
- 1推荐开源项目:PyCryptodome——Python加密库的卓越替代品
- 2NameError: name xxxxxx is not defined
- 3大神之路-起始篇 | 第2章.计算机科学导论之【数字系统】学习笔记_计算机导论中数码的数量怎么理解
- 42023年中国研究生数学建模等待成绩的心路历程(二十届华为杯)_2023华为杯数学建模竞赛成绩
- 5杠上Google I/O?OpenAI抢先一天直播,ChatGPT或将具备通话功能
- 6Java开发9年经验,三轮技术面+HR面试成功砍下阿里巴巴Offer!_java 9年面试
- 7neo4j3.0 java使用,neo4j 3.0中的存储过程
- 8盘点分布式文件存储系统____分布式文件存储系统简介
- 9网络安全专业名词解释_计算机靶机是什么意思
- 10SQL Server使用教程_初学者必备
LLaMA-Factory添加adalora_llama-factory lora
赞
踩
感谢https://github.com/tsingcoo/LLaMA-Efficient-Tuning/commit/f3a532f56b4aa7d4200f24d93fade4b2c9042736和https://github.com/huggingface/peft/issues/432的帮助。
在LLaMA-Factory中添加adalora
1. 修改src/llmtuner/hparams/finetuning_args.py代码
在FinetuningArguments中修改finetuning_type,添加target_r和init_r

修改__post_init__函数

2. 修改src/llmtuner/tuner/core/adapter.py代码
添加AdaLoraConfig

在init_adapter函数中添加一个if判断,添加位置在如红框所示:
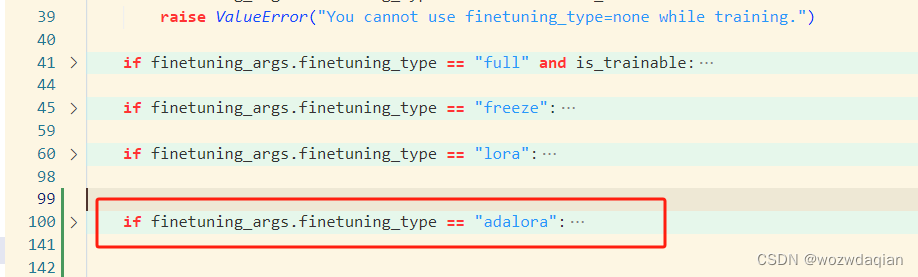
if finetuning_args.finetuning_type == "adalora": logger.info("Fine-tuning method: AdaLoRA") latest_checkpoint = None if model_args.checkpoint_dir is not None: if (is_trainable and finetuning_args.resume_lora_training) or (not is_mergeable): # continually fine-tuning checkpoints_to_merge, latest_checkpoint = model_args.checkpoint_dir[:-1], model_args.checkpoint_dir[-1] else: checkpoints_to_merge = model_args.checkpoint_dir for checkpoint in checkpoints_to_merge: model = PeftModel.from_pretrained(model, checkpoint) model = model.merge_and_unload() if len(checkpoints_to_merge) > 0: logger.info("Merged {} model checkpoint(s).".format(len(checkpoints_to_merge))) if latest_checkpoint is not None: # resume lora training or quantized inference model = PeftModel.from_pretrained(model, latest_checkpoint, is_trainable=is_trainable) if is_trainable and latest_checkpoint is None: # create new lora weights while training if len(finetuning_args.lora_target) == 1 and finetuning_args.lora_target[0] == "all": target_modules = find_all_linear_modules(model, model_args.quantization_bit) else: target_modules = finetuning_args.lora_target lora_config = AdaLoraConfig( task_type=TaskType.CAUSAL_LM, inference_mode=False, target_r=finetuning_args.target_r, init_r=finetuning_args.init_r, r=finetuning_args.lora_rank, target_modules=target_modules, lora_alpha=finetuning_args.lora_alpha, lora_dropout=finetuning_args.lora_dropout, ) model = get_peft_model(model, lora_config) if id(model.peft_config) != id(model.base_model.peft_config): # https://github.com/huggingface/peft/issues/923 model.base_model.peft_config = model.peft_config

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
3. 修改src/llmtuner/tuner/core/parser.py的代码
这边建议所有有关finetuning_args.finetuning_type==/!= "lora"的都改成图片所示

