
- 1Stata:拉索回归和岭回归-(Ridge,-Lasso)-简介
- 2SAP FI常用事务码_sap fb1s
- 3Linux——缺页中断与内存置换算法,你想知道的都在这里!_lru置换算法计算432143543215
- 4KMP算法详解及其Java实现_kmdkcnnj 哦对;下班必须滴不是客服。觉得
- 5Ollama 常用命令_ollama 命令
- 6【算法】位运算算法——两整数之和
- 7git cherry-pick冲突解决_gerrit中的cherry pick confict
- 8git Cherry-pick Failed your local changes would be overwritten by cherry-pick. hint: commit your
- 9Git多用户,不同项目配置不同Git账号_git 不同项目不同
- 102022年华为杯中国研究生数学建模竞赛C题思路_2022年华为杯c题思路
青椒学堂大数据学习笔记之2.1 HDFS的shell命令——增删改查_青椒课堂linux
赞
踩
引言:
之前通过Hadoop伪分布式集群搭建,已经将我们的基础环境配置完成。我们在此基础上,将进入本节知识点学习,HDFS分布式文件系统作为Hadooop的文件存储系统,结合自身高容错、高吞吐以及可扩展的特点,为我们大数据的大数据集存储提供保障。
HDFS概论:
在如今企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在集群上的文件系统称为分布式文件系统:

Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
HDFS伪分布式工作原理:
HDFS采用Master/Slave架构,一个HDFS集群有两个重要的角色,分别是Namenode和Datanode。Namenode是管理节点,负责管理文件系统的命名空间(namespace)以及客户端对文件的访问。Datanode是实际存储数据的节点。HDFS暴露了文件系统的命名空间,用户能够以操作文件的形式在上面操作数据。
HDFS的四个基本组件:HDFS Client、NameNode、DataNode和Secondary NameNode。

