 decimals not allowed
RAISE too_many_decimals.
ENDIF.
*- compute converting factor respecting currency
"然后默认转换比率是100。如果表tcurx中的currdec = 0就默认转换比率为100
cur_factor = 100.
IF tcurx-currdec NE 0.
"在currdec不等于0的情况下循环currdec次,每次将转换比率除以10
DO tcurx-currdec TIMES.
"当表tcurx中没有找到相应数据时则默认currdec = 2,转换比率也就是100 / 10 / 10 = 1。其他
"的比如表tcurx中的currdec = 4,则转换比率应该为 100 / 10 / 10 / 10 / 10 = 0.01
cur_factor = cur_factor / 10.
ENDDO.
ENDIF.
IF cur_factor = 0.
*- factor 0 not allowed; check data definition of factor
*- entry in tcurx with more than 5 decimals not allowed
RAISE too_many_decimals.
ENDIF.
factor = cur_factor.
ENDFUNCTION.
简单的使用Function CURRENCY_CONVERTING_FACTOR,输入币种,就可以得到相应的转换比率了。我们在SE16中看到的货币金额基本上都经过了这个转换,如日元,都是除以100后存入数据库的。所以当我们从数据库中读取日元金额时也应该作相应的转换,乘以100 。
1、如果某货币的小数位不是2位,则需要通过OY04设置其小数位数,即需在TCURX表中进行维护
2、系统中的数据表存放的日元JPY、俄卢布RUR等货币比前台输入的金额小100倍,因为它们没有小数位,所以转换因子为100,存入表之前SAP会先将金额除以这个因子后再存入
3、系统根据转换因子将原金额转换成含小位小数的金额后存储(据说根据ISO的什么标准),如日元为0位小数,转换因子为100,120日元除以因子100后转换后变成1.20,缩小100倍。如为USDN为5位小数,其转换因子为100/10/10/10/10/10=0.001,12.01230除以0.001后则转换成12012.30,扩大1000倍。SAP在金额数据存储时会自动的转换,其实SAP是有external及internal的数据格式,可以调用以下函数实现相互转换。BAPI_CURRENCY_CONV_TO_INTERNAL:转换成数据库中内部存储金额,BAPI_CURRENCY_CONV_TO_external:转换成外部实际金额
4、每次币别的汇率更改在正式生产系统中新创建一条记录,利用函数CONVERT_TO_LOCAL_CURRENCY自动会把当前最近的时间的汇率作为转化的汇率,而不是直接在原纪录上更改
5、OB07、OB08,维护各币种之间的汇率。
6、碰到比较变态的货币,例如日元,它们是没有小数点的,系统内存储的和你看到的不同,有个BAPI可以使用:BAPI_CURRENCY_CONV_TO_INTERNAL
7、还有两个不同币种之间的转换FM:CONVERT_TO_FOREIGN_CURRENCY,和CONVERT_TO_LOCAL_CURRENCY基本没有区别,功能都是一样的,只是转换的源与目标相反而已:CONVERT_TO_FOREIGN_CURRENCY是将外币转换为本位币,而CONVERT_TO_LOCAL_CURRENCY是将本位币转换为其他外币
15.4.3.货币内外格式转换
"所有金额的在数据库里(内部格式)都是带两位的小数数字类型用来存储内部金额时,用来存储金额的变量类型一定要与数据库表里的类型一致,否则使用WRITE输出时会不准确
DATA: usd(7) TYPE p DECIMALS 2,
jpy(7) TYPE p DECIMALS 2,
jpy_e(12) TYPE p DECIMALS 4.
DATA: usd_k TYPE waers, jpy_k TYPE waers.
DATA: ret TYPE bapireturn.
"此处为实际金额,所以不宜直接格式化(只有对内部表中存储格式的金额格式化输出才有意义,否则是错误的输出),不过这里为实际的金额似乎也有点不对,因为日元真实金额是不会有小数的,所以变量jpy用来存储外部实际金额是不妥的,jpy应该为整数类型才恰当
jpy = '10000.01'.
usd_k = 'USD'.
jpy_k = 'JPY'.
"使用CONVERT_TO_LOCAL_CURRENCY、CONVERT_TO_FOREIGN_CURRENCY函数时,涉及到的金额输入输出参数都是采用内部金额,所以在使用这些函数时,如果是外部金额,应先将它们转换为内部金额后再传入
CALL FUNCTION 'CONVERT_TO_LOCAL_CURRENCY'"将一种货币兑换成另一种货币
EXPORTING
date = sy-datum
foreign_amount = jpy"该程序中的jpy本身为外部金额,但在这里会将
"它当作是内部金额,所以最后相当于外部金额1000001
foreign_currency = jpy_k
local_currency = usd_k
IMPORTING
local_amount = usd."转换出来的也是内部金额
*CALL FUNCTION 'CONVERT_TO_LOCAL_CURRENCY'
* EXPORTING
* date = sy-datum
* foreign_amount = '1.00'"内部金额,美元的外部金额也是1.00美元
* foreign_currency = 'USD'
* local_currency = 'JPY'
* IMPORTING
* local_amount = usd."结果为内部金额:1.15,相当于外部金额为115日元
*CALL FUNCTION 'CONVERT_TO_LOCAL_CURRENCY'
* EXPORTING
* date = sy-datum
* "如果内部金额没有小数,也要补上两位小数位0,否则实质金额不准确,这里正是
* "因为末尾未补两位0,所以这里的金额实质上为0.01美元,而不是1美元
* foreign_amount = '1'"内部金额,相当于外部0.01美元
* foreign_currency = 'USD'
* local_currency = 'JPY'
* IMPORTING
* local_amount = usd. "结果为:0.01内部金额,实质相当于外部金额1日元
WRITE: jpy, jpy_k,usd, usd_k.
"由于jpy本身为实际金额,所以不能在这里格式输出;但usd为内部
"格式的金额,所以需要使用格式化输出(但usd本身就是带两位小数
"的内部金额,转换
WRITE:/ jpy CURRENCY jpy_k, jpy_k,
usd CURRENCY usd_k, usd_k.
ULINE.
jpy_e = jpy.
"将外部金额转换为内部存储金额,实质上过程是将外部金额除以转换因子即可得到
CALL FUNCTION 'BAPI_CURRENCY_CONV_TO_INTERNAL'
EXPORTING
currency = jpy_k
amount_external = jpy_e"外部金额
max_number_of_digits = 23"没什么作用,一般写23即可
IMPORTING
amount_internal = jpy "转换后的内部存储金额
return = ret.
CALL FUNCTION 'CONVERT_TO_LOCAL_CURRENCY'
EXPORTING
date = sy-datum
foreign_amount = jpy "源货币金额(内部格式)
foreign_currency = jpy_k"源货币类型
local_currency = usd_k"目标货币类型
IMPORTING
local_amount = usd."目标货币金额(内部格式)
WRITE: jpy, jpy_k,usd, usd_k.
WRITE: / jpy CURRENCY jpy_k, jpy_k,
usd CURRENCY usd_k, usd_k.

16.业务
16.1.表、业务流程
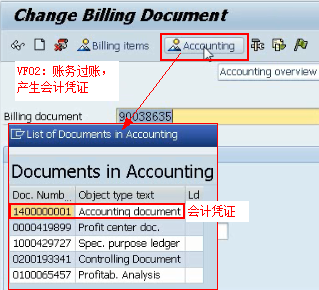
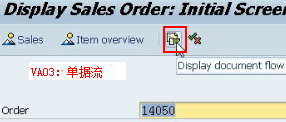
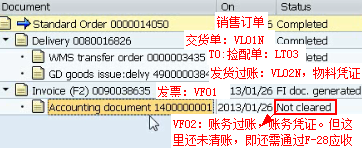
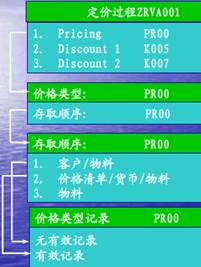
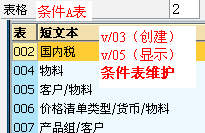
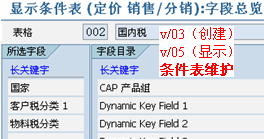

BSEG主要通过“凭证号”“会计年度”“行号”和这六张表关联
一般情况下一笔业务产生的凭证都是未清的,那么:如果该业务行是客户相关的,则被记录到BSID;
如果该业务行是供应商相关的,则被记录到BSIK;
无论和客户相关还是和供应商相关,都是和总帐相关,所以也会有记录到BSIS;
但是如果这笔业务被清帐了,则相应的记录会从BSIS转移到BSAS
一般情况下:应收账款、预收账款、其他应收款、应收汇票等科目既和客户相关,又和未清项管理的总帐科目相关;
应付账款、预付账款、其他应付款、应付汇票等科目既和供应商相关,又和未清项管理的总帐科目相关;
其他总帐科目一般不启用未清项管理,所以记录一般都放在BSIS中。
BSEG 本身是一个 Cluster Table(簇表),BSEG就是由上述的六大表的集成,当要读取”BSEG”Table时就等于去读取那六个表,这样你可以想像它读起来会就多慢。对於 簇表或Pool Table,都是SAP系统本身在使用的,因此簇表本身是不存在资料库实体的,虽然是可以在ABAP使用,不过还是有一些限制: 1.不能使用select distinct or group by语法 2.不能使用Native SQL 3.不能使用specify field names after the order by clause 4.不能在建立次索引 5.查询时一定要用KEY FIELD
16.2. MM
16.2.1.常用表
16.2.2.库存

![]()
可用库存:可通过BAPI_MATERIAL_AVAILABILITY来获取
当前库存:一般保存在MARD-LABST字段中
在途库存:MARC-UMLMC(中转库存)+ MARC-TRAME(在途库存),在途库存是不存在库位关系的
寄售库存:MSKU-KULAB,寄售库存是不存在库位关系的
16.2.3.物料凭证
物料凭证批记录物料变动的单据:如收发货、调拨、销售、盘点过账等都会产生。
凭证类型,即物料的移动类型,三位编码
常用物料移动类型:
101采购订单收货、生产订单收货(MB01 采购订单的过账收货、MB31 按生产订单收货)102:反冲;122:退货
261从仓库发货到订单的消耗(领料生产MB1A)
301跨工厂间一步库存转移
311同一工厂一步库存转移
561期初库存的导入
601成品、原材料的销售出库
103 入冻结库
105 释放冻结库
16.3.SD
16.3.1.表
| VBAK:销售订单抬头 VBAP:销售订单项目 VBUK:抬头状态 VBUP:行项目状态 | VBKD:销售凭证:业务数据 VBPA:销售凭证:合作伙伴 VBEP:销售凭证:计划行数据 | LIKP:交货单抬头 LIPS:交货单明细 VBFA:销售凭证流(单据流) KNA1:客户主数据 |
| VBRK:发票抬头 VBRP:发票行项目
| A***:价格条件都存在名称为 A+3个数字的表中,如A012 KONV:按条件保存订单中的定价、税额等 KONP:按条件保存定价数据(保存VK11中的定价) |
|
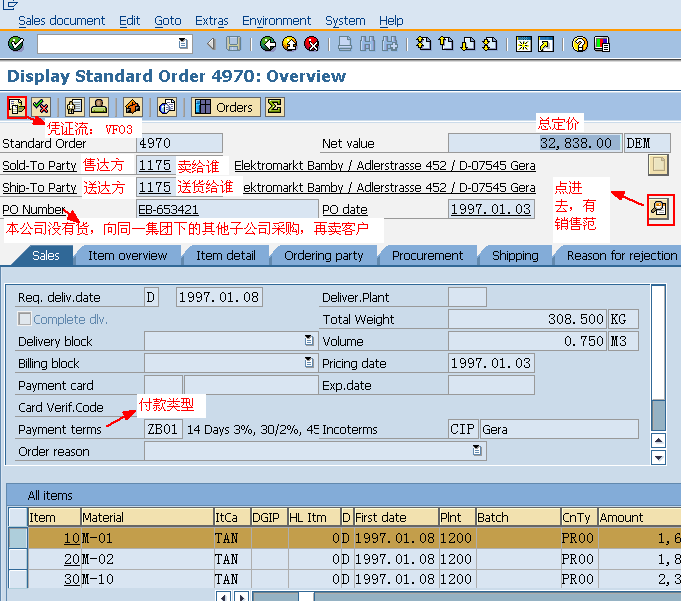
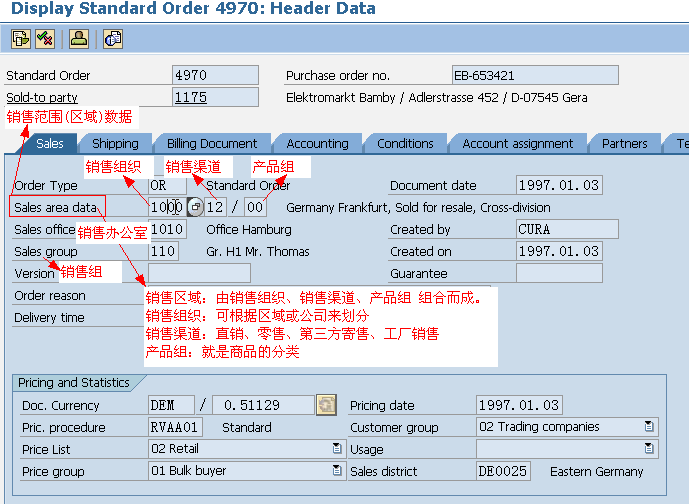
16.3.2.定价过程
16.3.2.1.条件技术七要素
1.条件字段(Condition Field):条件表(A表)的关键字段,如客户、物料
2.条件字段目录(Field Catalog):条件字段的集合,也即AXXX条件表的关键字段,决定在不同层次上的定价
3.条件表(Condition Table):即AXXX表,包含一个或多个条件字段为关键字段,关键字段对应一个字段目录
4.存取顺序(Access Sequence):存取顺序中包含一个或者多个条件表,多个条件表时需指定读取这些表的顺序
5.条件类型(Condition Type):条件类型即条件分类,如计算价格的PR00、计算折扣的K007、计算税额的MWSI
6.定价过程(Procedure):由多个条件类型组成,每个一条件类型就是一个定位步骤
7.定价过程确定(Procedure Determination):根据销售范围(销售组织+分销渠道+产品组)、客户、订单类型来确定
当创建销售订单时,系统首先确定定价过程,再根据定价过程确定需要的条件类型,然后订单中条件类型(如销售折扣K007)就根据存取顺序在条件表中读取相应价格主数据
16.3.2.2. 条件表V/03、V/04、V/05
自定义的条件表编号从600到999。定价条件表中允许的条件字段都来自于定价表KOMK、KOMP
16.3.2.3.存取顺序 V/07
以PR00为例,该条件类型可根据三个定价的关键字组合(即对应三个条件A表)进行维护,系统则通过存取顺序确定三个条件表的优先级顺序,该优先级顺序称存取顺序(Access Sequence)。

图中存取顺序为PR02,系统按编号10、20、30、40依次读取条件表A305、A306、A304,系统最先读取305,即根据销售组织+分销渠道+客户+物料确定销售单价,图中字段“排斥的”钩选后表示如果在A305表中读取到了数据,则不再继续读取后面的A表
定价参考物料:通常来说定价参考物料等于销售订单中输入的物料,但也可在物料主数据的销售视图维护定价物料,定价物料的目的在于减少价格维护的工作量
16.3.2.4.条件类型 V/06
条件类型重要属性:
l条件类型(Condition Class):定义条件类型属于单价、折扣、还是税收类型
l计算类型(Calculation Type):定义单价、折扣、税收是如何计算的
l条件类别(Condition Category):对于特殊类型的条件类型,系统预定义了条件类别,如对于条件类型 VPRS,其条件类型为G,因此系统自动根据物料主数据中维护的标准价格(移动平均价格)确定该条件类型的条件类型金额
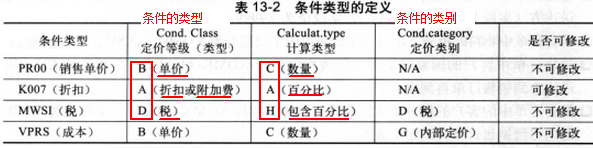
16.3.2.5.定价过程V/08与确定OVKK
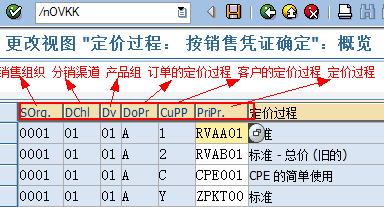

1、From ~ To步骤范围
作用:确定条件类型基础(Condition Base Value)
适用情况:仅针对计算类型为百分比的条件类型
逻辑说明:系统中提供三种百分比的计算类型,A(Percentage)、H(Percentage Include)、I(Percentage/travel expenses)。以计算类型A为例,其条件类型金额等于条件类型基础乘以百分数,而条件类型基础默认等于该条件类型的步骤范围内的条件类型的值的合计,当不输入步骤范围时,则条件类型基础等于该条件类型前所有步骤的条件类型金额之和
本例中,折扣的条件类型K007的计算类型设置为百分比,按图中配置,K007条件类型基础等于条件类型K007前所有条件类型的金额之手,即条件类型PR00的条件类型金额,具体为1600元,所以条件类型K007的金额等于条件类型基础(1600)*前台VK11维护的折扣率(10%)=160元。
若设置条件类型K007的步骤范围为“From 11 To 11”与不输入步骤配置时条件类型基础值是相同的
2、Manual手工的
作用:确定条件类型是否在销售订单定价界面中自动出现
适用情况:无存取的条件类型
逻辑说明:图中一共长个条件类型,条件类型EDI1代表期望的价格,被标准为了“手工”,该条件类型没有分配存取顺序,所以此种条件类型不读取主数据(因为没有条件A表),而是在销售订单中手工输入
3、Required必须的
作用:如果单据中条件类型没有值,系统数据检查时会提示
适用情况:任何条件类型
逻辑说明:定价类类型(Condition Class)为B(Price 单价)或者A(Discount Or Surcharge 折扣或附加费)的条件类型,必须维护相应的价格主数据,具维护值不能等于0;对于定价类型为D(Taxes 税收)的定价类型,只要维护相应的主数据即可,可以是零(表示无税收)
4、Statistics统计的
对于一张销售订单来说,金额信息中最主要的是计算订单的不含税金额(Net Value 即净价值,下图中的Net字段)和税额(Tax Value,下图中的Tax字段),后续开票时,不含税金额将过账到账务收入科目,税额将过账到税金科目,二者合计代表着现金(应收账款)
系统将定价过程中的各个中满足下面三个条件的值纳入到订单的净价值(Net Value,下图中的Net字段)计算:
1、 条件1:该步骤勾选上统计,如钩选统计,则代表该金额不纳入净价值
2、 条件2:该步骤存在条件类型。如下图(VA03)中的最后一个步骤“Test Only”不存在条件类型,因此尽管未被勾选统计,但系统也不将该步骤的值纳入净价值中。不存在条件类型的步骤,系统一律认为是统计性
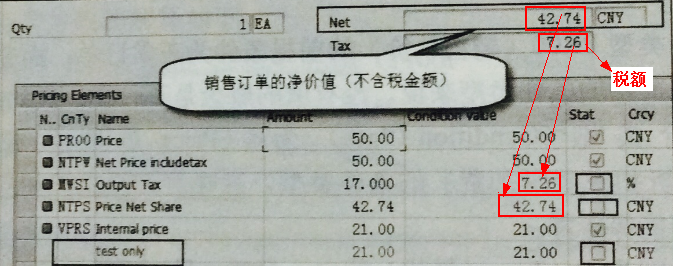
条件3:该步骤的条件类型的定价类型(Condition Class)不是“税类型D”(Taxes:税收)。如上图中的MWSI,虽然未勾选统计,但系统也不将它纳入净价值统计
小计即将步骤(条件类型)的值或者价格赋值到小计中,不同的小计有不同的用途,有些小计可以用来做后续的计算,有些小计的值将会保存到数据库中。上上图中条件类型PR00的小计被设置为5,表示小计对应字段为KOMP-KZWI5,KOMP-KZWI5的金额等于条件类型PR00金额,当销售订单保存后,VBAP-KZWI5的值等于KOMP-KZWI5
下面列举了定价过程中预置的22个小计,并对这些小计做了简单分类,划分为四类型:
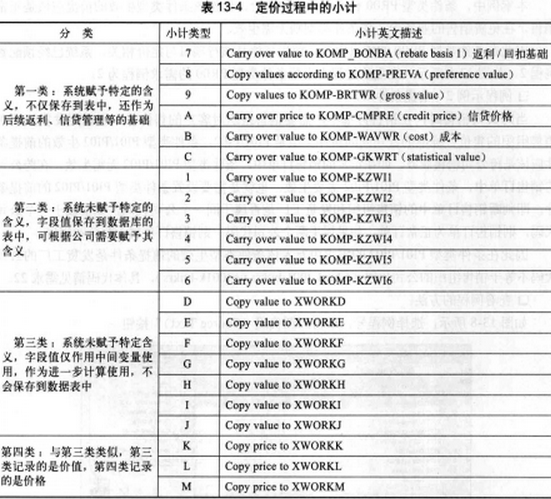
第一类:不可以随意使用,系统已经赋予其特定含义。该类小计的值最终都会保存到VBAP相同名称的字段里
第二类:系统预留的,可根据公司需要赋予特定含义。这6个小计的值最终都会保存在销售订单行项目表字段VBAP-KZWI1 ~ VBAP-KZWI6中。如可设置小计1用来记录领导审批的折扣金额,小计2用来记录客户期望价格
第三、四类:系统未赋予特定含义。这两类小计字段值不会保存到数据表中,仅作为中间变量使用,是为了定价过程中进行一步计算使用。其中第三类小计是将步骤的条件类型金额赋值到小计中,第四类是将条件类型价格赋值到小计中
6、Requirement需求
条件类型生效的前提条件,可以写自定义的程序来定义条件类型生效的前提条件,系统也提供了很多程序可供选择。查看程序代码:
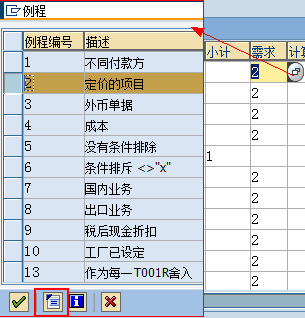
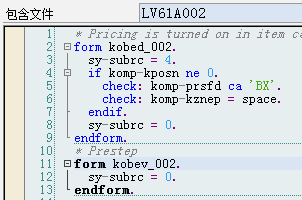
7、Condition Value Formula条件金额公式
通过该字段主要用来改变当前条件金额的值(字段XKWERT),也可同时改变当前条件类型的其他字段的值,如条件类型价格。
条件类型NTPW(含税金额)等于折扣前含税金额减去折扣金额,因此系统将条件类型(PR00)含税价金额复制到小计字段5(KOMP-KZWI5),将条件类型折扣(K007)的金额复制到小计字段(KOMP-KZWI6)中,同时该条件类型NTPW条件金额公式的例程设置为81,下面是例程81源码:

在程序81中定义了条件类型NTPW金额(XKWERT)等于小计5(komp-kzwi5) + 小计6(komp-kzwi6),同时在程序还根据条件类型NTPW金额计算得到该条件类型价格(XKOMV-KWERT)
8、 Condition Base formula条件基础公式
与条件金额公式类似,主要是通过例程来改变条件类型基础值
9、Acckey和Accruals账户码和应计项
通过定价过程的账号码(Account Key)和应计码(Accrual Key)实现与销售开票时的会计科目的确定无缝集成,实现收入、折扣、成本、税额进入各自的会计科目
销售开票的会计科目确定一般由6个条件字段确定,销售组织、分销渠道、产品组、客户的科目分配组、物料的科目分配组、账户码(应计项),其中客户科目分配组由客户确定,物料的科目分配组由物料确定,而账户码(应计项)则由定价过程中的定价类型确定
另外,凡是纳入销售订单净值计算的条件类型都必须有对应的账户码
16.3.2.6.VK11:价格主数据维护
通过VK11维护条件后,数据存放在对应的条件AXXX表中
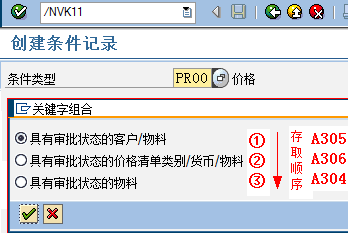
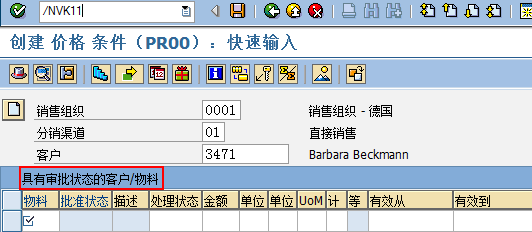
16.3.2.7. 定价计算:KONV
系统根据定价过程,并结合价格主数据(AXXX表中的数据)计算得到条件类型金额,并将条件类型单价(KBETR)、条件类型基础(KAWRT)、条件类型金额(KWERT,计算结果)一并存放到KONV表中
下表为最终KONV计算结果:

注:为了阅读方便,上图中表格做了适当修改,如对于百分比的条件类型MWSI,表中实际存储的为170,而非17%
KONV-KBETR:从价格主数据(AXXX表)表中读取得到
KONV-KAWRT:部分条件类型(如折扣、税)是根据定价过程定义在创建订单时动态计算得到
KONV-KWERT:以KBETR、KAWRT为基础,并通过相应的计算公式计算得到,该字段即为最终计算出的定价结果
创建销售订单时,条件屏幕的字段在内表XKOMV中,最终内容将保存在数据库表KONV中,VBAK与KONV通过KNUMV(条件记录号)进行关联(注,只有VBAK里才有KNUMV,VBAP里没有,因为一张单就只对应一个定价过程,所以整张单只需一个KNUMV,与Item无关)
16.3.2.7.1.条件类型的计算公式
条件类型金额的计算公式三要素:
1.条件类型价格[Rate(condition amount or percentage)]:如单价(800元/个)、折扣(10%)、税率(17%),来自VK11所维护的价格主数据
2.条件类型基础(Condition Base Value):如数量(2个)、折扣前金额(即销售金额 1600元),部分条件类型(如折扣、税)是根据定价过程定义动态计算得到,一般为前面几步条件类型统计结果
3.条件类型金额(Condition Value):以条件类型价格和条件类型基础为基础计算出来的金额,如含税金额1600元、折扣160元
条件类型金额是以条件类型单价、条件类型基础为基础,通过某个公式计算得来
根据条件类型的计算类型,条件类型金额有不同的计算方式,最常用的三种计算方式:
1.条件类型中的计算类型KONV-KRECH为C(数量):条件类型金额 = 条件类型价格(单价)* 条件类型基础(数量),如销售金额PR00的金额等于单价800元/个 * 数量2个 = 金额1600元
2.条件类型中的计算类型KONV-KRECH为A(百分比):条件类型金额 = 条件类型价格(百分比)* 条件类型基础(金额),如折扣K007的金额等于10% * 1600 = 160元
3.条件类型中的计算类型KONV-KRECH为H(包括在内的百分比):条件类型金额 =条件类型基础(金额)/(1+百分比)*百分比,如税收MWSI的金额等于1440/(1+17%)*17% = 209.23元
16.3.2.8.定价过程示例
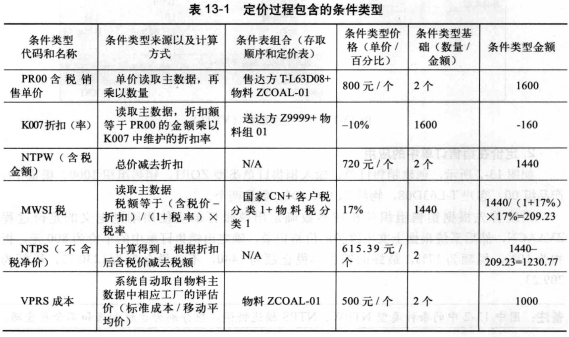
其中NTPW(含税金额)的条件类型价格 = 1440 / 2 = 720 ,NTPS(不含税净价)的条件类型价格 = 1230.77 / 2 = 615.385
|
| 条件价格或百分比 | 条件基值 | 条件金额 |
| PR00 含税销售额 | 65元/个 | 2个 | 65*2 = 130元 |
| K007 折口 | 0.1 | 130元 | 130*(0.1) = 13元 |
| NTPW 折口后含税销售额 | 58.5元/个 | 2个 | 130-13 = 117元 |
| MWSI 销项税 | 17% | 117元 | 117/(1+17%)*17% =17元 |
| NTPS 销售净额 | 50元/个 | 2个 | 117–17 = 100元 |
16.3.2.9.销售订单中的定价示例
销售单价:800元 折扣:10% 税率:17%
最终销售含税金额:1440元 不含税金额:1230.77 税额:209.23
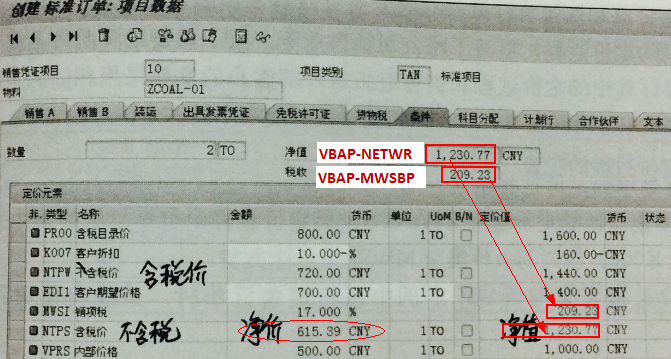
注:上图中的条件类型NTPW、NTPS描述错误,应该分别为含税金额和不含税金额,弄反了
销售订单的净值(实为NTPS条件类型的KONV-KWERT的值)和税额(实为MWSI条件类型的KONV-KWERT的值)还存储在了销售订单行项目表VBAP-NETWR与VBAP-MWSBP中(还有一个VBAP-NETPR净价(实为NTPS条件类型的KONV-KBETR的值?),也直接存储在了VBAP表中);

