
- 1软考中级系统集成必备100题(21-40)真题精炼_系统集成案例分析必背100题
- 2软考.项目配置管理CM(Configuration Management)
- 3阿里云网盘内测(附下载地址)_阿里云盘内测版官网
- 4记录一次Https请求设置了传输层安全协议(SecurityProtocolType.Tls )依旧报错:未能创建 SSL/TLS 安全通道的问题
- 5消息中间件如何选型 图解 Kafka vs RabbitMQ vs RocketMQ 的差异_kafka 权限控制与rocketmq权限控制
- 6JavaSE-IO流基础详解_什么可单独使用来完成对数据源的读写
- 7抖音seo矩阵系统源代码开发部署技术文档--基于PHP语言开源_创胜定制嘉年华源码
- 8vue2 实现原生 WebSocket
- 9AI技术内参102-基础文本分析模型之三:EM算法_杨森不等式
- 10【STM32+FPGA】先进算力+强安全+边缘AI,64位STM32MP2聚焦工业4.0应用_stm32 fpga
算子是什么
赞
踩
什么是算子?
在知道什么是算子之前我们还需要知道一些其他的相关概念,大概来说,算子是一个函数空间到函数空间上的映射O:X→X。广义上的算子可以推广到任何空间,如内积空间等。
映射
从一个拓扑空间到另一个拓扑空间的对应关系。对于每一个x,都有唯一的y与之对应。如果对于一个x,对应一个“集合”,而非唯一的一个y,这种对应关系称为“集值映射”。
映射的概念是最一般的。对于映射的操作,最典型的是同伦。对于集值映射,最有名的结果是Kakutani不动点定理及其在博弈论和最优化中的应用。这些内容都属于拓扑学。
集值映射和映射统称为对应。
对应属于“关系”,关系是一个哲学范畴。
算子(即算符)
广义的讲,对任何函数进行某一项操作都可以认为是一个算子,甚至包括求幂次,开方都可以认为是一个算子,只是有的算子我们用了一个符号来代替他所要进行的运算罢了,所以大家看到算子就不要纠结,它甚至和加减乘除的基本运算符号都没有区别,只是他可以对单对象操作罢了(有的符号比如大于、小于号要对多对象操作)。又比如取概率P{X<x},概率是集合{X<x}(他是属于实数集的子集)对[0,1]区间的一个映射,我们知道实数域和[0,1]区间是可以一一映射的(这个后面再说),所以取概率符号P,我们认为也是一个算子,和微分,积分算子没区别。总而言之,算子就是映射,就是关系,就是变换。
从一个函数空间(比如Banach空间、Hilbert空间、Sobolev空间)到另一个函数空间。注意,函数空间当然属于拓扑空间,而且是拓扑线性空间,不过是无限维度的。而无限维的拓扑“非线性”空间一般称为Banach流形/Hilbert流形。因此算子属于映射。
有的时候,从有限维空间到有限维空间的映射也会称为“算子”,比如矩阵,是最常见的线性算子。
算子有线性与非线性之分。
有关线性算子的统一结果参考线性泛函分析的Baire纲定理和它的一系列推论:如共鸣定理、Banach逆算子定理以及闭图像定理。它们在工程数学中都有重要的作用。
有关非线性算子的理论需要依托非线性泛函分析,其中最重要的结果还是无限维空间中的隐函数定理。其实这里应该叫“隐算子定理”,但“隐函数”大家都叫了百年叫习惯了。有关非线性算子,更深的内容需要Banach流形上的一些拓扑方法,如伪梯度流和拓扑形变定理。对于非线性算子,最简单、工程数学和经济数学上也最常用的一个结果则是压缩映射原理。
变换
如果一个算子,其定义域和值域是拓扑线性同构的(线性同胚的),那么这种算子称为“变换”。比如矩阵,就是一个“线性变换”。对于这块内容,线性代数这门课已经作了透彻的研究。再比如Fourier变换,给定一个f(t)就有一个F(w)——这也是函数空间到其线性同构的函数空间的变换。
函数
一般指从一个有限维空间/有限维流形到数域(实数域或复数域)的映射。“函数”应该是我们最最熟悉的映射了。
有关函数,最重要的结果是微积分中的隐函数定理,这是微分学中最为重要的结果。没有之一。
泛函
从一个空间(有限维/无限维均可)到数域的映射。听名字也知道,普通的函数也属于泛函。但一般情况下,为了强调定义域是无限维空间/无限维流形的,我们会把这一类映射称为泛函。
为什么要强调定义域是无限维的 ?因为无限维与有限维有着拓扑学上的质变。比如,对于定义在紧集上的连续实值函数,必能取到最大值最小值,但对于泛函,这一结论并不成立。
有关线性泛函的重要结论有Hahn Banach定理以及Riesz表示定理以及弱收敛方法等一系列结果。
对于非线性泛函的研究主要参考变分方法(参考张恭庆的临界点理论)和非线性偏微分方程理论。
总结
函数属于泛函,泛函和变换都属于算子,算子属于映射。
算法和算子的关系:算法(algorithm)是为了达到某个目标,实施的一系列指令的过程,而指令包含算子(operator)和操作数(operand)。算子:operator,简单说来就是进行某种“操作“,动作。与之对应的,就是被操作的对象,称之为操作数,operand
什么是算子
深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称OP)。在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully-connected Layer, FC layer)中的权值求和过程,是一个算子。
再例如:tanh、ReLU等,为在网络模型中被用做激活函数的算子。

