
- 1Brocade交换机PortErrShow命令er_bad_os各输出项释义
- 2HIve之ORC与Parquet_hive orc parquet
- 3全网最全的网络安全技术栈内容梳理(持续更新中)_网络安全和网站开发维护技术_网络攻防技术栈
- 4智慧在线医疗在线诊疗APP患者端+医生端音视频诊疗并开处方
- 5ElasticSearch 集群添加用户安全认证功能(设置访问密码)_es集群添加密码验证
- 6卡塔尔世界杯 16 强全部出炉,欧洲占半席、亚足联三队出线,淘汰赛有哪些看点?你看好哪支球队晋级?
- 7关于ondraw你该知道的(一)
- 8华为OD机试C卷-- 文本统计分析(Java & JS & Python)
- 9黑马程序员——Java学习笔记--IO流_黑马程序员java io流
- 10(附源码)springboot+基于微信小程序音乐播放器的设计与实现 毕业设计271156_微信小程序音乐播放器毕业论文
初学者怎么入门大语言模型(LLM)?_llm自学
赞
踩
真的想入门大语言模型,只看这一个文章应该是可以入门的。但是修行下去,还是要靠自己的了!
如果你把大语言模型/LLM 当成一门技术来看,那就要看一下这门技术需要什么。
基本要求:
-
开发语言:Python, C/C++
-
开发框架:Numpy/Pytorch/Tensorflow/Keras/Onnx
-
数学知识:线性代数、高数、概率、凸优化
这些东西我们假定你都已经会了,或者熟练使用了。
如果不熟,我建议你自己再学习一下。尤其是数学的几个基本公式,是要学会的。我列一下吧。
数学核心内容
-
「线性代数」:关键概念包括向量、矩阵、特征值和特征向量。重要的公式涉及矩阵乘法、行列式以及特征值方程Av=λv,其中 A是矩阵,v 是特征向量,λ是特征值。
-
「高数」:基本主题是微分和积分,重点是理解极限、导数和积分的概念。函数 f(x) 在点 x的导数由f′(x)=limh→0 f(x+h)−f(x) 给出,基本微积分定理将微分与积分联系起来。
-
「概率」:关键点包括概率公理、条件概率、贝叶斯定理、随机变量和分布。例如,贝叶斯定理由P(A∣B)=P(B∣A)P(A)/P(B)给出,它帮助在发生B 的情况下更新 A 的概率。
-
「凸优化」:关注目标函数为凸函数的问题。关键概念包括凸集、凸函数、梯度下降和拉格朗日乘数。梯度下降更新规则可以表示为 xn+1 =xn −_α_∇_f_(xn ),其中 _α_是学习率。
你可以看到这些相对经常用到的数学,其实没有多难,只要你再看一下记住就好了。
开发框架
Numpy 主要是掌握各种数据的使用方法
Pytorch 与 Tensor、 Keras 就是完成各种网络及训练的方法
你至少要能保证下面的代码里的每一行代码都能完全理解
import torch from torch import nn, optim from torchvision import datasets, transforms from torch.utils.data import DataLoader # Define a transformation to normalize the data transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]) # Load the Fashion MNIST dataset train_dataset = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform) test_dataset = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform) train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False) # Define the neural network structure class FashionMNISTNN(nn.Module): def __init__(self): super(FashionMNISTNN, self).__init__() self.flatten = nn.Flatten() self.linear_relu_stack = nn.Sequential( nn.Linear(28*28, 512), nn.ReLU(), nn.Linear(512, 256), nn.ReLU(), nn.Linear(256, 10), ) def forward(self, x): x = self.flatten(x) logits = self.linear_relu_stack(x) return logits model = FashionMNISTNN() # Define the loss function and optimizer loss_fn = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # Function to train the model def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) model.train() for batch, (X, y) in enumerate(dataloader): # Compute prediction and loss pred = model(X) loss = loss_fn(pred, y) # Backpropagation optimizer.zero_grad() loss.backward() optimizer.step() if batch % 100 == 0: loss, current = loss.item(), batch * len(X) print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]") # Function for testing the model def test(dataloader, model, loss_fn): size = len(dataloader.dataset) num_batches = len(dataloader) model.eval() test_loss, correct = 0, 0 with torch.no_grad(): for X, y in dataloader: pred = model(X) test_loss += loss_fn(pred, y).item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() test_loss /= num_batches correct /= size print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n") # Train the model epochs = 5 for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") train(train_loader, model, loss_fn, optimizer) test(test_loader, model, loss_fn) print("Done!") print("关注微信公众号:佑佑有话说")
- 1
注意,是每一行代码,都能完全理解!!!
