
机器学习周报第十六周
赞
踩
摘要
词嵌入、序列到序列模型(Seq2Seq)以及注意力机制是深度学习中的三个重要组成部分,它们共同推动了自然语言处理的发展。词嵌入是将文本数据映射到低维向量空间的技术,使得计算机能够更好地理解和处理文本数据。Seq2Seq模型引入了编码器-解码器结构,可以处理序列到序列的任务,如机器翻译和文本摘要生成。而注意力机制则允许模型在处理长序列时关注输入序列的不同部分,从而提高了模型的性能和泛化能力。
Abstract
Word embedding, sequence-to-sequence modeling (Seq2Seq), and attention mechanisms are three important components of deep learning that together drive the development of natural language processing. Word embedding is a technique for mapping textual data into a low-dimensional vector space, allowing computers to better understand and process textual data.The Seq2Seq model introduces an encoder-decoder structure that can handle sequence-to-sequence tasks such as machine translation and text summary generation. The attention mechanism, on the other hand, allows the model to focus on different parts of the input sequence when processing long sequences, thus improving the performance and generalization of the model.
一、循环神经网络
1.1 词嵌入
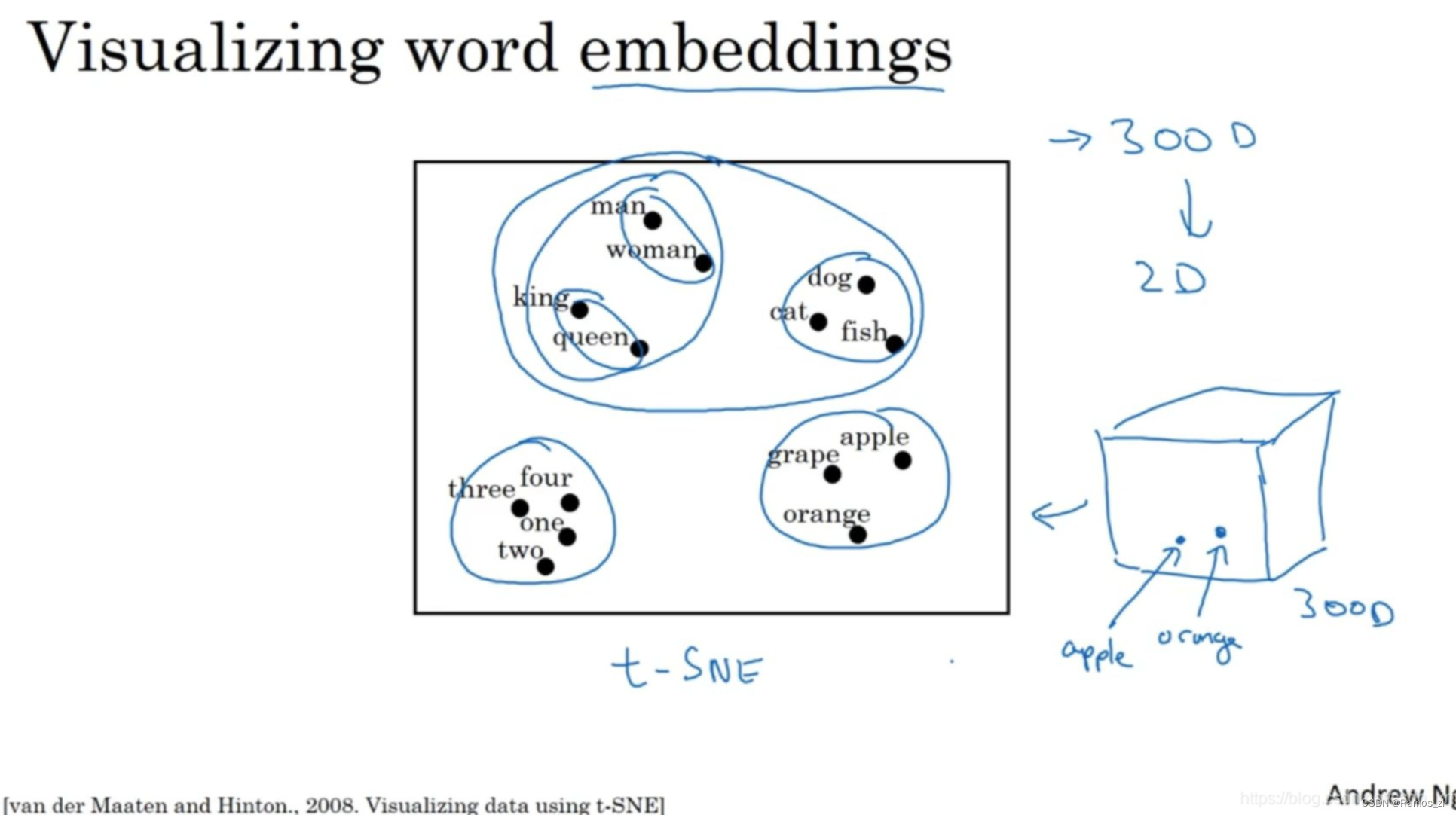
如果我们能够学习到一个300维的特征向量(词嵌入),通常我们可以把这300维的数据嵌入到一个二维空间里实现可视化。常用的可视化算法是t-SNE算法,来自于Laurens van der Maaten 和 Geoff Hinton的论文。
如下图,如果观察这种词嵌入的表示方法,我们看到man和woman这些词聚集在一块,king和queen聚集在一块,表示人的单词也都聚集在一起。动物都聚集在一起,水果也都聚集在一起,像1、2、3、4这些数字也聚集在一起。如果把这些生物看成一个整体,他们也聚集在一起。
就整体而言,这种词嵌入算法(word embeddings algorithms)对于相近的概念,学到的特征也比较类似,在对这些概念可视化的时候,最终把它们映射为相似的特征向量。这种表示方式用的是在300维空间里的特征表示,这叫做嵌入(embedding)。之所以叫嵌入的原因是,你可以想象一个300维的空间,这里用个3维的代替。现在取每一个单词比如orange,它对应一个3维的特征向量,所以这个词就被嵌在这个300维空间里的一个点上了,apple这个词就被嵌在这个300维空间的另一个点上。为了可视化,t-SNE算法把这个空间映射到低维空间,也可以画出一个2维图像然后观察,这就是这个术语嵌入的来源。
如下图所示,我们用命名实体识别(named entity recognition)的例子,假如有一个句子:“Sally Johnson is an orange farmer.”(Sally Johnson是一个种橙子的农民),Sally Johnson是一个人名,所以这里的输出为1。之所以能确定Sally Johnson是一个人名而不是一个公司名,是因为你知道种橙子的农民一定是一个人。
如果用特征化表示方法,将词嵌入向量输入训练好的模型,如果你看到一个新的输入:“Robert Lin is an apple farmer.”(Robert Lin是一个种苹果的农民),因为知道orange和apple很相近,那么你的算法很容易得出Robert Lin也是一个人。那么对于不常见的单词,如这句话:“Robert Lin is a durian cultivator.”(Robert Lin是一个榴莲培育家)怎么办?榴莲(durian)是一种比较稀罕的水果,这种水果在新加坡和其他一些国家流行。如果对于一个命名实体识别任务,你只有一个很小的标记的训练集,里面甚至可能没有durian(榴莲)或者cultivator(培育家)这两个词。但是如果你有一个已经学好的词嵌入,它会告诉你durian(榴莲)也是水果,就像orange(橙子),并且cultivator(培育家),做培育工作的人其实跟farmer(农民)差不多,那么你就有可能从你的训练集里的“an orange farmer”(种橙子的农民)推断出“a durian cultivator”(榴莲培育家)也是一个人。
词嵌入能够达到上述效果,因为学习词嵌入的算法会考察非常大的文本集(very large text corpuses),可以从网上找到,因此数据集可以是1亿个单词,甚至达到100亿。通过大量无标签文本的训练集,学习这种嵌入表达,可以发现orange(橙子)和durian(榴莲)相近,都是水果,farmer(农民)和cultivator(培育家)相近。尽管你只有一个很小的训练集,也许训练集里有100,000个单词,甚至更小,这就使得你可以使用迁移学习(transfer learning),把从互联网上免费获得的大量的无标签文本中学习到的知识迁移到一个任务中,比如只有少量标记的训练数据集的命名实体识别任务中。这里为了简化Andrew只画了单向的RNN,事实上在命名实体识别任务中应该用一个双向的RNN,而不是这样一个简单的。
如下图我们总结一下用词嵌入做迁移学习的步骤。
(1)第一步,先从大量的文本集中学习词嵌入(一个非常大的文本集)或者可以下载网上预训练好的词嵌入模型。
(2)第二步,你可以用这些词嵌入模型把它迁移到你的新的只有少量标注训练集的任务中,比如说用这个300维的词嵌入来表示你的单词。这样做的一个好处就是你可以用更低维度的特征向量代替原来的10000维的one-hot向量,可以用一个300维更加紧凑的向量。尽管one-hot向量很快计算,而学到的用于词嵌入的300维的向量会更加紧凑。