1. Client:客户端。
(1)文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
(2)与NameNode 交互 ,获取文件的位置信息。
(3)与DataNode 交互 ,读取或者写入数据。
(4)管理和访问HDFS ,比如启动或者关闭HDFS。
2.NameNode:就是 master,它是一个主管、管理者。
(1)管理HDFS的名称空间。
(2)管理数据块(Block)映射信息。
(3)配置副本策略。
(4)处理客户端读写请求。
3. DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
(1)存储实际的数据块。
(2)执行数据块的读/写操作。
4. Secondary NameNode:并非NameNode的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
(1)辅助NameNode,分担其工作量。
(2)定期合并fsimage和fsedits,并推送给NameNode。
(3)在紧急情况下,可辅助恢复NameNode。
实训任务
1. 本节实训分为两个任务,分别为:
(1)操作HDFS文件或目录命令。
(2)查看,追加和合并文本内容命令。
2. shell命令大全:
在集群开启状态下,通过管理命令查看shell命令大全,如图所示:
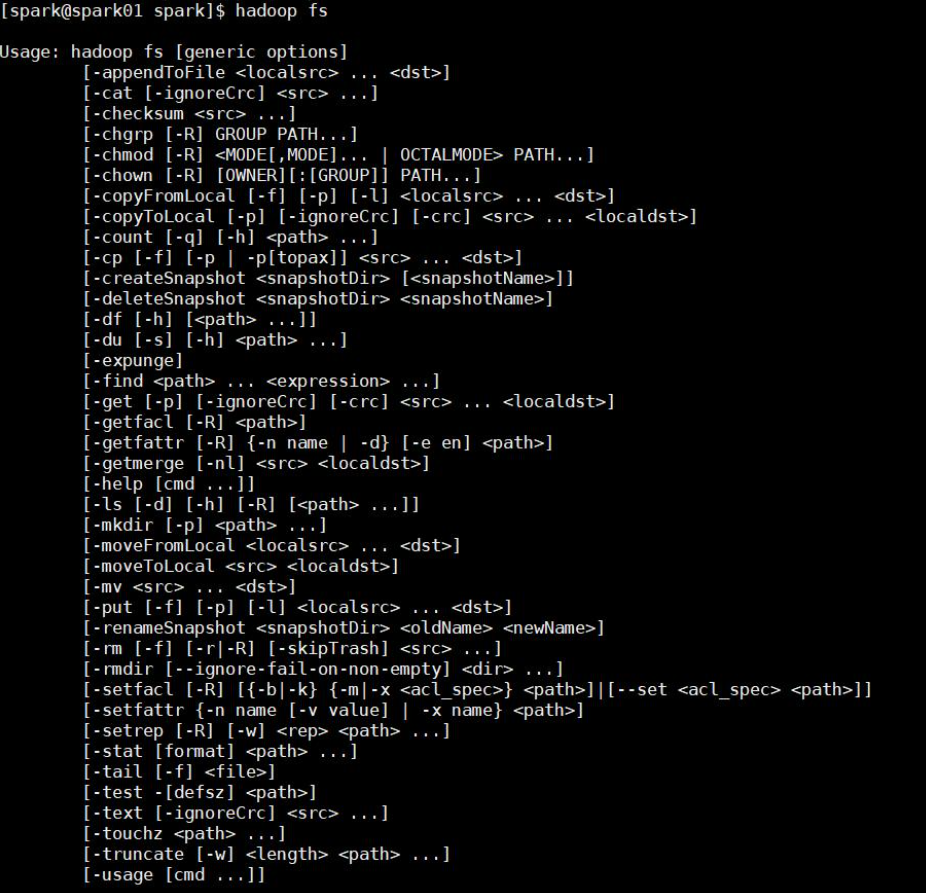
- 选项名称 使用格式 含义
- -ls -ls <路径> 查看指定路径的当前目录结构
- -lsr -lsr <路径> 递归查看指定路径的目录结构
- -du -du <路径> 统计目录下个文件大小
- -dus -dus <路径> 汇总统计目录下文件(夹)大小
- -count -count [-q] <路径> 统计文件(夹)数量
- -mv -mv <源路径> <目的路径> 移动
- -cp -cp <源路径> <目的路径> 复制
- -rm -rm [-skipTrash] <路径> 删除文件/空白文件夹
- -rmr -rmr [-skipTrash] <路径> 递归删除
- -put -put <多个linux上的文件> <hdfs路径> 上传文件
- -copyFromLocal -copyFromLocal <多个linux上的文件> <hdfs路径> 从本地复制
- -moveFromLocal -moveFromLocal <多个linux上的文件> <hdfs路径> 从本地移动
- -getmerge -getmerge <源路径> <linux路径> 合并到本地
- -cat -cat <hdfs路径> 查看文件内容
- -text -text <hdfs路径> 查看文件内容
- -copyToLocal -copyToLocal [-ignoreCrc] [-crc] [hdfs源路径] [linux目的路径] 从本地复制
- -moveToLocal -moveToLocal [-crc] <hdfs源路径> <linux目的路径> 从本地移动
- -mkdir -mkdir <hdfs路径> 创建空白文件夹
- -setrep -setrep [-R] [-w] <副本数> <路径> 修改副本数量
- -touchz -touchz <文件路径> 创建空白文件
- -stat -stat [format] <路径> 显示文件统计信息
- -tail -tail [-f] <文件> 查看文件尾部信息
- -chmod -chmod [-R] <权限模式> [路径] 修改权限
- -chown -chown [-R] [属主][:[属组]] 路径 修改属主
- -chgrp -chgrp [-R] 属组名称 路径 修改属组
- -help -help [命令选项] 帮助

