
- 1女生适不适合软件测试?从薪资、就业、学习、工作难度和加班多方面解读女生适不适合软件测试这一工作_女生做自动化测试怎么样
- 2笔记本电脑怎样连接打印机_国产打印机品牌有哪些?什么值得推荐
- 3iOS ------ 多线程基础
- 4如何保证MQ中消息的顺序性?_怎么保证mq顺序消费
- 5【论文笔记】| 定制化生成PuLID
- 6【程序源代码】奶茶点餐订餐餐饮小程序
- 7毕业设计基于SpringBoot+Vue智慧云办公系统源码+数据库+项目文档_springboot+vue oa流程源码
- 8YashanDB携手慧点科技完成产品兼容认证 助力国产信创生态建设
- 9git 和码云_git码云
- 10微信分享打不开分享界面_微信分享什么都可以了,就是调不起分享按钮
Multi Diffusion: Fusing Diffusion Paths for Controlled Image Generation——【论文笔记】_multidiffusion: fusing diffusion paths for control
赞
踩
本文发表于ICML 2023
论文官网:MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation

一、Intorduction
文本到图像生成模型已经具有合成高质量和多样化图像的能力,但是由于难以为用户提供对生成内容的直观控制,因此将文本到图像模型部署到现实世界的应用程序仍然具有挑战性。目前实现对扩散模型实现可控的图像生成主要有两种方式:1.从头开始训练模型或针对手头的任务微调给定的扩散模型;2.重用预先训练好的模型,并添加一些控制生成功能。
本文提出了一种新的方法:MultiDiffusion,这是一个新的统一框架,可以显着提高将预训练扩散模型适应受控图像生成的灵活性。MultiDiffusion背后的基本思想是定义一个新的生成过程,该过程由几个参考扩散生成过程组成,这些参考扩散生成过程通过一组共享参数或约束绑定在一起。更详细地,将参考扩散模型应用于所生成的图像中的不同区域,预测每个区域的去噪采样步骤。反过来,MultiDiffusion采用全局去噪采样步骤,通过最小二乘最优解协调所有这些不同的步骤。
通过MultiDiffusion,我们能够将参考预训练的文本到图像应用于不同的应用,包括以所需的分辨率或纵横比合成图像,或使用粗略的基于区域的文本提示合成图像等等,且有着很好的图像生成质量。
二、Related work
1.Diffusion Models
这部分主要介绍了扩散模型的相关知识。扩散模型是一类生成概率模型,当前扩散模型已经成为最先进的生成模型,因为它在学习复杂分布和生成各种高质量样本方面有着很好的效果。
2.Controllable generation with diffusion models
这部分主要介绍了在扩散模型上实现可控的图像生成,然后提了一下论文所提出的方法MultiDiffusion,这是一种更加通用的方法,能够以更有原则的方式统一不同的用户控制输入。
三、Methods
这部分主要讲了方法的核心原理,里面具体的公式等在此就不细讲。
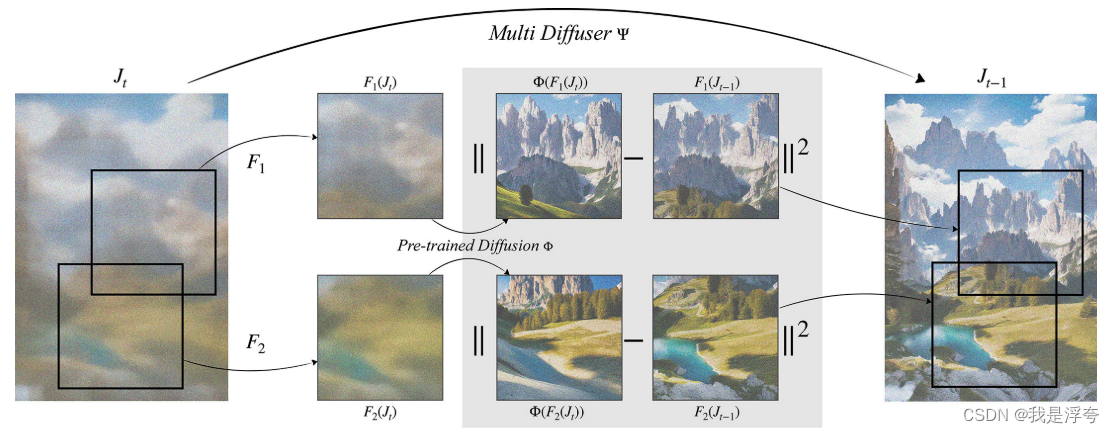
论文提出的方法核心思想如上图,Multi Diffusion会将图像随机分成不同区域,然后分别使用预训练的扩散模型,然后会对所有区域生成的结果进行全局优化。在全局优化过程中,MultiDiffusion方法使用最小二乘法(最小二乘法(Least Squares Method)是一种常用的数学优化方法,用于寻找一组参数,使得给定的函数与观测数据之间的残差平方和最小化。在本文中,最小二乘法主要用于优化生成过程,以使生成的图像与给定的约束或目标尽可能接近。)来将不同区域的生成结果进行整合。具体而言,将每个区域的生成结果视为一个向量,并将这些向量组合成一个矩阵。然后,它通过最小化矩阵与预定义的目标矩阵之间的距离来确定最终的生成结果。
当然,这些区域可以由用户提供的控制信号(如粗糙的区域掩模)或其他空间引导信号来定义。MultiDiffusion方法允许用户以多种方式提供控制信号,以指导图像生成过程。这种灵活的控制信号输入方式使得用户能够根据具体需求对图像生成过程进行精细调整,从而实现对生成图像的多样性和质量的要求。
四、Applications
为了能够证明论文所提的方法性能的优越性,在论文中主要提及了两个应用场景:
第一小节主要介绍了MultiDiffusion在全景图像生成中的应用,而第二小节则介绍了MultiDiffusion在受控的区域图像生成中的应用。
而在第二小节中,作者介绍了如何使用MultiDiffusion方法生成具有特定区域约束的图像,同时论文中提到,在受控的区域图像生成过程中添加了一个引导阶段bootstrapping,bootstrapping方法通过引入时间依赖性(时间依赖性在这里可以理解为一种动态调整的机制,它允许生成的图像随着生成过程的进行而逐渐适应和调整,以更好地符合给定的蒙版。这种动态调整可以帮助生成的图像更好地填充蒙版区域,使得最终的生成结果更加符合预期。)来调整生成的图像,以确保生成的图像在给定的蒙版区域内保持高保真度。这种时间依赖性的引入使得生成的图像能够更好地适应给定的蒙版,并产生更高质量的结果。
五、Results
1.Panorama Generation

为了表现Multi Diffusion的优越性,论文主要提及了两种应用场景,第一种就是全景图像512*4096的生成,相比于其他的方法,Multi Diffusion的性能是比较好的。
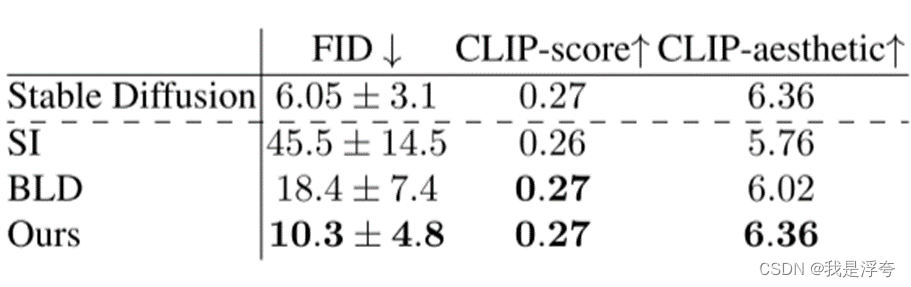
这里所用的三个性能指标分别是:FID、CLIP-score、CLIP-aesthetic
FID 是用于衡量生成图像与参考模型生成图像之间的差距的指标,FID值越低表示生成图像与真实图像的分布越接近。
CLIP-score是使用CLIP模型计算的文本和图像之间的相似度得分,它衡量了生成图像与输入文本之间的语义一致性。
CLIP-aesthetic是使用CLIP模型计算的生成图像的美学评分,它衡量了生成图像的质量和视觉吸引力。
2.Region-based Text-to-Image Generation

第二个应用是区域控制图像生成,这里主要是与其他方法在COCO数据集上的效果进行了对比,所用的性能指标是IoU, 即交并比。IoU用来衡量这些候选区域与真实标签之间的重叠程度,从而判断特定的对象在图像生成的指定区域的准确性。

表中的w/o bootstrapping是指是否在Multi Diffusion实现的过程中添加时间依赖性用来引导图像生成过程。
论文还展现了使用模糊区域控制来进行图像生成的效果:


