
热门标签
热门文章
- 1将Gitee代码同步到Github
- 2python socket模块 TCP协议 两个py文件的通讯02_python tcp 通信双方
- 32023 搞懂git 工作目录---暂存区---本地仓库---版本库_本地git路经
- 4搭建邮箱服务器注意事项_自建邮箱应注意那些问题
- 5python第三方库安装教程(超详细)_openpyxl怎么安装
- 6【prometheus】监控MySQL并实现可视化_下载mysqld-exporter
- 7MySQL--索引、事务_mysql 修改列事务
- 8Spark相关配置参数_spark资源配置,最新大数据开发开发面试解答_spark内存 配置
- 9中国铁塔成立6周年 | 致敬时光,致敬奋斗者!
- 10HDFS元数据更新机制_新版本的hdfs怎么更新元数据
当前位置: article > 正文
爬山法(八皇后问题)_爬山法算法与八皇后问题
作者:你好赵伟 | 2024-06-13 03:38:23
赞
踩
爬山法算法与八皇后问题
实验原理
Agent的问题求解
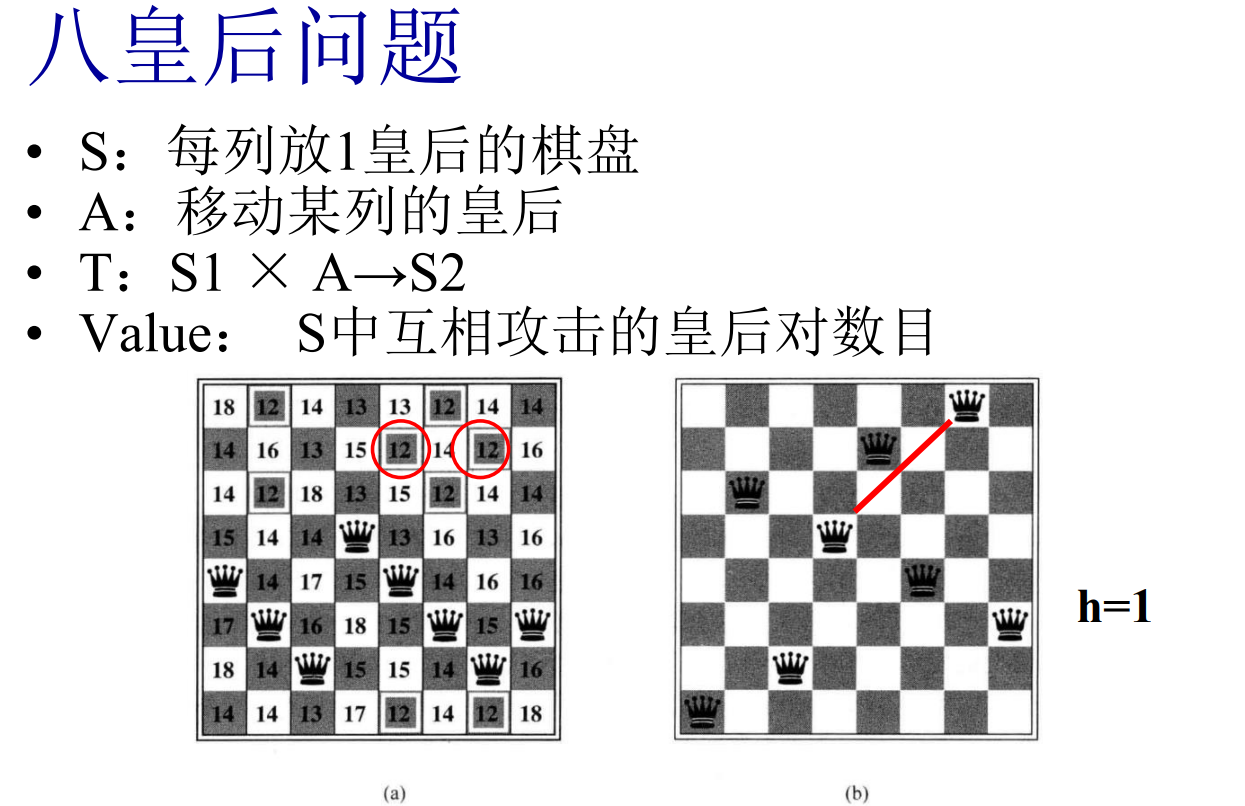
目标函数定义

