
- 1机器学习---迁移学习
- 2护网2024-攻防对抗解决方案思路_2024护网
- 3《啊哈!算法》笔记——C语言、MATLAB 只有五行的算法——Floyd-Warshall_floyd-warshall算法代码matlab
- 4Elasticsearch-高级搜索(拼音|首字母|简繁|二级搜索)_java整合elasticsearch 7.17.5 实现中文+拼音+简繁搜索
- 5SWAN之ikev2协议multi-auth-rsa-eap-sim-id配置测试_leftauth=cert
- 6VS Code主题设置(美化VS Code)(主题+背景+图标+特效+字体)_vscode主题
- 7Datawhale AI夏令营- 讯飞机器翻译挑战赛baseline解析
- 8CentOS7安装部署git和gitlab_centos7下载安装gitlab
- 9大数据工程师简历怎么写,更受到HR青睐?_大数据技术简历
- 10换新电脑,怎么迁移旧电脑数据到新电脑_电脑迁移 csdn
Spring Boot项目配置Druid数据源(druid-spring-boot-starter)_springboot druid
赞
踩
Druid介绍
Druid是阿里巴巴的一个开源项目,号称为监控而生的数据库连接池,在功能、性能、扩展性方面都超过其他例如DBCP、C3P0、BoneCP、Proxool、JBoss DataSource等连接池,而且Druid已经在阿里巴巴部署了超过600个应用,通过了极为严格的考验,这才收获了大家的青睐!
Spring boot集成Druid
Apache Druid(Incubating) - 面向列的分布式数据存储,非常适合为交互式应用程序提供动力,开发中使用的更多。
以往我们都是直接引入Druid的依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.12</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
apache中已经出了一套完美支持SpringBoot的方案所以说我们不使用上面的依赖而是使用:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.22</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
两种依赖都可以,但是配置的方式有些不同,使用druid依赖项的,在配置的时候需要新建Druid的配置类文件,而druid-spring-boot-starter依赖项则不需要,这里我使用的druid-spring-boot-starter–更简单。
配置YML文件
spring:
datasource:
# 数据源基本配置
username: root
password: XXXX
url: jdbc:mysql://XXX.XX.XX.XXX:33306/数据库名?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
# driver-class需要注意mysql驱动的版本(com.mysql.cj.jdbc.Driver 或 com.mysql.jdbc.Driver)
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
# Druid的其他属性配置
druid:
# 初始化时建立物理连接的个数
initial-size: 5
# 连接池的最小空闲数量
min-idle: 5
# 连接池最大连接数量
max-active: 20
# 获取连接时最大等待时间,单位毫秒
max-wait: 60000
# 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
test-while-idle: true
# 既作为检测的间隔时间又作为testWhileIdel执行的依据
time-between-eviction-runs-millis: 60000
# 销毁线程时检测当前连接的最后活动时间和当前时间差大于该值时,关闭当前连接(配置连接在池中的最小生存时间)
min-evictable-idle-time-millis: 30000
# 用来检测数据库连接是否有效的sql 必须是一个查询语句(oracle中为 select 1 from dual)
validation-query: select 'x'
# 申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-on-borrow: false
# 归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-on-return: false
# 是否缓存preparedStatement, 也就是PSCache,PSCache对支持游标的数据库性能提升巨大,比如说oracle,在mysql下建议关闭。
pool-prepared-statements: false
# 置监控统计拦截的filters,去掉后监控界面sql无法统计,stat: 监控统计、Slf4j:日志记录、waLL: 防御sqL注入
filters: stat,wall,slf4j
# 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100
max-pool-prepared-statement-per-connection-size: -1
# 合并多个DruidDataSource的监控数据
use-global-data-source-stat: true
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connect-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
这里配置很重要,比如不配置filters的stat,我们在Druid的监控页面中就拿不到想要的信息。
新建配置文件
这里使用的是druid-spring-boot-starter的依赖项, 无需创建对应的Druid配置项, 但是如果使用的druid依赖项, 除了yml配置不同外, 还需要创建一个下面这样的配置文件
@Configuration
@Slf4j
public class DruidDatasrouceConfig {
/**
* DruidDatasrouceConfig
*
* @return DataSource
*/
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DruidDataSource druidDataSource() {
//
DruidDataSource druidDataSource = new DruidDataSource();