算子的名称(Name)与类型(Type)
算子的名称:标识网络中的某个算子,同一网络中算子的名称需要保持唯一。
算子的类型:网络中每个算子根据算子类型进行实现逻辑的匹配,在一个网络中同一类型的算子可能存在多个。
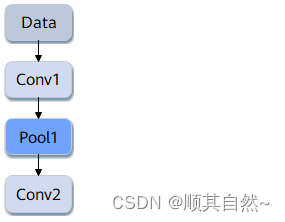
如下图所示,Conv1、Pool1、Conv2都是此网络中的算子名称,其中Conv1与Conv2算子的类型都为Convolution,表示分别做一次卷积计算。
张量(Tensor)
张量是算子计算数据的容器,包括输入数据与输出数据。
张量描述符(TensorDesc)是对输入数据与输出数据的描述,主要包含如下属性:
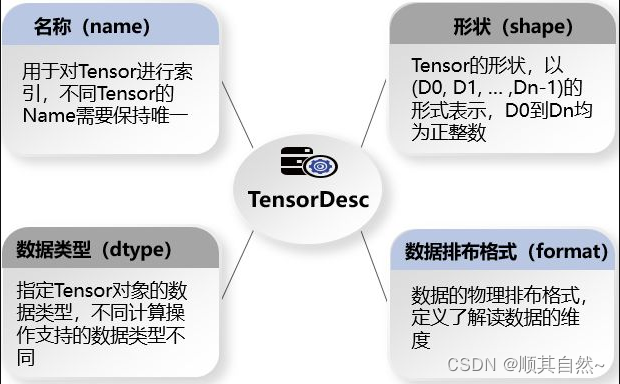
下面我们详细介绍下张量描述符中的形状和数据排布格式。
形状(Shape)
张量的形状,比如形状(3,4)表示第一维有3个元素,第二维有4个元素,是一个3行4列的矩阵数组。在形状中有多少个数字,就代表这个张量有多少维。形状的第一个元素要看张量最外层的中括号中有几个元素,形状的第二个元素要看张量中从左边开始数第二个中括号中有几个元素,依此类推。例如:

下面我们看一下形状的物理含义,假设shape=(4, 20, 20, 3)。
假设有4张照片,即shape里4的含义,每张照片的宽和高都是20,也就是20*20=400个像素,每个像素点都由红/绿/蓝3色组成,即shape里面3的含义,这就是shape=(4, 20, 20, 3)的物理含义。

数据排布格式
在深度学习领域,多维数据通过多维数组存储,比如卷积神经网络的特征图(Feature Map)通常用四维数组保存,即4D格式:
- N:Batch数量,例如图像的数目。
- H:Height,特征图高度,即垂直高度方向的像素个数。
- W:Width,特征图宽度,即水平宽度方向的像素个数。
- C:Channels,特征图通道,例如彩色RGB图像的Channels为3。
由于数据只能线性存储,因此这四个维度有对应的顺序。不同深度学习框架会按照不同的顺序存储特征图数据,比如Caffe,排列顺序为[Batch, Channels, Height, Width],即NCHW。TensorFlow中,排列顺序为[Batch, Height, Width, Channels],即NHWC。
以一张格式为RGB的图片为例,NCHW中,C排列在外层,实际存储的是“RRRRRRGGGGGGBBBBBB”,即同一通道的所有像素值顺序存储在一起;而NHWC中C排列在最内层,实际存储的则是“RGBRGBRGBRGBRGBRGB”,即不同通道的同一位置的像素值顺序存储在一起。

尽管存储的数据相同,但不同的存储顺序会导致数据的访问特性不一致,因此即便进行同样的运算,相应的计算性能也会不同。
在昇腾AI处理器中,为了提高数据的访问效率,张量数据采用NC1HWC0的五维格式。其中C0与微架构强相关,等于AI Core中矩阵计算单元的大小,这部分数据需要连续存储;C1是将C维度按照C0进行拆分后的数目,即C1=C/C0。如果不整除,最后一份数据需要补齐以对齐C0。

