
前言
这是 数据结构和算法面试题系列的下半部分,这部分主要是算法类 包括二分查找、排序算法、递归算法、随机算法、背包问题、数字问题等算法相关内容。本系列完整代码在 github 建了个仓库,所有代码都重新整理和做了一些基本的测试,代码仓库地址在这里: shishujuan/dsalg: 数据结构与算法系列汇总,如有错误,请在文章下面评论指出或者在 github 给我留言,我好及时改正以免误导其他朋友。
文章末尾有系列目录,可以按需取阅,如果需要测试,亦可以将仓库代码 clone 下来进行各种测试。如有错误或者引用不全、有侵权的地方,请大家给我指出,我好及时调整改正。如果本系列有帮助到你,也欢迎点赞或者在 github 上 star✨✨,十分感谢。
数据结构和算法面试题系列—二分查找算法详解
0.概述
二分查找本身是个简单的算法,但是正是因为其简单,更容易写错。甚至于在二分查找算法刚出现的时候,也是存在 bug 的(溢出的 bug),这个 bug 直到几十年后才修复(见《编程珠玑》)。本文打算对二分查找算法进行总结,并对由二分查找引申出来的问题进行分析和汇总。若有错误,请指正。本文完整代码在 这里 。
1.二分查找基础
相信大家都知道二分查找的基本算法,如下所示,这就是二分查找算法代码:
- /**
- * 基本二分查找算法
- */
- int binarySearch(int a[], int n, int t)
- {
- int l = 0, u = n - 1;
- while (l <= u) {
- int m = l + (u - l) / 2; // 同(l+u)/ 2,这里是为了溢出
- if (t > a[m])
- l = m + 1;
- else if (t < a[m])
- u = m - 1;
- else
- return m;
- }
- return -(l+1);
- }
- 复制代码
算法的思想就是:从数组中间开始,每次排除一半的数据,时间复杂度为 O(lgN)。这依赖于数组有序这个性质。如果 t 存在数组中,则返回t在数组的位置;否则,不存在则返回 -(l+1)。
这里需要解释下为什么 t 不存在数组中时不是返回 -1 而要返回 -(l+1)。首先我们可以观察 l 的值,如果查找不成功,则 l 的值恰好是 t 应该在数组中插入的位置。
举个例子,假定有序数组 a={1, 3, 4, 7, 8}, 那么如果t = 0,则显然t不在数组中,则二分查找算法最终会使得l = 0 > u=-1退出循环;如果 t = 9,则 t 也不在数组中,则最后 l = 5 > u = 4 退出循环。如果 t=5,则最后l=3 > u=2退出循环。因此在一些算法中,比如DHT(一致性哈希)中,就需要这个返回值来使得新加入的节点可以插入到合适的位置中,在求最长递增子序列的 NlgN 算法中,也用到了这一点,参见博文最长递增子序列算法。
还有一个小点就是之所以返回 -(l+1) 而不是直接返回 -l 是因为 l 可能为 0,如果直接返回 -l 就无法判断是正常返回位置 0 还是查找不成功返回的 0。
2.查找有序数组中数字第一次出现位置
现在考虑一个稍微复杂点的问题,如果有序数组中有重复数字,比如数组 a={1, 2, 3, 3, 5, 7, 8},需要在其中找出 3 第一次出现的位置。这里3第一次出现位置为 2。这个问题在《编程珠玑》第九章有很好的分析,这里就直接用了。算法的精髓在于循环不变式的巧妙设计,代码如下:
- /**
- * 二分查找第一次出现位置
- */
- int binarySearchFirst(int a[], int n, int t)
- {
- int l = -1, u = n;
- while (l + 1 != u) {
- /*循环不变式a[l]<t<=a[u] && l<u*/
- int m = l + (u - l) / 2; //同(l+u)/ 2
- if (t > a[m])
- l = m;
- else
- u = m;
- }
- /*assert: l+1=u && a[l]<t<=a[u]*/
- int p = u;
- if (p>=n || a[p]!=t)
- p = -1;
- return p;
- }
- 复制代码
算法分析:设定两个不存在的元素 a[-1]和 a[n],使得 a[-1] < t <= a[n],但是我们并不会去访问者两个元素,因为(l+u)/2 > l=-1, (l+u)/2 < u=n。循环不变式为l<u && t>a[l] && t<=a[u] 。循环退出时必然有 l+1=u, 而且 a[l] < t <= a[u]。循环退出后u的值为t可能出现的位置,其范围为[0, n],如果 t 在数组中,则第一个出现的位置 p=u,如果不在,则设置 p=-1返回。该算法的效率虽然解决了更为复杂的问题,但是其效率比初始版本的二分查找还要高,因为它在每次循环中只需要比较一次,前一程序则通常需要比较两次。
举个例子:对于数组 a={1, 2, 3, 3, 5, 7, 8},我们如果查找 t=3,则可以得到 p=u=2,如果查找 t=4,a[3]<t<=a[4], 所以p=u=4,判断 a[4] != t,所以设置p=-1。 一种例外情况是 u>=n, 比如t=9,则 u=7,此时也是设置 p=-1.特别注意的是,l=-1,u=n 这两个值不能写成l=0,u=n-1。虽然这两个值不会访问到,但是如果改成后面的那样,就会导致二分查找失败,那样就访问不到第一个数字。如在 a={1,2,3,4,5}中查找 1,如果初始设置 l=0,u=n-1,则会导致查找失败。
扩展 如果要查找数字在数组中最后出现的位置呢?其实这跟上述算法是类似的,稍微改一下上面的算法就可以了,代码如下:
- /**
- * 二分查找最后一次出现位置
- */
- int binarySearchLast(int a[], int n, int t)
- {
- int l = -1, u = n;
- while (l + 1 != u) {
- /*循环不变式, a[l] <= t < a[u]*/
- int m = l + (u - l) / 2;
- if (t >= a[m])
- l = m;
- else
- u = m;
- }
- /*assert: l+1 = u && a[l] <= t < a[u]*/
- int p = l;
- if (p<=-1 || a[p]!=t)
- p = -1;
- return p;
- }
- 复制代码
当然还有一种方法可以将查询数字第一次出现和最后一次出现的代码写在一个程序中,只需要对原始的二分查找稍微修改即可,代码如下:
- /**
- * 二分查找第一次和最后一次出现位置
- */
- int binarySearchFirstAndLast(int a[], int n, int t, int firstFlag)
- {
- int l = 0;
- int u = n - 1;
- while(l <= u) {
- int m = l + (u - l) / 2;
- if(a[m] == t) { //找到了,判断是第一次出现还是最后一次出现
- if(firstFlag) { //查询第一次出现的位置
- if(m != 0 && a[m-1] != t)
- return m;
- else if(m == 0)
- return 0;
- else
- u = m - 1;
- } else { //查询最后一次出现的位置
- if(m != n-1 && a[m+1] != t)
- return m;
- else if(m == n-1)
- return n-1;
- else
- l = m + 1;
- }
- }
- else if(a[m] < t)
- l = m + 1;
- else
- u = m - 1;
- }
-
- return -1;
- }
- 复制代码
3.旋转数组元素查找问题
题目
把一个有序数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。例如数组{3, 4, 5, 1, 2}为{1, 2, 3, 4, 5}的一个旋转。现在给出旋转后的数组和一个数,旋转了多少位不知道,要求给出一个算法,算出给出的数在该数组中的下标,如果没有找到这个数,则返回 -1。要求查找次数不能超过 n。
分析
由题目可以知道,旋转后的数组虽然整体无序了,但是其前后两部分是部分有序的。由此还是可以使用二分查找来解决该问题的。
解1:两次二分查找
首先确定数组分割点,也就是说分割点两边的数组都有序。比如例子中的数组以位置2分割,前面部分{3,4,5}有序,后半部分{1,2}有序。然后对这两部分分别使用二分查找即可。代码如下:
- /**
- * 旋转数组查找-两次二分查找
- */
- int binarySearchRotateTwice(int a[], int n, int t)
- {
- int p = findRotatePosition(a, n); //找到旋转位置
- if (p == -1)
- return binarySearchFirst(a, n, t); //如果原数组有序,则直接二分查找即可
-
- int left = binarySearchFirst(a, p+1, t); //查找左半部分
- if (left != -1)
- return left; //左半部分找到,则直接返回
-
- int right = binarySearchFirst(a+p+1, n-p-1, t); //左半部分没有找到,则查找右半部分
- if (right == -1)
- return -1;
-
- return right+p+1; //返回位置,注意要加上p+1
- }
-
- /**
- * 查找旋转位置
- */
- int findRotatePosition(int a[], int n)
- {
- int i;
- for (i = 0; i < n-1; i++) {
- if (a[i+1] < a[i])
- return i;
- }
- return -1;
- }
- 复制代码
解2:一次二分查找
二分查找算法有两个关键点:1)数组有序;2)根据当前区间的中间元素与t的大小关系,确定下次二分查找在前半段区间还是后半段区间进行。
仔细分析该问题,可以发现,每次根据 l 和 u 求出 m 后,m 左边([l, m])和右边([m, u])至少一个是有序的。a[m]分别与a[l]和a[u]比较,确定哪一段是有序的。
- 如果左边是有序的,若
t<a[m] && t>a[l], 则u=m-1;其他情况,l =m+1; - 如果右边是有序的,若
t> a[m] && t<a[u]则l=m+1;其他情况,u =m-1; 代码如下:
- /**
- * 旋转数组二分查找-一次二分查找
- */
- int binarySearchRotateOnce(int a[], int n, int t)
- {
- int l = 0, u = n-1;
- while (l <= u) {
- int m = l + (u-l) / 2;
- if (t == a[m])
- return m;
- if (a[m] >= a[l]) { //数组左半有序
- if (t >= a[l] && t < a[m])
- u = m - 1;
- else
- l = m + 1;
- } else { //数组右半段有序
- if (t > a[m] && t <= a[u])
- l = m + 1;
- else
- u = m - 1;
- }
- }
- return -1;
- }
- 复制代码
数据结构和算法面试题系列—排序算法之基础排序
0.概述
排序算法也是面试中常常提及的内容,问的最多的应该是快速排序、堆排序。这些排序算法很基础,但是如果平时不怎么写代码的话,面试的时候总会出现各种 bug。虽然思想都知道,但是就是写不出来。本文打算对各种排序算法进行一个汇总,包括插入排序、冒泡排序、选择排序、计数排序、归并排序,基数排序、桶排序、快速排序等。快速排序比较重要,会单独写一篇,而堆排序见本系列的二叉堆那篇文章即可。
需要提到的一点就是:插入排序,冒泡排序,归并排序,计数排序都是稳定的排序,而其他排序则是不稳定的。本文完整代码在 这里。
