
- 1【语音识别】搭建本地的语音转文字系统:FunASR(离线不联网即可使用)_funasr本地部署
- 2分布式锁全面总结_分布式锁机制
- 3【Git】版本控制工具——Git介绍及使用_version control 版本控制工具
- 4ViT( Vision Transformer) 多头自注意力机制 计算机视觉领域应用Transformer架构的模型 首次将NLP领域中广泛使用的Transformer模型引入到了CV领域_vit 多头注意力机制
- 5使用eve-ng模拟器进入山石防火墙的web界面_eve默认账号密码
- 6模型Model:文件系统模型QFileSystemModel
- 7Anaconda 下配置 R 环境并配置 Jupyter Notebook 的 R Kernel_anaconda安装r语言
- 8布隆过滤器_布隆过滤器误判
- 9开源开放,共建开发者新生态 | 2022 开发者生态汇_坚持开源开放 建立自主可控生态
- 10uni-app商品分类_uniapp商品分类
Flink HA方案介绍
赞
踩
1.Flink HA方案介绍
每个Flink集群只有单个JobManager,存在单点失败的情况。Flink有YARN、Standalone和Local三种模式,其中YARN和Standalone是集群模式,Local是指单机模式。但Flink对于YARN模式和Standalone模式提供HA机制,使集群能够从失败中恢复。这里主要介绍YARN模式下的HA方案。
Flink支持HA模式和Job的异常恢复。这两项功能高度依赖ZooKeeper,在使用之前用户需要在“flink-conf.yaml”配置文件中配置ZooKeeper,配置ZooKeeper的参数如下:
high-availability: zookeeper
high-availability.zookeeper.quorum: ZooKeeperIP地址:24002
high-availability.storageDir: hdfs:///flink/recovery
- 1
- 2
- 3
YARN模式
Flink的JobManager与YARN的Application Master(简称AM)是在同一个进程下。YARN的ResourceManager对AM有监控,当AM异常时,YARN会将AM重新启动,启动后,所有JobManager的元数据从HDFS恢复。但恢复期间,旧的业务不能运行,新的业务不能提交。ZooKeeper上还是存有JobManager的元数据,比如运行Job的信息,会提供给新的JobManager使用。对于TaskManager的失败,由JobManager上Akka的DeathWatch机制监听处理。当TaskManager失败后,重新向YARN申请容器,创建TaskManager。
Standalone模式
对于Standalone模式的集群,可以启动多个JobManager,然后通过ZooKeeper选举出leader作为实际使用的JobManager。该模式下可以配置一个主JobManager(Leader JobManager)和多个备JobManager(Standby JobManager),这能够保证当主JobManager失败后,备的某个JobManager可以承担主的职责。如下图所示为主备JobManager的恢复过程。
恢复过程

TaskManager恢复
对于TaskManager的失败,由JobManager上Akka的DeathWatch机制监听处理。当TaskManager失败后,由JobManager负责创建一个新TaskManager,并把业务迁移到新的TaskManager上。
JobManager恢复
Flink的JobManager与YARN的Application Master(简称AM)是在同一个进程下。YARN的ResourceManager对AM有监控,当AM异常时,YARN会将AM重新启动,启动后,所有JobManager的元数据从HDFS恢复。但恢复期间,旧的业务不能运行,新的业务不能提交。
Job恢复
Job的恢复必须在Flink的配置文件中配置重启策略。当前包含三种重启策略:fixed-delay、failure-rate和none。只有配置fixed-delay、failure-rate,job才可以恢复。另外,如果配置了重启策略为none,但job设置了Checkpoint,默认会将重启策略改为fixed-delay,且重试次数是配置项“restart-strategy.fixed-delay.attempts”配置为“Integer.MAX_VALUE”。
三种策略的具体信息请参考Flink官网:https://ci.apache.org/projects/flink/flink-docs-release-1.15/dev/task_failure_recovery.html。配置策略的参考如下:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
- 1
- 2
- 3
以下场景的异常,都会导致job重新恢复:
- 当JobManager失败后,所有Job会停止,直到新的JobManager起来后,所有Job恢复。
- 当某一TaskManager失败后,这个TaskManager上的所有作业都将停止,然后等待有可用资源后重启。
- 当某个Job的Task失败后,整个Job也会重启。
说明: 有关Job的配置重启策略,具体内容请参见https://ci.apache.org/projects/flink/flink-docs-release-1.15/ops/jobmanager_high_availability.html。
2.组件的关系
Flink支持基于YARN管理的集群模式,在该模式下,Flink作为YARN上的一个应用,提交到YARN上执行。Flink基于YARN的集群部署如下图所示。
Flink基于YARN的集群部署
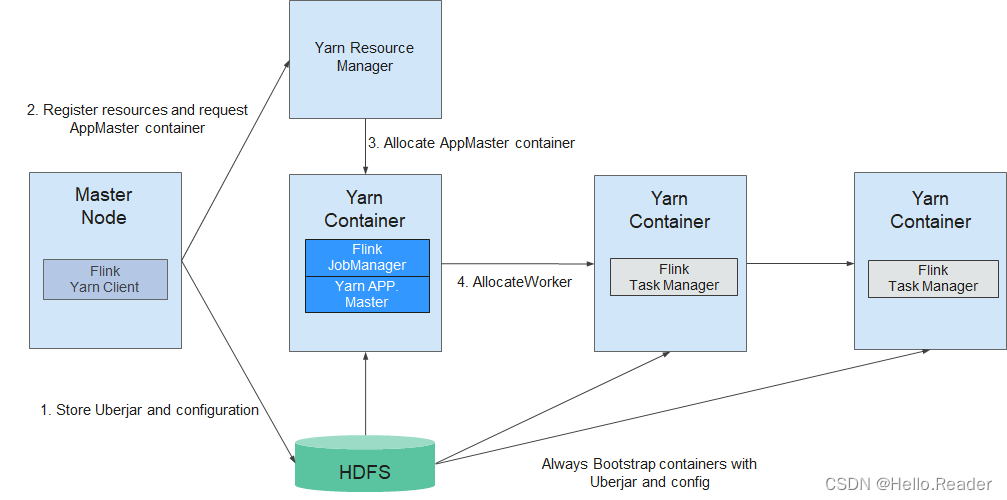
- Flink YARN Client首先会检验是否有足够的资源来启动YARN集群,如果资源足够的话,会将jar包、配置文件等上传到HDFS。
- Flink YARN Client首先与YARN Resource Manager进行通信,申请启动Application Master(以下简称AM)的Container,并启动AM。等所有的YARN的Node Manager将HDFS上的jar包、配置文件下载后,则表示AM启动成功。
- AM在启动的过程中会和YARN的RM进行交互,向RM申请需要的Task Manager Container,申请到Task Manager Container后,启动TaskManager进程。
- 在Flink YARN的集群中,AM与Flink JobManager在同一个Container中。AM会将JobManager的RPC地址通过HDFS共享的方式通知各个TaskManager,TaskManager启动成功后,会向JobManager注册。
- 等所有TaskManager都向JobManager注册成功后,Flink基于YARN的集群启动成功,Flink YARN Client就可以提交Flink Job到Flink JobManager,并进行后续的映射、调度和计算处理。