与之对应的采购订单的净价EKPO-NETPR、净值EKPO-NETWR也是直接存储在了Item表EKPO中了:
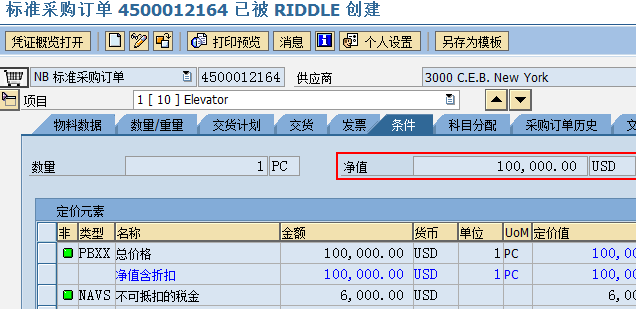
另外还有两个重要的字段:VBAP-KWMENG:销售数量、EKPO-MENGE:采购数量。(这两个字段实际上可对应到某个条件类型如PR00/NTPW/NTPS 的KONV-KAWRT的基础值?)
创建订单时,系统根据 销售组织+分销渠道+产品组+客户的定价过程+单据的定价过程 来确定一个定价过程,其中客户的定价过程在客户主数据(KNA1,XD03)中定义:
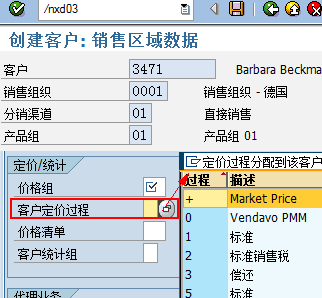
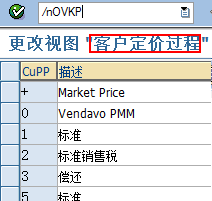
单据的定价过程(不同的单据类型有不同的定价过程)通过事务代码OVKJ分配给销售订单:
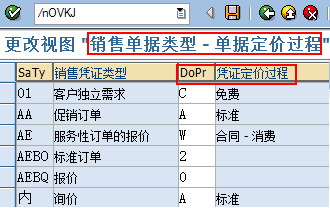
16.3.2.10.定价通信表KOMK、KOMP
系统通过两个表KOMK、KOMP为销售单与前台价格主数据、后台定价配置之间建立桥梁。创建订单时,系统首先根据销售订单中的信息为这两个表赋值,然后根据这两个表中的值确定销售单据中的定价,即这两个表起通信(Communication)作用
创建销售单时,会将VBAK中的部分信息赋值给KOMK表,VBAP同赋值给KOMP表
这两个表仅仅起通信作用,是销售订单维护时产生的两个内表,当销售订单保存后,表中的信息也会消失
定价表KOMK、KOMP的字段与VBAK、VBAP中的字段,大多相同,但并不是所有字段命完全相同,系统也并非根据字段名进行赋值,在系统内部有一套默认赋值规则
对于定价表KOMK、KOMP赋值是定价的基础,系统只是将部分信息赋值了,某些字段如物料主数据中销售视图下的物料组1字段MVKE-MVGR1就没有自动赋值过去,现在某个折扣需要根据物料组1确定,标准功能无法实现,原因是该字段的值系统没有将其复制到定价表KOMP中。此时首先检查该字段是否在表KOMK、KOMP中存在,SE11时发现KOMP中有同名字段MVGR1,此时只需要利用SAP系统预留的用户出口程序MV45AFZZ,在USEREXIT_PRICING_PREPARE_TKOMP FORM中加入以下代码即可:TKOMP-MVGR1 = VBAP-MVGR1.在创建订单时系统会自动将TKOMP-MVGR1原封不动的复制到表KOMP-MVGR1中。如果有相应字段,可通过SE11修改KOMK、KOMP表,修改时查找CI_ 开头的 .INCLUDE 结构可其他以Z打头的INCLUDE或APPEND结构
16.3.3.销售相关的凭证类型、类型
销售相关的凭证类别(SD document category),表示凭证的分门别类,常用的有销售订单、交货订单、发票,在VBAK、LIKP、VBRK抬头表里都有一个VBTYP字段,用来区别表里的凭证具体属性哪一类凭证。
VBAK-VBTYP的取值可以是:A、B、C、D、E、G、H、I、K、L、W 等,C是最常用,表示销售订单凭证;
LIKP-VBTYP的取值可以是:7、J、T 等,J是最常用,表示交货单凭证;
VBRK-VBTYP的取值可以是:3、5、M、N、O、P、U 等,M是最常用,表示发票凭证;
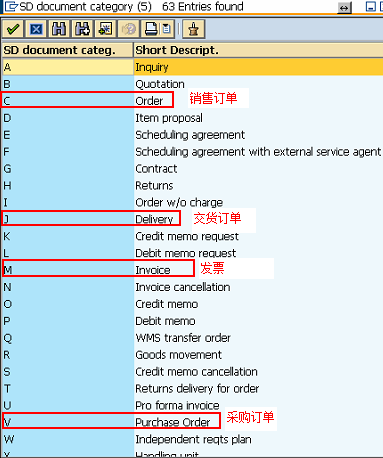
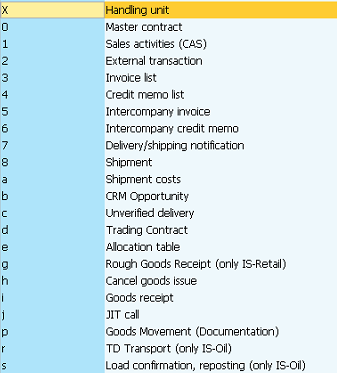

每种凭证又可分为N种类型,如VBAK、LIKP、VBRK这些表里都有相对应的类型字段,它们分别是:AUART、LFART、FKART。如销售订单的类型,常用的有标准订单类型OR:
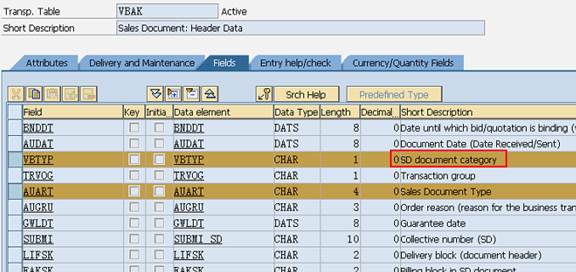
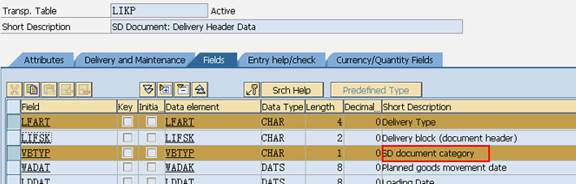

发票抬头表里还有一个发票的小分类FKTYP,用来表示某种具体的发票类别,在是发票这一大分类中再细分
查看了一下采购订单,也有类别与类型两个字段,但类别不是销售里的凭证类别VBTYP,采购与销售是不相同的,所以采购相关凭证类型使用BSTYP来表示了:
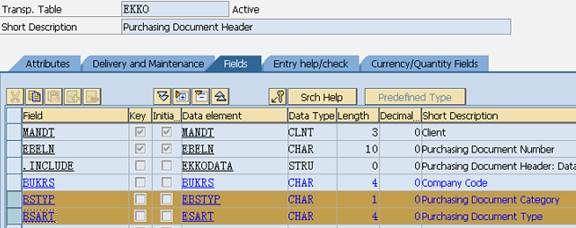

16.4.业务概念
16.4.1.售达方、送达方、开票方、付款方
送达方
The party who receives delivery of the goods.
售达方
The customer who orders the goods or services. The sold-to party is contractually responsible for sales orders
举例的:
其实简单的说,售达方就是买东西的客户,送达方就是你要发货之后收货的客户。
通常这2个字段输入同一个客户,但是有例外,比如你的客户是一个大集团总部,那大集团下面的一些公司也是你的一些客户,那因为这个集团采购是统一总部进行,你的订单的售达方就是这个集团总部这个客户代码,但是你的货物是指定要送到集团下的一个分公司,那么你的送达方就是这个分公司客户代码。
通俗的:曾经看到一个强悍的解释:你老婆刷你的卡买了瓶茅台送给老丈人,发票抬头开的是你老婆单位的名称。那么它们之间的关系如下:
售达方:你老婆
送达方:你老丈人
付款方:你
收票方:你老婆单位
Sold-to-party : 售达方,下订单客户
Ship-to-party : 送达方,收货之客户
Bill-to-party : 开票方,仅指收发票之客户,发票开给谁
Payer-to-party : 付款方,付款人
16.4.2.进项税、销项税
所谓进项税和销项税是指增值税的进项和销项税。增值税是国家就增值额征的一种税。如果你是一般人纳税人,你花1元钱买的商品的同时(卖方如果能提供增值税发票的话),给你商品的一方要替税务局向你收0.17元的税款,你要向卖给你商品方支付1.17元。当你把1元的商品以1.2元卖出的时侯(或加工成别的商品以1.2元卖出时),你要替税务局向购买方收取1.2*0.17=0.204元税款,实际你的纳税额是0.204-0.17=0.034元(因为0.17在进货时已经交过了,所以需扣除掉),0.17元叫进项税0.204元叫销项税。用0.17元抵减0.204元的过程就叫抵扣进项税。抵扣的前提是你是一般纳税人,有认证过的进项税额,当月没抵扣完的可到以后抵扣。小规模的企业帐上没有进项税,只有销项税。进项税可以抵扣一部分的销项税,进项税是采购时发生的,销项税是销售环节产生的。进项税是在购入材料或物品取得增值税发票时记入应交税金的借方
借:原材料
应交税金---进项税
贷:银行存款或现金等
销项税是开了发票入帐进入应交税金的贷方
借:银行存款或应收帐款
贷:主营业务收入
应交税金--销项税
这是借方的税大于贷方的税就可相抵如果贷方的税大于借方的税,那就要交税了
计算公式为:应纳税额=当期销项税额- 当期进项税额
销售额=含税销售额÷(1+税率)
销项税额=销售额 × 税率
销项税额:是指纳税人提供应税服务按照销售额和增值税税率计算的增值税额。
进项税额:是指纳税人购进货物或者接受加工修理修配劳务和应税服务,支付或者负担的增值税税额。
基本示例
A公司4月份购买甲产品支付货款10000元,增值税进项税额1700元(销售货物或者提供加工、修理修配劳务以及进口货物的公司按17%税率来征收,个人消费按6%税率来征收),取得增值税专用发票。销售甲产品含税销售额为23400元。
进项税额=1700元
销项税额=23400/(1+17%)×17%=3400元
应纳税额=3400-1700=1700
16.4.3.订单日期、凭证日期、过账日期
订单日期:订单创建时所在日期
凭证日期:一般直接从订单创建日期带过来
过账日期:某笔交易小记到哪天的账上
凭证日期:业务发生的日期
记账日期:记账到哪个期间
录入日期:什么时候录入的
会计期间与日期天不一样,一般为1到12期间,中国的期间与日期天对应,即第一期间对应于1月,第二期间对应2月
16.5.业务知识
16.5.1.客户联系人相关信息
T001W:工厂(WERKS、ADRNR)
KNA1:客户主数据(KUNNR、ADRNR)
EKKO(ADRNR收货地址)
VBPA:合作伙伴
这些表的ADRNR都在是ADRC(地址表ADDRNUMBER)中定义的。
ADRC:存储了公司、客户的名称(NAME1/2/3/4)以及地址、邮编等数据
KNVK:客户主要联系人(客户一般指公司,各部门设有联系人 PARNR:主键,联系人号码;KUNNR:客户编号;PRSNR:人员编号)
KNA1:客户主数据,KUNNR:主键,客户编号;ADRNR:地址
ADR2:电话号码 (ADDRNUMBER(10),PERSNUMBER(10))
ADR3:传真号 (ADDRNUMBER(10),PERSNUMBER(10))
ADR6:邮件 (ADDRNUMBER(10),PERSNUMBER(10))
如查找某客户联系人所对应邮件:通过KNVK-KUNNR=KNA1-KUNNR到KNVK表中取到人员编号KNVK-PRSNR(可能会有多个,某个公司的联系人可以有多个),再到ADR6(E-Mail Addresses,ADR6-ADDRNUMBER=KNA1-ADRNRAND ADR6-PERSNUMBER= KNVK-PRSNR)得到邮件地址SMTP_ADDR,使用XD03也可以查看某个客户所对应的邮件地址。
另一种查找法(上面根据非主键查,下面都是根据主键来查询,所以优先考虑下面查找法):
先根据订单号VBAP-VBELN、Item行号VBAP-POSNR = 000000、合作伙伴功能VBPA-PARVW,到合作伙伴表VBPA查找得到地址号VBPA-ADRNR与联系人号码VBPA-PARNR:
vbpa~vbeln=vbap~vbeln AND vbpa~posnr='000000'AND vbpa~parvw = 'AG'AG表示伙伴为售达方,因为VBAK头表(整张单)中的VBAK-KUNNR只能是售达方客户编号(注:VBAP中没有KUNNR客户编号)。这里查的只是表头(整张单),而非Item对应的合作伙伴,如果查某个Item合作伙伴,则需将vbpa~posnr='000000'修改为vbpa~posnr= vbap~posnr,并且vbpa~parvw = 'AG'中的AG修改为对应的伙伴功能,或去掉此条件
再根据联系人号码VBPA-PARNR到KNVK中(KNVK-PARNR=VBPA-PARNR)查找得到人员编号KNVK-PRSNR,最后根据地址号与人员编号ADR2/3/6-ADDRNUMBER=VBPA-ADRNR AND ADR2/3/6-PERSNUMBER= KNVK-PRSNR条件到ADR2/3/6表中查找得到电话/传真/邮件信息

16.5.2.销售订单合作伙伴功能
VBAK中有一个客户字段KUNNR的信息,但只能表示Sold-to party售达方:
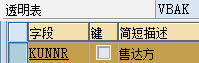
如果要知道每个Item的所对应的不同功能的客户,则需要将VBAP与VBPA(合作伙伴)通过 VBELN、POSNR进行关联来得到Item所对应的客户信息(也是KUNNR),至于该客户的功能,则需要根据VBPA-PARVW(就是Partner Function,即合作伙伴功能)来判断,该字段决定了客户是Sold-to-party(售达方)、Ship-to-party(送达方)、Bill-to-part(开票方)还是Payer-to-party(付款方)等。得到KUNNR后,就可以到KNA1(客户记主数据表)中获取客户的联系人信息;另外还可以根据VBPA-ADRNR到ADRC获取客户的名称(NAME1/2/3/4)以及地址、邮编等数据
17.增强
标准教材:BC425、BC427
17.1.第一代:基于源码增强(子过程subroutine)
这些Form集中存储在一些文件名倒数第二个字符为Z的包含程序中(如后面销售凭证主程序SAPMV45A中的MV45ATZZ、MV45AOZZ等Include文件)
这些Form的名称一般是以UserExit_打头的子模块,所以一般找到所要增强的主程序,再查找UserExit_ 关键字即可找到相关的出口
Form源代码增强事先要到 service marketplace 申请对象键(ACCESS KEY),然后才能修改这些子程序
另外,可以在SPRO中搜索 USER EXIT关键字来查找
17.2.第二代:基于函数出口增强(Function)
用SMOD(激活增强,只需一次激活)和CMOD(实现增强)维护;在SAP发布的版本中,使用CALL CUSTOMER-FUNCTION <3位数字>调用函数模块的,所以你可以通过在程序中查找cusomer-function来查找增强,出口函数名称由三部分组成:EXIT_<程序名>_<3位数字>(注:这里的<程序名>即指调用此出口函数的程序名),这样你就可以找到对应的增强函数了
针对数据表的增强出口是 “CI_ ”打头的结构,这些结构将.INCLUDE 结构的形式包含到时相应的数据表中,用户可以通过向这些结构中添加字段从而达到对数据表字段的增加
第二代增强中主要有4类:
1)E. Function exits:函数增强(最常用,在SAP上线很多年后都会使用,如:销售单VA02中,对PO长度限制在10-15位之间,且不能为中文与其他特殊字符,还有如对PO采购日期不能晚于交货日期的检验等,这些都会用来函数增强)
2)C.GUI codes:GUI增强
3)S. Screens:屏幕增强增强屏幕的调用是使用CALL CUSTOMER-SUBSCREEN(不常用,一般在上线之初才会做,上线后不常用)
4)T. Tabes:表结构增强
查找Enhancement的方法:
1、 在程序中搜索CUSTOMER-FUNCTION找到后面的3位数字编号,出口函数名的规则为EXIT_<程序名>_<3位数字>,然后通过找到的出口函数名到MODSAP表里查找所对应的出口对象(即增强点)
2、 通过调试系统相关函数:MODX_FUNCTION_ACTIVE_CHECK
3、 代码找增强

以VA01对应的主程序SAPMV45A为例,在源码中可以查找包含CALL CUSTOMER-FUNCTION的字符串,可以找到这样的代码:
根据出口所对应的函数名规则,这个函数名为EXIT_SAPMV45A_003
再根据出口函数,到MODSAP表中查找对应的增强点(出口对象):
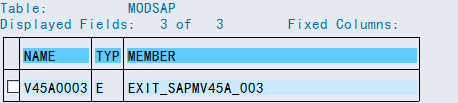
注:一个出口函数只对应一个出口对象,而一个出口对象可以对应到多个出口函数
Enhancement比较重要的表MODSAP,这个表里重要的字段有增强名(Name,即出口对象名),组件类型(TYP: E C S T),组件功能模块名(Member):里面记录了所有enhancement的增强。TFDIR所有的函数表,重要字段有FUNCName(函数名),MAND(功能模块激活状态如果是C代表此函数模块激活)

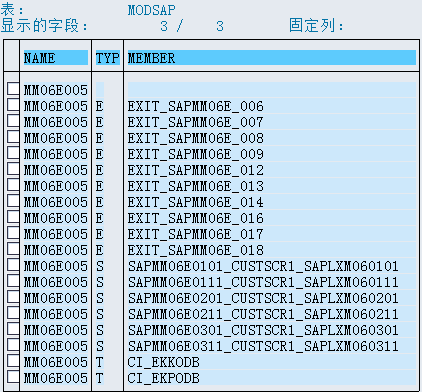
17.2.1.示例:采购订单屏幕增强
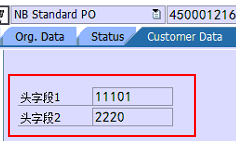
通过调试MODX_FUNCTION_ACTIVE_CHECK系统函数,运行ME23N,找到名为EXIT_SAPMM06E_006的出口函数,再根据这个出口函数到MODSAP表中找到对应的出口对象(增强点)MM06E005,再通过SMOD查看这个出口对象(增强点):
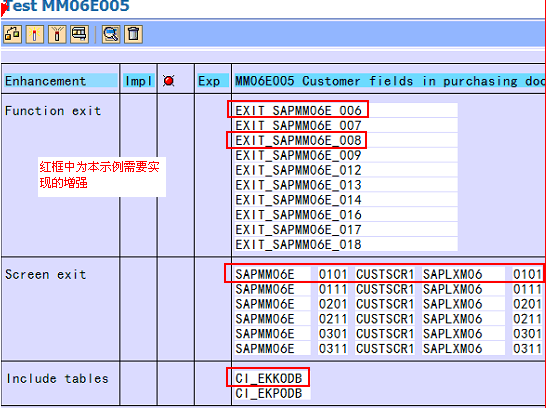
MM06E005包含功能出口、屏幕出口、表出口三种增强
在上面MM06E005增强的SMOD界面上双击表出口“CI_EKKODB”,可以对EKKO表结构进行扩充
在上面MM06E005增强的SMOD界面上双击出口函数“EXIT_SAPMM06E_006”,则会打开函数编辑器SE37,再点击工具栏中的“Display Object List”按钮,则切换到SE80编辑器模式中显示,这样就可以找到出口函数所在的函数组为XM06,主程序为SAPLXM06:
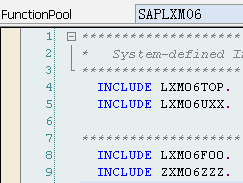
INCLUDE LXM06TOP(Global Data在此为增强定义global data)
INCLUDE LXM06UXX.(Function Modules实际上包含所有可用的user exit出口函数)
INCLUDE LXM06F00. (SAP-Formpool for Customer-Use可在此建立Form pool)
INCLUDE ZXM06ZZZ. (Subprograms and Modules,在此创建增强子屏幕)
17.2.1.1.定义全局变量
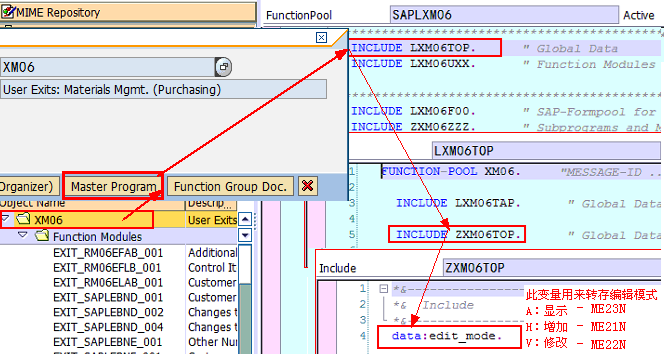
屏幕字段名的前缀必须要设置为系统预先定义好的全局 EKKO_CI 内表类型名,这样屏幕字段的就可以自动与该内表结构进行交互,EKKO_CI即为系统预先就定义好的增强屏幕所需的结构类型:
当向结构预留结构CI_EKKODB中扩展字段时,EKKO_CI也会自动的得到扩展,还有EKKO表结构也会被扩充
17.2.1.2.子屏幕
在MM06E005增强点的SMOD界面上双击出口函数“SAPMM06E 0101 CUSTSCR1 SAPLXM06 0101”屏幕出口行,则会新创建屏幕0101(屏幕属性需设置为子屏幕):
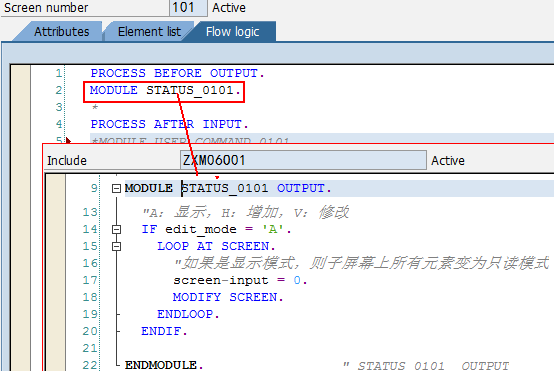
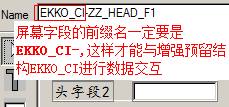
17.2.1.3.屏幕与业务表数据间传递
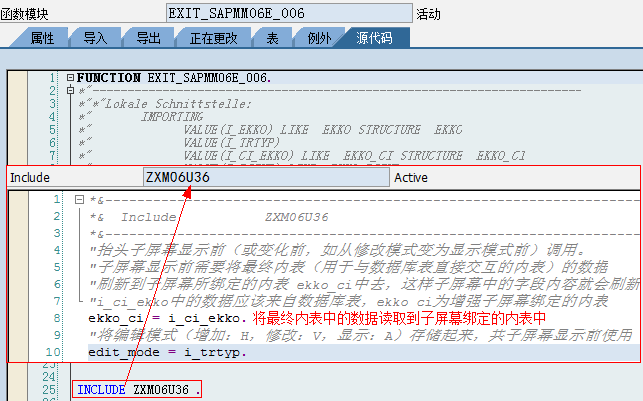
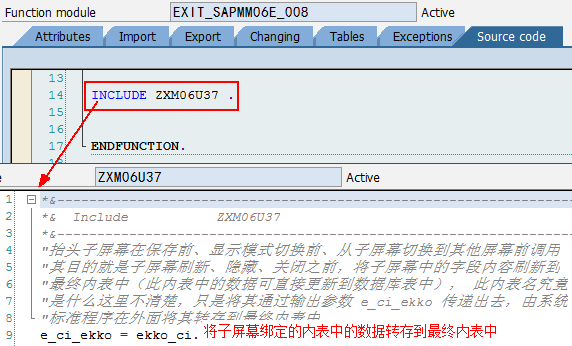
17.2.1.4.相关函数说明
MM06E005增强出口中各个出口函数功能说明:
006:Export Data to Customer Subscreen for Purchasing Document Header (PBO) Header,显示子屏幕前调用,即在子屏幕的PBO事件块执行前就会先调用此函数,在该函数中可以:将数据表中扩展字段所存业务数据导出到采购凭证头中的客户增强子屏幕中
007:Export Data to Customer Subscreen for Purchasing Document Header (PAI) Header,输入后校验
在该函数中:可以对输入的数据进行检验
008:Import Data from Customer Subscreen for Purchasing Document Header Header,将通过验证后的最终屏幕数据转存到业务数据内表中,将作为最终业务数据插入到数据库中
012:Check Customer-Specific Data Before Saving 按保存按钮后执行,保存前调用
016: Export Data to Customer Subscreen for Purchasing Document Item (PBO) Item,与006相同
017:Export Data to Customer Subscreen for Purchasing Document Item (PAI) Item,与007相同
018:Import Data from Customer Subscreen for Purchasing Document Item Item,与008相同
17.2.2.如何快速找到增强
尽管可以快速根据Tcode找到其对应的增强,可是往往因为这样找到的是所有的增强,而且有些增强可能是随着系统启动了某模块才可能会用到的,这样你可能会面临究竟使用哪个增强的困惑, 所以在此介绍一种方法不用任何程序可以快速定位每个事务码对应的增强,一刀致命.
第一步:在检查出口增强函数设置断点(Tcode:SE37).
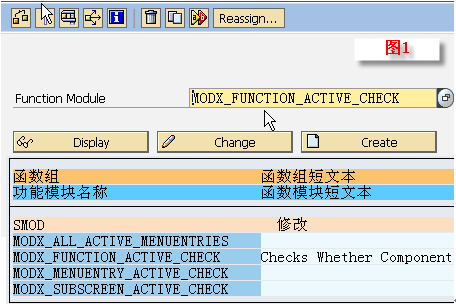
SE37输入出口检查函数MODX_FUNCTION_ACTIVE_CHECK.
系统有3种类增强,一是FUNCTION增强,这个最常用,我们一般所用的增强就是它,一是MENUENTRY菜单增强,还有一个就是SUBSCREEN增强,比如采购订单(Tcode:ME21N),工单等很多主数据上都允许屏幕增强,就是如果你有非常极其BT的需求,允许自定义一个用户屏幕,在屏幕上搞些自定义的字段,这些东西当然最后被保存在自定义的表格中,这种思路代表了ERP设计的先进方向,如果你有兴趣可以学习学习.
第二步:执行你想执行的任何Tcode
现在假设我执行MB1B我需要做一些检查增强,系统自然执行到MODX_FUNCTION_ACTIVE_CHECK ,输入变量l_funcname看看它是啥值,比如是EXIT_SAPLF048_001,这个增强的输入参数有doc header and Item(如图3),凭证头和身子在这俩内表都有了,应该可做任何检查.
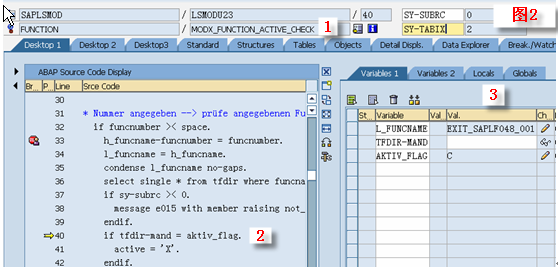
根据屠宰经验,是这样的,函数包括增强函数都躺在表TFDIR,如果强函数TFDIR-MAND = ‘C’则表示该增强是激活的,于是系统赋予一个标志active = ‘X’,测试一下,现在有人将TFDIR-MAND改成’C’或直接将Active改成’X’, 系统马上会到增强哪去逛一下,如果增强有诸如某个条件不match就错误的逻辑,系统就报告错误知道你纠正为止. 不过,象我这样一看就非常老实厚道的人一般不会做这种欺骗系统的事情.
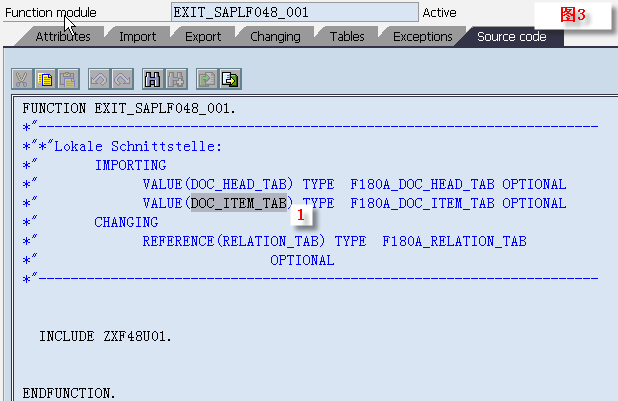
第三步:快速找到增强名称(SE16|SMOD|CMOD).
确定增强函数EXIT_SAPLF048_001可用后,SE16:MODSAP,这表保存了函数和增强名称的对应关系,在MEMBER输入EXIT_SAPLF048_001,如图4,找到增强F180A001 .
SMOD|CMOD激活增强F180A001,激活函数EXIT_SAPLF048_001,建立程序ZXF48U01,在该程序中写入增强逻辑并激活,注意一个增强生效时必须同时激活这3个东东.
有个弟兄说跟我在项目中学到了不少”歪门邪道“,什么世道?祖传的杀猪独门功夫都让他学去了
17.3.第三代:基于类的增强(BADI)
BADI维护是通过SE18、SE19事务来来维护的。SE18用于创建及维护BADI对象;SE19用于维护BADI的实例
BADI的查找方法:
1、主程序都会调用cl_exitHandler=>get_instance(这只是经典BADI是这样来调用的,如果是新式的BADI,则调用为GET BADI handle-BADI定义名、CALL BADI handle->method)来判断对象是否存在,并返回实例。我们可以在se24中对类cl_exitHandler=>get_instance方法进行调试,运行一个tcode,看一下exit_name的值,这就是要找的BADI
2、在主程序中搜索cl_exitHandler,查看它所引用(TYPE REF TO)的接口名,根据接口命名规则 IF_EX_<badi>,得到<badi>命称
3、通过程序查找
命名规则:
Badi definition: Z<badi>
BADI implementation:Z<impl>
Implementing class:ZCL_IM_<impl>

