
- 1什么是RPC?有哪些RPC框架?
- 2R9000P2021版拯救者 装ubuntu系统相关问题(WiFi、蓝牙、亮度调节,驱动安装)记录总结_r9000p重装蓝牙
- 3解决Spring Boot应用中的内存优化问题
- 4搭建hadoop+spark完全分布式集群环境
- 5软件测试除了做好功能测试自动化测试之外,如何在职位上获得提升?_测试工程师除了功能测试还能做什么
- 6BERT参数计算,RBT3模型结构
- 7Android Studio运行项目_android studio怎么运行当前项目csdn
- 8量化机器人能否实现多资产交易?
- 9深度学习环境配置_ubuntu18及以上_nvcc fatal : failed to preprocess host compiler pr
- 10数据库逻辑设计 完全函数依赖、部分函数依赖、传递函数依赖、码、候选码、主码、范式_数据库部分函数依赖
DeepSeek-Coder-v2击败GPT-4 Turbo,成为竞技场最强开源编码模型!_deepseek v2
赞
踩
目录
就在刚刚,竞技场排名再次刷新:
深度求索的DeepSeek-Coder-v2成为竞技场最强开源编码模型!
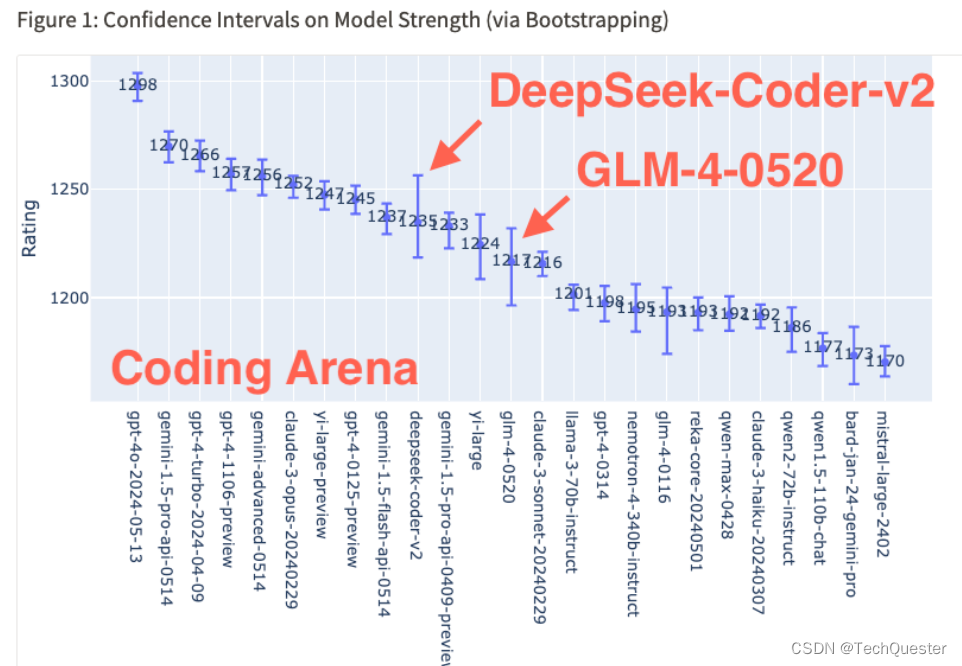
它在Coding Arena中已攀升至第4名,水平接近GPT-4 Turbo。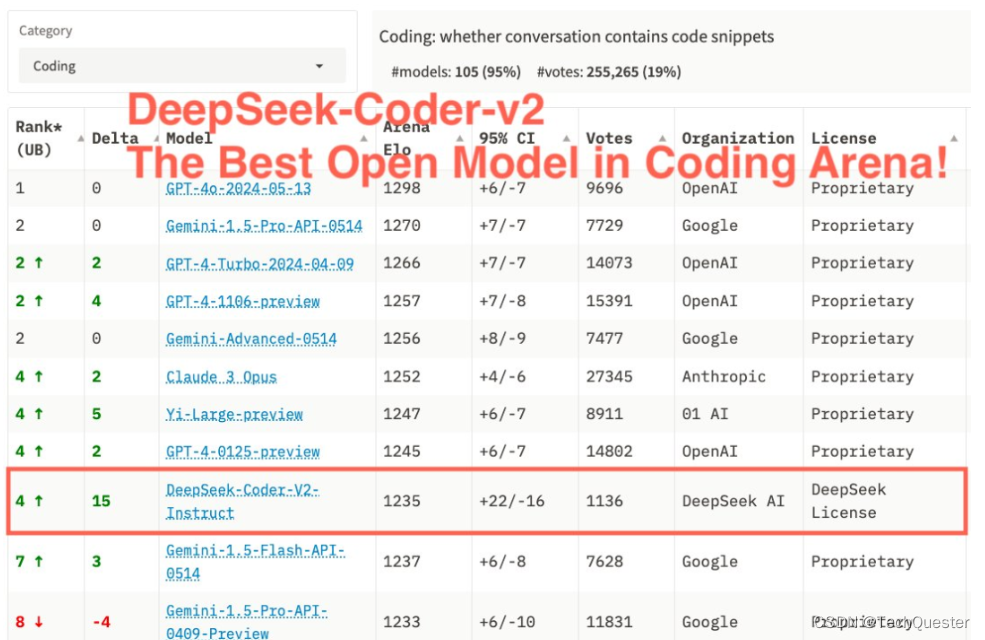
没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几分钟搞定:
升级ChatGPT-4o Turbo步骤![]() https://www.zhihu.com/pin/1768399982598909952
https://www.zhihu.com/pin/1768399982598909952
