
- 1照片动起来的软件哪个好用?照片秒变动态大片
- 2医疗AI产业链如何颠覆传统?AI大模型携手医疗巨头,打造未来医疗生态圈!_联邦学习 医疗问诊模型
- 3skewx 字体模糊_1+x证书Web前端开发初级理论考试样题2019
- 4ssl证书获取与tomcat和nginx设置https_nginx 映射tomcat ssl部署
- 5多lib架构android,2020-08-19 RN / Android多Lib资源依赖合并方案
- 6姿态估计openpose算法笔记_heatmaps openpose
- 7深入研究simulink建模与仿真之小数转换为整数的舍入模式(圆整模式、取整模式)_simulink取整
- 8云开发npm安装wx-server-sdk没有创建一个package-lock.json_npm 全局安装没有package-lock.json
- 9mac pro M1(ARM)安装:window虚拟机(三)_m1安装windows虚拟机
- 10ORACLE更新序列最大值为表的最大值_oracle修改序列的最大值sql语句
图嵌入Graph embedding学习笔记_graph2vec
赞
踩
1 什么是图嵌入?
将图的节点或边映射到一个低维的向量空间,即将海量、高维、异构、复杂和动态的数据表示为统一、低维、稠密的向量,用以保存图的结构和性质,旨在实现节点分类与聚类、链接预测、图的重构和可视化 等,提供一种具有更低计算复杂度的方法。
包括节点、边、子图、全图基于手工构造特征、矩阵分解、随机游走、图神经网络的图嵌入方法。
2 图嵌入方法
2.0 方法基础 — Word2vec方法和Skip-Gram模型
Word2vec方法和Skip-Gram模型是图嵌入方法的基础。
word2vec的思想可以简单的归结为一句话: 利用海量的文本序列,根据上下文单词预测目标单词共现的概率,让一个构造的网络向概率最大化优化,得到的参数矩阵就是单词的向量。
Word2vec是一种将单词转换为嵌入向量的嵌入方法,相似的词应该有相似的嵌入。采用一层隐含神经网络的Skip-Gram网络,输入中心词预测周围词【CBOW模型,用周围词预测中心词】。Skip-Gram被训练来预测句子中的相邻单词。这个任务被称为伪任务,因为它只是在训练阶段使用。网络在输入端接受单词,并对其进行优化,使其能够以高概率预测句子中的相邻单词。
2.1 深度游走DeepWalk
word2vec假设相邻单词相似,随机游走假设相邻节点相似,可以套用。
深度游走( DeepWalk) 是基于 Word2vec 提出的一种图嵌入方法,是语言模型和无监督学习从单词序列到图上的一种扩展,首先随机生成网络中节点的邻居节点、形成定长的随机游走序列,再用 Skip-Gram 模 型对生成的定长节点序列映射成低维嵌入向量.该方法能学习到节点对的关系信息,时间复杂度为 O( log | V| ) ,实现了动态图的增量学习。
流程:
①输入一个图
②采样随机游走序列
③用随机游走序列训练work2vec
④为了解决分类个数过多的问题可以加一个分层softmax或者霍夫曼编码数
⑤得到每一个节点的图嵌入向量表示
注意:
·Deepwalk把节点压缩、映射编码为一个d维向量,原图中相近的点在embedding后。
·Emmbedding 包含了节点的连接、社群 关联信息,可用于后续节点分类等下游任务
·Wordvec假设相邻单词相似 随机游走假设相邻节点相似,可以套用~
·相邻接点在编码后依然相近
·即来即训,加入数据时不用从头训练
伪代码如下图所示:


DeepWalk有两套权重:
①N个节点的D维embedding ②(N-1)个逻辑回归,每个有D个权重
优缺点
【优点】
①首个将深度学习和自然语言处理的思想用于图机器学习。
②在稀疏标注节点分类场景下,嵌入性能卓越。
③可以线性并行采样、在线增量训练
【缺点】
①均匀随机游走,没有偏向的游走方向。(Node2Vec)
②需要大量随机游走序列训练。
③基于随机游走,管中窥豹。距离较远的两个节点无法相互影响。看不到全图信息。(图神经网络可以),即有限的步长会影响上下文信息的完整性。
④无监督,仅编码图的连接信息,没有利用节点的属性特征。
⑤没有真正用到神经网络和深度学习。
⑥不适合带权图,只能保持图的二阶相似性;
⑦面对大规模的图,调整超参数较复杂,且游走步数超过2^5 后嵌入效果不够显著。
DeepWalk方法执行随机步,这意味着嵌入不能很好地保留节点的局部邻域。Node2vec方法解决了这个问题。
2.2 节点-向量模型node2vec
Node2vec 是DeepWalk的一个改进,通过分别调整广度优先游走( Breadth-First Search,BFS) 和 深度优先游走 ( Depth-First Search,DFS ) 策略的参数,来获取图的全局结构和局部结构.