17.3.1.新式BADI创建
新式BADI中的增强容器Enhancement Spot、BADI定义 BADI Definitions、接口Interface、增强实现Enhancement Implementation、BADI实现BADI Implementation、实现类之间的关系:
一个增强容器下可以创建多个BADI定义,每个BADI定义由一个接口与多个增强实现组成,而每个增强实现里又可以创建多个BADI实现,而每个BADI实现里可以创建一个现实类
17.3.1.1.定义

首先需要创建BADI增强点(Enhancement Spot), Enhancement Spot是作为一个BADI的容器, 在容器里面,我们可以定义自己的多个BADI:
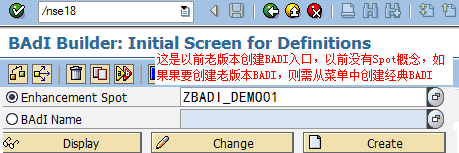
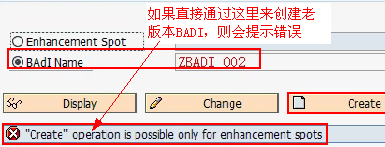
在新建立的enhancement spot中创建BADI:
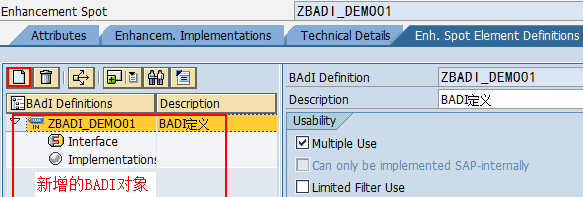
定义BADI时,默认采用的是单一使用(single-use),如果没有选中复合使用选项(Multiple Use),单一使用的限制是只能有一个实现
一个Enhancement Spot可以定义多个BADI,每个BADI又是由一个接口与多个实例类组成的。Enhancement Spot相当于容器概念,用来存储多个BADI,而每一个BADI必须定义一个接口,该接口可以有一个或多个实现(增强实现 Enhancement Implementation,每个增强实现里面才能定义实现类),BADI实质上就是将接口与实现类组织(打包、捆绑)在一起了:
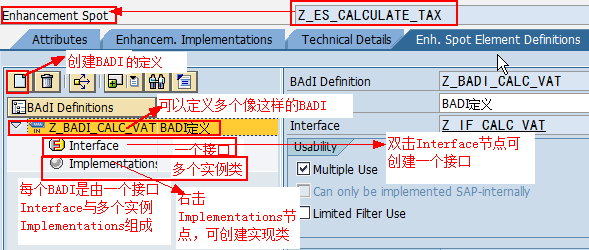
BADI对象是由接口与实现组成的,下面创建BADI接口:
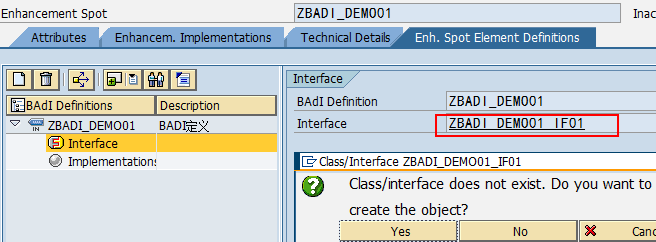
双击接口名,可以创建接口,以及定义接口中的方法
17.3.1.2.实现
由于一个BADI的实现可以有多个类,这些多个实现类需要组织(打包、捆绑)在一起(与多个BADI放在一个Enhancement Spot容器中是一个概念),所以需要创建一个新的BADI增强实现容器ZBADI_DEM001_IMP:
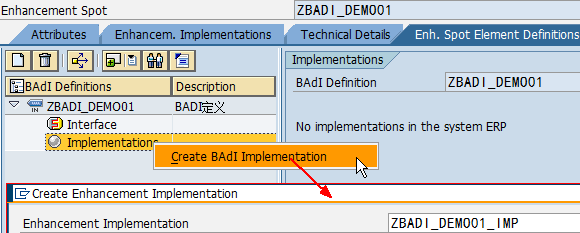
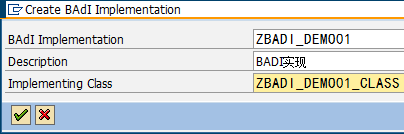
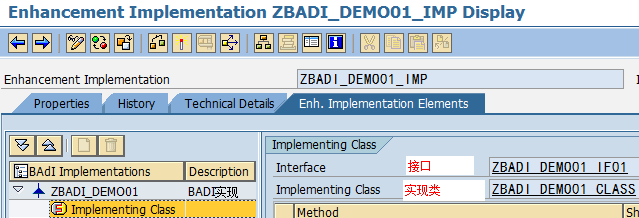
一个增强实现(Enhancement Implementation)可以有多个BADI Implementations(相当于多个版本,每个BADI Implementations即与一个且仅一个实现类对应),但起作用的同时只能有一个,有多个版本时需要进行设置:
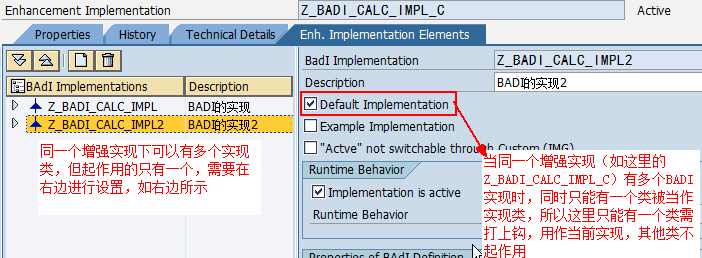
如果想要达到像Java中多态的话,需要创建多个不同的Enhancement Implementation增强实现,BADI中的多态就是通过不同的Enhancement Implementation增强实现来实现的:

当有两个增强实现Z_BADI_CALC_IMPL_C、Z_BADI_CALC_IMPL_C2,需要把其中一个的Implementation is active前的钩去掉才能被激活:
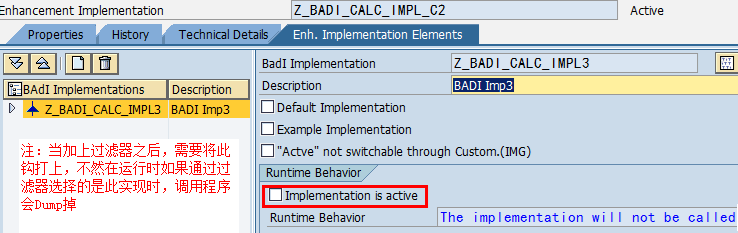
17.3.1.3.过滤器
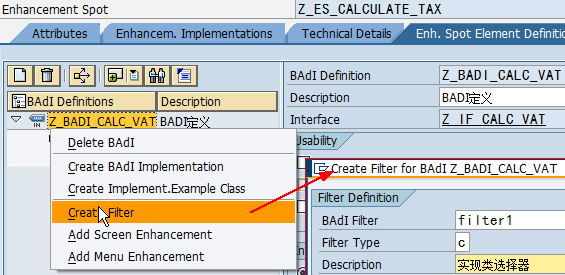

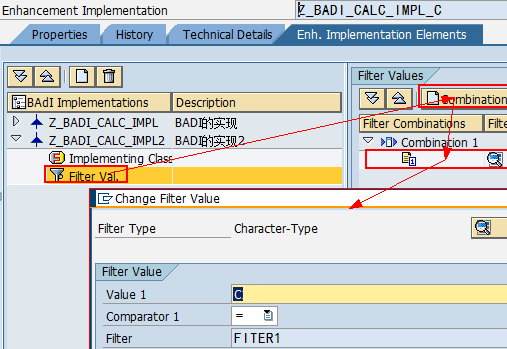
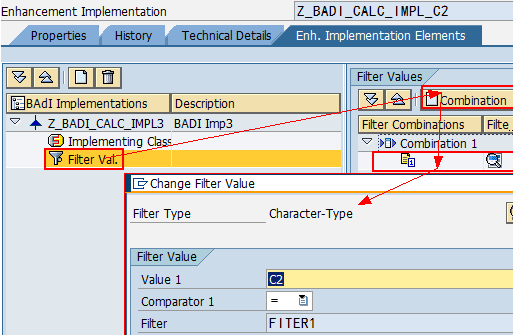
注意:上面过滤值一定要大写,否则运行时匹配不到
17.3.1.3.1.调用
parameters: filter(2) type c.
DATA: handle TYPE REF TO z_badi_calc_vat,"z_badi_calc_vat为BADI定义名,不是接口也不是类
sum TYPE p,
vat TYPE p,
percent TYPE p.
sum = 50.
GET BADI handle
FILTERS "SE18中定义的过滤器名作为这里的参数名
filter1 = 'C'.
CALL BADI handle->get_vat
EXPORTING
im_amount = sum
IMPORTING
ex_amount_vat = vat
ex_percent_vat = percent.
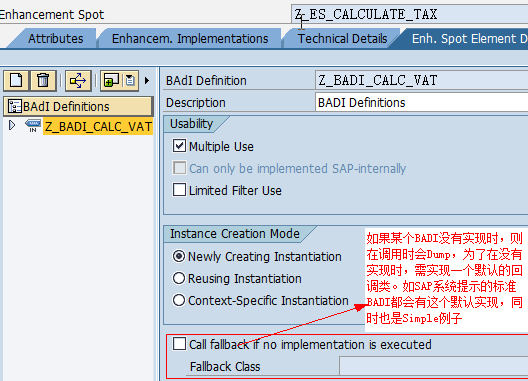
17.3.1.4. 多个BADI/ Enhancement实现时究竟调谁
在同一Enhancement Implementation中(如下图中的Z_BADI_CALC_IMPL_C),不同的BADIImplementations(Z_BADI_CALC_IMPL、Z_BADI_CALC_IMPL2)之间究竟选谁的问题,是由 Default Implementation、Implementation is active选项共同来决定的,且在同一时间内只能有一个BADI Implementations能被激活调用,所以要通过这两个选项来控制究竟谁被用来当作当前实现被使用,是否被使用也可通过图中的 Runtime Behavior说明文字来查看:

不同的Enhancement Implementation之间(Z_BADI_CALC_IMPL、Z_BADI_CALC_IMPL2)调用由过滤器来决定:
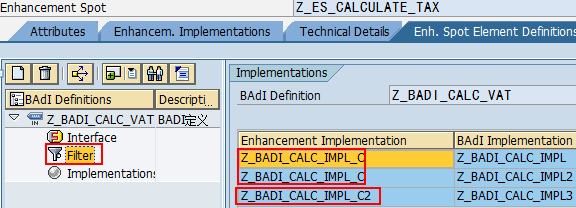
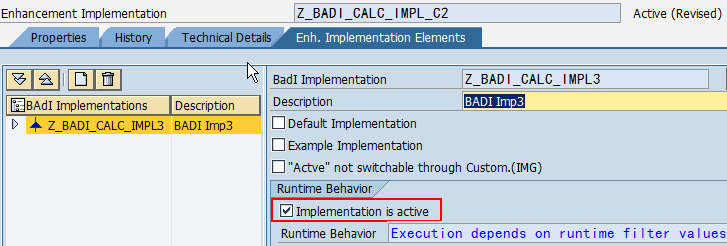
17.3.2.经典BADI创建
通过SE18->Utilities->Create Classic BAdi创建经典BADI
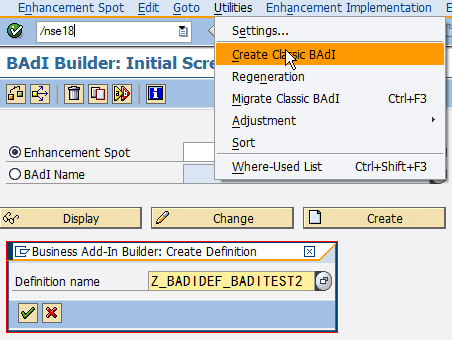
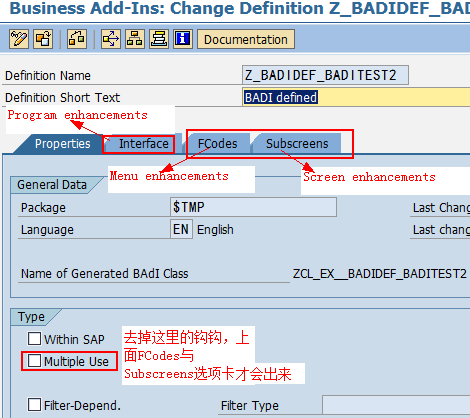

17.3.2.1.Filter-Depend.过滤器
当BADI的某个实现版本有多个实现类时,这时在调用时如果想要调用指定的类,则需添加过滤器参数,该参数实质上由其代理类来使用,在运行时代理类会去实例化所对应的类。
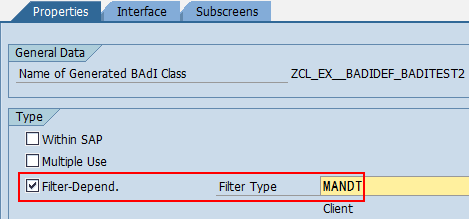
加上该选项后,接口与实现类中的所有方法都会自动的加上一个必输参数:FLT_VAL
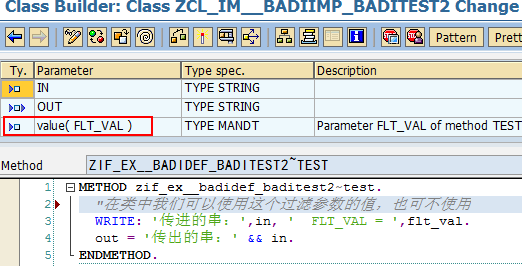
钩选Filter-Depend选项后,我们再为实现增加过滤值:
17.3.2.1.1.调用
DATA: out TYPE string.
DATA: l_badi_instance TYPE REF TO zif_ex__badidef_baditest2. zif_ex__badidef_baditest2是BAdi Definition的Interface name接口名
CALL METHOD cl_exithandler=>get_instance
CHANGING instance = l_badi_instance.
IF l_badi_instance IS NOT INITIAL.
CALL METHOD l_badi_instance->test
EXPORTING
"flt_val参数是由l_badi_instance实例来使用的,从这里可以推断l_badi_instance应该属于代理对象,由它在运行时根据过滤器值来选择性的调用相应实现类的方法
flt_val = '800'
in = 'hello'
CHANGING
out = out.
WRITE: / out.
ENDIF.
17.3.2.2. 通过经典BADI扩展自定义程序(菜单、屏幕、功能)
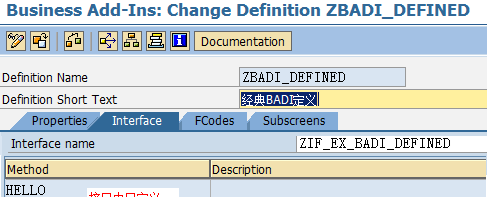


下面是实现:
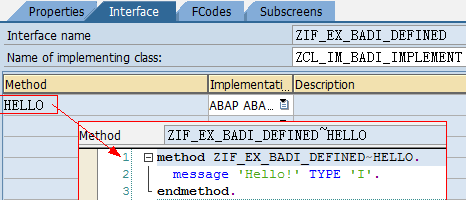


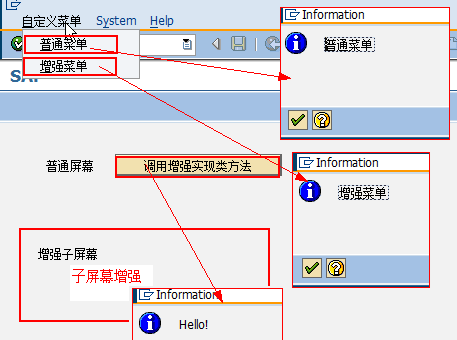
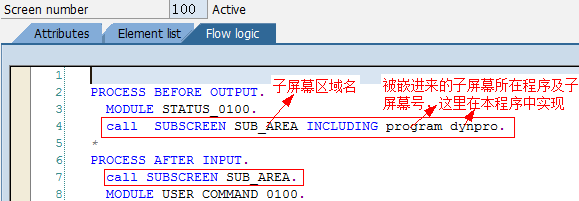
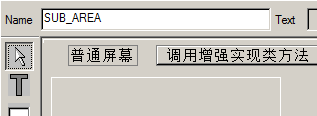

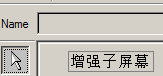
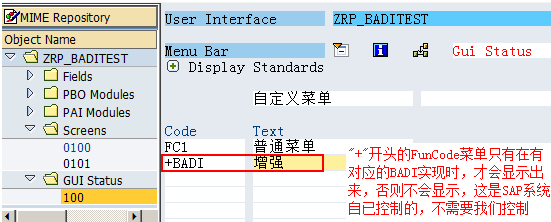
DATA: ok_code LIKE sy-ucomm.
DATA: program TYPE program,
dynpro TYPE dynnr.
DATA: ref_badi_interface TYPE REF TO zif_ex_badi_defined.
CALL SCREEN 100.
MODULE status_0100 OUTPUT.
SET PF-STATUS '100'.
IF ref_badi_interface IS INITIAL.
DATA: act_imp_existing .
"获取 BADI 的实现 Generated Exit Class
CALL METHOD cl_exithandler=>get_instance
EXPORTING
exit_name = 'ZBADI_DEFINED'
"如果未找到BADI实现或有实现但未激活时,ref_badi_interface是否可以接受NULL(即 INITIAL)
"一般设置为空,在为空时,如果未实现或未激活时,还是会返回一个代理实现,这样后面程序运行不
"会出错,否则设置为X时,在未实现或未激活时,ref_badi_interface不会有值,则如果通过它调用
"方法时,会抛异常
null_instance_accepted = ' '
IMPORTING
act_imp_existing = act_imp_existing "实现是否已激活
CHANGING
instance = ref_badi_interface.
IF act_imp_existing <> 'X'.
MESSAGE 'BADI实现没有被激活' TYPE 'I'.
"EXIT.
ENDIF.
CALL METHOD cl_exithandler=>set_instance_for_subscreens
EXPORTING
instance = ref_badi_interface.
"获取BADI实现中所配置的增强子屏幕信息
CALL METHOD cl_exithandler=>get_prog_and_dynp_for_subscr
EXPORTING
exit_name = 'ZBADI_DEFINED'"BADI 出口名,即BADI定义名
calling_dynpro = '0100'"主调屏幕号
calling_program = 'ZRP_BADITEST'"主调屏幕所属程序
subscreen_area = 'SUB_AREA'"主调屏幕中的增强子屏幕区域名
IMPORTING
called_dynpro = dynpro "增强子屏幕号
called_program = program."增强子屏幕所属程序
ENDIF.
ENDMODULE. " STATUS_0100 OUTPUT
MODULE user_command_0100 INPUT.
CASE ok_code.
WHEN 'FC1'.
MESSAGE '普通菜单' TYPE 'I'.
"只要BADI实现激活后,才会出现菜单,即可以点击,才可能走这里的逻辑
WHEN '+BADI'.
MESSAGE '增强菜单' TYPE 'I'.
WHEN 'BUT1'.
"如果BADI未实现或实现但未激活时,只要 cl_exithandler=>get_instance
"时,设置输入参数 null_instance_accepted = ' ',ref_badi_interface
"就会指向一个代理实现类,调用不会抛异常,但只是个空的方法,什么作用
"也不会有
CALL METHOD ref_badi_interface->hello.
ENDCASE.
ENDMODULE.
17.3.3.示例:通过BADI实现采购订单屏幕增强
主要用到两个BADI:ME_GUI_PO_CUST(屏幕处理)和ME_PROCESS_PO_CUST(业务数据处理)
详细请参考增强相关文档
17.4.第四代:Enhancement-Point
此种不建议使用,只有无法通过 User Exit与BADI都无法实现时,才考虑这个
第四代其实是第三代上的加强
Ehancement Spot: 用来组织Enhancement options,it's a container of Enhancement options
Enhancement Implementation:用来组织Enhancement options的实现代码
Enhancement Spot是对Enhancement的一个管理平台,Enhancement-Point技术与BADI是有区别的,首先BADI是SAP预留的类的接口,而Enhancement-Point则是允许用户对现有的SAP代码进行修改,例如插入、替换,只要符合一定的规则即可,不需要SAP预先定义好
ENHANCEMENT-POINT是在程序中直接插入代码,其概念与BADI的USER_EXIT类似,标准程序预留了部分已定义好的增强点可以让ABAP做插入代码来实现这个增强(也可以自定义增强点(ENHANCEMENT-POINT),但不能自定义增强选项(ENHANCEMENT-OPTION),增强选项一定是系统预留下来的,如果没有增强选项则该处不可做增强),但是不能做屏幕和菜单增强。
其最大的优势在于方便,可以直接使用程序中所有已定义的变量,不像BADI和USER EXIT中只能使用方法或函数接口传过来看参数
一般增强步骤:
1.DEBUG标准程序找到需要增强的位置,点EDIT->SHOW IMPLICIT ENHANCEMENT OPTIONS查看是否有预留增强选项。(标准程序不能自己创建enhancement option ,只能使用系统预留的)
2.创建增强点实现
17.4.1.为自己程序创建显示增强
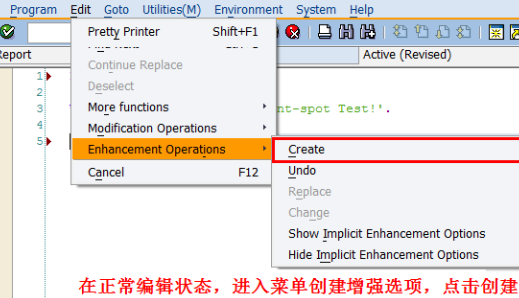
进入创建增强选项界面,输入增强点名及增强容器名(以Z开头),确认回车。
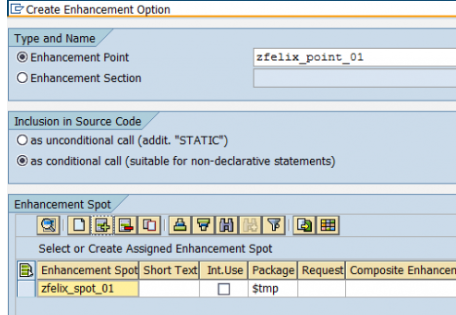
注:Enhancement Spot 就是SE18中的Enhancement Spot
随后Editor上会多出一条语句,然后转到增强模式
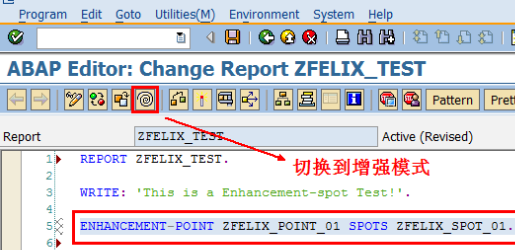
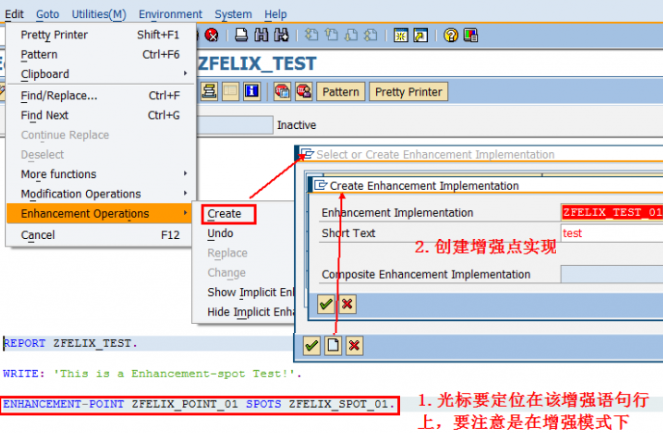
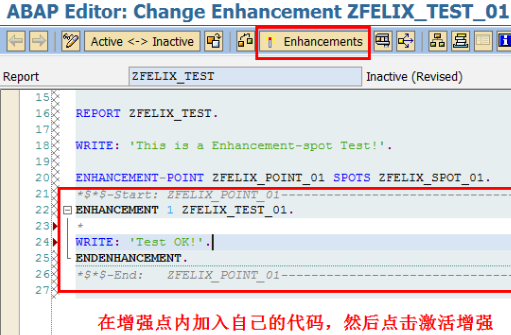
注:Enhancement Spot相当于一个容器,创建一个增强点的必要条件是要有一个容器。每个增强点(如ZENH_POINT_01)都可以创建到这个容器当中,也可以再创建一个容器。删除这个容器的方法:在本地对象或它的包中删除或在SE18中删除
对于ENHANCEMENT-SECTION,定义和实现的方法与ENHANCEMENT-POINT一样。两者的区别是:enhancement-point没有代码,只有一个预留点,允许在这个位置插入新代码(implementation),而nhancement-section和end-enhancement-section.之间有代码,implementation之后,替换旧代码,只执行新代码,原来的代码不再执行
17.4.2.隐式与显示增强
Implicit enhancements comprise(包含)class enhancements, function group enhancements and predefined enhancement points at particular predefined positions such as the end of a report, a function module, an include or a structure and the beginning and the end of a method。隐式增强就是系统内置的Enhancement options
显式增强就是手动加入到程序中的Enhancement options,有两种显式增强:
ENHANCEMENT-POINT,用来插入新的功能代码,没有代码,只有一个预留点
Defines a position in an ABAP program as an enhancement option, at which one or more source code plug-ins can be inserted.
ENHANCEMENT-POINT enh_id SPOTS spot1 spot2 ...
[STATIC]
[INCLUDE BOUND].
ENHANCEMENT-SECTION,ENHANCEMENT-SECTION 和 END-ENHANCEMENT-SECTION. 之间有代码, implementation 之后,替换旧代码,只执行新代码,原来的代码不再执行
Defines a section of an ABAP program as an enhancement option, which can can be replaced by one or more source code plug-ins.
ENHANCEMENT-SECTION enh_id SPOTS spot1 spot2 ...
[STATIC]
[INCLUDE BOUND].
...
END-ENHANCEMENT-SECTION.
隐式增强:在 执行程序,包含程序,函数组,对话模块的结尾;Form例程,函数模块,方法等的开始和结尾;结构的结尾这些地方都会有
显示增强:需要在编辑器中创建,可参考上面
18.数据批量维护
18.1.BDC(SM35、SHDB)

运行程序时可指定数据来源于服务器上的某个测试文件。
可以通过SAP提供的工具CG3Y,将此生成的服务器测试数据文件下载到本地后进行编辑,修改好后,再通过工具CG3Z将文件上传到服务器上
生成以内表作为测试数据源的程序:
从本地读取测试数据文件:需手动读取本地文件
BDC的两种通用写法。
1. Call Transaction: 顾名思义,就是直接调用BDC进行数据批量导入。优点:方便快捷,程序处理方便。缺点:日志管理能力差,需自己建透明表来维护数据。我只是把它用作测试用途,不做正式使用。
2. BDC Insert(即CALL Function):这是一种不直接运行,而是将BDC程序生成session(但不立即运行,需要手工或通过RSBDCSUB专用程序来运行会话)。优点:通过T-code SM35可以进行运行管理及日志管理,方便查错。缺点:相对方法1来说实现起来比较繁琐。我主要是用这种方法来实现BDC功能。
下面主要来谈一下BDC Insert这种方法。
1. 需要在程序中调用 function BDC_OPEN_GROUP、'BDC_INSERT'来把BDCDATA生成SESSION.
2. 通过程序RSBDCSUB来执行SESSION(后续建立JOB中使用,目前手动运行会话)
3. 建立BATCH JOB来定期执行RSBDCSUB,从而实现SESSION自动执行的目的
4. 当然,不使用程序RSBDCSUB和JOB,每次手工在SM35中执行SESSION也是可以的
18.2.LSMW
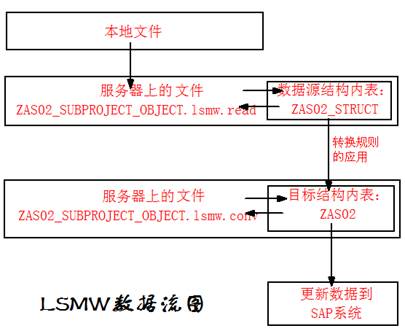

创建数据源存储结构
数据源结构与目标结构映射
分配字段转换规则
指定数据源文件并分配给数据源结构
将文件内容读取到服务器上
数据转换:数据会从.read文件中,经转换后存储到.conv文件中
18.3.业务对象和BAPI
18.3.1.SAP业务对象(SWO1)
业务对象类型是业务对象的定义和描述,对象类型(Object Type) 相当于(但不等于)对象设计语言中类(Class) 的概念,它封装了业务功能和数据
业务对象与BAPI早于ABAP OO,通过非面向对象语言,以面向对象的形式设计了业务对象与BAPI
18.3.1.1.业务对象类型的组成
l 接口:需实现的业务接口,可以是多个
l 关键字段:用于唯一确定一个业务对象类型的实例,通常是业务对象底层数据库表的对应主键
l 属性:业务对象的数据部分, 可以是数据表中的字段、运行值(又称虚拟属性, virtual attribute) 或指向其它业务对象的指针(对象引用, object reference)等
l 方法:用于操作业务对象属性,可以通过调用事务、function module、 report 或ABAP程序来实现方法,即业务方法的实现方法有多种
l 事件:状态的改变,可通过事件触发工作流或任务
业务对象类型也是可以继承的,如业务对象类型BUS1001006(标准物料)和BUS1001001(零售物料)的父类型都是BUS1001(物料):
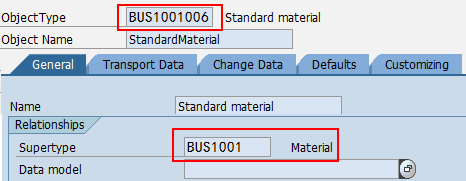
18.3.1.2.业务对象(BO)设计
18.3.1.2.1.创建业务表
业务对象代表具体的业务数据,因此业务对象类型都有相对应的数据字典结构对应:

18.3.1.2.2.创建业务对象类型


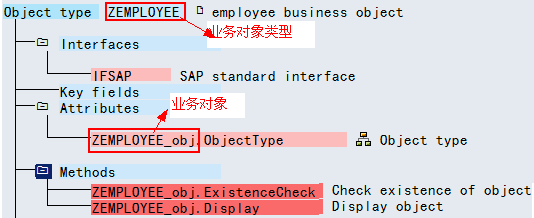
系统已自动引用SAP标准接口IFSAP,并从中继承了一些默认的属性和方法
18.3.1.2.3.添加(继承)接口
创建业务对象类型时,除自动默认继承的接口IFSAP外:

还可以为业务对象添加(或叫实现吧)其他的SAP接口,业务对象将从接口中自动继承接口里的属性或方法,其中大多方法需要在业务对象中重新实现。将光标放在Interfaces位置,点击按钮![]() ,添加IFCREATE接口
,添加IFCREATE接口
注:这些接口类型也是通过SWO1创建的,只是在初始界面选择的是“Interface type(相当于接口)”,而不是“Object type(相当于类)”
同理添加IFEDIT接口,最后结构如下:
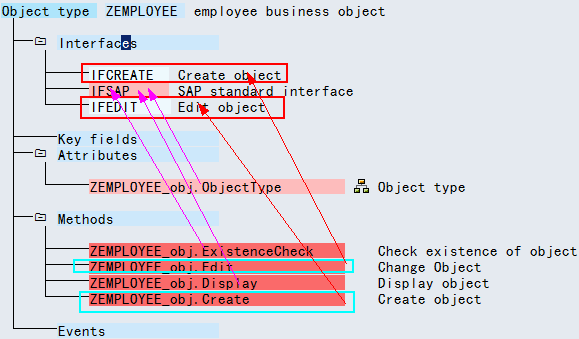
通过查看继承过来的方法属性,发现只有Create方法是静态的,与实例无关
18.3.1.2.4.添加关键字段Key
关键字段代表着一个业务对象类型的实例,由它来区分各个业务对象,实例业务对象需要此Key
将鼠标放在“Key fields”所在位置上,点击新建按钮![]() ,系统将提示是否参照ABAP字典中的表结构创建关键字段,本例中的业务对象基于数据库表ZTAB_EMPLOYEE:
,系统将提示是否参照ABAP字典中的表结构创建关键字段,本例中的业务对象基于数据库表ZTAB_EMPLOYEE:


生成的程序代码:

18.3.1.2.5.添加属性
将光标置于Attributes所在行,点击新建按钮![]() 功能,系统将提示是否参照ABAP字典中的表结构创建关键字段:
功能,系统将提示是否参照ABAP字典中的表结构创建关键字段:
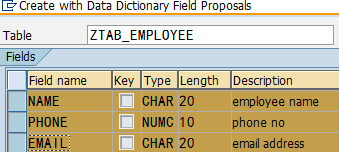
并为每一个属性输入名称之后,各字段将出现在Attributes列表中:
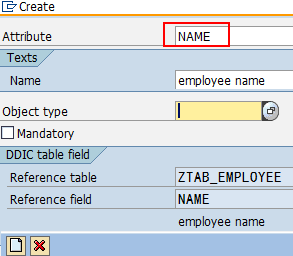
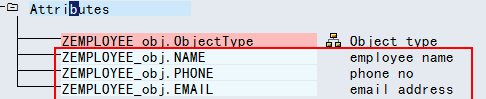
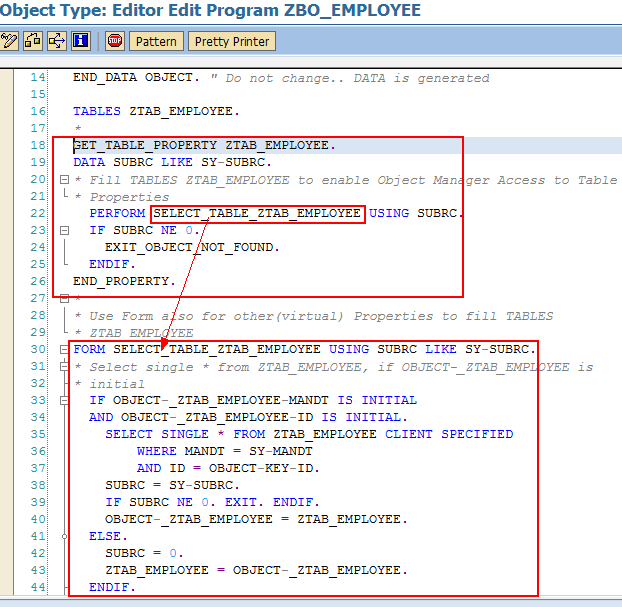
18.3.1.2.6.通过报表程序来实现业务对象的方法
18.3.1.2.6.1.报表程序
现以报表程序的方式,来重新实现业务对象类型继承过来原有方法(Create、Edit、Display等),业务对象的这些方法将通过提交到该报表的方式来实现这些方法的功能:
REPORT zbo_employee_rep.
TABLES: ztab_employee.
PARAMETERS: id LIKE ztab_employee-id OBLIGATORY,
name LIKE ztab_employee-name,
phone LIKE ztab_employee-phone,
email LIKE ztab_employee-email,
op.
START-OF-SELECTION.
ztab_employee-id = id.
ztab_employee-name = name.
ztab_employee-phone = phone.
ztab_employee-email = email.
CASE op.
WHEN 'I'."插入数据
INSERT ztab_employee.
IF sy-subrc = 0.
MESSAGE s016(rp) WITH 'One record inserted.'.
ELSE.
MESSAGE e016(rp) WITH 'No record inserted,ID existed.'.
ENDIF.
WHEN 'U'."更新数据
UPDATE ztab_employee.
IF sy-subrc = 0.
MESSAGE s016(rp) WITH 'One record updated.'.
ELSE.
MESSAGE e016(rp) WITH 'No record update,ID not existed.'.
ENDIF.
WHEN 'V'."显示数据
SELECT SINGLE * FROM ztab_employee WHERE id = ztab_employee-id.
IF sy-subrc = 0.
WRITE:/ 'Employee No:',ztab_employee-id,
/ 'Employee Name:',ztab_employee-name,
/ 'Employee Phone:',ztab_employee-phone,
/ 'Employee Email:',ztab_employee-email.
ENDIF.
ENDCASE.
18.3.1.2.6.2.重定义接口与方法实现
在没有进行重定义之前,这些继承而来的方法名称显示为深红色。将光标置于方法名上,点击![]() (即方法的重定义)按钮,每个方法都经过该操作后,底色会变为白色:
(即方法的重定义)按钮,每个方法都经过该操作后,底色会变为白色:

将光标置于Display方法名上,点击“Program”按钮,提示方法还未进行代码实现:
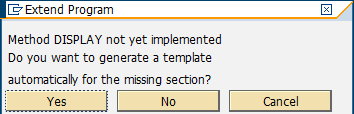
YES后,进行程序代码实现界面,在业务对象的实现程序中添加以下代码:

ExistenceCheck方法用于检查对象实现是否存在,如在对象测试界面中,需要选择“Instance”按钮来测试实例相关的一些方法时,如果未实现该方法,则如果输入一个不存在的ID,系统将仍进入实例测试界面,但实例相关的测试功能不可用。正确实现ExistenceCheck方法后,如果指定关键字段的对象不存在,系统将给出消息提示:Object does not exist。
其中object变量为前面自动生成的变量,相关代码如下:
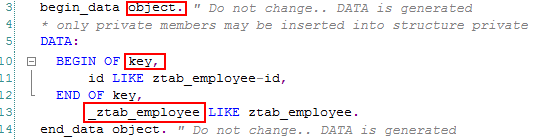
注:在每次修改程序后,都需要保存并重新生成![]() 业务对象类型,才能进行测试
业务对象类型,才能进行测试
18.3.1.2.6.3.测试

注:测试界面上的屏幕参数就是 Report 程序选择屏幕
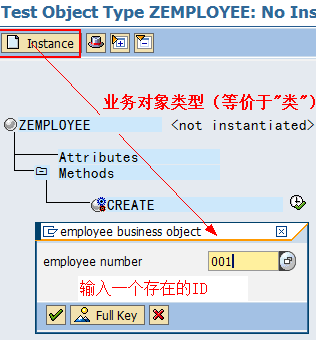
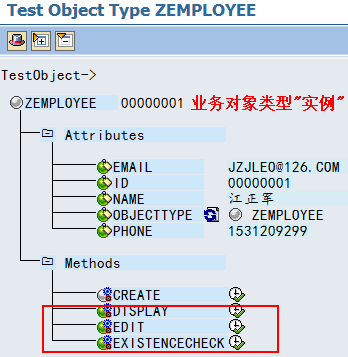
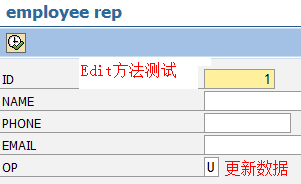

18.3.1.2.7.通过BAPI函数来实现业务对象方法
本小节将在前面章节的基础上,为业务对象类型添加两个BAPI方法:ZEMPLOYEE_obj.GetList(读取职员列表)和ZEMPLOYEE_obj.GetDetail(读取职员详细信息)。
BAPI方法与上节中所添加的普通方法是不同的,那些借助于报表程序来实现的Create、Edit等方法,仅可在SAP系统内部使用,但BAPI不同的是可以供非SAP系统对业务对象进行访问。
18.3.1.2.7.1.创建BAPI参数结构
BAPI方法ZEMPLOYEE_obj.GetList需要用到的结构类型(BAPI自定义结构类型需要以ZBAPI开头——其实BAPI函数、BAPI函数的Group、以及BAPI函数参数参照的结构名称中都需要包含BAPI名称串,另外,BAPI函数参数所参照的表结构类型只能被一个BAPI使用,因为释放BAPI后相应结构会被冻结):
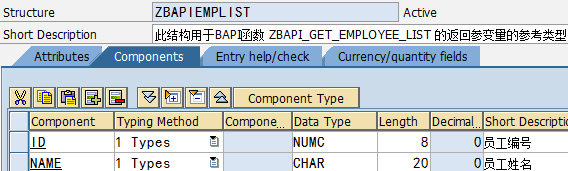
BAPI方法ZEMPLOYEE_obj.GetDetail需要用到的结构类型:

18.3.1.2.7.2.创建BAPI函数、BAPI调用返回RETURN结果处理
先创建函数组 ZEMP,并激活:

现创建BAPI方法需要调用的两个RFM远程函数:ZBAPI_GET_EMPLOYEE_LIST和ZBAPI_GET_EMPLOYEE_DETAIL,ZEMPLOYEE_obj.GetList、ZEMPLOYEE_obj.GetDetail两个BAPI业务方法将借助于这两个BAPI函数来实现。

注:BAPI函数中Export必须有return返回参数(约定俗成), BAPI调用成功与否一般通过RETURN参数返回,该参数的数据结构可以参照数据字典结构BAPIRETURN,其重要的字段有:
lTYPE, 消息类型,如S、E、W、I
lID, 消息类型
lNUMBER, 消息编号
lMESSAGE, 消息文本
lMESSAGE_V1、MESSAGE_V2、MESSAGE_V3、MESSAGE_V4,消息变量

在函数组ZEMP 的LZEMPTOP顶层包含文件中定义全局的数据变量:
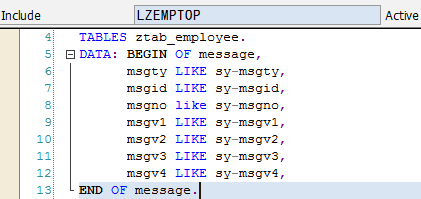
并为ZBAPI_GET_EMPLOYEE_LIST函数添加以下源码:
FUNCTION zbapi_get_employee_list.
*"----------------------------------------------------------------------
*"*"Local Interface:
*" EXPORTING
*" VALUE(RETURN) TYPE BAPIRETURN
*" TABLES
*" ZEMP_LIST STRUCTURE ZBAPIEMPLIST
*"----------------------------------------------------------------------
CLEAR zemp_list.
REFRESH zemp_list.
CLEAR return.
CLEAR ztab_employee.
SELECT * FROM ztab_employee INTO CORRESPONDING FIELDS OF TABLE zemp_list.
IF sy-subrc <> 0."如果BAPI函数中数据验证不通过,则对返回具有E类型消息的RETURN消息返回内表,则外部主调程序对RETURN内表进行判断,根据RETURN中的结果来决定是否Commit Work
CLEAR message.
message-msgty = 'E'.
message-msgid = 'RP'.
message-msgno = 16.
message-msgv1 = 'No Employee is available.'.
PERFORM set_return_message USING message CHANGING return.
ENDIF.
ENDFUNCTION.
BAPIRETURN构造:
FORM set_return_message USING p_message LIKE message
CHANGING p_return LIKE bapireturn.
CHECK NOT message IS INITIAL.
CALL FUNCTION 'BALW_BAPIRETURN_GET'
EXPORTING
type = p_message-msgty
cl = p_message-msgid
number = p_message-msgno
par1 = p_message-msgv1
par2 = p_message-msgv2
par3 = p_message-msgv3
par4 = p_message-msgv4
IMPORTING
bapireturn = p_return
EXCEPTIONS
OTHERS = 1.
ENDFORM.

注:此BAPI函数为实例对象业务方法,所以需要在Import设置与业务对象Key一样的参数,如这里的ID(名称与类型最好都一致)

FUNCTION zbapi_get_employee_detail.
*"----------------------------------------------------------------------
*"*"Local Interface:
*" IMPORTING
*" VALUE(ID) TYPE ZTAB_EMPLOYEE-ID
*" EXPORTING
*" VALUE(ZEMP_DETAIL) TYPE ZBAPIEMPDETAIL
*" TABLES
*" RETURN STRUCTURE BAPIRETURN
*"----------------------------------------------------------------------
CLEAR zemp_detail.
CLEAR return.
CLEAR ztab_employee.
SELECT SINGLE * FROM ztab_employee INTO CORRESPONDING FIELDS OF zemp_detail WHERE id = id.
IF sy-subrc <> 0.
CLEAR message.
message-msgty = 'E'.
message-msgid = 'RP'.
message-msgno = 16.
message-msgv1 = 'Employee does not exist.'.
PERFORM set_return_message USING message CHANGING return.
ENDIF.
ENDFUNCTION.
18.3.1.2.7.3.将BAPI函数绑定到相应的业务方法
为什么在RFC函数创建好后,还需要将该函数绑定到业务对象类型中:

创建BAPI的最后一步就是为业务对象类型添加BAPI方法,并将上面创建BAPI函数分配给这些BAPI方法:


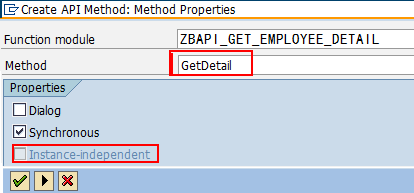
由于BAPI函数中定义了关键字段作为输入参数,当在添加该方法时就默认此方法为实例方法,所以不能选中Instance-independent选项
点击![]() 按钮进行下一步操作,设置待加BAPI方法的参数,一般使用建议,与BAPI函数参数相对应:
按钮进行下一步操作,设置待加BAPI方法的参数,一般使用建议,与BAPI函数参数相对应:


绿色![]() 表示为BAPI方法
表示为BAPI方法

通过相同的方法,创建List BAPI方法,并将ZBAPI_GET_EMPLOYEE_LIST BAPI函数分配给它,由于List为静态方法,所以钩上Instance-independent:
![]()
业务对象方法如果是通过BAPI方法来实现的,则实现方式要选择API function,另外还需要指定对应到的BAPI功能模块:

18.3.2.BAPI
BAPI:Business Application Process Interface(业务应用编辑接口),它实质上就是一种特殊的RFC函数
BAPI函数及函数参数参考的结构类型名,都要以ZBAPI开
BAPI函数参数只能是传值,不能有Change与Exception参数
BAPI函数需要有Return返回参数
18.3.2.1.BAPI浏览器


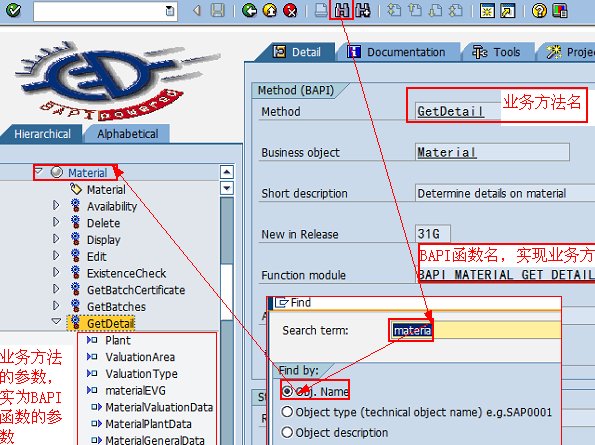
18.3.2.2.SE37查找:BAPI函数的命名规则
BAPI对应的功能模块命名规则BAPI_<业务对象名>_<method>,因此可以直接在SE37中通过前缀BAPI加对象名称或方法名称作为关键字,快速查找一个BAPI功能模块函数。如检索 BAPI*Material*Get*
18.3.2.3.查找某事务码所对应的BAPI
如果只知道事物代码,可以通过下面的方式查询相应的BAPI。例如找创建销售(物料模板根据此方法好像找不出)订单的BAPI,我们知道事物代码是VA01:
1.我们进入VA01 界面,找到system status
2.在事物代码位置上双击(注:不是程序上双击),找到PACKAGE VA
3.用SE80打开包 VA ,或点击 Display Object List按钮直接进入到SE80对象列表:
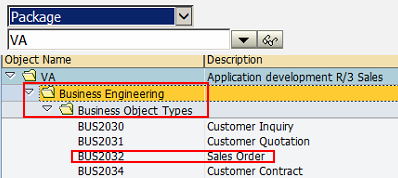

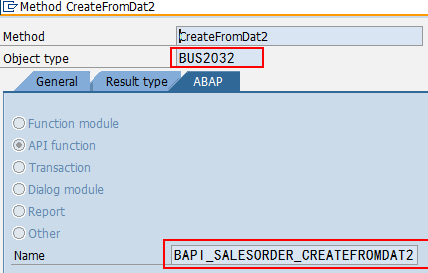
18.3.2.4.常用BAPI函数
BAPI_TRANSACTION_COMMIT COMMIT WORK AND WAIT.
BAPI_TRANSACTION_ROLLBACK ROLLBACK WORK.
BAPI_MATERIAL_SAVEDATA 创建及更改物料主数据
BAPI_GOODSMVT_CREATE 物料移动(创建物料凭证 )
BAPI_MATERIAL_AVAILABILITY 可用库存
BAPI_PR_CREATE 创建PR (采购申请)
BAPI_PO_CREATE1 创建PO(采购单)
BAPI_SALESORDER_CREATEFROMDAT2 创建销售订单
BAPI_OUTB_DELIVERY_CREATE_SLS 根据销售订单创建交货单
BAPI_BILLINGDOC_CREATEMULTIPLE 创建发票
BAPI_ACC_DOCUMENT_POST 创建会计凭证
18.3.2.5.调用BAPI
SAP系统提供的BAPI的参数结构有个特点:一般会将类似的字段放在同一个结构中,同时,还会存在一个与该结构名类似(后面以X结尾)标识结构,该标识结构中的字段名与赋值的结构中的字段名一致,但是其字段类型只是一个长度为1的字符,用于标识某个字段的数据是否需要通过BAPI来变更
18.3.2.5.1.BAPI事务处理
根据事务的ACID原则,一个独立的BAPI实现必须具有事务性,同时,BAPI事务模型还必须允许开发者在调用多个BAPI时可以将它们绑定到同一个LUW上。因此,如果同时调用几个BAPI,开发者需要在程序中进行的事务控制,决定何时执行数据库提交或回滚操作;而BAPI内部则通常不包含COMMIT WORK和ROLLBACK WORK命令
操作多个BAPI时必须遵循以下原则:
l如果有更新操作的BAPI,如创建、修改或删除一个业务对象实例,则对该实例进行另外的读取操作的BAPI只能访问上一个COMMIT WORK执行后的最新数据
l在同一个LUW中,不能对同一个业务对象实例时行超过一次的更新操作。例如,不允许在一个LUW中创建一个新实例,随后就修改它。但可以创建多个相同的类型的不同实例
在BAPI内部,数据库更新操作必须通过同步或异步的更新过程实现(需使用CALL FUNCTION update_function IN UPDATE TASK的方式来更新数据库),因为否则可能出现不必要的数据库提交过程,从而破坏了BAPI调用的ACID原则。同样原因,BAPI内部也不能触发新的LUW,因而其内部程序代码中不能包含以下命令:
lCALL TRANSACTION
lSUBMIT REPORT AND RETURN
lCOMMIT WORK
lROLLBACK WORK
因此,BAPI事务中的数据库提交和回滚必须在主调程序中通过调用SAP标准业务对象BapiService(业务对象类型为SAP0001)的BAPI方法BapiService.TransactionCommit(此BAPI方法实际上还是通过调用BAPI函数BAPI_TRANSACTION_COMMIT来实现的)和BapiService.TransactionRollback(此BAPI方法实际上还是通过调用BAPI函数BAPI_TRANSACTION_ROLLBACK来实现的)来完成
外部程序直接到调用BapiService.TransactionCommit方法,才会触发BAPI方法中的数据库提交
对于BAPI的操作都要用BAPI_TRANSACTION_COMMIT来提交的,在提交前,要根据BAPI函数的执行返回参数RETURN来判断函数是否执行成功(RETURN中是否有E类消息),如果有错误消息则要用BAPI_TRANSACTION_ROLLBACK取消所做的操作,而不是COMMIT WORK,如:
CALL FUNCTION 'BAPI_FIXEDASSET_CHANGE'
...
IMPORTING
return = return.
IF return-type <> 'S'.
CALL FUNCTION 'BAPI_TRANSACTION_ROLLBACK'.
ELSE.
CALL FUNCTION 'BAPI_TRANSACTION_COMMIT'
EXPORTING
wait = 'X'.
ENDIF.
另外建议在调用BAPI_TRANSACTION_COMMIT函数进行提交BAPI操作时,加上wait参数,这样直到BAPI函数中的数据库操作提交数据库后,才去执行其后面的语句,这样后面程序依赖于此提交的数据时就不会出问题:
CALL FUNCTION 'BAPI_TRANSACTION_COMMIT'
EXPORTING
wait = 'X'.
WAIT为X时,会执行COMMIT WORK AND WAIT语句,否则执行COMMIT WORK语句
18.3.2.5.2.外部系统(Java)调用BAPI函数
18.3.2.5.2.1. 直连、连接池
import java.io.File;
import java.io.FileOutputStream;
import java.util.Properties;
import com.sap.conn.jco.JCoDestination;ˌdestɪˈneɪʃn
import com.sap.conn.jco.JCoDestinationManager;
import com.sap.conn.jco.JCoException;
import com.sap.conn.jco.ext.DestinationDataProvider;
publicclass ConnectNoPool {// 直连方式,非连接池
// 连接属性配置文件名,名称可以随便取
static String ABAP_AS = "ABAP_AS_WITHOUT_POOL";
static {
Properties connectProperties = new Properties();
connectProperties.setProperty(DestinationDataProvider.JCO_ASHOST,
"192.168.111.137");
connectProperties.setProperty(DestinationDataProvider.JCO_SYSNR, "00");
connectProperties
.setProperty(DestinationDataProvider.JCO_CLIENT, "800");
connectProperties.setProperty(DestinationDataProvider.JCO_USER,
"SAPECC");
// 注:密码是区分大小写的,要注意大小写
connectProperties.setProperty(DestinationDataProvider.JCO_PASSWD,
"sapecc60");
connectProperties.setProperty(DestinationDataProvider.JCO_LANG, "en");
// *********连接池方式与直接不同的是设置了下面两个连接属性
// JCO_PEAK_LIMIT - 同时可创建的最大活动连接数,0表示无限制,默认为JCO_POOL_CAPACITY的值
// 如果小于JCO_POOL_CAPACITY的值,则自动设置为该值,在没有设置JCO_POOL_CAPACITY的情况下为0
connectProperties.setProperty(DestinationDataProvider.JCO_PEAK_LIMIT,
"10");
// JCO_POOL_CAPACITY - 空闲连接数,如果为0,则没有连接池效果,默认为1
connectProperties.setProperty(
DestinationDataProvider.JCO_POOL_CAPACITY, "3");
// 需要将属性配置保存属性文件,该文件的文件名为 ABAP_AS_WITHOUT_POOL.jcoDestination,
// JCoDestinationManager.getDestination()调用时会需要该连接配置文件,后缀名需要为jcoDestination
createDataFile(ABAP_AS, "jcoDestination", connectProperties);
}
// 基于上面设定的属性生成连接配置文件
staticvoid createDataFile(String name, String suffix, Properties properties) {
File cfg = new File(name + "." + suffix);
if (!cfg.exists()) {
try {
FileOutputStream fos = new FileOutputStream(cfg, false);
properties.store(fos, "for tests only !");
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
publicstaticvoid connectWithoutPool() throws JCoException {
// 到当前类所在目录中搜索 ABAP_AS_WITHOUT_POOL.jcoDestination
// 属性连接配置文件,并根据文件中的配置信息来创建连接
JCoDestination destination = JCoDestinationManager
.getDestination(ABAP_AS);// 只需指定文件名(不能带扩展名jcoDestination名,会自动加上)
System.out.println("Attributes:");
// 调用destination属性时就会发起连接,一直等待远程响应
System.out.println(destination.getAttributes());
}
publicstaticvoid main(String[] args) throws JCoException {
connectWithoutPool();
}
}
18.3.2.5.2.2. 访问结构
JCoDestination destination = JCoDestinationManager
.getDestination(ABAP_AS);
JCoFunction function = destination.getRepository().getFunction(
"RFC_SYSTEM_INFO");//从对象仓库中获取 RFM 函数
function.execute(destination);
JCoStructure exportStructure = function.getExportParameterList()
.getStructure("RFCSI_EXPORT");
for (int i = 0; i < exportStructure.getMetaData().getFieldCount(); i++) {
System.out.println(exportStructure.getMetaData().getName(i) + ":\t"
+ exportStructure.getString(i));
}
System.out.println();
// 也可以使用下面的方式来遍历
for (JCoField field : exportStructure) {
System.out.println(field.getName() + ":\t" + field.getString());
}
//*********也可直接通过结构中的字段名或字段所在的索引位置来读取某个字段的值
System.out.println(exportStructure.getString(0));
System.out.println(exportStructure.getString("RFCPROTO"));
18.3.2.5.2.3. 访问表 (Table)
JCoDestination destination = JCoDestinationManager
.getDestination(ABAP_AS);
JCoFunction function = destination.getRepository().getFunction(
"BAPI_COMPANYCODE_GETLIST");//从对象仓库中获取 RFM 函数:获取公司列表
function.execute(destination);
JCoStructure returnStructure = function.getExportParameterList()
.getStructure("RETURN");
//判断读取是否成功
if (!(returnStructure.getString("TYPE").equals("") || returnStructure
.getString("TYPE").equals("S"))) {
throw new RuntimeException(returnStructure.getString("MESSAGE"));
}
//获取Table参数:COMPANYCODE_LIST
JCoTable codes = function.getTableParameterList().getTable(
"COMPANYCODE_LIST");
for (int i = 0; i < codes.getNumRows(); i++) {//遍历Table
codes.setRow(i);//将行指针指向特定的索引行
System.out.println(codes.getString("COMP_CODE") + '\t'
+ codes.getString("COMP_NAME"));
}
// move the table cursor to first row
codes.firstRow();//从首行开始重新遍历 codes.nextRow():如果有下一行,下移一行并返回True
for (int i = 0; i < codes.getNumRows(); i++, codes.nextRow()) {
//进一步获取公司详细信息
function = destination.getRepository().getFunction(
"BAPI_COMPANYCODE_GETDETAIL");
function.getImportParameterList().setValue("COMPANYCODEID",
codes.getString("COMP_CODE"));
// We do not need the addresses, so set the corresponding parameter
// to inactive.
// Inactive parameters will be either not generated or at least
// converted. 不需要返回COMPANYCODE_ADDRESS参数(但服务器端应该还是组织了此数据,只是未经过网络传送?)
function.getExportParameterList().setActive("COMPANYCODE_ADDRESS",
false);
function.execute(destination);
returnStructure = function.getExportParameterList().getStructure(
"RETURN");
if (!(returnStructure.getString("TYPE").equals("")
|| returnStructure.getString("TYPE").equals("S") || returnStructure
.getString("TYPE").equals("W"))) {
throw new RuntimeException(returnStructure.getString("MESSAGE"));
}
JCoStructure detail = function.getExportParameterList()
.getStructure("COMPANYCODE_DETAIL");
System.out.println(detail.getString("COMP_CODE") + '\t'
+ detail.getString("COUNTRY") + '\t'
+ detail.getString("CITY"));
}// for
18.3.2.5.2.4. Java多线程调用有/无状态RFM
有状态调用:指多次调用某个程序(如多次调用某个RFC函数、调用某个函数组中的多个不同的RFC函数、及BAPI函数——因为BAPI函数也是一种特殊的具有RFC功能的函数,它也有自己的函数组)时,在这多次调用过程中,程序运行时的内存状态(即全局变量的值)可以在每次调用后保留下来,供下一次继续使用,而不是每次调用后,程序所在的内存状态被清除。这种调用适用于那些使用到函数组中的全局变量的RFC函数的调用
无状态调用:每次的调用都是独立的一次调用(上一次调用与当前以及下一次调用之间不会共享任何全局变量),调用后不会保留内存状态,这种调用适用于那些没有使用到函数组中的全局变量的RFC函数调用
如果主调程序为Java,有状态调用的前提是:
l 多次调用RFC函数时,Java端要确保每次调用所使用的连接与上次是同一个(应该不需要是同一物理连接,只需要确保是同一远程会话,从下面演示程序来看,用的是连接池,但同一任务执行时并未去特意使用同一物理连接去发送远程调用,而只是要求是同一远程会话)
l ABAP端需要在每次调用后,保留每一次被调用后函数组的内存状态,直到最后一次调用完成止,这需要Java与ABAP配合来完成(Java在第一次调用时,调用JCoContext.begin、JCoContext.end这两个方法,告诉SAP这一调用过程将是有状态调用,需要保留内存状态,然后SAP端就会自动保留内存状态)
如果主调程序是ABAP(即ABAP程序调用ABAP函数),此种情况下没有特殊的要求,直接调用就即可,只要是在同一程序的同一运行会话其间(会话相当于Java中的同一线程吧),不管是多次调用同一个函数、还是调用同一函数组中的不同函数,则都会自动保留内存状态,直到程序运行结束,这是系统自己完成的。一个函数组好比一个类,函数组中不同的函数就相当于类中不同的方法、全局变量就相当于类中的属性,所以只要是在同一程序的同一运行会话期间,调用的同一函数所在的函数组中的全局变量都是共享的,就好比调用一类的某个方法时,该方法设置了某个类的属性,再去调用该类的其它方法时,该属性值还是保留了以前其它方法修改后的状态值。
状态调用只要保证同一Java线程中多次远程方法调用采用的都是同一会话即可
18.3.2.5.3.ABAP访问Java服务
18.3.2.5.4.ABAP创建远程目标
SAP通过JCO反向调用JAVA的RFC服务其实也是相对简单的,只是在JAVA端需要使用JCO创建一个RFC服务,然后在SAP端注册这个服务程序。
首先,JCo服务器程序需在网关中进行注册,在SM59中,定义一个连接类型为T的远程目标
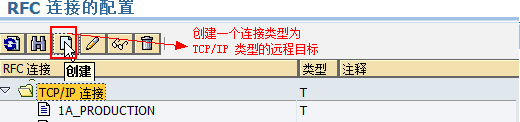
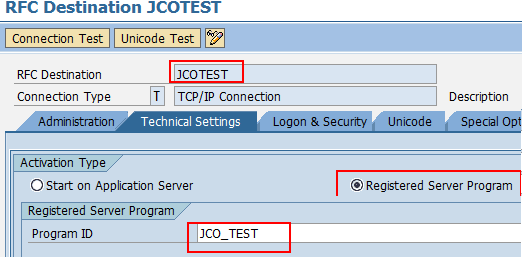
RFC目标系统:是ABAP RFC调用Java时,需指定的目标系统名。
Program ID:是JAVA程序中使用的
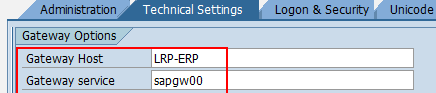
Gateway Host与Gateway service值来自以下界面(Tcode:SMGW):
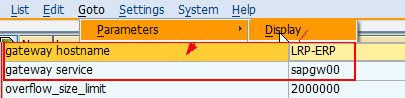
TCP服务sapgw是固定的,后面的00就是系统编号
所有配置好且Java服务器代码跑起来后,点击“Connection Test”按钮,如不出现红色文本,则表示链接成功(注:此时需要ServerDataProvider.JCO_PROGID设置的Program ID要与SM59中设置的相同,否则测试不成功。另要注意的是:即使Java服务器设置的Program ID乱设置,Java服务端还是能启起来,但ABAP测试连接时会不成功,也就代表ABAP不能调用Java)
18.3.2.5.5.连接异常registrationnot allowed
Java服务启动时,如出现以下异常,则需在SAP中修改网关参数:
com.sap.conn.jco.JCoException: (113) JCO_ERROR_REGISTRATION_DENIED: CPIC-CALL: SAP_CMACCPTP3 on convId:
LOCATION SAP-Gateway on host LRP-ERP / sapgw00
ERROR registration of tp JCOTEST from host JIANGZHENGJUN not allowed
……
通过事务码SMGW修改参数:

18.3.2.5.6.带状态访问
// 如果是某任务LUW中第一次调用时,则jcoServerCtx服务上下文为非状态,需设置为状态调用
if (!jcoServerCtx.isStatefulSession()) {
// 设置为状态调用,这样在有状态调用的情况下,上下文中会携带会话ID
jcoServerCtx.setStateful(true);
cachedSession = new SessionContext();// 新建会话
// 将会话存储在映射表中,以便某个任务里每次远程调用都可以拿到同一会话
statefulSessions.put(jcoServerCtx.getSessionID(),
cachedSession);
} else {// 非第一次调用
cachedSession = statefulSessions.get(jcoServerCtx
.getSessionID());
}
18.4.IDoc
IDoc是基于文档,用作异步传输数据的载体,类似于XML
18.4.1.数据段类型和数据段定义(WE31)
数据段是IDoc结构组件,是IDoc的构成的单元。它由Segment type(数据段类型)与Segm. definition(数据段定义)两部分组成,其中Segment type的名称与SAP版本无关,但Segm. definition名称是与SAP版本有关的,外部系统就是根据Segm. definition名称来确定当前数据段的版本的:
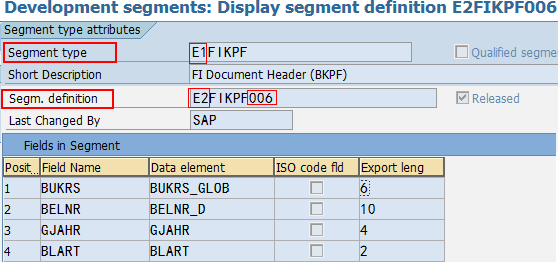
SAP提供的标准数据段类型定义中,Segment type名称以“E1”开头,而Segm. definition名称则以“E2”开头(如果为用户自定的数据段,则数据段类型名应以“Z1”开头,数据段定义名称应以“Z2”开头),且后面跟上版本号(如上面的006),如数据段类型E1FIKPF对应多个版本的数据段定义(包括最初版本在内共7个版本):

双击006版本,即可查看数据段类型F1FIKPF的最新具体定义,如上上图所示
IDoc数据段中各个字段的数据类型均为字符类型(如上上图中的Export leng),在出站时已将原数据类型都转换为字符型了。另外,在ABAP程序中,访问IDoc中的具体某个字段时,需要通过Segment type(数据段类型)名而不是Segm. definition(数据段定义)名,如:E1FIKPF-BUKRS,而不是E2FIKPF006-BUKRS之类的。
IDoc Type中的数据段类型实质会在数据字典中的创建相应的结构,如上图数据段类型E1FIKPF:
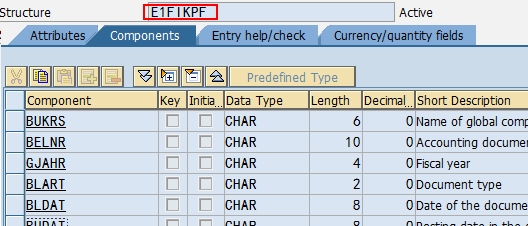
18.4.2.IDoc定义(WE30)
IDoc类型中定义了数据段以及数据段的层级和次序

标准SAP系统提供的IDoc类型称为基本类型(Basic type),该类型可以通过IDoc扩展(Extention)进行调整,即在SAP IDoc类型结构的基础上增加新的数据段或者在数据段中增加新字段
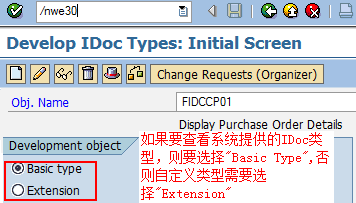
如果是自己完全创建一个新的类型,不扩展任何类型,则选择“Basic Type”,否则如果是要从已存在类型来扩展出新的类型时,需要选择“Extension”,并且需要指定basic type
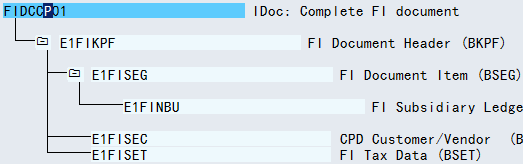
18.4.3.自定义IDoc发送与接收实例
该实例使用800发送端向810接收端发送Idoc进行实验
18.4.3.1.发送端800(outbound)配置
1、创建segment(WE31)
segment,类似于创建XML的节点及节点属性,即定义XML文档中的节点及节点属性。
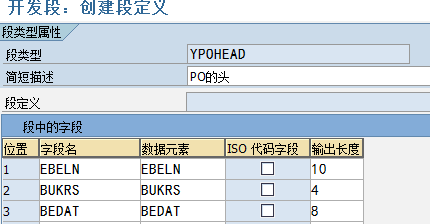
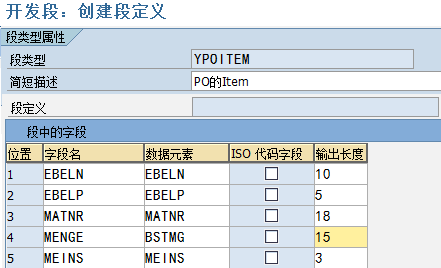
2、创建IDOC Type(WE30)
创建IDOC Type,定义结点间的相互逻辑关系
先输入YPOIDOC,然后点击创建,紧跟着选择create new:
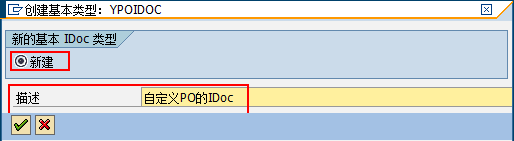
在主界面中,先点击创建按钮,将YPOHEAD添加,设置Mandatory seg打勾,min = 1, max = 1,代表我们每个IDOC仅包含一张采购订单:

然后在YPOHEAD下添加YPOITEM,同样的Mandatory seg打勾,min = 1, max =99999:

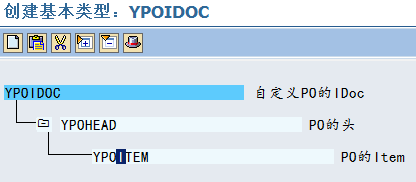
3、创建Message Type(WE81)
先切换到编辑状态,然后点击New Entries,输入YPO_MESS_TYPE即可。

4、关联Message Type和IDOC Type(WE82)

5、创建接收端RFC Destination(SM59)
创建一个到接收端810的物理连接,由于是该实例是在同一个SAP系统内部进行实验,所以“连接类型”选择的是ABAP Connection连接,名为ZTO810:


6、创建到收端的端口(WE21)
注:这里讲的端口不是单纯的指定Socket端口号,而是指连接到RFC目标系统的统称,包括IP、端口等信息,实质上是在SM59创建的物理连接基础之上创建的另一种逻辑名而已
基于上面第5步创建的RFC Destionation,创建端口Port,类型选TRANSACTIONAL RFC,名为TO810PORT,RFC destination则填写ZTO810:


7、创建发送端Logical System并分配(SALE)
为发送端800创建逻辑系统 Z800LS:
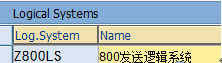
并将逻辑系统分配到发送端800:
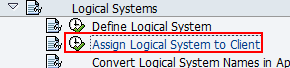
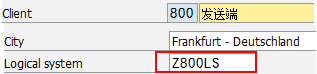
注:这里不需要为本端(Client 800)在本端创建发送端逻辑系统的合作和伴配置文件,但需要在接收端810中配置
8、创建接收端Logical System(SALE)
为接收端810创建逻辑系统 Z810LS,这将在下一步创建到接收端的合作伙伴配置文件Partner profile(WE20)时用到:

但与上面创建发送端逻辑系统不一样的是,在发送端系统800中是不需要将它分配给Client 810,而分配操作是在接收端810中进行的,这一分配操作请参考后面接收端(Inbound)配置章节
9、创建接收端合作和伴配置文件Partner profile(WE20)
合作和伴配置文件将Message Type消息类型、receiver port RFC目标端口、IDoc类型关联起来
创建一个patner no为Z810LS的合作和伴配置文件,该配置文件描述了将IDoc发往何处:
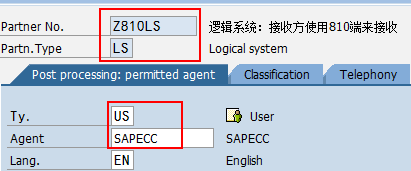
上图中合作伙伴编号填上一步创建的接收端逻辑系统,类型选择LS。Ty.选择是“用户”类型,代理人为本系统(发送端800)中的用户,如果在Idoc发送过程中出现什么问题,会向此用户发送邮件。当上面信息填好后,点击保存(保存之后才可以对Outbound parmtrs进行设置)。
然后,点击outbound下方的加号,创建一个outbound parameter。Message Type为YPO_MESS_TYPE,receiver port为TO810PORT,output mode选择Transfer idoc immed.,Basic Type填写YPOIDOC,保存即可:
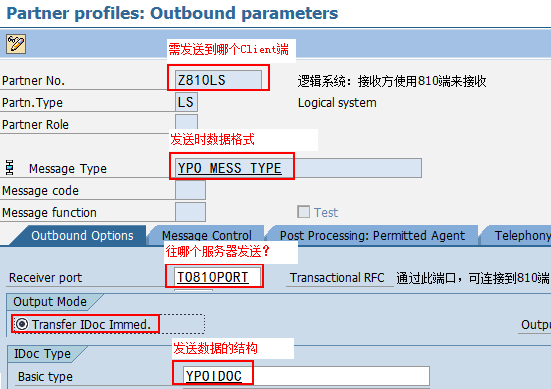
10、通过ABAP程序发送IDOC
程序的思路就是,把每个IDOC节点按字符串形式逐个添加,而字符串的添加次序自然也体现了IDOC节点间的逻辑关系。代码如下:
DATA: ls_pohead TYPE ypohead,"IDoc数据段:头
ls_poitem TYPE ypoitem,"IDoc数据段:Item
ls_edidc TYPE edidc,"IDoc的控制记录
lt_edidc TYPE TABLE OF edidc,
lt_edidd TYPE TABLE OF edidd WITH HEADER LINE."IDoc的数据记录
CLEAR ls_edidc.
*系统根据下面4行即可与WE20(合作和伴配置文件)设置关联起来
ls_edidc-mestyp = 'YPO_MESS_TYPE'. "Message Type
ls_edidc-idoctp = 'YPOIDOC'. "IDOC Type
ls_edidc-rcvprn = 'Z810LS'. "partner Number of Recipient接收方合作伙伴
ls_edidc-rcvprt = 'LS'. "partner Type of Receiver接收方类型为逻辑系统
*添加IDOC节点
CLEAR lt_edidd.
lt_edidd-segnam = 'YPOHEAD'."头节点
lt_edidd-dtint2 = 0.
CLEAR ls_pohead.
ls_pohead-ebeln = '4001122334'."采购单号
ls_pohead-bukrs = '1000'."公司代码
ls_pohead-bedat = '20090630'."日期
lt_edidd-sdata = ls_pohead. "节点内容:ls_pohead结构中的数据最后被拼接成字符串再赋值给lt_edidd-sdata,最大长度不能超过1000
APPEND lt_edidd.
CLEAR lt_edidd.
lt_edidd-segnam = 'YPOITEM'."Item节点
lt_edidd-dtint2 = 0.
CLEAR ls_poitem.
ls_poitem-ebeln = '4001122334'."采购单号
ls_poitem-ebelp = '0001'."Item行号
ls_poitem-matnr = '000000000000004527'."物料号
ls_poitem-menge = '3'."数量
ls_poitem-meins = 'ST'."单位
lt_edidd-sdata = ls_poitem.
APPEND lt_edidd.
CLEAR lt_edidd.
lt_edidd-segnam = 'YPOITEM'."Item节点
lt_edidd-dtint2 = 0.
CLEAR ls_poitem.
ls_poitem-ebeln = '4001122334'."采购单号
ls_poitem-ebelp = '0002'."Item行号
ls_poitem-matnr = '000000000000009289'."物料号
ls_poitem-menge = '5'."数量
ls_poitem-meins = 'M'."单位
lt_edidd-sdata = ls_poitem.
APPEND lt_edidd.
CALL FUNCTION 'MASTER_IDOC_DISTRIBUTE'"发送IDoc
EXPORTING
master_idoc_control = ls_edidc "IDoc控制记录
TABLES
communication_idoc_control = lt_edidc "接收:用来接收IDoc发送情况
master_idoc_data = lt_edidd "IDoc数据记录
EXCEPTIONS"
error_in_idoc_control = 1
error_writing_idoc_status = 2
error_in_idoc_data = 3
sending_logical_system_unknown = 4
OTHERS = 5.
IF sy-subrc <> 0.
MESSAGE ID sy-msgid TYPE sy-msgty NUMBER sy-msgno
WITH sy-msgv1 sy-msgv2 sy-msgv3 sy-msgv4.
ELSE.
COMMIT WORK.
WRITE: 'Idoc sent:'.
LOOP AT lt_edidc INTO ls_edidc.
NEW-LINE.
WRITE: 'Idoc number is', ls_edidc-docnum,
'; receiver partner is', ls_edidc-rcvprn,
'; sender partner',ls_edidc-sndprn.
ENDLOOP.
ENDIF.


选中消息,并点击“处理”按钮后,该消息就会发往目的客户端810,状态从准备发送到成功发送:

发送的数据可以选择数据记录节点来查看:
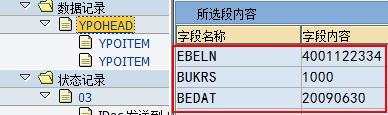
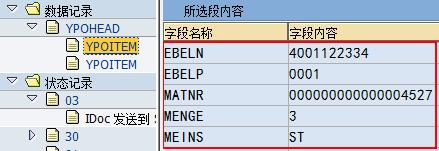
以上都是在发送端800进行的,下面登录到接收端810去看看IDoc接收情况:
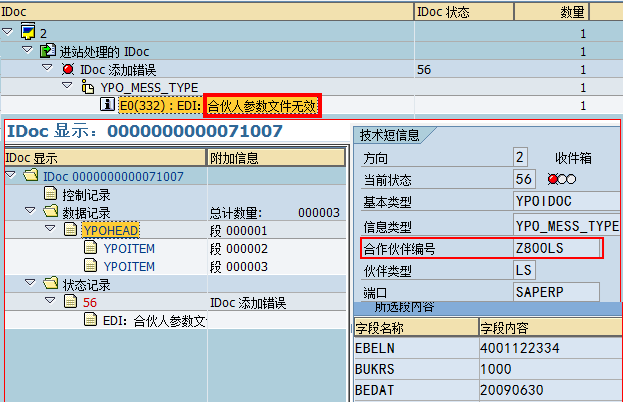
由于在接收端810未配置到发送端800的合作伙伴配置文件,所以出错。下面章节在接收端810中进行发送端800的相关配置
18.4.3.2.接收端810(Inbound)配置
由于该实例是在同一服务器的同一实例中进行的,又由于Segment、IDoc Type、Message Type这些都是跨Client的,所以上面1、2、3、4步就不需要在810端再次配置了,这些是共享的(但如果不是在同一服务器上,则需要像上面那样进行配置)
1、创建发送端RFC Destination(SM59)
创建到发送端810的物理连接


2、创建发送端的端口(WE21)
基于上面创建的RFC Destionation,创建端口Port,类型选TRANSACTIONAL RFC,名为FRM800PORT,RFC destination则填写上面创建的RFC远程目标ZFROM800:
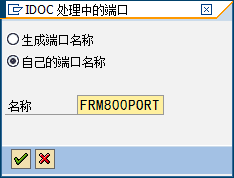
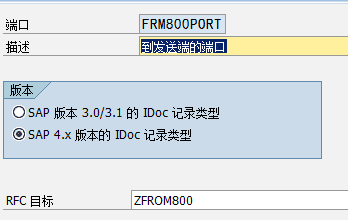
3、将接收端Logical System分配到Client 810(SALE)
如果是在不同的服务器中,则接收端需要像在发送端那样:发送端逻辑系统Z800LS与接收端逻辑系统Z810LS都需要被创建,并且还需要将接收端逻辑系统Z810LS分配到Client 810,并且还需要以发送端逻辑系统Z800LS为基础创建发送端合作伙伴配置文件
由于是在同一服务器的同一实例中,所以在发送端中创建的发送端逻辑系统Z800LS与接收端逻辑系统Z810LS在此端是通用共享,这里不需要再次创建(outbound中已经创建了这两个逻辑系统了),但(outbound章节中并未分配到具体的Client)Z810LS逻辑系统没有分配到相应的Client,这一步操作需要在接收端完成,所以需要在此进行分配:
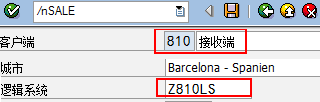
4、创建入站处理函数
创建一个function:Y_IDOC_PO_PROCESS.
当IDOC设置完毕之后,SAP可以自动调用该Funtion Module处理IDOC,所以这个函数的参数接口是有规范的,可以从IDOC_INPUT_BBP_IV这些标准函数拷贝参数接口部分:
"ypohead\ypoitem实为上面定义的IDoc类型
DATA: ls_chead TYPE ypohead,
ls_citem TYPE ypoitem.
CLEAR idoc_contrl.
READ TABLE idoc_contrl INDEX 1.
IF idoc_contrl-mestyp <> 'YPO_MESS_TYPE'.
RAISE wrong_function_called.
ENDIF.
LOOP AT idoc_contrl.
LOOP AT idoc_data WHERE docnum = idoc_contrl-docnum.
CASE idoc_data-segnam.
WHEN 'YPOHEAD'.
"直接将字符赋值给结构,赋值过程中会按照结构中的字段长度来划分各字段
ls_chead = idoc_data-sdata.
WRITE: / 'Head',ls_chead.
WHEN 'YPOITEM'.
ls_citem = idoc_data-sdata.
WRITE: / 'Item',ls_citem.
WHEN OTHERS.
ENDCASE.
ENDLOOP.
"根据数据处理情况设置当前IDoc处理的状态
IF 1 = 0.
CLEAR idoc_status.
idoc_status-docnum = idoc_contrl-docnum."当前正处理的IDoc
idoc_status-status = '53'. "IDOC处理成功
APPEND idoc_status.
ELSE.
CLEAR idoc_status.
idoc_status-docnum = idoc_contrl-docnum.
idoc_status-status = '51'. "IDOC不成功
idoc_status-msgty = 'E'. "错误信息
idoc_status-msgid = 'YMSG'.
idoc_status-msgno = '001'.
APPEND idoc_status.
ENDIF.
ENDLOOP.
ENDFUNCTION.
5、注册入站处理函数(BD51)
填入函数名Y_IDOC_PO_PROCESS,Input Type=1

6、将入站函数与IDOC Type/Message Type关联(WE57)
Function Module输入Y_IDOC_PO_PROCESS,其下的Type填写F;IDOC Type下的Basic Type填写YPOIDOC;Message Type填写YPO_MESS_TYPE;Direction填写2(Inbound)

7、创建入站处理代码Inbound Process Code(WE42)
Process Code输入YPC_PO,在Option ALE下选择Processing with ALE service,在Processing Type下选择function module,保存后,在随后的窗口中,输入Inbound Module为Y_IDOC_PO_PROCESS


8、创建发送端合作和伴配置文件Partner profile(WE20)
由于在发送端800中已创建了发送端逻辑系统Z800LS ,所以在此端不需要在创建(发送端逻辑系统Z800LS),只是需要以此为基础创建和伴配置文件,保存后,点击加号增加进站参数:


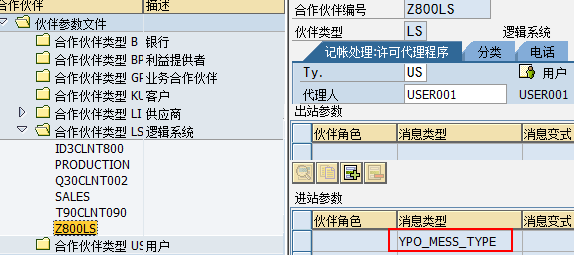
9、测试 BD87
在接收端810使用BD87,登录进去后,会看到发送端发送过来的IDoc,但由于先前还没有配置发送伙伴配置文件,所以失败了:
现在在入站处理理函数中设置断点:
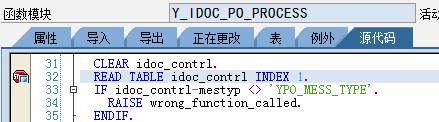
再执行BD87事务,继续处理出错的消息,最后发现处理成功:


调试程序时,发现数据也传递过来了:

19.数据共享与传递

19.1.程序调用、会话、SAP/ABAP内存 关系
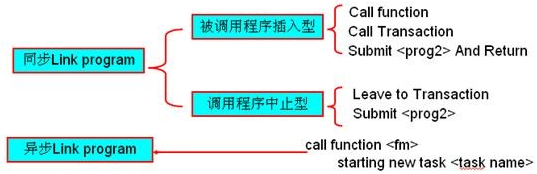
“被调用程序插入型”是指:主调用程序(calling program)并不结束,当遇到Link 语句时,会去执行被调用程序(called program),当被调用程序结束后,调用程序回到调用处继续执行;
“调用程序中止型”是指:调用程序(calling program)当遇到Link 语句时会立即中止,然后去执行被调用程序(called program),即使被调用程序执行完毕后,也不会返回到主调程序的调用处继续执行;
SUBMIT<program> AND RETURN:中断(不终止)当前运行的程序,启动新的被调用程序<program>,当<program>运行完后,控制权又返回到被中断的调用程序,继续执行
CALL TRANSACTION <TCode>:可以插入一个具有事务代码的ABAP程序,中断当前运行的程序,待被调程序执行完后,再继续执行主调程序
SUBMIT <program>:结束当前运行的程序,启动新的被调用程序<program>
LEAVE TO TRANSACTION <TCode>:结束当前运行的程序,并启动由事务码<TCode>指定的ABAP程序。在程序中使用该语句的效果等同于用户直接在命令行输入“/n<TCode>”并执行的效果。
使用LEAVE TO TRANSACTION <TCode>调用另一程序时,可以在主调程序中使用“SET PARAMETER ID”将被传递的数据存储到SAP memory中,在被调用的Tcode中可以使用“GET PARAMETER ID”来获取,另外,也可以为被调用Tcode屏幕参数的data element设置parameter ID,这样会自动的获取与存储该屏幕参数(只设置Data Element中的Parameter ID是不起作用的,请看后面)。
只有LEAVE TO TRANSACTION <TCode> 不能使用ABAP MEMORY共享数据(其它调用方式均可以),而应该使用SAP Memory;注,SUBMIT <program>调用后虽然不会返回到主调程序,但也是可以通过ABAP memory来传递数据
异步的Link Program:当遇到这种Function时,将会重新打开一个external session(外部会话,窗口会话),它并行地、独立于当前的external session.
三种会话:![]()
一个External session(外部会话,一个窗口就是一个外部会话)对应着一个ABAP MEMORY内存,所以同一个Window中的所有Internal session(内部会话,一个程序的调用就是一个内部会话)共用着同一个ABAP MEMORY,同一user logon session(用户终端会话,登录就会产生)中不同的window共用一个SAP MEMORY内存:
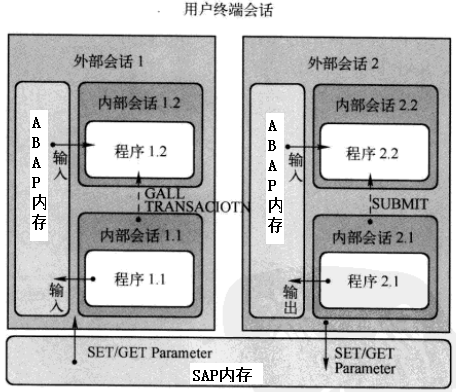
同一窗口中的不同程序共享同一个ABAP memory,同一用户的不同窗口之间共享同一个SAP memory
当系统用户登录后,就会产生一个与该用户对应的“用户终端会话”(User Terminal Session),用户可以开辟很多外部会话(即窗口,最多可打开6个窗口),在每个窗口会话(外部会话)中又可以先后执行多个ABAP程序(调用一个程序就会产生一个内部会话)
每一个外部会话都有一个叫ABAP Memory的内存区域,在该会话内部可以通过“EXPORT TO MEMORY”和“IMPORT FROM MEMORY”在该会话中的多个运行程序之间(即多个内部会话之间)进行数据共享,并可使用“FREE MEMORY ID”语句将共享数据从ABAP Memory中清除
SAP Memory是所有的会话(指同一用户登录会话中)都可以访问的内存区域,因此可以通过“SET PARAMETER”与“GET PARAMETER”把数据保存在SAP内存中进行数据共享
所以,在同一个external session的Link program我们使用ABAP Memory进行传递数据;而在不同的external session间的Link program我们使用SAP Memory进行数据传递。
19.2.ABAP Memory数据共享
19.2.1.EXPORT
EXPORT {p1 = dobj1 p2 = dobj2 ...} | {p1 FROM dobj1 p2 FROM dobj2 ...} | (ptab) TO
| { MEMORY ID id }
| { DATABASE dbtab(ar) [FROM wa] [CLIENT cl] ID id }
| { SHARED MEMORY dbtab(ar) [FROM wa] [CLIENT cl] ID id }
| { SHARED BUFFER dbtab(ar) [FROM wa] [CLIENT cl] ID id }
1.{p1 = dobj1 p2 = dobj2 ...}与 {p1 FROM dobj1 p2 FROM dobj2 ...}的意义一样,只是写法不一样,dobj1、dobj2…变量将会以p1、p2…名称存储到内存或数据库中。p1、p2…名称随便取,如果p1、p2…与将要存储的变量名相同时,只需写变量名即可,即等号与 FROM 后面可以省略。p1、p2…这些名称必须与IMPORT语句中相一致,否则读取不出
2.(ptab):为动态指定需要存储的变量,ptab内表结构要求是这样的:只需要两列,列名任意,但类型需要是字符型;第一列存储如上面的p1、p2…名称,第二列为上面的dobj1、dobj2…变量,如果变量与名称相同,则也可以像上面一样,省略第二列的值。两列的值都必需要大写,实例如下:
TYPES:BEGIN OF tab_type,
para TYPE string,"列的名称任意,类型为字符型
dobj TYPE string,
END OF tab_type.
DATA:text1 TYPE string VALUE `TXT1`,
text2 TYPE string VALUE `TXT2`,
line TYPE tab_type,
itab TYPE STANDARD TABLE OF tab_type.
line-para = 'P1'."值都需要大写
line-dobj = 'TEXT1'."值都需要大写
APPEND line TO itab.
line-para = 'P2'.
line-dobj = 'TEXT2'.
APPEND line TO itab.
EXPORT (itab) TO MEMORY ID 'TEXTS'.
IMPORT p1 = text2 p2 = text1 FROM MEMORY ID 'TEXTS'.
WRITE: / text1,text2."TXT2 TXT1
CLEAR: text1,text2.
IMPORT (itab) FROM MEMORY ID 'TEXTS'.
WRITE: / text1,text2."TXT1 TXT2
3.MEMORY ID:将变量存储到ABAP MEMORY内存(同一用户的同一窗口Session)
4.DATABASE:将变量存储到数据库中;dbtab为簇数据库表的名称(如系统提供的标准表INDX);ar的值为区域ID,它将数据库表的行分成若干区域,它必须被直接指定,且值是两位字符,被存储到簇数据库表中的RELID字段中;id 的值会存储到簇数据表中的RELID字段的下一用户自定义字段中:
TYPES:BEGIN OF tab_type,
col1 TYPE i,
col2 TYPE i,
END OF tab_type.
DATA:wa_indx TYPE demo_indx_table,
wa_itab TYPE tab_type,
itab TYPE STANDARD TABLE OF tab_type.
WHILE sy-index < 100.
wa_itab-col1 = sy-index.
wa_itab-col2 = sy-index ** 2.
APPEND wa_itab TO itab.
ENDWHILE.
wa_indx-timestamp = sy-datum && sy-uzeit.
wa_indx-userid = sy-uname.
EXPORT tab = itab TO DATABASE demo_indx_table(sq) FROM wa_indx ID 'TABLE'.

