
- 1【字节跳动】职级、薪酬、绩效全认知_职级3-1是什么意思
- 2【java】仿级联查询 | Java通过DSL字符串查询ES (es8 dsl java)_java dsl
- 3openstack 查看_软件定义存储之ScaleIO,OpenStack环境部署使用
- 4自适应直方图均衡化(CLAHE)
- 5Video.js使用教程一(详解)
- 6Python_调用/usr/bin下python解释器,来指定脚本用什么解释器来执行
- 7stm32启动代码详细分析记录_stm32 启动代码 实现|c语言
- 8http协议入门之 SameSite cookies_http2.0会有samesite
- 9Coco数据集中的rle格式处理_coco rle
- 102024华为OD机试真题指南宝典—持续更新(JAVA&Python&C++&JS)【彻底搞懂算法和数据结构—算法之翼】
自注意力机制 Self-Attention与Transformer的原理及结构(编码器、解码器的原理及代码实现)_自注意力中的残差连接
赞
踩
Transformer
1.自注意力机制 Self-Attention
自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题。
自注意力机制的计算过程:
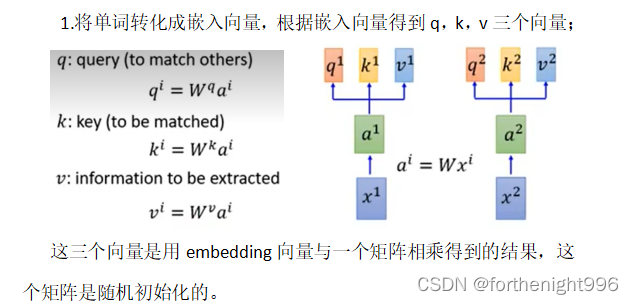
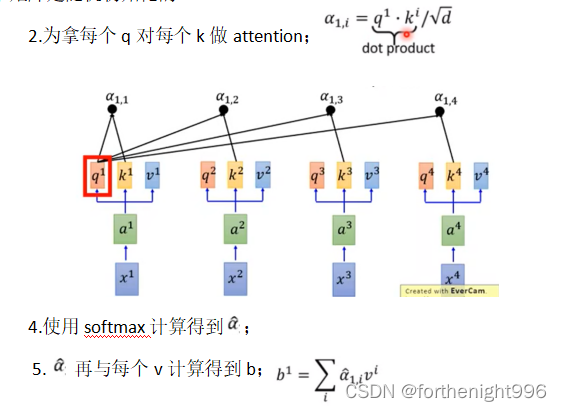

①Multi-head Self-Attention
之前我们都是用Q去找K,来计算相关性。但是两个事物之间相关性本身可能有多种不同的类型。因此设置多个Q(head),不同的Q来负责不同的相关性,所以需要Multi-head Self-Attention。
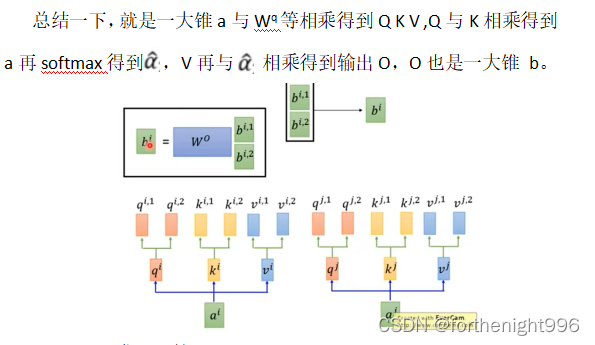
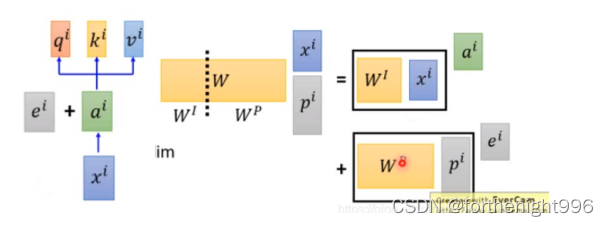
