
- 1论文阅读之Robot Learning System Based on Adaptive Neural Control and Dynamic Movement Primitives_杨辰光
- 2Python的分布式系统与Celery实战
- 3postgresql远程连接中断_postgres 连接经常断开
- 4uniapp通过custom-tab-bar 自定义tabbar导航栏(主要用于微信小程序)_uniapp自定义导航栏custom
- 5《精通PHP+MySQL动态网站开发》_php5+mysql网站开发基础与应用 心得
- 6数字化转型的人工智能与人机交互 2
- 7python中import,from……import使用方法_python中from import怎么用
- 8https://leetcode.com
- 9C语言进阶——动态内存管理
- 10输入n个字符串,进行排序,然后从小到大输出_一行内输入n个字符串,按字典序从小到大进行排序后输出。
LlamaFactory 进行大模型 llama3 微调,轻松上手体验学习_llama3 factory
赞
踩
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集:《大模型面试宝典》(2024版) 发布!
最近,大模型领域最受关注的事件就是meta发布了llama3,前段时间我们介绍的LlamaFactory也第一时间支持了llama3,并且发布了自己的Colab微调实战案例,并对外推出了两个社区中文微调版本:
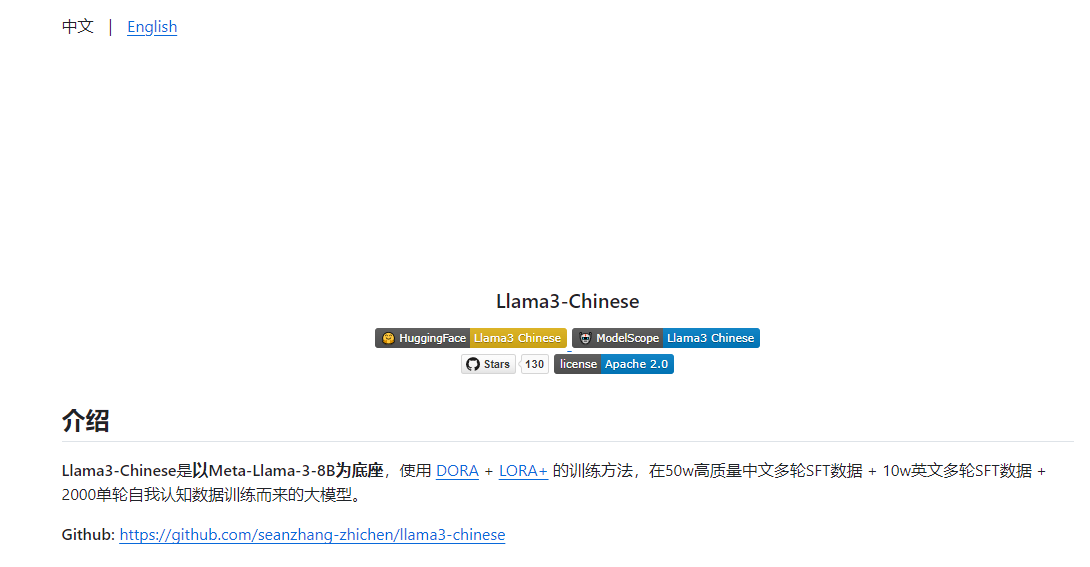
- Llama3-Chinese,首个使用 DoRA 和 LoRA+ 算法微调的中文 Llama3 模型,仓库地址:https://github.com/seanzhang-zhichen/llama3-chinese
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群, 想要大模型技术交流、了解最新面试动态的、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:技术交流
下面我们一起来看看它的微调案例,整个流程与其他模型微调基本一致:
from llmtuner import run_exp
%cd /content/LLaMA-Factory/
run_exp(dict(
stage="sft",
do_train=True,
model_name_or_path="unsloth/llama-3-8b-Instruct-bnb-4bit",
dataset="identity,alpaca_gpt4_en,alpaca_gpt4_zh",
template="llama3",
finetuning_type="lora",
lora_target="all",
output_dir="llama3_lora",
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
lr_scheduler_type="cosine",
logging_steps=10,
warmup_ratio=0.1,
save_steps=1000,
learning_rate=5e-5,
num_train_epochs=3.0,
max_samples=500,
max_grad_norm=1.0,
quantization_bit=4,
loraplus_lr_ratio=16.0,
use_unsloth=True,
fp16=True,
))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
训练数据集:
[
{
"instruction": "hi",
"input": "",
"output": "Hello! I am Llama-3, an AI assistant developed by LLaMA Factory. How can I assist you today?"
},
{
"instruction": "hello",
"input": "",
"output": "Hello! I am Llama-3, an AI assistant developed by LLaMA Factory. How can I assist you today?"
},
{
"instruction": "Who are you?",
"input": "",
"output": "I am Llama-3, an AI assistant developed by LLaMA Factory. How can I assist you today?"
},
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
更多llama3数据集(huggingface&魔搭):
https://huggingface.co/datasets?sort=trending&search=llama3
值得一提的是,llamafactory的微调方案利用unsloth加速,而unsloth也在更早的时候发布了自己的微调方案,感兴趣的读者可以体验。
unsloth(https://github.com/unslothai/unsloth)是一个用于加速深度学习模型训练的开源工具。它可以实现5倍到30倍的训练速度提升,同时还能减少50%的内存占用。
地址:https://colab.research.google.com/drive/1mPw6P52cERr93w3CMBiJjocdTnyPiKTX#scrollTo=IqM-T1RTzY6C
面试精选
参考文章
https://zhuanlan.zhihu.com/p/693905042
https://colab.research.google.com/drive/1d5KQtbemerlSDSxZIfAaWXhKr30QypiK?usp=sharing

