
- 1深度学习中2D检测
- 2腾讯新预训练模型LP-BERT
- 3机器学习实验三:logistic回归_logistic 回归实验
- 4人工智能与数据分析:新时代的趋势和机会_数据分析和人工智能
- 5C# 集合(二) —— List/Queue类
- 6Java开发工具:IDEA 2023.3(Win&Mac)中文激活版_mac idea 激活
- 7pytest(12): 三种参数化方案_pytest 参数化
- 8matlab绘图和基础信号分析,电子科技大学信号处理实验1 - 信号的基本表示及时域分析...
- 9yolov5v7v8目标检测增加计数功能--免费源码_yolov8怎么计数一张图片中检测框
- 10UE4-UMG_ue4 umg
一篇文章深入理解分布式锁_分布式锁卡死系统
赞
踩

分布式应用经常会遇见并发问题,如果并发问题处理不好,会产生数据的异常问题,这是一个程序的致命问题,所以对于并发问题,必须的设计一个好的方法来处理它,分布式锁就是解决并发问题的一个比较常用的手段。
一、并发问题的引入
假设这里有一个分布式应用,它拥有多个客户端,每个客户端都会对存储在Redis中的数据进行计算并修改,计算的前提是获取到最新的数据,然后进行计算,最后写回Redis。在一个不存在并发的程序中,程序可以直接读取Redis中的数据进行计算并写回结果,也不会产生什么问题,因为计算的过程是一个串行的过程,但是如果在一个并发环境中,多个客户端完全存在并行读取,并行写入的情景,那么就可能会产生并发问题,导致最终计算的数据产生偏差。

上图就展示了两个客户端同时读取Redis中的数据并计算后写回Redis的场景,因为没有加锁控制,那么最终Redis中存储的结果必然会与单线程读写两次计算的结果产生差异,这种差异往往是无法容忍的差异。如果有某种手段加以控制,保证在同一时间段内只能有一个线程(客户端)来操作Redis中的数据,那么这个并发问题就会得到解决。分布式锁就是用来解决这类问题的,保证了同一时间内线程操作的原子性。所谓的原子性,就是在同一时间内,某个共享变量只能由一个线程来操作,并且从线程读取该变量开始直到结束,不会发生线程调度或者共享变量被其他线程改变。
