
热门标签
热门文章
- 1【 Spark编程基础 】实验1_spark实验一
- 2电影评价情感分析
- 32024 年最新 Python 使用 Flask 和 Vue 基于腾讯云向量数据库实现 RAG 搭建知识库问答系统
- 4查询Oracle当前用户下,所有数据表的总条数_oracle 查询数据库用户库表条数
- 5微调Paddle UIE模型实现命名实体抽取
- 6微信小程序与公众号关联(同一主体),获取unionId并关联公众号openid_通过unionid获取公众号openid
- 710:HAL---高级定时器_高级定时器重复计数器
- 8系统架构——Spring Framework
- 9kivy--python图形界面工具_kivy可视化工具
- 10微信小程序-webview分享_微信小程序 webview 分享
当前位置: article > 正文
简单的理解K近邻算法的实现_kneighbors
作者:你好赵伟 | 2024-06-11 11:52:25
赞
踩
kneighbors
K近邻算法介绍
- 近朱者赤,近墨者黑
- 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一类别,则该样本也属于该类别
总结knn工作流程
- 计算待分类物体与其他物体之间的距离
- 统计距离最近的k个邻居
- 对于k个邻居,他们属于哪种分类多,待分类物体就属于哪一类
1.手动实现KNN算法
五个步骤
1.读取数据
2.数据的基本处理
3.特征工程
4.数据可视化
训练数据 特征:打斗和亲吻次数 类别:电影类型
预测数据
5.算法实现
- 导入所需要的模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
- 1
- 2
- 3
- 替换Microsoft YaHei字体
- 解决坐标轴负数的负号显示问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
- 1
- 2
1.读取数据
my_df = pd.read_excel('电影数据.xlsx')
print(my_df)
- 1
- 2

2.可视化查看这个点离那个近
- 1.导入模块,以及处理坐标显示字体的问题
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
- 1
- 2
- 3
- 4
- 5
- 2.开始绘图
x = [5,3,31,59,60,80] y = [100,95,105,2,3,10] labels = ["《战狼》","《红海行动》","《碟中谍 6》","《前任3》","《春娇与志明》","《泰坦尼 克号》"] plt.xlabel("亲吻次数") plt.ylabel("打斗次数") plt.xticks(range(0, 150, 10)) plt.yticks(range(0, 150, 10)) i= 0 for x_i, y_i in zip(x, y): plt.annotate(text='{}'.format(labels[i]),xy=(x_i,y_i),xytext=(x_i,y_i)) i+=1 plt.scatter(x,y,s=100)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

- 3.我们可以写方程来进行判断

我们需要判断美人鱼电影是动作片还是爱情片,就需要看这个电影距离哪些电影最近,我们选择近邻点个数k为3来做出判断
class MYknn(object): def __init__(self, train_df, k): """ :param train_df: 训练数据 :param k: 近邻点个数 """ self.train_df = train_df self.k = k def predict(self, test_df): """预测函数""" # 计算欧式距离 self.train_df['距离'] = np.sqrt((test_df['打斗次数']-train_df['打斗次数'])**2+(test_df['接吻次数']-train_df['接吻次数'])**2) # 按距离排序 前K个数据的类别 my_types = self.train_df.sort_values(by='距离').iloc[:self.k]['电影类型'] print(my_types) my_type = my_types.value_counts().index[0] print(my_type) # 训练数据 特征:打斗和亲吻次数 类别:电影类型 train_df = my_df.loc[:5, ['打斗次数', '接吻次数', '电影类型']] print(train_df) # 预测数据 test_df = my_df.loc[6, ['打斗次数', '接吻次数']] print(test_df)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3.算法实现
mk = MYknn(train_df, 3)
mk.predict(test_df)
- 1
- 2
按距离排序离哪个最近,我们可以发现美人鱼电影距离这三个爱情片是最近的,所以,我们可以认为这是个爱情片。
距离3最近 然后是4 最后是5
当底下出现俩个爱情片,一个动作片的时候我们需要做出判断,得出出现次数最多的电影,来以此进行分类,可见这个电影出现最多的是爱情

