
- 1PELCO-D与PELCO-P基本协议_pelco-d/p协议
- 2像素级图像融合的常用算法_图像融合算法
- 3R语言GLM广义线性模型:逻辑回归、泊松回归拟合小鼠临床试验数据(剂量和反应)示例和自测题_r语言广义线性模型示例
- 4High&NewTech:元宇宙(metaverse)的简介(多角度理解与探讨)、发展历史、现状与未来_元宇宙 发展 英语作文
- 5【数据结构】串(定长顺序串、堆串、块链串)的存储结构及基本运算(C语言)_串堆结构c语言
- 6【贪心算法】跳跃游戏_跳跃游戏贪心算法
- 7通过cursor游标讲解,带你初步搞懂python操作mysql数据库
- 8Unable to load the mojo ‘repackage‘ in the plugin ‘org.springframework.boot:spring-boot-maven-plug_unable to load the mojo 'repackage' in the plugin
- 9Tiktok api接口 获取视频列表、用户详情、视频详情无水印接口 python数据采集_tiktokapi
- 10信息炸弹——Message Boom_信息炸蛋
zookeeper实现分布式锁原理_zk实现分布式锁原理用到协议
赞
踩
zookeeper典型使用场景实战
1,zookeeper实现分布式锁
1,之前分析过一篇redis分布式锁实现的原理,今天谈谈zookeeper实现分布式锁的原理。由于每个结点都具有独占性,因此可以通过zookeeper的监听机制,来保证这个锁被谁占有。
zookeeper实现分布式锁的流程如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PXMOkYA5-1658500677686)(C:\Users\HULOUBO\AppData\Roaming\Typora\typora-user-images\1658147525986.png)]](https://img-blog.csdnimg.cn/49951c4f6d284b2689a7b0e36e43239f.png)
大致流程如下:就是说可以对一个结点进行加锁,当其他结点要来加锁时就判断这个结点是否被其他事务创建,如果没有被创建,那么就可以创建当前事务,并且获取当前锁;如果被创建,那么要来获取锁的这个结点可以对这个拥有锁的结点进行监听,当当前锁被释放,就是结点被删除的时候,那么其他结点就可以通过这个监听机制,获取到锁被释放的消息,那么就可以来竞争这把锁了。因此这把锁也是一把非公平锁。
如上实现方式在并发问题比较严重的情况下,性能会下降的比较厉害,主要原因是,所有的连接都在对同一个节点进行监听,当服务器检测到删除事件时,要通知所有的连接,所有的连接同时收到事件,再次并发竞争,这就是羊群效应,会大大的降低系统的效率。
1.1,公平锁实现
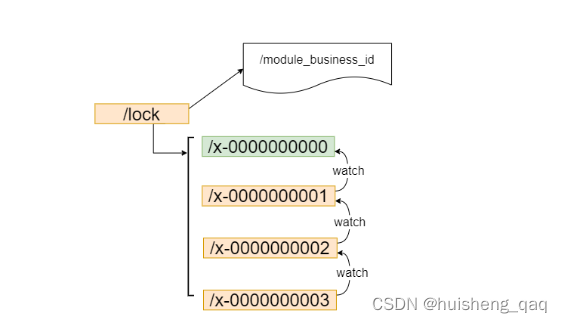
1,请求进来,直接创建一个顺序的临时结点。
2,判断当前结点是否最小结点,如0最小,其次是1,2,3,4…,如果是最小的,那么就获取锁,如果不是最小的,那么就会对前面的结点进行监听,如3监听2,2监听1,依次类推。
3,处理完释放锁,由于1监听0,因此1最先收到锁释放的通知,从而实现这种顺序性,公平锁。
借助于这种临时顺序结点,可以避免同时多个结点的并发竞争锁,从而缓解服务端压力。
2,代码方式实现
可以模拟一个减库存的操作
@Transactional public void reduceStock(Integer id){ // 1.获取库存 Product product = productMapper.getProduct(id); // 模拟耗时业务处理 sleep( 500); // 其他业务处理 if (product.getStock() <=0 ) { throw new RuntimeException("out of stock"); } // 2.减库存 int i = productMapper.deductStock(id); if (i==1){ Order order = new Order(); order.setUserId(UUID.randomUUID().toString()); order.setPid(id); orderMapper.insert(order); }else{ throw new RuntimeException("deduct stock fail, retry."); } } /** * 模拟耗时业务处理 * @param wait */ public void sleep(long wait){ try { TimeUnit.MILLISECONDS.sleep( wait ); } catch (InterruptedException e) { e.printStackTrace(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
