
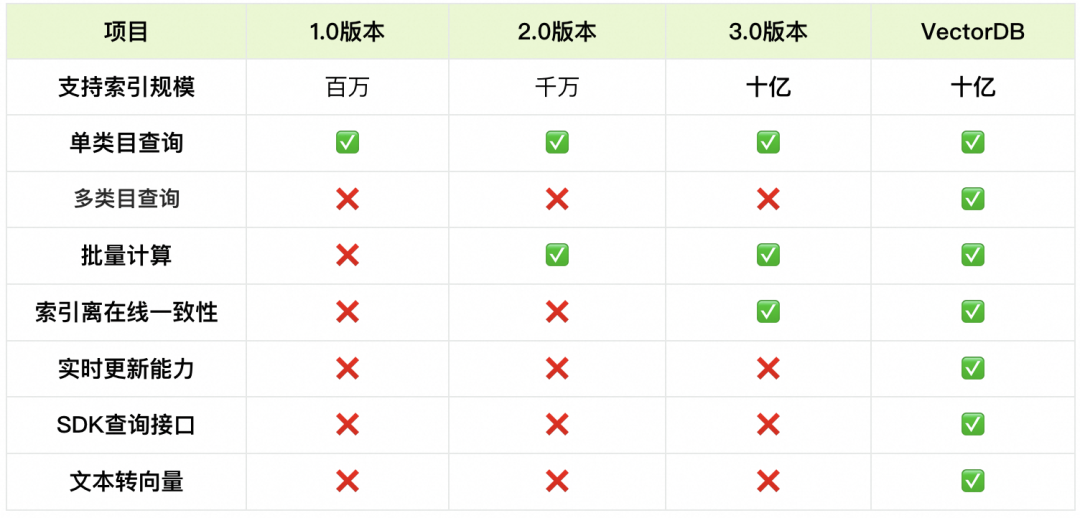
- 1设置rules属性改变后不立即出发校验_vue watch 晚于 rules 触发
- 2共享内存bug
- 3配置Manjaro Linux_archlinux卸载wps
- 4AI 大模型_ai大模型学习
- 5Linux基础开发工具(yum、vim、gcc/g++、Makefile、gdb、git)_linux yum gcc
- 6Android 点亮屏幕_mainactivity.this.wakeupscreen(10000l);
- 7二分查找最大比较次数
- 8Flink入门和学习总结
- 9FlinkSQL-- sql-client及源码解析 -- flink-1.13.6_如何代码实现sql-client m -f 这样的命令
- 10ROS系列:七、熟练使用rviz_rviz是ros自带的吗?
AI生成存储基座:自研超大规模向量数据库 Dolphin VectorDB
赞
踩
一、业务背景
随着以OpenAI为代表的AI生成式技术不断突破,在万物皆可向量化的时代直接带动向量计算和存储需求大幅提升,让向量存储和计算技术关注度达到新高,业界涌现出各类向量数据库。阿里妈妈拥有丰富的AI应用场景,我们基于过去在向量引擎的积累和AI场景下需求,在近五年时间里不断迭代升级,沉淀出Dolphin VectorDB,具有大规模、高性能、低成本且易开发的优势,在妈妈内容风控、营销知识问答、达摩盘人群AI圈人和AI经营分析师等场景中落地应用。尤其在支持内容风控10亿级超大规模向量检索场景中,使用Dolphin VectorDB表现出性能、成本及易用性综合优势,获得显著收益:
索引构建加速:索引构建时间减少71%。