二、分布式锁的基本实现原理
实现分布式锁所使用到的中间件有很多,比如Redis、Zookeeper、数据库乐观锁等。本文讲解的分布式锁是基于Redis来实现的,揭开分布式锁的面纱,其本质就是线程(客户端)在Redis中占“坑位”。当一个线程占据了Redis中指定key,也就是为该key加锁,那么其他线程只能等待该线程释放锁后才可以继续争夺。
Redis提供了强大易懂指令来操作数据,为了读者理解分布式锁的基本实现原理,这里采用循序渐进的方式来介绍。在Redis中,“占坑”一般使用setnx指令来执行,该指令的意思是set if not exist,也就是说只允许一个客户端占坑,当key被其他客户端占用了的话,那么其他客户端必须等待key被删除后才可以继续占。
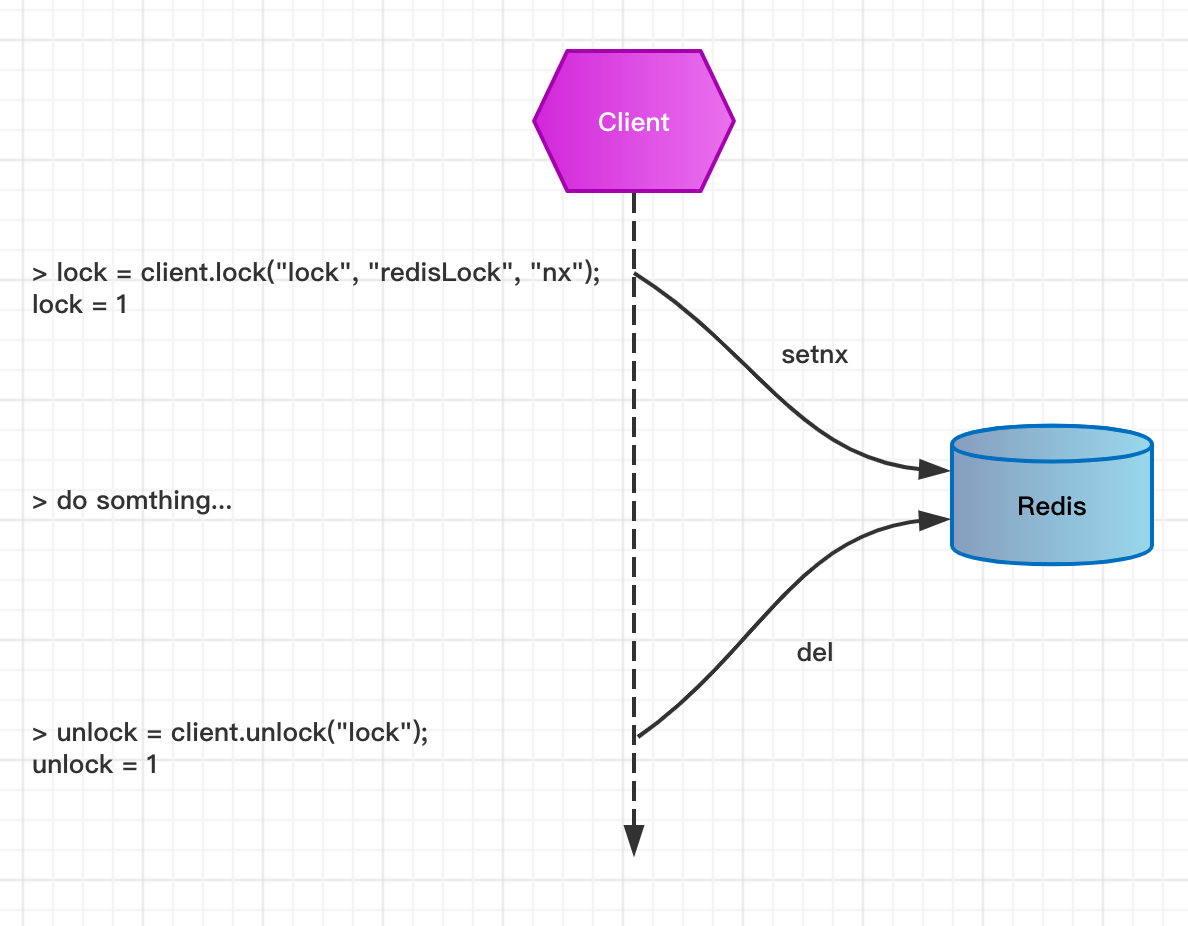
把上图翻译到redis中就是执行了两条命令,分别是:
127.0.0.1:6379> setnx lock redisLock
(integer) 1
// do something....
127.0.0.1:6379> del lock
(integer) 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
细心的读者就会发现一个问题,使用这种方式实现的分布式锁,有可能会发生死锁的情况,客户端在调用加锁方法后,向Redis中存储了key为lock的锁,此时其他客户端将无法再次存储key为lock的锁。虽然达到了占锁的目的,但是如果客户端在加锁后,还没到达解锁的步骤就发生了异常,那么解锁的操作将无法执行,此时Redis中将会一直存储着key为lock的锁,这样就陷入了死锁,锁永远得不到释放。
读者可能会提出,给锁加上一个过期时间,这样的好处就是客户端在解锁之前发生了异常,也不会影响锁的释放,在过期时间结束之后,锁就会自动释放。比如:
127.0.0.1:6379> setnx lock redisLock
(integer) 1
127.0.0.1:6379> expire lock 10
// do something....