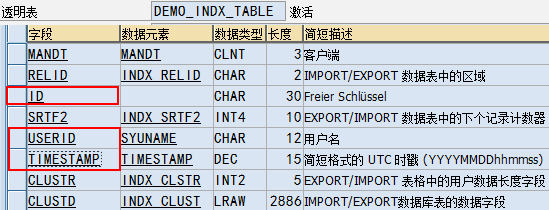
TABLES: indx.
DATA: BEGIN OF i_tab OCCURS 100,
col1 TYPE i,
col2 TYPE i,
END OF i_tab.
DO 3000 TIMES.
i_tab-col1 = sy-index.
i_tab-col2 = sy-index ** 2.
APPEND i_tab.
ENDDO.
indx-aedat = sy-datum.
indx-usera = sy-uname.
indx-pgmid = sy-repid.
"省略了FROM选项,因为已经使用TABLES indx语句定义了名为indx的结构变量了
"Export时会自动将表工作区indx变量中的用户字段存储到簇数据库表中
EXPORT i_tab TO DATABASE indx(HK) ID 'Key'.
WRITE: ' SRTF2',AT 20 'AEDAT',AT 35 'USERA',AT 50 'PGMID'.
ULINE.
"注:下面完全可以使用 IMPORT FROM DATABASE TO wa 语句来读取用户区字段
SELECT * FROM indx WHERE relid = 'HK'AND srtfd = 'Key'.
WRITE: / indx-srtf2 UNDER 'SRTF2',
indx-aedat UNDER 'AEDAT',
indx-usera UNDER 'USERA',
indx-pgmid UNDER 'PGMID'.
ENDSELECT.
SRTF2 AEDAT USERA PGMID
0 2011.10.12 ZHENGJUN YJZJ_TEST2
1 2011.10.12 ZHENGJUN YJZJ_TEST2
2 2011.10.12 ZHENGJUN YJZJ_TEST2
3 2011.10.12 ZHENGJUN YJZJ_TEST2
4 2011.10.12 ZHENGJUN YJZJ_TEST2
5.SHARED MEMORY/BUFFER :将数据存储到SAP应用服务器上的内存中,可共同一服务上的所有程序访问。两种的作用是一样的,最大不同是在数据达到最大内存限制时的处理方式不同:最大内存限制值分别是通过rsdb/esm/buffersize_kb (SHARED MEMORY)、rsdb/obj/buffersize (SHARED BUFFER)来设置的,当内存占用快满时,SHARED MEMORY必须通过DELETE FROM SHARED MEMORY来手动清理,而SHARED BUFFER会自动删除很少被使用到的数据(当然也可以通过DELETE FROM SHARED BUFFER手动及时的删除不用的数据)
6.FROM wa:wa工作区类型可以参照簇数据库dbtab类型,也可定义成只含有用户数据字段的结构,它是用来设置簇数据库表中SRTF2 与 CLUSTR两个字段之间的用户数据字段(参见簇数据表图中的编号为5的用户数据)的值,然后在Export时将相应的字段存储到SRTF2字段与CLUSTR字段间的相应字段中去。如果使用“TABLES dbtab.”定义语句,可以省略“[FROM wa]”,也会默认将其存储到数据库表中,但如果没有“TABLES dbtab.”这样的定义语句,也没有“[FROM wa]”选项时,将不会有数据存储到簇数据库表中的用户字段中去
7.CLIENT cl:默认为当前客户端,存储到簇数据库表中的MANDT字段中
19.2.2.IMPORT
IMPORT {p1 = dobj1 p2 = dobj2 ...} | {p1 TO dobj1 p2 TO dobj2 ...} | (ptab) FROM
| { MEMORY ID id }
| { DATABASE dbtab(ar) [TO wa] [CLIENT cl] ID id }
| { SHARED MEMORY dbtab(ar) [TO wa] [CLIENT cl] ID id }
| { SHARED BUFFER dbtab(ar) [TO wa] [CLIENT cl] ID id }
从簇数据表中读取数据,各项参数与EXPORT是一样的,请参考EXPORT各项解释
TYPES:BEGIN OF tab,
col1 TYPE i,
col2 TYPE i,
END OF tab.
DATA:wa_indx TYPE demo_indx_table,
wa_itab TYPE tab,
itab TYPE STANDARD TABLE OF tab.
IMPORT tab = itab FROM DATABASE demo_indx_table(sq) TO wa_indx ID 'TABLE'.
WRITE: wa_indx-timestamp, wa_indx-userid.
ULINE.
LOOP AT itab INTO wa_itab.
WRITE: / wa_itab-col1, wa_itab-col2.
ENDLOOP.
TABLES indx.
DATA: BEGIN OF jtab OCCURS 100,
col1 TYPE i,
col2 TYPE i,
END OF jtab.
"注意:i_tab的名称不能是其他的,必须与EXPORT语句中的分类存储标签名一样。如果i_tab本身又是一个jtab类型的内表,则TO后面的jtab可以省略
IMPORT i_tab TO jtab FROM DATABASE indx(hk) ID 'Key'.
"注:在该程序中并没有明显的为indx工作区设置值,但由于使用了TABLES indx.语句定义了与indx簇数据库表同名的结构变量,所以上面IMPORT会默认加上使用TO indx 选项
WRITE: / 'AEDAT:', indx-aedat,
/ 'USERA:', indx-usera,
/ 'PGMID:', indx-pgmid.
SKIP.
WRITE 'JTAB:'.
LOOP AT jtab FROM 1 TO 5.
WRITE: / jtab-col1, jtab-col2.
ENDLOOP.
AEDAT: 2011.10.12
USERA: ZHENGJUN
PGMID: YJZJ_TEST2
JTAB:
1 1
2 4
3 9
4 16
5 25
19.2.3.DELETE
DELETE FROM { {MEMORY ID id}
| {DATABASE dbtab(ar) [CLIENT cl] ID id}
| {SHARED MEMORY dbtab(ar) [CLIENT cl] ID id}
| {SHARED BUFFER dbtab(ar) [CLIENT cl] ID id} }.
用来清理EXPORT语句的存储的数据。如果是针对MEMORY ID,则还可以使用 FREE MEMORY IDid与DELETE FROM MEMORY ID id 作用一样
DATA: id TYPE c LENGTH 4 VALUE 'TEXT',
text1 TYPE string VALUE 'Tina',
text2 TYPE string VALUE 'Mike'.
EXPORT p1 = text1 p2 = text2 TO SHARED BUFFER demo_indx_table(xy) ID id.
IMPORT p1 = text2 p2 = text1 FROM SHARED BUFFER demo_indx_table(xy) ID id.
DELETE FROM SHARED BUFFER demo_indx_table(xy) ID id.
"此语句会执行后,sy-subrc返回4
IMPORT p1 = text2 p2 = text1 FROM SHARED BUFFER demo_indx_table(xy) ID id.
19.3. SAP MEMORY数据共享
19.3.1.PARAMETERS/SELECT-OPTIONS选项MEMORY ID
Data Element中的Parameter ID的作用只是在屏幕设计时,起到一个辅助填充的作用,例如:当给某个屏幕字段命令时,如果这个字段的名称为“表名(或结构)- 字段名” 形式时,回车时系统会提示:
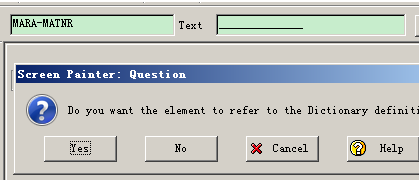
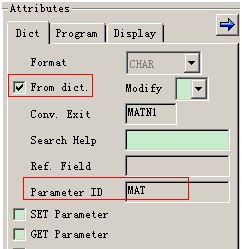
当点击Yes后,该字段的Parameter ID属性会自动的设置为 MARA-MATNR字段所对应Data Element所设置的Parameter ID MAT,另外,From dict.也会自动被钩上,但时,SET Parameter与GET Parameter 没有自动钩上,如果需要通过SAP Memory传递值,则还需要将这两个手动钩上(如上图)
Data Element中的Parameter ID对选择屏幕是没有任何作用的,如下面的语句不能用来在SAP Memory中传递值:
PARAMETERS: m TYPE mara-matnr.
PARAMETERS: m TYPE mara-matnr MEMORY ID mat.
所以选择屏幕中的参数选项 MEMORY ID的作用就等同于对话屏幕中的SET/GET Parameter,它们是作用是相同的,只不过一个用于选择屏幕中,一个用于屏幕计中。
REPORT ztest_sap_memory_1.
*PARAMETERS: p_spa TYPE zdele_1 MEMORY ID zpara1.或者是下面这种写法,根本不用参照zdele_1这个Data Element,因为Data Element中的Parameter ID对选择屏幕参数没有任何意义,所以只需要通过MEMORY ID选项动态的创建Parameter ID即可,不需要先选通过SE80或SM30来事先创建好
PARAMETERS: p_spa(10) MEMORY ID zpara1.
START-OF-SELECTION.
LEAVE TO TRANSACTION 'zsap_mem_2'.
zsap_mem_2事务码对应的报表程序为:
DATA: mem(10).
GET PARAMETER ID 'ZPARA1' FIELD mem.
19.3.2.GET/SET PARAMETER ID
除了通过上面MEMORY ID 在同一用户下不同窗口之间自动传递选择屏幕参数外,也可以通过以下语句来手动传递屏幕参数以及非屏幕参数:
REPORT ztest_sap_memory_3.
PARAMETERS: p_spa TYPE zdele_1.
START-OF-SELECTION.
SET PARAMETER ID ’ZPARA1’ FIELD p_spa.
LEAVE TO TRANSACTION ’ztest_sap_memory_4’.
使用SE91为下面ztest_sap_memory_4程序创建了Tcode为:ztest_sap_memory_4
REPORT ztest_sap_memory_4.
PARAMETERS: p_spa TYPE zdele_1.
AT SELECTION-SCREEN OUTPUT."
GET PARAMETER ID ’ZPARA1’ FIELD p_spa.
GET/SET PARAMETER ID还可以与对话屏幕Parameter ID一起使用,如通过MM02输入物料后,可以在程序中直接读取:
DATA: material TYPE mara-matnr.
GET PARAMETER ID 'MAT' FIELD material.
WRITE:/ material.
19.4.DATABASE
SHARED BUFFER并不访问(存储)数据库,而要存放在数据库就应该用DATABASE
EXPORT DATABASE与普通数据库操作的不同之处是,它适合大数据量的操作,系统自动将其拆分成多条记录并存储到数据库中,比如图片或文档(甚至是程序中的某个内表,请参考后面的实例),而用IMPORT DATABASE的过程则相反,系统将把这些条相关记录又自动组合起来成为一个整体。
如果要自定义INDX这样的表,需要按以下表结构顺序来定义:
该数据库表结构要求:
①、可以有也可以无 MANDT字段
②、除开第一个字段MANDT(如果有的情况下),下一个字段必须是RELID,类型为CHAR 2,它是用来存储area ID,系统会根据用户在使用EXPORT语句保存数据时指定的area ID来填充它。
③、紧接下一个字段是一个任意长度(根据自己的需要定)的CHAR字段,名字也可以是随便取的,该字段用为主键的一部分来使用,该字段的值也是在使用EXPORT语句保存数据时使用ID选项指定的值。
④、下一个字段的名字必须是SRTF2,类型为INT4,用来存储数据行号(大数据对象——如图片、文件、程序中的内表对象等,要分成多行来存储)。由于某个数据可能很大,需要多行来存储,理念是可能达到2**31行,该字段会自动的由系统填充。
⑤、在SRTF2字段的后面,你可以包括任意数量及类型的数据字段,这些字段是用来管理大对象的相应信息(如文件名、文件类型、创建者等),当你在保存数据时系统不会自动的填充这些字段,所以在保存这些字段时,需要通过一个结构传递需要存储的值(即EXPORT语句中的From选项所带的结构)。
⑥、倒数第二个字段的名必须为CLUSTR,类型为INT2,它存储了最后一个字段CLUSTD所存储数据的长度(字节数),在使用EXPORT语句保存数据时系统会自动填充
⑦、最后一个字段的名必须是CLUSTD,并且数据类型为LRAW,其长度表示能最大存储多少个字节的内容,如果大数据对象很大(一行存储不下时),会分成多行来存储,行号就存储在前面的SRTF2字段中。
19.4.1.将文件存入表中

注意:上面这个表中的SRTFD实际上没用上,因为Export时,ID选项的值实质上存储到了它前面的ZZKEY中了,所以可以去掉这个字段(一般会留名为SRTFD字段而去掉ZZKEY字段)。
PARAMETERS: p_file TYPE string OBLIGATORY.
AT SELECTION-SCREEN ON VALUE-REQUEST FOR p_file.
CALL FUNCTION 'WS_FILENAME_GET'
EXPORTING
def_filename = '*.*'
def_path = 'c:\'
mask = ',*'
mode = 'O'
title = 'File select'
IMPORTING
filename = p_file.
START-OF-SELECTION.
DATA: il_data LIKE solix OCCURS 0 WITH HEADER LINE,
l_len TYPE i.
**Upload file
REFRESH: il_data.
CLEAR l_len.
CALL FUNCTION 'GUI_UPLOAD'
EXPORTING
filename = p_file
filetype = 'BIN'
IMPORTING
filelength = l_len
TABLES
data_tab = il_data."ABAP没有二进制类型,X类型代替
EXPORT il_data TO DATABASE indx(YY) ID 'ZZZ' .

上面是直接将读取到的文件的二进制数据内表存储到簇数据库表中,我也也可通过SCMS_BINARY_TO_XSTRING函数将读取的二进制数据内表拼接成只有一行的二进制串,然后再存储这个被转换后的二进制串也可:
PARAMETERS: p_file TYPE string OBLIGATORY,
p_id LIKE ybc_file-zzkey OBLIGATORY,
p_ftype LIKE ybc_file-mimetype OBLIGATORY,
p_fname LIKE ybc_file-filename OBLIGATORY.
AT SELECTION-SCREEN ON VALUE-REQUEST FOR p_file.
CALL FUNCTION 'WS_FILENAME_GET'
EXPORTING
def_filename = '*.*'
def_path = 'c:\'
mask = ',*'
mode = 'O'
title = 'File select'
IMPORTING
filename = p_file.
START-OF-SELECTION.
DATA: il_data LIKE solix OCCURS 0 WITH HEADER LINE,
l_len TYPE i.
**Upload file
REFRESH: il_data.
CLEAR l_len.
CALL FUNCTION 'GUI_UPLOAD'
EXPORTING
filename = p_file
filetype = 'BIN'
IMPORTING
filelength = l_len
TABLES
data_tab = il_data."X类型内表
CHECK il_data[] IS NOT INITIAL.
**Convert data
DATA: l_xstr TYPE xstring.
CLEAR l_xstr.
"将内表以X类型拼接成XString字符串
CALL FUNCTION 'SCMS_BINARY_TO_XSTRING'
EXPORTING
input_length = l_len
IMPORTING
buffer = l_xstr
TABLES
binary_tab = il_data.
**Save data
"wl_file用于填充ybc_file表中非规定字段
DATA: wl_file LIKE ybc_file.
wl_file-uname = sy-uname.
wl_file-aedtm = sy-datum.
wl_file-pgmid = sy-cprog.
wl_file-mimetype = p_ftype.
wl_file-filename = p_fname.
DATA: l_answer TYPE c.
EXPORT l_xstr = l_xstr TO DATABASE ybc_file(bc) FROM wl_file ID p_id .
19.4.2.从表中读取文件
DATA: il_data LIKE solix OCCURS 0.
IMPORT il_data FROM DATABASE indx(YY) ID 'ZZZ'.
CALL METHOD cl_gui_frontend_services=>gui_download
EXPORTING
" bin_filesize = l_bytes
filename = 'c:\1.jpg'
filetype = 'BIN'
CHANGING
data_tab = il_data.
与存储文件一样,如果存储的是拼接好的二进制串,则要使用SCMS_XSTRING_TO_BINARY函数来还原后再下载:
PARAMETERS: p_key LIKE ybc_file-zzkey.
DATA: l_xstr TYPE xstring.
IMPORT l_xstr = l_xstr FROM DATABASE ybc_file(bc) ID p_key.
DATA: l_xstring TYPE xstring,
l_xcnt TYPE i,
l_bytes TYPE i.
TYPES: hex512(512) TYPE x.
DATA: tab_xstring TYPE TABLE OF hex512 WITH HEADER LINE.
"将Xstring以X类型视图存储到内表中
CALL FUNCTION 'SCMS_XSTRING_TO_BINARY'
EXPORTING buffer = l_xstr
TABLES binary_tab = tab_xstring.
DATA: l_ftype LIKE yhr_attach-mimetype,
l_fname LIKE yhr_attach-filename.
"二进内容需使用IMPORT语句中读取,但其他字段除了可使用 IMPORT语句的TO选项来直接读取外,还可以通过SQL直接查询
SELECT SINGLE mimetype filename INTO (l_ftype,l_fname) FROM ybc_file
WHERE relid = 'BC' AND zzkey = p_key.
DATA: l_file_name TYPE string.
CONCATENATE 'C:\' l_fname '.' l_ftype INTO l_file_name.
CALL METHOD cl_gui_frontend_services=>gui_download
EXPORTING
bin_filesize = l_bytes
filename = l_file_name
filetype = 'BIN'
CHANGING
data_tab = tab_xstring[].
19.5.JOB间数据传递
有两种方式:
l SHARED MEMORY/SHARED BUFFER
l 通过Cluster Databases
20.拾遗
20.1.Function调用
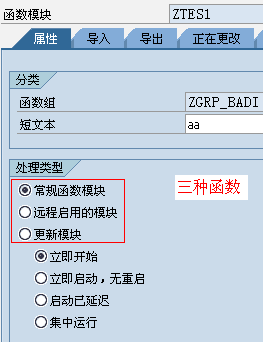
20.1.1.更新FM:LUW
CALL FUNCTION update_function IN UPDATE TASK,直到Commit Work 才运行
主要用于本地更新(非远程RFC调用,如果是远程调用,则采用事务性RFC调用方式:IN BACKGROUND TASK)
20.1.2.RFC函数:远程调用
20.1.2.1.同步
CALL FUNCTION func [DESTINATION dest] [ˌdestiˈneiʃən]
(在DESTINATION不省略的情况下,且dest取值又不为SPACE,则函数一定要是RFC函数才能采用此方式进行远程同步调用)
20.1.2.2. 异步
CALL FUNCTION rfm_name STARTING NEW TASK [DESTINATION dest]tasknamePERFORMING return_form ON END OF TASK
FORM return_form USING taskname.
...
RECEIVE RESULTS FROM FUNCTION rfm_name
...
ENDFORM.
等待多个异步调用的返回结果:WAIT UNTIL log_exp [UP TO sec SECONDS].
异步调用时不能有IMPORTING、CHANGE参数;函数一定要是RFC函数才能采用异步调用;只要有STARTING NEW TASK选项,即为异步调用;如果是异步调用同一目标端的RFC函数,则可以省略DESTINATION
20.1.2.2.1.事务性RFC调用
实质上事务RFC调用也属于异步调用
CALL FUNCTION func IN BACKGROUND TASK [DESTINATION dest],并不立即执行,直到主调程序中的COMMIT WORK语句(隐式提交不要,一定要使用COMMIT WORK显示提交)才一次性执行多个远程函数调用
(函数一定要为RFC函数,且要通过Commit Work语句显示提交后,才会去执行,否则不会执行;如果是同一目标端的RFC函数,则可以省略DESTINATION;不能返回参数,即不能使用RECEIVE语句来接收返回参数)
20.1.2.3.DESTINATION 取值
l 目标NONE:当前程序所在应用服务器作为目标系统,但调用过程还是RFC远程方式来调用,这与SPACE是不同的
l目标SPACE: DESTINATION选项将会被忽略,被调功能函数将作为普通函数在本机调用
l目标BACK:用于被远程调用的RFM程序内部的CALL FUNCTION语句中的目标指定,通过已建立的RFC连接反过来调用该函数的主调者系统中的其他功能模块(即主调程序—>远程系统中的RFM—>又回调主调程序所在系统中的其他函数)
20.2.函数、类
CL_GUI_FRONTEND_SERVICES:
| 客户端文件操作: FILE_OPEN_DIALOG FILE_SAVE_DIALOG FILE_COPY FILE_DELETE FILE_EXIST FILE_GET_SIZE | 客户端目录操作: DIRECTORY_BROWSE DIRECTORY_CREATE DIRECTORY_DELETE DIRECTORY_EXIST DIRECTORY_GET_CURRENT DIRECTORY_LIST_FILES DIRECTORY_SET_CURRENT GET_TEMP_DIRECTORY | 客户端文件上传下载: GUI_DOWNLOAD GUI_UPLOAD | 客户端文件分隔符: GET_FILE_SEPARATOR
登录的PagCode与语言: GET_SAPLOGON_ENCODING |
GUI_DOWNLOAD
GUI_UPLOAD
20.3.FTP
FTP_COMMAND
FTP_DISCONNECT
20.4.文件读写
DATA: file TYPE string VALUE `jzjflights.dat`,
wa TYPE spfli.
OPEN DATASET file FOR OUTPUT IN BINARY MODE.
SELECT *
FROM spfli
INTO wa.
TRANSFER wa TO file. "写
ENDSELECT.
CLOSE DATASET file.
DATA: file TYPE string VALUE `jzjflights.dat`,
wa TYPE spfli.
OPEN DATASET file FOR INPUT IN BINARY MODE.
DO.
"由于没有使用MAXIMUM LENGTH选项,所以每次读取的最大字节数由wa所占字节数决定
READ DATASET file INTO wa. "读
IF sy-subrc = 0.
WRITE: / wa-carrid,
wa-connid,
wa-countryfr,
wa-cityfrom,
wa-cityto,
wa-fltime,
wa-distance.
ELSE.
EXIT.
ENDIF.
ENDDO.
CLOSE DATASET file.
20.5.Email
DATA: send_request TYPE REF TO cl_bcs,
document TYPE REF TO cl_document_bcs,
document = cl_document_bcs=>create_document( 创建邮件内容
CALL METHOD document->add_attachment 添加附件
send_request = cl_bcs=>create_persistent( ). 创建发送请求 [pəˈsistənt] 持续的; 持久的
CALL METHOD send_request->set_sender 设置发送者
CALL METHOD send_request->add_recipient 设置接收者 [riˈsipiənt]
CALL METHOD send_request->set_document( document ).
CALL METHOD send_request->send( 发送
20.6.XML
if_ixml
if_ixml_document
if_ixml_node
if_ixml_element
if_ixml_istream
if_ixml_ostream
document、element、ATTRIBUTE、COMMENT、TEXT都属于 Node
20.6.1.生成

<?xml version="1.0"?>
<flow BAPI="ZBAPI_MM_RK_AFTER_APP" DES="广深公司-采购订单" KEY="gsgs-cgdd"><customform><fd n="flight"><V>110000</V></fd><fd n="flight"><V>090000</V></fd></customform></flow>
TYPE-POOLS: ixml,abap.
TYPES: BEGIN OF xml_line,
data(512) TYPE x,"这里的长度设置不会影响输出结果,设置成1都可以
END OF xml_line.
DATA: l_ixml TYPE REF TO if_ixml,
l_streamfactory TYPE REF TO if_ixml_stream_factory,
l_ostream TYPE REF TO if_ixml_ostream,
l_renderer TYPE REF TO if_ixml_renderer,
l_document TYPE REF TO if_ixml_document.
DATA: l_element_flights TYPE REF TO if_ixml_element,
l_element_airline TYPE REF TO if_ixml_element,
l_element_flight TYPE REF TO if_ixml_element,
l_element_dummy TYPE REF TO if_ixml_element,
l_value TYPE string.
DATA: l_xml_table TYPE TABLE OF xml_line WITH HEADER LINE,
l_xml_size TYPE i,
l_rc TYPE i.
DATA: lt_spfli TYPE TABLE OF spfli.
DATA: l_spfli TYPE spfli.
START-OF-SELECTION.
SELECT * FROM spfli INTO TABLE lt_spfli UP TO 2 ROWS.
SORT lt_spfli BY carrid.
* 生成XML数据
LOOP AT lt_spfli INTO l_spfli.
AT FIRST.
* Creating a ixml factory
l_ixml = cl_ixml=>create( ).
* Creating the dom object model
l_document = l_ixml->create_document( ).
* Fill root node with value flow
l_element_flights = l_document->create_simple_element(
name = 'flow'
parent = l_document ).
l_rc = l_element_flights->set_attribute( name = 'KEY' value = 'gsgs-cgdd' ).
l_rc = l_element_flights->set_attribute( name = 'DES' value = '广深公司-采购订单').
l_rc = l_element_flights->set_attribute( name = 'BAPI' value ='ZBAPI_MM_RK_AFTER_APP' ).
l_element_airline = l_document->create_simple_element(
name = 'customform'
parent = l_element_flights ). "parent为父节点
ENDAT.
AT NEW connid.
l_element_flight = l_document->create_simple_element(
name = 'fd'
parent = l_element_airline ).
"l_value = l_spfli-connid.
l_rc = l_element_flight->set_attribute( name = 'n' value = 'flight' ).
ENDAT.
l_value = l_spfli-deptime.
l_element_dummy = l_document->create_simple_element(
name = 'V'
value = l_value
parent = l_element_flight ).
ENDLOOP.
* Creating a stream factory
l_streamfactory = l_ixml->create_stream_factory( ).[stri:m] 流
* Connect internal XML table to stream factory
l_ostream = l_streamfactory->create_ostream_itable( table = l_xml_table[] ).
* Rendering the document
l_renderer = l_ixml->create_renderer( ostream = l_ostream [ˈrendə] ![]()
document = l_document )." l_document为根节点
l_rc = l_renderer->render( )."注:执行此句后, l_xml_table内表里才会有数据
l_xml_size = l_ostream->get_num_written_raw( )."取得XML数据大小
*************************************************************
**--将xml数据导出到本地
* call method cl_gui_frontend_services=>gui_download
* exporting
* bin_filesize = l_xml_size
* filename = 'd:\flights.xml'
* filetype = 'BIN'
* changing
* data_tab = l_xml_table[].
************************************************************
****************************************************
**--将XML数据导入到内表
* DATA xmldata TYPE xstring .
* DATA: result_xml TYPE STANDARD TABLE OF smum_xmltb .
* DATA: return TYPE STANDARD TABLE OF bapiret2 .
* DATA: wa_xml TYPE smum_xmltb.
* "如果需要上载XML可以用一下方法
* CALL FUNCTION 'GUI_UPLOAD'
* EXPORTING
* filename = 'd:\flights.xml'
* filetype = 'BIN'
* IMPORTING
* filelength = l_xml_size
* TABLES
* data_tab = l_xml_table.
* "将二进制内表转换(拼接)成一个二进制串
* CALL FUNCTION 'SCMS_BINARY_TO_XSTRING'
* EXPORTING
* input_length = l_xml_size
* IMPORTING
* buffer = xmldata
* TABLES
* binary_tab = l_xml_table.
* CALL FUNCTION 'SMUM_XML_PARSE'"解析
* EXPORTING
* xml_input = xmldata
* TABLES
* xml_table = result_xml
* return = return.
* LOOP AT result_xml INTO wa_xml .
* WRITE: / wa_xml-hier,wa_xml-type,wa_xml-cname,wa_xml-cvalue.
* ENDLOOP.
************************************************
**************************************************
**将XML转换成字符串
* DATA: w_string TYPE xstring.
* DATA ls_xml TYPE string.
* FIELD-SYMBOLS: <fs> TYPE string.
* CALL FUNCTION 'SDIXML_DOM_TO_XML'
* EXPORTING
* document = l_document
* IMPORTING
* xml_as_string = w_string
* size = l_xml_size
* TABLES
* xml_as_table = l_xml_table.
*
* DATA: convin TYPE REF TO cl_abap_conv_in_ce.
* "创建解码对象
* convin = cl_abap_conv_in_ce=>create( input = w_string ).
* DATA: str TYPE string.
* CALL METHOD convin->read
* IMPORTING
* data = ls_xml.
* WRITE: / ls_xml.
* 将一个二进制串分割存储到二进制内表中
* call function 'SCMS_XSTRING_TO_BINARY'
* exporting
* BUFFER = W_STRING
* importing
* OUTPUT_LENGTH = L_XML_SIZE
* tables
* BINARY_TAB = L_XML_TABLE.
"将二进制内表转换(拼接)成一个字符串
* CALL FUNCTION 'SCMS_BINARY_TO_STRING'
* EXPORTING
* input_length = l_xml_size
* IMPORTING
* text_buffer = ls_xml
* TABLES
* binary_tab = l_xml_table.
* WRITE: / ls_xml.
****************************************************************
20.6.2.解析

