
- 1.pkl文件 打开方式 python3
- 2IEEE SLT 2022论文丨如何利用x-vectors提升语音鉴伪系统性能?
- 3宿舍安全用电监控系统解决方案_校园智能电控系统设计
- 4Linux系统安全和应用笔记
- 5开源大模型部署——ollama_ollama部署大模型
- 6开启SSH服务远程登录_ubuntu_ssh服务开启
- 7网站地址栏提示“不安全”该如何解决_浏览器地址栏显示不安全怎么解决
- 8python之Django学习笔记(五)---后台(admin.py)基础参数介绍
- 9Node.js:pnpm - 速度快、节省磁盘空间的软件包管理器_nodejs pnpm
- 10关于我想在windows上编译colmap这件事_colmap boost
终于有人总结了大模型技术!(非常详细)零基础入门到精通,收藏这一篇就够了_大模型入门
赞
踩
1、GPT、LLaMA、ChatGLM、Falcon等大语言模型的技术细节比较
在深入研究LLaMA、ChatGLM和Falcon等大语言模型时,我们不难发现它们在技术实现上有着诸多共通之处与独特差异。例如,这些模型在tokenizer(分词器)的选择上,可能会根据模型的特性和应用场景来定制;位置编码(Positional Encoding)的实现方式也各具特色,对模型性能的影响不容忽视。此外,Layer Normalization(层归一化)和激活函数(Activation Function)的选择与运用,都直接影响到模型的训练速度和准确性。

2、大语言模型的分布式训练技术概览
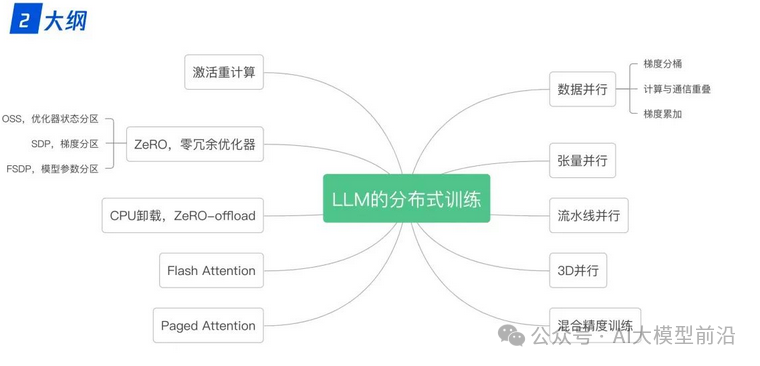
在训练大语言模型时,分布式技术发挥着至关重要的作用。数据并行(Data Parallelism)确保多个处理单元同时处理不同的数据子集,显著提高训练速度。张量模型并行(Tensor Model Parallelism)和流水线并行(Pipeline Parallelism)则针对模型的不同部分进行分布式处理,进一步优化了计算资源的利用率。3D并行则进一步拓展了分布式计算的维度。
同时,零冗余优化器ZeRO(Zero Redundancy Optimizer)和CPU卸载技术ZeRo-offload,通过减少内存占用和提高计算效率,进一步加速了训练过程。混合精度训练(Mixed Precision Training)则通过结合不同精度的计算,平衡了计算速度与内存占用。激活重计算技术(Activation Recomputation)和Flash Attention、Paged Attention等优化策略,则进一步提升了模型的训练效率和准确性。
3、大语言模型的参数高效微调技术探索
在微调大语言模型时,参数的高效利用成为关键。Prompt Tuning、Prefix Tuning和Adapter等方法,通过调整模型的部分参数而非全部,实现了高效的模型定制。LLaMA-Adapter和LoRA等技术则进一步优化了这一过程,使模型能够更快地适应新的任务和领域,同时保持较高的性能。