1.插入排序
插入排序是很基本的排序,特别是在数据基本有序的情况下,插入排序的性能很高,最好情况可以达到O(N),其最坏情况和平均情况时间复杂度都是 O(N^2)。代码如下:
- /**
- * 插入排序
- */
- void insertSort(int a[], int n)
- {
- int i, j;
- for (i = 1; i < n; i++) {
- /*
- * 循环不变式:a[0...i-1]有序。每次迭代开始前,a[0...i-1]有序,
- * 循环结束后i=n,a[0...n-1]有序
- * */
- int key = a[i];
- for (j = i; j > 0 && a[j-1] > key; j--) {
- a[j] = a[j-1];
- }
- a[j] = key;
- }
- }
- 复制代码
2.希尔排序
希尔排序内部调用插入排序来实现,通过对 N/2,N/4...1阶分别排序,最后得到整体的有序。
- /**
- * 希尔排序
- */
- void shellSort(int a[], int n)
- {
- int gap;
- for (gap = n/2; gap > 0; gap /= 2) {
- int i;
- for (i = gap; i < n; i++) {
- int key = a[i], j;
- for (j = i; j >= gap && key < a[j-gap]; j -= gap) {
- a[j] = a[j-gap];
- }
- a[j] = key;
- }
- }
- }
- 复制代码
3.选择排序
选择排序的思想就是第 i 次选取第 i 小的元素放在位置 i。比如第 1 次就选择最小的元素放在位置 0,第 2 次选择第二小的元素放在位置 1。选择排序最好和最坏时间复杂度都为 O(N^2)。代码如下:
- /**
- * 选择排序
- */
- void selectSort(int a[], int n)
- {
- int i, j, min, tmp;
- for (i = 0; i < n-1; i++) {
- min = i;
- for (j = i+1; j < n; j++) {
- if (a[j] < a[min])
- min = j;
- }
- if (min != i)
- tmp = a[i], a[i] = a[min], a[min] = tmp; //交换a[i]和a[min]
- }
- }
- 复制代码
循环不变式:在外层循环执行前,a[0...i-1]包含 a 中最小的 i 个数,且有序。
-
初始时,
i=0,a[0...-1]为空,显然成立。 -
每次执行完成后,
a[0...i]包含a中最小的i+1个数,且有序。即第一次执行完成后,a[0...0]包含a最小的1个数,且有序。 -
循环结束后,
i=n-1,则a[0...n-2]包含a最小的n-1个数,且已经有序。所以整个数组有序。
4.冒泡排序
冒泡排序时间复杂度跟选择排序相同。其思想就是进行 n-1 趟排序,每次都是把最小的数上浮,像鱼冒泡一样。最坏情况为 O(N^2)。代码如下:
- /**
- * 冒泡排序-经典版
- */
- void bubbleSort(int a[], int n)
- {
- int i, j, tmp;
- for (i = 0; i < n; i++) {
- for (j = n-1; j >= i+1; j--) {
- if (a[j] < a[j-1])
- tmp = a[j], a[j] = a[j-1], a[j-1] = tmp;
- }
- }
- }
- 复制代码
循环不变式:在循环开始迭代前,子数组 a[0...i-1] 包含了数组 a[0..n-1] 的 i-1 个最小值,且是排好序的。
对冒泡排序的一个改进就是在每趟排序时判断是否发生交换,如果一次交换都没有发生,则数组已经有序,可以不用继续剩下的趟数直接退出。改进后代码如下:
- /**
- * 冒泡排序-优化版
- */
- void betterBubbleSort(int a[], int n)
- {
- int tmp, i, j;
- for (i = 0; i < n; i++) {
- int sorted = 1;
- for (j = n-1; j >= i+1; j--) {
- if (a[j] < a[j-1]) {
- tmp = a[j], a[j] = a[j-1], a[j-1] = tmp;
- sorted = 0;
- }
- }
- if (sorted)
- return ;
- }
- }
- 复制代码
5.计数排序
假定数组为 a[0...n-1] ,数组中存在重复数字,数组中最大数字为k,建立两个辅助数组 b[] 和 c[],b[] 用于存储排序后的结果,c[] 用于存储临时值。时间复杂度为 O(N),适用于数字范围较小的数组。
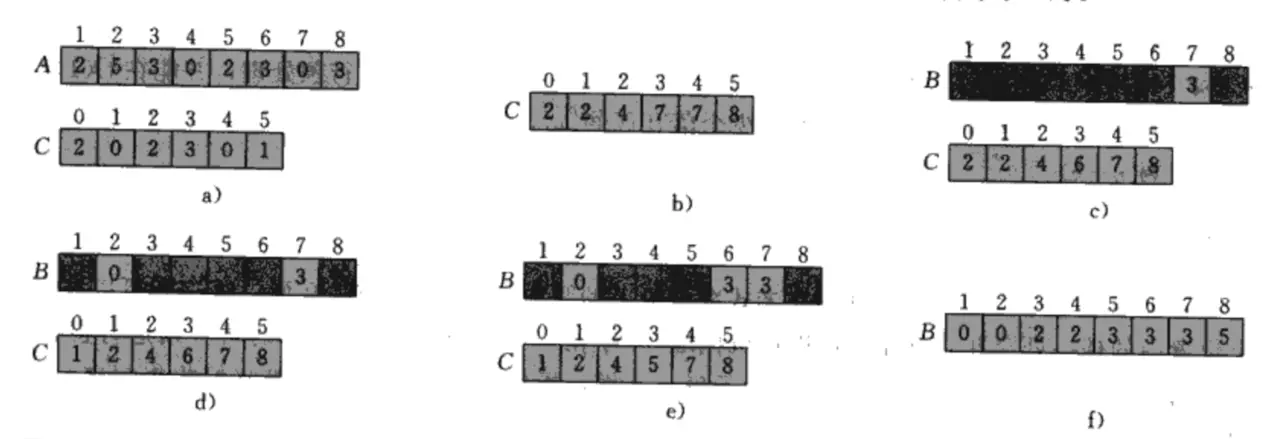
计数排序原理如上图所示,代码如下:
- /**
- * 计数排序
- */
- void countingSort(int a[], int n)
- {
- int i, j;
- int *b = (int *)malloc(sizeof(int) * n);
- int k = maxOfIntArray(a, n); // 求数组最大元素
- int *c = (int *)malloc(sizeof(int) * (k+1)); //辅助数组
-
- for (i = 0; i <= k; i++)
- c[i] = 0;
-
- for (j = 0; j < n; j++)
- c[a[j]] = c[a[j]] + 1; //c[i]包含等于i的元素个数
-
- for (i = 1; i <= k; i++)
- c[i] = c[i] + c[i-1]; //c[i]包含小于等于i的元素个数
-
- for (j = n-1; j >= 0; j--) { // 赋值语句
- b[c[a[j]]-1] = a[j]; //结果存在b[0...n-1]中
- c[a[j]] = c[a[j]] - 1;
- }
-
- /*方便测试代码,这一步赋值不是必须的*/
- for (i = 0; i < n; i++) {
- a[i] = b[i];
- }
-
- free(b);
- free(c);
- }
- 复制代码
扩展: 如果代码中的给数组 b[] 赋值语句 for (j=n-1; j>=0; j--) 改为 for(j=0; j<=n-1; j++),该代码仍然正确,只是排序不再稳定。
6.归并排序
归并排序通过分治算法,先排序好两个子数组,然后将两个子数组归并。时间复杂度为 O(NlgN)。代码如下:
- /*
- * 归并排序-递归
- * */
- void mergeSort(int a[], int l, int u)
- {
- if (l < u) {
- int m = l + (u-l)/2;
- mergeSort(a, l, m);
- mergeSort(a, m + 1, u);
- merge(a, l, m, u);
- }
- }
-
- /**
- * 归并排序合并函数
- */
- void merge(int a[], int l, int m, int u)
- {
- int n1 = m - l + 1;
- int n2 = u - m;
-
- int left[n1], right[n2];
- int i, j;
- for (i = 0; i < n1; i++) /* left holds a[l..m] */
- left[i] = a[l + i];
-
- for (j = 0; j < n2; j++) /* right holds a[m+1..u] */
- right[j] = a[m + 1 + j];
-
- i = j = 0;
- int k = l;
- while (i < n1 && j < n2) {
- if (left[i] < right[j])
- a[k++] = left[i++];
- else
- a[k++] = right[j++];
- }
- while (i < n1) /* left[] is not exhausted */
- a[k++] = left[i++];
- while (j < n2) /* right[] is not exhausted */
- a[k++] = right[j++];
- }
- 复制代码
扩展:归并排序的非递归实现怎么做?
归并排序的非递归实现其实是最自然的方式,先两两合并,而后再四四合并等,就是从底向上的一个过程。代码如下:
- /**
- * 归并排序-非递归
- */
- void mergeSortIter(int a[], int n)
- {
- int i, s=2;
- while (s <= n) {
- i = 0;
- while (i+s <= n){
- merge(a, i, i+s/2-1, i+s-1);
- i += s;
- }
-
- //处理末尾残余部分
- merge(a, i, i+s/2-1, n-1);
- s*=2;
- }
- //最后再从头到尾处理一遍
- merge(a, 0, s/2-1, n-1);
- }
- 复制代码
7.基数排序、桶排序
基数排序的思想是对数字每一位分别排序(注意这里必须是稳定排序,比如计数排序等,否则会导致结果错误),最后得到整体排序。假定对 N 个数字进行排序,如果数字有 d 位,每一位可能的最大值为 K,则每一位的稳定排序需要 O(N+K) 时间,总的需要 O(d(N+K)) 时间,当 d 为常数,K=O(N) 时,总的时间复杂度为O(N)。
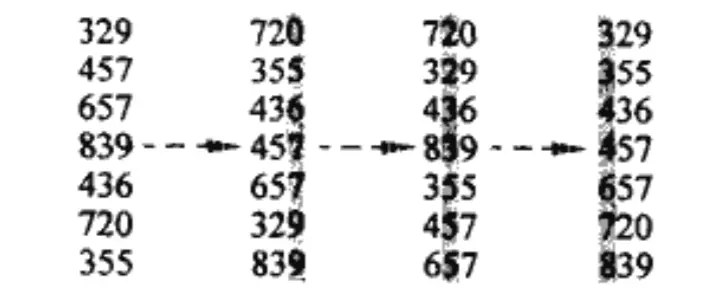
而桶排序则是在输入符合均匀分布时,可以以线性时间运行,桶排序的思想是把区间 [0,1) 划分成 N 个相同大小的子区间,将 N 个输入均匀分布到各个桶中,然后对各个桶的链表使用插入排序,最终依次列出所有桶的元素。
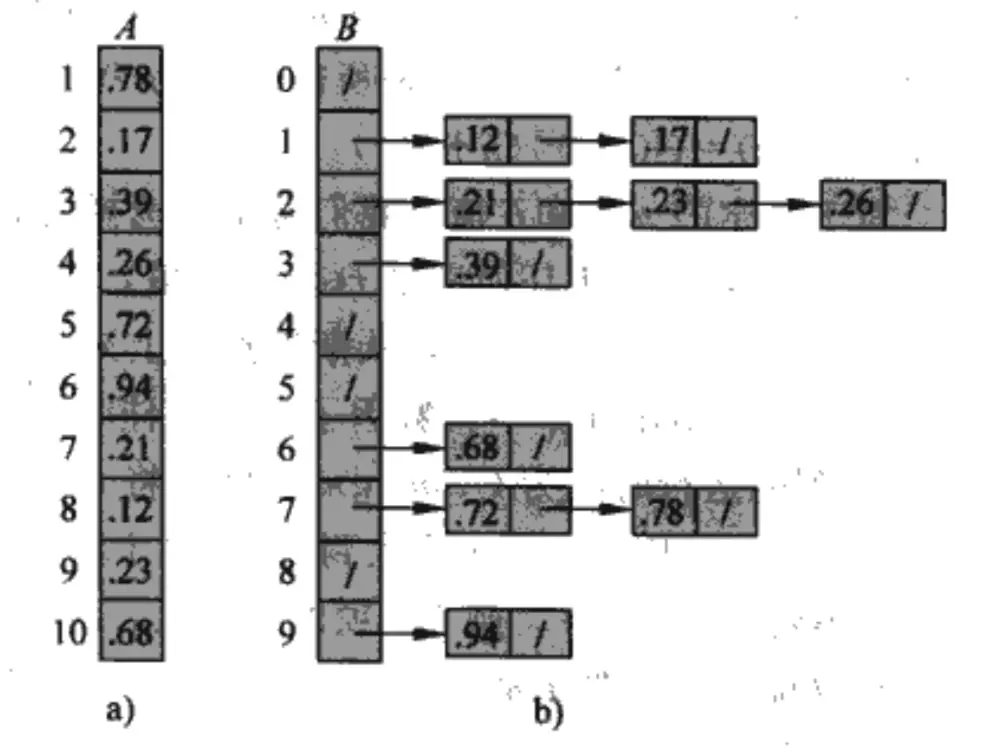
这两种排序使用场景有限,代码就略过了,更详细可以参考《算法导论》的第8章。
数据结构和算法面试题系列—排序算法之快速排序
0.概述
快速排序也是基于分治模式,类似归并排序那样,不同的是快速排序划分最后不需要merge。对一个数组 A[p..r] 进行快速排序分为三个步骤:
- 划分: 数组
A[p...r]被划分为两个子数组A[p...q-1]和A[q+1...r],使得A[p...q-1]中每个元素都小于等于A[q],而A[q+1...r]每个元素都大于A[q]。划分流程见下图。 - 解决: 通过递归调用快速排序,对子数组分别排序即可。
- 合并:因为两个子数组都已经排好序了,且已经有大小关系了,不需要做任何操作。

快速排序算法不算复杂的算法,但是实际写代码的时候却是最容易出错的代码,写的不对就容易死循环或者划分错误,本文代码见 这里。
1.朴素的快速排序
这个朴素的快速排序有个缺陷就是在一些极端情况如所有元素都相等时(或者元素本身有序,如 a[] = {1,2,3,4,5}等),朴素的快速算法时间复杂度为 O(N^2),而如果能够平衡划分数组则时间复杂度为 O(NlgN)。
- /**
- * 快速排序-朴素版本
- */
- void quickSort(int a[], int l, int u)
- {
- if (l >= u) return;
-
- int q = partition(a, l, u);
- quickSort(a, l, q-1);
- quickSort(a, q+1, u);
- }
-
- /**
- * 快速排序-划分函数
- */
- int partition(int a[], int l, int u)
- {
- int i, q=l;
- for (i = l+1; i <= u; i++) {
- if (a[i] < a[l])
- swapInt(a, i, ++q);
- }
- swapInt(a, l, q);
- return q;
- }
- 复制代码
2.改进-双向划分的快速排序