127.0.0.1:6379> del lock
(integer) 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上面的逻辑看似是不会发生死锁,其实不然,如果在setnx和expire命令之间,客户端发生了异常,可以是物理异常,比如断电,或者人为代码异常,那么设置过期时间的指令就不会执行,最后还是会发生死锁。这种情况发生的死锁,其根本原因是setnx和expire是两条指令,不具有原子性,客户端在执行完第一条指令后,不能保证第二条指令一定能正常执行。也许有人会想到Redis事务机制,但是事务机制是为了保证多条命令要么同时成功,要么同时失败,而这里的expire指令是依赖setnx指令的执行结果的,如果setnx指令没有成功抢到锁,那么expire指令不应该去执行。
为了解决这个问题,在Redis的2.8版本及更新版本,为set命令加入了扩展参数,使得set命令的扩展参数融合了setnx和expire两条指令,使得两者成为一条原子指令,解决了上面的所有问题。具体指令如下所示:
127.0.0.1:6379> set lock redisLock ex 10 nx
(integer) 1
// do something....
127.0.0.1:6379> del lock
(integer) 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
即使客户端在加锁后发生了异常,也不担心发生死锁,因为到了过期时间,占据的锁会自动释放,这就大大提高了分布式锁的安全性。其实这么实现还是有问题的,假设客户端获取到分布式锁以后,执行中间操作的时间较长,超过了过期时间,那么也会自动释放锁,那么其他客户端还是会“乘虚而入”,直接抢夺到分布式锁。那么这个分布式锁就需要被设计成为可重入性的,也就是指客户端持有锁的情况下再次请求加锁,如果一个锁支持同一个客户端的多次加锁请求,那么这个锁就是可重入性的。在Java中,ReentrantLock就是一个可重入锁,那么在设计分布式锁的时候可以参考ReentrantLock的设计思想。
接下来,我们一起来研究一下比较常用的基于Redis的分布式锁框架Redisson的基本原理,最后我们一起实现一个简易的分布式锁。
三、Redisson基于Redis分布式锁的底层原理