1. 大语言模型的细节
1.0 transformer 与 LLM
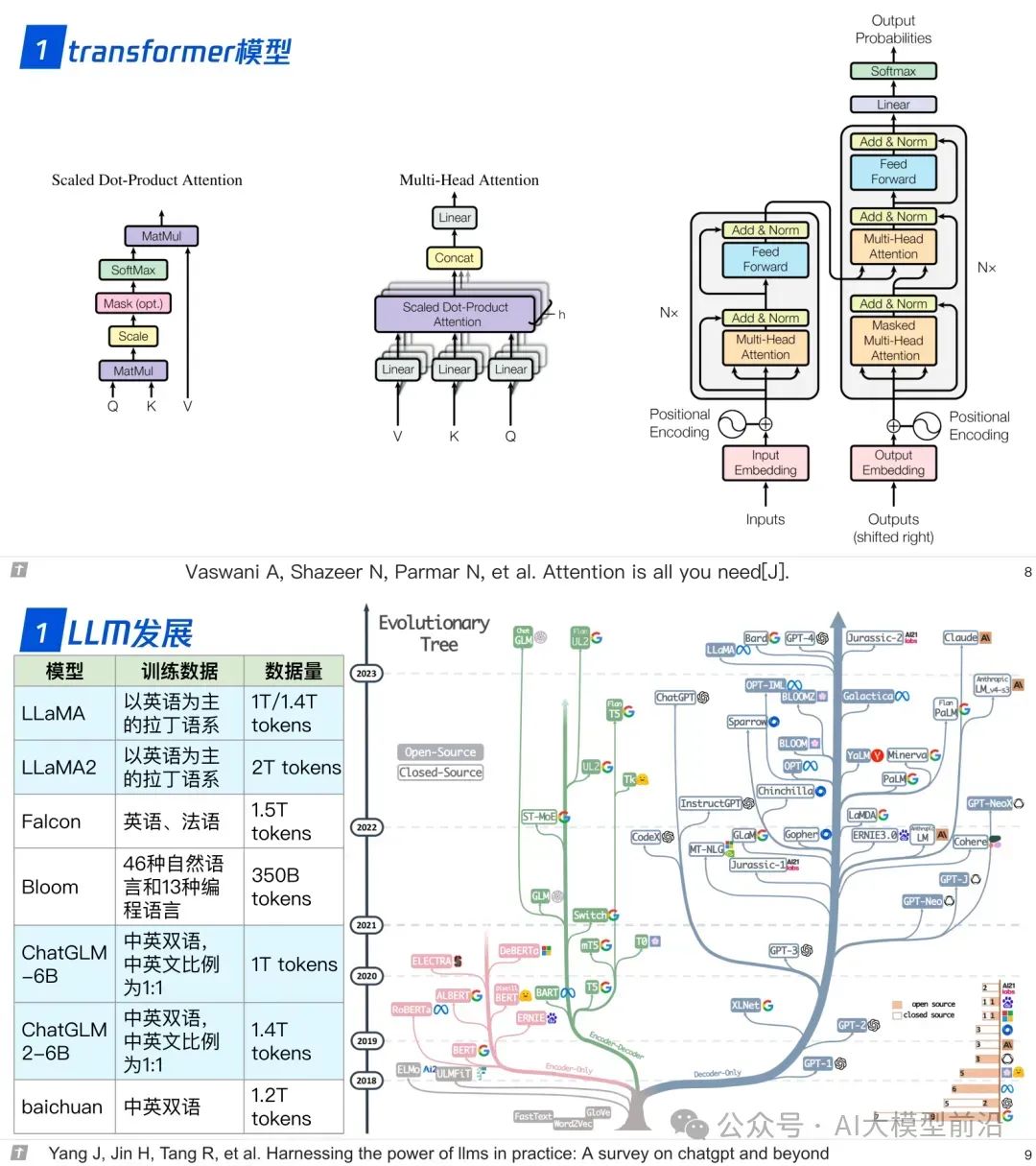
1.1 模型结构