一种改进方法就是采用双向划分,使用两个变量 i 和 j,i 从左往右扫描,移过小元素,遇到大元素停止;j 从右往左扫描,移过大元素,遇到小元素停止。然后测试i和j是否交叉,如果交叉则停止,否则交换 i 与 j 对应的元素值。
注意,如果数组中有相同的元素,则遇到相同的元素时,我们停止扫描,并交换 i 和 j 的元素值。虽然这样交换次数增加了,但是却将所有元素相同的最坏情况由 O(N^2) 变成了差不多 O(NlgN) 的情况。比如数组 A={2,2,2,2,2}, 则使用朴素快速排序方法,每次都是划分 n 个元素为 1 个和 n-1 个,时间复杂度为 O(N^2),而使用双向划分后,第一次划分的位置是 2,基本可以平衡划分两部分。代码如下:
- /**
- * 快速排序-双向划分函数
- */
- int partitionLR(int a[], int l, int u, int pivot)
- {
- int i = l;
- int j = u+1;
- while (1) {
- do {
- i++;
- } while (a[i] < pivot && i <= u); //注意i<=u这个判断条件,不能越界。
-
- do {
- j--;
- } while (a[j] > pivot);
-
- if (i > j) break;
-
- swapInt(a, i, j);
- }
-
- // 注意这里是交换l和j,而不是l和i,因为i与j交叉后,a[i...u]都大于等于枢纽元t,
- // 而枢纽元又在最左边,所以不能与i交换。只能与j交换。
- swapInt(a, l, j);
-
- return j;
- }
-
- /**
- * 快速排序-双向划分法
- */
- void quickSortLR(int a[], int l, int u)
- {
- if (l >= u) return;
-
- int pivot = a[l];
- int q = partitionLR(a, l, u, pivot);
- quickSortLR(a, l, q-1);
- quickSortLR(a, q+1, u);
- }
- 复制代码
虽然双向划分解决了所有元素相同的问题,但是对于一个已经排好序的数组还是会达到 O(N^2) 的复杂度。此外,双向划分还要注意的一点是代码中循环的写法,如果写成 while(a[i]<t) {i++;} 等形式,则当左右划分的两个值都等于枢纽元时,会导致死循环。
3.继续改进—随机法和三数取中法取枢纽元
为了解决上述问题,可以进一步改进,通过随机选取枢纽元或三数取中方式来获取枢纽元,然后进行双向划分。三数取中指的就是从数组A[l... u]中选择左中右三个值进行排序,并使用中值作为枢纽元。如数组 A[] = {1, 3, 5, 2, 4},则我们对 A[0]、A[2]、A[4] 进行排序,选择中值 A[4](元素4) 作为枢纽元,并将其交换到 a[l] ,最后数组变成 A[] = {4 3 5 2 1},然后跟之前一样双向排序即可。
- /**
- * 随机选择枢纽元
- */
- int pivotRandom(int a[], int l, int u)
- {
- int rand = randInt(l, u);
- swapInt(a, l, rand); // 交换枢纽元到位置l
- return a[l];
- }
-
- /**
- * 三数取中选择枢纽元
- */
- int pivotMedian3(int a[], int l, int u)
- {
- int m = l + (u-l)/2;
-
- /*
- * 三数排序
- */
- if( a[l] > a[m] )
- swapInt(a, l, m);
-
- if( a[l] > a[u] )
- swapInt(a, l, u);
-
- if( a[m] > a[u] )
- swapInt(a, m, u);
-
- /* assert: a[l] <= a[m] <= a[u] */
- swapInt(a, m, l); // 交换枢纽元到位置l
-
- return a[l];
- }
- 复制代码
此外,在数据基本有序的情况下,使用插入排序可以得到很好的性能,而且在排序很小的子数组时,插入排序比快速排序更快,可以在数组比较小时选用插入排序,而大数组才用快速排序。
4.非递归写快速排序
非递归写快速排序着实比较少见,不过练练手总是好的。需要用到栈,注意压栈的顺序。代码如下:
- /**
- * 快速排序-非递归版本
- */
- void quickSortIter(int a[], int n)
- {
- Stack *stack = stackNew(n);
- int l = 0, u = n-1;
- int p = partition(a, l, u);
-
- if (p-1 > l) { //左半部分两个边界值入栈
- push(stack, p-1);
- push(stack, l);
- }
-
- if (p+1 < u) { //右半部分两个边界值入栈
- push(stack, u);
- push(stack, p+1);
- }
-
- while (!IS_EMPTY(stack)) { //栈不为空,则循环划分过程
- l = pop(stack);
- u = pop(stack);
- p = partition(a, l, u);
-
- if (p-1 > l) {
- push(stack, p-1);
- push(stack, l);
- }
-
- if (p+1 < u) {
- push(stack, u);
- push(stack, p+1);
- }
- }
- }
- 复制代码
数据结构和算法面试题系列—随机算法总结
0.概述
随机算法涉及大量概率论知识,有时候难得去仔细看推导过程,当然能够完全了解推导的过程自然是有好处的,如果不了解推导过程,至少记住结论也是必要的。本文总结最常见的一些随机算法的题目,是几年前找工作的时候写的。需要说明的是,这里用到的随机函数 randInt(a, b) 假定它能随机的产生范围 [a,b] 内的整数,即产生每个整数的概率相等(虽然在实际中并不一定能实现,不过不要太在意,这个世界很多事情都很随机)。本文代码在 这里。
1.随机排列数组
假设给定一个数组 A,它包含元素 1 到 N,我们的目标是构造这个数组的一个均匀随机排列。
一个常用的方法是为数组每个元素 A[i] 赋一个随机的优先级 P[i],然后依据优先级对数组进行排序。比如我们的数组为 A = {1, 2, 3, 4},如果选择的优先级数组为 P = {36, 3, 97, 19},那么就可以得到数列 B={2, 4, 1, 3},因为 3 的优先级最高(为97),而 2 的优先级最低(为3)。这个算法需要产生优先级数组,还需使用优先级数组对原数组排序,这里就不详细描述了,还有一种更好的方法可以得到随机排列数组。
产生随机排列数组的一个更好的方法是原地排列(in-place)给定数组,可以在 O(N) 的时间内完成。伪代码如下:
- RANDOMIZE-IN-PLACE ( A , n )
- for i ←1 to n do
- swap A[i] ↔ A[RANDOM(i , n )]
- 复制代码
如代码中所示,第 i 次迭代时,元素 A[i] 是从元素 A[i...n]中随机选取的,在第 i 次迭代后,我们就再也不会改变 A[i]。
A[i] 位于任意位置j的概率为 1/n。这个是很容易推导的,比如 A[1] 位于位置 1 的概率为 1/n,这个显然,因为 A[1] 不被1到n的元素替换的概率为 1/n,而后就不会再改变 A[1] 了。而 A[1] 位于位置 2 的概率也是 1/n,因为 A[1] 要想位于位置 2,则必须在第一次与 A[k] (k=2...n) 交换,同时第二次 A[2] 与 A[k]替换,第一次与 A[k] 交换的概率为(n-1)/n,而第二次替换概率为 1/(n-1),所以总的概率是 (n-1)/n * 1/(n-1) = 1/n。同理可以推导其他情况。
当然这个条件只能是随机排列数组的一个必要条件,也就是说,满足元素 A[i] 位于位置 j 的概率为1/n 不一定就能说明这可以产生随机排列数组。因为它可能产生的排列数目少于 n!,尽管概率相等,但是排列数目没有达到要求,算法导论上面有一个这样的反例。
算法 RANDOMIZE-IN-PLACE可以产生均匀随机排列,它的证明过程如下:
首先给出k排列的概念,所谓 k 排列就是从n个元素中选取k个元素的排列,那么它一共有 n!/(n-k)! 个 k 排列。
循环不变式:for循环第i次迭代前,对于每个可能的i-1排列,子数组A[1...i-1]包含该i-1排列的概率为 (n-i+1)! / n!。
-
初始化:在第一次迭代前,i=1,则循环不变式指的是对于每个0排列,子数组A[1...i-1]包含该0排列的概率为
(n-1+1)! / n! = 1。A[1...0]为空的数组,0排列则没有任何元素,因此A包含所有可能的0排列的概率为1。不变式成立。 -
维持:假设在第i次迭代前,数组的i-1排列出现在
A[1...i-1]的概率为(n-i+1) !/ n!,那么在第i次迭代后,数组的所有i排列出现在A[1...i]的概率为(n-i)! / n!。下面来推导这个结论:- 考虑一个特殊的 i 排列 p = {x1, x2, ... xi},它由一个 i-1 排列 p' ={x1, x2,..., xi−1} 后面跟一个 xi 构成。设定两个事件变量E1和E2:
-
E1为该算法将排列
p'放置到A[1...i-1]的事件,概率由归纳假设得知为Pr(E1) = (n-i+1)! / n!。 -
E2为在第 i 次迭代时将 xi 放入到
A[i]的事件。 因此我们得到 i 排列出现在A[1...i]的概率为Pr {E2 ∩ E1} = Pr {E2 | E1} Pr {E1}。而Pr {E2 | E1} = 1/(n − i + 1),所以Pr {E2 ∩ E1} = Pr {E2 | E1} Pr {E1}= 1 /(n − i + 1) * (n − i + 1)! / n! = (n − i )! / n!。 -
结束:结束的时候
i=n+1,因此可以得到A[1...n]是一个给定 n 排列的概率为1/n!。
C实现代码如下:
- void randomInPlace(int a[], int n)
- {
- int i;
- for (i = 0; i < n; i++) {
- int rand = randInt(i, n-1);
- swapInt(a, i, rand);
- }
- }
- 复制代码
扩展
如果上面的随机排列算法写成下面这样,是否也能产生均匀随机排列?
- PERMUTE-WITH-ALL( A , n )
- for i ←1 to n do
- swap A[i] ↔A[RANDOM(1 , n )]
- 复制代码
注意,该算法不能产生均匀随机排列。假定 n=3,则该算法可以产生 3*3*3=27 个输出,而 3 个元素只有3!=6个不同的排列,要使得这些排列出现概率等于 1/6,则必须使得每个排列出现次数 m 满足 m/27=1/6,显然,没有这样的整数符合条件。而实际上各个排列出现的概率如下,如 {1,2,3} 出现的概率为 4/27,不等于 1/6。
| 排 列 | 概 率 |
|---|---|
| <1, 2, 3> | 4/27 |
| <1, 3, 2> | 5/27 |
| <2, 1, 3> | 5/27 |
| <2, 3, 1> | 5/27 |
| <3, 1, 2> | 4/27 |
| <3, 2, 1> | 4/27 |
2.随机选取一个数字
题: 给定一个未知长度的整数流,如何随机选取一个数?(所谓随机就是保证每个数被选取的概率相等)
解1: 如果数据流不是很长,可以存在数组中,然后再从数组中随机选取。当然题目说的是未知长度,所以如果长度很大不足以保存在内存中的话,这种解法有其局限性。
解2: 如果数据流很长的话,可以这样:
- 如果数据流在第1个数字后结束,那么必选第1个数字。
- 如果数据流在第2个数字后结束,那么我们选第2个数字的概率为1/2,我们以1/2的概率用第2个数字替换前面选的随机数,得到新的随机数。
- ......
- 如果数据流在第n个数字后结束,那么我们选择第n个数字的概率为1/n,即我们以1/n的概率用第n个数字替换前面选的随机数,得到新的随机数。
一个简单的方法就是使用随机函数 f(n)=bigrand()%n,其中 bigrand() 返回很大的随机整数,当数据流到第 n 个数时,如果 f(n)==0,则替换前面的已经选的随机数,这样可以保证每个数字被选中的概率都是 1/n。如当 n=1 时,则 f(1)=0,则选择第 1 个数,当 n=2 时,则第 2 个数被选中的概率都为 1/2,以此类推,当数字长度为 n 时,第 n 个数字被选中的概率为 1/n。代码如下(注:在 Linux/MacOS 下,rand() 函数已经可以返回一个很大的随机数了,就当做bigrand()用了):
- void randomOne(int n)
- {
- int i, select = 0;
- for (i = 1; i < n; i++) {
- int rd = rand() % n;
- if (rd == 0) {
- select = i;
- }
- }
- printf("%d\n", select);
- }
- 复制代码
3.随机选取M个数字
题: 程序输入包含两个整数 m 和 n ,其中 m<n,输出是 0~n-1 范围内的 m 个随机整数的有序列表,不允许重复。从概率角度来说,我们希望得到没有重复的有序选择,其中每个选择出现的概率相等。
解1: 先考虑个简单的例子,当 m=2,n=5 时,我们需要从 0~4 这 5 个整数中等概率的选取 2 个有序的整数,且不能重复。如果采用如下条件选取:bigrand() % 5 < 2,则我们选取 0 的概率为2/5。但是我们不能采取同样的概率来选取 1,因为选取了 0 后,我们应该以 1/4 的概率来选取 1,而在没有选取 0 的情况下,我们应该以 2/4 的概率选取 1。选取的伪代码如下:
- select = m
- remaining = n
- for i = [0, n)
- if (bigrand() % remaining < select)
- print i
- select--
- remaining--
- 复制代码
只要满足条件 m<=n,则程序输出 m 个有序整数,不多不少。不会多选,因为每选择一个数,select--,这样当 select 减到 0 后就不会再选了。同时,也不会少选,因为每次都会remaining--,当 select/remaining=1 时,一定会选取一个数。每个子集被选择的概率是相等的,比如这里5选2则共有 C(5,2)=10 个子集,如 {0,1},{0,2}...等,每个子集被选中的概率都是 1/10。
更一般的推导,n选m的子集数目一共有 C(n,m) 个,考虑一个特定的 m 序列,如0...m-1,则选取它的概率为m/n * (m-1)/(n-1)*....1/(n-m+1)=1/C(n,m),可以看到概率是相等的。
Knuth 老爷爷很早就提出了这个算法,他的实现如下:
- void randomMKnuth(int n, int m)
- {
- int i;
- for (i = 0; i < n; i++) {
- if ((rand() % (n-i)) < m) {
- printf("%d ", i);
- m--;
- }
- }
- }
- 复制代码
解2: 还可以采用前面随机排列数组的思想,先对前 m 个数字进行随机排列,然后排序这 m 个数字并输出即可。代码如下:
- void randomMArray(int n, int m)
- {
- int i, j;
- int *x = (int *)malloc(sizeof(int) * n);
-
- for (i = 0; i < n; i++)
- x[i] = i;
-
- // 随机数组
- for (i = 0; i < m; i++) {
- j = randInt(i, n-1);
- swapInt(x, i, j);
- }
-
- // 对数组前 m 个元素排序
- for (i = 0; i < m; i++) {
- for (j = i+1; j>0 && x[j-1]>x[j]; j--) {
- swapInt(x, j, j-1);
- }
- }
-
- for (i = 0; i < m; i++) {
- printf("%d ", x[i]);
- }
-
- printf("\n");
- }
- 复制代码
4.rand7 生成 rand10 问题
题: 已知一个函数rand7()能够生成1-7的随机数,每个数概率相等,请给出一个函数rand10(),该函数能够生成 1-10 的随机数,每个数概率相等。
解1: 要产生 1-10 的随机数,我们要么执行 rand7() 两次,要么直接乘以一个数字来得到我们想要的范围值。如下面公式(1)和(2)。
- idx = 7 * (rand7()-1) + rand7() ---(1) 正确
- idx = 8 * rand7() - 7 ---(2) 错误
- 复制代码
上面公式 (1) 能够产生 1-49 的随机数,为什么呢?因为 rand7() 的可能的值为 1-7,两个 rand7() 则可能产生 49 种组合,且正好是 1-49 这 49 个数,每个数出现的概率为 1/49,于是我们可以将大于 40 的丢弃,然后取 (idx-1) % 10 + 1 即可。公式(2)是错误的,因为它生成的数的概率不均等,而且也无法生成49个数字。
- 1 2 3 4 5 6 7
- 1 1 2 3 4 5 6 7
- 2 8 9 10 1 2 3 4
- 3 5 6 7 8 9 10 1
- 4 2 3 4 5 6 7 8
- 5 9 10 1 2 3 4 5
- 6 6 7 8 9 10 * *
- 7 * * * * * * *
- 复制代码
该解法基于一种叫做拒绝采样的方法。主要思想是只要产生一个目标范围内的随机数,则直接返回。如果产生的随机数不在目标范围内,则丢弃该值,重新取样。由于目标范围内的数字被选中的概率相等,这样一个均匀的分布生成了。代码如下:
- int rand7ToRand10Sample() {
- int row, col, idx;
- do {
- row = rand7();
- col = rand7();
- idx = col + (row-1)*7;
- } while (idx > 40);
-
- return 1 + (idx-1) % 10;
- }
- 复制代码
由于row范围为1-7,col范围为1-7,这样idx值范围为1-49。大于40的值被丢弃,这样剩下1-40范围内的数字,通过取模返回。下面计算一下得到一个满足1-40范围的数需要进行取样的次数的期望值:
- E(# calls to rand7) = 2 * (40/49) +
- 4 * (9/49) * (40/49) +
- 6 * (9/49)2 * (40/49) +
- ...
-
- ∞
- = ∑ 2k * (9/49)k-1 * (40/49)
- k=1
-
- = (80/49) / (1 - 9/49)2
- = 2.45
- 复制代码
解2: 上面的方法大概需要 2.45 次调用 rand7 函数才能得到 1 个 1-10 范围的数,下面可以进行再度优化。对于大于 40 的数,我们不必马上丢弃,可以对 41-49 的数减去 40 可得到 1-9 的随机数,而rand7可生成 1-7 的随机数,这样可以生成 1-63 的随机数。对于 1-60 我们可以直接返回,而 61-63 则丢弃,这样需要丢弃的数只有 3 个,相比前面的 9 个,效率有所提高。而对于 61-63 的数,减去60后为 1-3,rand7 产生 1-7,这样可以再度利用产生 1-21 的数,对于 1-20 我们则直接返回,对于 21 则丢弃。这时,丢弃的数就只有1个了,优化又进一步。当然这里面对rand7的调用次数也是增加了的。代码如下,优化后的期望大概是 2.2123。
- int rand7ToRand10UtilizeSample() {
- int a, b, idx;
- while (1) {
- a = randInt(1, 7);
- b = randInt(1, 7);
- idx = b + (a-1)*7;
- if (idx <= 40)
- return 1 + (idx-1)%10;
-
- a = idx-40;
- b = randInt(1, 7);
- // get uniform dist from 1 - 63
- idx = b + (a-1)*7;
- if (idx <= 60)
- return 1 + (idx-1)%10;
-
- a = idx-60;
- b = randInt(1, 7);
- // get uniform dist from 1-21
- idx = b + (a-1)*7;
- if (idx <= 20)
- return 1 + (idx-1)%10;
- }
- }
- 复制代码
5.趣味概率题
1)称球问题
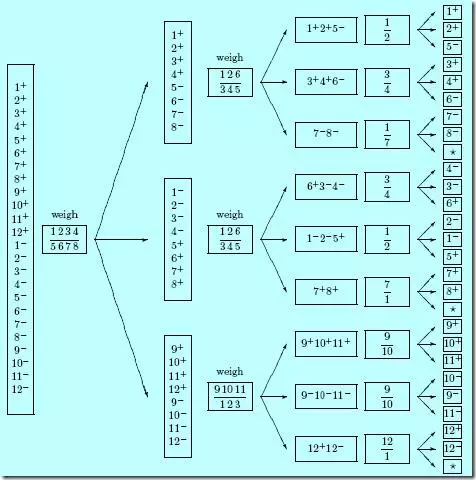
题: 有12个小球,其中一个是坏球。给你一架天平,需要你用最少的称次数来确定哪个小球是坏的,并且它到底是轻了还是重了。
解: 之前有总结过二分查找算法,我们知道二分法可以加快有序数组的查找。相似的,比如在数字游戏中,如果要你猜一个介于 1-64 之间的数字,用二分法在6次内肯定能猜出来。但是称球问题却不同。称球问题这里 12 个小球,坏球可能是其中任意一个,这就有 12 种可能性。而坏球可能是重了或者轻了这2种情况,于是这个问题一共有 12*2 = 24 种可能性。每次用天平称,天平可以输出的是 平衡、左重、右重 3 种可能性,即称一次可以将问题可能性缩小到原来的 1/3,则一共 24 种可能性可以在 3 次内称出来(3^3 = 27)。
为什么最直观的称法 6-6 不是最优的?在 6-6 称的时候,天平平衡的可能性是0,而最优策略应该是让天平每次称量时的概率均等,这样才能三等分答案的所有可能性。
具体怎么实施呢? 将球编号为1-12,采用 4, 4 称的方法。
- 我们先将
1 2 3 4和5 6 7 8进行第1次称重。 - 如果第1次平衡,则坏球肯定在
9-12号中。则此时只剩下9-124个球,可能性为9- 10- 11- 12- 9+ 10+ 11+ 12+这8种可能。接下来将9 10 11和1 2 3称第2次:如果平衡,则12号小球为坏球,将12号小球与1号小球称第3次即可确认轻还是重。如果不平衡,则如果重了说明坏球重了,继续将9和10号球称量,重的为坏球,平衡的话则11为坏球。 - 如果第1次不平衡,则坏球肯定在
1-8号中。则还剩下的可能性是1+ 2+ 3+ 4+ 5- 6- 7- 8-或者1- 2- 3- 4- 5+ 6+ 7+ 8+,如果是1 2 3 4这边重,则可以将1 2 6和3 4 5称,如果平衡,则必然是7 8轻了,再称一次7和1,便可以判断7和8哪个是坏球了。如果不平衡,假定是1 2 6这边重,则可以判断出1 2重了或者5轻了,为什么呢?因为如果是3+ 4+ 6-,则1 2 3 4比5 6 7 8重,但是1 2 6应该比3 4 5轻。其他情况同理,最多3次即可找出坏球。
下面这个图更加清晰说明了这个原理。
2)生男生女问题
题: 在重男轻女的国家里,男女的比例是多少?在一个重男轻女的国家里,每个家庭都想生男孩,如果他们生的孩子是女孩,就再生一个,直到生下的是男孩为止。这样的国家,男女比例会是多少?
解: 还是1:1。在所有出生的第一个小孩中,男女比例是1:1;在所有出生的第二个小孩中,男女比例是1:1;.... 在所有出生的第n个小孩中,男女比例还是1:1。所以总的男女比例是1:1。
3)约会问题
题: 两人相约5点到6点在某地会面,先到者等20分钟后离去,求这两人能够会面的概率。
解: 设两人分别在5点X分和5点Y分到达目的地,则他们能够会面的条件是 |X-Y| <= 20,而整个范围为 S={(x, y): 0 =< x <= 60, 0=< y <= 60},如果画出坐标轴的话,会面的情况为坐标轴中表示的面积,概率为 (60^2 - 40^2) / 60^2 = 5/9。
4)帽子问题
题: 有n位顾客,他们每个人给餐厅的服务生一顶帽子,服务生以随机的顺序归还给顾客,请问拿到自己帽子的顾客的期望数是多少?