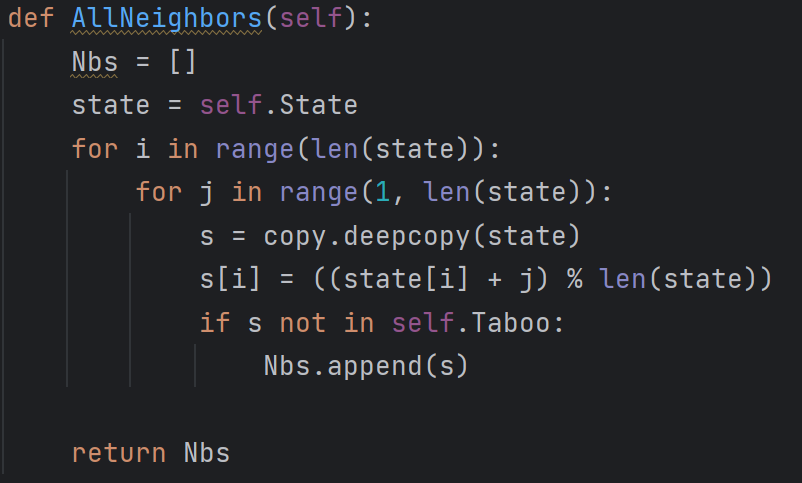
后继结点定义

代码实现
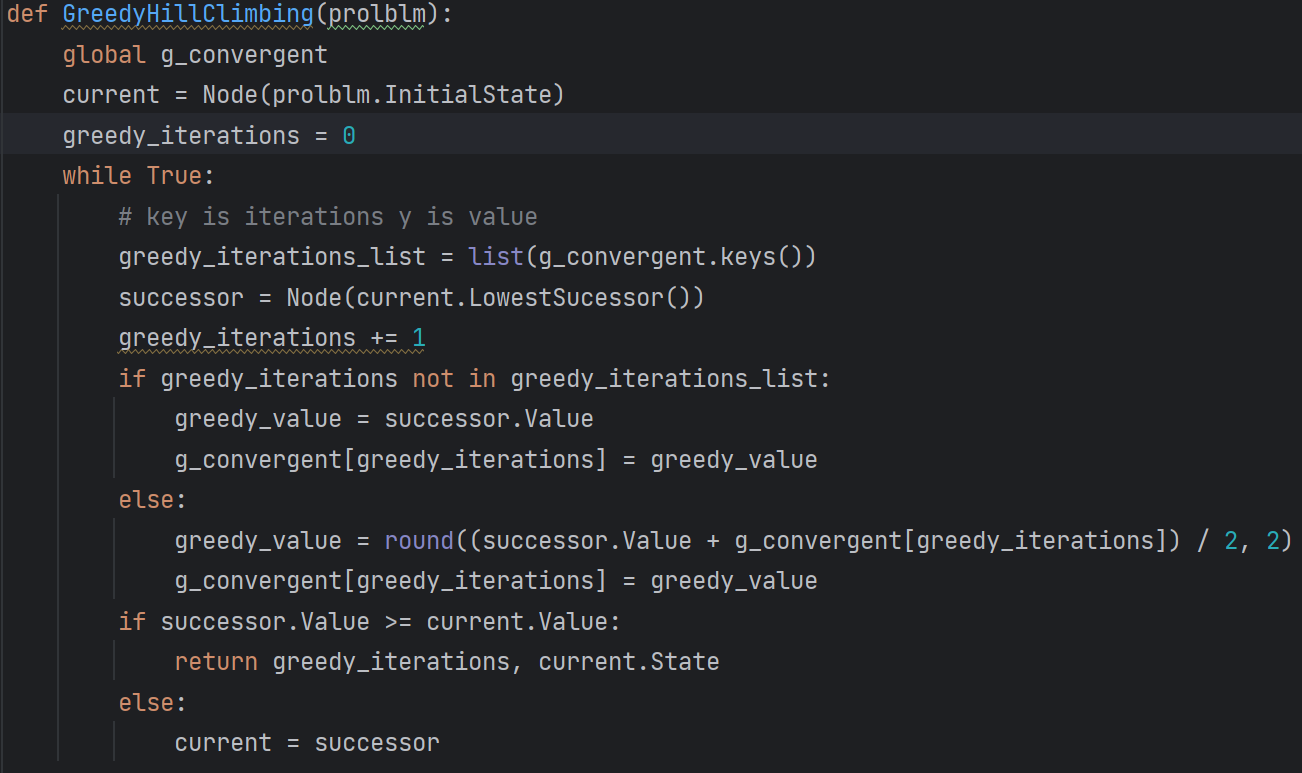
贪婪爬山法
在解决优化问题时,爬山法只是一个简单的循环。以求最小值问题为 例,爬山法是一个不断向下爬的过程:从邻居中选择一个后继状态使得目 标值减小,在到达一个谷底时停止。因为问题不关注最优状态如何得到, 算法只需更新当前状态和目标值,不需要维护搜索路径。
实现思路
- 寻找目标值最小的随机索引