3. 常用命令:
(1)ls:查看目录下文件或文件夹。
格式:
hadoop fs -cmd < args >
举例:
- # 查看根目录下的目录和文件
- hadoop fs -ls -R /
(2)put:本地上传文件到HDFS。
格式:
-put <多个linux上的文件> <hdfs路径>
举例:
- # 将本地根目录下a.txt上传到HDFS根目录下
- hadoop fs /a.txt /
(3)get:HDFS文件下载到本地。
格式:
hadoop fs -get < hdfs file > < local file or dir>
举例:
- # 将HDFS根目录下a.txt复制到本地/root/目录下
- hadoop fs -get /a.txt /root/
注意: 如果用户不是root, local 路径要为用户文件夹下的路径,否则会出现权限问题。
(4)rm:删除文件/空白文件夹。
格式:
hadoop fs -rm [-skipTrash] <路径>
举例:
- # 删除HDFS根目录下的a.txt
- hadoop fs -rm /a.txt
(5)mkdir:创建空白文件夹。
格式:
hadoop fs -mkdir <hdfs路径>
举例:
- # 在HDFS根目录下创建a文件夹
- hadoop fs -mkdir /a
(6)cp:复制。
格式:
hadoop fs -cp < hdfs file > < hdfs file >
举例:
- # 将HDFS根目录下的a.txt复制到HDFS/root/目录下
- hadoop fs -cp /a.txt /root/
(7)mv:移动。
格式:
hadoop fs -mv < hdfs file > < hdfs file >
举例:
# 将HDFS根目录下a.txt移动到HDFS /root/目录下 hadoop fs -cp /a.txt /root/任务1:操作HDFS文件或目录
1. 操作HDFS文件或目录命令:
(1)ls:查看指定路径的当前目录结构。
(2)makdir:在指定路径下创建子目录。
(3)put:将本地系统的文件或文件夹复制到HDFS上。
(4)get:将HDFS的文件或文件夹复制到本地文件系统上。
(5)cp:将指定文件从 HDFS 的一个路径(源路径)复制到 HDFS 的另外一个路径(目标路径)。
(6)mv:在HDFS目录中移动文件。
(7)rm:在HDFS中删除指定文件或文件夹。
2. shell命令实操:
(1)查看HDFS根目录下结构。
提示:因为我们根目录下没有问价或文件夹,因此不显示内容。
(2)在HDFS根目录下创建root文件夹。
(3)在本地/root目录下创建hadoop.txt文件,添加如下内容:
- hadoop hdfs yarn
- hello hadoop
(4)将本地hadoop.txt上传到HDFS目录/root/下。
(5)将HDFS目录文件/root/hadoop.txt复制到根目录下并查看内容。
(6)删除HDFS目录文件/root/hadoop.txt。
(7)将HDFS目录文件/hadoop.txt迁移到HDFS目录/root/下并查看迁移是否成功。
(8)将HDFS目录文件/root/hadoop.txt复制到本地根目录下并查看。
任务1解析:
shell命令实操:
(1)查看HDFS根目录下结构。
命令:
hadoop fs -ls /
(2)在HDFS根目录下创建root文件夹。
命令:
- # 创建目录
- hadoop fs -mkdir /root
(3)在本地/root目录下创建hadoop.txt文件,添加如下内容:
- hadoop hdfs yarn
- hello hadoop
命令:
- # 进入本地/root/目录
- cd /root/
- # 创建文件并编辑
- vi hadoop.txt
(4)将本地hadoop.txt上传到HDFS目录/root/下。
命令:
hadoop fs -put /root/hadoop.txt /root/
(5)将HDFS目录文件/root/hadoop.txt复制到根目录下并查看内容。
命令:
- # 复制文件
- hadoop fs -cp /root/hadoop.txt /
- # 查看文件
- hadoop fs -cat /hadoop.txt
如图所示:
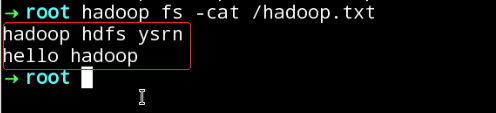
(6)删除HDFS目录文件/root/hadoop.txt。
命令:
hadoop fs -rm /root/hadoop.txt
如图所示:

(7)将HDFS目录文件/hadoop.txt迁移到HDFS目录/root/下并查看是否迁移成功。
命令:
- # 迁移文件
- hadoop fs -mv /hadoop.txt /root/
- # 查看文件
- hadoop fs -ls /root/
如图所示:

(8)将HDFS目录文件/root/hadoop.txt复制到本地根目录下并查看。
命令:
- # 将HDFS文件复制到本地
- hadoop fs -get /root/hadoop.txt /
- # 查看本地文件
- ls /
如图所示:

任务2:查看、追加、合并文本
1. cat:查看文本内容命令。
命令:
hadoop fs -cat [-ignoreCrc] <src>
举例:
- # 查看根目录下的hadoop文件
- hadoop fs -cat /hadoo.txt
2. appendToFile:追加一个或者多个文件到hdfs指定文件中。
命令:
hadoop fs -appendToFile <localsrc> ... <dst>
举例:
- # 将当前文件*.xml追加到HDFS文件big.xml中。
- hadoop fs -appendToFile *.xml /big.xml
3. getmerge:合并下载多个文件。
参数: 加上nl后,合并到local file中的hdfs文件之间会空出一行。命令:
hadoop fs -getmerge -nl < hdfs dir > < local file >
举例:
- # 将HDFS目录下的log.*文件合并下载到本地log.sum文件中
- hadoop fs -getmerge /aaa/log.* ./log.sum
4. appendToFile命令实操:
(1)在本地当前目录(/headless)下创建a.txt,b.txt,c.txt文件。
(2)分别添加内容123,456,789。
(3)在HDFS根目录下创建abc.txt文件并查看。
提示:创建文件名命令hadoop fs -touchz /abc.txt
(4)将本地a.txt,b.txt,c.txt追加到abc.txt文件。
(5)查看abc.txt文件。
5. getmerge命令实操:
(1)将刚才创建的a.txt,b.txt,c.txt文件上传到HDFS根目录。
(2)将HDFS根目录下*.txt文件下载到本地/root/sum.txt。
任务2解析:
1. appendToFile命令实操:
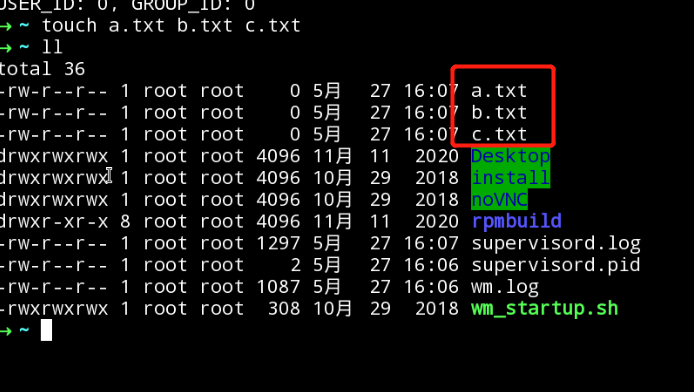
(1)在本地当前(/headless)目录下创建a.txt,b.txt,c.txt文件。
命令:
- # 创建文件
- touch a.txt b.txt c.txt
如图所示:
(2)分别添加内容123,456,789。
命令:
- # 添加内容
- echo 123 >> ./a.txt
- echo 456>> ./b.txt
- echo 789>> ./c.txt
如图所示:

(3)在HDFS根目录下创建abc.txt文件并查看。
提示:创建文件名命令hadoop fs -touchz /abc.txt命令:
- # 创建文件
- hadoop fs -touchz /abc.txt
- # 查看文件
- hadoop fs -ls /
如图所示:

(4)将本地a.txt,b.txt,c.txt追加到abc.txt文件。
命令:
- # 确保在创建的文件目录
- cd /headless
- # 追加文件
- hadoop fs -appendToFile ./*.txt /abc.txt
(5)查看abc.txt文件。
命令:
hadoop fs -cat /abc.txt
如图所示:

2. getmerge命令实操:
(1)将刚才创建的a.txt,b.txt,c.txt文件上传到HDFS根目录。
命令:
- # 确保在创建的文件目录
- cd /headless
- # 追加文件
- hadoop fs -put ./*.txt /
如图所示:

(2)将HDFS根目录下*.txt文件下载到本地并查看内容/root/sum.txt。
命令:
- # 下载文件
- hadoop fs -getmerge -nl /*.txt /root/sum.txt
- # 查看文件内容
- cat /root/sum.txt
如图所示:


