
- 1Elasticsearch查询文档--常见API篇(附详细代码和案例图文)_elasticsearch api文档
- 2关于TypeError: list indices must be integers or slices, not float报错
- 3本科,60k*13薪,外包到新疆!你会去吗?
- 4IDEA GenerateAllSetter插件 一键set实体类中所有属性_idea设置set所有bean属性
- 5计算机论文的参考文献,应该怎么引用? - 易智编译EaseEditing_计算机研究与发展 参考文献格式从哪里引用
- 6树莓派使用通过i2s使用MAX98357播放音频_树莓派 i2s
- 7华为昇腾310B初体验,OrangePi AIpro开发板使用测评
- 8C语言实现循环队列基本操作_循环队列中清空队列的语句
- 9C语言字符集
- 10详解C++移动语义std::move()
【C语言 - 数据结构】树、二叉树(上篇)_c语言树和二叉树
赞
踩
树是计算机算法最重要的非线性结构。因为树能很好地描述结构的分支关系和层次特性,所以在计算机科学和计算机应用领域有着广泛的应用。这篇文章我就带大家一起了解一下树、二叉树这种结构,下篇文章会重点向大家介绍二叉树的遍历算法。

如果人生值得活,那只是为了注视美。——柏拉图
毫无疑问的是,树也是一种美丽的结构!
提示:以下是本篇文章正文内容,下面案例可供参考
一、树概念及结构
1.1树的概念
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因 为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。


·有一个特殊的结点,称为根结点,根节点没有前驱结点
·除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<= i <= m)又是一棵结构与树类似的子树。
·每棵子树的根结点有且只有一个前驱,可以有0个或多个后继 因此,树是递归定义的。
注意:树形结构中,子树之间不能有交集,否则就不是树形结构

1.2 树的相关概念
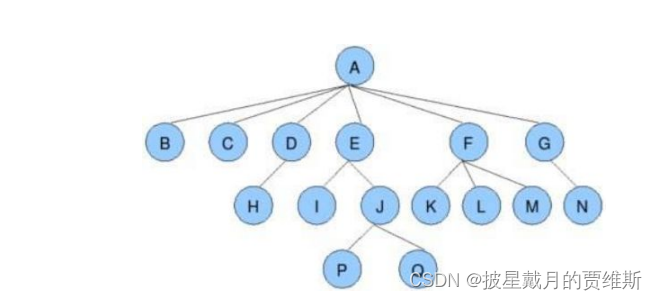
节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A的为6
叶节点或终端节点:度为0的节点称为叶节点; 如上图:B、C、H、I...等节点为叶节点
非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G...等节点为分支节点
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
森林:由m(m>0)棵互不相交的树的集合称为森林;
1.3 树的表示
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,既然保存值域,也要保存结点和结点之间 的关系,实际中树有很多种表示方式如:双亲表示法,孩子表示法、孩子双亲表示法以及孩子兄弟表示法 等。我们这里就简单的了解其中最常用的孩子兄弟表示法。
如下图所示:

二、二叉树概念及结构
2.1概念
什么是二叉树?简言之一棵二叉树是结点的一个有限集合,该集合:
1. 或者为空
2. 由一个根节点加上两棵别称为左子树和右子树的二叉树组成
如下图示
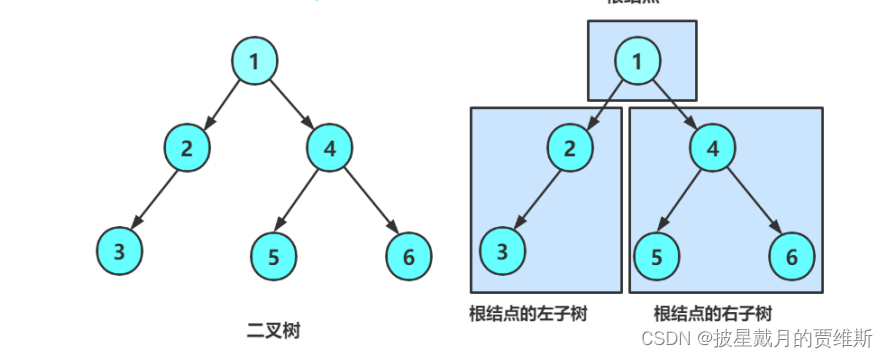
从上图我们可以看出二叉树的两个特点
1. 二叉树不存在度大于2的结点
2. 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
注意:对于任意的二叉树都是由以下几种情况复合而成的:
2.2 特殊的二叉树:
1. 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是 说,如果一个二叉树的层数为K,且结点总数是 ,则它就是满二叉树。
2. 完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K 的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对 应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。
2.3 二叉树的性质
1. 若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有 2^(i - 1)个结点.
2. 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是2^h - 1 .
3. 对任何一棵二叉树, 如果度为0其叶结点个数为n0 , 度为2的分支结点个数为n1 ,则有n0 =n2 +1.
4. 若规定根节点的层数为1,具有n个结点的满二叉树的深度,h=log2(n + 1) (是log以2 为底,n+1为对数)
5. 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对 于序号为i的结点有:
1. 若i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点.
2.若2i+1<n, 左孩子序号;如果2i + 1 >=n 无左孩子
3. 若2i+2<n, 右孩子序号;如果2i + 1 >=n 无右孩子
解释:二叉树存储下标从0开始就会出现这种结果
2.5 二叉树的存储结构
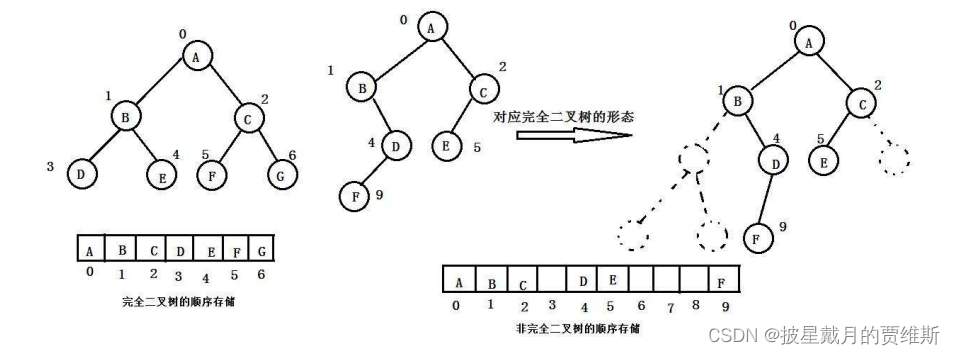
1. 顺序存储
顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空 间的浪费。而现实中使用中只有堆才会使用数组来存储,关于堆我们后面的章节会专门讲解。二叉树顺 序存储在物理上是一个数组,在逻辑上是一颗二叉树。
2. 链式存储
二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是 链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所 在的链结点的存储地址 。链式结构又分为二叉链和三叉链,当前我们学习中一般都是二叉链,后面课程 学到高阶数据结构如红黑树等会用到三叉链。

三、实现一种完全二叉树-堆,并实现堆排序
3.1堆的概念和结构
如果有一个关键码的集合K = { , , ,…, },把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,并满足: = 且 >= ) i = 0,1, 2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆的性质: 堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。

3.2实现堆的难点:向上调整算法和向下调整算法
由于堆是一种非线性存储结构,因此我们在执行堆的删除时会比较复杂,涉及到向下调整算法。
1、原先我们在栈和队列那讲中的挪动数据覆盖根的位置的数据删除会导致堆的结构被破坏了,父子间的结构全乱了。
向下调整算法的思路:
1、第一个数(根位置)和最后一个位置进行交换。
2、删除最后一个数据。
3、找出左右孩子中小的那个和父亲比较,如果比父亲小,交换,再从交换的孩子位置继续往下调整。
过程如下图所示:

- 向下调整算法
- void* AdjustDown(HPDataType* a, size_t size, size_t root)
- {
- size_t parent = root;
- size_t child = parent * 2 + 1;//默认是左孩子
- while (child < size)
- {
- //1、选出左右孩子中小的那个,而且保证不会越界访问
- if (child + 1 < size && a[child + 1] < a[child])
- {
- child++;//左孩子变为右孩子
- }
- if (a[child]< a[parent])
- {
- Swap(&a[child], &a[parent]);
- parent = child;//继续计算
- child = parent * 2 + 1;//默认还是计算左孩子
- }
- else
- {
- break;
- }
- }
- }

