
- 1使用 Vue.js 和 Python 构建 DevOps 应用程序
- 2Docker安全最佳实践_docker安全端口配置
- 3数据库系统(二)数据库关系代数 | 选择 投影 笛卡尔积 自然连接 外连接等_投影选择笛卡尔积自然连接
- 4西蒙斯告诉你何为传奇人生 James Simons_吉姆 西蒙斯
- 5CSDN 博客等级获取及介绍_csdn等级升级
- 6csdn专用必杀技----谷歌浏览器插件_csdn谷歌插件
- 7导致Oracle裁员的原因有哪些?
- 8Java智能语音电销机器人 可私有化部署 自带小程序系统_java开发智能外呼机器人系统
- 9Hadoop 3.0磁盘均衡器(diskbalancer)新功能及使用介绍
- 10Mac电脑M1芯片Python环境搭建_mac m1 python 安装 依赖
spark java udf_Spark SQL 用户自定义函数UDF、用户自定义聚合函数UDAF 教程(Java踩坑教学版)...
赞
踩
在Spark中,也支持Hive中的自定义函数。自定义函数大致可以分为三种:
UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等
UDAF(User- Defined Aggregation Funcation),用户自定义聚合函数,类似在group by之后使用的sum,avg等
UDTF(User-Defined Table-Generating Functions),用户自定义生成函数,有点像stream里面的flatMap
本篇就手把手教你如何编写UDF和UDAF
先来个简单的UDF
场景:
我们有这样一个文本文件:
1^^d
2^b^d
3^c^d
4^^d
在读取数据的时候,第二列的数据如果为空,需要显示'null',不为空就直接输出它的值。定义完成后,就可以直接在SparkSQL中使用了。
代码为:
package test;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
import java.util.List;
/**
* Created by xinghailong on 2017/2/23.
*/
public class test3 {
public static void main(String[] args) {
//创建spark的运行环境
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[2]");
sparkConf.setAppName("test-udf");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
SQLContext sqlContext = new SQLContext(sc);
//注册自定义方法
sqlContext.udf().register("isNull", (String field,String defaultValue)->field==null?defaultValue:field, DataTypes.StringType);
//读取文件
JavaRDD lines = sc.textFile( "C:\\test-udf.txt" );
JavaRDD rows = lines.map(line-> RowFactory.create(line.split("\\^")));
List structFields = new ArrayList();
structFields.add(DataTypes.createStructField( "a", DataTypes.StringType, true ));
structFields.add(DataTypes.createStructField( "b", DataTypes.StringType, true ));
structFields.add(DataTypes.createStructField( "c", DataTypes.StringType, true ));
StructType structType = DataTypes.createStructType( structFields );
DataFrame test = sqlContext.createDataFrame( rows, structType);
test.registerTempTable("test");
sqlContext.sql("SELECT con_join(c,b) FROM test GROUP BY a").show();
sc.stop();
}
}
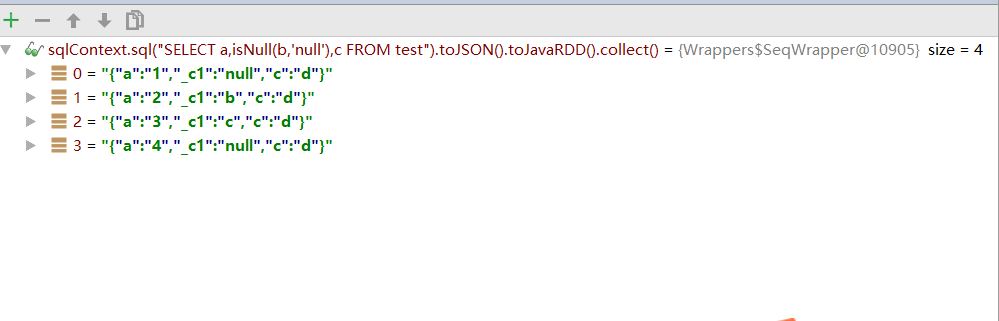
输出内容为:
+---+----+---+
| a| _c1| c|
+---+----+---+
| 1|null| d|
| 2| b| d|
| 3| c| d|
| 4|null| d|
+---+----+---+
其中比较关键的就是这句:
sqlContext.udf().register("isNull", (String field,String defaultValue)->field==null?defaultValue:field, DataTypes.StringType);
这里我直接用的java8的语法写的,如果是java8之前的版本,需要使用Function2创建匿名函数。
再来个自定义的UDAF—求平均数
先来个最简单的UDAF,求平均数。类似这种的操作有很多,比如最大值,最小值,累加,拼接等等,都可以采用相同的思路来做。
首先是需要定义UDAF函数
package test;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.expressions.MutableAggregationBuffer;
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction;
import org.apache.spark.sql.types.DataType;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
import java.util.List;
/**
* Created by xinghailong on 2017/2/23.