检索速度更快:检索RT快3倍。
资源使用更省:服务资源节省75%。
研发效能提升:开发向量召回业务效率从天/小时提升到分钟级别。
二、行业技术调研
业界主要分为向量数据库和有向量能力的数据库两条技术路线:
向量数据库 (Specified Vector Database):提供基于SDK的RPC/HTTP调用,专门用于向量数据的构建、存储和查询。
支持向量能力的数据库:基于已有各类通用数据库系统,再结合向量库(Vector Library)实现向量数据的构建、存储和查询能力。

2.1 业界现状
业界向量数据库百花齐放,但面临复杂业务场景仍有些不足:
传统支持向量能力的数据库主要面向静态向量数据,不适用于索引数据频繁更新场景,不支持实时向量写入及更新。
向量数据库普遍支持在线计算,但没有专门针对离线批量计算场景,而真实场景同一业务会有在线和离线批量两类计算需求,很多情况下在线和离线计算不是一套服务,导致在线和离线因索引不同查询结果不一致。
现有产品在大规模、高性能和低成本这三个方面很难平衡,既能满足大规模、高性能,还能保证低成本的挑战很大。
基于当前现状,Dolphin VectorDB选择第二条技术路线(支持向量能力的数据库),基于Dolphin多年在MPP数据库方向能力积累,实现高性能向量数据库能力。
三、技术演进
Dolphin(延展阅读:Dolphin:面向营销场景的超融合多模智能引擎)自2019年开始探索向量计算,向量引擎底层计算能力经历从最初版使用Hologres内置向量插件,到基于Faiss自研2.0版,逐步迭代到3.0版基于DFS共享存储(DFS类似开源的HDFS),最后升级到现在的Dolphin VectorDB,每一次升级背后都是业务规模扩展和新功能需求,推动技术不断迭代进化。
3.1 向量引擎1.0