2.手动实现KNN算法鸢尾花的实现
注:可以通过该类鸢尾花的 “ 花萼长度 花萼宽度 花瓣长度 花瓣宽度 ” 信息来得到,此类鸢尾花属于以下三种的哪一种 “ 山鸢尾 变色鸢尾 维吉尼亚鸢尾 ”
- 导入所需模块
import numpy as np
from sklearn import datasets # 可以提供数据集
from sklearn.model_selection import train_test_split # 分割训练数据和测试数据
from collections import Counter # 计数器
- 1
- 2
- 3
- 4
1.导入数据
-
可以得到鸢尾花对应的四个特征和三个类别
-
data 对应的以下四个特征
花萼长度 花萼宽度 花瓣长度 花瓣宽度 -
target 类别目标对应以下三种类别
山鸢尾 变色鸢尾 维吉尼亚鸢尾
iris = datasets.load_iris()
# print(iris)
# print(iris.data.shape)
X = iris.data
Y = iris.target
print(X, Y)
- 1
- 2
- 3
- 4
- 5
- 6
2.训练数据和测试数据
- X_train, X_test, Y_train, Y_test 分别代表:训练数据集特征 测试集特征 训练数据类别 测试数据类别这四类
- 后面添加的random——state可以让随机的数值不发生改变,如果我们不添加的话,训练数据和测试数据将会随机改变
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=2003)
print(len(X_train))
- 1
- 2
3.算法实现
- 计算两个样本之间欧式距离
instance1:样本1
instance2:样本2
def euc_dis(instance1,instance2):
dist = np.sqrt(sum((instance1-instance2)**2))
return dist
- 1
- 2
- 3
4.建模
- 给定一个测试数据testInstance,通过KNN算法预测它的标签
X:训练数据的特征
y:训练数据的标签
testInstance : 测试数据 假定 一个测试数据array类型
k:选择多少个近邻点
def knn_classify(X, y, testInstance, k=3):
distance = [euc_dis(x,testInstance) for x in X] # 每个训练数据到测试数据的距离集合
print(distance)
# 排序
kneighbors = np.argsort(distance)[:k]
# 投票
count = Counter(y[kneighbors])
return count.most_common()[0][0]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 排序解释
- 返回的结果是从小到大的索引值
print(np.argsort([11, 2.5, 3.6, 1.5, 9]))
- 1

5.测试(预测模型的好坏)
- 其中 012 代表着三种类别
- 模型的正确率是0.921,可见模型效果很好
pred = [knn_classify(X_train,Y_train,data,3) for data in X_test]
print(pred)
count = np.count_nonzero((pred == Y_test) == True)
print(count)
print('模型预测正确率:%.3f'%(count/len(X_test)))
- 1
- 2
- 3
- 4
- 5
- 当我们发现列表中第一个数据是1 ,代表着第一个花的四个特征来识别出此类花是变色鸢尾 如果是0就是山鸢尾,以此来达到花瓣的预测

3.自带模型的实现(自带API的实现)
- API说明文档
- 导入所需模块
import numpy as np
from sklearn import datasets # 自带数据集
from sklearn.model_selection import train_test_split # 分割训练数据和测试数据
from sklearn.neighbors import KNeighborsClassifier
from sklearn.externals import joblib # 加载和保存模型
- 1
- 2
- 3
- 4
- 5
1. 导入数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
- 1
- 2
- 3
2. 训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y)
- 1
3. 实例化KNN算法分类器
clf = KNeighborsClassifier(n_neighbors=7)
- 1
4. 训练
clf.fit(X_train,y_train)
- 1
5. 预测
- 我们可以输入一个二维数组 从而可以预测它的特征
data = np.array([[1,5,8,6]])
res = clf.predict(data)
print(res)
- 1
- 2
- 3
count = np.count_nonzero((clf.predict(X_test) == y_test) == True)
print('模型预测正确率:%.3f'%(count/len(X_test)))
- 1
- 2
6.保存模型(把我们测试好的模型保存起来,下次使用就不需要训练了
joblib.dump(clf,“test.pkl”)
7. 读取模型
clf = joblib.load("test.pkl")
count = np.count_nonzero((clf.predict(X_test) == y_test) == True)
print('模型预测正确率:%.3f'%(count/len(X_test)))
- 1
- 2
- 3
4.k值的选择
- 导入模块
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets # 自带数据集
from sklearn.model_selection import train_test_split # 分割训练数据和测试数据
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
- 1
- 2
- 3
- 4
- 5
- 6
- 解决负号显示和默认字体的问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
- 1
- 2
1. 导入数据
iris = datasets.load_iris()
# 4个特征
# 花萼长度 花萼宽度 花瓣长度 花瓣宽度
X = iris.data
data = iris.data[:, :2]
# 山鸢尾 变色鸢尾 维吉尼亚鸢尾
y = iris.target
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.可视化来分析用哪种算法
- 对种类0 1 2 的三种类别 进行可视化观察
label = np.array(y) index_0 = np.where(label == 0) # 查找所有类别为0的索引位置 # data[index_0, 0] 查找类别为0 的第一列特征的数据 plt.scatter(data[index_0, 0], data[index_0, 1], marker='x', color='b', label='0', s=15) index_1 = np.where(label == 1) plt.scatter(data[index_1, 0], data[index_1, 1], marker='o', color='r', label='1', s=15) index_2 = np.where(label == 2) plt.scatter(data[index_2, 0], data[index_2, 1], marker='s', color='g', label='2', s=15) plt.xlabel('X1') plt.ylabel('X2') plt.legend() plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