- 一旦发现后继结点的值大于或者等于当前结点,就退出
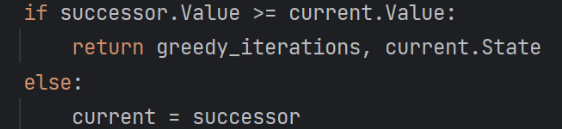
代码实现
实验结果
随机启动1次

实验结果表明:
- 在每种情况下,算法都会到达一个无法再取得进展的点。从一个随机生成的8皇后状态开始,在86%的情况下,最陡上升爬山法会被卡住,它只能解决 14% 的问题实例。但是,它求解速度很快,成功找到解时平均步数为5。
利用重新启动提高性能
- 10次

- 20次

- 30次

- 40次

实验结果表明:
- 利用随机重启,可以提高成功求解的次数,但是成功平均迭代数也会增长,所需时间也会大大增加。
收敛函数
一千次随机结果目标值的平均值
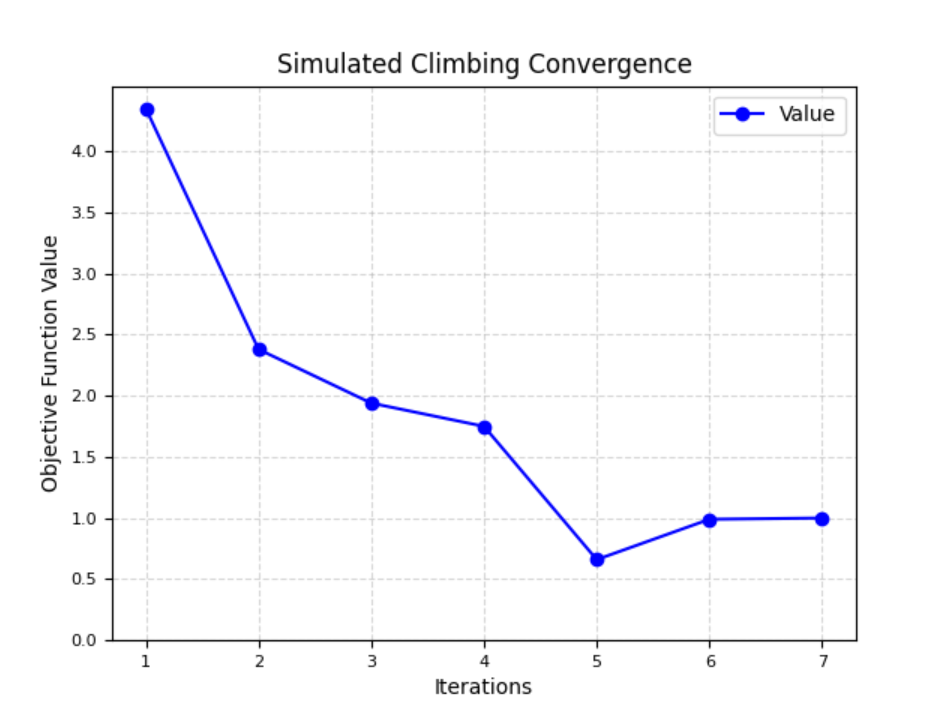
该图像实验结果表明:
- 收敛曲线通常会非常快速地收敛到局部最优解。