解: 使用指示随机变量来求解这个问题会简单些。定义一个随机变量X等于能够拿到自己帽子的顾客数目,我们要计算的是 E[X]。对于 i=1, 2 ... n,定义 Xi =I {顾客i拿到自己的帽子},则 X=X1+X2+...Xn。由于归还帽子的顺序是随机的,所以每个顾客拿到自己帽子的概率为1/n,即 Pr(Xi=1)=1/n,从而 E(Xi)=1/n,所以E(X)=E(X1 + X2 + ...Xn)= E(X1)+E(X2)+...E(Xn)=n*1/n = 1,即大约有1个顾客可以拿到自己的帽子。
5)生日悖论
题: 一个房间至少要有多少人,才能使得有两个人的生日在同一天?
解: 对房间k个人中的每一对(i, j)定义指示器变量 Xij = {i与j生日在同一天} ,则i与j生日相同时,Xij=1,否则 Xij=0。两个人在同一天生日的概率 Pr(Xij=1)=1/n 。则用X表示同一天生日的两人对的数目,则 E(X)=E(∑ki=1∑kj=i+1Xij) = C(k,2)*1/n = k(k-1)/2n,令 k(k-1)/2n >=1,可得到 k>=28,即至少要有 28 个人,才能期望两个人的生日在同一天。
6)概率逆推问题
题: 如果在高速公路上30分钟内看到一辆车开过的几率是0.95,那么在10分钟内看到一辆车开过的几率是多少?(假设常概率条件下)
解: 假设10分钟内看到一辆车开过的概率是x,那么没有看到车开过的概率就是1-x,30分钟没有看到车开过的概率是 (1-x)^3,也就是 0.05。所以得到方程 (1-x)^3 = 0.05 ,解方程得到 x 大约是 0.63。
数据结构和算法面试题系列—递归算法总结
0.概述
前面总结了随机算法,这次再把以前写的递归算法的文章梳理一下,这篇文章主要是受到宋劲松老师写的《Linux C编程》的递归章节启发写的。最能体现算法精髓的非递归莫属了,希望这篇文章对初学递归或者对递归有困惑的朋友们能有所帮助,如有错误,也恳请各路大牛指正。二叉树的递归示例代码请参见仓库的 binary_tree 目录,本文其他代码在 这里。
1.递归算法初探
本段内容主要摘自《linux C一站式编程》,作者是宋劲松老师,这是我觉得目前看到的国内关于Linux C编程的最好的技术书籍之一,强烈推荐下!
关于递归的一个简单例子是求整数阶乘,n!=n*(n-1)!,0!=1 。则可以写出如下的递归程序:
- int factorial(int n)
- {
- if (n == 0)
- return 1;
- else {
- int recurse = factorial(n-1);
- int result = n * recurse;
- return result;
- }
- }
- 复制代码
factorial这个函数就是一个递归函数,它调用了它自己。自己直接或间接调用自己的函数称为递归函数。如果觉得迷惑,可以把 factorial(n-1) 这一步看成是在调用另一个函数--另一个有着相同函数名和相同代码的函数,调用它就是跳到它的代码里执行,然后再返回 factorial(n-1) 这个调用的下一步继续执行。
为了证明递归算法的正确性,我们可以一步步跟进去看执行结果。记得刚学递归算法的时候,老是有丈二和尚摸不着头脑的感觉,那时候总是想着把递归一步步跟进去看执行结果。递归层次少还算好办,但是层次一多,头就大了,完全不知道自己跟到了递归的哪一层。比如求阶乘,如果只是factorial(3)跟进去问题还不大,但是若是factorial(100)要跟进去那真的会烦死人。
事实上,我们并不是每个函数都需要跟进去看执行结果的,比如我们在自己的函数中调用printf函数时,并没有钻进去看它是怎么打印的,因为我们相信它能完成打印工作。 我们在写factorial函数时有如下代码:
- int recurse = factorial(n-1);
- int result = n * recurse;
- 复制代码
这时,如果我们相信factorial是正确的,那么传递参数为n-1它就会返回(n-1)!,那么result=n*(n-1)!=n!,从而这就是factorial(n)的结果。
当然这有点奇怪:我们还没写完factorial这个函数,凭什么要相信factorial(n-1)是正确的?如果你相信你正在写的递归函数是正确的,并调用它,然后在此基础上写完这个递归函数,那么它就会是正确的,从而值得你相信它正确。
这么说还是有点玄乎,我们从数学上严格证明一下 factorial 函数的正确性。刚才说了,factorial(n) 的正确性依赖于 factorial(n-1) 的正确性,只要后者正确,在后者的结果上乘个 n 返回这一步显然也没有疑问,那么我们的函数实现就是正确的。因此要证明factorial(n) 的正确性就是要证明 factorial(n-1) 的正确性,同理,要证明factorial(n-1) 的正确性就是要证明 factorial(n-2) 的正确性,依此类推下去,最后是:要证明 factorial(1) 的正确性就是要证明 factorial(0) 的正确性。而factorial(0) 的正确性不依赖于别的函数调用,它就是程序中的一个小的分支return 1; 这个 1 是我们根据阶乘的定义写的,肯定是正确的,因此 factorial(1) 的实现是正确的,因此 factorial(2) 也正确,依此类推,最后 factorial(n) 也是正确的。
其实这就是在中学时学的数学归纳法,用数学归纳法来证明只需要证明两点:Base Case 正确,递推关系正确。写递归函数时一定要记得写 Base Case,否则即使递推关系正确,整个函数也不正确。如果 factorial 函数漏掉了 Base Case,那么会导致无限循环。
2.递归经典问题
从上一节的一个关于求阶乘的简单例子的论述,我们可以了解到递归算法的精髓:要从功能上理解函数,同时你要相信你正在写的函数是正确的,在此基础上调用它,那么它就是正确的。 下面就从几个常见的算法题来看看如何理解递归,这是我的一些理解,欢迎大家提出更好的方法。
2.1)汉诺塔问题
题: 汉诺塔问题是个常见问题,就是说有n个大小不等的盘子放在一个塔A上面,自底向上按照从大到小的顺序排列。要求将所有n个盘子搬到另一个塔C上面,可以借助一个塔B中转,但是要满足任何时刻大盘子不能放在小盘子上面。
解: 基本思想分三步,先把上面的 N-1 个盘子经 C 移到 B,然后将最底下的盘子移到 C,再将 B 上面的N-1个盘子经 A 移动到 C。总的时间复杂度 f(n)=2f(n-1)+1,所以 f(n)=2^n-1。
- /**
- * 汉诺塔
- */
- void hano(char a, char b, char c, int n) {
- if (n <= 0) return;
-
- hano(a, c, b, n-1);
- move(a, c);
- hano(b, a, c, n-1);
- }
-
- void move(char a, char b)
- {
- printf("%c->%c\n", a, b);
- }
- 复制代码
2.2)求二叉树的深度
这里的深度指的是二叉树从根结点到叶结点最大的高度,比如只有一个结点,则深度为1,如果有N层,则高度为N。
- int depth(BTNode* root)
- {
- if (root == NULL)
- return 0;
- else {
- int lDepth = depth(root->left); //获取左子树深度
- int rDepth = depth(root->right); //获取右子树深度
- return lDepth>rDepth? lDepth+1: rDepth+1; //取较大值+1即为二叉树深度
- }
- }
- 复制代码
那么如何从功能上理解 depth 函数呢?我们可以知道定义该函数的目的就是求二叉树深度,也就是说我们要是完成了函数 depth,那么 depth(root) 就能正确返回以 root 为根结点的二叉树的深度。因此我们的代码中 depth(root->left) 返回左子树的深度,而depth(root->right) 返回右子树的深度。尽管这个时候我们还没有写完 depth 函数,但是我们相信 depth 函数能够正确完成功能。因此我们得到了 lDepth 和rDepth,而后通过比较返回较大值加1为二叉树的深度。
如果不好理解,可以想象在 depth 中调用的函数 depth(root->left) 为另外一个同样名字完成相同功能的函数,这样就好理解了。注意 Base Case,这里就是当 root==NULL 时,则深度为0,函数返回0。
2.3)判断二叉树是否平衡
一颗平衡的二叉树是指其任意结点的左右子树深度之差不大于1。判断一棵二叉树是否是平衡的,可以使用递归算法来实现。
- int isBalanceBTTop2Down(BTNode *root)
- {
- if (!root) return 1;
-
- int leftHeight = btHeight(root->left);
- int rightHeight = btHeight(root->right);
- int hDiff = abs(leftHeight - rightHeight);
-
- if (hDiff > 1) return 0;
-
- return isBalanceBTTop2Down(root->left) && isBalanceBTTop2Down(root->right);
- }
- 复制代码
该函数的功能定义是二叉树 root 是平衡二叉树,即它所有结点的左右子树深度之差不大于1。首先判断根结点是否满足条件,如果不满足,则直接返回 0。如果满足,则需要判断左子树和右子树是否都是平衡二叉树,若都是则返回1,否则0。
2.4)排列算法
排列算法也是递归的典范,记得当初第一次看时一层层跟代码,头都大了,现在从函数功能上来看确实好理解多了。先看代码:
- /**
- * 输出全排列,k为起始位置,n为数组大小
- */
- void permute(int a[], int k, int n)
- {
- if (k == n-1) {
- printIntArray(a, n); // 输出数组
- } else {
- int i;
- for (i = k; i < n; i++) {
- swapInt(a, i, k); // 交换
- permute(a, k+1, n); // 下一次排列
- swapInt(a, i, k); // 恢复原来的序列
- }
- }
- }
- 复制代码
首先明确的是 perm(a, k, n) 函数的功能:输出数组 a 从位置 k 开始的所有排列,数组长度为 n。这样我们在调用程序的时候,调用格式为 perm(a, 0, n),即输出数组从位置 0 开始的所有排列,也就是该数组的所有排列。基础条件是 k==n-1,此时已经到达最后一个元素,一次排列已经完成,直接输出。否则,从位置k开始的每个元素都与位置k的值交换(包括自己与自己交换),然后进行下一次排列,排列完成后记得恢复原来的序列。
假定数组a aan na a =3,则程序调用 perm(a, 0, 3) 可以如下理解: 第一次交换 0,0,并执行perm(a, 1, 3),执行完再次交换0,0,数组此时又恢复成初始值。 第二次交换 1,0(注意数组此时是初始值),并执行perm(a, 1, 3), 执行完再次交换1,0,数组此时又恢复成初始值。 第三次交换 2,0,并执行perm(a, 1, 3),执行完成后交换2,0,数组恢复成初始值。
也就是说,从功能上看,首先确定第0个位置,然后调用perm(a, 1, 3)输出从1开始的排列,这样就可以输出所有排列。而第0个位置可能的值为a[0], a[1],a[2],这通过交换来保证第0个位置可能出现的值,记得每次交换后要恢复初始值。
如数组 a={1,2,3},则程序运行输出结果为:1 2 3 ,1 3 2 ,2 1 3 ,2 3 1 ,3 2 1 ,3 1 2。即先输出以1为排列第一个值的排列,而后是2和3为第一个值的排列。
2.5)组合算法
组合算法也可以用递归实现,只是它的原理跟0-1背包问题类似。即要么选要么不选,注意不能选重复的数。完整代码如下:
- /*
- * 组合主函数,包括选取1到n个数字
- */
- void combination(int a[], int n)
- {
- int *select = (int *)calloc(sizeof(int), n); // select为辅助数组,用于存储选取的数
- int k;
- for (k = 1; k <= n; k++) {
- combinationUtil(a, n, 0, k, select);
- }
- }
-
- /*
- * 组合工具函数:从数组a从位置i开始选取k个数
- */
- void combinationUtil(int a[], int n, int i, int k, int *select)
- {
- if (i > n) return; //位置超出数组范围直接返回,否则非法访问会出段错误
-
- if (k == 0) { //选取完了,输出选取的数字
- int j;
- for (j = 0; j < n; j++) {
- if (select[j])
- printf("%d ", a[j]);
- }
- printf("\n");
- } else {
- select[i] = 1;
- combinationUtil(a, n, i+1, k-1, select); //第i个数字被选取,从后续i+1开始选取k-1个数