*/
public class MyAvg extends UserDefinedAggregateFunction {
@Override
public StructType inputSchema() {
List structFields = new ArrayList<>();
structFields.add(DataTypes.createStructField( "field1", DataTypes.StringType, true ));
return DataTypes.createStructType( structFields );
}
@Override
public StructType bufferSchema() {
List structFields = new ArrayList<>();
structFields.add(DataTypes.createStructField( "field1", DataTypes.IntegerType, true ));
structFields.add(DataTypes.createStructField( "field2", DataTypes.IntegerType, true ));
return DataTypes.createStructType( structFields );
}
@Override
public DataType dataType() {
return DataTypes.IntegerType;
}
@Override
public boolean deterministic() {
return false;
}
@Override
public void initialize(MutableAggregationBuffer buffer) {
buffer.update(0,0);
buffer.update(1,0);
}
@Override
public void update(MutableAggregationBuffer buffer, Row input) {
buffer.update(0,buffer.getInt(0)+1);
buffer.update(1,buffer.getInt(1)+Integer.valueOf(input.getString(0)));
}
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {
buffer1.update(0,buffer1.getInt(0)+buffer2.getInt(0));
buffer1.update(1,buffer1.getInt(1)+buffer2.getInt(1));
}
@Override
public Object evaluate(Row buffer) {
return buffer.getInt(1)/buffer.getInt(0);
}
}
使用的时候,需要先注册,然后在spark sql里面就可以直接使用了:
package test;
import com.tgou.standford.misdw.udf.MyAvg;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
import java.util.List;
/**
* Created by xinghailong on 2017/2/23.
*/
public class test4 {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[2]");
sparkConf.setAppName("test");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
SQLContext sqlContext = new SQLContext(sc);
sqlContext.udf().register("my_avg",new MyAvg());
JavaRDD lines = sc.textFile( "C:\\test4.txt" );
JavaRDD rows = lines.map(line-> RowFactory.create(line.split("\\^")));
List structFields = new ArrayList();
structFields.add(DataTypes.createStructField( "a", DataTypes.StringType, true ));
structFields.add(DataTypes.createStructField( "b", DataTypes.StringType, true ));
StructType structType = DataTypes.createStructType( structFields );
DataFrame test = sqlContext.createDataFrame( rows, structType);
test.registerTempTable("test");
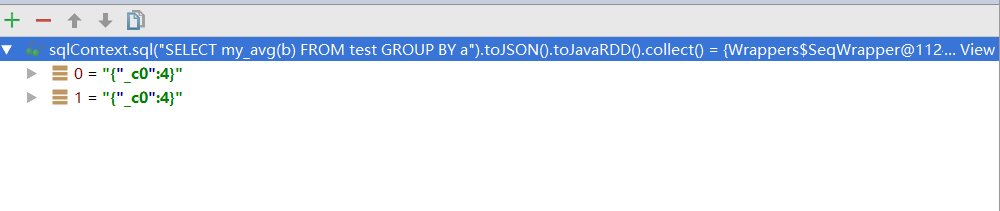
sqlContext.sql("SELECT my_avg(b) FROM test GROUP BY a").show();
sc.stop();
}
}
计算的文本内容为:
a^3
a^6
b^2
b^4
b^6
再来个无所不能的UDAF
真正的业务场景里面,总会有千奇百怪的需求,比如:
想要按照某个字段分组,取其中的一个最大值
想要按照某个字段分组,对分组内容的数据按照特定字段统计累加
想要按照某个字段分组,针对特定的条件,拼接字符串
再比如一个场景,需要按照某个字段分组,然后分组内的数据,又需要按照某一列进行去重,最后再计算值
1 按照某个字段分组
2 分组校验条件
3 然后处理字段
如果不用UDAF,你要是写spark可能需要这样做:
rdd.groupBy(r->r.xxx)
.map(t2->{
HashSet set = new HashSet<>();
for(Object p : t2._2){
if(p.getBs() > 0 ){
map.put(xx,yyy)
}
}
return StringUtils.join(set.toArray(),",");
});
上面是一段伪码,不保证正常运行哈。
这样写,其实也能应付需求了,但是代码显得略有点丑陋。还是不如SparkSQL看的清晰明了...
所以我们再尝试用SparkSql中的UDAF来一版!
首先需要创建UDAF类
import org.apache.commons.lang.StringUtils;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.expressions.MutableAggregationBuffer;
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction;
import org.apache.spark.sql.types.*;
import java.util.*;
/**
*
* Created by xinghailong on 2017/2/23.
*/
public class ConditionJoinUDAF extends UserDefinedAggregateFunction {
@Override
public StructType inputSchema() {
List structFields = new ArrayList<>();
structFields.add(DataTypes.createStructField( "field1", DataTypes.IntegerType, true ));
structFields.add(DataTypes.createStructField( "field2", DataTypes.StringType, true ));
return DataTypes.createStructType( structFields );
}
@Override
public StructType bufferSchema() {
List structFields = new ArrayList<>();
structFields.add(DataTypes.createStructField( "field", DataTypes.StringType, true ));
return DataTypes.createStructType( structFields );
}
@Override
public DataType dataType() {
return DataTypes.StringType;
}
@Override
public boolean deterministic() {//是否强制每次执行的结果相同
return false;
}
@Override
public void initialize(MutableAggregationBuffer buffer) {//初始化
buffer.update(0,"");
}
@Override
public void update(MutableAggregationBuffer buffer, Row input) {//相同的executor间的数据合并
Integer bs = input.getInt(0);
String field = buffer.getString(0);
String in = input.getString(1);
if(bs > 0 && !"".equals(in) && !field.contains(in)){
field += ","+in;
}
buffer.update(0,field);
}
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {//不同excutor间的数据合并
String field1 = buffer1.getString(0);
String field2 = buffer2.getString(0);
if(!"".equals(field2)){
field1 += ","+field2;
}
buffer1.update(0,field1);
}
@Override
public Object evaluate(Row buffer) {//根据Buffer计算结果
return StringUtils.join(Arrays.stream(buffer.getString(0).split(",")).filter(line->!line.equals("")).toArray(),",");
}
}
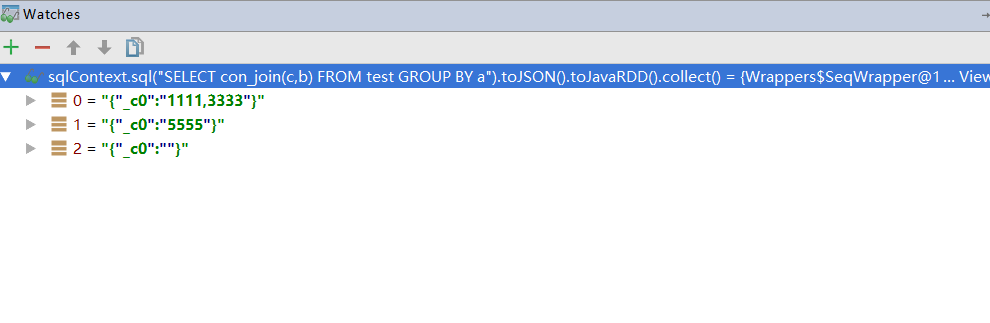
拿一个例子坐下实验:
a^1111^2
a^1111^2
a^1111^2
a^1111^2
a^1111^2
a^2222^0
a^3333^1
b^4444^0
b^5555^3
c^6666^0
按照第一列进行分组,不同的第三列值,进行拼接。
package test;
import test.ConditionJoinUDAF;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
import java.util.List;
/**
* Created by xinghailong on 2017/2/23.
*/
public class test2 {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[2]");
sparkConf.setAppName("test");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
SQLContext sqlContext = new SQLContext(sc);
sqlContext.udf().register("con_join",new ConditionJoinUDAF());
JavaRDD lines = sc.textFile( "C:\\test2.txt" );
JavaRDD rows = lines.map(line-> RowFactory.create(line.split("\\^")));
List structFields = new ArrayList();
structFields.add(DataTypes.createStructField( "a", DataTypes.StringType, true ));
structFields.add(DataTypes.createStructField( "b", DataTypes.StringType, true ));
structFields.add(DataTypes.createStructField( "c", DataTypes.StringType, true ));
StructType structType = DataTypes.createStructType( structFields );
DataFrame test = sqlContext.createDataFrame( rows, structType);
test.registerTempTable("test");
sqlContext.sql("SELECT con_join(c,b) FROM test GROUP BY a").show();
sc.stop();
}
}
这样SQL简洁明了,就能表达意思了。
参考