1.2 训练目标

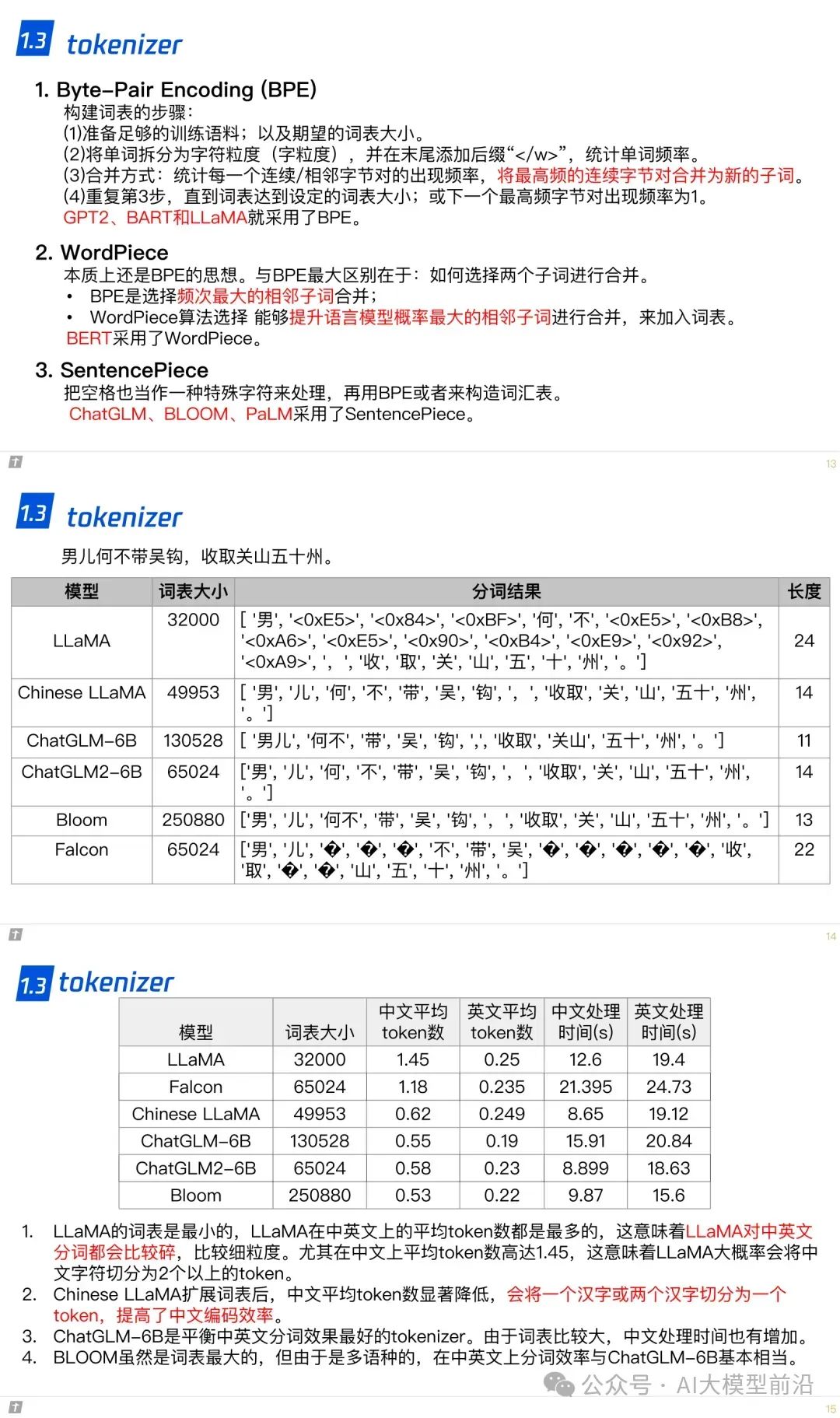
1.3 tokenizer
1.4 位置编码

1.5 层归一化