我们可以发现不管是Self-attention还是Multi-head Self-attention的操作中都没有加入关于输入input的位置信息(positional encoding)。
因此,当我们觉得我们做的任务中位置信息也很重要的话,可以使用positional encoding的方法来为每一个input设置一个唯一的位置。
2.Transformer的结构
Transformer 架构是以encoder/decoder架构为基础在Encoder和Decoder中都使用了Self-attention, Point-wise和全连接层。Encoder和decoder的大致结构分别如下图的左半部分和右半部分所示:
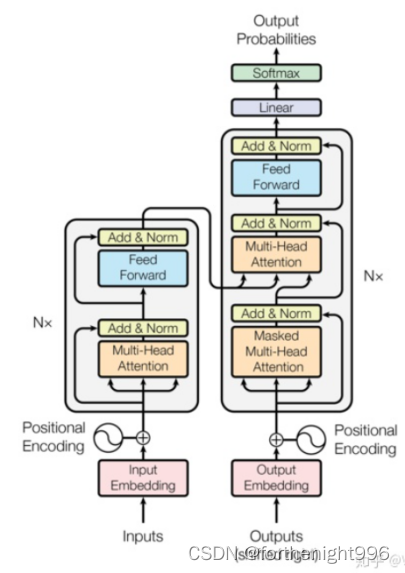
Encoder将输入序列(x1,…,xn)映射到一个连续表示序列 z=(z1,…,zn)。对于编码得到的z,Decoder每次解码生成一个符号,直到生成完整的输出序列:(y1,…,ym)。对于每一步解码,模型都是自回归的,即在生成下一个符号时将先前生成的符号作为附加输入。
①Encoder and Decoder
输入文本会先经过一个叫Encoders的模块进行编码,数据再传入一个叫Decoders的模块进行解码,解码后就得到了翻译后的文本。
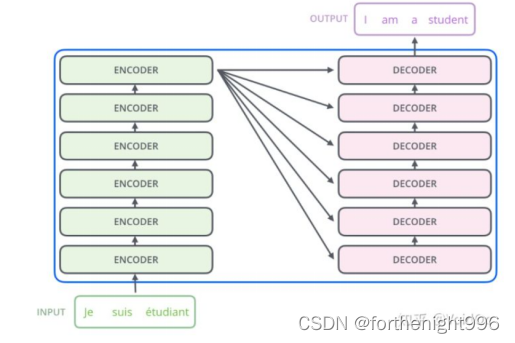
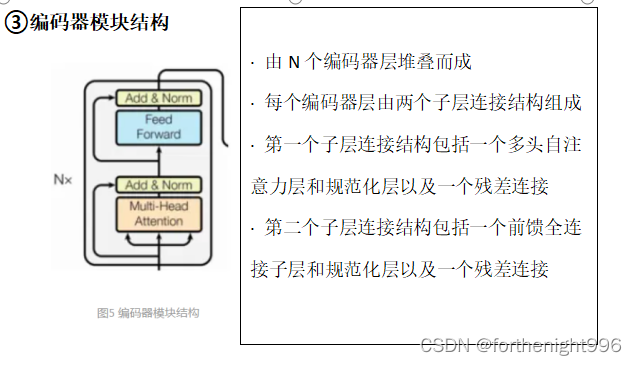
每个编码器的结构均相同(但它们不共享权重),每层有两个子层:自注意力层(self-attention) 和全连接的前馈网络层(feed-forward)。
从编码器输入的句子首先会经过一个自注意力层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。自注意力层的输出会传递到前馈神经网络中。每个位置的单词对应的前馈神经网络相同。
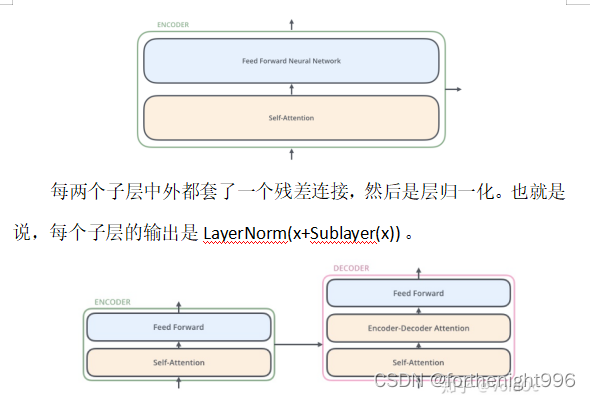
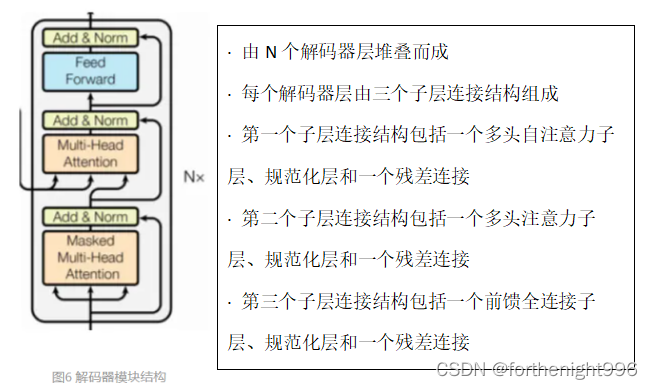