(3)第三步,当你在你新的任务上训练模型时,在你的命名实体识别任务上,只有少量的标记数据集上,你可以自己选择要不要继续微调(fine-tune),用新的数据调整词嵌入。实际中,只有这个第二步中有很大的数据集你才会这样做,如果你标记的数据集不是很大,通常不会在微调词嵌入上费力气。

1.2 嵌入矩阵
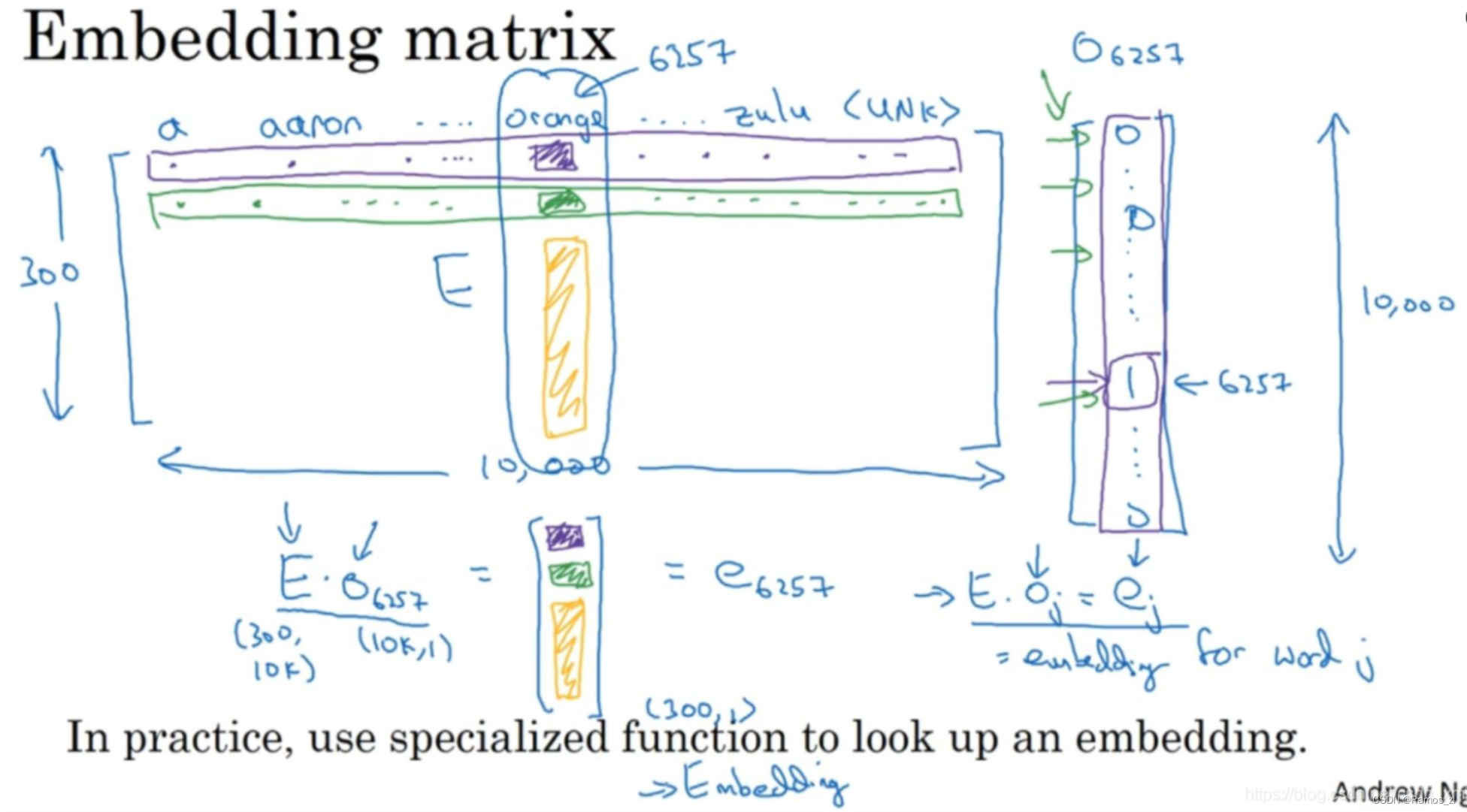
和之前一样,假设词汇表含有10,000个单词,词汇表里有a,aaron,orange,zulu,可能还有一个未知词标记UNK。我们要做的就是学习一个嵌入矩阵E,它将是一个300×10,000的矩阵,如果使用的词汇表里有10,000个,或者加上未知词就是10,001维。这个矩阵的各列代表的是词汇表中10,000个不同的单词所代表的不同向量。假设orange的单词编号是6257,代表词汇表中第6257个单词,我们用符号O_6257来表示这个one-hot向量,这个向量除了第6527个位置上是1,其余各处都为0,显然它是一个10,000维的列向量,它只在一个位置上有1,它的高度和左边的嵌入矩阵的宽度(行数)相等。
假设用嵌入矩阵E去乘以O_6257,那么就会得到一个300维的向量,E是300×10,000的,O_6257是10,000×1的,所以它们的积是300×1的,即300维的向量。以此类推,直到你得到这个向量剩下的所有元素。得到的300维向量我们记为e_6257,这个符号是我们用来表示这个300×1的嵌入向量(embedding vector)的,它表示的单词是orange。
1.3 学习词嵌入
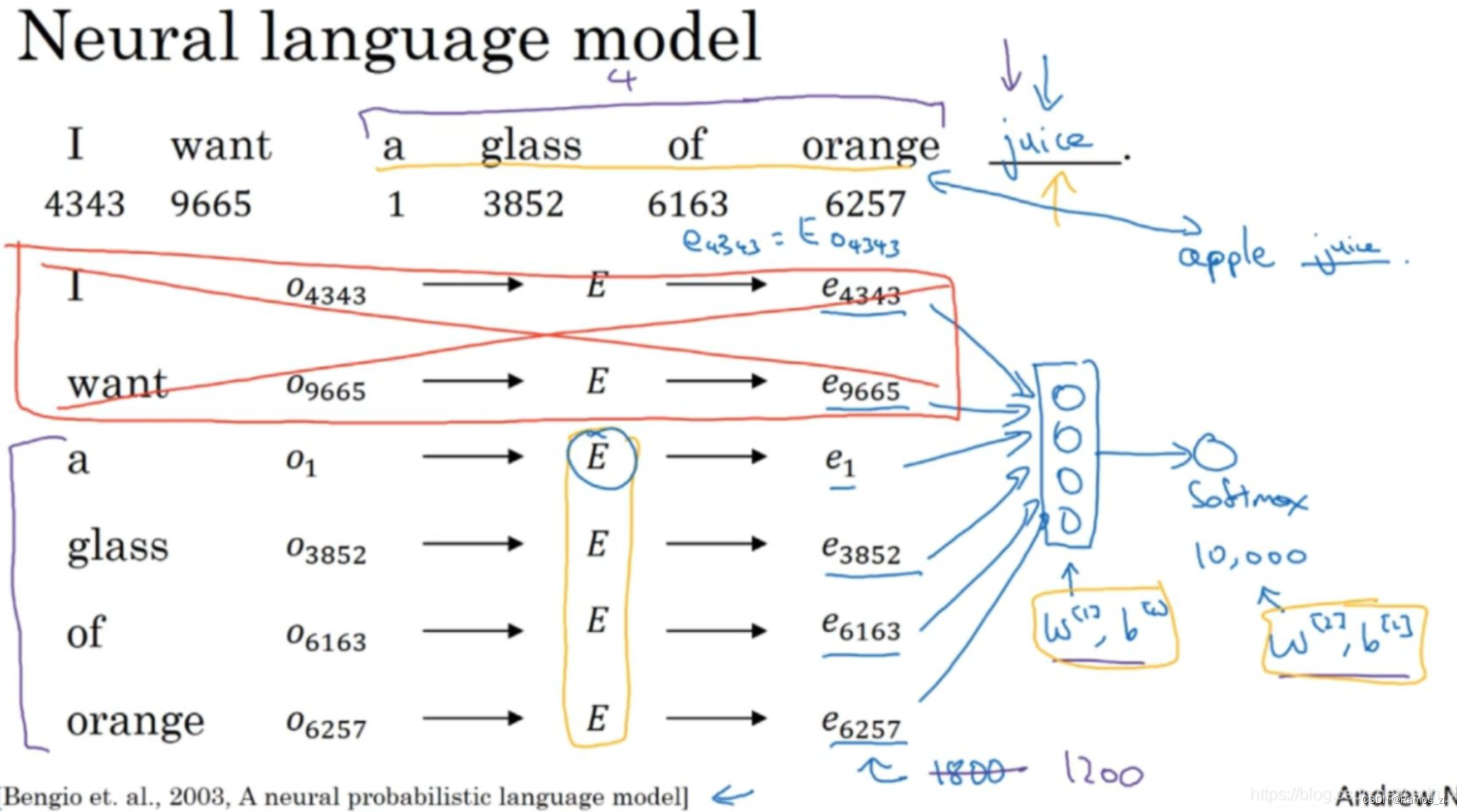
假如构建一个语言模型(language model),并且用神经网络(neural network)来实现这个模型。于是在训练过程中,你可能想要你的神经网络能够做到比如输入:“I want a glass of orange ___.”,然后预测这句话的下一个词。在每个单词下面,都写上了这些单词对应词汇表中的索引。实践证明,建立一个语言模型是学习词嵌入的好方法,Andrew提出的这些想法是源于Yoshua Bengio,Rejean Ducharme,Pascal Vincent,Rejean Ducharme,Pascal Vincent还有Christian Jauvin的这篇论文:A neural probabilistic language model。