- 由于贪心策略只选择当前最佳的邻居解,可能会陷入局部最优解,无法达到全局最优解。
- 曲线表现出一种快速下降的趋势,然后在某个局部最优解附近趋于稳定。
- 在本次实验中,迭代次数最多达到7次,而且迭代数在后半程寻找到全局最优解概率较大。
侧向移动爬山法
暂时没有引入禁忌机制
爬山法的变形
当一个状态的众多邻居跟该状态的目标值相等时,形成一个高原(GreedyHillClimbing中,一旦进入高原区会立即停止搜索。侧向移动爬山法(TranslationHillClimbing)允许在高原上继续搜索多次。多次侧向移动后,目标值有可能离开高原区域继续下降。
实验思路
- 寻找目标值最小的随机索引
- 在高原区继续做横向移动(最多100次)
- 当发现后继结点的值大于当前节点,退出
- 超出100次,退出
代码实现
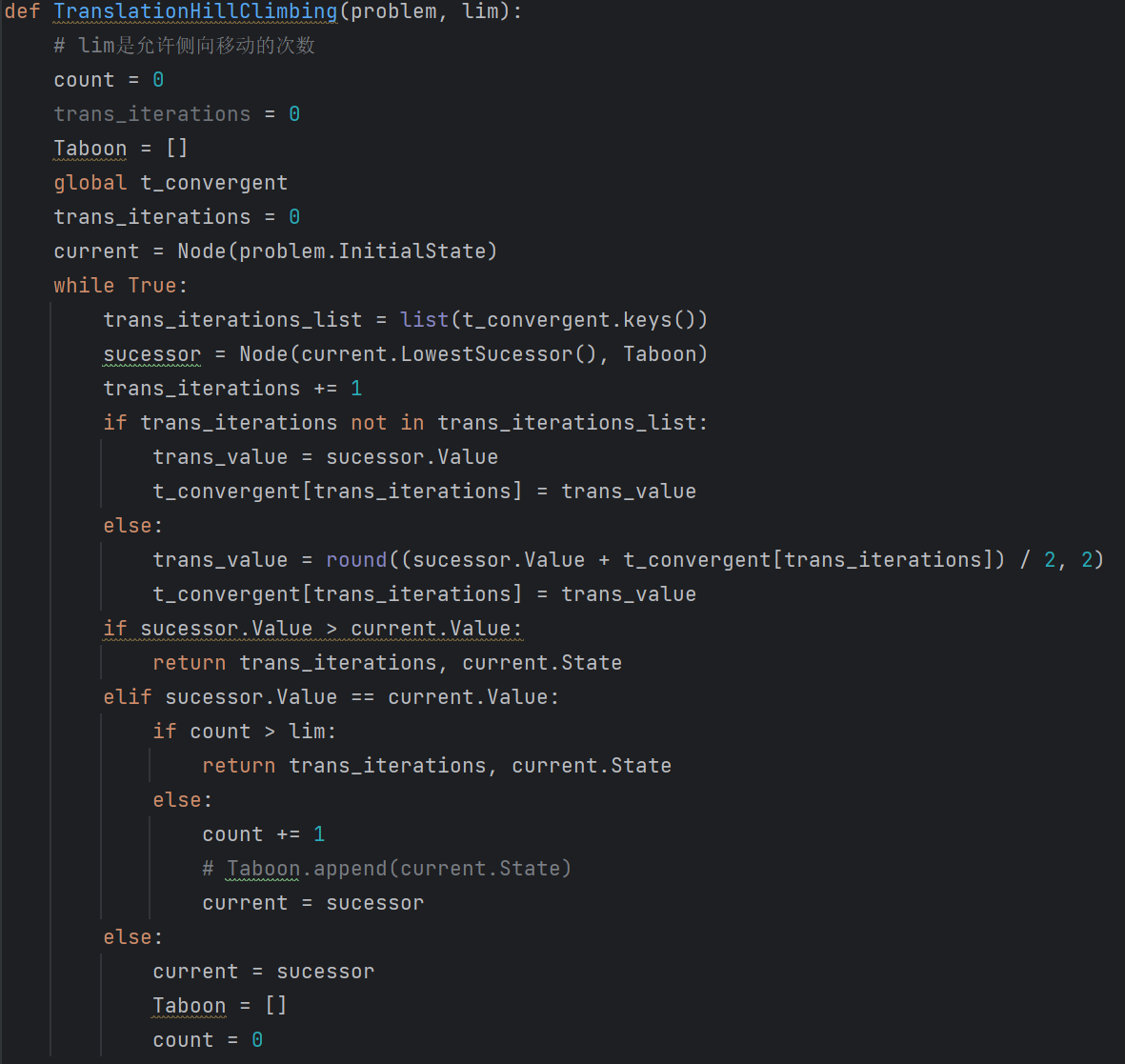
实验结果
随机启动1次

