- 1《2022-2023中国人工智能计算力发展评估报告》发布_人工智能行业应用渗透度
- 2解决方案: sqlserver 2008登陆时, 出现服务器主体 "xxxcom" 无法在当前安全上下文下访问数据库 "db_xxx_com"。_载入 sqlserver2008 主体失败
- 3web开发后端技能简历_通过这6门课程提高您的Web开发技能
- 4ubantu系统更换镜像源(出现E: 无法定位软件包 yum)_command 'yum' not found, did you mean:
- 5Ubuntu配置中文环境_ubuntu 如何设置中文环境
- 6微信公众号接入讯飞星火大模型_python sparkweb
- 7将图片合理分配到n个文件夹_照片文件夹合理明明
- 8JavaScript Class类详解_js class
- 9python3入门小题目_实现isprime()函数,参数为整数,如果整数是素数
- 102021计算机视觉-包揽所有前沿论文源码 -上半年_wacv 商汤
23. Opencv——图像拼接项目_cv2.surf_create()
赞
踩
特征检测的基本概念
应用场景:
1.图像搜索,如以图搜图,提取图片中的主要特征点进行搜索
2.拼图游戏
3.图像拼接,将两张有关联的图拼接到一起

拼图方法:
1.寻找特征
2.特征点唯一,可追踪,能比较
3.平坦部分很难找到它在原图中的位置
4.边缘相比平坦要好找一些,但也不能一下确定具体位置
5.角点可以一下就能找到其在原图的位置
什么是特征?
图像特征就是指有意义的图像区域,具有独特性、易于识别性,比如角点,斑点以及高密度区
角点
在特征中最重要的是角点
灰度梯度的最大值对应的像素、两条线的交点、极值点(一阶导数最大值,但二阶导数为0)
Harris角点(常用的方法)
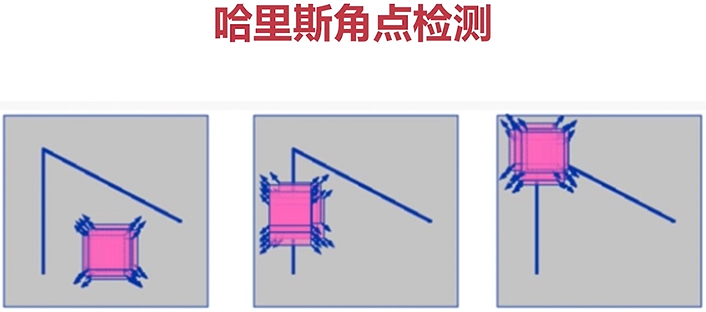
第一种情况:对于这个窗口来说,它可以朝任何方向进行移动,如果在这个窗口范围内它向任何一块方向移动之后,窗口内的像素没有任何的变化,说明这是一个平坦的图片,也就是说在这张图片中没有角点。
第二种情况:如果这个检测窗口在一条边沿上移动,虽然这个边缘与周围的像素不同,但是由于它上下移动,所以其中心点像素不会发生改变,线上及左右两边也不会发生改变,当检测窗口左右移动时像素有变化,则为一条边缘。
第三种情况:检测窗口在一个焦点上
- 光滑地区:无论向哪里移动,衡量系数不变
- 边缘处:垂直边缘移动时,衡量系数变化剧烈
- 在交叉点处,无论往那个方向移动,衡量系数都变化剧烈
Harris角点检测API
注:角点检测应为一张灰度图
cornerHarris(img, dst, blockSize, ksize, k)
dst 输出结果(检测到焦点时,输出矩阵)
blockSize 检测窗口的大小,设置的窗口越大,敏感度越高
ksize Sobel(索贝尔)的卷积核,朝着横向或者纵向进行卷积,卷积核一般设置为3
k 权重系数,经验值,一般取0.02~0.04之间
- import cv2
- from matplotlib.pyplot import gray
- import numpy as np
-
- blockSize = 2
- ksize = 3
- k = 0.04
-
- img = cv2.imread("E:\\chess.png")
-
- # 灰度化
- gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
-
- # Harris角点检测
- dst = cv2.cornerHarris(gray, blockSize, ksize, k)
-
- # 角点展示,取dst中的最大值进行判断,大于阈值的全被显示出来
- img[dst > 0.01*dst.max()] = [0,0,255] # 红色显示
-
- cv2.imshow('harris',img)
- cv2.waitKey(0)