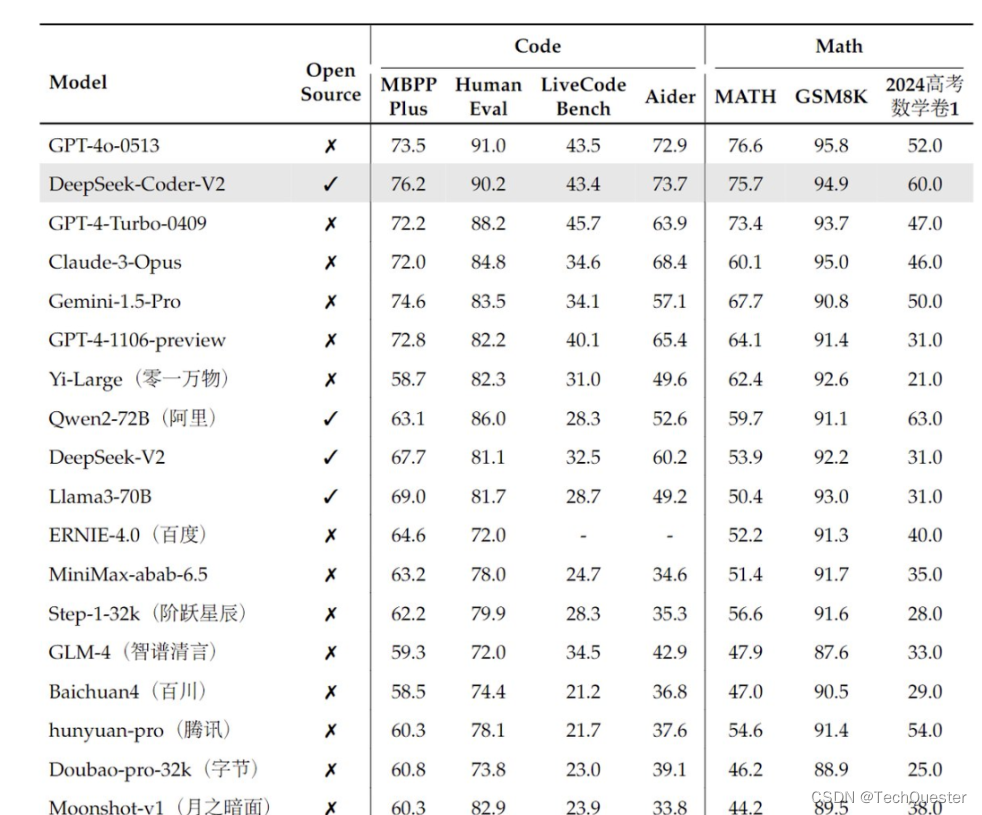
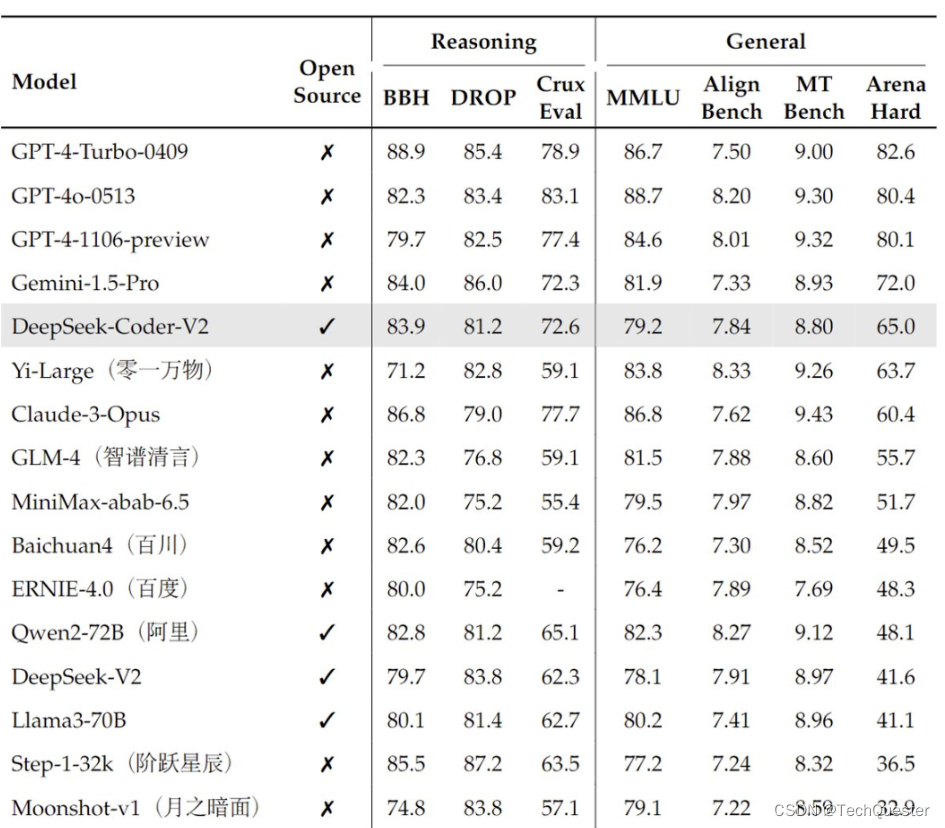
在编码领域的整体性能评估中,DeepSeek-Coder-v2的评分和稳定性均位于前10,超越了智谱GLM-4、Llama-3等一众知名开源模型。
据了解,完全开源的DeepSeek-Coder-v2现提供236B和16B两种参数规模,支持338种编程语言和128K上下文长度。
而且就在Claude 3.5 Sonnet发布同日,深度求索官网的代码助手也第一时间上线了类似“Artifacts”的功能(自动生成代码并直接在浏览器上运行)。
例如,DeepSeek-Coder-v2可以直接生成经典游戏——扫雷。

网页设计:
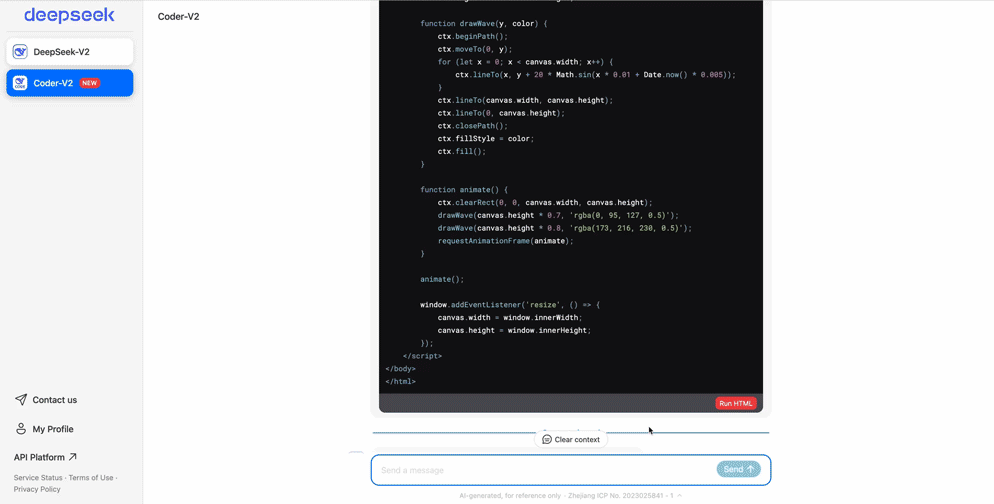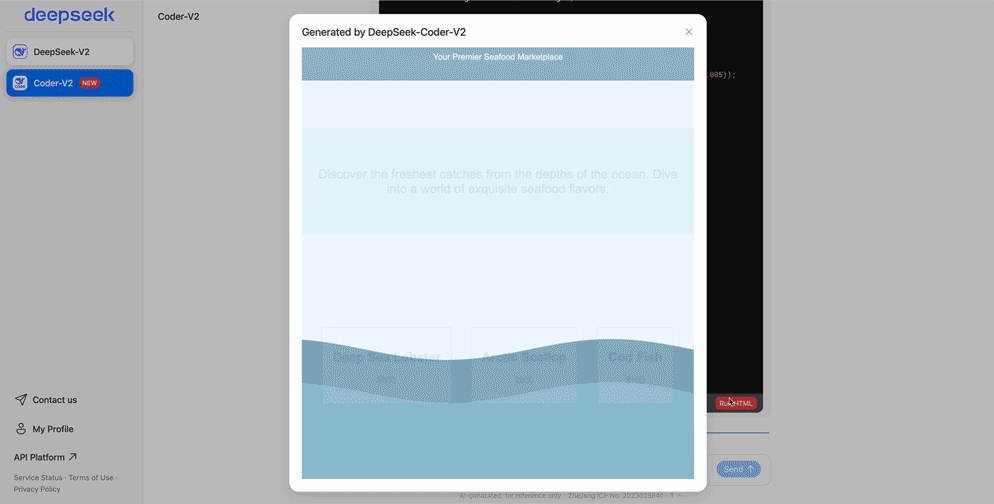