下面将介绍如何建立神经网络来预测序列中的下一个单词,首先为这些词列一个表格,每个词都用一个one-hot向量表示。然后生成一个参数矩阵E,用E乘以one-hot向量,得到嵌入向量。于是现在你有许多300维的嵌入向量。我们能做的就是把它们全部放进神经网络中,经过神经网络以后再通过softmax层,这个softmax也有自己的参数,然后这个softmax分类器会在10,000个可能的输出中预测结尾这个单词。假如说在训练集中有juice这个词,训练过程中softmax的目标就是预测出单词juice,就是结尾的这个单词。
实际上更常见的是有一个固定的历史窗口。举个例子,你总是想预测给定四个单词(上图紫色标记)后的下一个单词,注意这里的4是算法的超参数。这就是如何适应很长或者很短的句子,方法就是总是只看前4个单词,所以说我只用这4个单词(a,glass,of,orange)而不去看这几个词(上图红色标记)。如果你一直使用一个4个词的历史窗口,这就意味着你的神经网络会输入一个1200维的特征变量到这个层中,然后再通过softmax来预测输出,选择有很多种,用一个固定的历史窗口就意味着你可以处理任意长度的句子,因为输入的维度总是固定的。所以这个模型的参数就是矩阵E,对所有的单词用的都是同一个矩阵E,而不是对应不同的位置上的不同单词用不同的矩阵。然后这些权重也都是算法的参数,你可以用反向传播来进行梯度下降来最大化训练集似然(maximize the likelihood of your training set),通过序列中给定的4个单词去重复地预测出语料库中下一个单词什么。
1.4 Word2Vec
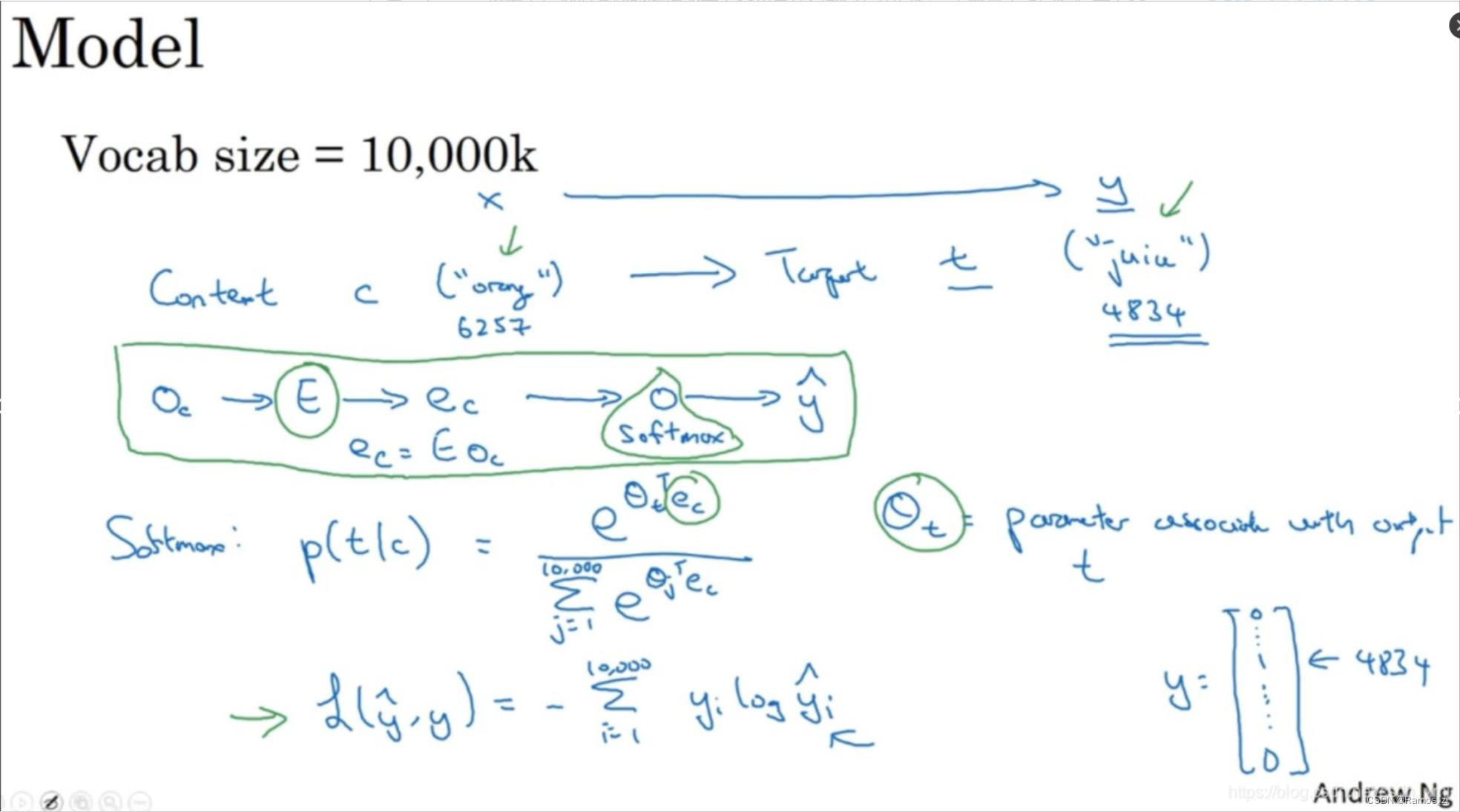