为支撑阿里妈妈达摩盘和直通车BP人群Lookalike业务(Lookalike是一种基于种子人群特征放大人群规模的算法技术),Dolphin向量引擎1.0版基于Hologres实现1.0版本向量计算能力(延展阅读:阿里妈妈Dolphin智能计算引擎基于Flink+Hologres实践),通过计算种子人群中心向量,然后从总体中召回Top K实现人群扩展。整个人群Lookalike扩展过程如下图所示。
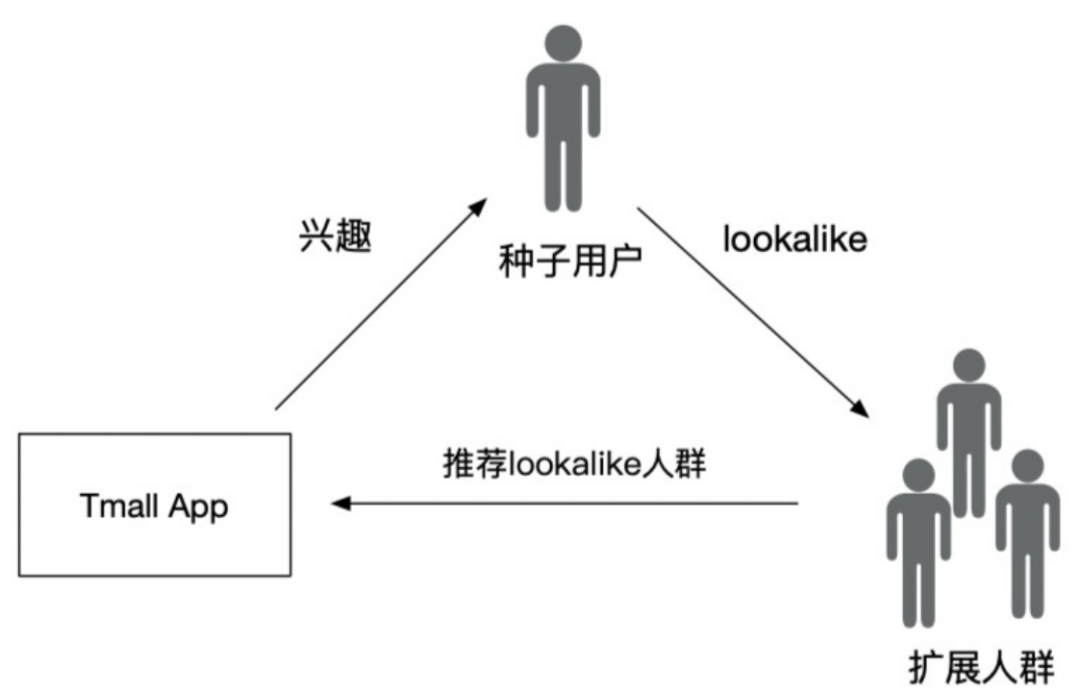
在业务支持中Dolphin初步集成基于Hologres的向量召回能力。
3.2 向量引擎2.0
在1.0版技术方案中,单shard模式有单点瓶颈,集群CPU利用率不高,多shard会构建分布式索引,但性能一般。为解决性能瓶颈,我们基于GreenPlum(下文简称“GP”)数据库和faiss自研实现2.0版(方案已开源,gpdb-faiss-vector 项目地址:https://github.com/AlibabaIncubator/gpdb-faiss-vector),延展阅读:Dolphin:面向营销场景的超融合多模智能引擎),基于UDF实现索引构建和查询能力,并采用共享缓存方案减少索引切换开销,性能上实现支持总向量百万规模,单类目几十万规模的向量召回计算。
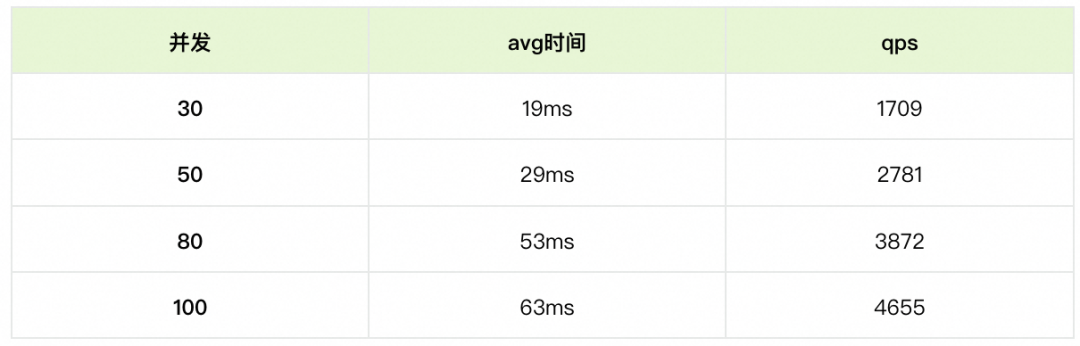
基于GP的方案,对于小规模索引我们采用复制表可大幅提升QPS;对于带类目(cate_id)的场景我们使用分布式表方案,其中对于复制表场景压测QPS(800CU资源)可以达到5000+qps。
此外还做了复制表和分布式表测试,其中复制表是把索引复制到每一个计算节点;分布式表是按cate把索引划分到不同节点,对每个cate_id构建一份索引。