实验结果表明:
- 限制连续横向移动的次数,如在 100 次连续横向移动之后停止。这种方法将爬山法成功求解问题实例的百分比从 14% 提高到了 94%。成功是有代价的:平均下来,对每个成功实例算法需要运行约 20 步,运行时间相对多一点。
利用重新启动提高性能
随机启动2次

实验表明:
- 基本两次成功率可以达到百分之百。
收敛函数
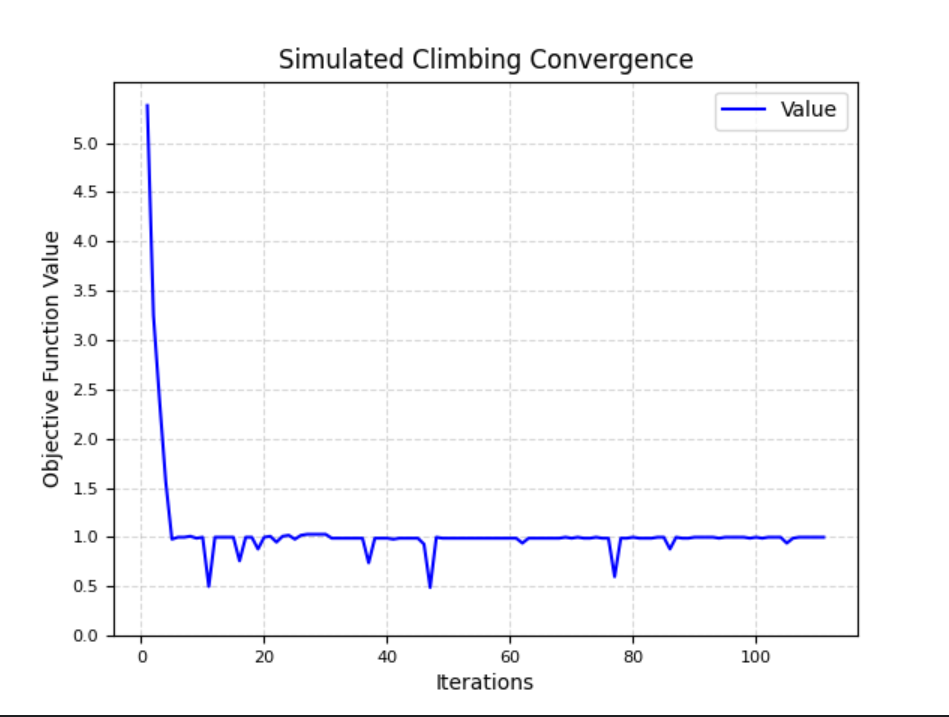
实验结果表明
- 收敛曲线表现出更多的波动和起伏。
- 算法引入了一定的随机性,允许进行侧向移动,从而增加了逃离局部最优解的机会。
- 曲线可能会显示出不断的上下波动,但整体趋势可能是向着更好的解收敛。
- 可以看出最大的迭代数在100-120之间,而且处于100-120之间基本找不到解。
随机爬山法
爬山法的变形
如果并不选取目标值最小的邻居,而是在比当前目标值更小的邻居中随机选取一个作为后继,则称为随机爬山法。
实验思路
- 当前目标值更小的邻居中随机选取一个作为后继

- 一旦发现后继结点的值大于或者等于当前结点,就退出
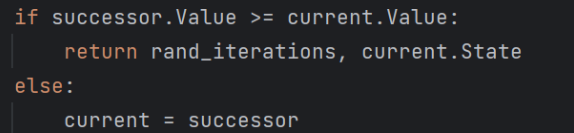
代码实现
实验结果
随机启动1次

实验结果表明:
- 成功求解概率:13%
- 成功平均迭代次数:7次
- 成功求解次数和贪婪爬山法差不多,但是迭代数相对于贪婪爬山法多一点
利用重新启动提高性能
- 10次

- 20次

- 30次

- 40次

实验表明:
- 利用随机重启,可以提高成功求解的次数,但是成功平均迭代数也会增长,所需时间也会大大增加。
收敛函数
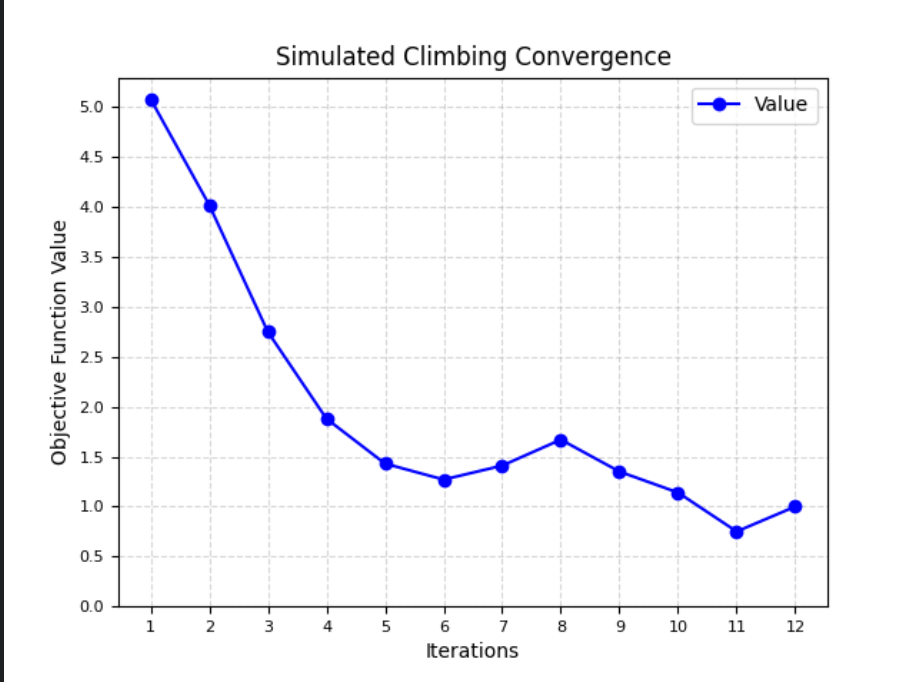
实验结果表明:
- 收敛曲线通常会表现出的波动和起伏,对比贪婪爬山法,会有更多的迭代数
- 被选中的概率随着上坡陡度的变化而变化。这种方法通常比最陡上升法收敛得更慢,但在某些状态地形图中,它能找到更好的解