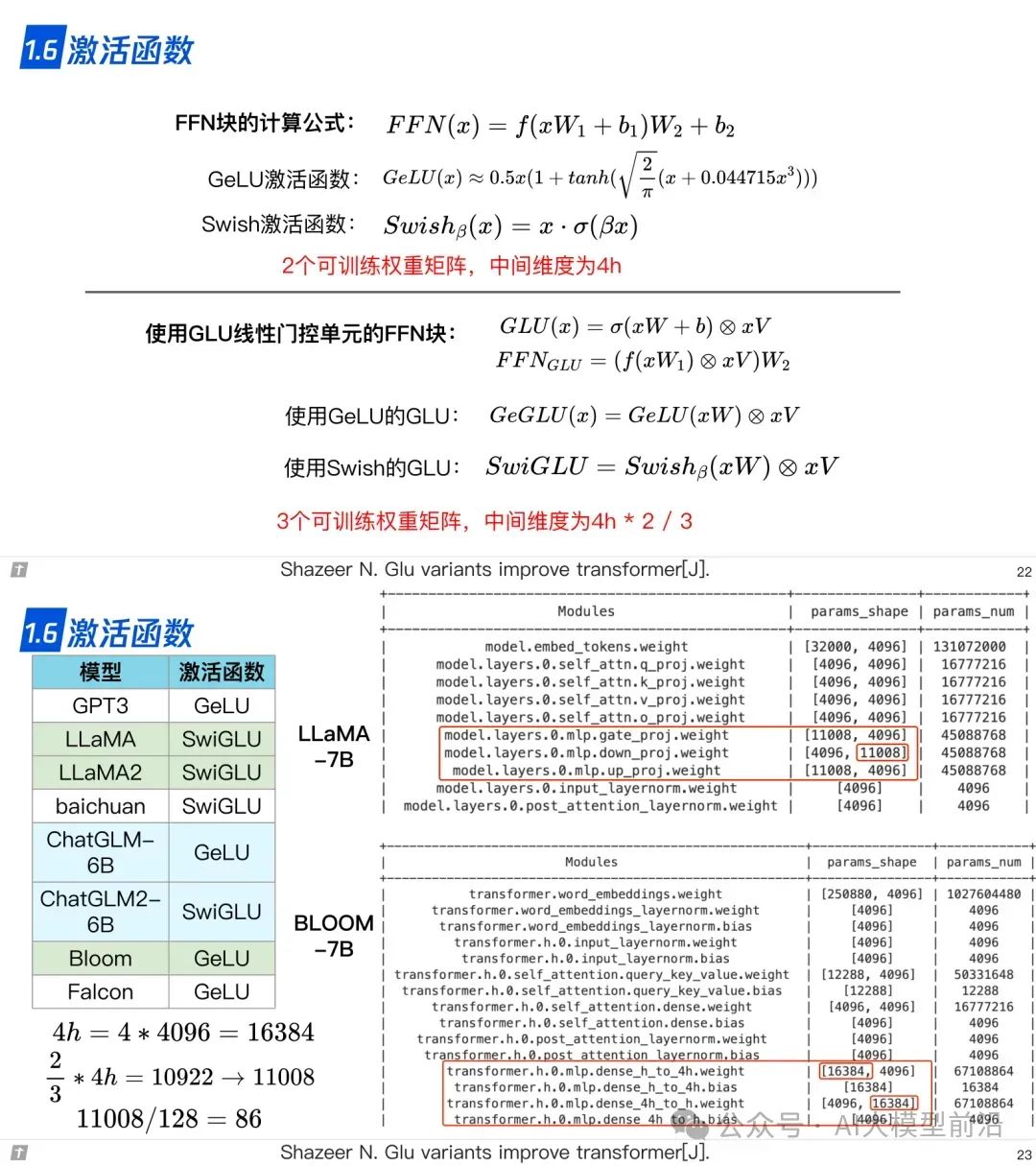
1.6 激活函数
1.7 Multi-query Attention 与 Grouped-query Attention