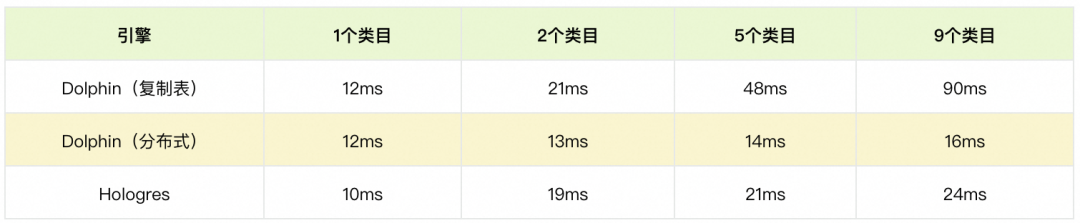
此外为支持Lazada算法千万级大规模批量向量召回需求,我们基于GP实现离线批量计算方案,虽然自研方案性能有较大提升,但是索引构建是在数据库进行,会受限于数据库存储限制,最大构建的索引限制为1G,导致更大规模的索引无法使用数据库构建,于是我们又进行新一轮升级。
3.3 向量引擎3.0
从系统架构上来看,Dolphin向量引擎2.0本质上是基于数据库的插件实现,其索引构建与召回流程完全依赖于数据库系统内核和执行器调度,存在诸多限制,比如索引大小不能超过1G的数据库字段限制,单个集群构建的索引只能自用无法共享等。
为支持构建亿级向量索引,我们设计3.0方案,在数据库segment节点实现外置独立向量服务,只依赖于数据库的数据分发与SQL化接口能力,理论上可以实现任意大小索引构建存储和查询。
从执行流程上看,通过对索引构建和向量召回的流程进行拆分,并将构建好的索引导入DFS存储,实现了一次索引构建可供在线、批量甚至多个集群读取使用,并以本地磁盘、内存实现索引多级缓存,极大提升了召回流程效率,同时也保障了在线向量召回集群不会受索引构建任务影响。
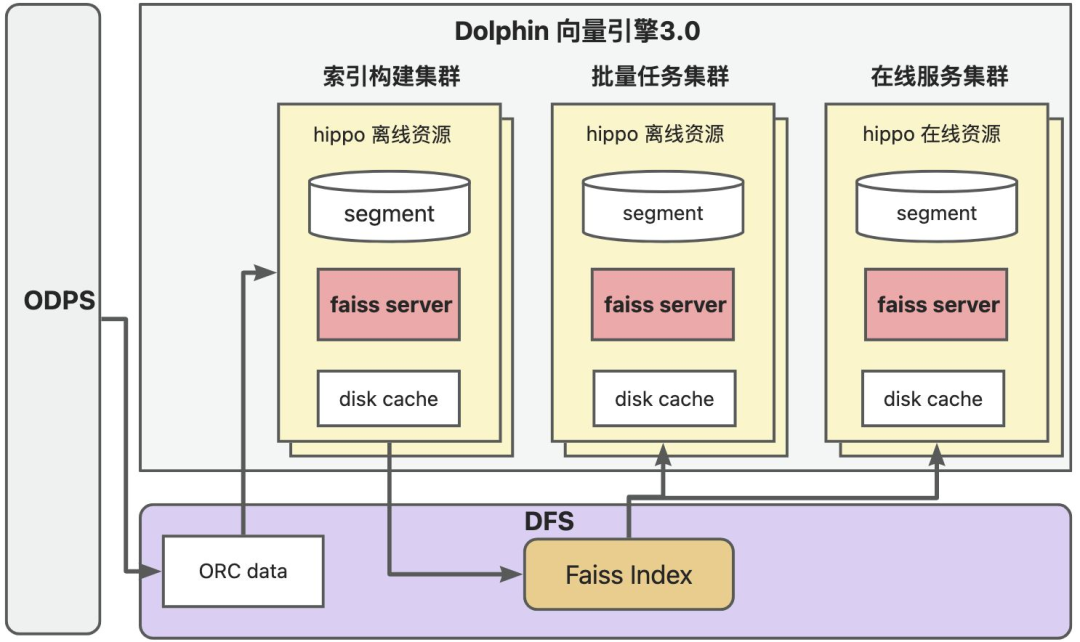
Dolphin向量引擎3.0可以很好支持超大规模向量索引构建和在离线一致性查询能力,但面对大模型实时写入更新场景还无法支持。
3.4 Dolphin VectorDB
Dolphin VectorDB源于跟内容风控团队合作共建,内容风控业务涉及图文、视频内容的安全底线,过去在很多重要风控事件中发挥重要作用,对向量召回能力要求低延迟、高吞吐、一致性和易用性。过去内容风控主要使用集团内DII、BE和Proxima CE 三套检索引擎来实现业务需求,但是仍面临巨大挑战:
低延迟:在线审核链路要求低延迟、实时增量更新黑图、文相似样本库,同时因为对广告主审核有体感,需要非常高的稳定性保障要求。
高吞吐:离线会面临百亿级别历史全量广告送审内容的高吞吐压力,例如敏感图文问题,此外还必须按照监管要求时间内完成全量图文内容清理。
一致性:在线和离线因为使用不同架构引擎导致索引召回不一致,可能有在线或离线风险外露风险。
易用性:内容风控一共20+检索业务,使用了DII、BE和Proxima 3套方案,每一种方案针对特定的问题都能很好的解决,但会出现在离线不一致和维护成本高的问题。
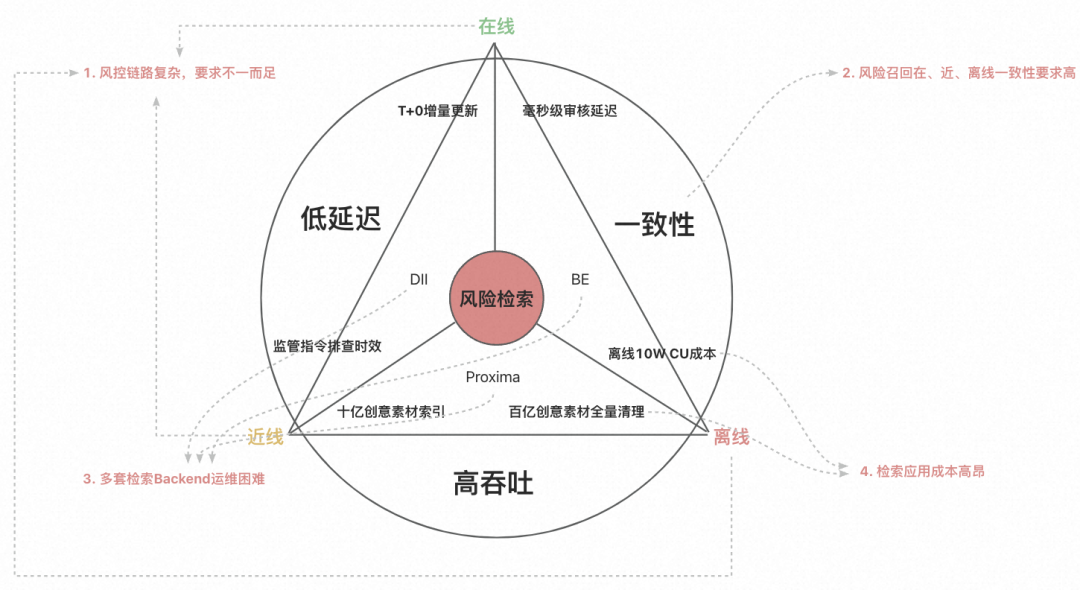
面对风控复杂的场景需求和大模型场景新需求,我们基于向量引擎3.0版本进一步升级为Dolphin VectorDB,实现体系化的数据接入、查询和索引构建等标准向量数据库能力,实现一套引擎高效支持在线和离线业务需求。
四、技术架构
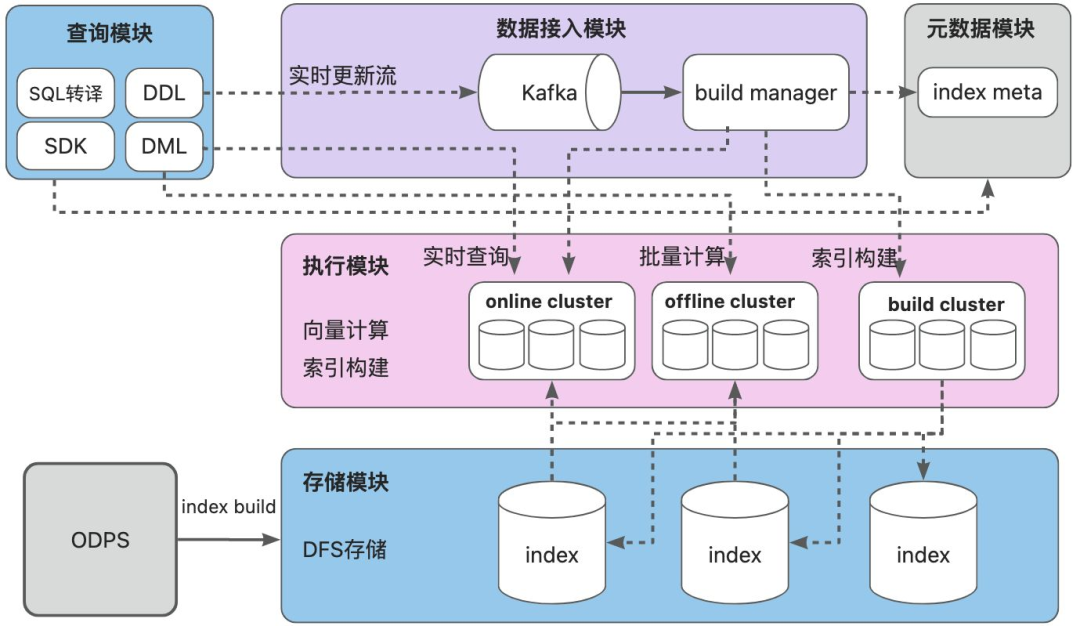
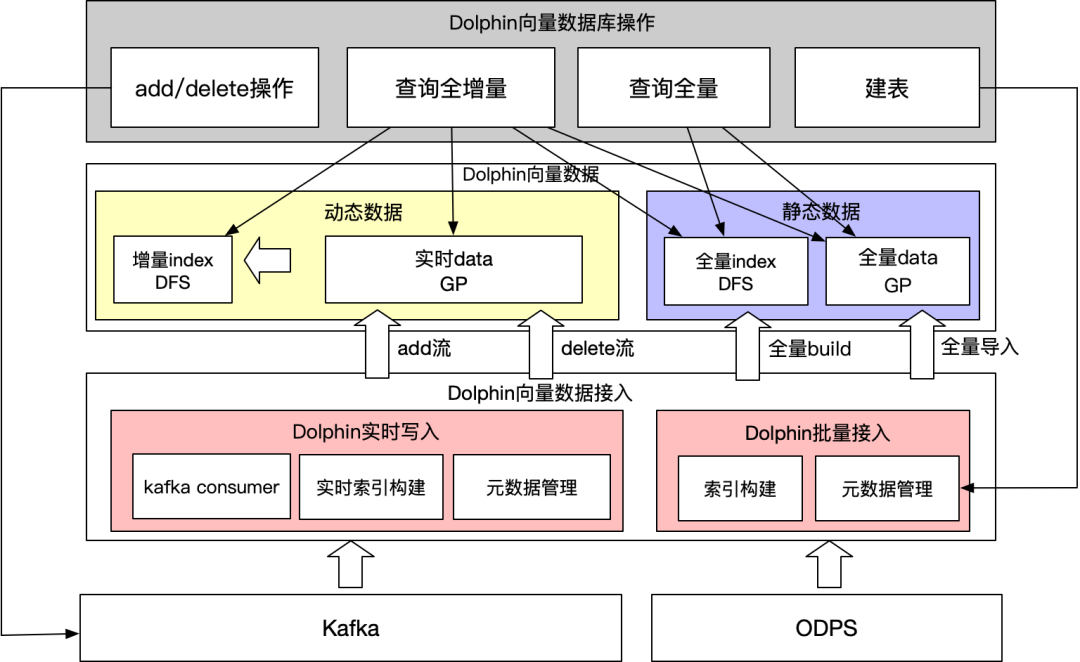
Dolphin VectorDB整体技术架构分为五个模块,包括数据接入、查询、执行、存储及元数据管理。
4.1 模块介绍
4.1.1 数据接入模块
数据接入模块是整个VectorDB的向量数据入口,负责外部实时及批量数据接入,元数据记录以及调用执行模块构建向量索引。数据接入分为两个链路:
实时链路:业务方通过SDK的请求经过消息队列Kafka,然后实时更新到在线集群向量数据表中。
离线链路:负责将odps数据表批量导入到在线集群,同时控制执行模块对向量数据使用离线集群构建索引,导入存储模块DFS提供给不同集群使用。