为了保持堆的结构,我们还要引入向上调整算法,由于两种算法原理差不多而且向上调整比较简单易懂,我直接上代码了。
- void Adjustup(HPDataType* a, size_t child)
- {
- size_t parent = (child - 1) / 2;
- while (child > 0)
- {
- //小堆a[child] <a[parent],大堆a[child] > a[parent]时交换
- if (a[child] < a[parent])
- {
- Swap(&a[child], &a[parent]);//因为是指针传参,所以要&
- child = parent;
- parent = (child - 1) / 2;
- }
- else
- {
- break;
- }
- }
- }
3.3小堆的实现
头文件:
- #pragma once
-
- // 小堆
- #include<stdio.h>
- #include<assert.h>
- #include<stdlib.h>
- #include<stdbool.h>
-
- typedef int HPDataType;
- typedef struct Heap
- {
- HPDataType* a;
- size_t size;
- size_t capacity;
- }HP;
- void PrintTopk(int* a, int n, int k);
- void HeapInit(HP* php);//堆的初始化
- void HeapDestory(HP* php);//堆的销毁
- void Swap(HPDataType* pa, HPDataType* pb);//交换
- void HeapPrint(HP* php);
- void AdjustDown(HPDataType* a, size_t size, size_t root);//堆的向下调整算法
- //插入x以后,依旧保持堆
- void HeapPush(HP* php, HPDataType x);
- void Adjustup(HPDataType* a, size_t child);//堆的向上调整算法
- //删除堆顶的数据,(最小/最小)
- void HeapPop(HP* php);
-
- bool HeapEmpty(HP* php);
- size_t HeapSize(HP* php);
- HPDataType HeapTop(HP* php);
源文件:
- #include"Heap.h"
-
- void HeapInit(HP* php)
- {
- assert(php);
- php->a = NULL;
- php->size = php->capacity = 0;
- }
- void HeapDestory(HP* php)
- {
- assert(php);
- free(php->a);
- php->a = NULL;
- php->size = php->capacity = 0;
-
- }
- void Swap(HPDataType* pa, HPDataType* pb)
- {
- HPDataType tmp = *pa;
- *pa = *pb;
- *pb = tmp;
- }
- void HeapPrint(HP* php)
- {
- assert(php);
- for (size_t i = 0; i < php->size; i++)
- {
- printf("%d ", php->a[i]);
- }
- printf("\n");
- }
- //涉及堆排序
- void Adjustup(HPDataType* a, size_t child)
- {
- size_t parent = (child - 1) / 2;
- while (child > 0)
- {
- //小堆a[child] <a[parent],大堆a[child] > a[parent]时交换
- if (a[child] < a[parent])
- {
- Swap(&a[child], &a[parent]);//因为是指针传参,所以要&
- child = parent;
- parent = (child - 1) / 2;
- }
- else
- {
- break;
- }
- }
- }
- void AdjustDown(HPDataType* a, size_t size, size_t root)
- {
- size_t parent = root;
- size_t child = parent * 2 + 1;//默认是左孩子
- while (child < size)
- {
- //1、选出左右孩子中小的那个,而且保证不会越界访问
- if (child + 1 < size && a[child + 1] < a[child])//建大堆时< 改 >
- {
- ++child;//左孩子变为右孩子
- }
- if (a[child] < a[parent])//建大堆时< 改 >
- {
- Swap(&a[child], &a[parent]);
- parent = child;//继续计算
- child = parent * 2 + 1;//默认还是计算左孩子
- }
- else
- {
- break;
- }
- }
- }
-
- void HeapPush(HP* php, HPDataType x)
- {
- assert(php);
-
- if (php->size == php->capacity)//满了,需要扩容
- {
- size_t newCapacity = php->capacity == 0 ? 4 : php->capacity * 2;
- //翻译:新定义一个无符号的newCapacity = 原来的capacity,如果原来的capacity = 0, 就赋值为4,4不够就再*二倍
- HPDataType* tmp = realloc(php->a, sizeof(HPDataType)* newCapacity);
- if (tmp == NULL)
- {
- printf("reallpc failed\n");
- exit(-1);
- }
- php->a = tmp;
- php->capacity = newCapacity;
- }
- //尾插
- php->a[php->size] = x;
- ++php->size;
- //向上调整保持是一个小堆
- Adjustup(php->a, php->size - 1);
- }
- void HeapPop(HP* php)
- {
- assert(php);
- assert(php->size > 0);
- Swap(&php->a[0], &php->a[php->size - 1]);
- --php->size;
- AdjustDown(php->a, php->size, 0);
- }
- bool HeapEmpty(HP* php)
- {
- assert(php);
- return php->size == 0;
- }
- size_t HeapSize(HP* php)
- {
- return php->size;
- }
- HPDataType HeapTop(HP* php)
- {
- return php->a[0];
- }
3.4 堆的应用 : 堆排序
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
1. 建堆 升序:建大堆
.降序:建小堆
2. 利用堆删除思想来进行排序 建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
代码示例:
- void AdjustDown(HPDataType* a, size_t size, size_t root)
- {
- size_t parent = root;
- size_t child = parent * 2 + 1;//默认是左孩子
- while (child < size)
- {
- //1、选出左右孩子中小的那个,而且保证不会越界访问
- if (child + 1 < size && a[child + 1] <a[child])//建大堆时< 改 >
- {
- ++child;//左孩子变为右孩子
- }
- if (a[child] < a[parent])//建大堆时< 改 >
- {
- Swap(&a[child], &a[parent]);
- parent = child;//继续计算
- child = parent * 2 + 1;//默认还是计算左孩子
- }
- else
- {
- break;
- }
- }
- }
- void HeapSort2(int* a, int n)
- {
- //向上调整--建堆
- //for (int i = 1; i < n; ++i)
- //{
- // AdjustUp(a, i);
- //}
- //向下调整--建堆O(N)
- for (int i = (n - 1 - 1) / 2; i >= 0; --i)
- {
- AdjustDown(a, n, i);//为什么向下调整要多传一个参数,因为当child>=size 时说明已经到了边界
- }
- size_t end = n - 1;//n - 1是最后一个数据的下标
- while (end > 0)
- {
- Swap(&a[0], &a[end]);
- AdjustDown(a, end, 0);
- //次大的数到了倒数第二个位置
- --end;
- }
- }
- int main()
- {
- // TestHeap();
- int a[] = { 4 , 2, 7, 8, 5, 1, 0, 6 };
- HeapSort(a, sizeof(a) / sizeof(int));
- for (int i = 0; i < sizeof(a) / sizeof(int); i++)
- {
- printf("%d ", a[i]);
- }
- printf("\n");
- return 0;
- }