- 由于算法的随机性质,可能会在搜索空间中跳跃,有时能够逃离局部最优解。
- 曲线可能会显示出不断的上下波动,但整体趋势可能是向着更好的解收敛。
禁忌爬山法
结合侧向移动爬山法
在运筹学领域,爬山法的一种变体禁忌搜索(tabu search)得到广泛应用(Glover and Laguna, 1997)。这种算法维护一个禁忌列表,列表包含 k 个已经访问过而且不能重新访问的状 态;除了能提高搜索图时的效率,它还可以让算法避开某些局部极小值 。
实验思路
- 引入Taboon
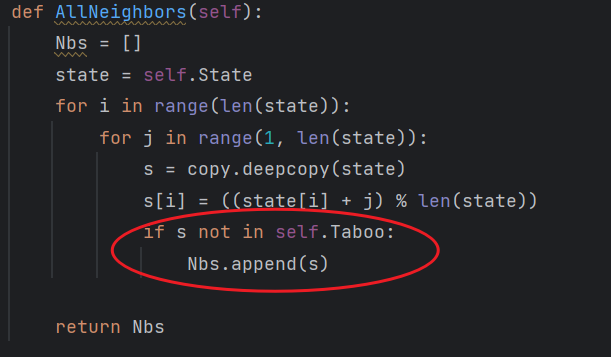
- 与侧向移动爬山法类似
代码实现
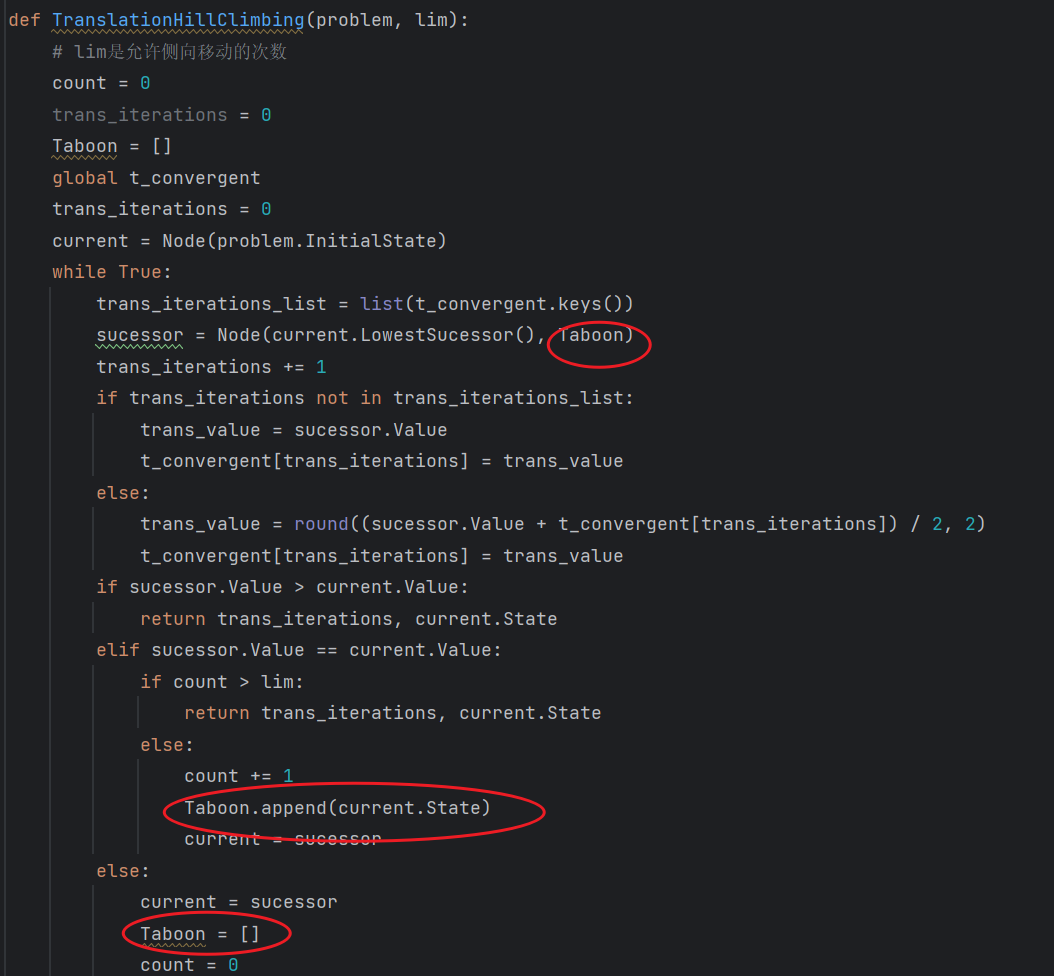
实验结果
随机启动1次