假设在训练集中给定了一个这样的句子:“I want a glass of orange juice to go along with my cereal.”,在Skip-Gram模型中,我们要做的是抽取上下文和目标词配对,来构造一个监督学习问题。上下文不一定总是目标单词之前离得最近的四个单词,或最近的n个单词。我们要的做的是随机选一个词作为上下文词(context),比如选orange,然后随机在一定词距内选另一个词,比如在上下文词前后5个词内或者10个词内,我们就在这个范围内选择目标词。可能你正好选到了juice作为目标词,正好是下一个词(表示orange的下一个词),也有可能你选到了前面第二个词,所以另一种配对目标词可以是glass,还可能正好选到了单词my作为目标词。
于是我们将构造一个监督学习问题,它给定上下文词,要求你预测在这个词正负10个词距或者正负5个词距内随机选择的某个目标词。显然,这不是个非常简单的学习问题,因为在单词orange的正负10个词距之间,可能会有很多不同的单词。但是构造这个监督学习问题的目标并不是想要解决这个监督学习问题本身,而是想要使用这个学习问题来学到一个好的词嵌入模型。
实际上使用这个算法会遇到一些问题,首要的问题就是计算速度(computational speed)。如上图所示,尤其是在softmax模型中,每次你想要计算这个概率,你需要对你词汇表中的所有10,000个词做求和计算,可能10,000个词的情况还不算太差。如果你用了一个大小为100,000或1,000,000的词汇表,那么这个分母的求和操作是相当慢的,实际上10,000已经是相当慢的了,所以扩大词汇表就更加困难了。
这里有一些解决方案,在一些文献中你会看到如分级(hierarchical)的softmax分类器和负采样(Negative Sampling)。
二、序列模型和注意力机制
2.1 seq2seq(sequence to sequence)模型
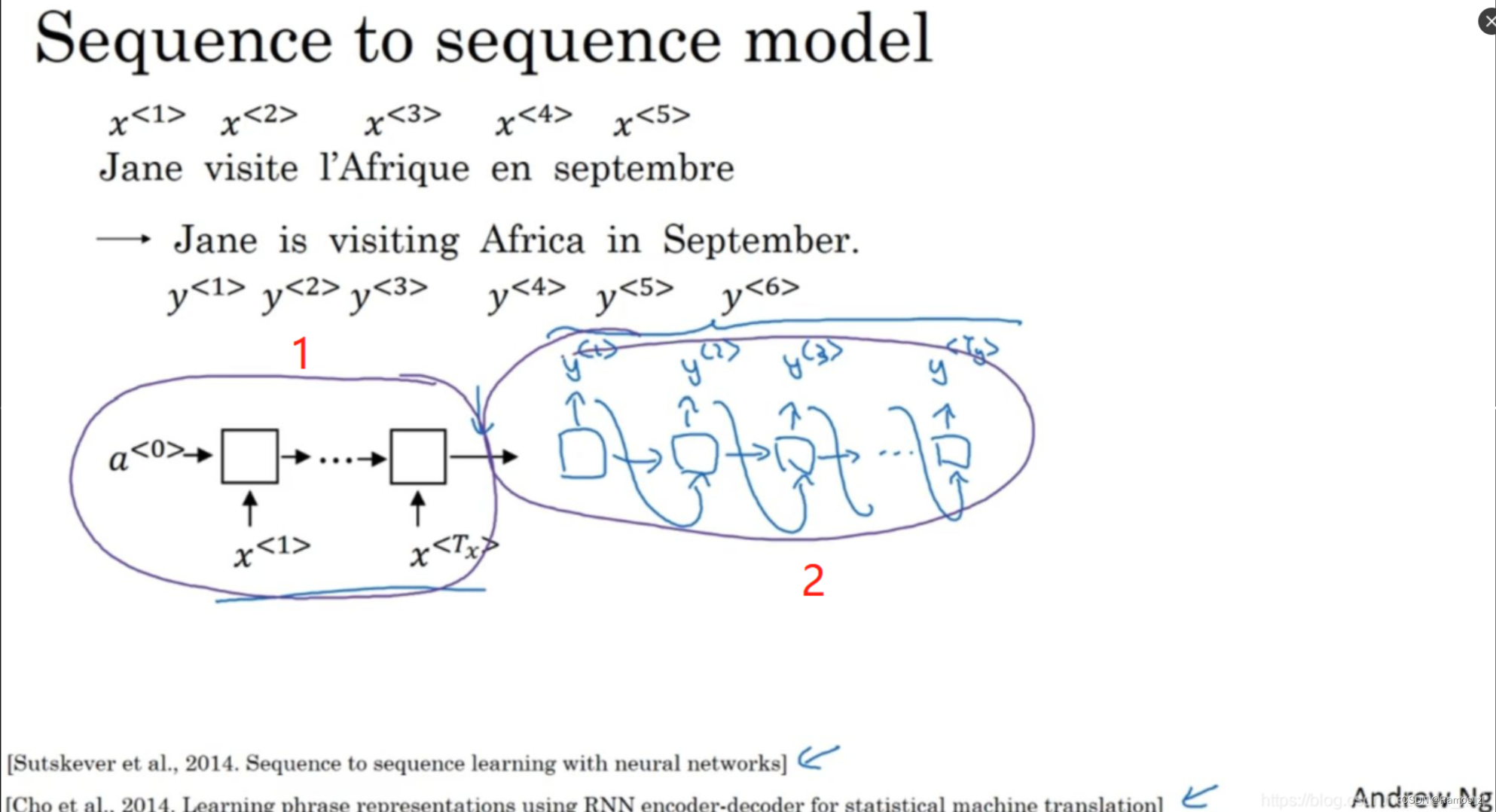
如下图所示,输入一个法语句子 “Jane visite I’Afrique en septembre.”,将它翻译成英语“Jane is visiting Africa in September.”。我们用x
<
1
>
^{<1>}
<1>一直到x