Transformer基础
做为 LLM 的基础模型,你要想入门,那对 Transformer 这个模型要了如指掌才成!
而 Transformer 的基本图像就是下面这样的:
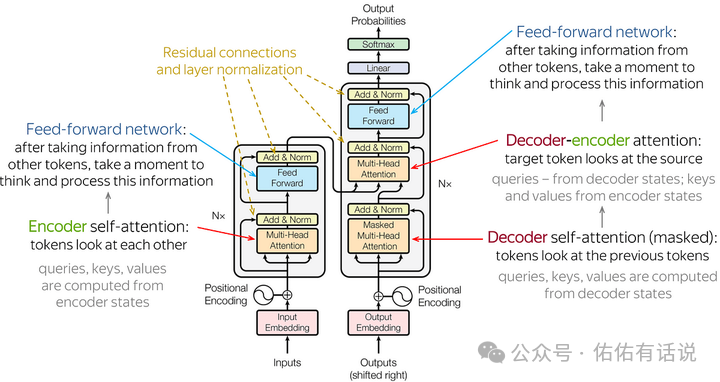
推荐自己手写一个 Transformer 模型,至少要写一个 Attention 的结构。还要看懂下面这个图。你就能体会到一个至简的模型是怎么遵循 Scaling Law的,AGI 可能就在这个简单的重复与变大中了!
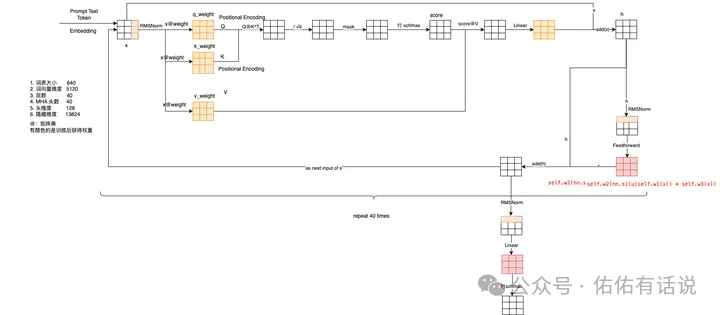
但是Transformer 这么简单的东西怎么就这么厉害了呢?整个大模型已经发展两三年了,如果你再不跟上,可能很快就淘汰了。
「只要你有想法,你就有结果!只要你投入,就会有成就!」
这些是个基础了。但是对于 LLM 来讲吧,如果你想自己继续研究,那可能要接触的就是下面这些东西了。
-
Prompt 工程
-
RAG 技术
-
Fine-Tune 技术
-
LLM Training From Scratch
-
LLM 部署及优化技术
这几项基本上是针对效果及成本的要求从低到高的顺序,也是技术上从简单到难的顺序列出来的。
-
「Prompt 工程」:涉及设计和完善给LLM的Prompt,来得到最准确或最有用的Response。核心原则是通过精心设计的问题或陈述引导LLM生成所需的输出。它需要理解LM的能力和限制,并且通常涉及反复试验以找到最有效的提示。基本技术就是三件事:
指令角色、精确表达、要求输出格式。 -
「RAG 技术(检索增强生成)」:RAG 是一种方法,结合了检索器模型来获取相关文档或数据和生成器模型来产生最终输出。这种技术通过外部信息丰富LLM的响应,提高其准确性和可靠性,特别是对于知识密集型任务。关键是有效整合检索和生成过程,以利用现有知识和生成能力。
你需要了解的就是 LangChain -
「Fine-Tune 技术」:微调涉及在特定数据集或特定任务上轻微调整预训练模型参数以提高性能。这种方法允许利用大型预训练模型并将它们适应于专门的要求,无需进行大量重新训练。本质是保持LM的一般能力,同时为特定用例进行优化。
没啥好说的了,自己准备数据针对特定任务训练 -
「LLM 从零开始训练」:从头开始训练大型语言模型(LLM)意味着在不依赖现有预训练权重的情况下构建模型。这个过程涉及收集大量数据集、设计模型架构,然后在高性能计算资源上长时间训练模型。核心挑战是需要大量的计算能力和数据,以及有效管理训练过程的专业知识。
如果你没有在一个顶级的公司或者研究团队,想想就好了。 -
「LLM 部署及优化技术」:部署和优化LLM涉及有效提供预测的策略,同时有效管理计算资源。这包括模型量化(减少数字的精度以节省内存)、模型修剪(移除不那么重要的权重)和蒸馏(训练一个较小的模型来模仿一个较大的模型)。目标是减少模型的大小和推理时间,而不会显著影响其性能,使其适合生产环境。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/755240?site
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