- select[i] = 0;
- combinationUtil(a, n, i+1, k, select); //第i个数字不选,则从后续i+1位置开始还要选取k个数
- }
- }
- 复制代码
2.6) 逆序打印字符串
这个比较简单,代码如下:
- void reversePrint(const char *str)
- {
- if (!*str)
- return;
-
- reversePrint(str + 1);
- putchar(*str);
- }
- 复制代码
2.7) 链表逆序
链表逆序通常我们会用迭代的方式实现,但是如果要显得特立独行一点,可以使用递归,如下,代码请见仓库的 aslist 目录。
- /**
- * 链表逆序,递归实现。
- */
- ListNode *listReverseRecursive(ListNode *head)
- {
- if (!head || !head->next) {
- return head;
- }
-
- ListNode *reversedHead = listReverseRecursive(head->next);
- head->next->next = head;
- head->next = NULL;
- return reversedHead;
- }
- 复制代码
数据结构和算法面试题系列—背包问题总结
0.概述
背包问题包括0-1背包问题、完全背包问题、部分背包问题等多种变种。其中,最简单的是部分背包问题,它可以采用贪心法来解决,而其他几种背包问题往往需要动态规划来求解。本文主要来源于《背包问题九讲》,我选择了比较简单的0-1背包问题和完全背包问题进行汇总。同时给出实现代码,如有错误,请各位大虾指正。本文代码在 这里。
1.部分背包问题
部分背包问题描述: 有 N 件物品和一个容量为 C 的背包。第 i 件物品的重量是 w[i],价值是 v[i]。求解将哪些物品装入背包可使价值总和最大。注意这里不要求把物品整个装入,可以只装入一个物品的部分。
解法: 部分背包问题常采用贪心算法来解决,先对每件物品计算其每单位重量价值 v[i]/w[i],然后从具有最大单位价值的物品开始拿,然后拿第二大价值的物品,直到装满背包。按照这种贪心策略拿到的必然是价值总和最大,这个比较简单,实现代码就略去了。
2. 0-1背包问题
0-1背包问题描述
有 N 件物品和一个容量为 C 的背包。第 i 件物品的重量是 w[i],价值是v[i]。求解将哪些物品装入背包可使价值总和最大。注意物品只能要么拿要么不拿,这也正是 0-1 的意义所在。可以把部分背包问题看作是拿金粉,而 0-1 背包问题则是拿金块,一个可分,一个不可分。
分析
这是最基础的背包问题,特点是:每种物品仅有一件,可以选择放或不放。 用子问题定义状态:即 f[i][w] 表示前 i 件物品恰放入一个容量为 c 的背包可以获得的最大价值。则其状态转移方程便是:
- f[i][c] = max{f[i-1][c], f[i-1][c-w[i]]+v[i]}
- 复制代码
这个方程非常重要,基本上所有跟背包相关的问题的方程都是由它衍生出来的。所以有必要将它详细解释一下:将前 i 件物品放入容量为 c 的背包中 这个子问题,若只考虑第i件物品的策略(放或不放),那么就可以转化为一个只牵扯前 i-1 件物品的问题。
- 如果不放第 i 件物品,那么问题就转化为
前 i-1 件物品放入容量为 v 的背包中,价值为f[i-1][c]; - 如果放第i件物品,那么问题就转化为
前 i-1 件物品放入剩下的容量为 c-w[i] 的背包中,此时能获得的最大价值就是f[i-1][c-w[i]]再加上通过放入第 i 件物品获得的价值 v[i]。
优化空间复杂度
以上方法的时间和空间复杂度均为 O(CN),其中时间复杂度应该已经不能再优化了,但空间复杂度却可以优化到 O(N)。 由于在计算 f[i][c] 的时候,我们只需要用到 f[i-1][c] 和 f[i-1][c-w[i]],所以完全可以通过一维数组保存它们的值,这里用到的小技巧就是需要从 c=C...0 开始反推,这样就能保证在求 f[c] 的时候 f[c-w[i]] 保存的是 f[i-1][c-w[i]] 的值。注意,这里不能从 c=0...C 这样顺推,因为这样会导致 f[c-w[i]] 的值是 f[i][c-w[i]] 而不是 f[i-1][c-w[i]。这里可以优化下界,其实只需要从 c=C...w[i] 即可,可以避免不需要的计算。伪代码如下所示:
- for i=0..N-1
- for c=C..w[i]
- f[c]=max{f[c],f[c-w[i]]+v[i]};
- 复制代码
最终实现代码如下:
- int knap01(int N, int C, int w[], int v[])
- {
- int *f = (int *)calloc(sizeof(int), C+1);
- int i, c;
-
- for (i = 0; i < N; i++) {
- for (c = C; c >= w[i]; c--) {
- f[c] = max(f[c], f[c-w[i]] + v[i]);
- }
- printf("%d: ", i+1);
- printIntArray(f, C+1); // 打印f数组
- }
- return f[C];
- }
- 复制代码
测试结果如下,即在背包容量为 10 的时候装第1和第2个物品(索引从0开始),总重量为 4+5=9,最大价值为 5+6=11。
- 参数:
- w = [3, 4, 5] //物品重量列表
- v = [4, 5, 6] //物品价值列表
- C = 10
-
- 结果(打印数组f,i为选择的物品索引,c为背包重量,值为背包物品价值):
-
- i/c 0 1 2 3 4 5 6 7 8 9 10
- 0: 0 0 0 4 4 4 4 4 4 4 4
- 1: 0 0 0 4 5 5 5 9 9 9 9
- 2: 0 0 0 4 5 6 6 9 10 11 11
-
- KNap01 max: 11
- 复制代码
初始化的细节问题
我们看到的求最优解的背包问题题目中,事实上有两种不太相同的问法。有的题目要求“恰好装满背包”时的最优解,有的题目则并没有要求必须把背包装满。一种区别这两种问法的实现方法是在初始化的时候有所不同。
如果是第一种问法,要求恰好装满背包,那么在初始化时除了 f[0] 为 0 其它 f[1..C] 均设为 -∞,这样就可以保证最终得到的 f[N] 是一种恰好装满背包的最优解。如果并没有要求必须把背包装满,而是只希望价格尽量大,初始化时应该将 f[0..C] 全部设为0。
为什么呢?可以这样理解:初始化的 f 数组事实上就是在没有任何物品可以放入背包时的合法状态。如果要求背包恰好装满,那么此时只有容量为 0 的背包可能被价值为 0 的东西 “恰好装满”,其它容量的背包均没有合法的解,属于未定义的状态,它们的值就都应该是 -∞ 了。如果背包并非必须被装满,那么任何容量的背包都有一个合法解“什么都不装”,这个解的价值为0,所以初始时状态的值也就全部为0了。
3.完全背包问题
问题描述
有 N 种物品和一个容量为 C 的背包,每种物品都有无限件可用。第i种物品的重量是 w[i],价值是v[i]。求解将哪些物品装入背包可使这些物品的重量总和不超过背包容量,且价值总和最大,物品不能只装部分。
基本思路
这个问题非常类似于0-1背包问题,所不同的是每种物品有无限件。也就是从每种物品的角度考虑,与它相关的策略已并非取或不取两种,而是有取0件、取1件、取2件...等很多种。如果仍然按照解01背包时的思路,令 f[i][c] 表示前 i 种物品恰放入一个容量为 c 的背包的最大权值。仍然可以按照每种物品不同的策略写出状态转移方程,像这样:
- f[i][c] = max{f[i-1][c-k*w[i]]+ k*w[i]| 0<=k*w[i]<=c }
- 复制代码
这跟0-1背包问题一样有O(CN)个状态需要求解,但求解每个状态的时间已经不是常数了,求解状态 f[i][c] 的时间是 O(c/w[i]),总的复杂度可以认为是 O(CN*Σ(c/w[i])),是比较大的。实现代码如下:
- /*
- * 完全背包问题
- */
- int knapComplete(int N, int C, int w[], int v[])
- {
- int *f = (int *)calloc(sizeof(int), C+1);
- int i, c, k;
- for (i = 0; i < N; i++) {
- for (c = C; c >= 0; c--) {
- for (k = 0; k <= c/w[i]; k++) {
- f[c] = max(f[c], f[c-k*w[i]] + k*v[i]);
- }
- }
- printf("%d: ", i+1);
- printIntArray(f, C+1);
- }
- return f[C];
- }
- 复制代码
使用与0-1背包问题相同的例子,运行程序结果如下,最大价值为 13,即选取 2个重量3,1个重量4的物品,总价值最高,为 4*2 + 5 = 13。
- i/c: 0 1 2 3 4 5 6 7 8 9 10
- 0: 0 0 0 4 4 4 8 8 8 12 12
- 1: 0 0 0 4 5 5 8 9 10 12 13
- 2: 0 0 0 4 5 6 8 9 10 12 13
-
- KNapComplete max: 13
- 复制代码
转换为0-1背包问题
既然01背包问题是最基本的背包问题,那么我们可以考虑把完全背包问题转化为01背包问题来解。最简单的想法是,考虑到第i种物品最多选 C/w[i] 件,于是可以把第 i 种物品转化为 C/w[i] 件费用及价值均不变的物品,然后求解这个01背包问题。这样完全没有改进基本思路的时间复杂度,但这毕竟给了我们将完全背包问题转化为01背包问题的思路:将一种物品拆成多件物品。
更高效的转化方法是:把第 i 种物品拆成重量为 w[i]*2^k、价值为 w[i]*2^k 的若干件物品,其中 k 满足 w[i]*2^k<=C。这是二进制的思想,因为不管最优策略选几件第 i 种物品,总可以表示成若干个 2^k 件物品的和。这样把每种物品拆成 O(log C/w[i]) 件物品,是一个很大的改进。但我们有更优的 O(CN) 的算法。
进一步优化—O(CN)解法
我们可以采用与0-1背包问题相反的顺序遍历,从而可以得到 O(CN) 的解法,伪代码如下:
- for i=0..N-1
- for c=w[i]..C
- f[c]=max{f[c],f[c-w[i]]+v[i]};
- 复制代码
这个伪代码与0-1背包伪代码只是 C 的循环次序不同而已。0-1背包之所以要按照 v=V..0的逆序来循环。这是因为要保证第i次循环中的状态 f[i][c] 是由状态 f[i-1][c-w[i]] 递推而来。换句话说,这正是为了保证每件物品只选一次,保证在考虑“选入第i件物品”这件策略时,依据的是一个绝无已经选入第i件物品的子结果 f[i-1][c-w[i]]。而现在完全背包的特点恰是每种物品可选无限件,所以在考虑“加选一件第i种物品”这种策略时,却正需要一个可能已选入第i种物品的子结果 f[i][c-w[i]],所以就可以并且必须采用 c=w[i]..C 的顺序循环。这就是这个简单的程序为何成立的道理。实现代码如下:
- /**
- * 完全背包问题-仿01背包解法
- */
- int knapCompleteLike01(int N, int C, int w[], int v[])
- {
- int *f = (int *)calloc(sizeof(int), C+1);
- int i, c;
- for (i = 0; i < N; i++) {
- for (c = w[i]; c <= C; c++) {
- f[c] = max(f[c], f[c-w[i]] + v[i]);
- }
- printf("%d: ", i+1);
- printIntArray(f, C+1);
-
- }
- return f[C];
- }
- 复制代码
数据结构和算法面试题系列—数字题总结
0.概述
数学是科学之基础,数字题往往也是被面试玩出花来。数学本身是有趣味的一门学科,前段时间有点不务正业,对数学产生了浓厚的兴趣,于是看了几本数学史论的书,也买了《几何原本》和《陶哲轩的实分析》,看了部分章节,受益良多,有兴趣的朋友可以看看。特别是几何原本,欧几里得上千年前的著作,里面的思考和证明方式真的富有启发性,老少咸宜。本文先总结下面试题中的数字题,我尽量增加了一些数学方面的证明,如有错误,也请指正。本文代码都在 这里。
1.找质数问题
题: 写一个程序,找出前N个质数。比如N为100,则找出前100个质数。
分析: 质数(或者叫素数)指在大于1的自然数中,除了1和该数自身外,无法被其他自然数整除的数,如 2,3,5...。最基本的想法就是对 1 到 N 的每个数进行判断,如果是质数则输出。一种改进的方法是不需要对 1 到 N 所有的数都进行判断,因为除了 2 外的偶数肯定不是质数,而奇数可能是质数,可能不是。然后我们可以跳过2与3的倍数,即对于 6n,6n+1, 6n+2, 6n+3, 6n+4, 6n+5,我们只需要判断 6n+1 与 6n+5 是否是质数即可。
判断某个数m是否是质数,最基本的方法就是对 2 到 m-1 之间的数整除 m,如果有一个数能够整除 m,则 m 就不是质数。判断 m 是否是质数还可以进一步改进,不需要对 2 到 m-1 之间的数全部整除 m,只需要对 2 到 根号m 之间的数整除m就可以。如用 2,3,4,5...根号m 整除 m。其实这还是有浪费,因为如果2不能整除,则2的倍数也不能整除,同理3不能整除则3的倍数也不能整除,因此可以只用2到根号m之间小于根号m的质数去除即可。