shi—Tomasi角点检测
shi—Tomasi是Harris角点检测的改进。Harris角点检测算的稳定性和K有关,而K是个经验值,不好设定最佳值。


默认采用false不使用Harris角点检测,若使用Harris角点检测(true),则需要设置K,默认为0.04
在实际使用中,填写前4个参数即可
- import cv2
- from cv2 import cornerSubPix
- from matplotlib.pyplot import gray
- import numpy as np
-
- # tomasi
- maxCorners = 1000
- qualityLevel = 0.01
- minDistance = 10 # 距离越大,检测的角数越少
-
- img = cv2.imread("E:\\chess.png")
-
- # 灰度化
- gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
-
- corners = cv2.goodFeaturesToTrack(gray, maxCorners, qualityLevel, minDistance)
- corners = np.int0(corners) # 将浮点型转换为整型
-
- # shi_Tomasi 绘制角点
- for i in corners:
- x,y = i.ravel() #转换为一维数组
- cv2.circle(img, (x,y), 3, (0,0,255),-1)
-
- cv2.imshow('shi_Tomasi',img)
- cv2.waitKey(0)
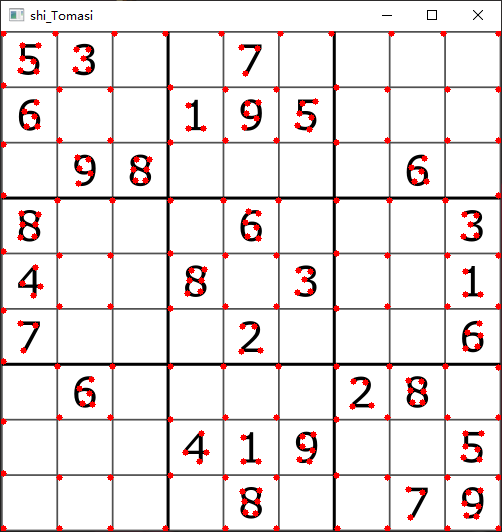 shi—Tomasi角点检测是更常用的角点检测方法。
shi—Tomasi角点检测是更常用的角点检测方法。
SIFT关键点检测
Scale-Invariant Feature Transform(SIFI) 与缩放无关的角点检测,也是OPENCV中获取角点的一个重要方法。
sift出现的原因:
Harris角点具有旋转不变的特性,但缩放后,原来的角点有可能就不是角点了
sift优点:原来检测的为角,放大后检测的还是一个角
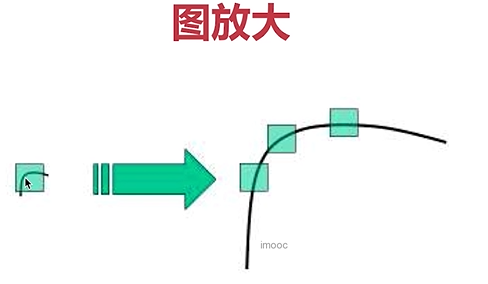 harris检测:原来检测的为角,但是放大后,检测的就变为了边缘,不是一个角。
harris检测:原来检测的为角,但是放大后,检测的就变为了边缘,不是一个角。
使用SIFT的步骤
- 创建SIFT对象
- 进行检测,获取关键点 kp = sift.detect(img, ...)
- 绘制关键点, drawKeypoints(gray, kp, img)
- import cv2
- from cv2 import cornerSubPix
- from matplotlib.pyplot import gray
- import numpy as np
-
- img = cv2.imread("E:\\chess.png")
-
- # 灰度化
- gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
-
- # 创建sift对象
- sift = cv2.SIFT_create()
- kp = sift.detect(gray, None) # 第二个参数为mask区域
-
- # 绘制角点,第三个参数为在那张图上进行绘制
- cv2.drawKeypoints(gray, kp, img)
-
- cv2.imshow('img',img)
- cv2.waitKey(0)
SIFI算法的报错处理
将 sift = cv2.xfeatures2d.SIFT_create()
改为 sift = cv2.SIFT_create() 即可
SIFT计算描述子
关键点和描述子
- 关键点:位置,大小和方向
- 关键点描述子:记录了关键点周围对其有贡献的像素点的一组向量值,其不受仿射变换、光照变换等影响
计算描述子
kp, des = sift.compute(img, kp) 其作用是进行特征匹配
 在实际使用中,常用该API进行计算
在实际使用中,常用该API进行计算
- kp, des = sift.detectAndCompute(gray, None)
- print(des) #打印描述子
描述子主要用在特征匹配上
SURF特征检测
Speeded-Up Robust Features(SURF) :加速的鲁棒性特征检测
SIFT最大的优点:进行检测时,特征点检测的特别准确,描述子也描述的非常详细
SURF的优点:SIFT最大的问题是速度慢,因此才有SURF,进行一系列图片检测时,处理速度非常慢,SURF保留了SIFT的优点
使用SURF的步骤