log.info("Datasource创建完成 ...");
log.info(druidDataSource.toString());
return druidDataSource;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
配置监控
上边我们已经开启filters的stat监控统计插件,下边进行添加监控配置:
spring:
datasource:
druid:
web-stat-filter:
# 是否启用StatFilter默认值true
enabled: true
# 添加过滤规则
url-pattern: /*
# 忽略过滤的格式
exclusions: /druid/*,*.js,*.gif,*.jpg,*.png,*.css,*.ico
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
StatViewServlet配置:Druid内置提供了一个StatViewServlet用于展示Druid的统计信息,StatViewServlet的用途包括:
- 提供监控信息展示的html页面
- 提供监控信息的JSON API
配置如下,需要注意的是用户名和密码:
spring:
datasource:
druid:
stat-view-servlet:
# 是否启用StatViewServlet默认值true
enabled: true
# 访问路径为/druid时,跳转到StatViewServlet
url-pattern: /druid/*
# 是否能够重置数据
reset-enable: false
# 需要账号密码才能访问控制台,默认为root
login-username: druid
login-password: druid
# IP白名单
allow: 127.0.0.1
# IP黑名单(共同存在时,deny优先于allow)
deny:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
到这里,关于Druid的配置就基本完成了, 想要了解更多的朋友,可以去查阅官方文档Druid github
验证Druid
我们直接启动项目,浏览器访问localhost:8080/druid或者127.0.0.1:8080/druid得到如下页面说明配置成功:
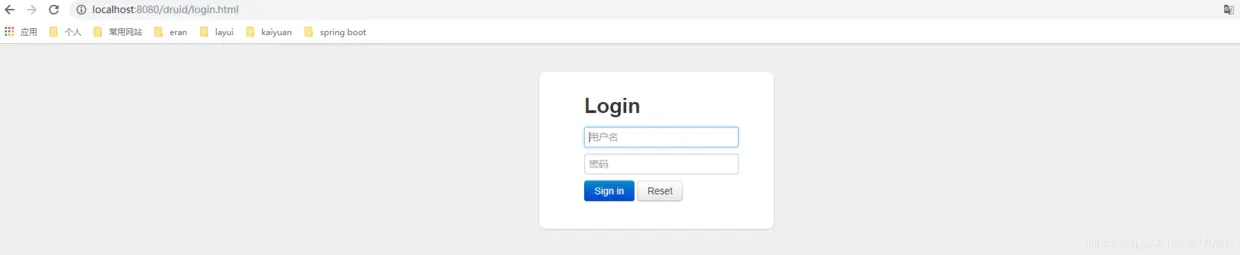
进入Druid的登陆页面,输入我们在配置文件中配置的用户名和密码登陆,进入下面的页面:
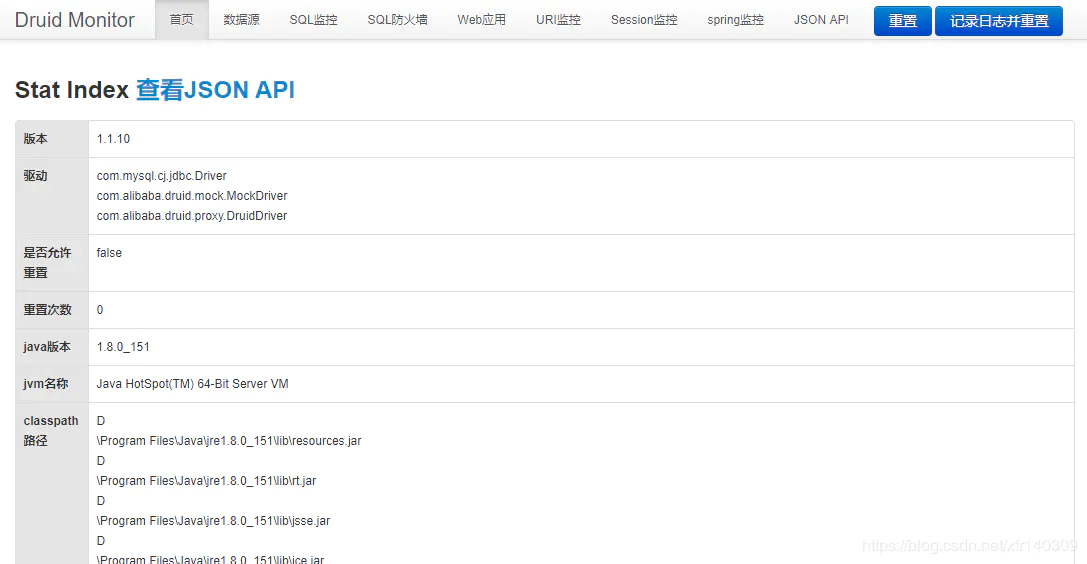
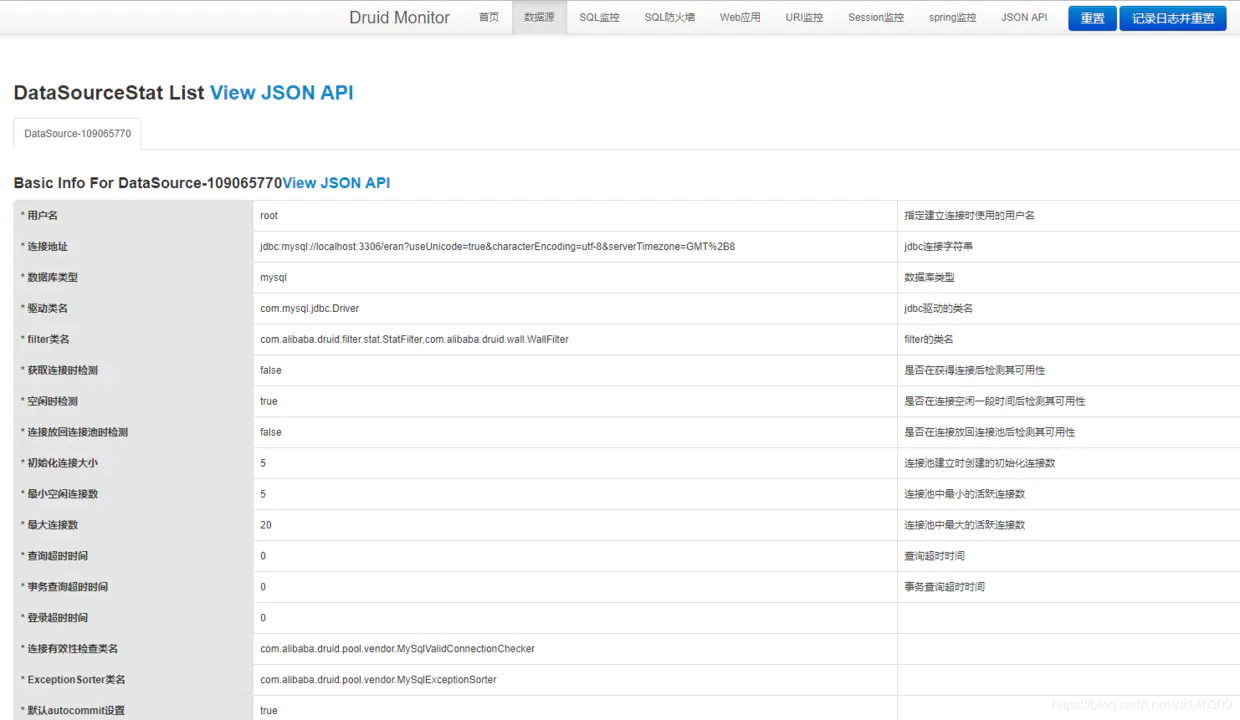
首页可以看到一些基本配置信息,点击菜单栏中的数据源可以查看到我们的数据源配置信息,以及连接池配置信息:
点击sql监控,查看执行sql信息:

发现此时没有任何sql执行记录,所以我们访问链接localhost:8080/user(自己整一个测试请求),执行一次查询操作,再来查看 sql监控页面,发现已经有了一条记录:

点击该条记录可以查看更多详情,这里就不介绍了,配置成功的小伙伴们可以自己体验Druid的各种强大功能!
结语
到这里,Spring boot整合Druid的内容就介绍完了,希望对您有所帮助


