
- 1【Quart 框架——来源于Flask的强大且灵活的异步Web框架】
- 2IDEA支付宝小程序开发流程——授权登录_支付宝小程序 minidev identitykeypath
- 3【计算机网络】域名劫持无处遁形:基于HTTPDNS打造可靠且安全的域名解析体系_域名解析接口
- 4什么是同步整流和异步整流_同步整流和异步整流的区别
- 525K Stars! Open WebUI + Ollama + Llama3搭建本地私人ChatGPT
- 6Postman 接口测试神器_在线postman
- 7RENISHAW雷尼绍双读数头系统应用分享
- 8亚马逊云科技 EC2服务搭配SD Webui开箱即用的AIGC文生图/图生图平台_aws sd-webui 配额
- 9elasticsearch配置文件详解_cluster.name
- 10MyBatis查询数据库之四(动态SQL -- if、trim、where、set、foreach 标签)_insert into和if标签
nn.RNN的输入输出及其内部结构说明
赞
踩
目录
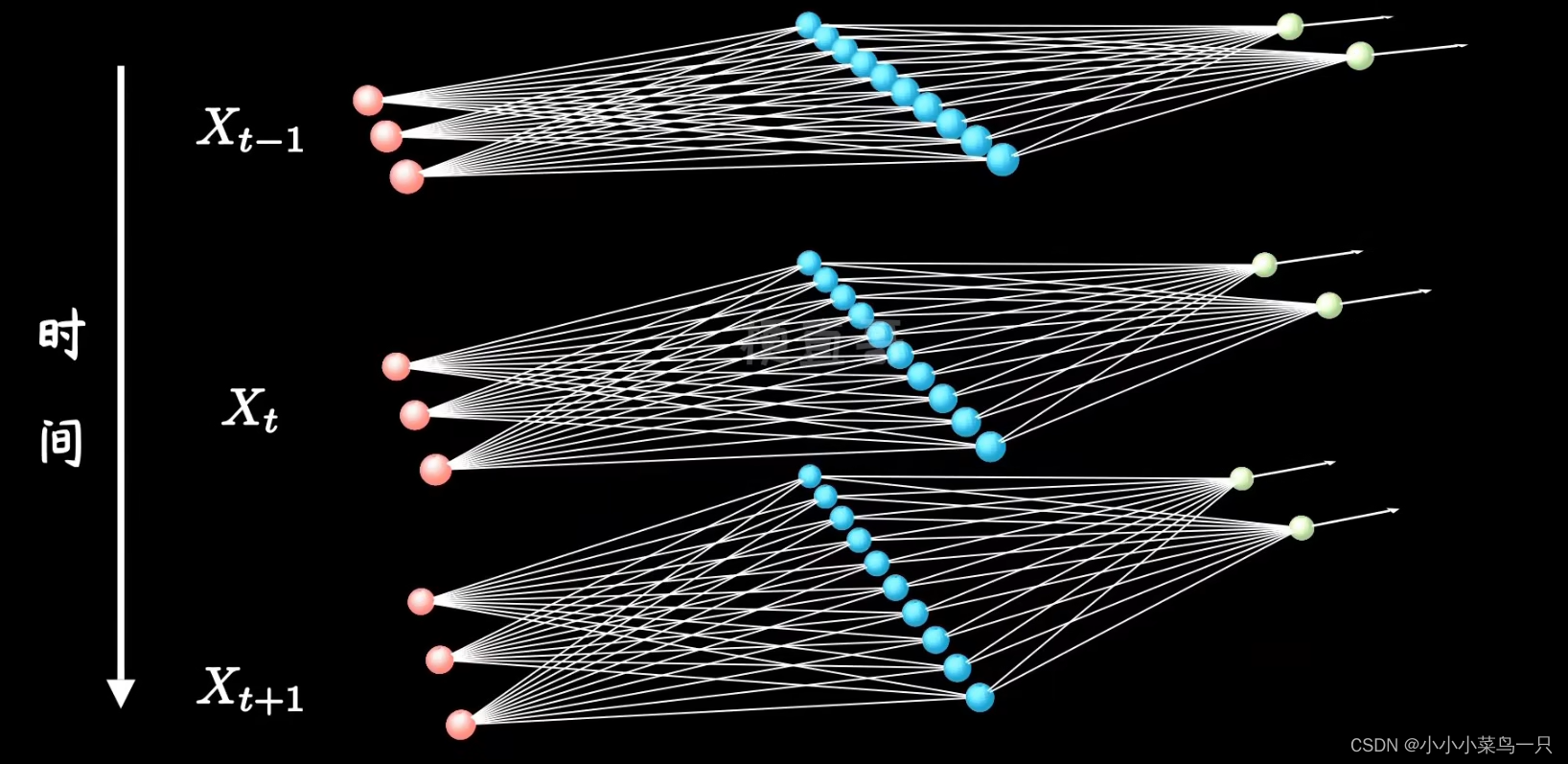
我们可以注意到这里的input是(T, N, E)而非和embedding的输出一样是(N, T, E)。这是因为rnn的自身结构:
为什么最后一个是hidden_size而不是神经网络的output_size呢?
