
深入理解内联函数(C语言)
赞
踩
1.什么是内联函数
很多人都会知道,可以将比较小的函数写成内联函数的形式,这样会节省函数调用的开销,具体是什么样的开销呢?
一个函数在执行过程中,如果需要调用其他函数,则一般会执行下面的过程。
- 保存当前函数现场
- 跳到调用函数执行
- 恢复当前函数现场
- 继续执行当前函数
一个C语言程序,在main()函数中对某些数据进行处理,运算结果暂时保存在R0寄存器中。接着调用另一个函数call_fun(),调用结束后,返回main()函数继续执行。如果我们在call_fun()函数中要用到R0寄存器,就会改变R0中的值,当我们返回main()中继续执行程序的时候,就会出现错误的计算。
处理办法很简单,就是在跳到call_fun()之前,先将R0中的值保存到对战中,调用结束后,再将其值取出来,这样就可以顺利地执行main()函数了。这就是所谓的现场保存和恢复。
对于一般的函数调用,当然没有什么问题,但如果需要调用的函数本来就很小(指令和数据都不多),这个时候如果频繁地调用,就会出现频繁地保存现场,恢复现场,降低了程序的执行效率,这个时候就可以将call_fun()改写为内联函数,简单高效。
2.内联函数与宏
内联函数和宏的功能差不多,为什么不直接定义一个宏,而去定义一个内联函数呢?二者又有什么不同呢?
与宏相比,内联函数具有以下优势。
- 参数类型检查:内联函数具有宏的展开特性,但本质仍是函数,在编译过程中,编译器仍然可以对其进行参数检查,而宏不具备此功能。
- 便于调试:函数支持丰富的断点调试功能,而宏定义不支持,这样便于软件的调试和开发。
- 接口封装:有些内联函数可以用来封装一个接口,而宏并无此特性。
3.编译器对内联函数的处理
众所周知,并不是在函数前添加了inline关键字,程序在执行过程中就会乖乖执行内联展开,这与开发者和计算机都有关系。
而若要得知函数是否真正进行了内联展开,则需要深入底层,从汇编程序中得知。
尺有所短,寸有所长,内联函数也有缺点。内联函数会增大程序的体积,如果在一个文件中多次调用内联函数,多次展开,则整个函数的体积就会变大,降低了代码的执行效率。这与函数的设计初衷相悖(函数的作用之一就是提高代码的复用性)。
编译器在对内联函数做展开时,除了检测用户定义的内联函数是否有指针、循环、递归,还会在函数执行效率和函数调用开销之间进行权衡。一般来说,从程序员角度来说,主要考虑以下因素。