自注意力层和前馈层之间还有一个注意力层,用来关注输入句子的相关部分。确保了生成位置i的预测时,仅依赖小于i的位置处的已知输出,相当于把后面不该看到的信息屏蔽掉。
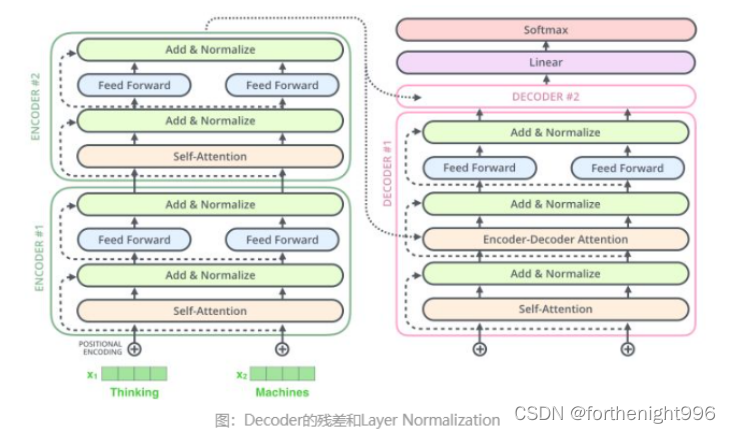
②残差连接 residual connections
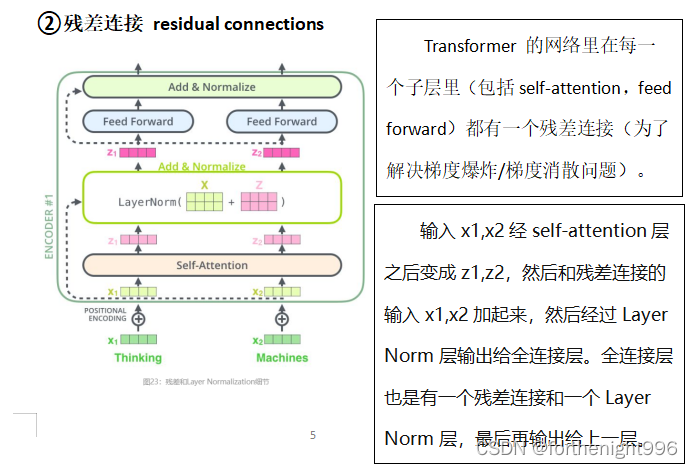
整体加到Encoder\Decoder中看就是如下图所示:区别在于它多了一个Encoder-Decoder Attention层,这个层的输入除了来自Self-Attention之外还有Encoder最后一层的所有时刻的输出。Encoder-Decoder Attention层的Query来自下一层,而Key和Value则来自Encoder的输出。
③编码器模块结构
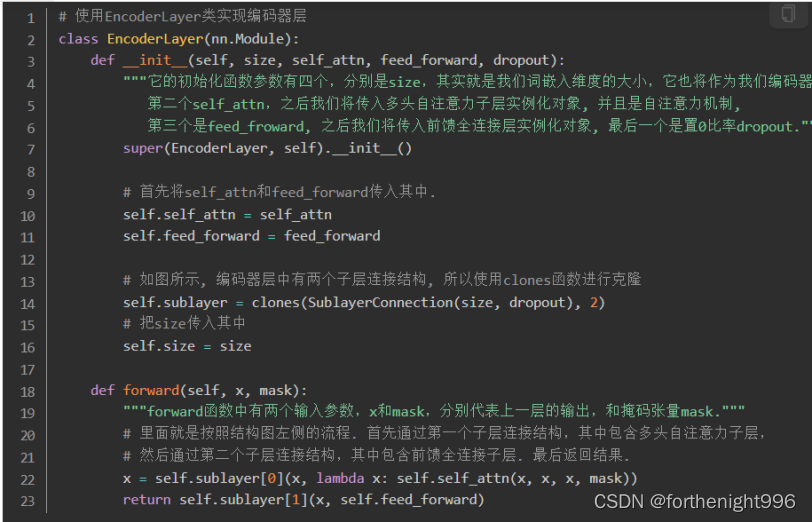
编码器的代码分析:

编码器层的代码分析:
④解码器模块结构
解码器的代码分析:

解码器层的代码实现:
# 使用DecoderLayer的类实现解码器层class DecoderLayer(nn.Module): def __init__(self, size, self_attn, src_attn, feed_forward, dropout): """ 初始化函数的参数有5个 第一个是分别是size,代表词嵌入的维度大小, 同时也代表解码器层的尺寸, 第二个是self_attn,多头自注意力对象,也就是说这个注意力机制需要Q=K=V, 第三个是src_attn,多头注意力对象,这里Q!=K=V, 第四个是前馈全连接层对象, 最后是droupout置0比率。""" super(DecoderLayer, self).__init__() # 在初始化函数中, 主要就是将这些输入传到类中 self.size = size self.self_attn = self_attn self.src_attn = src_attn self.feed_forward = feed_forward # 