不知道大家有没有发现:input、output的格式相同,都是[T,N,E]的形式,但为什么hidden_size如此不同变为了(num_layers, N, E)的形式呢?
根据PyTorch文档,nn.RNN的输入输出如下:
1.input
nn.RNN输入要求:(seq_len, batch_size, input_size)(T, N, E):
其中:
seq_len是序列长度- batch_size是批大小,
input_size是输入的特征维度
我们可以注意到这里的input是(T, N, E)而非和embedding的输出一样是(N, T, E)。这是因为rnn的自身结构:
图片来自b站耿直哥、
我们可以明显看到rnn网络在每个时间步中完成一次神经网络的功能。而embedding则是在每个时间步中向量化一个单词。
所以在处理数据时一定要记得进行矩阵变化!!!
例:
在seq2seq中因为要将信息压缩在一个矩阵中通常还会执行以下步骤:
hz = torch.reshape(hz, shape=(hz.shape[0], self.output_dim)) # [N,?,E] -> [N,?*E]
2.output
nn.RNN会有两个输出,分别是ho(output)和hn(hidden)。
2.1 h_o(output)h_o会输出RNN在所有时间步上的隐藏状态输出。它包含了整个序列在每个时间步的隐藏状态。
ho的输出如下:(seq_len, batch_size, num_directions * hidden_size) (T, N, E*(1or2)):
其中:
seq_len是输入序列的长度- batch_size是批大小
num_directions是方向数,单向为1,双向为2hidden_size是隐藏状态的维度为什么最后一个是hidden_size而不是神经网络的output_size呢?
原因是
h_n只保留了最后一步的 hidden_state,但中间的 hidden_state 也有可能会参与计算,所以 pytorch 把中间每一步输出的 hidden_state 都放到output中(当然,只保留了 hidden_state 最后一层的输出),因此,你可以发现这个output的维度是(seq_len, batch, num_directions * hidden_size)。
接下来我们介绍h_n(hidden)。我想你一定好奇为什么是h_n而不叫h_h?说实话我也很好奇,但大家约定俗成的名称就是h_n。有哪位大神知道可以留言感激不尽。
2.2 h_n(hidden):(h_n代表隐藏层的输入输出,在rnn网络中输入输出是格式是相同的)
(num_layers * num_directions, batch_size, hidden_size)
(num_layers*(1or2), N, E):
如果没有提供,默认为全0
其中:
num_layers是RNN的层数。(不明白可以看下面的rnn结构)num_directions是方向数,如果是单向RNN则为1,如果是双向RNN则为2。hidden_size是隐藏状态的维度。不知道大家有没有发现:input、output的格式相同,都是[T,N,E]的形式,但为什么hidden_size如此不同变为了(num_layers, N, E)的形式呢?
简单来说就是因为隐藏状态不是一个时间序列,而是在每一层中都持有一个向量。而输出中间状态就是为了得到每个时刻的隐层输出。所以num_layers * num_directions 这个维度代替了seq_len。
初始化rnn:
rnn = nn.RNN(input_size, hidden_size, num_layers)无需多言看图即懂:
- 其中Xn是input_size,
- A(第一层), A'(第二层), A''(第三层) 则是num_layers,
- 在每个A中都是一个RNN_cell,每个都是一个全连接网络,而hidden_size类似于全连接网络中的隐藏层。
多层rnn不懂看这里:循环神经网络的改进:多层RNN、双向RNN与预训练-CSDN博客
RNN_cell:
其内部结构如下:
没想到吧依旧是这张图。其实所谓的RNN_cell就是一个全连接神经网络。
而内部的计算过程:
输入:
input: 当前时间步的输入,形状为(batch_size, input_size) (T, E)hidden: 前一时间步的隐藏状态,形状为(batch_size, hidden_size)前向计算:
- 将输入
input和前一隐藏状态hidden进行线性变换:
- 将线性变换的结果
gate应用激活函数(如tanh)得到新的隐藏状态new_hidden:new_hidden = F.tanh(gate)输出:
new_hidden: 当前时间步的新隐藏状态,形状为(batch_size, hidden_size)(N, E)这个
new_hidden里的hidden_size就是前面input、output、h_0的hidden_size啦。对于RNN整个网络来说,这个new_hidden是RNN_cell的输出,就是隐层的输出。但是对于RNN_cell来说,则是经过完整的全连接网络并且激活过的output!