4.1.2 查询模块
查询模块负责接收HTTP/RPC/SDK请求,先查询元数据并对请求进行转译,再经过负载均衡路由到执行模块。
HTTP/RPC:用户输入向量查询SQL,直接转译、路由、执行
SDK:先对用户输入参数组装为查询SQL,然后走转译、路由、执行流程
4.1.3 执行模块
执行模块是与向量索引数据的计算直接相关的模块,它的基本功能包括:
接收数据接入模块索引构建请求,从存储模块读取原始的向量数据,构建向量索引文件存回远端存储
将索引加载到不同的线上任务集群
执行在线向量检索服务和离线批量向量召回任务计算。
因此执行层是沟通其他各层的桥梁,接收数据接入层和查询层的访问。
执行模块由多个负责在线、离线、索引构建任务的GP分布式数据库集群组成,每个GP集群独立负责对应的工作,互相之间共享一份向量索引。集群中的每个计算节点执行独立或分布式并行计算。计算节点由GP数据库进程和基于Faiss的向量引擎RPC服务进程构成,GP负责数据表存储、SQL执行与任务分发,与向量引擎进程沟通。而向量引擎会实际执行从与存储模块沟通的数据读写,Faiss向量索引构建,执行单条或批量的向量召回计算。
4.1.4 存储模块
负责存储原始向量数据和构建好的向量索引。
1. 负责原始向量和构建好的向量索引存储
2. 执行层需要数据可以直接从存储层读取。
4.1.5 元数据模块
负责存储索引构建的参数和表名信息,包括在线和离线场景数据,在线元数据用于查询转译使用。
五、核心能力
5.1 在离线一致性