当然如果存在多个jvm进程的话,那么一定会出现超卖的问题,这个就可以使用这个zookeeper的分布式锁来解决这个问题。因此接下来通过创建一个zookeeper的互斥锁来解决这个超卖问题,主要通过这个InterProcessMutex这个互斥锁实现。
@Autowired private OrderService orderService; @Autowired CuratorFramework curatorFramework; @PostMapping("/stock/deduct") public Object reduceStock(Integer id) throws Exception { //互斥锁 InterProcessMutex ipm = new InterProcessMutex(curatorFramework, "/product_" + id); try { // xxx业务逻辑 //加锁 interProcessMutex.acquire(); //调用这个减库存的方法 orderService.reduceStock(id); } catch (Exception e) { if (e instanceof RuntimeException) { throw e; } }finally { //释放锁 interProcessMutex.release(); } return "ok" ; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
2.1,InterProcessMutex底层
/**
* CuratorFramework:Curator客户端
* path:结点
* 主要是通过new这个StandardLockInternalsDriver类实现
*/
InterProcessMutexpublic InterProcessMutex(CuratorFramework client, String path) {
this(client, path, new StandardLockInternalsDriver());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2,加锁的的具体细节
//加锁
interProcessMutex.acquire();
- 1
- 2
acquire方法的具体实现如下,
public void acquire() throws Exception {
if (!this.internalLock(-1L, (TimeUnit)null)) {
throw new IOException(this.basePath);
}
}
- 1
- 2
- 3
- 4
- 5
通过这个internalLock方法来判断是否加过锁,如果没有加过锁就会调用attemptLock方法来进行加锁
private boolean internalLock(long time, TimeUnit unit) throws Exception { //获取当前线程 Thread currentThread = Thread.currentThread(); //InterProcessMutex互斥锁中判断是否已经加过锁 InterProcessMutex.LockData lockData = (InterProcessMutex.LockData)this.threadData.get(currentThread); //加过锁 if (lockData != null) { //将数据进行加1的操作 lockData.lockCount.incrementAndGet(); return true; } else { //进行一个加锁 String lockPath = this.internals.attemptLock(time, unit, this.getLockNodeBytes()); //判断是否加锁成功 if (lockPath != null) { InterProcessMutex.LockData newLockData = new InterProcessMutex.LockData(currentThread, lockPath); this.threadData.put(currentThread, newLockData); return true; } else { return false; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