<
5
>
^{<5>}
<5>来表示输入的句子的单词,然后我们用y
<
1
>
^{<1>}
<1>到y
<
6
>
^{<6>}
<6>来表示输出的句子的单词。
首先,我们先建立一个网络,这个网络叫做编码网络(encoder network),这里的RNN的单元可以是GRU和LSTM。每次只向该网络中输入一个法语单词,将输入(input)序列接收完毕后,这个RNN网络会输出(output)一个向量来代表这个输入序列。之后你可以建立一个解码网络(decoder network),它以编码网络的输出作为输入(input),编码网络是左边的黑色部分(记号1),之后它可以被训练为每次输出(output)一个翻译后的单词,一直到它输出序列的结尾或者句子结尾标记。和往常一样我们把每次生成的标记都传递到下一个单元中来进行预测。
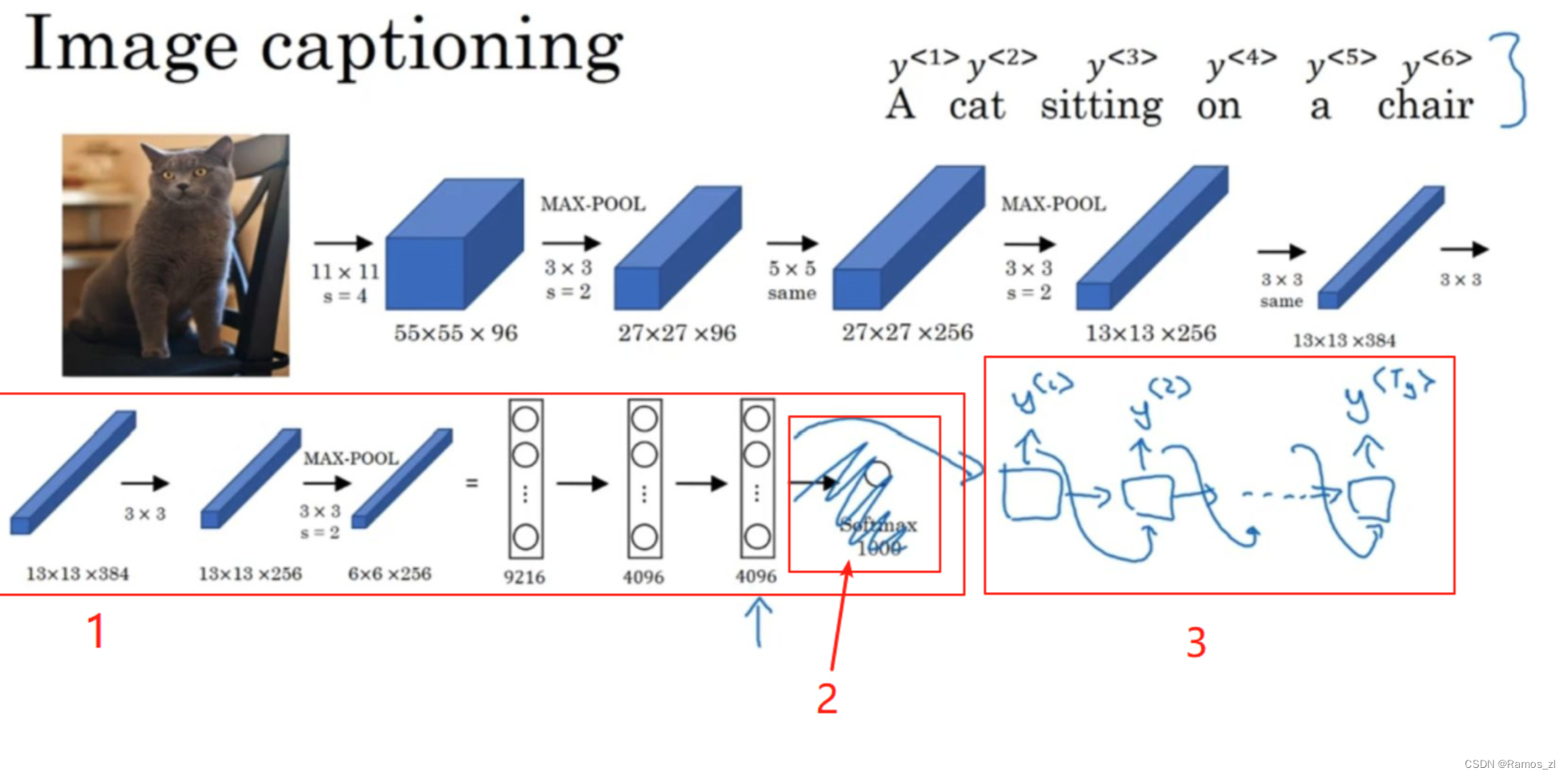
图像描述(image captioning)有类似的结构,给出一张猫的图片,它能自动地输出该图片的描述,一只猫坐在椅子上,那么如何训练出这样的网络?
在之前的学习中,我们知道如何将图片输入到卷积神经网络中,比如一个预训练的AlexNet结构,然后让其学习图片的编码或者图片的特征。现在我们去掉最后的softmax单元,这个预训练的AlexNet结构会得到一个4096维的特征向量(feature vector),表示这只猫的图片,所以这个预训练网络可以是图像的编码网络。现在我们用4096维的向量来表示这张图片,接着把这个向量输入到RNN中,RNN要做的就是生成图像的描述,每次生成一个单词,这和机器翻译中看到的结构很像,现在输入(input)一个描述输入的特征向量,然后让网络生成一个输出序列,或者说一个一个地输出(output)单词序列。
2.2 注意力模型直观理解
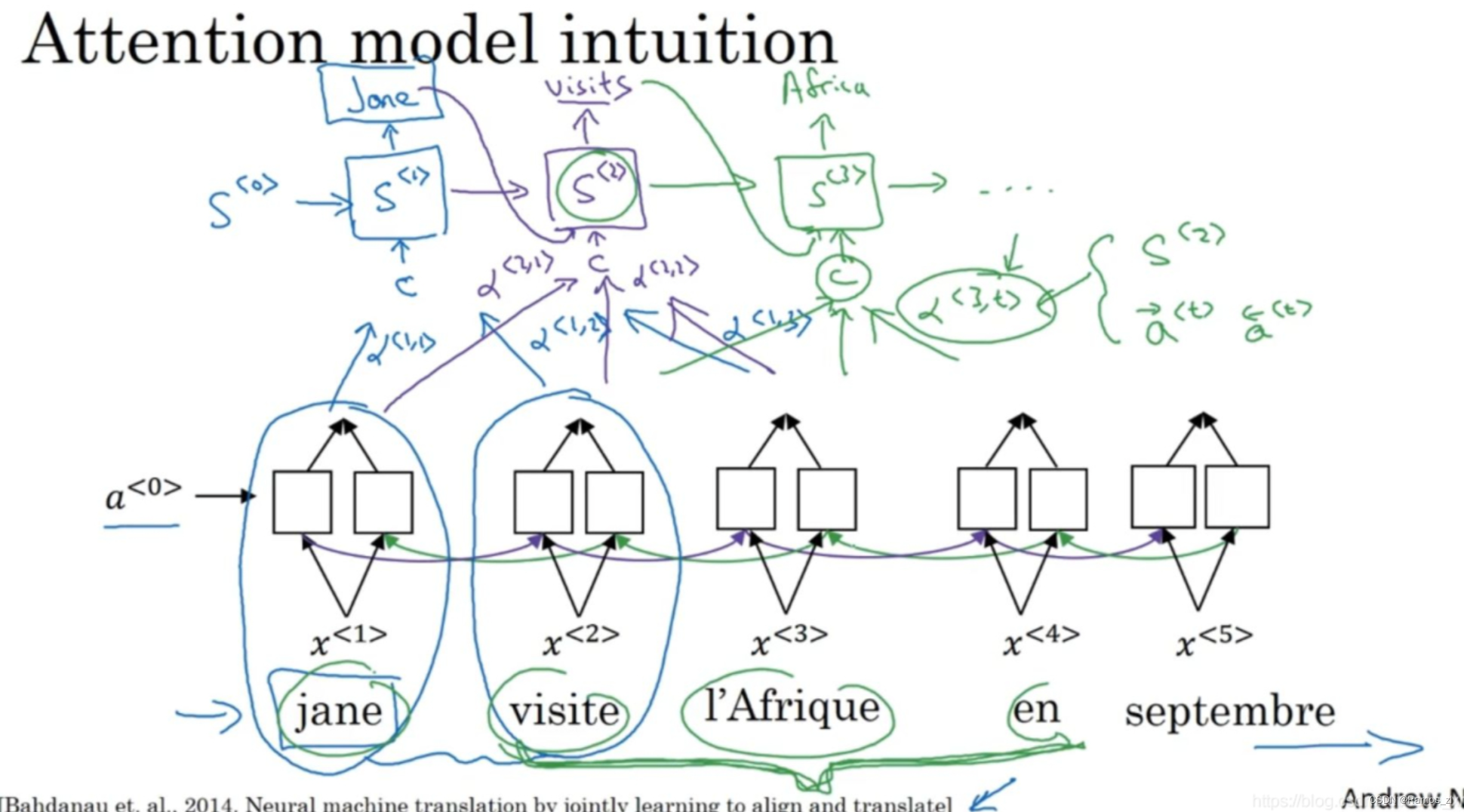