解: 预先可得2,3,5为质数,然后跳过2与3的倍数,从7开始,然后判断11,然后判断13,再是17...规律就是从5加2,然后加4,然后加2,然后再加4。如此反复即可,如下图所示,只需要判断 7,11,13,17,19,23,25,29... 这些数字。
判断是否是质数采用改进后的方案,即对2到根号m之间的数整除m来进行判断。需要注意一点,不能直接用根号m判断,因为对于某些数字,比如 121 开根号可能是 10.999999,所以最好使用乘法判断,如代码中所示。
- /**
- * 找出前N个质数, N > 3
- */
- int primeGeneration(int n)
- {
- int *prime = (int *)malloc(sizeof(int) * n);
- int gap = 2;
- int count = 3;
- int maybePrime = 5;
- int i, isPrime;
-
- /* 注意:2, 3, 5 是质数 */
- prime[0] = 2;
- prime[1] = 3;
- prime[2] = 5;
-
- while (count < n) {
- maybePrime += gap;
- gap = 6 - gap;
- isPrime = 1;
- for (i = 2; prime[i]*prime[i] <= maybePrime && isPrime; i++)
- if (maybePrime % prime[i] == 0)
- isPrime = 0;
-
- if (isPrime)
- prime[count++] = maybePrime;
- }
-
- printf("\nFirst %d Prime Numbers are :\n", count);
-
- for (i = 0; i < count; i++) {
- if (i % 10 == 0) printf("\n");
- printf("%5d", prime[i]);
- }
- printf("\n");
- return 0;
- }
- 复制代码
2.阶乘末尾含0问题
题: 给定一个整数N,那么N的阶乘N!末尾有多少个0呢?(该题取自《编程之美》)
解1: 流行的解法是,如果 N!= K10M,且K不能被10整除,则 N!末尾有 M 个0。考虑 N!可以进行质因数分解,N!= (2X) * (3Y) * (5Z)..., 则由于10 = 25,所以0的个数只与 X 和 Z 相关,每一对2和5相乘得到一个 10,所以 0 的个数 M = min(X, Z),显然 2 出现的数目比 5 要多,所以 0 的个数就是 5 出现的个数。由此可以写出如下代码:
- /**
- * N!末尾0的个数
- */
- int numOfZero(int n)
- {
- int cnt = 0, i, j;
- for (i = 1; i <= n; i++) {
- j = i;
- while (j % 5 == 0) {
- cnt++;
- j /= 5;
- }
- }
- return cnt;
- }
- 复制代码
解2: 继续分析可以改进上面的代码,为求出1到N的因式分解中有多少个5,令 Z=N/5 + N/(52) + N/(53)+... 即 N/5 表示 1 到 N 的数中 5 的倍数贡献一个 5,N/(52) 表示 52 的倍数再贡献一个 5...。举个简单的例子,比如求1到100的数因式分解中有多少个5,可以知道5的倍数有20个,25的倍数有4个,所以一共有24个5。代码如下:
- /**
- * N!末尾0的个数-优化版
- */
- int numOfZero2(int n)
- {
- int cnt = 0;
- while (n) {
- cnt += n/5;
- n /= 5;
- }
- return cnt;
- }
- 复制代码
总结: 上面的分析乏善可陈,不过需要提到的一点就是其中涉及到的一条算术基本定理,也就是 任意大于1的自然数都可以分解为质数的乘积,而且该分解方式是唯一的。 定理证明分为两个部分,存在性和唯一性。证明如下:
存在性证明
使用反证法来证明,假设存在大于1的自然数不能写成质数的乘积,把最小的那个称为n。自然数可以根据其可除性(是否能表示成两个不是自身的自然数的乘积)分成3类:质数、合数和1。
- 首先,按照定义,n大于1。
- 其次,n 不是质数,因为质数p可以写成质数乘积:p=p,这与假设不相符合。因此n只能是合数,但每个合数都可以分解成两个严格小于自身而大于1的自然数的积。设
n = a*b,a 和 b都是大于1小于n的数,由假设可知,a和b都可以分解为质数的乘积,因此n也可以分解为质数的乘积,所以这与假设矛盾。由此证明所有大于1的自然数都能分解为质数的乘积。
唯一性证明
- 当n=1的时候,确实只有一种分解。
- 假设对于自然数 n>1,存在两种因式分解: n=p1...pm = q1...qk,p1<=...<=pm, q1<=...<=qk,其中 p 和 q 都是质数,我们要证明 p1=q1,p2=q2...如果不相等,我们可以设 p1 < q1,从而 p1 小于所有的 q。由于 p1 和 q1 是质数,所以它们的最大公约数为1,由欧几里德算法可知存在整数 a 和 b 使得 a * p1 + b * q1 = 1。因此 a * p1 * q2...qk + b * q1 * q2...qk = q2...qk (等式1)。由于 q1...qk = n,因此等式1左边是 p1 的整数倍,从而等式1右边的 q2...qk 也必须是 p1 的整数倍,因此必然有 p1 = qi,i > 1。而这与前面 p1 小于所有的 q 矛盾,因此,由对称性,对 p1 > q1 这种情况可以得到类似结论,故可以证明 p1 = q1,同理可得 p2 = q2...pm=qk,由此完成唯一性的证明。
3.1-N正整数中1的数目
题: 给定一个十进制正整数N,求出从 1 到 N 的所有整数中包含 1 的个数。比如给定 N=23,则包含1的个数为13。其中个位出现1的数字有 1,11,21,共3个,十位出现1的数字有 10,11...19 共10个,所以总共包含 1 的个数为 3 + 10 = 13 个。
分析: 最自然的想法莫过于直接遍历1到N,求出每个数中包含的1的个数,然后将这些个数相加就是总的 1 的个数。需要遍历 N 个数,每次计算 1 的个数需要 O(log10N),该算法复杂度为 O(Nlog10N)。当数字N很大的时候,该算法会耗费很长的时间,应该还有更好的方法。
解: 我们可以从1位数开始分析,慢慢找寻规律。
-
当 N 为 1 位数时,对于 N>=1,1 的个数 f(N) 为1。
-
当 N 为 2 位数时,则个位上1的个数不仅与个位数有关,还和十位数字有关。
- 当 N=23 时,个位上 1 的个数有 1、11、21 共3个,十位上1的个数为 10,11...19 共10个,所以 1 的个数
f(N) = 3+10 = 13。如果 N 的个位数 >=1,则个位出现1的次数为十位数的数字加1;如果 N 的个位数为0,则个位出现 1 的次数等于十位数的数字。 - 十位数上出现1的次数类似,如果N的十位数字等于1,则十位数上出现1的次数为各位数字加1;如果N的十位数字大于1,则十位数上出现1的次数为10。
- 当 N=23 时,个位上 1 的个数有 1、11、21 共3个,十位上1的个数为 10,11...19 共10个,所以 1 的个数
-
当 N 为 3 位数时,同样分析可得1的个数。如 N=123,可得
1出现次数 = 13+20+24 = 57。 -
当 N 为 4,5...K 位数时,我们假设
N=abcde,则要计算百位上出现1的数目,则它受到三个因素影响:百位上的数字,百位以下的数字,百位以上的数字。- 如果百位上数字为0,则百位上出现1的次数为更高位数字决定。如 N=12013,则百位出现1的数字有100~199, 1000~1199, 2100~2199...11100~111999 共 1200 个,等于百位的更高位数字(12)*当前位数(100)。
- 如果百位上数字为1,则百位上出现1的次数不仅受更高位影响,还受低位影响。如12113,则百位出现1的情况共有 1200+114=1314 个,也就是高位影响的 12 * 100 + 低位影响的 113+1 = 114 个。
- 如果百位上数字为其他数字,则百位上出现1的次数仅由更高位决定。如 12213,则百位出现1的情况为 (12+1)*100=1300。
有以上分析思路,写出下面的代码。其中 low 表示低位数字,curr 表示当前考虑位的数字,high 表示高位数字。一个简单的分析,考虑数字 123,则首先考虑个位,则 curr 为 3,低位为 0,高位为 12;然后考虑十位,此时 curr 为 2,低位为 3,高位为 1。其他的数字可以以此类推,实现代码如下:
- /**
- * 1-N正整数中1的个数
- */
- int numOfOne(int n)
- {
- int factor = 1, cnt = 0; //factor为乘数因子
- int low = 0, curr = 0, high = 0;
- while (n / factor != 0) {
- low = n - n/factor * factor; //low为低位数字,curr为当前考虑位的数字,high为高位数字
- curr = n/factor % 10;
- high = n/(factor * 10);
-
- switch(curr) {
- case 0: //当前位为0的情况
- cnt += high * factor;
- break;
- case 1: //当前位为1的情况
- cnt += high * factor + low + 1;
- break;
- default: //当前位为其他数字的情况
- cnt += (high+1) * factor;
- break;
- }
- factor *= 10;
- }
- return cnt;
- }
- 复制代码
4.和为N的正整数序列
题: 输入一个正整数数N,输出所有和为N连续正整数序列。例如输入 15,由于 1+2+3+4+5=4+5+6=7+8=15,所以输出 3 个连续序列 1-5、4-6和7-8。
解1:运用数学规律
假定有 k 个连续的正整数和为 N,其中连续序列的第一个数为 x,则有 x+(x+1)+(x+2)+...+(x+k-1) = N。从而可以求得 x = (N - k*(k-1)/2) / k。当 x<=0 时,则说明已经没有正整数序列的和为 N 了,此时循环退出。初始化 k=2,表示2个连续的正整数和为 N,则可以求出 x 的值,并判断从 x 开始是否存在2个连续正整数和为 N,若不存在则 k++,继续循环。
- /**
- * 查找和为N的连续序列
- */
- int findContinuousSequence(int n)
- {
- int found = 0;
- int k = 2, x, m, i; // k为连续序列的数字的数目,x为起始的值,m用于判断是否有满足条件的值。
- while (1) {
- x = (n - k*(k-1)/2) / k; // 求出k个连续正整数和为n的起始值x
- m = (n - k*(k-1)/2) % k; // m用于判断是否有满足条件的连续正整数值
-
- if (x <= 0)
- break; // 退出条件,如果x<=0,则循环退出。
-
- if (!m) { // m为0,表示找到了连续子序列和为n。
- found = 1;
- printContinuousSequence(x, k);
- }
- k++;
- }
- return found;
- }
-
- /**
- * 打印连续子序列
- */
- void printContinuousSequence(int x, int k)
- {
- int i;
- for (i = 0; i < k; i++) {
- printf("%d ", x++);
- }
- printf("\n");
- }
- 复制代码
解2:序列结尾位置法
因为序列至少有两个数,可以先判定以数字2结束的连续序列和是否有等于 n 的,然后是以3结束的连续序列和是否有等于 n 的,...以此类推。此解法思路参考的何海涛先生的博文,代码如下:
- /**
- * 查找和为N的连续序列-序列结尾位置法
- */
- int findContinuousSequenceEndIndex(int n)
- {
- if (n < 3) return 0;
-
- int found = 0;
- int begin = 1, end = 2;
- int mid = (1 + n) / 2;
- int sum = begin + end;
-
- while (begin < mid) {
- if (sum > n) {
- sum -= begin;
- begin++;
- } else {
- if (sum == n) {
- found = 1;
- printContinuousSequence(begin, end-begin+1);
- }
-
- end++;
- sum += end;
- }
- }
-
- return found;
- }
- 复制代码
扩展: 是不是所有的正整数都能分解为连续正整数序列呢?