实验结果表明:
- 相对于侧向移动爬山法,虽然成功求解的次数会下降,但是迭代数也同样下降了,大大降低了程序运行时间。成功率大约在74%,迭代数11左右。
利用重新启动提高性能
- 2次

这个结果表明成功率与侧向移动爬山法大致相同,但是平均迭代数会12步比之前20步减少了很多,极大提高了性能。
- 3次
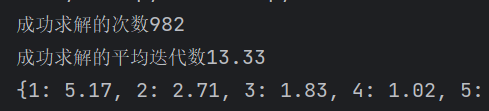
- 4次

迭代步数仍然很少,说明这个算法性能非常高。
收敛函数
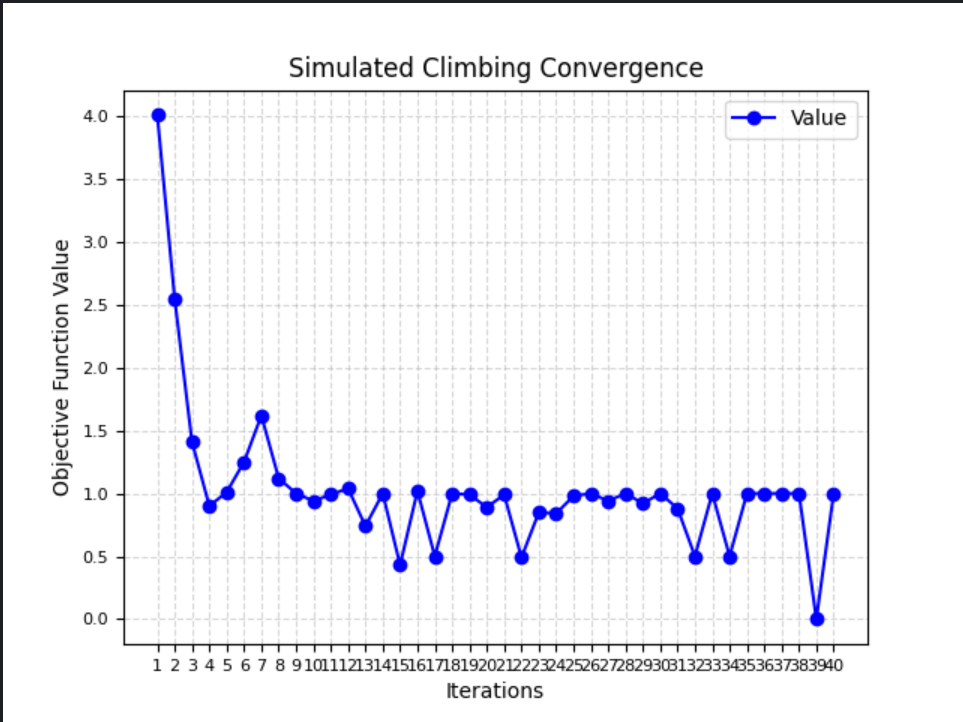
实验结果表明:
- 收敛到局部最优解:
- 初始阶段,禁忌爬山法通常会迅速收敛到一个局部最优解。
- 收敛曲线可能会显示出一种快速下降的趋势,但会停留在某个局部最优解附近。
- 逐渐逃离局部最优解:
- 禁忌列表的作用是避免重复访问已经探索过的解,从而有机会逃离局部最优解。
- 收敛曲线可能会表现出一些波动,因为算法在搜索过程中可能会选择次优解来避免禁忌操作。
- 长期记忆的影响:
- 禁忌列表记录了已经禁忌的操作,使得算法对之前禁忌的操作保持记忆。
- 曲线可能会显示出一种周期性的波动,因为算法可能会在一段时间内避免某些操作
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