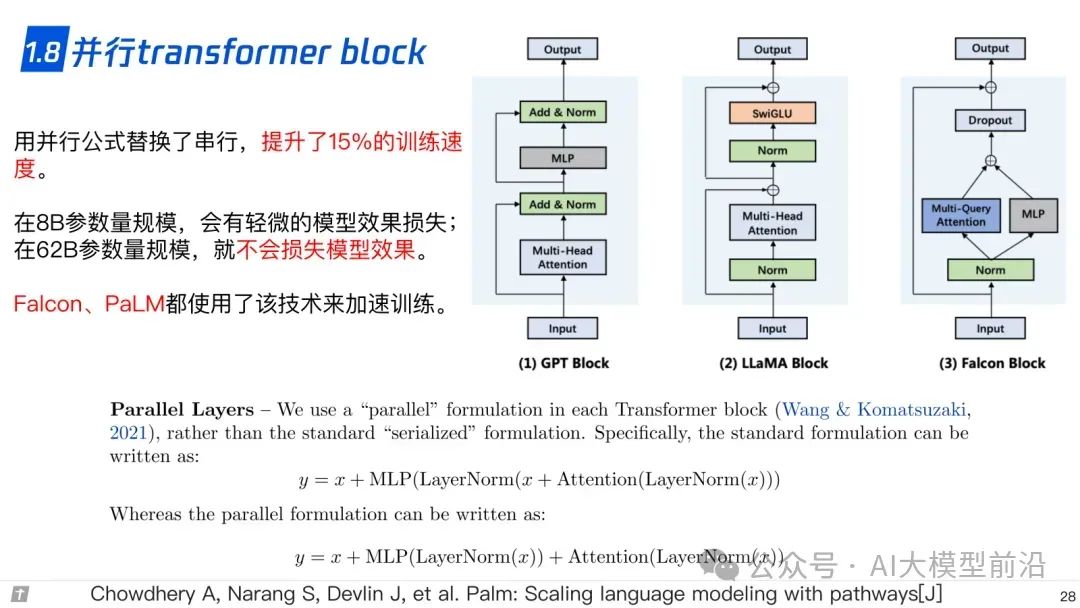
1.8 并行 transformer block
1.9 总结-训练稳定性

2. LLM 的分布式预训练

2.0 点对点通信与集体通信

2.1 数据并行

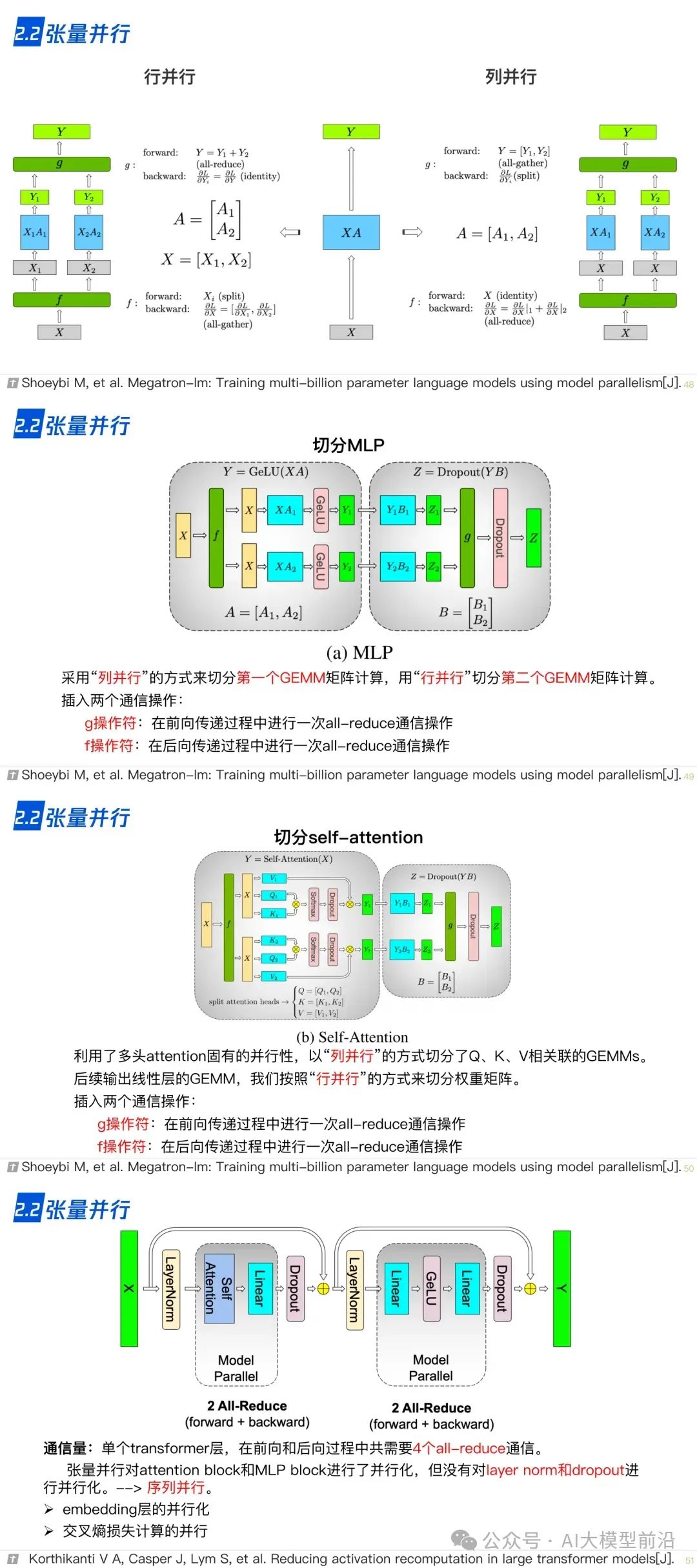
2.2 张量并行

2.3 流水线并行

2.4 3D 并行

