
- 1【数据竞赛】2020 Kaggle 10大竞赛方案汇总
- 2深入了解软件测试:从入门到奥秘,揭开测试的精髓
- 3抖音最近很火的QQ在线价值评估网站源码(qq价值在线评估)_抖音qq价格评估是哪个网站
- 4informatica学习1-数据仓库,ETL,数据仓库工具Informatica介绍_informatic技术是什么意思
- 5macOS 环境下安装 Nginx_macos 安装nginx
- 6数据库MySql实验学习总结(一)_mysql实验总结
- 7大数据框架之Hadoop_hdfs存储600mb数据图
- 8异步电机矢量控制matlab simulink
- 9ISO26262汽车功能安全软件级产品研发的主要内容_汽车软件功能安全
- 10慕课美和易思_美和易思学习脚本最新
一文了解Spark引擎的优势及应用场景
赞
踩
Spark引擎诞生的背景
Spark的发展历程可以追溯到2009年,由加州大学伯克利分校的AMPLab研究团队发起。成为Apache软件基金会的孵化项目后,于2012年发布了第一个稳定版本。
以下是Spark的主要发展里程碑:
- 初始版本发布:2010年开发的Matei Zaharia的研究项目成为Spark的前身。在2010年夏季,Spark首次公开亮相。
- Apache孵化项目:2013年,Apache Spark成为Apache软件基金会的孵化项目。这一举动增加了Spark的可信度和可靠性,吸引了更多的贡献者和用户。
- 发布1.0版本:2014年5月,Spark发布了第一个1.0版本,标志着其正式成熟和稳定可用。
- 成为顶级项目:2014年6月,Spark成为Apache软件基金会的顶级项目。这个里程碑确认了Spark在大数据处理领域的领导地位。
- Spark Streaming和MLlib:2014年6月,Spark 1.0版本中首次引入了Spark Streaming和MLlib(机器学习库),丰富了Spark的功能。
- Spark SQL和DataFrame:2015年,Spark 1.3版本中引入了Spark SQL和DataFrame API,使得开发者可以更方便地进行结构化数据处理。
- 发布2.0版本:2016年7月,Spark发布了2.0版本,引入了Dataset API,更加统一了Spark的编程模型。
- 扩展生态系统:Spark逐渐形成了一个庞大的生态系统,包括了许多扩展库和工具,如GraphX、SparkR、Sparklyr等。
- 运行更灵活:Spark不仅可以运行在独立模式下,还可以与其他大数据处理框架(如Hadoop YARN和Apache Mesos)集成。
目前,Spark已经成为大数据处理领域的主要引擎之一,并在各个行业和领域得到广泛应用。它的发展依然持续,持续推出新的功能和改进,以满足不断增长的大数据处理需求。
主要功能和hive 相比较的优势是哪些?
主要功能
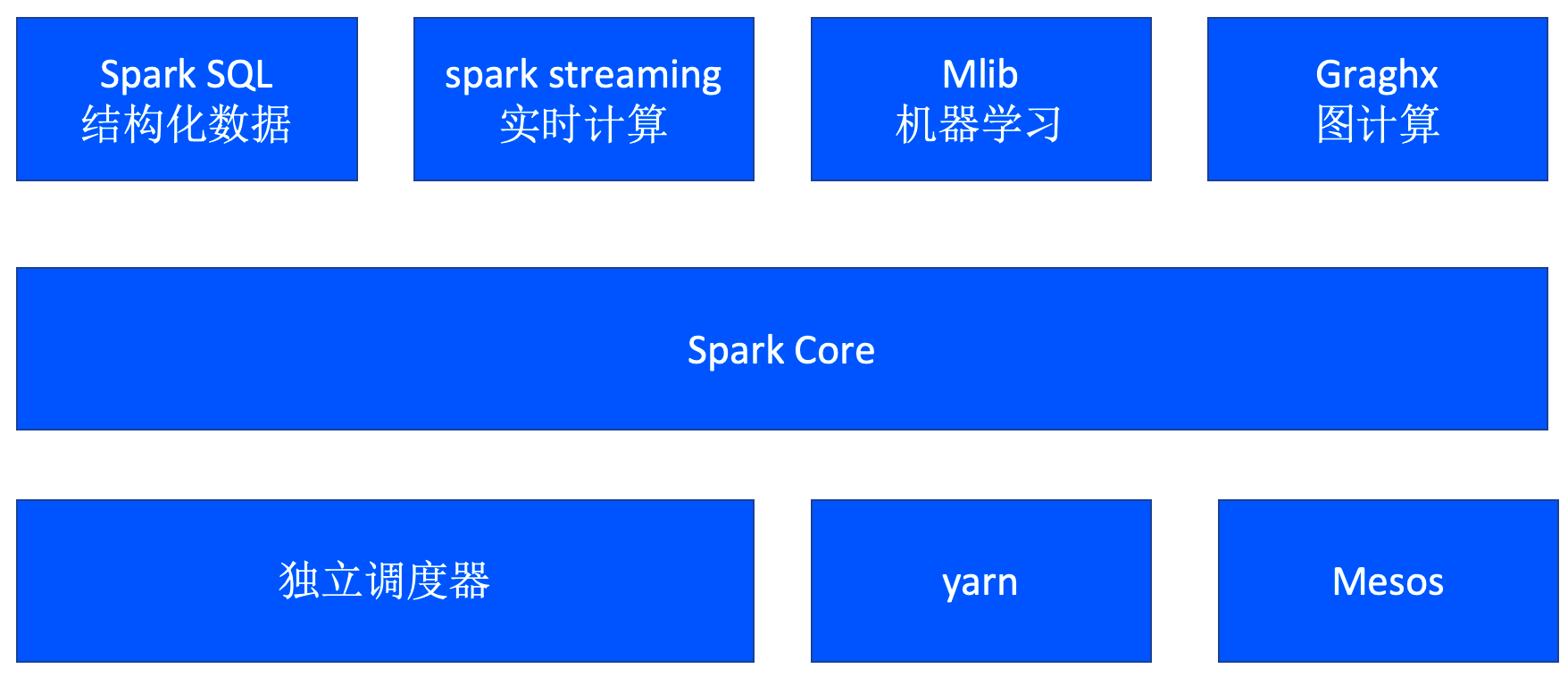
上图是spark 引擎的核心功能,其中包括Spark Core、Spark SQL、Spark Streaming、Spark MLlib、GraphX和Structured Streaming等。
- Spark Core:实现了Spark的基本功能,包含了RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
- Spark SQL:用于操作结构化数据的程序包。通过Spark SQL,我们可以使用SQL操作数据,方便数据分析和处理。
- Spark Streaming:提供了对实时数据进行流式计算的组件。Spark Streaming提供了用于操作数据流的API,可以实时处理数据并进行计算。