Redisson提供的分布式锁的解决方案,其设计分布式锁的基本原理值得我们学习。Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还实现了可重入锁(Reentrant Lock)、公平锁(Fair Lock)、联锁(MultiLock)、 红锁(RedLock)、 读写锁(ReadWriteLock)等,还提供了许多分布式服务。Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。Redisson的优秀特性很多,不是一篇文章能描述清楚的,本小节将着重分析RedissonLock的基本原理,它基于Redis Master/Slave模式基本原理图如下所示:
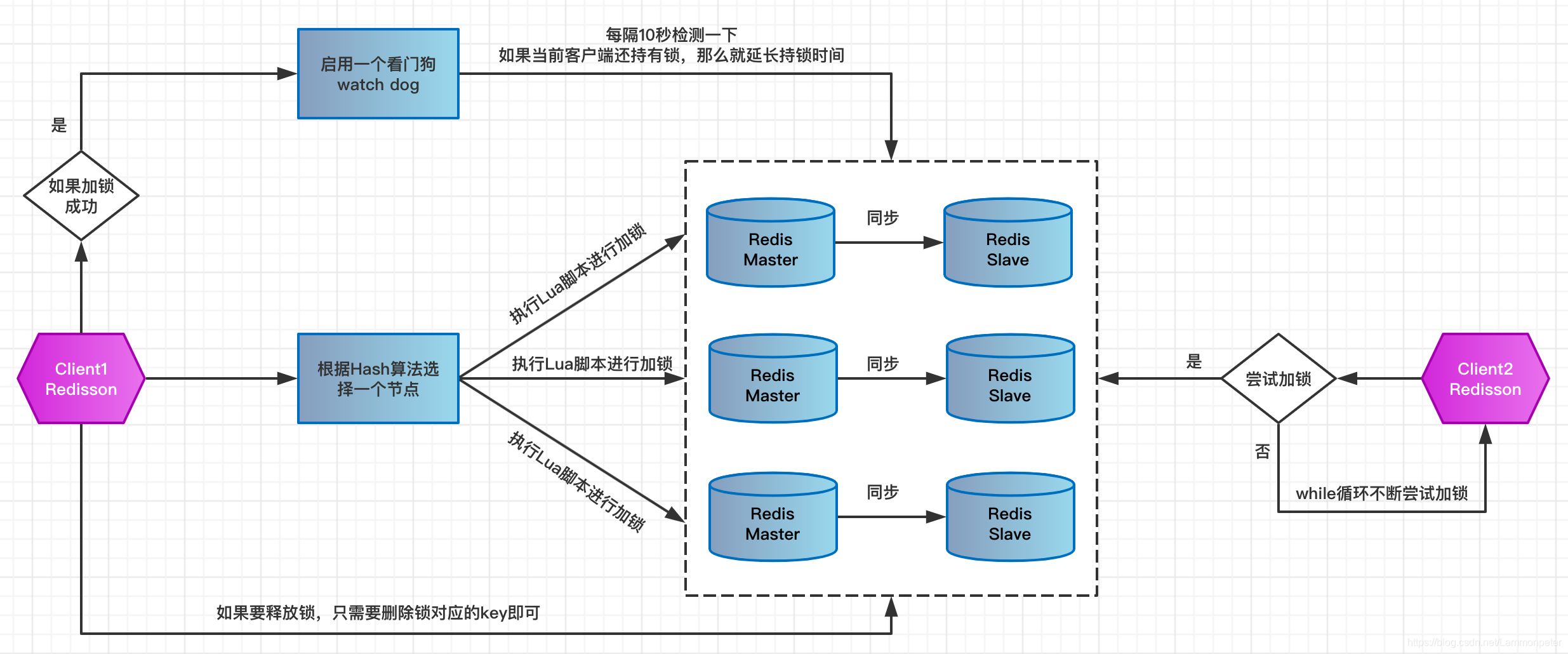
上面这幅图简易地描述了客户端获取锁以及释放锁的基本过程,现在我将基本的过程描述出来,后续将进入到RedissonLock的源码里进行分析,本文分析的Redisson的版本是3.12.3。
3.1 加锁机制
某个客户端需要加锁,那么它需要到Redis集群中去占坑,它通过Hash算法选择出一个节点的一台机器,然后将执行获取锁的Lua脚本发送到该Redis服务上进行执行,具体的Lua脚本基本如下所示:
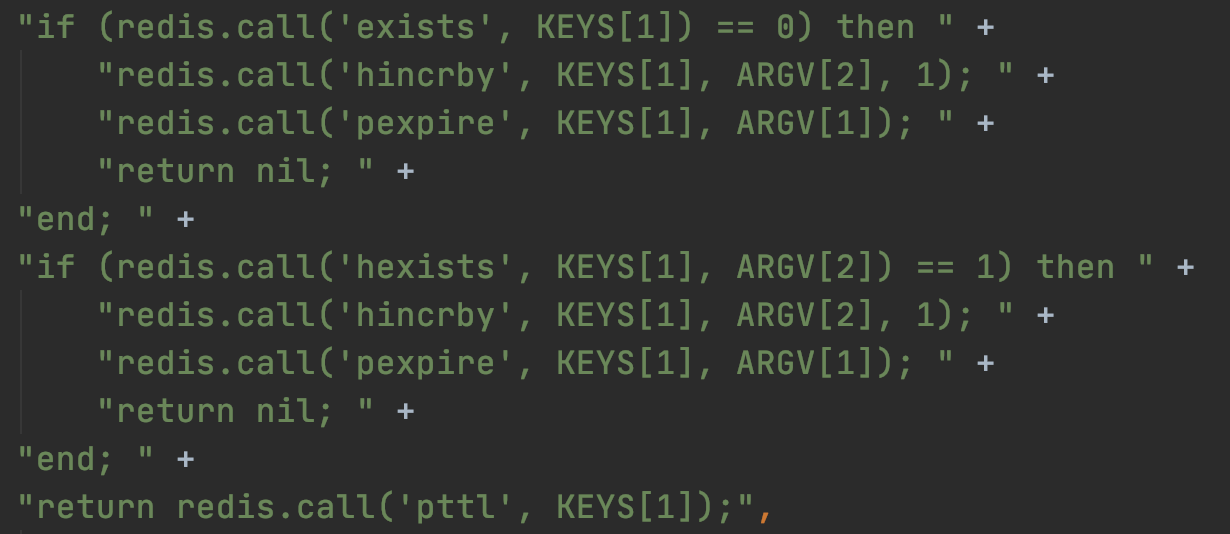
使用Lua脚本的好处不言而喻,因为某些逻辑不方便在客户端来实现,因为客户端存在诸多不稳定因素,比如客户端成功设置了key到Redis中,但是发生了异常,后续的设置过期时间和解锁都不会在继续,Lua脚本的存在解决了这个问题,将多个原子操作写到Lua脚本中,封装成一个原子操作,从而保证了这段复杂业务逻辑执行的原子性。
Redisson分布式锁采用的Redis数据结构是hash,现在来解释一下这段Lua脚本的基本参数:
- 首先判断存储的key是否存在,这里的KEYS[1]就是
RLock lock = redisson.getLock("redisLock");中的redisLock,如果不存在,则进入到设置key的逻辑中。 - ARGV[2]代表的是加锁的客户端的ID,一般是代表客户端的UUID和线程ID组成的字符串,类似于
b8402e6b-4802-4f70-858e-8b5998d68449:1,这样做的好处是在解锁的时候即区分了客户端,也区分了线程。 - ARGV[1]代表的就是锁key的默认有效时间,默认30秒。
给大家解释一下基本流程,第一段if判断语句,就是用exists redisLock命令判断一下,如果你要加锁的那个锁key不存在的话,你就进行加锁。加锁其实就是利用Redis的hash结构设置值,键为客户端ID(包含线程ID),值就是整型数值,默认值为1,后续该客户端有多次加锁请求 ,那么将自增,自增的幅度为1,理解为可重入锁。紧接着就设置key为redisLock的hash结构数据的过期时间,默认为30秒。第一个if全部完成的话,那么就返回nil。如果key已经存在,且客户端ID(包含线程ID)都相等,那么说明是同一客户端重复获取锁,那么就直接将键(客户端ID)对应的值+1,并延长锁的有效时间,完成之后,返回nil。如果key被其他客户端占据,那么就返回key的剩余有效时间。然后根据其他的相关判断,是否需要while循环来尝试加锁。
3.2 watch dog自动延期机制
watch dog我们可以翻译为看门狗,Redisson引入的看门狗机制,是一个自动延期key有效期的机制,客户端加锁后的有效期是30秒,加锁成功后会立马启用一个看门狗线程,它是一个后台线程,会每隔10秒来检测一下,如果客户端还持有锁,那么将自动延长锁的有效时间。
3.3 释放锁机制
客户端如果执行了lock.unlock(),就会向Redis发送释放分布式锁的指令,此时的业务逻辑也是非常简单的。其实说白了,就是每次都对redisLock数据结构中的那个加锁次数减1。如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:del redisLock命令,从redis里删除这个key。后续其他客户端就可以正常获取到锁了,这就是开源框架Redisson提供的RedissonLock的基本原理。
3.4 Redis分布式锁的缺点
其实上面那种方案也是存在问题的,假设客户端1对某个Redis Master写入了redisLock锁,此时Redis Master会异步将对应的数据复制给Redis Slave实例,但是存在在复制过程中Master宕机的可能性,那么一旦发生Master实例的宕机,那么异步复制必然失败,那么此时主备切换,原先的Slave实例变成了Master实例,但是此时新的Master实例却没有同步到锁信息,这就给其他客户端提供了上锁的机会,一旦上锁成功,就会导致多个客户端对一个分布式锁完成了加锁。这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。所以这个就是Redis Cluster,或者是Redis master/slave架构的主从异步复制导致的Redis分布式锁的最大缺陷:在Redis Master实例宕机的时候,可能导致多个客户端同时完成加锁。
了解更多干货,欢迎关注我的微信公众号:爪哇论剑(微信号:itlemon)