主要步骤如下:
①计算转移概率,结合 BFS 和 DFS 生成随机游走序列
②用 Skip-Gram 模型对生成的游走序列进行嵌入
优缺点
【优点】
每一步都能可并行处理,能保持语义信息和结构信息。
【缺点】
对于含有特定属性的节点嵌入效果仍有待提高.
Node2vec vs DeepWalk
node2vec区别于deepwalk,主要是通过节点间的跳转概率。跳转概率是三阶关系,即考虑当前跳转节点,以及前一个节点 到下一个节点的“距离”,通过返回参数p和进出(或叫远离)参数q控制游走的方向(返回还是继续向前)
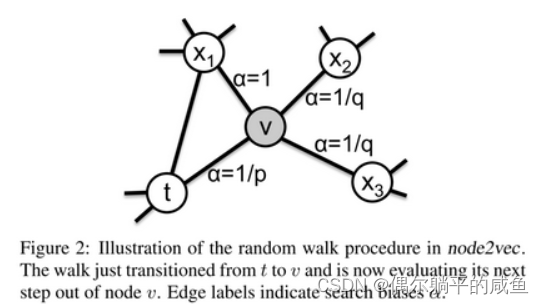
p和q均为1的时候,node2vec退化为deepwalk,因此实际上我们可以知道,deepwalk本身就是纯粹的随机乱走,而node2vec更像是基于deepwalk上的一个灵活的框架,因为我们可以通过指定超参数来改变我们想要进行embedding的目的。
因此,只能说deepwalk能够捕捉节点之间的共现性,这个共现性可能包含了同质性也可能包含了结构性,而node2vec可以让使用者灵活的定义我们要捕捉更多的结构性还是更多的同质性。如果要考虑基于整个graph的同质性,比如上面所说的远距离局部社区相同或者相似角色的embedding问题,我们就需要考虑使用别的embedding算法来解决了,比如计算复杂度非常高基本没法在大规模graph上运行的struc2vec。
2.3 LINE
可以应用于大规模的图上,表示节点之间的结构信息。
LINE方法详解
LINE采用广度优先搜索策略来生成上下文节点:只有距离给定节点最多两跳的节点才被视为其相邻节点。 此外,与 DeepWalk 中使用的分层 softmax 相比,它使用负采样来优化 Skip-gram 模型。
特点:
考虑了一阶相似性和二阶相似性【一阶:局部的结构信息;二阶:节点的邻居。共享邻居的节点可能是相似的。】,将一阶相似性和二阶相似性拼接。
优缺点
【优点】
deepwork只能无向图、而LINE可以有向图也可以无向图。
【缺点】
在对低度节点进行embedding编码时效果不好,
2.4 struc2vec