TYPE-POOLS: ixml.
DATA: ixml TYPE REF TO if_ixml,
document TYPE REF TO if_ixml_document,
streamfactory TYPE REF TO if_ixml_stream_factory,
istream TYPE REF TO if_ixml_istream,
parser TYPE REF TO if_ixml_parser,
node TYPE REF TO if_ixml_node,
string TYPE string,
count TYPE i,
index TYPE i,
totalsize TYPE i .
TYPES: BEGIN OF xml_line,
data(256) TYPE x,
END OF xml_line.
DATA: xml_table TYPE TABLE OF xml_line.
START-OF-SELECTION.
CALL FUNCTION 'GUI_UPLOAD'
EXPORTING
filename = 'd:\flights.xml'
filetype = 'BIN'
IMPORTING
filelength = totalsize
TABLES
data_tab = xml_table
EXCEPTIONS
OTHERS = 11.
IF sy-subrc <> 0.
EXIT.
ENDIF.
ixml = cl_ixml=>create( ).
document = ixml->create_document( ).
streamfactory = ixml->create_stream_factory( ).
istream = streamfactory->create_istream_itable( table = xml_table
size = totalsize ).
parser = ixml->create_parser( stream_factory = streamfactory
istream = istream
document = document ).
IF parser->parse( ) NE 0.
IF parser->num_errors( ) NE 0.
count = parser->num_errors( ).
WRITE: count, ' parse errors have occured:'.
DATA: pparseerror TYPE REF TO if_ixml_parse_error,
i TYPE i.
index = 0.
WHILE index < count.
pparseerror = parser->get_error( index = index ).
i = pparseerror->get_line( ).
WRITE: 'line: ', i.
i = pparseerror->get_column( ).
WRITE: 'column: ', i.
string = pparseerror->get_reason( ).
WRITE: string.
index = index + 1.
ENDWHILE.
ENDIF.
ENDIF.
CALL METHOD istream->close( ).
CLEAR istream.
node = document.
PERFORM print_node USING node 0.
FORM print_node USING p_node TYPE REF TO if_ixml_node deep TYPE i.
DATA: nodetype TYPE i,
attrslen TYPE i,
attrs TYPE REF TO if_ixml_named_node_map,
attr TYPE REF TO if_ixml_node.
nodetype = p_node->get_type( ).
CASE p_node->get_type( ).
WHEN if_ixml_node=>co_node_element."这里只处理元素节点
WRITE: /.
PERFORM printnodeinfo USING '元素' deep p_node.
attrs = p_node->get_attributes( ).
attrslen = attrs->get_length( ).
DO attrslen TIMES.
attr = attrs->get_item( sy-index - 1 ).
PERFORM printnodeinfo USING '属性' deep attr.
ENDDO.
"WHEN if_ixml_node=>co_node_text.
"PERFORM printnodeinfo USING '文本' deep p_node.
ENDCASE.
DATA: childs TYPE REF TO if_ixml_node_list,
child TYPE REF TO if_ixml_node,
childslen TYPE i.
childs = p_node->get_children( ).
childslen = childs->get_length( ).
DATA: deep2 TYPE i.
deep2 = deep + 1.
DO childslen TIMES.
child = childs->get_item( sy-index - 1 ).
PERFORM print_node USING child deep2.
ENDDO.
ENDFORM.
FORM printnodeinfo USING nodetype TYPE string deep TYPE i node TYPE REF TO if_ixml_node.
DATA: name TYPE string,
value TYPE string,
spaces TYPE string.
DO deep TIMES.
spaces = spaces && ` `.
ENDDO.
name = node->get_name( ).
value = node->get_value( ).
WRITE: spaces, nodetype ,name,value .
ENDFORM.
20.7.OLE
CREATE OBJECT obj_name 'app'."创建APP应用类的一个对象obj_name实例
SET PROPERTY OF obj_name 'XXX' = f ."设置对象OBJ_NAME属性xxx为值f
GET PROPERTY OF obj_name 'xxx' = f ."将obj_name的属性xxx的值获取赋给f
CALL METHOD OF
obj_name
'xxx' = f "由f来接收返回值
EXPORTING
#1 = f1. "调用Obj_name的方法xxx 传入参数f1…fn
FREE OBJECT obj_name. "释放obj_name.
*定义OLE变量
DATA:EXCEL TYPE OLE2_OBJECT,
WORKBOOK TYPE OLE2_OBJECT,
SHEET TYPE OLE2_OBJECT,
CELL TYPE OLE2_OBJECT.
CREATE OBJECT EXCEL 'EXCEL.APPLICATION'.
SET PROPERTY OF EXCEL 'VISIBLE' = 1."使excel可见
SET PROPERTY OF EXCEL 'SHEETSINNEWWORKBOOK' = 1."设置 Microsoft Excel 软件打开时,自动插入到新工作簿中的工作表数目(即初始sheet数目,默认名字依次为 Sheet1、Sheet2.....)
CALL METHOD OF EXCEL 'WORKBOOKS' = WORKBOOK.
"由于Workbooks同时为属性,所以可以使用下面语句代替上面语句
*GET PROPERTY OF EXCEL 'Workbooks' = WORKBOOK .
CALL METHOD OF WORKBOOK 'ADD'.
CALL METHOD OF WORKBOOK 'OPEN'EXPORTING #1 = 'c:\1.xlsx'."开文件
添加sheet:
CALL METHOD OF EXCEL 'sheets' = SHEET.
CALL METHOD OF SHEET 'Add'.
SET PROPERTY OF SHEET 'Name' = 'aaa'."sheet重命名
切换sheet:
CALL METHOD OF EXCEL 'Worksheets' = SHEET EXPORTING #1 = 'sheet3'.
CALL METHOD OF SHEET 'Activate'.
CaLL METHOD OF EXCEL 'CELLS' = CELL EXPORTING #1 = 2 #2 = 2.
SET PROPERTY OF CELL 'value' = xxxx.
执行宏:
CALL METHOD OF EXCEL 'RUN' EXPORTING #1 = 'ZMACRO2'.
保存和退出:
GET PROPERTY OF EXCEL 'ACTIVESHEET' = SHEET."激活工作簿
GET PROPERTY OF EXCEL 'ACTIVEWORKBOOK' = WORKBOOK."激活工作区
CALL METHOD OF WORKBOOK 'SAVEAS'EXPORTING #1 = 'c:\1.xls' #2 = 1.
CALL METHOD OF WORKBOOK 'CLOSE'. "关闭工作区
CALL METHOD OF EXCEL 'QUIT'."退出excel
释放资源:
FREE OBJECT SHEET.
FREE OBJECT WORKBOOK.
FREE OBJECT EXCEL.
20.7.1.导出Exel文件多种方式
FM函数 SAP_CONVERT_TO_XLS_FORMAT:
优点是快速,简单;缺点就是不能控制格式,导出的数据看起来不够美观,不能使用公式,宏等
OLE:
这个方法使用对象OLE2_OBJECT,模拟手工来填写EXCEL的内容,所以基本上可以实现Excel的绝大部分功能,诸如特殊格式、函数、宏、图片等等
优点是功能强大,能做到用户指定的格式;缺点是复杂,速度慢。
OLE + Excel模板:
这个方法是在纯OLE的基础上增加使用Excel模板,原理是通过在Excel模板里面设定格式,公式等已知的内容,然后使用OLE去填充其它数据
优点是比纯OLE速度要快;缺点还是速度慢,虽然比第二种方法有所提高,但是如果数据量比较大的时候,比如超过1000行,速度方面还是不尽如人意
OLE + Excel模板 + TXT:
这个方法在方法3的基础上增加使用TXT文本文件,原理是先将数据根据按照Excel行列准备好,导出到TXT文本文件中,然后在Excel模板中使用宏打开文本文件进行填充
优点是功能强,速度快;缺点是实现起来较为复杂,且需要懂VBA
20.8.ABAP示例代码
通过ABAPDOCU、DWDM事务码查看
20.9.长文本

在函数 Read_text 中设置一个断点,然后打开相应的Tcode,进行对应的长文本界面,程序会停止在Read_text函数里,然后按 F7 ,即可回到调用Read_text 函数的上层主调程序,这样可以找到这传递的参数信息。
20.9.1.物料长文本

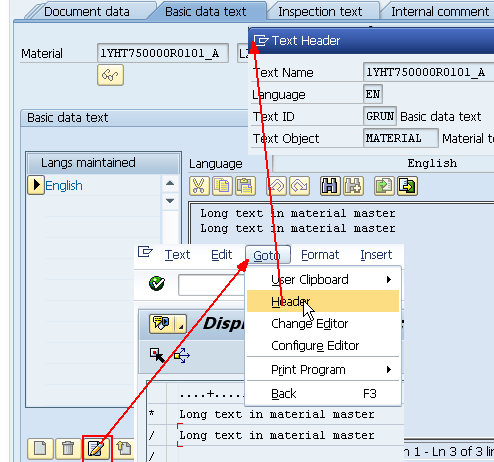
20.9.2.生产定单长文本

20.9.3.采购定单长文本
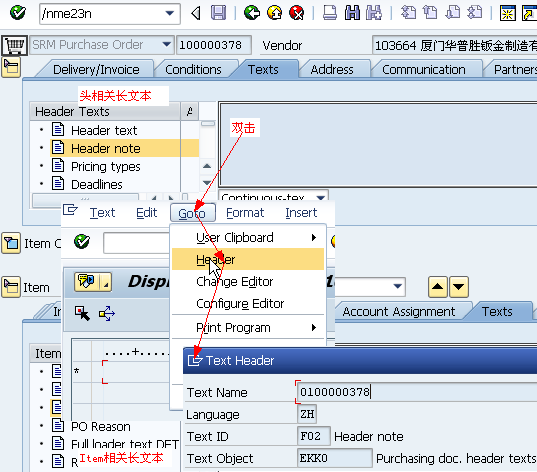
20.9.4.销售定单长文本
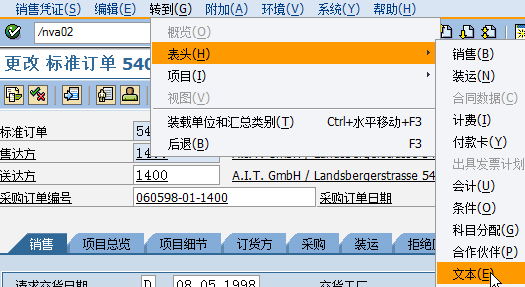
20.10.Smart Forms
主窗口中的数据可以在多个打印页面中可连续输出,即可跨页面(分页显示)每个页面(PAGE)中只能包含一个主窗口,但可以有多个子窗口(分页情况下,子窗口应该在每页上都会显示,就是页眉页脚一样)。
一个FORM中只能定义一个主窗体;不同PAGE上的主窗体必须宽度相同,但是高度可以不同;
一个没有主窗体的PAGE指向的下一个页面不能为它自己(但可以被其他Page指定为下一页)
&field(*)& 如果该字段类型是abap数据字典里定义的类型,系统将按照字典定义的长度设置输出长度
&field(S)& 禁止输出符号位
&field(.<length >)& 设置显示小数的位数
&field(Z)& 禁止数字前导0的显示
&field(I)& 禁止显示空值
&field(K)& 禁止类型系统按数据字典定义的转换函数进行输出转换
&field(R)& 右对齐(只有在定义了输出长度时才有效)
&field(C)& 该设置效果和ABAP的CONDENSE语句相同。把金额、数量转换为字符串后显示
&field(<)& 符号位显示在数据前面
20.11.BOM
一个物料,知道物料号,想知道由这种物料组成的一种或数种产成品应该使用CS15;一产成品,知道物料号,想知道这产成品是由哪几种物料组成应该使用CS03(显示BOM)、CS11(逐层显示BOM)、CS12(多层BOM)
BOM Header/Item : STKO/STOP;
Order BOM 展开:CS_BOM_EXPL_KND_V1 ;
Material BOM 展开:CS_BOM_EXPL_MAT_V2
CALL FUNCTION 'CS_BOM_EXPL_MAT_V2' explosion 英[ɪkˈspləʊʒn]:爆炸
EXPORTING
CAPID = 'PP01' " BOM应用DATUV = sy-datum " 有效起始日
EMENG = '1' " 需求数量MEHRS = 'X' " 多层展开
MMORY = '1' " 是否使用缓存 MTNRV= imatnr-matnr " 待展开物料号
STLAN = '1'" BOM用途WERKS= s_werks-low" 物料所在工厂
TABLES
STB = stb
20.12.传输请求SE01、SE09、SE10
20.13.Script Form传输:SCC1
需在目标客户端Client上操作
20.14.权限检查
AT SELECTION-SCREEN.
DATA: BEGIN OF lt_bukrs OCCURS 0,
bukrs TYPE t001-bukrs,
END OF lt_bukrs.
SELECT bukrs FROM t001 INTO CORRESPONDING FIELDS OF TABLE lt_bukrs WHERE bukrs IN s_bukrs.
LOOP AT lt_bukrs.
AUTHORITY-CHECK OBJECT 'ZDABAP' [ɔ:ˈθɔriti]
ID 'VKORG' DUMMY 销售组织
ID 'BUKRS' FIELD lt_bukrs-bukrs 公司代码
ID 'WERKS' DUMMY 工厂
ID 'EKORG' DUMMY 采购组织
ID 'KOKRS' DUMMY
ID 'GSBER' DUMMY
ID 'SEGMENT' DUMMY.
IF sy-subrc <> 0."
MESSAGE s001(00) DISPLAY LIKE 'E' WITH 'You do not have authorization to access company code:' lt_bukrs-bukrs.
STOP.
ENDIF.
ENDLOOP.
ENDFORM.
20.15.允许对表数据维护
允许通过维护工具数据浏览器(事务 SE16)和表视图维护(事务 SM30)显示/维护表数据,一般设置此属性后,就可以直接通过SE16进行表数据的维护了
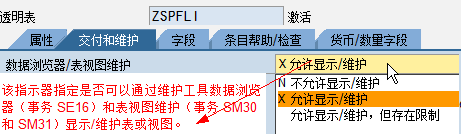
20.16.SE93创建事务码

平时我们选择的是第二个(是基于“程序和选择屏幕”来创建)会出现选择屏幕,这里我们选择最后一个(基于“事务码”),并且可以先配置事务码需要的初始化参数,在运行时直接跳过初始屏幕:
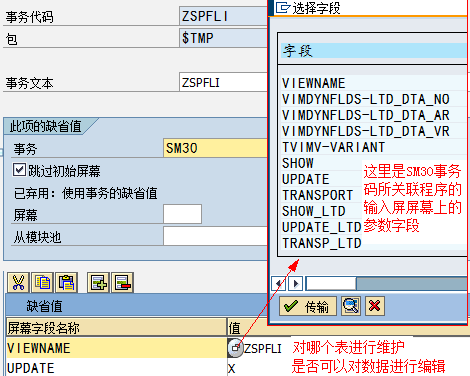
20.17.表字段初始值、NULL等问题
20.17.1.SE11表设置中的Initial Values
如果一个表是新创建的,数据库中的所有字段都会被设计成非NULL,此时与钩不钩上“Initial Values”框没有关系,且都会设置默认值,并且所有的主键都会强制将“Initial Values”框钩上
该标示只在修改表结构且在现有表结构增加一个字段时,才起作用,并且只对新增的字段有影响
如果在给现已有的表中增加一个字段,调整表结构时,如果新加的字段没有钩上“Initial Values”,则对应到数据库表设计中表示该字段则为NULL;如果钩上了,则数据库中的相应字段不为NULL,并且会设置一个默认值
20.17.2.底层数据库表字段默认值
字符类型的字段默认值大多数(极个别使用空字符串)为一个空格,数字字符串与日期为相应位数的0字符中,数字类型为0:
![]()
![]()
![]()


上面数据库表设计视图中的默认值所对应的创建SQL如下:
createdefault [ecc].[str_default] as ' ' 一个空格
createdefault [ecc].[empstr_default] as '' 空字符串
createdefault [ecc].[raw_default] as 0x00
createdefault [ecc].[numc5_default] as '00000'
createdefault [ecc].[numc8_default] as '00000000'
createdefault [ecc].[num_default] as 0
20.17.3.ABAP初始值、底层数据库表默认值相互转换
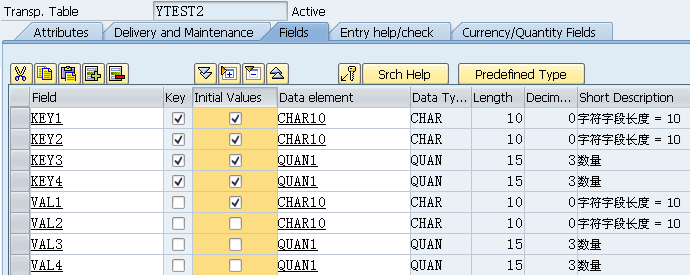
20.17.3.1.向表中插入初始值
在通过ABAP向数据库中插入数据时,不可能将NULL插入到表中,因为SAP系统将数据插入到数据库表之前会判断各字段值是否是ABAP程序中相应的初始值,如果为ABAP程序初始值,则使用相对应ABAP词典中的内置类型初始值进行插入;所以数据库表中字段值为NULL只有一种情况,就是调整表结构时(增加字段),没有将Initial Values钩上
DATA: wa_strc LIKE ytest2..
CLEAR: wa_strc.
INSERT ytest2 FROM wa_strc.
内存中的数据(其中类型为P类型字段的初始值为 000...00C ,最后的 C 表示整数位为12位,剩下小数位数为 16 -12 – 1 = 3 位,其中算术式中的1表示一个小数点,所以整体来看类型为P的字段初始值还是0):

向表中插入初始行后,字符字段全为一个空格,数字类型为0:
![]()
20.17.3.2.读取数据
CLEAR: wa_strc.
SELECT SINGLE * INTO CORRESPONDING FIELDS OF wa_strc FROM ytest2.
得到的结果与上面插入数据一样。即使手动将数据库中的一个空格修改成多个,还是能读取出来恢复成插入时的初始数据。另外,以下SQL还是能读出数据:
SELECT SINGLE * INTO CORRESPONDING FIELDS OF wa_strc FROM ytest2 WHERE
key1 eq '' and key1 eq ' ' and key1 eq ' ' 分别为一个、两个、三个空格
但如果加上 key1 is null,则查询不出数据。
由此可以看出,数据库中的默认值加载到ABAP内存中后,也会转换成相应ABAP程序内置类型相应的初始值
20.17.4.SAP系统中的表字段不允许为NULL的原因
下面VAL2字段值为NULL时,使用 val2 <> 33 查询时,VAL2为NULL值是查询不出来的(标准SQL语句就是这样):
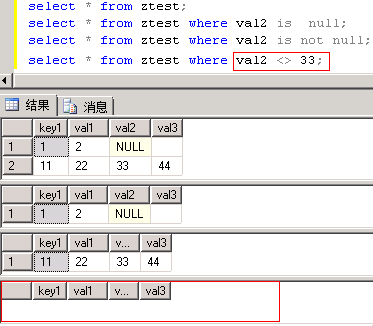
20.18.ABAP中的“空”、INITIAL
DATA: n(4) TYPE n VALUE '0000'.
IF '' = ' ' AND '' = 0 AND ' ' = 0 AND '' IS INITIAL AND ' ' IS INITIAL AND 0 IS INITIAL AND n IS INITIAL.
WRITE: 'IS INITIAL'. 以上条件为真
ENDIF.
但'0000'数字常量串不能视为初始,下面条件也为真:
IF '' <> '0000' AND ' ' <> '0000' AND '0000' IS NOT INITIAL.
当查询某个表时,如果要判断某个字段是否为空,则要使用是否等于' '空格(''空字符也行)来判断(XX EQ ' '如果是数字类型,则需要与0进行对比),而不能使用 is NULL来查询,因为SAP中的表字段几乎没有为NULL的,基本上都是一个空格,所以不能使用is NULL。从ST05可以看出:is NULL会原样写在SQL语句中,而空字符串或空格字符串都会转换成一个空格,这正好与数据库字符类型字段的默认字段对应:
SELECT SINGLE * FROM mara WHERE matnr IS NULL OR matnr = '' OR matnr = ' ' OR matnr = ' '.
SELECT WHERE "MANDT" = '210' AND ( "MATNR" IS NULL OR "MATNR" = ' ' OR "MATNR" = ' ' OR "MATNR" = ' ' ) AND ROWNUM <= 1
另外,如果是查询条件字段是Date、Numc、QUAN类型时,Where条件后面的值不会使用引号引起来,而是把它们直接看作是数字类型,特别是Date与Numc类型,所对应的数据库表字段的类型为Nvarchar,这样在查询时会先将数据库表字段的值转换为数字类型后再进行比较:
SELECT WHERE "MANDT" = '210' AND "MATNR" = 'FOOTBALL' AND "ERSDA" = 00000000 AND "LAEDA" = 20120511 AND "BLANZ" = 000 AND "COMPL" = 01 AND "BRGEW" = 0 AND "NTGEW" = 10
下面是此生成SQL的查询界面:

20.19.调试工具
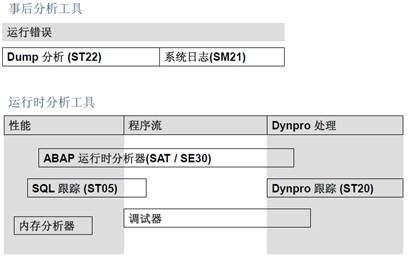
20.19.1.ST05

hh:mm:ss.ms: 發送數據庫請求的開始時間點 (小時:分鐘:秒:毫秒)
Duration: 數據庫操作的持續時間,以毫秒計 (根據系統負載而變化)
Program: 調用SQL語句的程式名
Object name: SQL語句中的table或 view的名稱
Oper 所執行的數據庫操作符.
Curs: 數據庫游標的標記
ArrSz: 數據記錄從database server 到 application server傳輸的數據包大小.
Rec: 通過數據庫操作數據記錄的傳輸數量
RC: 從數據庫系統返回的代碼
Statement: SQL 語句的文本
20.20.程序创建Job(报表自已设置后台运行,前后台数据共享)
REPORT ymais_sust.
TABLES vbap.
PARAMETERS: p_back .
SELECT-OPTIONS: s_vbeln FOR vbap-vbeln .
DATA: l_number TYPE tbtcjob-jobcount,
l_name TYPE tbtcjob-jobname .
DATA: run_flg."当前程序是否已在后台运行过了
l_name = sy-repid."当前程序名
START-OF-SELECTION.
DATA: c_tmp(20).
DATA:l_jobcount TYPE tbtcm-jobcount,
l_jobname TYPE tbtcm-jobname.
"如果当前程序是在后台运行时,从SAP内存中读取前台共享的参数
IF sy-batch IS NOT INITIAL.
CALL FUNCTION 'GET_JOB_RUNTIME_INFO'"获取当前后台Job名与Job编号
IMPORTING
jobcount = l_jobcount
jobname = l_jobname.
CONCATENATE 'YMAIS_SUST' l_jobcount INTO c_tmp RESPECTING BLANKS.
"读取从前台传递过来的参数
IMPORT run_flg FROM SHARED BUFFER indx(fi) ID c_tmp.
IF sy-subrc <> 0.
MESSAGE e001(00) WITH 'import data unsuccessful'.
ELSE.
"所有输出的 message 可以在假脱机日志里看到
MESSAGE i001(00) WITH '从前台读取来的值 run_flg = ' run_flg.
"共享内存使用后即时删除,否则要等到服务器重启再消失
DELETE FROM SHARED BUFFER indx(fi) ID c_tmp.
ENDIF.
ELSE."如果是通过前台运行时
CALL FUNCTION 'JOB_OPEN'
EXPORTING
jobname = l_name
IMPORTING
jobcount = l_number
EXCEPTIONS
cant_create_job = 1
invalid_job_data = 2
jobname_missing = 3
OTHERS = 4.
IF sy-subrc = 0.
"直接采用 SUBMIT 的方式,让报表程序在后台运行
SUBMIT ymais_sust
WITH p_back = p_back"Paramters参数
WITH s_vbeln IN s_vbeln"Selection-option参数
* WITH s_bukrs BETWEEN '1106' AND '1111' SIGN 'I'"如果Selection-option只有一行时,可以这样使用,如果是单个值,还可以这样使用:
* WITH bukrs eq '1106' SIGN 'I'
VIA JOB l_name NUMBER l_number AND RETURN.
"由于 Shared Buffer是整个服务器都可以共享的,所以每个后台Job需要自己的 Buffer,所以
"使用各自Job的编号来区分。该方式用来在前台程序与后台Job之间传递参数
CONCATENATE 'YMAIS_SUST' l_number INTO c_tmp RESPECTING BLANKS.
EXPORT run_flg FROM 'X' TO SHARED BUFFER indx(fi) ID c_tmp.
"也可以通过下面标准函数来提交Job,但此标准函数不能直接将前台参数传递给后台Job程序(除通过变式
"参数 VARIANT 外)。所以只能采用上面 EXPORT ... SHARED BUFFER 语句来共享服务器内存来实现
* CALL FUNCTION 'JOB_SUBMIT'
* EXPORTING
* authcknam = sy-uname
* jobcount = l_number
* jobname = l_name
** PRIPARAMS = ' '打印参数
* report = 'YMAIS_SUST'
** VARIANT = ' '可通过变式来传递参数
CALL FUNCTION 'JOB_CLOSE'
EXPORTING
jobcount = l_number
jobname = l_name
strtimmed = 'X'.
ENDIF.
ENDIF.
END-OF-SELECTION.
"如果当前程序是在后台运行时
IF sy-batch IS NOT INITIAL.
"会输出到假脱机输出列表中
WRITE: / '后台输出'.
"后面还可以写在后台运行时需要执行的代码逻辑及输出
......
ELSE.
MESSAGE '当前程序已经通过后台运行' TYPE 'I'.
LEAVE PROGRAM.
ENDIF.
20.21.SE78、SWM0
SE78也可以上传图片,但那是为Smart/Script Form设计使用的;SWM0除了上传图片外,还可以上传其他一些二进制文件(如上传一些Excel模块,供用户下载到PC端,再通过OLE来操作此文档),通过DOWNLOAD_WEB_OBJECT函数下载使用。SWM0过程如下:
选择二进制数据回车