- import cv2
- import numpy as np
-
- img = cv2.imread("E:\\chess.png")
-
- # 灰度化
- gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
-
- # 创建surf对象
- surf = cv2.xfeatures2d.SURF_create() #surf检测
-
- # 使用surf进行检测
- kp, des = surf.detectAndCompute(gray, None)
- # print(des) #打印描述子
-
- # 绘制角点,第三个参数为在那张图上进行绘制
- cv2.drawKeypoints(gray, kp, img)
-
- cv2.imshow('img',img)
- cv2.waitKey(0)
解决SIFT和SURF由于专利原因报错的方法
- 卸载高版本的python,安装python3.6
- 复制以下两条命令到控制端进行安装:
- pip install opencv-python==3.4.2.16
pip install opencv-contrib-python==3.4.2.16
经过以上步骤,即可解决程序报错问题
ORB特征检测
Oriented FAST and Rotated BRIEF 特征点检测与描述子计算的结合

需要抛弃部分数据,才能提升速度,检测准确度有所下降,当检测大量数据时采用该方法。
注:ORB没有版权问题,是开源的
FAST 可以做到特征点的实时检测,不带方向
BRIEF 其是对已检测到的特征点进行描述,它加快了特征描述符建立的速度,同时也极大的降低了特征匹配的时间

- # 创建orb对象
- orb = cv2.ORB_create()
- kp, des = orb.detectAndCompute(gray, None)
小结
SIFT 计算准确率最高,但是速度较慢
SURF 准确率略低于SIFT,但是速度块
ORB 可以进行实时检测,速度更快,但是准确性没有前两者好
暴力特征匹配
经过以上几节的特征点检测的学习,接下来进行两张图片的特征点匹配学习
特征匹配方法:
BF(Brute- Force) 暴力特征匹配方法,通过枚举的方式实现
FLANN 最快邻近区特征匹配方法
暴力特征匹配原理
它使用第一组中的每个特征的描述子,与第二组中的所有特征描述子进行匹配,计算他们之间的差距,然后将最接近一个匹配返回
OPENCV特征匹配步骤
- 创建匹配器 BFMatcher(normType, crossCheck) 第一个参数为匹配类型,第二个参数为交叉检查
- 进行特征匹配 bf.match(des1,des2) 第一幅图的描述子与第二幅图进行匹配
- 绘制匹配点 cv2.drawMatches(img1,kp1,img2,kp2,...)



- import cv2
- import numpy as np
-
- img1 = cv2.imread('E:\\opencv_photo\\opencv_search.png')
- img2 = cv2.imread('E:\\opencv_photo\\opencv_orig.png')
-
- # 灰度化
- gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
- gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
-
- # 创建surf对象
- surf = cv2.xfeatures2d.SURF_create()
- # 计算特征点和描述子
- kp1, des1 = surf.detectAndCompute(gray1, None)
- kp2, des2 = surf.detectAndCompute(gray2, None)
-
- # 创建匹配器
- bf = cv2.BFMatcher(cv2.NORM_L1)
- # 进行特征匹配
- match = bf.match(des1, des2)
-
- img3 = cv2.drawMatches(img1, kp1, img2, kp2, match, None)
-
- cv2.imshow('img3',img3)
- cv2.waitKey(0)
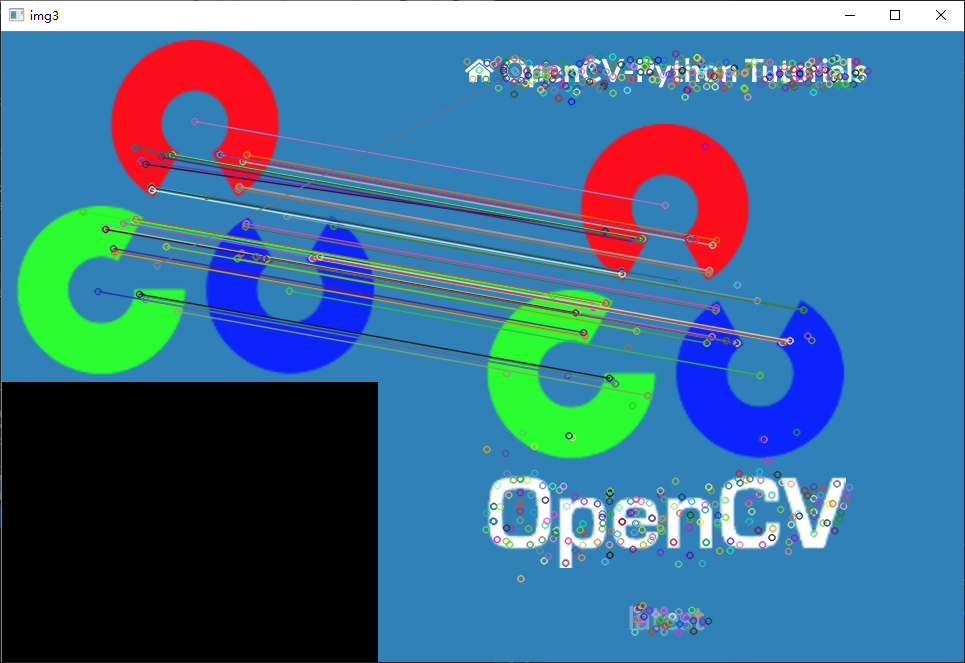
FLANN特征匹配


当选择SIFT和SURF时,选择KDTREE,若为ORB选择LSH
经验值,一般KDTREE设为5






- # FLANN特征匹配
- import cv2
- import numpy as np
-
- img1 = cv2.imread('E:\\opencv_photo\\opencv_search.png')
- img2 = cv2.imread('E:\\opencv_photo\\opencv_orig.png')
- # 灰度化
- gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
- gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
- # 创建surf对象
- surf = cv2.xfeatures2d.SURF_create()
- # 计算特征点和描述子
- kp1, des1 = surf.detectAndCompute(gray1, None)
- kp2, des2 = surf.detectAndCompute(gray2, None)
-
- # 创建匹配器
- index_params = dict(algorithm = 1, trees = 5)
- search_params = dict(checks = 50)
- flann = cv2.FlannBasedMatcher(index_params, search_params)
-
- #对描述子进行匹配计算
- matchs = flann.knnMatch(des1, des2, k=2)
-
- # 过滤,对所有匹配点进行优化
- good = []
- for i, (m,n) in enumerate(matchs):
- if m.distance < 0.7 * n.distance:
- good.append(m)
-
- ret = cv2.drawMatchesKnn(img1, kp1, img2, kp2, [good], None)
-
- cv2.imshow('result',ret)
- cv2.waitKey()
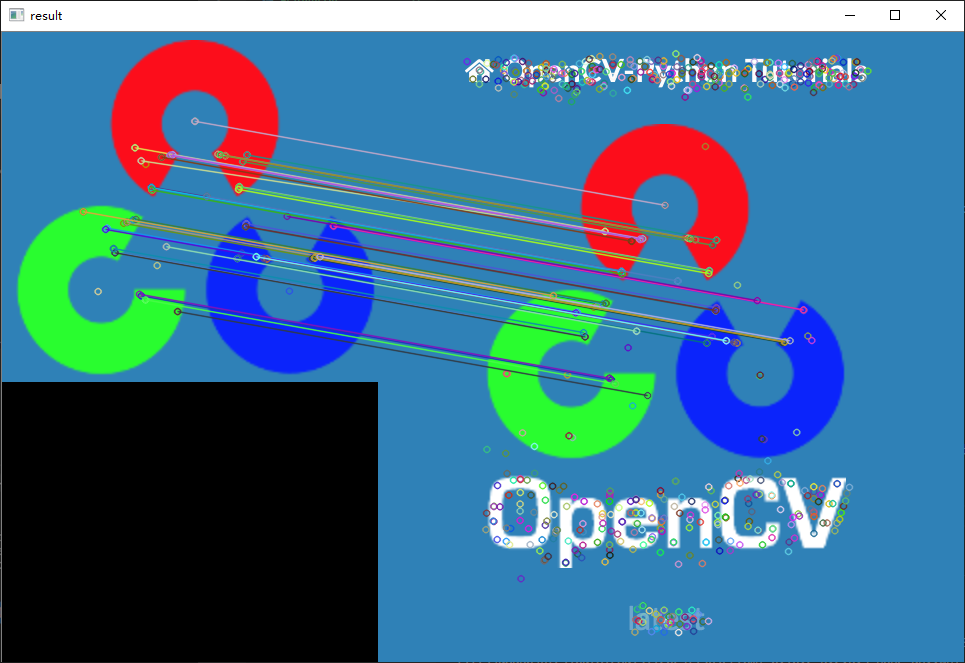
结果与暴力匹配类似,但是速度更快,暴力匹配的精度更高一点
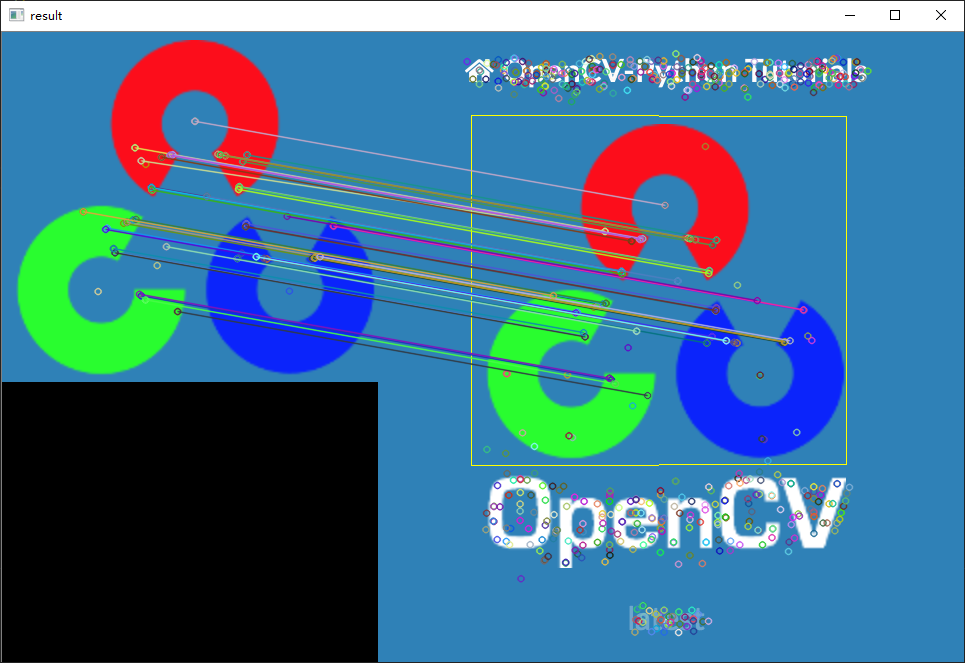
图像查找
用到两种技术:特征匹配+单应性矩阵