加锁的方式具体如下,主要是在这个方法里面attemptLock(),具体流程如下,首先会去创建一个结点,然后会去判断当前结点是不是最小的结点,如果当前结点是最小的结点,那么就会获取锁,如果当前结点不是最小的结点,那么就会对前面的结点进行监听,内部会有一些排序等,监听等的操作,最后结点处理完之后会去释放锁。
while(!isDone) { isDone = true; try { //创建结点 ourPath = this.driver.createsTheLock(this.client, this.path, localLockNodeBytes); //创建创建成功之后判断当前节点是不是最小的子结点,内部会进行这个排序的操作 //最小的结点可以获取锁 hasTheLock = this.internalLockLoop(startMillis, millisToWait, ourPath); } catch (NoNodeException var14) { if (!this.client.getZookeeperClient().getRetryPolicy().allowRetry(retryCount++, System.currentTimeMillis() - startMillis, RetryLoop.getDefaultRetrySleeper())) { throw var14; } isDone = false; } } return hasTheLock ? ourPath : null;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
createsTheLock,创建锁的方式如下
public String createsTheLock(CuratorFramework client, String path, byte[] lockNodeBytes) throws Exception {
String ourPath;
if (lockNodeBytes != null) {
//通过容器结点实现,如果没有容器结点,则创建容器结点
//如果有容器结点,那么就在容器节点中创建这个临时的顺序结点
ourPath = (String)((ACLBackgroundPathAndBytesable)client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL)).forPath(path, lockNodeBytes);
} else {
//临时的顺序节点
ourPath = (String)((ACLBackgroundPathAndBytesable)client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL)).forPath(path);
}
return ourPath;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
internalLockLoop里面的方法如下,主要是用来判断当前节点是否最小结点,即使这个结点是一个有序的临时顺序结点,但是由于是需要通过网络获取,因此需要重新进行排序,从而判断当前结点是不是最小结点,如果不是,就会根据排好的顺序,放入到指定的位置,从而监听上一个临时顺序结点。
while(this.client.getState() == CuratorFrameworkState.STARTED && !haveTheLock) { //获取全部的这个子结点 List<String> children = this.getSortedChildren(); String sequenceNodeName = ourPath.substring(this.basePath.length() + 1); PredicateResults predicateResults = this.driver.getsTheLock(this.client, children, sequenceNodeName, this.maxLeases); if (predicateResults.getsTheLock()) { haveTheLock = true; } else { String previousSequencePath = this.basePath + "/" + predicateResults.getPathToWatch(); synchronized(this) { try { ((BackgroundPathable)this.client.getData().usingWatcher(this.watcher)).forPath(previousSequencePath); if (millisToWait == null) { this.wait(); } else { millisToWait = millisToWait - (System.currentTimeMillis() - startMillis); startMillis = System.currentTimeMillis(); if (millisToWait > 0L) { this.wait(millisToWait); } else { doDelete = true; break; } } } catch (NoNodeException var19) { ; } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
3,redis和zookeeper分布锁的区别
redis在使用主从复制时,master主节点挂掉之后,slave故障转移时生成master,会有可能造成因为原master挂掉的数据故障丢失的情况。同时redis使用rdb和aof两种方式做持久化,如果出现宕机的情况也可能会造成数据的丢失问题。在设计方面,只需要保证主节点中有数据就行,通过主从复制的方式来保证这个结点数据的一致性,并且主从复制是异步的,也就是说往master主节点中写入数据和slaver去同步这个master结点中的数据是异步的,两个步骤是各位各的,由于这种异步也会造成这个数据丢失的问题。因此更多保证的是这个ap协议,即保证了这个redis分布式锁的高可用
zookeeper使用的是leader-follower模式,需要多个结点同时写成功才算成功,因此可以保证多个结点里面都会有相同的数据,follower结点会及时的去同步主节点中的数据。因此在保障这个多个结点数据的一致性能,因此这个zookeeper更多的是保证这个cp协议,一致性。主从的一致性主要是通过ZAB(ZooKeeper Atomic Broadcast)协议实现的,即ZooKeeper原子播送协议。
4,zookeeper其他业务场景
如果只有读的情况,是不需要所有的结点都进行加锁的。
如果有读有些的话,可能遇到的问题:
1,读写并发不一致
2,读写不一致,即网络产生的延迟问题,在写完数据库之后,更新缓存出现网络问题,被别的线程修改该数据并更新缓存。
解决方案
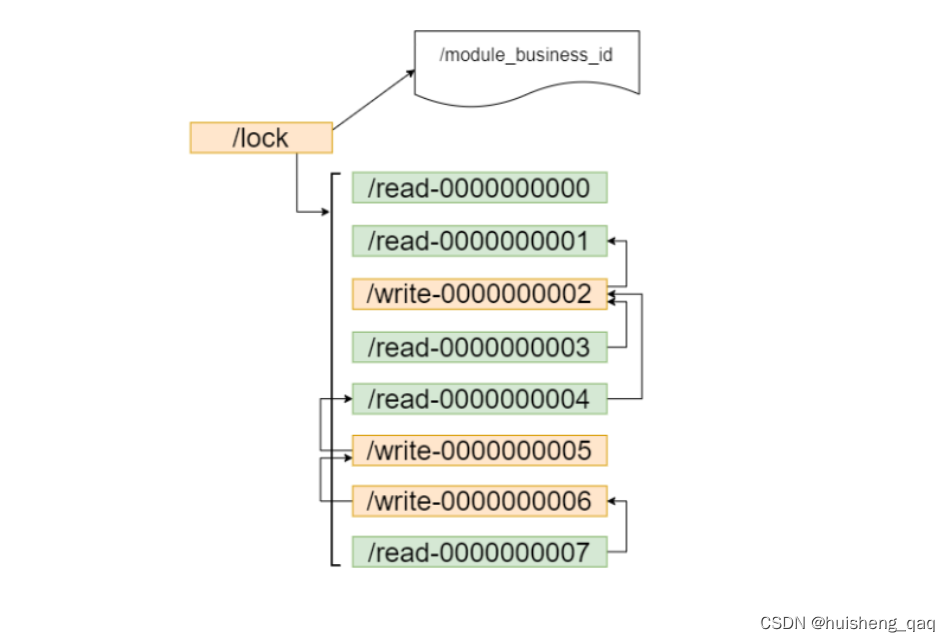
1,通过共享锁实现,即读写锁实现。如果前面的结点是读锁,则直接获取锁,如果当前结点是一个写锁,则不能直接获取锁,需要对前面的结点进行监听的操作。
2,write写操作,和这个互斥锁的原理一样,需要对前面的结点进行这个监听操作。
5,总结
5.1,分布式锁原理总结
主要是利用zookeeper的临时顺序结点的特性,从而保障这个锁的公平性,从而解决并发上锁竞争的问题,并且结合这个watch监听的机制,后一个结点结点监听前一个结点,解决了zookeeper分布式锁的羊群效应,所谓羊群效应就是说,当一个节点挂掉后,所有结点都去监听,然后做出反应,这样会给服务器带来巨大压力。有了临时顺序节点以及节点监听机制,当一个节点挂掉,只有它后面的那一个节点才做出反应。并且通过这个ZAB协议,保证数据的一致性。
5.2,zookeeper分布式锁底层流程总结
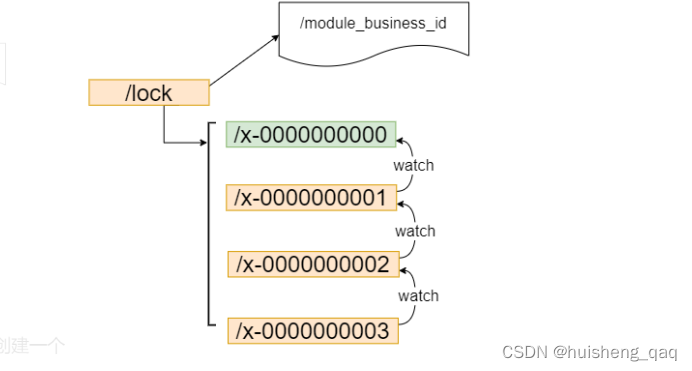
通过上面的源码分析可知,首先会去新建一个container的容器结点,也可以创建一个持久化结点,如对面的 /lock,接下来创建这个顺序的临时结点,大小长度为10位。创建一个结点之后,内部会做一个排序,判断当前节点是不是最小结点,如果当前结点是最小结点,那么当前结点就可以获取到锁,如果不是最小结点,就会根据这个临时顺序结点的特性,将此结点加入到最后面进行排队,并且监听前面一个结点。一旦前面这个结点有了释放锁的消息,那么么当前结点就可以去获取锁了,获取锁之后,就开始处理具体的业务流程,处理完业务流程之后,再去释放锁。