点“执行”按钮,显示当前系统中已上传的二进制资源。如果待上传的资源文件扩展名不在系统中时,上传会报错,此时需对MIME类型进行维护,如上传GIF文件时,需要先维护MIME类型:
20.22.客户端文本文件或Excel文件上传与下载
20.22.1. 读取客户端Txt、Excel文件到内表:TEXT_CONVERT_XLS_TO_SAP
TEXT_CONVERT_XLS_TO_SAP函数可以将本地的文本文件(列与列之间默认使用TAB键分开,但也可以指定)或真正的Excel文件上传到服务内表中,并且文件转换成内表中的数据是自动完成,不需要手动,这与ALSM_EXCEL_TO_INTERNAL_TABLE函数是不一样的
PARAMETERS:p_file LIKE rlgrap-filename OBLIGATORY.
DATA: il_raw TYPE truxs_t_text_data.
DATA:l_obj TYPE REF TO cl_gui_frontend_services.
DATA: it_file TYPE filetable WITH HEADER LINE.
DATA: g_rc TYPE i.
DATA: BEGIN OF i_data OCCURS 0,
c(2),
n(2) TYPE n,
i TYPE i,
d TYPE d,
END OF i_data.
AT SELECTION-SCREEN ON VALUE-REQUEST FOR p_file. "弹出选择文件对话框
CREATE OBJECT l_obj.
CALL METHOD l_obj->file_open_dialog
EXPORTING
file_filter = '*.xls;*.xlsx;*.txt'
initial_directory = 'C:\data'
CHANGING
file_table = it_file[]
rc = g_rc.
READ TABLE it_file INDEX 1.
p_file = it_file-filename.
START-OF-SELECTION.
CALL FUNCTION 'TEXT_CONVERT_XLS_TO_SAP'"可以是Excel文件,也可以是Txt文件
EXPORTING
* I_FIELD_SEPERATOR = 分隔符,默认为Tab
* i_line_header = 'X' "文本中的第一行是否是标题头,如果是则不会读取
i_tab_raw_data = il_raw "该参数实际上没有使用到,但为必输参数
i_filename = p_file
TABLES
i_tab_converted_data = i_data. "会自动的将Excel、Txt文件中的数据一行行读取到数据内表中
20.22.2. 将数据内表导出为EXCEL文件:SAP_CONVERT_TO_XLS_FORMAT
DATA: t100_lines TYPE STANDARD TABLE OF t001.
SELECT * FROM t001 INTO TABLE t100_lines.
CALL FUNCTION 'SAP_CONVERT_TO_XLS_FORMAT'
EXPORTING
i_filename = 'c:\1.xlsx'
TABLES
i_tab_sap_data = t100_lines.
如果EXCEL文件已经存在,那么数据会被覆盖
注:数据内表中的字段类型不能是数字类型,否则会出现意想不到的错,如有数字类型字段,转出前最好先转换为字符类型再输出
20.23.Unicode字符串互转
DATA: c(4) TYPE c VALUE 'ABCD'.
FIELD-SYMBOLS <fs1>.
ASSIGN c TO <fs1> type 'X'. "将字符串以十六进制的Unicode码来表示
WRITE: / <fs1>.0041004200430044这是在AIX上测试的结果。注意,SAP上使用的是Unicode码,所以为双字节,在转换为十六进制时,与服务器所在操作系统的字节顺有关(Java是与平台无关的,在任何平台上都是高字节序),从这里就可以看出Windows与Unix上的字节序不是一样的。
"====分配时指定类型
DATA: x(8) TYPE x ."这里的8表示8个字节
x = <fs1>.
FIELD-SYMBOLS <fs3> .
"将十六进制的Unicode码转换为字符串
ASSIGN x TO <fs3> type 'C'. "C在这里是一般类型,代指字符串,而不是只一个C
WRITE:/ <fs3>. "ABCD
"====通过强转
FIELD-SYMBOLS <fs4> TYPE c. "C在这里也是一般类型
ASSIGN x TO <fs4> CASTING.
WRITE:/ <fs4>."ABCD
20.24.字符编码与解码
DATA: xstr TYPE xstring.
DATA: l_codepage(4) TYPE n .
DATA: l_encoding(20).
**********字符集名与内码转换
"将外部字符集名转换为内部编码
CALL FUNCTION 'SCP_CODEPAGE_BY_EXTERNAL_NAME'
EXPORTING
external_name = 'UTF-8'
IMPORTING
sap_codepage = l_codepage.
l_encoding = l_codepage.
**********编码
DATA: convout TYPE REF TO cl_abap_conv_out_ce.
"创建编码对象
convout = cl_abap_conv_out_ce=>create( encoding = l_encoding ).
convout->write( data = '江正军')."编码
xstr = convout->get_buffer( )."获取码流
WRITE: / xstr."E6B19FE6ADA3E5869B
**********解码
DATA: convin TYPE REF TO cl_abap_conv_in_ce.
"创建解码对象
convin = cl_abap_conv_in_ce=>create( encoding = l_encoding input = xstr ).
DATA: str TYPE string.
CALL METHOD convin->read"解码
IMPORTING data = str.
WRITE: / str."江正军
20.25.ABAP中的特殊字符列表
cl_abap_char_utilities=>horizontal_tab 09 TAB符
cl_abap_char_utilities=>CR_LF 0D0A 回车换行
cl_abap_char_utilities=>VERTICAL_TAB 0B 垂直制表符
cl_abap_char_utilities=>NEWLINE 0A 换行
cl_abap_char_utilities=>FORM_FEED 0C 换页
cl_abap_char_utilities=>BACKSPACE 08 退格符
CL_ABAP_CHAR_UTILITIES=>BYTE_ORDER_MARK_LITTLE (utf-16le)的文件头
CL_ABAP_CHAR_UTILITIES=>BYTE_ORDER_MARK_UTF8 (utf-8)的文件头
如果是要单独取得回车或者换行(不是回车加换行),可以采用:
cl_abap_char_utilities=>CR_LF(1)
cl_abap_char_utilities=>CR_LF 1(1)
空白字符:System.out.println((int)'');//12288
DATA: gc_result(50) TYPE c.
CONSTANTS: c_tab TYPE c VALUE cl_abap_char_utilities=>horizontal_tab.
CONCATENATE 'text01' c_tab 'text02' c_tab 'text03' INTO gc_result.
20.26.下载文件
20.26.1.以BIN二进制下载
DATA: xstr TYPE xstring.
DATA: l_codepage(4) TYPE n .
DATA: l_encoding(20).
**********字符集名与内码转换
"将外部字符集名转换为内部编码
CALL FUNCTION 'SCP_CODEPAGE_BY_EXTERNAL_NAME'
EXPORTING
external_name = 'UTF-8'
IMPORTING
sap_codepage = l_codepage.
l_encoding = l_codepage.
**********编码
DATA: convout TYPE REF TO cl_abap_conv_out_ce.
"创建编码对象
convout = cl_abap_conv_out_ce=>create( encoding = l_encoding ).
convout->write( data = '江正军')."编码
xstr = convout->get_buffer( )."获取二进制码流
WRITE: / xstr."E6B19FE6ADA3E5869B
**********解码
DATA: convin TYPE REF TO cl_abap_conv_in_ce.
"创建解码对象
convin = cl_abap_conv_in_ce=>create( encoding = l_encoding input = xstr ).
DATA: str TYPE string.
CALL METHOD convin->read"解码
IMPORTING data = str.
WRITE: / str."江正军
TYPES : xx(100) TYPE x.
DATA: xtab TYPE STANDARD TABLE OF xx WITH HEADER LINE.
xtab = xstr.
APPEND xtab.
CALL FUNCTION 'GUI_DOWNLOAD'
EXPORTING
filename = 'c:\2.txt'
filetype = 'BIN'
TABLES
"data_tab的类型为ANY,所以xtab是一列还是多列,都会写到
"文件中去,这里还只有一列,而且还没有列名,这也没有关系
data_tab = xtab[].
20.26.2.以字符模式下载
DATA: BEGIN OF strc OCCURS 0,
c1(2) TYPE c,
c2(1) TYPE c,
END OF strc.
strc-c1 = '中'.
strc-c2 = '国'.
APPEND strc.
APPEND strc.
CALL FUNCTION 'GUI_DOWNLOAD'
EXPORTING
* BIN_FILESIZE =
filename = 'c:\1.txt'
filetype = 'DAT'"列与列之间会使用TAB分隔
* APPEND = ' '
* WRITE_FIELD_SEPARATOR = ' '
* HEADER = '00'
* codepage = '8400' "GBK
* codepage = '8450' "GB2312
codepage = '4110'"utf-8
* CODEPAGE = '4102'"UTF-16BE
* CODEPAGE = '4103'"UTF-16LE
TABLES
data_tab = strc[].
20.27.将文件上传到数据库表中,并可邮件发送
以后考虑将CONTENT_HEX字段定义为LRAW类型,这样直接存储二进制,数据不会膨胀一倍了(也可采用其他方式,请参考数据共享与传递->DATABASE章节)
"Table: ZJZJPDF 表结构设计如下:
"Field name Key Data element Datatype Length
"MANDT X MANDT CLNT 3
"ROW_ORDER X NUMC 10
"CHR_COUNT INT4 10
"CONTENT_HEX LCHR 510 "注:内类型为 C,并非 X
"LCHR类型的字段前必须有一个INT4类型的字段,并且该字段不能是主键,该字段的值为后面
"CONTENT_HEX的字符个数,并且需要在插入表时一并进行插入,否则CONTENT_HEX字段的值不能Select出来
DATA: BEGIN OF xtab255 OCCURS 0,
x(255) TYPE x,"一个字节需使用两个十六进制字符来表示
END OF xtab255.
DATA: ctab255 TYPE STANDARD TABLE OF solisti1 WITH HEADER LINE.
DATA: BEGIN OF pdf_table OCCURS 0,
mandt TYPE zjzjpdf-mandt,
row_order TYPE zjzjpdf-row_order,
chr_count TYPE zjzjpdf-chr_count,
content_hex(510), "实为字符类型
END OF pdf_table.
********==========================================插入
CALL FUNCTION 'GUI_UPLOAD'
EXPORTING
filename = 'c:\1.txt'
filetype = 'BIN'
TABLES
data_tab = xtab255.
*CALL FUNCTION 'GUI_UPLOAD'
* EXPORTING
* filename = 'c:\1.JPG'
* filetype = 'BIN'
* TABLES
* "接收上传数据时,按收的内表行类型也可以是Char类型内表
* ",尽管是以BIN 模式上传的,因为该上传函数内部还是以
* "X类型视图来维护ctab255内表的
* data_tab = ctab255.
LOOP AT xtab255.
pdf_table-row_order = sy-tabix.
pdf_table-content_hex = xtab255-x.
"chr_count为内容content_hex字段值的长度,一定要设置,否则下次不能Select出来
pdf_table-chr_count = strlen( pdf_table-content_hex ).
APPEND pdf_table .
ENDLOOP.
DELETE FROM zjzjpdf."清空数据库表中的所有数据
MODIFY zjzjpdf FROM TABLE pdf_table[]."插入到数据库
********==========================================读取
CLEAR: pdf_table[].
SELECT * INTO TABLE pdf_table FROM zjzjpdf.
SORT pdf_table BY row_order.
CLEAR:xtab255[].
LOOP AT pdf_table.
"将数据库表中字面上的HEX字符串转换为真正的HEX二进制
xtab255-x = pdf_table-content_hex.
APPEND xtab255.
ENDLOOP.
"注意:虽然是原生态下载,但这里生成的文件在字节数上会多于源文本,并且字节数是255的整数倍,因为在上传的过程中使用的是xtab255类型的内表,当最后一行不满255个字节时,也会在后面补上直到255个字节,但补的都是00这样的字节,所以文件大小还是有区别的,但经过测试pdf与mp3在码流后面补00字节好像没有什么影响唯独是文件大小变大了。但如果是TXT文件,打开后发现多了很多空格(按理来说也是什么也没有,因为空格的ASCII码为32,但后面补的是00字节)
CALL FUNCTION 'GUI_DOWNLOAD'
EXPORTING
filename = 'c:\2.txt'
filetype = 'BIN'
TABLES
data_tab = xtab255.
*************************************************************************************
如果需要将PDF以邮件的形式发送出去时,上面的 xtab255 内表接口就已适合于使用cl_document_bcs类的add_attachment方法来发送邮件的i_att_content_hex内表参数接口;但如果使用SO_DOCUMENT_SEND_API1函数的方式来发送邮件时,并使用CONTENTS_BIN过时(可以使用新参参数CONTENTS_HEX内表接口时不需转换为下面的ctab255内表接口,也可以直接使用上面的xtab255内表接口)的内表参数接口传递PDF文件内容时,需要使用下面方式经过转换后的内表ctab255,即需要将上面的 xtab255 内表中每两行转换为 ctab255(行类型为 Char255)内表中的一行(因为一个X类型为一个字节,但在Unicode中一个C可存两个字节的内容,所以需二行转换一行操作)
*************************************************************************************
FIELD-SYMBOLS: <x> TYPE x.
DATA: c_tmp1(510) TYPE c.
DATA: c_tmp2(510) TYPE c.
DATA: c_total(1020) TYPE c.
DATA: tabix TYPE i,mod TYPE i.
CLEAR: ctab255[].
LOOP AT xtab255.
tabix = sy-tabix.
mod = tabix MOD 2.
IF mod = 1.
CLEAR: ctab255.
"原来是准备使用字段符号<c>(FIELD-SYMBOLS <c> type c) 指向xtab255-x使用 assign xtab255-x to <c>,但该语句使用时有限制:xtab255-x的类型的长度(所定义的字节数)一定要是4的倍数,否则编译出错,所以换成了现在这样,思路:将赋值双方中不是X类型的需要以X类型视图来操作,这样X类型与X类型赋值时不会发生数据的丢失或者是类型的转换,而不是将原本为X类型的一方以C或者其类型视图来看待,这样在非X类型间的赋值可能会导致数据丢失或发生类型转换
ASSIGN COMPONENT 'LINE' OF STRUCTURE ctab255 TO <x> CASTING.
c_tmp1 = xtab255-x.
ELSE.
c_tmp2 = xtab255-x.
CONCATENATE c_tmp1 c_tmp2 INTO c_total .
<x> = c_total. "因为4个字面上的十六进制字符才能表示一个字符C,所以从c_total以十六进制方式赋值给ctab255 时,缩短了3/4
APPEND ctab255.
CLEAR: c_tmp1.
ENDIF.
ENDLOOP.
"可能是奇数后,所以需要判断一下,将最后一行也要附加上去
IF c_tmp1 IS NOT INITIAL.
<x> = c_tmp1.
APPEND ctab255.
ENDIF.
20.28.Append、Include系统表结构增强
如果表的结构修改后,不能激活或激活失败,此时可以使用SE14重新对表进行调整即可
l Include方式时,会在透明表中增加一行名为“.INCLUDE”的列,而Append时,会在末尾增加一列名为“.APPEND”的列
l Include可以插入到任何位置,但Append每次只能附加到当前表结构的末尾(可以附加多个)(但经过多次的修改,最后Append进来的结构也可能位于当前表结构的中间)
l Include时,结构要事先创建好,但Append时,不能引用事先创建好的结构,只能在Append过程中创建。当多个表有相同的几个字段时,这时可以将这些相同的字段抽出来形成一个结构,然后再将这个结构Include到表结构中
l 与Include不同的是,Append可以在不修改SAP系统表(编辑状态)的情况下,可以给系统表新增一字段,对现有使用该表的程序影响很小。
l 不能够为Pooled与Cluster表进行Append。
l 如果某个表中有长文本字段(类型为LCHR或LRAW)的表,不能够在使用Append对它进行扩展,因为长文本字段通常也是只能放在表结构的最后面。
l Append的结构名需要以Z或Y打头
l Append结构中的字段名要使用YY或ZZ打头。
l Append时,SE11不需要切换到编辑模式,但Include需要切换到编辑模式下才能使用
l Append后,被Append的结构中所字段会全部紧跟着显示在“.APPEND”行后面,但Include时是不会将被Include里的字段显示出来不是没显示出来,是没有展开(Append与Include其实都是可以展开的):
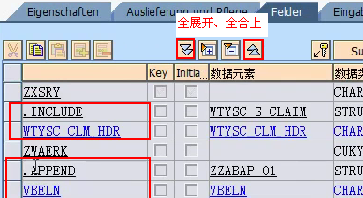
l 在复制表时,“.Append”会丢失,但Append中的字段会被拷贝过来,但Include与之不同,包括 .INCLUDE 与其字段都会被拷贝过来,这进一步证实了 .INCLUDE 结构是可以重复使用的,但Append结构不能
20.29.结构复用(INCLUDE)
TYPES BEGIN OF struc_type.
TYPES comp ...
TYPES comp TYPE struc_type BOXED. "参照另一结构类型
INCLUDE { {TYPE struc_type} | {STRUCTURE struc} } "将另一结构包括进来
[AS name [RENAMING WITH SUFFIX suffix]].
TYPES END OF struc_type.
INCLUDE { {TYPE struc_type} | {STRUCTURE struc} }
[AS name [RENAMING WITH SUFFIX suffix]].
该语句只能用在定义结构的BEGIN OF与 END OF之间。作用是将结构类型struc_type与结构变量struc的所有组件字段拷贝到当前结构定义的指定位置,INCLUDE就是将可以重复使用的东西先做好,再包含进来。
AS name:给包含进来的结构类型(或结构变量)取一个别名,这样就可以通过结构组件符(-)来选取这个结构类型(或结构变量)
RENAMING WITH SUFFIX suffix:如果include进来的结构类型(或结构变量)的组件字段与现有的重复,则可以使用此选项重命名include进来的结构类型(或结构变量)的各组件字段名,具体做法只是在原来组件名后加上了指定的后缀suffix
TYPES: BEGIN OF t_day,
work TYPE c LENGTH 8,
free TYPE c LENGTH 16,
END OF t_day.
DATA BEGIN OF week.
INCLUDE TYPE t_day AS monday RENAMING WITH SUFFIX _mon.
INCLUDE TYPE t_day AS tuesday RENAMING WITH SUFFIX _tue.
INCLUDE TYPE t_day AS wednesday RENAMING WITH SUFFIX _wed.
...
DATA END OF week.
可以通下面的方式来访问week结构变量:
直接看作是week结构变量组件:week-work_mon, week-free_mon, week-work_tue
由于使用as别名,所以还可以这样访问:week-monday-work, week-monday-free, week-tuesday-work
当程序中多个结构使用共同的字段时,将公用的部分提取出来,使用INCLUDE将它们组装起来,编程结构更清晰。下面是结构对象的复用:
DATA: BEGIN OF comm1 OCCURS 0,
bukrs TYPE bseg-bukrs,
END OF comm1.
TYPES:BEGIN OF comm2,
blart TYPE bkpf-blart,
END OF comm2.
DATA: BEGIN OF gt_result OCCURS 0,
c1 TYPE c. "直接定义组件字段,但前面语句后面使用逗号
INCLUDE STRUCTURE comm1."直接将结构对象包括进来
INCLUDE TYPE comm2."直接将结构类型包括进来
DATA:comm LIKE comm1,"直接参照
c2 TYPE c. "直接定义组件字段,但前面语句后面使用逗号
DATA: END OF gt_result.
gt_result-bukrs = '111'.
gt_result-blart = '222'.
gt_result-comm-bukrs = '333'.
下面是类型的复用:
TYPES: BEGIN OF street_type,
name TYPE c LENGTH 40,
no TYPE c LENGTH 4,
END OF street_type.
DATA: BEGIN OF comm1 OCCURS 0,
bukrs TYPE bseg-bukrs,
END OF comm1.
TYPES: BEGIN OF address_type,
name1 TYPE c LENGTH 30."直接定义类型,但前面语句需使用逗号
TYPES:street TYPE street_type,"参照另一结构类型
c TYPE c."直接定义类型,但前面语句需使用逗号
INCLUDE STRUCTURE comm1.
INCLUDE TYPE street_type.
TYPES: END OF address_type.
*或者是这样
*TYPES: BEGIN OF address_type,
* name1 TYPE c LENGTH 30,
* street TYPE street_type,
* c TYPE c.
* INCLUDE STRUCTURE comm1.
* INCLUDE TYPE street_type.
*TYPES: END OF address_type.
DATA: name TYPE address_type-street-name.
DATA: name2 TYPE address_type-name.
DATA: bukrs TYPE address_type-bukrs.
20.30.常用事务码
|
SE16N 业务顾问表数据查询工具
|
SM13:查看Update Table更新(当使用V3更新时) SM50:管理SAP后台进程
SE73:条形码 |
|
|
|
|
CS15: 由这种物料组成的一种或数种产成品 CS03: 成品是由哪几种物料组成应该使用
CS12 多层显示BOM
ME11创建采购信息记录,类似销售里的条件记录VK11, 物料号+采购组织+供应商+工厂(可选)决定一条 Info Record | MIGO 入库、收货 MMBE 按公司、工厂、库位、批次,库存分类汇总显示 MB52 库存详细 MB5B库存信息 |
|
|
FB03 显示会计凭证 |
| PFCG权限角色维护 SU01登录用户维护
SU21权限对象维护 SU22权限对象分配到事务码 SU24查看事务码有哪些权限对象 | SE83 ABAP实例 |









21.常用Function
21.1.日期函数
21.1.1.日期、时间验证
DATE_CHECK_PLAUSIBILITY:检查一个日期是否是有效格式,如果不是有效日期,则报异常:
CALL FUNCTION 'DATE_CHECK_PLAUSIBILITY'
EXPORTING
date = '20110229'
EXCEPTIONS
plausibility_check_failed = 1
OTHERS = 2.
IF sy-subrc <> 0.
ENDIF.
TIME_CHECK_PLAUSIBILITY:时间有效性检查,与上面日期有效性检查使用方式相同
21.1.2.内部转换外部格式
FORMAT_DATE_4_OUTPUT:将数据库中8位的日期(YYYYMMDD)转换为指定的任意格式


注意:在程序中,日期格式要使用大写格式。
CONVERT_DATE_TO_EXTERNAL:将数据库中的8位内部日期(YYYYMMDD)以当前Client设置的外部日期格式显示:

21.1.3.外部转内部格式
CONVERT_DATE_TO_INTERNAL:将外部日期(要符合Client设置的日期格式)转换为数据库内部日期(YYYYMMDD)
INPUT: 02/03/2008 "Should be same as the user's default setting
OUPUT: 20080203
CONVERT_DATE_INPUT:将外部日期(要符合Client设置的日期格式)转换为数据库内部日期
DATA: d TYPE d.
CALL FUNCTION 'CONVERT_DATE_INPUT'
EXPORTING
input = '2011.10.18'
plausibility_check = 'X'"进行日期有效性验证
IMPORTING
output = d
EXCEPTIONS
plausibility_check_failed = 1
wrong_format_in_input = 2
OTHERS = 3.
![]()
21.1.4.获取Client格式
获取当前Client端的日期格式与时间格式:
SELECT datfm INTO lv_datfm FROM usr01 UP TO 1 ROWS WHERE bname = zname . ENDSELECT.

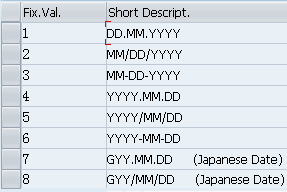

21.1.5.日期加减
RP_CALC_DATE_IN_INTERVAL:加减自然年、自然月,还可以加减天数(一般加多少天直接通过日期类型就加减就可以了,但如果向下面那样需要在20070101加上1年1个月零28天时,就很有用了):
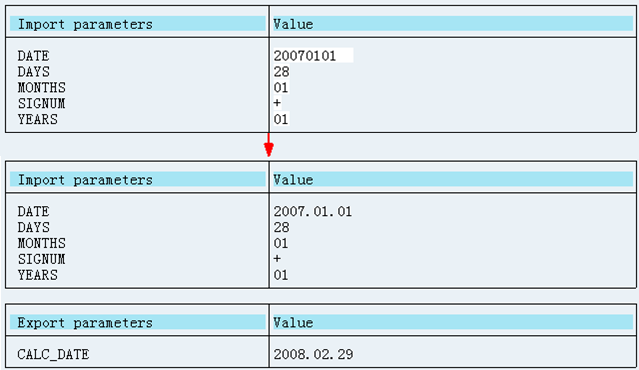
21.1.6.转成工厂日期
DATE_CONVERT_TO_FACTORYDATE:如果输入的是周末与公共节假日,则将它把调整为工厂日历日期(工作日期):
DATA: date LIKE scal-date,
factorydate LIKE scal-facdate,
workday LIKE scal-indicator.
CALL FUNCTION 'DATE_CONVERT_TO_FACTORYDATE'
EXPORTING
"如果输入的日期不是工作日,则是该函数会返回离该输入的节假日前或者后面的最近的工作日,是返回前面还是后面由 +/- 来决定 +:返回后面最近的工作日 -:返回前面最近的工作日默认就是+
* CORRECT_OPTION = '+'
date = '20111119'
"使用的工厂日历ID,可以从 T001W-FABKL 中获取
factory_calendar_id = 'CN'
IMPORTING
"如果输入的是节假日,则返回是经过转换过了的工作日;如果输入的就是工作时,则返回的是自身,格式为 YYYYMMDD
date = date
"返回的工作日在指定的工作日历中位于第几个工作日,一般对我们没什么作用
factorydate = factorydate
"标示返回的DATE是否是工作日,如果为空,则是,如果为 + ,表示返回的是输入的节假日后面最近一个工作;如果为 - ,表示返回的是输入的节假日前面最近一个工作日。
workingday_indicator = workday.
WRITE:/ date , factorydate, workday.
其中工厂日历的代码按工厂号到表T001W上取:
SELECT SINGLE fabkl INTO l_fabkl FROM t001w WHERE werks = im_mt61d-werks.
FACTORYDATE_CONVERT_TO_DATE:该函数可以将DATE_CONVERT_TO_FACTORYDATE返回的factorydate(工作日序号:工作日在指定的工作日历中位于第几个工作日)转换成工作日,也可以用在“加几个工作日”的应用中:比如给某个时间加上几个工作日时,可以先使用DATE_CONVERT_TO_FACTORYDATE函数将某个时间转换为工厂日期,并获取factorydate工作日序号,再在这个工作日序号上加上几个工作日,得到新的工作日序号,然后再将这个新的工作日序号传递给FACTORYDATE_CONVERT_TO_DATE函数,得到最终的新的工作日期:
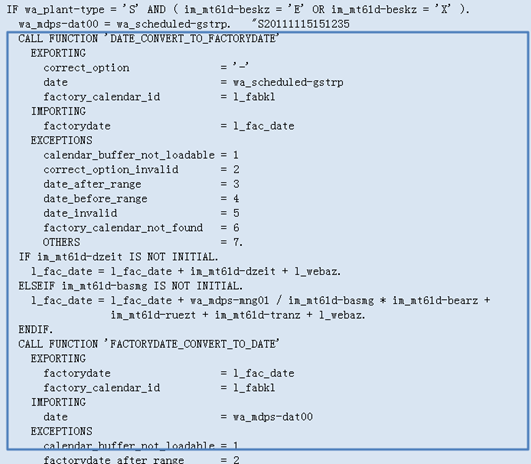
工厂日历定义表为TFACD(节假日历定义表THOCD),表里存储了工厂日历ID(TFACD-IDENT)与节假日历ID(TFACD-HOCID)的关系,所以只要知道了工厂日历ID,则要使用节假日历ID则可以查询出来(注:工厂日历ID还可以通过T001W来查询得到):

工厂日历相关表是以“TFA”开头的表,节假日历相关的表是以“THO”开头相关的表
21.1.7.日期属性
DAY_ATTRIBUTES_GET:查看某日期的属性(休息日、节假日、星期几):
CALL FUNCTION 'DAY_ATTRIBUTES_GET'
EXPORTING
FACTORY_CALENDAR = 'CN'引用表字段TFACD-IDENT
* HOLIDAY_CALENDAR = ' '引用表字段THOCI-IDENT
DATE_FROM = '20110428'
DATE_TO = '20110510'
* LANGUAGE = SY-LANGU
* NON_ISO = ' '
* IMPORTING
* YEAR_OF_VALID_FROM =
* YEAR_OF_VALID_TO =
* RETURNCODE =
TABLES
day_attributes = attr .

21.1.8.节假日
HOLIDAY_CHECK_AND_GET_INFO:判断某天是否是假日,并且可以返回该日期所对应的节假日信息。
DATA attr TYPE casdayattr OCCURS 0.
DATA: is_hol .
DATA: THOL TYPE THOL OCCURS 0.
CALL FUNCTION 'HOLIDAY_CHECK_AND_GET_INFO'
EXPORTING
date = '20100529'
holiday_calendar_id = 'Z1'
"需要返回节假日属性内表信息
with_holiday_attributes = 'X'
IMPORTING
"是否节假日(注:周末不是节假日,但是一种休息日)
holiday_found = is_hol
"Attributes of the found public holidays The table contains
"the holiday aAttributes, if the specified date is a holiday.
"The attributes must be passed in a table because several
"holidays can fall on a date.即一天有可能有两个节,所以需要使用内表接收
TABLES
holiday_attributes = THOL.
21.1.9.年月选择框
POPUP_TO_SELECT_MONTH:弹出一个对话框显示月份和年度下拉列表,让用户选择年与月
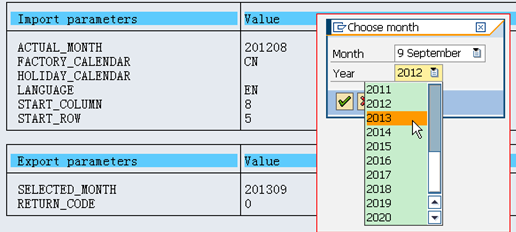
输入:
ACTUAL_MONTH: 当前月份(弹出框中的默认值),必须填写。形式为 YYYYMM。
FACTORY_CALENDAR:工厂日历,可以省略,默认值为空。更多信息请参考表 TFACD。
HOLIDAY_CALENDAR: 公共假日日历,可以省略,默认值为空。更多信息请参考表 THOCI。
LANGUAGE: 语言,可以省略。用来指定月份名称用哪种语言显示,不指定就是当前登录语言。
START_COLUMN: 弹出对话框出现的位置,列,可以省略,默认值为 8。
START_ROW: 弹出对话框出现的位置,行,可以省略,默认值为 5。
输出:
SELECTED_MONTH: 选择的月份,如果按了取消按钮,则值为 000000。
RETURN_CODE: 返回码,如果按了取消按钮,则值为 4,否则为 0。
说明:工厂日历和公共假日日历主要用来限制下拉列表中的可选年份范围。如果不指定,就是当前年前后各 50 年,共 100 年
21.1.10. 财政年
GET_CURRENT_YEAR:得到当前的财政年(fiscal year)
21.1.11. 星期翻译对照表
WEEKDAY_GET:从数据表中获得指定语言每周七天的名称,例如中文就是星期一、星期二……星期日,英文就是Sunday、Monday……Saturday
输入参数:
LANGUAGE:指定语言代码,可以省略,如果不填就是当前登录语言。注意,在调用时如果指定某种特定语言,必须用一个字节的语言代码,例如中文是 1、英文是 E……,而不能用 ZH、EN,语言代码参见表 T002
输出内表:WEEKDAY:结构与透明表 T246 相同,用来存储返回给用户的周日名称。
21.1.12.日期所在周末、天/周、周/年
HR_GBSSP_GET_WEEK_DATES:获得某个日期所在周的周六周日、所在周的第几天、所在年的第几周:
输入参数:
P_PDATE:一个日期,必须填写。
输出参数:
P_SUNDAY:该周的周日,在 SSP 日期系统中,周日为第一天。
P_SATURDAY:该周的周六,在 SSP 日期系统中,周六为最后一天。
P_DAY_IN_WEEK:输入日期在当周的第几天,周日第 1 天,周一第 2 天,依此类推,周六第 7 天。
P_WEEK_NO:该周是年度的第几周。6 位数字,格式为 YYYYWW,前四位是年,后两位是周。
说明:SSP 是 Statutory Sick Pay的缩写
该函数包括了以下两个函数的功能:
DATE_GET_WEEK:获得某个日期所在的周


WEEK_GET_FIRST_DAY:计算某周的第一天(如下面的1999年的第52周第一天):