答案: 不是。并不是所有的正整数都能分解为连续的正整数和,如 32 就不能分解为连续正整数和。对于奇数,我们总是能写成 2k+1 的形式,因此可以分解为 [k,k+1],所以总是能分解成连续正整数序列。对于每一个偶数,均可以分解为质因数之积,即 n = 2i * 3j * 5k...,如果除了i之外,j,k...均为0,那么 n = 2i,对于这种数,其所有的因数均为偶数,是不存在连续子序列和为 n 的,因此除了2的幂之外的所有 n>=3 的正整数均可以写成一个连续的自然数之和。
5.最大连续子序列和
题: 求取数组中最大连续子序列和,例如给定数组为 A = {1, 3, -2, 4, -5}, 则最大连续子序列和为 6,即 1 + 3 +(-2)+ 4 = 6。
分析: 最大连续子序列和问题是个很老的面试题了,最佳的解法是 O(N) 复杂度,当然有些值得注意的地方。这里总结三种常见的解法,重点关注最后一种 O(N) 的解法即可。需要注意的是有些题目中的最大连续子序列和如果为负,则返回0;而本题如果是全为负数,则返回最大的负数即可。
解1: 因为最大连续子序列和只可能从数组 0 到 n-1 中某个位置开始,我们可以遍历 0 到 n-1 个位置,计算由这个位置开始的所有连续子序列和中的最大值。最终求出最大值即可。
- /**
- * 最大连续子序列和
- */
- int maxSumOfContinuousSequence(int a[], int n)
- {
- int max = a[0], i, j, sum; // 初始化最大值为第一个元素
- for (i = 0; i < n; i++) {
- sum = 0; // sum必须清零
- for (j = i; j < n; j++) { //从位置i开始计算从i开始的最大连续子序列和的大小,如果大于max,则更新max。
- sum += a[j];
- if (sum > max)
- max = sum;
- }
- }
- return max;
- }
- 复制代码
解2: 该问题还可以通过分治法来求解,最大连续子序列和要么出现在数组左半部分,要么出现在数组右半部分,要么横跨左右两半部分。因此求出这三种情况下的最大值就可以得到最大连续子序列和。
- /**
- * 最大连续子序列和-分治法
- */
- int maxSumOfContinuousSequenceSub(int a[], int l, int u)
- {
- if (l > u) return 0;
- if (l == u) return a[l];
- int m = (l + u) / 2;
-
- /*求横跨左右的最大连续子序列左半部分*/
- int lmax = a[m], lsum = 0;
- int i;
-
- for (i = m; i >= l; i--) {
- lsum += a[i];
- if (lsum > lmax)
- lmax = lsum;
- }
-
- /*求横跨左右的最大连续子序列右半部分*/
- int rmax=a[m+1], rsum = 0;
- for (i = m+1; i <= u; i++) {
- rsum += a[i];
- if (rsum > rmax)
- rmax = rsum;
- }
-
- return max3(lmax+rmax, maxSumOfContinuousSequenceSub(a, l, m),
- maxSumOfContinuousSequenceSub(a, m+1, u)); //返回三者最大值
- }
- 复制代码
解3: 还有一种更好的解法,只需要 O(N) 的时间。因为最大 连续子序列和只可能是以位置 0~n-1 中某个位置结尾。当遍历到第 i 个元素时,判断在它前面的连续子序列和是否大于0,如果大于0,则以位置 i 结尾的最大连续子序列和为元素 i 和前面的连续子序列和相加;否则,则以位置 i 结尾最大连续子序列和为a[i]。
- /**
- * 最打连续子序列和-结束位置法
- */
- int maxSumOfContinuousSequenceEndIndex(int a[], int n)
- {
- int maxSum, maxHere, i;
- maxSum = maxHere = a[0]; // 初始化最大和为a[0]
-
- for (i = 1; i < n; i++) {
- if (maxHere <= 0)
- maxHere = a[i]; // 如果前面位置最大连续子序列和小于等于0,则以当前位置i结尾的最大连续子序列和为a[i]
- else
- maxHere += a[i]; // 如果前面位置最大连续子序列和大于0,则以当前位置i结尾的最大连续子序列和为它们两者之和
-
- if (maxHere > maxSum) {
- maxSum = maxHere; //更新最大连续子序列和
- }
- }
- return maxSum;
- }
- 复制代码
6.最大连续子序列乘积
题: 给定一个整数序列(可能有正数,0和负数),求它的一个最大连续子序列乘积。比如给定数组a[] = {3, -4, -5, 6, -2},则最大连续子序列乘积为 360,即 3*(-4)*(-5)*6=360。
解: 求最大连续子序列乘积与最大连续子序列和问题有所不同,因为其中有正有负还有可能有0,可以直接利用动归来求解,考虑到可能存在负数的情况,我们用 max[i] 来表示以 a[i] 结尾的最大连续子序列的乘积值,用 min[i] 表示以 a[i] 结尾的最小的连续子序列的乘积值,那么状态转移方程为:
- max[i] = max{a[i], max[i-1]*a[i], min[i-1]*a[i]};
- min[i] = min{a[i], max[i-1]*a[i], min[i-1]*a[i]};
- 复制代码
初始状态为 max[0] = min[0] = a[0]。代码如下:
- /**
- * 最大连续子序列乘积
- */
- int maxMultipleOfContinuousSequence(int a[], int n)
- {
- int minSofar, maxSofar, max, i;
- int maxHere, minHere;
- max = minSofar = maxSofar = a[0];
-
- for(i = 1; i < n; i++){
- int maxHere = max3(maxSofar*a[i], minSofar*a[i], a[i]);
- int minHere = min3(maxSofar*a[i], minSofar*a[i], a[i]);
- maxSofar = maxHere, minSofar = minHere;
- if(max < maxSofar)
- max = maxSofar;
- }
- return max;
- }
- 复制代码
7.比特位相关
1) 判断一个正整数是否是2的整数次幂
题: 给定一个正整数 n,判断该正整数是否是 2 的整数次幂。
解1: 一个基本的解法是设定 i=1 开始,循环乘以2直到 i>=n,然后判断 i 是否等于 n 即可。
解2: 还有一个更好的方法,那就是观察数字的二进制表示,如 n=101000,则我们可以发现n-1=100111。也就是说 n -> n-1 是将 n 最右边的 1 变成了 0,同时将 n 最右边的 1 右边的所有比特位由0变成了1。因此如果 n & (n-1) == 0 就可以判定正整数 n 为 2的整数次幂。
- /**
- * 判断正整数是2的幂次
- */
- int powOf2(int n)
- {
- assert(n > 0);
- return !(n & (n-1));
- }
- 复制代码
2) 求一个整数二进制表示中1的个数
题: 求整数二进制表示中1的个数,如给定 N=6,它的二进制表示为 0110,二进制表示中1的个数为2。
解1: 一个自然的方法是将N和1按位与,然后将N除以2,直到N为0为止。该算法代码如下:
-
- int numOfBit1(int n)
- {
- int cnt = 0;
- while (n) {
- if (n & 1)
- ++cnt;
- n >>= 1;
- }
- return cnt;
- }
- 复制代码
上面的代码存在一个问题,如果输入为负数的话,会导致死循环,为了解决负数的问题,如果使用的是JAVA,可以直接使用无符号右移操作符 >>> 来解决,如果是在C/C++里面,为了避免死循环,我们可以不右移输入的数字i。首先 i & 1,判断i的最低位是不是为1。接着把1左移一位得到2,再和i做与运算,就能判断i的次高位是不是1...,这样反复左移,每次都能判断i的其中一位是不是1。
- /**
- * 二进制表示中1的个数-解法1
- */
- int numOfBit1(int n)
- {
- int cnt = 0;
- unsigned int flag = 1;
- while (flag) {
- if(n & flag)
- cnt++;
-
- flag = flag << 1;
- if (flag > n)
- break;
- }
- return cnt;
- }
- 复制代码
解2: 一个更好的解法是采用第一个题中类似的思路,每次 n&(n-1)就能把n中最右边的1变为0,所以很容易求的1的总数目。
- /**
- * 二进制表示中1的个数-解法2
- */
- int numOfBit1WithCheck(int n)
- {
- int cnt = 0;
- while (n != 0) {
- n = (n & (n-1));
- cnt++;
- }
- return cnt;
- }
- 复制代码
3) 反转一个无符号整数的所有比特位
题: 给定一个无符号整数N,反转该整数的所有比特位。例如有一个 8 位的数字 01101001,则反转后变成 10010110,32 位的无符号整数的反转与之类似。
解1: 自然的解法就是参照字符串反转的算法,假设无符号整数有n位,先将第0位和第n位交换,然后是第1位和第n-1位交换...注意一点就是交换两个位是可以通过异或操作 XOR 来实现的,因为 0 XOR 0 = 0, 1 XOR 1 = 0, 0 XOR 1 = 1, 1 XOR 0 = 1,使用 1 异或 0/1 会让其值反转。
- /**
- * 反转比特位
- */
- uint swapBits(uint x, uint i, uint j)
- {
- uint lo = ((x >> i) & 1); // 取x的第i位的值
- uint hi = ((x >> j) & 1); // 取x的第j位的值
- if (lo ^ hi) {
- x ^= ((1U << i) | (1U << j)); // 如果第i位和第j位值不同,则交换i和j这两个位的值,使用异或操作实现
- }
- return x;
- }
-
- /**
- * 反转整数比特位-仿字符串反转
- */
- uint reverseXOR(uint x)
- {
- uint n = sizeof(x) * 8;
- uint i;
- for (i = 0; i < n/2; i++) {
- x = swapBits(x, i, n-i-1);
- }
- return x;
- }
- 复制代码
解2: 采用分治策略,首先交换数字x的相邻位,然后再是 2 个位交换,然后是 4 个位交换...比如给定一个 8 位数 01101010,则首先交换相邻位,变成 10 01 01 01,然后交换相邻的 2 个位,得到 01 10 01 01,然后再是 4 个位交换,得到 0101 0110。总的时间复杂度为 O(lgN),其中 N 为整数的位数。下面给出一个反转32位整数的代码,如果整数是64位的可以以此类推。
- /**
- * 反转整数比特位-分治法
- */
- uint reverseMask(uint x)
- {
- assert(sizeof(x) == 4); // special case: only works for 4 bytes (32 bits).
- x = ((x & 0x55555555) << 1) | ((x & 0xAAAAAAAA) >> 1);
- x = ((x & 0x33333333) << 2) | ((x & 0xCCCCCCCC) >> 2);
- x = ((x & 0x0F0F0F0F) << 4) | ((x & 0xF0F0F0F0) >> 4);
- x = ((x & 0x00FF00FF) << 8) | ((x & 0xFF00FF00) >> 8);
- x = ((x & 0x0000FFFF) << 16) | ((x & 0xFFFF0000) >> 16);
- return x;
- }
- 复制代码
系列文章目录
- 0. 数据结构和算法面试题系列—C指针、数组和结构体
- 1. 数据结构和算法面试题系列—字符串
- 2. 数据结构和算法面试题系列—链表
- 3. 数据结构和算法面试题系列—栈
- 4. 数据结构和算法面试题系列—二叉堆
- 5. 数据结构和算法面试题系列—二叉树基础
- 6. 数据结构和算法面试题系列—二叉树面试题汇总
- 7. 数据结构和算法面试题系列—二分查找算法详解
- 8. 数据结构和算法面试题系列—排序算法之基础排序
- 9. 数据结构和算法面试题系列—排序算法之快速排序
- 10. 数据结构和算法面试题系列—随机算法总结
- 11. 数据结构和算法面试题系列—递归算法总结
- 12. 数据结构和算法面试题系列—背包问题总结
- 13. 数据结构和算法面试题系列—数字题总结
其他
此外,在我 简书的博客 上还整理有《docker相关技术笔记》、《MIT6.828操作系统学习笔记》、《python源码剖析笔记》等文章,请大家指正。
参考资料
- 编程珠玑第二版第九章
- 旋转数组的二分查找
- 《算法导论》
- 归并排序(递归实现+非递归实现+自然合并排序) - geeker
- 《数据结构和算法-C语言实现》
- Implement Rand10() Using Rand7() - LeetCode Articles
- 数学之美番外篇:快排为什么那样快 – 刘未鹏 | Mind Hacks
- 网上整理的google面试题
- 宋劲松老师《Linux C编程》递归章节
- 数据结构与算法-C语言实现
- 背包问题九讲
- 编程之美
- 具体数学
- 微软、Google等面试题
- Reverse Bits – LeetCode