- Spark MLlib:是Spark提供的机器学习功能的程序库。它包括了常见的机器学习算法,如分类、回归、聚类、协同过滤等,还提供了模型评估和数据导入等支持功能。
- GraphX:是Spark中用于图计算的API。GraphX具有良好的性能,并提供了丰富的功能和运算符,可以在海量数据上运行复杂的图算法。
- Structured Streaming:是用于处理结构化流数据的组件,它可以统一离线和实时数据处理的API。Structured Streaming能够处理连续的数据流,并提供了更高级、更易用的API。
除了这些子项目,Spark还提供了集群管理器,可以高效地在一个计算节点到数千个计算节点之间伸缩计算。这使得Spark能够处理大规模的数据,并具有良好的可扩展性。
Spark的子项目和功能的不断扩展,使得Spark成为一个功能强大且灵活的大数据处理引擎。无论是在离线批处理还是实时流处理方面,Spark都提供了丰富的工具和API,满足了各种数据处理需求。
为了和hive 想比较,我们重点看看Spark SQL的语法.在Spark SQL中,常见的SQL语法包括以下内容:
1、查询语句: SELECT: 用于选择要查询的列 FROM: 用于指定要查询的数据表或视图 WHERE: 用于设置查询条件 GROUP BY: 用于对结果进行分组 HAVING: 用于对分组后的结果进行过滤 ORDER BY: 用于对结果进行排序 LIMIT: 用于限制返回的行数 2、表操作语句: CREATE TABLE: 用于创建表 DROP TABLE: 用于删除表 ALTER TABLE: 用于修改表结构 TRUNCATE TABLE: 用于清空表数据 3、数据操作语句: INSERT INTO: 用于向表中插入数据 UPDATE: 用于更新表中的数据 DELETE FROM: 用于删除表中的数据 4、聚合函数: COUNT: 统计行数 SUM: 求和 AVG: 求平均值 MIN: 求最小值 MAX: 求最大值 5、条件表达式: AND, OR: 逻辑与和逻辑或 NOT: 逻辑非 =, <>, <, >, <=, >=: 比较运算符 LIKE, IN, BETWEEN: 字符串匹配和范围判断

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
这些是Spark SQL中最常见的SQL语法,您可以根据需要使用它们来进行数据查询、表操作和数据操作等操作。并且Spark SQL可以从多种数据源读取数据。包括但不限于以下几种:
-
文件系统:Spark SQL可以从本地文件系统或Hadoop分布式文件系统(HDFS)中读取数据。它支持读取常见的文件格式,如文本文件(CSV、JSON、XML等)、Parquet文件、Avro文件、ORC文件等。
-
关系型数据库:Spark SQL可以从关系型数据库中读取数据,包括MySQL、PostgreSQL、Oracle等。您可以使用JDBC连接器来连接到数据库并执行SQL查询。
-
NoSQL数据库:Spark SQL也可以通过连接到NoSQL数据库(如MongoDB、Cassandra、Redis等)来读取数据。您可以使用相应的连接器来访问这些数据库,并使用Spark SQL查询语言进行查询。
-
Hive:Spark SQL可以与Hive集成,直接读取Hive表中的数据。这使得您可以使用Spark SQL查询来访问Hive中的数据,而无需写HiveQL语句。
除了以上几种常见的数据源,Spark SQL还支持许多其他的数据源,如Kafka、Elasticsearch、Azure Blob存储、Amazon S3等。您可以根据需要选择适合的数据源,并使用Spark SQL进行数据读取和查询操作。
既然Spark SQL 可以处理数据,那么为什么没有替代HIVE了?