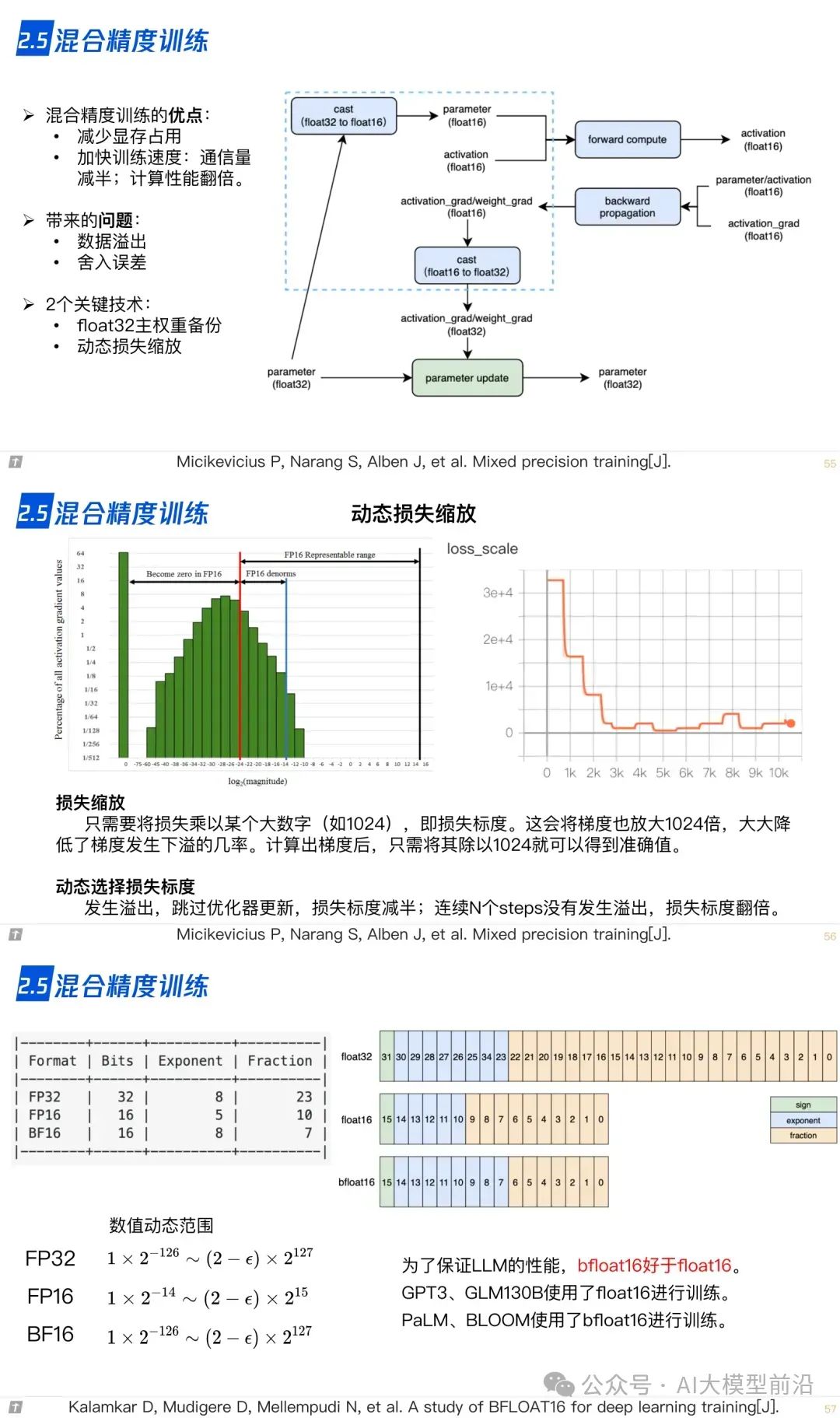
2.5 混合精度训练
2.6 激活重计算

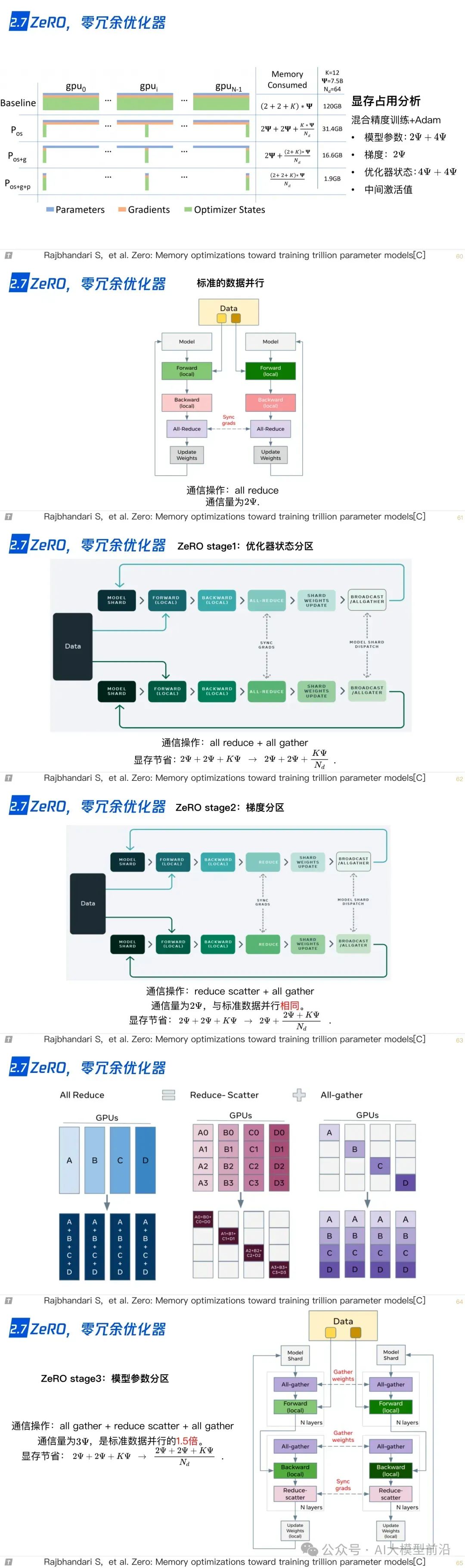
2.7 ZeRO,零冗余优化器
2.8 CPU-offload,ZeRO-offload

2.9 Flash Attention

2.10 vLLM: Paged Attention

3. LLM 的参数高效微调