按照结构图使用clones函数克隆三个子层连接对象. self.sublayer = clones(SublayerConnection(size, dropout), 3) def forward(self, x, memory, source_mask, target_mask): """forward函数中的参数有4个, 分别是来自上一层的输入x, 来自编码器层的语义存储变量mermory, 以及源数据掩码张量和目标数据掩码张量.""" # 将memory表示成m方便之后使用 m = memory # 将x传入第一个子层结构,第一个子层结构的输入分别是x和self-attn函数,因为是自注意力机制,所以Q,K,V都是x # 最后一个参数是目标数据掩码张量,这时要对目标数据进行遮掩,因为此时模型可能还没有生成任何目标数据 # 比如在解码器准备生成第一个字符或词汇时,我们其实已经传入了第一个字符以便计算损失 # 但是我们不希望在生成第一个字符时模型能利用这个信息,因此我们会将其遮掩,同样生成第二个字符或词汇时, # 模型只能使用第一个字符或词汇信息,第二个字符以及之后的信息都不允许被模型使用. x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask)) # 接着进入第二个子层,这个子层中常规的注意力机制,q是输入x; k,v是编码层输出memory, # 同样也传入source_mask,但是进行源数据遮掩的原因并非是抑制信息泄漏,而是遮蔽掉对结果没有意义的字符而产生的注意力值, # 以此提升模型效果和训练速度. 这样就完成了第二个子层的处理. x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask)) # 最后一个子层就是前馈全连接子层,经过它的处理后就可以返回结果.这就是我们的解码器层结构. return self.sublayer[2](x, self.feed_forward)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35