主要是HIVE 支持一些Spark SQL 不支持的SQL语法。
例如以下是hive SQL 支持,而Spark SQL不支持的语法
1、查询建表 Create table lvhou_test as selec * from lvhou_test1; 2、Select子查询 select * from test1 where a,b in (select a,b from test2 where a = 'aa'); select * from test1 where a,b not in (select a,b from test2 where a = 'aa'); 3、Select union 查询 select * from test union all select * from test0;(合一) select * from test union select * from test0;(去重) select * from (select * from test union select * from test0) a; select a from (select * from test union all select * from test0) a; 4、Update 语句 update test1 set b = 'abc' where a = 'aa'; update test1 set a = 'abc'; 5、delete/alter 语句 delete from test1 where a = 'aa'; alter table test1 add columns (d string); 6、order by 语句 select a from test order by a desc; 7、sort by 语句 select a,b from test sort by b desc; 8、count 函数 select count(distinct *) from test00;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
注意这里说的不支持,是指它不是以sql的形式支持的,和前面说spark SQL支持聚合函数方式是不一样的,它是以data frame的形式支持
以下是使用count函数的示例:
import org.apache.spark.sql.SparkSession
// 创建SparkSession对象
val spark = SparkSession.builder()
.appName("CountFunctionExample")
.getOrCreate()
// 创建DataFrame
val data = Seq(("Alice", 25), ("Bob", 30), ("Charlie", 35), ("Alice", 40))
val df = spark.createDataFrame(data).toDF("name", "age")
// 使用count函数计算非空值的个数
val count = df.selectExpr("count(name)").as[Long].first()
println(s"Count: $count")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在上述示例中,通过创建一个包含姓名和年龄的DataFrame,然后使用count函数计算姓名列中的非空值的个数,最后打印结果。
请注意,count函数可以用于单列或多列,甚至可以在整个DataFrame上使用,以计算非空行的数量。
以上的语法上的区别就可以说明了hive SQL 和Spark SQL 的应用场景上的区别。
-
Hive SQL适用于大规模的离线批处理,而Spark SQL则适用于迭代式计算和交互式数据挖掘。Spark SQL通过使用RDD数据结构和内存存储优化来提高中间结果的计算效率。
-
相比之下,Hive SQL会将中间结果数据写入稳定的文件系统中,这可能会导致数据的复制备份、磁盘I/O和数据的序列化,从而在需要复用中间结果的操作中效率较低。而Spark SQL使用RDD数据结构将中间结果保存在内存中,可以通过控制数据集的分区来实现最优化的数据存储和处理。同时,Spark SQL还提供了丰富的API来操作数据集。
总结一下,hiveSQL 应用于大规模的离线跑批,但是对时间要求不高,而Spark SQL 应用于迭代式计算和交互式数据挖掘、Spark Streaming 支持流式数据计算、Spark MLlibk提供的机器学习功能的程序库。它包括了常见的机器学习算法,如分类、回归、聚类、协同过滤等,还提供了模型评估和数据导入等支持功能。GraphX用于图计算的API。可以在海量数据上运行复杂的图算法。