3.0 为什么进行参数高效微调?

3.1 prompt tuning

3.2 prefix tuning

3.3 adapter

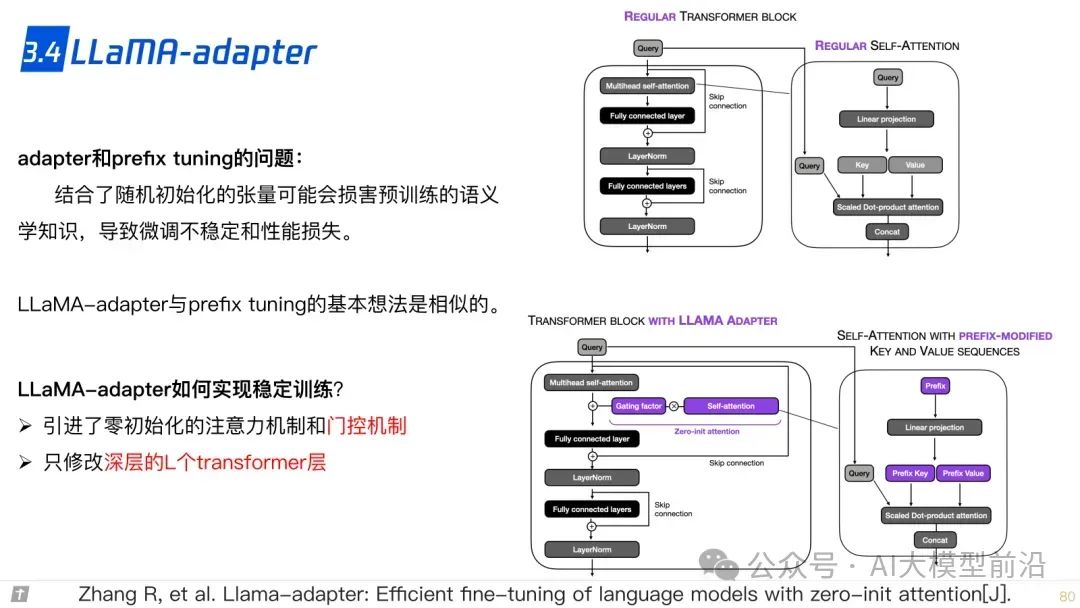
3.4 LLaMA adapter
3.5 LoRA

3.6 实验比较

4. 参考文献

AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