DeepWalk和Node2vec的一个缺点是由于walk的采样长度有限,无法有效的对远距离的具有结构相似性的节点进行建模。但之前的算法表现较好的原因是由于大部分的数据集更倾向于同质性的刻画,即距离相近的节点在特征空间中也相近,已经足够覆盖大部分数据集了。Struc2vec在构建图的过程中,不需要节点的位置信息和标签信息,仅仅依靠节点的度这个概念去进行多层图的构建。
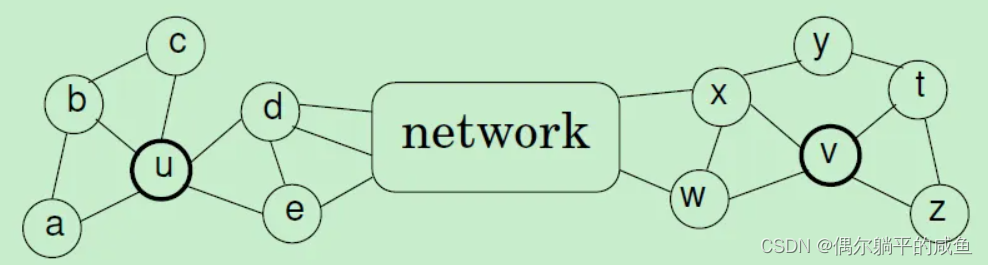
一个直观的概念,如果两个节点具有相同的度,那么这两个节点在结构上更相似,更进一步的,如果这两个节点的全部邻居节点也有相同的度,那这两个节点在结构上应该更相似。Struc2vec基于上述这个很直观的概念,使用动态规整方式,去进行多层图和相应边的构建。
2.5 SDNE
之前的DeepWalk、LINE、node2vec、struc2vec都使用了浅层的结构,浅层模型往往不能捕获高度非线性的网络结构。即产生了SDNE方法,使用多个非线性层来捕获node的embedding,它不执行随机游走。SDNE在不同任务上的表现非常稳定。
它的结构类似于一个自编码器:
自己—>向量—>邻居
它的设计使嵌入保持一阶和二阶接近。
一阶近似是由边连接的节点之间的局部成对相似。它描述了本地网络结构的特征。如果网络中的两个节点与边缘相连,则它们是相似的。当一篇论文引用了另一篇论文,这意味着它们涉及了类似的主题;
二阶邻近性表示节点邻近结构的相似性。它捕获了全局网络结构。如果两个节点共享许多邻居,它们往往是相似的。
SDNE提出的自动编码器神经网络有两个部分-见下图。自动编码器(左、右网络)接受节点邻接向量,并经过训练来重建节点邻接。这些自动编码器被命名为原始自动编码器,它们学习二级邻近性。邻接向量(邻接矩阵中的一行)在表示连接到所选节点的位置上具有正值。
还有一个网络的监督部分——左翼和右翼之间的联系。它计算从左到右的嵌入距离,并将其包含在网络的共同损耗中。网络经过这样的训练,左、右自动编码器得到所有由输入边连接的节点对。距离部分的损失有助于保持一阶接近性。
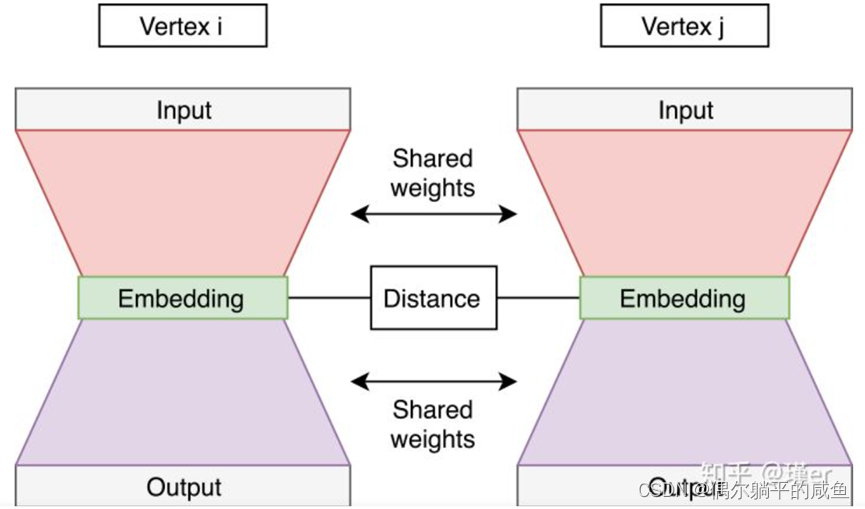
网络的总损耗是由左、右自编码器的损耗和中间部分的损耗之和来计算的。
以上五种方法总结及代码实现
总结
1.DeepWalk
采用随机游走形成序列,采用skip-gram方法生成节点embedding。
2.node2vec
采用不同的随机游走策略形成序列,类似skip-gram方式生成节点embedding。
3.LINE
捕获节点的一阶和二阶相似度,分别求解,再将一阶二阶拼接在一起,作为节点的embedding。
4.struc2vec
对图的结构信息进行捕获,在其结构重要性大于邻居重要性时,有较好的效果。
5.SDNE
采用了多个非线性层的方式捕获一阶二阶的相似性。
代码实现
https://github.com/shenweichen/GraphEmbedding
2.6 graph2vec
这种方法是嵌入整个图。它计算一个描述图形的向量。在这一部分选择graph2vec来作为典型的例子,因为它是实现图嵌入的较优秀的方法。
Graph2vec基于doc2vec方法的思想,它使用了SkipGram网络。它获得输入文档的ID,并经过训练以最大化从文档中预测随机单词的概率。
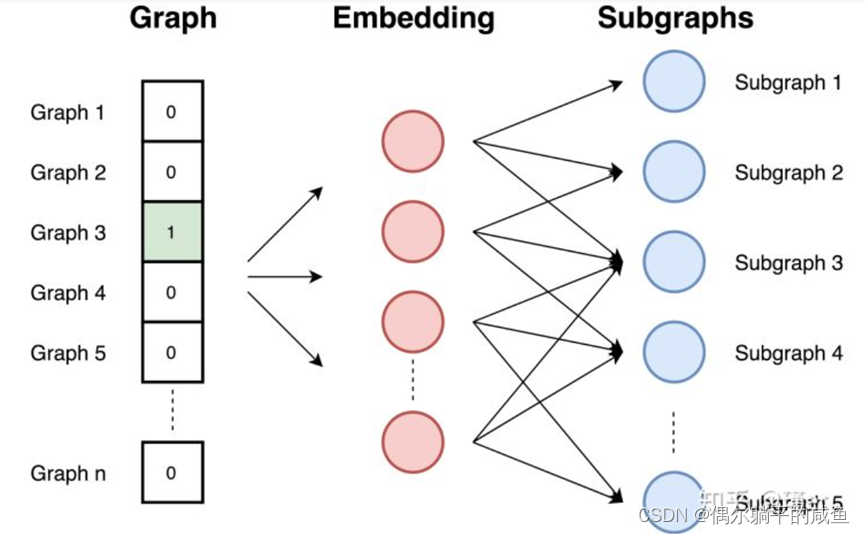
Graph2vec方法包括三个步骤:
①从图中采样并重新标记所有子图。子图是在所选节点周围出现的一组节点。子图中的节点距离不超过所选边数。
②训练跳跃图模型。图类似于文档。由于文档是词的集合,所以图就是子图的集合。在此阶段,对跳跃图模型进行训练。它被训练来最大限度地预测存在于输入图中的子图的概率。输入图是作为一个热向量提供的。
③通过在输入处提供一个图ID作为一个独热向量来计算嵌入。嵌入是隐藏层的结果。 由于任务是预测子图,所以具有相似子图和相似结构的图具有相似的嵌入。
2.7 其他嵌入方法
上面的分析是常用的一些方法。由于这个主题目前非常流行,还有其它的一些可用的方法:
• 顶点嵌入方法:LLE,拉普拉斯特征映射,图分解,GraRep, HOPE, DNGR, GCN, LINE
• 图形嵌入方法:Patchy-san, sub2vec (embed subgraphs), WL kernel和deep WL kernels