向量召回在线场景和离线场景往往是不同引擎,即使相同参数也大概率会有召回不一致,这对很多场景其实影响不大,但对于风控这类底线安全的场景,结果不一致会导致清理不完全风险外露,过去风控场景使用BE作为在线引擎,Proxima CE作为离线计算引擎,对在离线一致性的需求非常大。Dolphin VectorDB设计索引构建存储和计算分离方案,构建好的索引存储在共享存储DFS,分别提供给在线计算服务和离线计算服务,这样实现索引一次构建多场景使用,不仅减少构建成本,还保证在离线查询结果一致。

5.2 实时更新
实时索引更新是在大模型场景和风控场景下强诉求,在线索引数据需要实时更新写入到索引库。我们基于数据库表模型特点,实现基于数据库实现的高性能实时更新能力,通过离线构建和实时写入数据两条链路,支持实时更新QPS可以达到万级别。
5.3 多模式查询
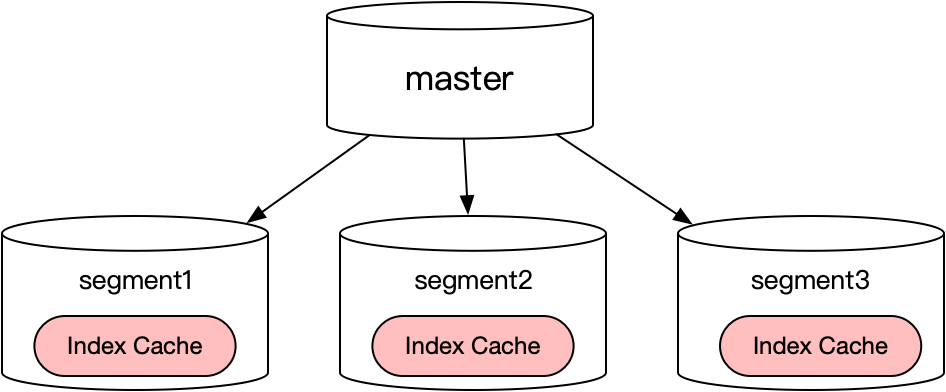
针对索引的规模大小,分为两种查询模式,一种是针对大规模索引的分布式查询;第二种是面向小规模索引的segment直查模式。

分布式查询:对于大规模向量(一般千万级以上),会把向量拆分存储到不同segment,查询的时候会从每一个segment查询top k,然后master对segment结果汇总取最终topk。
直连查询:对于小规模索引,会只构建一份索引,然后根据需求复制到多个节点,每一个节点都可以独立直接提供查询,避免master转发请求,可以显著提升集群QPS。
六、业务支撑
6.1 内容风控
内容风控业务主要包括阿里妈妈广告场景下文字、图片及视频内容的风险识别及控制,沉淀基于音视图文模型的风险识别能力,先把内容转换为向量,然后基于向量识别风险,其中很重要的是向量相似计算。
通过共建合作,Dolphin VectorDB在2023双十一期间支撑了风控场景face人脸检索、risk free等重要业务,在升级使用Dolphin VectorDB后,风控检索服务在离线一致性、服务器成本、性能和易用性有显著优化提升,其中对于10亿级超大规模向量检索业务,索引构建时间减少71%,检索RT快3倍,服务资源节省75%,开发效率从天/小时提升到分钟级别。