四.Top-k问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能 数据都不能一下子全部加载到内存中)。
最佳的方式就是用堆来解决,基本思路如下:
1. 用数据集合中前K个元素来建堆 前k个最大的元素,则建小堆 前k个最小的元素,则建大堆 2. 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素。
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。

因为N非常大,k非常小,所以复杂度相当于0(N)
设置10个比100万大的数,然后让电脑随机生成数,找出大于100万的10个数。
- void PrintTopk(int* a, int n, int k)
- {
- //1、建堆-- 用a中前k个元素建堆
- int* kminHeap = (int*)malloc(sizeof(int)* k);
- assert(kminHeap);
- //2、将剩余n-k元素依次与堆顶元素交换,不满则替换
-
- for (int i = 0; i < k; i++)
- {
- kminHeap[i] = a[i];//将前k个数给给它
- }
- //第k-1个是最后一位数的下标,(k - 1 -1) / 2是倒数第一个非叶子结点
- //建小堆
- for (int j = (k - 1 - 1) / 2; j >= 0; --j)
- {
- AdjustDown(kminHeap, k, j);
- }
- //2、将剩余n - k元素依次与堆顶元素交换,不满则替换
- for (int i = k; i < n; ++i)
- {
- if (a[i] > kminHeap[0])
- {
- kminHeap[0] = a[i];
- AdjustDown(kminHeap, k, 0);//从根这个点向下调
- }
- }
- for (int j = 0; j < k; j++)
- {
- printf("%d ", kminHeap[j]);
- }
- printf("\n");
- free(kminHeap);
-
- }
- void TestTopk()
- {
- int n = 10000;
- int* a = (int*)malloc(sizeof(int)* n);
- srand(time(0));
- for (size_t i = 0; i < n; ++i)
- {
- a[i] = rand() % 1000000;
- }
- a[5] = 1000000 + 1;
- a[1231] = 1000000 + 2;
- a[531] = 1000000 + 3;
- a[5121] = 1000000 + 4;
- a[115] = 1000000 + 5;
- a[2305] = 1000000 + 6;
- a[99] = 1000000 + 7;
- a[76] = 1000000 + 8;
- a[423] = 1000000 + 9;
- a[0] = 1000000 + 1000;
- PrintTopk(a, n, 10);
- }
- int main()
- {
- TestTopk();
-
- return 0;
- }
总结

本文近7500字,主要从树以及二叉树的概念和结构展开详讲,再详细介绍了堆(特殊的二叉树)这种数据结构的概念、原理以及实现,还有堆的重要应用:堆排序以及TOPK问题等,希望大家读后能够有所收获。