2. 数据预处理
- 2.1 训练数据和测试数据分割
- 训练数据集特征 测试集特征 训练数据类别 测试数据类别
X_train, X_test, y_train, y_test = train_test_split(X, y)
- 1
- 2.2 特征工程 - 标准化处理
tranfer = StandardScaler()
X_train = tranfer.fit_transform(X_train)
X_test = tranfer.fit_transform(X_test)
- 1
- 2
- 3
3.验证数据集 作用:找最优K
- 1.交叉验证 把训练集的数据分成四组
folds = 4
k_choices = [1,3,5,7,9,13,15,21,25,27]
# 训练集 分为4组数据
X_folds = np.vsplit(X_train,folds)
# print(X_folds)
y_folds = np.hsplit(y_train,folds)
# print(y_folds)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 2.k值对应的字典生成列表
accuracy_of_k = {}
for k in k_choices:
accuracy_of_k[k] = []
accuracy_of_k
- 1
- 2
- 3
- 4

- 3组做验证集,1组做测试集
for i in range(folds):
# 第二组 + 第三组 + 第四组数据 作训练集
X_train = np.vstack(X_folds[:i]+X_folds[i+1:])
# 第一组 作测试集
X_val = X_folds[i]
y_train = np.hstack(y_folds[:i]+y_folds[i+1:])
y_val = y_folds[i]
for k in k_choices:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train,y_train)
y_val_pred = knn.predict(X_val)
accuracy = np.mean(y_val_pred == y_val)
accuracy_of_k[k].append(accuracy)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
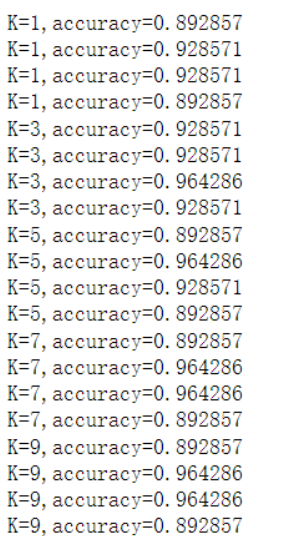
- 求四组的平均值,寻找最优的K值
for k in sorted(k_choices):
for accuracy in accuracy_of_k[k]:
print('K=%d,accuracy=%f'%(k,accuracy))
- 1
- 2
- 3
4.可视化寻找最优k值
for k in k_choices:
plt.scatter([k]*len(accuracy_of_k[k]),accuracy_of_k[k])
accuracies_mean = np.array([np.mean(v) for k,v in sorted(accuracy_of_k.items())])
accuracies_std = np.array([np.std(v) for k ,v in sorted(accuracy_of_k.items())])
plt.errorbar(k_choices,accuracies_mean,yerr=accuracies_std)
plt.title('在k上进行交叉验证')
plt.xlabel('k')
plt.ylabel('交叉验证准确性')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

5. 实例化KNN算法分类器
clf = KNeighborsClassifier(n_neighbors=7)
- 1
6. 训练
clf.fit(X_train,y_train)
- 1
7. 预测
count = np.count_nonzero((clf.predict(X_test) == y_test) == True)
print('模型预测正确率:%.3f'%(count/len(X_test)))
- 1
- 2

5.常用距离计算方法
常用距离计算方法:
欧氏距离(欧几里得距离)
曼哈顿距离
闵可夫斯基距离
切比雪夫距离
余弦距离
- 以下是对这几种常用距离的方法进行解释






声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