- 函数体积小。
- 函数体内无指针赋值、递归、循环等语句。
- 调用频繁。
下面的例子,我们用一个简单的程序实现了某个数的阶乘。
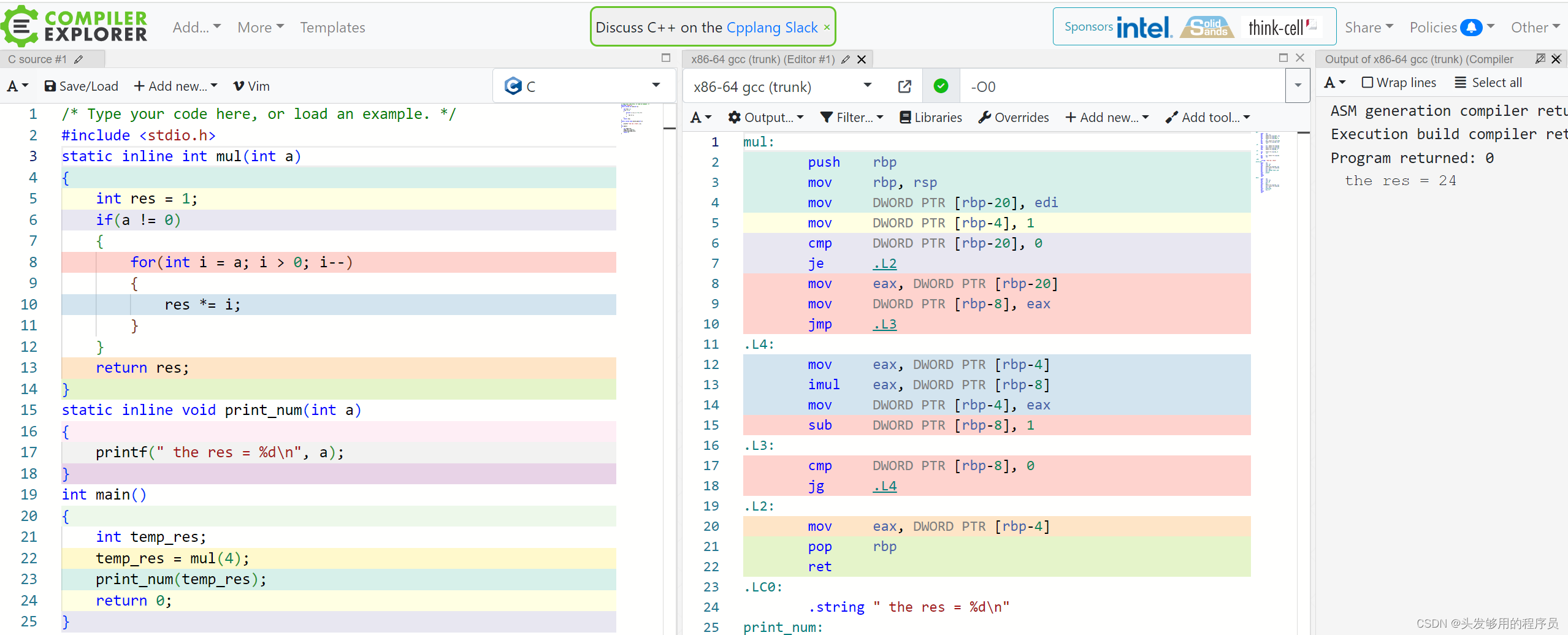
我们封装了两个函数,都含有linline关键字,而从编译后的汇编程序可以看出,一个函数进行了内联展开,而另一个可能考虑到了函数并不是很精简,并未对其进行内联展开。
然后将优化等级调到了1,再看看结果:
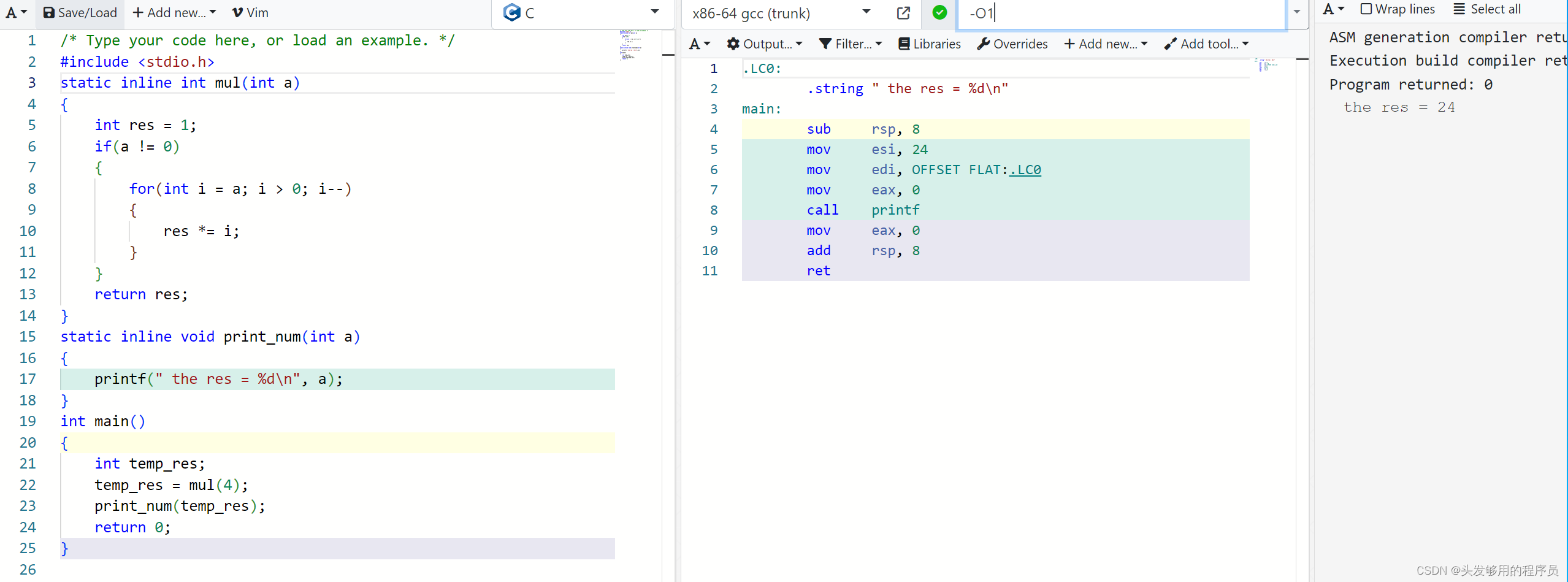
可以看到,将两个函数都进行了内联展开。输出结果仍然是24,保持不变。
接下来我们使用GCC编译器提供的特性__attribute__来实现强制内联:
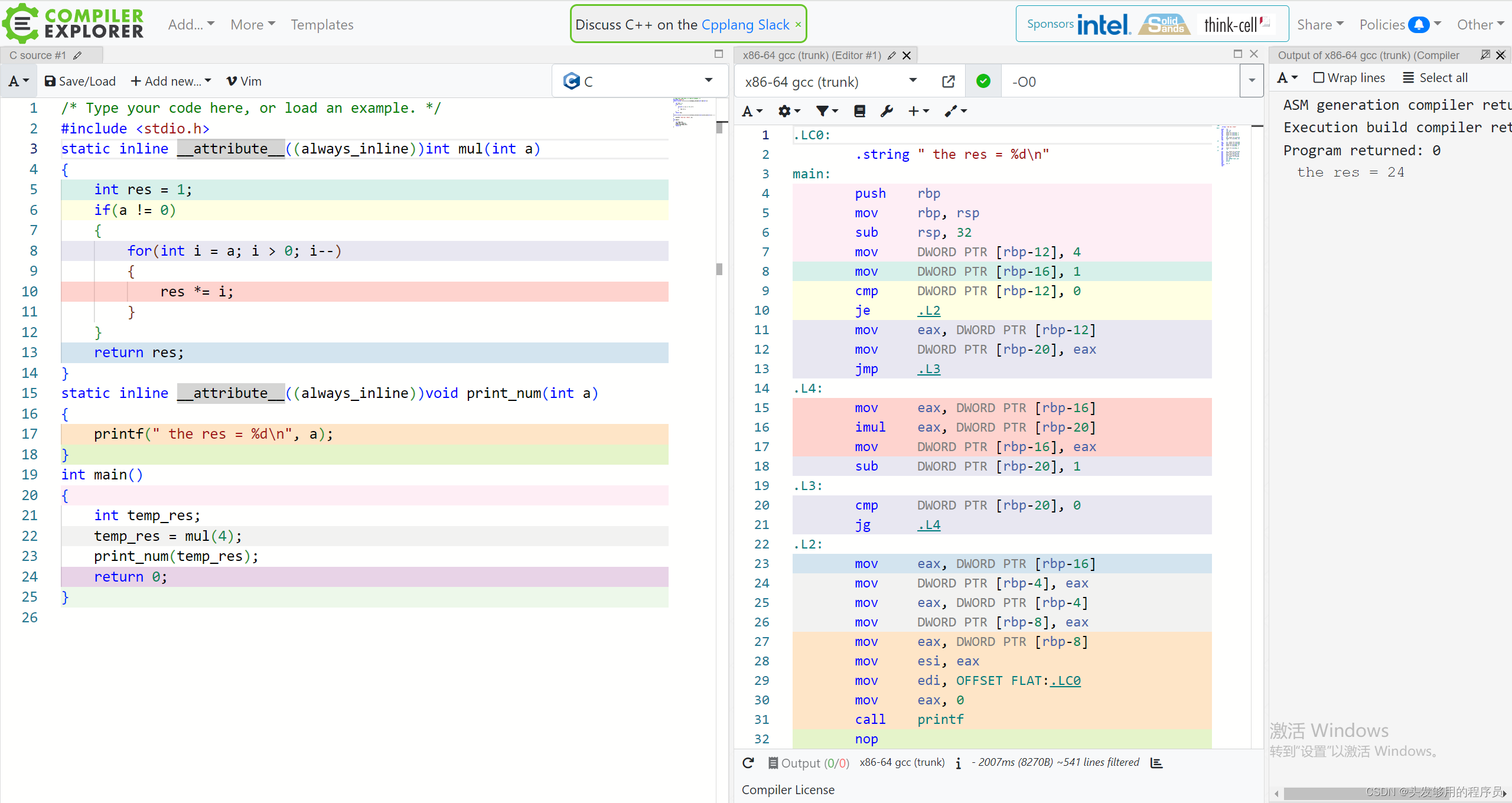
可以看到,此时即使关闭了优化等级,编译器还是对两个内联函数进行了内联展开。程序的运行结果也不会受影响。
此次我们采用了在线的编译工具,感觉还不错,喜欢的同学可以试试。
Compiler Explorer
4.参考文献
《嵌入式C语言自我修养》