单应性矩阵作用:获取到一个矩阵,这个矩阵与图像A进行运算,可以得到图像2的位置
图像2经过计算可以得到原始的位置
 把图片转正
把图片转正

抠图,贴图
步骤:
首先进行特征点匹配,计算单应性矩阵,计算透视变换
- # 图像查找
- import cv2
- import numpy as np
-
- img1 = cv2.imread('E:\\opencv_photo\\opencv_search.png')
- img2 = cv2.imread('E:\\opencv_photo\\opencv_orig.png')
- # 灰度化
- gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
- gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
- # 创建surf对象
- surf = cv2.xfeatures2d.SURF_create()
- # 计算特征点和描述子
- kp1, des1 = surf.detectAndCompute(gray1, None)
- kp2, des2 = surf.detectAndCompute(gray2, None)
-
- # 创建匹配器
- index_params = dict(algorithm = 1, trees = 5)
- search_params = dict(checks = 50)
- flann = cv2.FlannBasedMatcher(index_params, search_params)
-
- #对描述子进行匹配计算
- matchs = flann.knnMatch(des1, des2, k=2)
-
- # 过滤,对所有匹配点进行优化
- good = []
- for i, (m,n) in enumerate(matchs):
- if m.distance < 0.7 * n.distance:
- good.append(m)
-
- # ret = cv2.drawMatchesKnn(img1, kp1, img2, kp2, [good], None)
-
- # 匹配点必须大于等于4
- if len(good) >= 4:
- # 查找单应性矩阵
- srcpts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1,1,2)
- #对数组进行重新变换,有无数行,每一行有1个元素,每个元素由2个子元素组成
- dstpts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1,1,2)
-
- H,_ = cv2.findHomography(srcpts, dstpts, cv2.RANSAC, 5.0)
- # 第三个参数是对匹配点进行过滤,随机抽样获取规律,最后一个参数为阈值
- # 第一个返回值为单应性矩阵,第二个参数为其掩码,不需要显示,所以用_代替
-
- # 透视变换
- h,w = img1.shape[:2]
- pts = np.float32([[0,0],[0,h-1], [w-1, h-1], [w-1, 0]]).reshape(-1,1,2) # 四个角点,左上角,左下角,右下角,右上角
- dst = cv2.perspectiveTransform(pts, H)
-
- # 用多边形框起来
- cv2.polylines(img2, [np.int32(dst)], True,(0,255,255))
- else:
- print('the number of good is less than 4.')
- exit()
- # 绘制图像
- ret = cv2.drawMatchesKnn(img1, kp1, img2, kp2, [good], None)
- cv2.imshow('result',ret)
- cv2.waitKey()