应用场景
Spark SQL 的迭代式计算的应用场景
迭代式计算是一种通过重复执行相同的计算步骤来达到某个目标的计算方法。在迭代式计算中,计算的结果会作为下一次计算的输入,这样可以逐步逼近目标值。迭代式计算通常用于解决无法通过单次计算得出精确解的问题,例如优化问题、机器学习算法等。通过多次迭代,可以逐步提高计算的精度和准确性。常见的迭代式计算用于最优化问题,用于求解最大化或最小化目标函数的问题。通过不断迭代,在每次迭代中找到使目标函数值最优化的参数。
- 在工程优化设计领域。它可以用来优化各种工程系统的设计和维护,例如确定一个复杂机械装置的尺寸、材料及配制,以最小化能源消耗或者最大化生产效率。
- 在金融领域,迭代式计算可以用于对股票、期权和其他金融资产的价格建模。通过对复杂的财务数据进行分析,迭代式计算可以帮助金融机构做出更好的风险决策,从而更好地保护资产。
- 交通规划也可以应用迭代式计算,以建立最优的道路和交通网络。迭代式计算可以考虑到不同的目标,如最小化出行时间、最小化交通拥堵、最小化公共交通成本,以及最小化环境污染等。
Spark Streaming 支持流式数据计算应用场景
Spark Streaming 支持许多流式数据计算应用场景,包括但不限于以下几个:
-
实时数据处理和分析:Spark Streaming可以处理连续流入的数据,并实时计算、聚合和分析数据。这可用于实时监控、实时报警、网络流量分析、实时可视化等。
-
基于流的机器学习:Spark Streaming可结合Spark的机器学习库(如MLlib)进行流式机器学习。通过连续接收数据流,并实时训练和更新模型,可以构建实时推荐系统、欺诈检测、实时广告投放等。
-
事件驱动的应用:Spark Streaming可以用于处理事件驱动的应用,如实时日志处理、社交媒体分析、网络安全监测等。它可以从事件流中提取有用的信息、进行模式识别和异常检测。
Spark MLlibk提供的机器学习功能应用场景
Spark MLlib的机器学习算法库可以在各种应用场景中使用。以下是一些常见的应用场景:
-
分类和回归:在分类和回归问题中,MLlib提供了支持向量机(SVM)、逻辑回归(Logistic Regression)、决策树(Decision Trees)、随机森林(Random Forests)、梯度提升树(Gradient-Boosted Trees)等算法。这些算法可以用于许多领域,如金融、营销、医疗等,用于预测和分类。
-
聚类:MLlib提供了多种聚类算法,如k均值聚类(K-means)、高斯混合模型(Gaussian Mixture Model)等。这些算法可以用于市场细分、用户分群、异常检测等。
-
协同过滤:MLlib提供了基于用户的协同过滤(User-Based Collaborative Filtering)和基于物品的协同过滤(Item-Based Collaborative Filtering)算法,用于推荐系统。这些算法可以根据用户的行为数据,如浏览记录或评分,为用户提供个性化的推荐。
-
特征工程:MLlib提供了一系列特征工程的函数和工具,用于数据的预处理和特征提取。例如,通过特征提取、降维、尺度变换等方法,可以将原始数据转换为高维特征向量,更好地适应机器学习算法的输入格式要求。
除了上述应用场景外,MLlib还支持模型评估、参数调优、模型持久化等常见机器学习任务。尤其是由于Spark的分布式计算模型,MLlib在大规模数据集上能够提供高性能的机器学习解决方案。
Spark GraphX 图计算框架应用场景
GraphX 是 Spark 提供的图计算框架,用于处理大规模图数据。它的应用场景包括但不限于以下几个方面:
-
社交网络分析:GraphX 可以用于分析社交网络中的节点和关系,如查找社交网络中的影响力最大的节点、查找节点之间的关系强度等。
-
推荐系统:GraphX 可以用于构建用户和商品之间的关系图,通过图算法进行推荐,如基于相似性的协同过滤、基于随机游走的推荐算法等。
-
路径分析:GraphX 可以用于分析路径相关的问题,如查找两个节点之间的最短路径、查找节点周围的节点等。
-
网络流分析:GraphX 可以用于分析网络流量,如找出网络中的瓶颈、计算最大流等。
结论:
当进行大规模数据量的离线跑批的时候,对时间延迟要求不高,成本投入有限的情况下使用Hive SQL,hive sql 对机器的要求不高,因为数据存储在文件中。而对数据计算复杂(有推荐、分类、聚类算法场景)且时延要求高的场景,如迭代计算, 交互式计算, 流计算、有机器学习算法需求,图计算需求,且成本投入可以接受的情况下使用Spark SQL,Spark SQL读取的数据都是存入到内存中,因此对机器的内存有要求,且要求内存较大, 相对较贵.