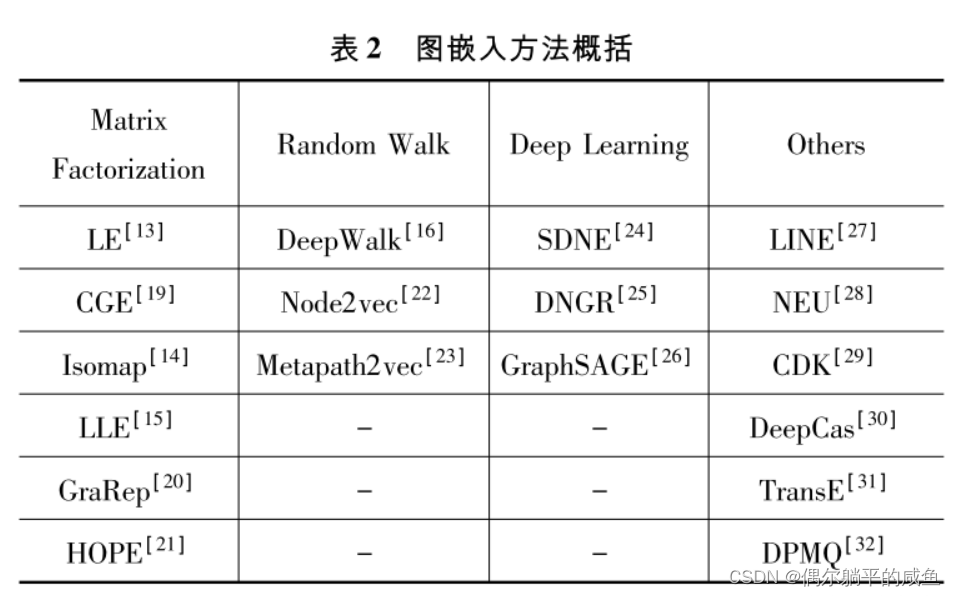
3 图嵌入面临的挑战
如前所述,图嵌入的目标是发现高维图的低维向量表示,而获取图中每个节点的向量表示是十分困难的,并且具有几个挑战,这些挑战一直在推动本领域的研究:
① 属性选择:节点的“良好”向量表示应保留图的结构和单个节点之间的连接。第一个挑战是选择嵌入应该保留的图形属性。考虑到图中所定义的距离度量和属性过多,这种选择可能很困难,性能可能取决于实际的应用场景。它们需要表示图拓扑、节点连接和节点邻居。预测或可视化的性能取决于嵌入的质量。
② 可扩展性:大多数真实网络都很大,包含大量节点和边。嵌入方法应具有可扩展性,能够处理大型图。定义一个可扩展的模型具有挑战性,尤其是当该模型旨在保持网络的全局属性时。好的嵌入方法需要在大型图上高效。
③ 嵌入的维数:实际嵌入时很难找到表示的最佳维数。例如,较高的维数可能会提高重建精度,但具有较高的时间和空间复杂性。较低的维度虽然时间、空间复杂度低,但无疑会损失很多图中原有的信息。用户需要根据需求做出权衡。在一些文章中,他们通常报告说嵌入大小在128到256之间对于大多数任务来说已经足够了。在Word2vec方法中,他们选择了嵌入长度300。
4 图嵌入面试题
图嵌入和图网络的关系
参考:word2vec和全连接神经网络
图嵌入利用了图的哪些信息,丢弃了哪些信息
参考:利用到了拓扑信息,丢弃了节点的内部属性
图嵌入算法如何应对数据稀疏问题
参考:可以使用LINE、SDNE之类的能利用到一二阶近邻的算法
SDNE模型原理、损失函数和优化方式
参考:用深度学习模型,使用包含自编码(2阶)+ 邻居相似(1阶)的损失函数,捕获全局和局部信息,SGD。
图嵌入有哪些方式
参考:因子分解、随机游走、深度学习
如何计算新增节点的顶点嵌入
参考:如果是直推式的模型,需要采样新增的数据微调训练模型,或者重新训练模型。如果是归纳试模型,就具备处理动态图的能力,比如GraphSAGE。
SDNE学习范式
参考:论文中认为是1阶相似性是监督,2阶相似性是无监督,总体是半监督。其实1阶相似性的刻画只用到了图的拓扑结构,没用到节点的标签,可以认为是self-supervised。