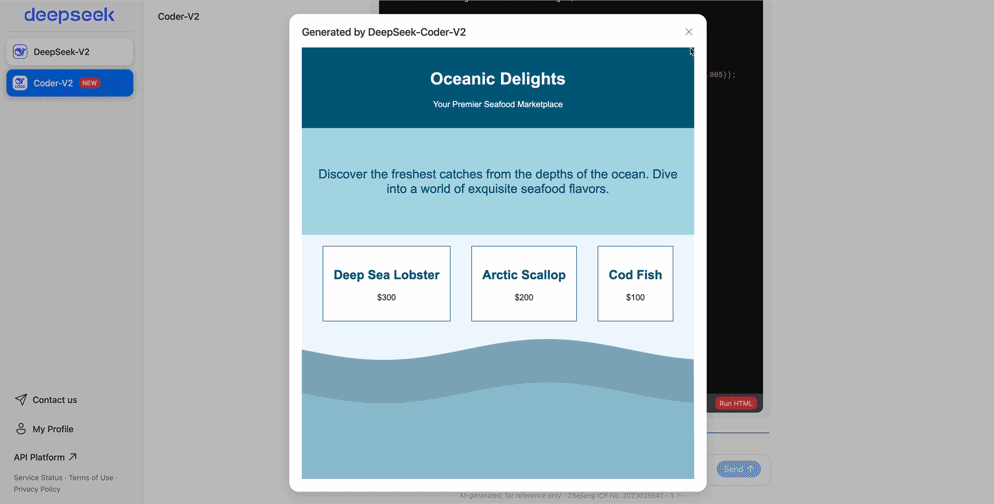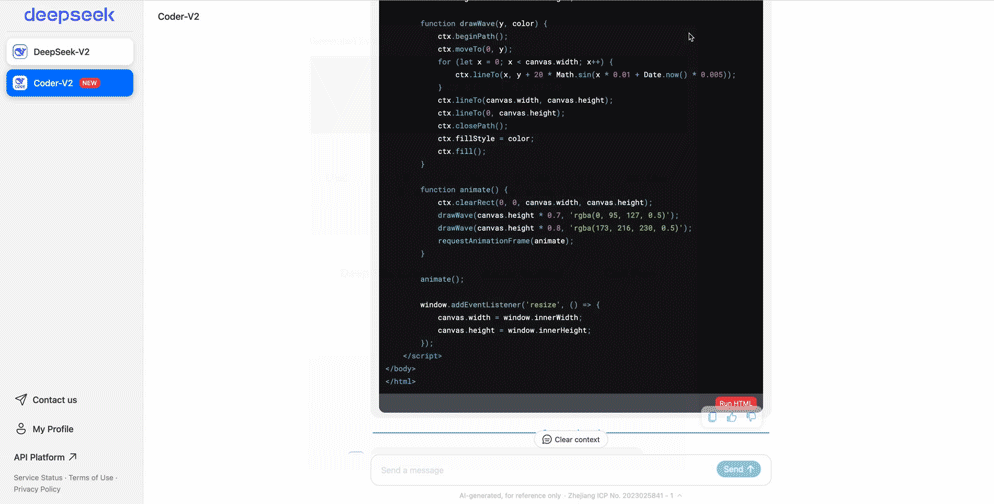
总之,DeepSeek-Coder-v2尤为擅长编码和数学。
01 编码与数学击败GPT-4 Turbo
深度求索于上周发布了DeepSeek-Coder-v2,它在编码和数学方面击败了GPT-4 Turbo。
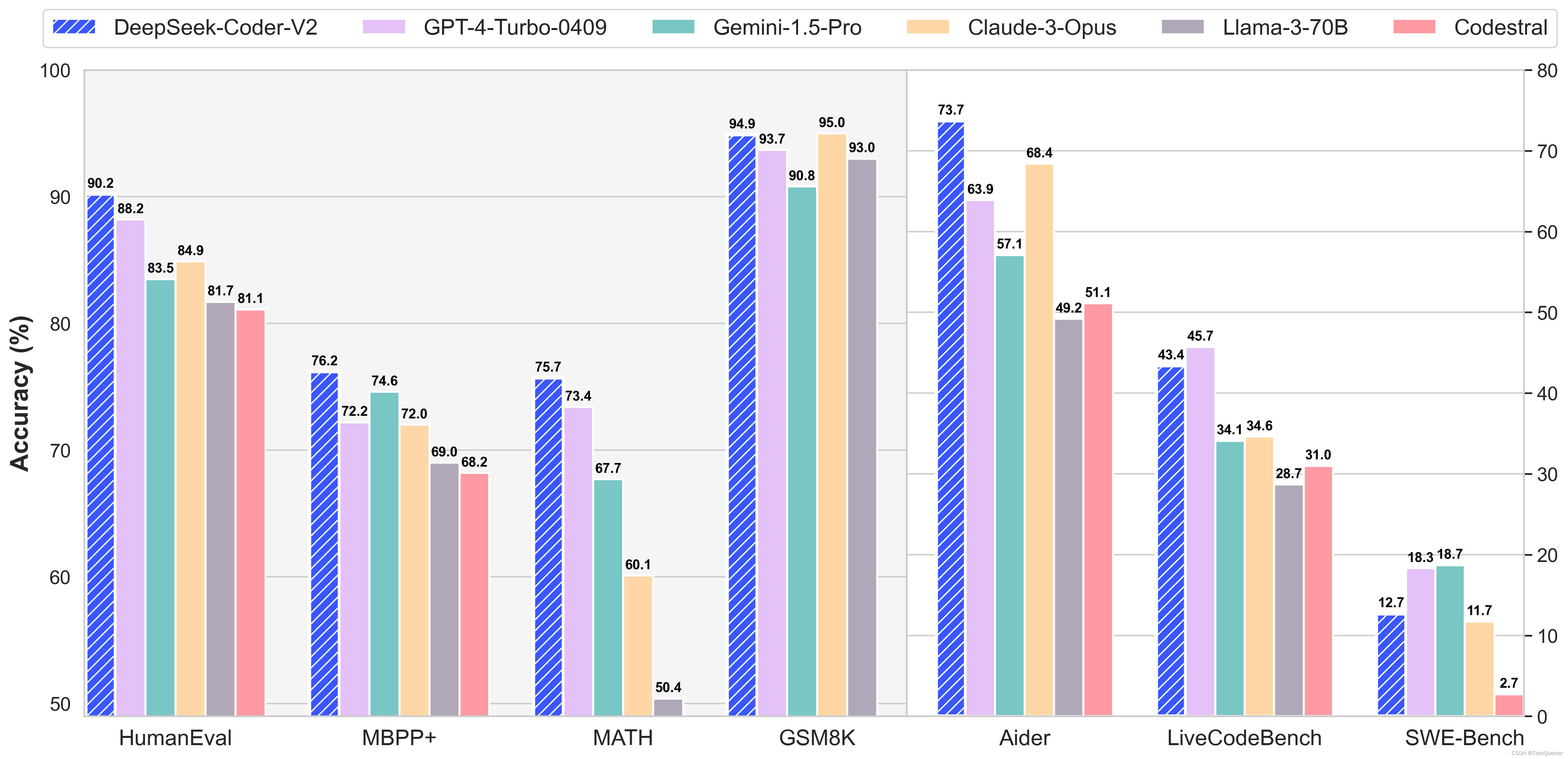
在Arena-Hard-Auto排行榜上,DeepSeek-Coder-v2超过了Yi-large、Claude3-Opus、GLM-4和Qwen2-72B。
同时,DeepSeek-Coder-v2还具有良好的通用性能,在推理和中英通用能力上位列国内第一梯队。
现在,仅过去一周时间,DeepSeek-Coder-v2正式登顶竞技场最强开源编码模型。
随着这一登顶,其背后的公司深度求索再次引人关注。