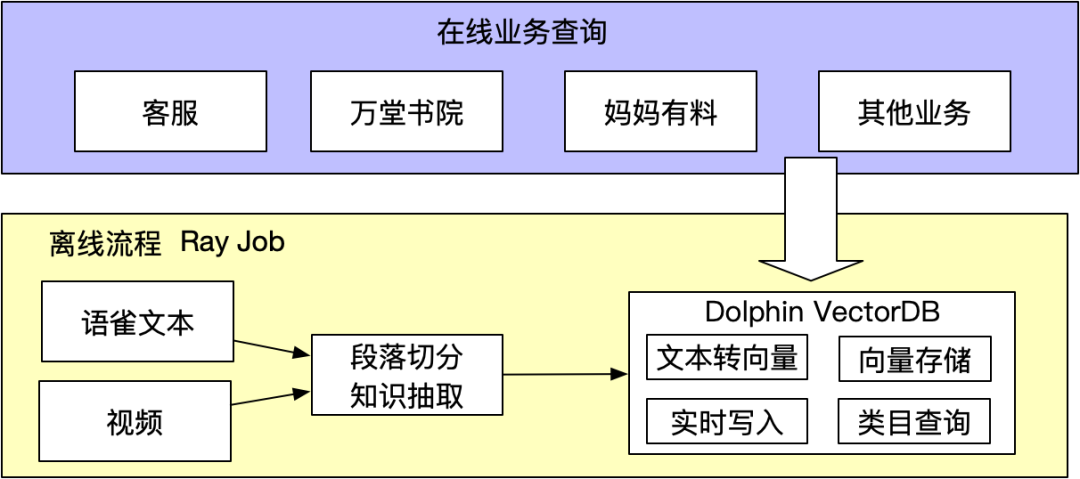
6.2 营销助手
在万堂AI讲师、妈妈有料问答助手和内部知识库通过提供营销知识问答,解决广告主对知识和答案"找得到"的诉求。我们把语雀和万堂书院等私域数据进行段落切分、知识点抽取、向量转换处理后存储在Dolphin VectorDB,然后提供在线文本向量查询,对结果使用LLM做归纳总结。
6.3 人群AI圈选
在达摩盘圈人场景,过去是广告主手动圈人,而达摩盘有上千标签数百万选项值,对几十万的中长尾客户来讲学习和使用门槛极高,而通过自然语言到人群标签组合的方式极大降低圈人成本,降低理解和使用标签组合圈人成本。在该场景下,我们会根据用户输入自然语言,通过向量召回相似标签,然后组合标签得到圈人组合。
七、未来展望
向量计算能力是生成式AI场景下必备基础能力,在搜索、推荐、广告和大模型场景下都是重要能力依赖,其能力scope决定上层业务规模和性能,未来我们主要有两个发展方向:
向量计算能力持续升级:业界对向量计算和存储能力的需求会继续提升,向量数据库在超大规模场景下的计算性能、计算成本和易用性方面仍有较大发展空间,未来可拓展到百亿规模计算。
多模计算能力融合:向量计算只是场景需求中的一个环节,真实场景中向量计算会跟很多其他计算结合,Dolphin本身定位多模态融合引擎,未来会由点到面,解决多模态复杂计算中的性能问题。
▐ 阿里妈妈数据引擎团队-系列内容
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