看这个法语:Jane visite l’Afrique en Septembre。(1)假定我们使用一个双向的RNN(a bidirectional RNN),为了计算每个输入单词的的特征集(set of features)。但是我们并不是只翻译一个单词,让我们先去掉上面的Y,然后对于句子里的每五个单词,计算一个句子中单词的特征集,也有可能是周围的词生成英文翻译。我们将使用另一个RNN生成英文翻译。用记号S来表示RNN的隐藏状态(the hidden state in this RNN),记为S^<1>。我们希望第一个生成的单词将会是Jane,那么我们应该看输入的法语句子的哪个部分?似乎你应该先看第一个单词或者它附近的词,但是别看太远了,比如句尾。
注意力模型就会计算注意力权重(a set of attention weights)。用α ^ <1,1>来表示生成第一个词时应该放多少注意力在这个第一块信息处。α^ 1,2> 表示计算第一个词Jane时,我们应该花多少注意力在输入的第二个词上面。α^ <1,3>同理。注意力权重将评估应该花多少注意力在记号为C的内容上。这就是RNN的一个单元,如何尝试生成第一个词的,这是RNN的其中一步(蓝色标记)。(2)对于RNN的第二步(紫色标记),我们将有一个新的隐藏状态S^<2>,使用一个新的注意力权值集(a new set of the attention weights),α^ <2,1>表示在生成第二个词时应该花多少注意力在输入的第一个法语词jane上, visits就会是第二个标签了(the ground trip label)。α^ <2,2>也同理,花多少注意力在visite词上。当然我们第一个生成的词Jane也会输入到这里,于是我们就有了需要花注意力的上下文,然后会一起生成第二个词,(3)第三步S^<3>(绿色标记),visits也是输入,我们再有上下文C,它取决于不同的时间集(time sets),其他分析过程类似。
总结
词嵌入为自然语言处理提供了有效的文本表示方法,使得模型能够更好地处理文本数据。Seq2Seq模型和注意力机制进一步扩展了深度学习在序列处理任务中的应用范围。Seq2Seq模型通过编码器-解码器结构使得机器翻译、文本摘要等任务变得更加可行,而注意力机制则允许模型自动关注与当前任务相关的信息,提高了模型的性能。这些技术的不断演进推动了自然语言处理领域的创新,未来还将继续为各种文本处理任务提供更强大的工具和方法。