老实说,这家公司一直很有看点。
与月之暗面、智谱AI、Minimax、百川智能等获得大厂投资的AI初创公司不同,深度求索由一家搞私募量化的投资基金发起。
当同行都在寻找AI应用落地时,深度求索却喊出了“不做应用做研究”的口号。
短短半年时间,它发布并开源了多个百亿级参数的大模型。
甚至仅凭一己之力点燃了大模型价格战的第一把火。
02 深度求索:价格战的导火索
深度求索由知名私募巨头幻方量化于2023年4月创立。
早在2019年,幻方就发布了自研深度学习训练平台“萤火一号”。据称该项目总投资近2亿元,共搭载了1100块GPU。
后来“萤火一号”升级为“二号”,搭载的GPU数量达到了约1万张。这意味着,单从算力看,幻方甚至比很多大厂都更早拿到了做ChatGPT的入场券。
去年11月,深度求索发布了第一代大模型DeepSeek Coder,免费商用,完全开源。紧接着12月,它又发布了参数670亿的DeepSeek,主打发布即开源。
今年5月初,深度求索宣布开源第二代MoE大模型DeepSeek-V2。没错,就是那个“性能比肩GPT-4 Turbo,价格却只有GPT-4百分之一”的模型。
DeepSeek-V2推出后,深度求索一度被AI圈称作“价格屠夫”,被认为是引爆大模型价格战的导火索之一。
此外,它还推出了专为视觉与语言理解应用设计的DeepSeek-VL系列大模型。
总之,这家公司一直被视为可能改变国内AI市场格局的“黑马”。
Anthropic联合创始人Jack Clark曾表示:
“DeepSeek组建了一支团队,他们对训练雄心勃勃的模型所需的基础设施有着深刻的理解。中国制造也将成为AI模型的发展趋势。”
面对竞技场最新排名,网友们纷纷猜测新王Claude 3.5 Sonnet在编码上的表现究竟如何。
如何使用WildCard正确方式打开GPT-4o,目前 WildCard 支持的服务非常齐全,可以说是应有尽有!
官网有更详细介绍:WildCard
推荐阅读:

