
- 1MindSpore大模型并行需要在对应的yaml里面做哪些配置_mindformer数据并行
- 2202105110111王宇骐_服务端会自动url解码吗
- 3Hadoop中jps有,但是http://hadoop01:50070/出现不了界面怎么解决?hadoop集群启动但不能访问50070?_jps五项正常启动,hadoop01:50070打不开如何解决
- 4NLPIR+Hadoop_nlpir的hadoop
- 5无人机航拍数据集整理_飞机图片数据集
- 6Java进阶学习之路_java进阶之路
- 7使用Ollama和Open WebUI 部署AI聊天机器人_open-webui 自定义模型名称
- 8pynuput模块 控制和监视鼠标键盘操作
- 9openmv图像识别(形状篇)_openmv识别圆形
- 10一步步带你解锁Stable Diffusion:老外都眼馋的 SD 中文提示词插件分享_sd中文提示词插件
链表详解(单链表、双向链表、链表逆序)_单向链表和双向链表
赞
踩
线性表
在计算机科学中,线性结构被称为线性表
线性表是在数据元素的非空集合中:
①存在唯一的一个首元素;
②存在唯一的一个尾元素;
③除首元素外每个元素有且只有一个直接前驱;
④除尾元素外每个元素有且只有一个直接后续;
按存储方式分为顺序存储与链式存储
线性表的基本操作有:
初始化、插入、删除、遍历(即访问每一个元素,如打印所有信息)、查找、排序
顺序存储结构
顺序存储结构:用一组地址连续的存储单元 依次存放线性表的所有数据元素
特点1:逻辑关系上相邻的两个元素在物理位置上也相邻,因此,可以直接存取表中任意一个元素
特点2(缺点):①存储空间闲置、存储容量难以扩充;②当进行插入和删除操作时,存在大量数据元素移动
链式存储结构
链式存储结构:①在链式存储结构中,数据元素的存储单元是不连续的。每个元素除自身信息外,还需要存储其后续元素的信息
②每个元素的存储映像称为结点,存放数据元素信息的域称为数据域,存放后续结点存储位置的域称为指针域,每个结点由数据域和指针域构成
③用指针相连的结点序列称为链表
单链表
单链表定义
链表,别名链式存储结构或单链表,用于存储逻辑关系为 “一对一” 的数据。链表中每个数据的存储都由以下两部分组成:
1.数据元素本身,其所在的区域称为数据域。
2.指向直接后继元素的指针,所在的区域称为指针域。

单链表存储结构中,有一首指针head指示链表中第一个结点的存储位置,同时,由于最后一个元素没有直接后续,所以单链表最后一个结点的指针域为空(NULL),而当head为NULL时,head所指向的单链表为空表,其表长length=0
单链空表逻辑状态图如下:
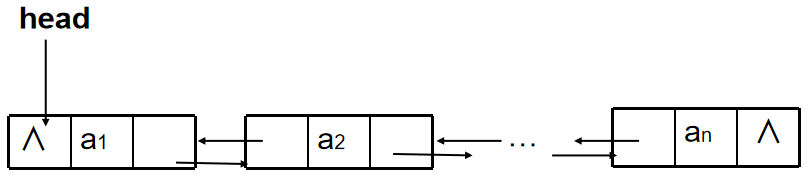
单链表一般逻辑状态图如下:

单链表基本操作(仅供参考)
单链表结构体定义
//单链表的结构定义
typedef struct list
{
int data; //存放数据的地址
struct list *next;
}LIST_T;
- 1
- 2
- 3
- 4
- 5
- 6
单链表的初始化(创建头结点)
LIST_T*List_Init(int data)
{
LIST_T * head;
head = (LIST_T *)malloc(sizeof(LIST_T));
head->data=data;
head->next=NULL;
return head;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
单链表的插入
void List_Add(LIST_T *head,int data)
{
LIST_T *pNode,*p1=head;
pNode=(LIST_T *)malloc(sizeof(LIST_T ));
while(p1->next != NULL )
{
p1=p1->next; //遍历链表,找到最末尾的节点
}
p1->next=pNode;
pNode->data=data;
pNode->next=NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
单链表结点位置的删除
//删除单链表中第index位置上的结点 int List_Del(LIST_T * head,int index) { LIST_T * p1; LIST_T * p2; //要删除结点的临时结点 int nCount = 0; p1=head; while(p1->next != NULL) { if(nCount == index) { p2 = p1->next; p1->next = p1->next->next; free(p2); } p1=p1->next; nCount++; } return nCount; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
单链表修改结点
// 修改单链表L的第index个位置上的结点 void replace(LIST_T *head, int index, int data) { LIST_T * p1; int nCount = 0; p1=head; while(p1->next != NULL) { if(nCount == index) { p1->data = data; break; } p1=p1->next; nCount++; } head = p1; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
单链表结点打印
void Data_Print(LIST_T *head)
{
LIST_T *p1=head->next;
while(p1 != NULL)
{
printf("data = %d\n",p1->data);
p1=p1->next;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
释放链表
LIST_T *List_Free(LIST_T *head)
{
LIST_T *ptr=head;
while(ptr!=NULL)
{
ptr=ptr->next;
free(head->data);//先释放数据存储的内存空间
free(head);//再释放链表节点的内存空间
head=ptr;
}
return head;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
实例
#include<stdio.h> #include <stdlib.h> #include <string.h> /*结构体定义,增删改查,和上面单链表基本操作等同,这里省略*/ int main() { LIST_T *head; //初始化链表 head=(LIST_T *)List_Init(NULL);//头节点不存储数据,参数为NULL //添加链表节点 List_Add(head,1); List_Add(head,2); Data_Print(head); replace(head,1,10); Data_Print(head); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
执行结果:
data = 1
data = 2
data = 10
data = 2
- 1
- 2
- 3
- 4
循环单链表的状态图
循环单链表一般逻辑状态图如下:

双向链表
双向链表定义
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。其结构图为:


双向链表中各节点包含以下 3 部分信息:
指针域:用于指向当前节点的直接前驱节点;
数据域:用于存储数据元素。
指针域:用于指向当前节点的直接后继节点;
双向链表特点
1.每次在插入或删除某个节点时, 需要处理四个节点的引用, 而不是两个. 实现起来要困难一些
2.相对于单向链表, 必然占用内存空间更大一些.
3.既可以从头遍历到尾, 又可以从尾遍历到头
双向链表基本操作(仅供参考)
双向链表的结构体定义
typedef struct list{
struct list *pre;
int data;
struct list *next;
}LIST_T;
- 1
- 2
- 3
- 4
- 5
双向链表的初始化(创建头结点)
LIST_T*List_Init()
{
LIST_T * head;
head = (LIST_T *)malloc(sizeof(LIST_T));
if(head == NULL)
{
printf("malloc error!\r\n");
return NULL;
}
head->data=0;
head->pre=NULL;
head->next=NULL;
return head;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
双向链表的插入
/*在尾部位置的插入data节点*/ void InsertNode(LIST_T * head,int data) { /*新建数据域为data的结点*/ LIST_T * pNode,*p=head; pNode=(LIST_T *)malloc(sizeof(LIST_T )); while(p->next) { p=p->next; //遍历链表,找到最末尾的节点 } if (p->next==NULL) { p->next=pNode; pNode->pre=p; pNode->next=NULL; pNode->data = data; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
双向链表数据结点位置的删除
LIST_T * DeleteList(LIST_T * head,int data) { LIST_T * temp=head; /*遍历链表*/ while(temp) { if (temp->data==data) { /*判断是否是头结点*/ if(temp->pre == NULL) { head=temp->next; temp->next = NULL; free(temp); return head; } /*判断是否是尾节点*/ else if(temp->next == NULL) { temp->pre->next=NULL; free(temp); return head; } else { temp->pre->next=temp->next; temp->next->pre=temp->pre; free(temp); return head; } } temp=temp->next; } return head; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
双向链表修改结点数据
// 修改链表L的第index个位置上的结点数据
LIST_T *replace(LIST_T * p,int index,int newdata)
{
LIST_T * temp=p;
int i=1;
/*遍历到被删除结点*/
for(i=1;i<index; i++)
{
temp=temp->next;
}
temp->data=newdata;
return p;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
双向链表结点数据查找
/*head为原双链表,elem表示被查找元素*/ int FindList(LIST_T * head,int elem) { /*新建一个指针t,初始化为头指针 head*/ LIST_T * temp=head; int i=1; while(temp->next!=NULL) { if (temp->data==elem) { return i; } i++; temp=temp->next; } /*程序执行至此处,表示查找失败*/ return -1; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
双向链表数据打印
/*输出链表的功能函数*/ void PrintList(LIST_T * head) { LIST_T * temp=head; printf("链表数据有:"); while (temp) { /*如果该节点无后继节点,说明此节点是链表的最后一个节点*/ if (temp->next==NULL) { printf("%d\n",temp->data); } else { printf("%d->",temp->data); } temp=temp->next; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
实例
#include<stdio.h> #include <stdlib.h> #include <string.h> /*结构体定义,增删改查,和上面双向链表基本操作等同,这里省略*/ int main() { LIST_T * head=NULL; //创建双链表 head=List_Init(); printf("新创建双链表为\t"); PrintList(head); //插入结点 InsertNode(head,1); printf("在表中插入元素 1\t"); PrintList(head); InsertNode(head,7); printf("在表中插入元素 7\t"); PrintList(head); InsertNode(head,6); printf("在表中插入元素 6\t"); PrintList(head); //表中删除元素 head=DeleteList(head,6); printf("表中删除元素 6\t\t\t"); PrintList(head); //查找元素 printf("元素 1 的位置是\t:%d\n",FindList(head,1)); //修改元素 head = replace(head,1,6); printf("表中第1个节点中的数据改为6\t"); PrintList(head); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
执行结果:
新创建双链表为 链表数据有:0
在表中插入元素 1 链表数据有:0->1
在表中插入元素 7 链表数据有:0->1->7
在表中插入元素 6 链表数据有:0->1->7->6
表中删除元素 6 链表数据有:0->1->7
元素 1 的位置是 :2
表中第1个节点中的数据改为6 链表数据有:6->1->7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
双向链表的状态图
双向链表一般逻辑状态图如下:
双向循环链表的状态图
双向循环链表一般逻辑状态图如下:

单链表逆序
逆序思想:
1、链表为空时:不需要逆序;
2、链表只有一个节点时:不需要逆序;
3、链表的节点为两个以及两个以上时:需要逆序
逆序代码:
LIST_T *link_reversed_order(LIST_T *p_head) { LIST_T *pf = NULL, *pb = NULL, *tmp = NULL; pf = p_head; if(p_head == NULL) { printf("链表为空,不需要逆序!\n"); return p_head; } else if(p_head->next == NULL) { printf("链表只有一个节点,不需要逆序!\n"); return p_head; } else { pf = p_head->next; pb = pf->next; //pf->next要赋值空,不然反向会在最后两个结点形成环 pf->next = NULL; free(p_head); //删掉头,不然反向链表会打印头结点数据NULL(例子这里为0) while(pb != NULL) { tmp = pb; pb = pb->next; tmp->next = pf; pf = tmp; } LIST_T *pNode; //链表反序后无头结点,这里自己建一个头 pNode=(LIST_T *)malloc(sizeof(LIST_T )); pNode->data=NULL; pNode->next = pf; return pNode; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
实例:
(结合上文单链表的操作)
int main()
{
LIST_T *head;
//初始化链表
head=(LIST_T *)List_Init(NULL);//头节点不存储数据,参数为NULL
//添加链表节点
List_Add(head,1);
List_Add(head,2);
List_Add(head,3);
Data_Print(head);
printf("\n");
head = link_reversed_order(head);
Data_Print(head);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
执行结果:
data = 1
data = 2
data = 3
data = 3
data = 2
data = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7