修改transformer源码
按照上面的改完之后虽然可以训练,但是其实并没有实现adalora的秩的调整。
我是通过在update_and_allocate函数中设置断点发现模型训练没有调用update_and_allocate函数,update_and_allocate函数位于python3.10/site-packages/peft/tuners/adalora.py中。
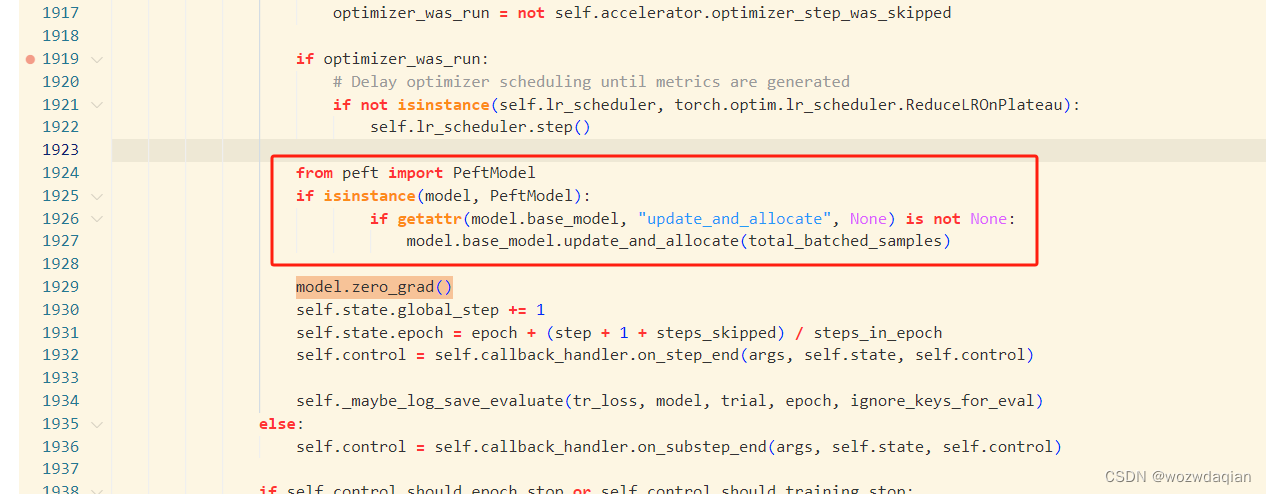
1. 修改python3.10/site-packages/transformers/trainer.py代码
from peft import PeftModel
if isinstance(model, PeftModel):
if getattr(model.base_model, "update_and_allocate", None) is not None:
model.base_model.update_and_allocate(total_batched_samples)
- 1
- 2
- 3
- 4
把上面的代码复制到train函数中,具体的位置应该是整个文件的第二个model.zero_grad()上面,不同transformers的位置可能不一样
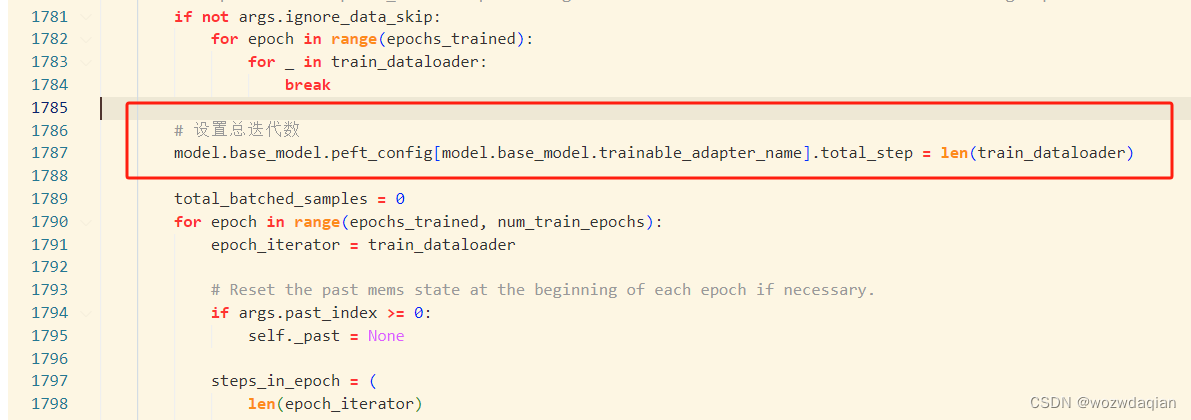
2. 设置adalora的总迭代次数
两个方法一个是在adaloraconfig定义的时候设定(我没试),另外一个就是一样修改train.py,如下:
在for epoch in range(epochs_trained, num_train_epochs):上面一行设置
# 设置总迭代数
model.base_model.peft_config[model.base_model.trainable_adapter_name].total_step = len(train_dataloader)
- 1
- 2
训练启动



{kind=link}