
- 1Vulnhub靶机:FunBox 8
- 2SpringBoot项目中使用SpringData-JPA持久化数据_项目中使用jpa
- 3django 模型数据类型_django模型数据类型
- 4MySQL基础~排序查询、聚合函数查询、Group by分组查询、limit分页_mysql如何让聚合函数在limit分页前进行
- 5请求封装(axios、fetch)
- 6jmeter-04创建请求
- 7面试官:如何处理高并发场景?_如何处理高并发问题面试
- 8php调用c dll,PHP中调用C/C++制作的动态链接库的教程
- 9react是什么?react和vue的区别?react有什么优点?_eva和react摸起来有什么区别?
- 102023前端面试题及答案整理(JS面试题)
人工智能、机器学习、深度学习的关系_和机器学习并列的
赞
踩
人工智能、机器学习、深度学习的关系
近些年人工智能、机器学习和深度学习的概念十分火热,但很多从业者却很难说清它们之间的关系。在研究深度学习之前,先从三个概念的正本清源开始。
概括来说,人工智能、机器学习和深度学习覆盖的技术范畴是逐层递减的。人工智能是最宽泛的概念。机器学习是当前比较有效的一种实现人工智能的方式。深度学习是机器学习算法中最热门的一个分支,近些年取得了显著的进展,并替代了大多数传统机器学习算法。三者的关系如 图1 所示,即:人工智能 > 机器学习 > 深度学习。

图1:人工智能、机器学习和深度学习三者关系示意
如字面含义,人工智能是研发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。由于这个定义只阐述了目标,而没有限定方法,因此实现人工智能存在的诸多方法和分支,导致其变成一个“大杂烩”式的学科。
机器学习
区别于人工智能,机器学习、尤其是监督学习则有更加明确的指代。机器学习是专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构,使之不断改善自身的性能。这句话有点“云山雾罩”的感觉,让人不知所云,下面从机器学习的实现和方法论两个维度进行剖析,更加清晰地认识机器学习的来龙去脉。
机器学习的实现
机器学习的实现可以分成两步:训练和预测,类似于熟悉的归纳和演绎:
• 归纳: 从具体案例中抽象一般规律,机器学习中的“训练”亦是如此。从一定数量的样本(已知模型输入XXX和模型输出YYY)中,学习输出YYY与输入XXX的关系(可以想象成是某种表达式)。
• 演绎: 从一般规律推导出具体案例的结果,机器学习中的“预测”亦是如此。基于训练得到的YYY与XXX之间的关系,如出现新的输入XXX,计算出输出YYY。如果通过模型计算的输出和真实场景的输出一致,说明模型是有效的。
机器学习的方法论
下面从“牛顿第二定律”入手,介绍机器学习的思考过程,以及在过程中如何确定模型参数,模型三个关键部分(假设、评价、优化)该如何应用。
案例:牛顿第二定律
机器学习的方法论和人类科研的过程有异曲同工之妙,下面以“机器从牛顿第二定律实验中学习知识”为例,帮助读者更加深入理解机器学习(监督学习)的方法论本质。
牛顿第二定律
牛顿第二定律是艾萨克·牛顿在1687年于《自然哲学的数学原理》一书中提出的,其常见表述:物体加速度的大小跟作用力成正比,跟物体的质量成反比,与物体质量的倒数成正比。牛顿第二运动定律和第一、第三定律共同组成了牛顿运动定律,阐述了经典力学中基本的运动规律。
在中学课本中,牛顿第二定律有两种实验设计方法:倾斜滑动法和水平拉线法,如 图2 所示。

图2:牛顿第二定律实验设计方法
相信很多读者都有摆弄滑轮和小木块做物理实验的青涩年代和美好回忆。通过多次实验数据,可以统计出如 表1 所示的不同作用力下的木块加速度。

表1:实验获取的大量数据样本和观测结果
观察实验数据不难猜测,物体的加速度aaa和作用力之间的关系应该是线性关系。因此提出假设 a=w⋅Fa = w \cdot Fa=w⋅F,其中,aaa代表加速度,FFF代表作用力,www是待确定的参数。
通过大量实验数据的训练,确定参数www是物体质量的倒数(1/m)(1/m)(1/m),即得到完整的模型公式a=F⋅(1/m)a = F \cdot (1/m)a=F⋅(1/m)。当已知作用到某个物体的力时,基于模型可以快速预测物体的加速度。例如:燃料对火箭的推力FFF=10,火箭的质量mmm=2,可快速得出火箭的加速度aaa=5。
确定模型参数
这个有趣的案例演示了机器学习的基本过程,但其中有一个关键点的实现尚不清晰,即:如何确定模型参数(w=1/m)(w=1/m)(w=1/m)?
确定参数的过程与科学家提出假说的方式类似,合理的假说至少可以解释所有的已知观测数据。如果未来观测到不符合理论假说的新数据,科学家会尝试提出新的假说。如天文史上,使用大圆和小圆组合的方式计算天体运行在中世纪是可以拟合观测数据的。但随着欧洲机械工业的进步,天文观测设备逐渐强大,越来越多的观测数据无法套用已有的理论,这促进了使用椭圆计算天体运行的理论假说出现。因此,模型有效的基本条件是能够拟合已知的样本,这给提供了学习有效模型的实现方案。
图3 是以HHH为模型的假设,它是一个关于参数WWW和输入XXX的函数,用H(W,X)H(W, X)H(W,X) 表示。模型的优化目标是H(W,X)H(W, X)H(W,X)的输出与真实输出YYY尽量一致,两者的相差程度即是模型效果的评价函数(相差越小越好)。那么,确定参数的过程就是在已知的样本上,不断减小该评价函数(H(W,X)H(W, X)H(W,X) 和YYY的差距)的过程,直到学习到一个参数WWW,使得评价函数的取值最小。这个衡量模型预测值和真实值差距的评价函数也被称为损失函数(损失Loss)。

图3:确定模型参数示意图
举例类比,机器如一个机械的学生一样,只能通过尝试答对(最小化损失)大量的习题(已知样本)来学习知识(模型参数WWW),并期望用学习到的知识(模型参数WWW)所代表的模型H(W,X)H(W, X)H(W,X),回答不知道答案的考试题(未知样本)。最小化损失是模型的优化目标,实现损失最小化的方法称为优化算法,也称为寻解算法(找到使得损失函数最小的参数解)。参数WWW和输入XXX组成公式的基本结构称为假设。在牛顿第二定律的案例中,基于对数据的观测,提出了线性假设,即作用力和加速度是线性关系,用线性方程表示。由此可见,模型假设、评价函数(损失/优化目标)和优化算法是构成模型的三个部分。
上述过程在一些文献中也常用下面的公式图所表示:未知目标函数f产生了一些训练样本D,从假设集合H中,通过学习算法A找到一个函数g,g能够最大程度的拟合训练样本D,那么可以认为函数g就接近于目标函数f。
图:使用数据去计算假设g去逼近目标f
模型结构介绍
那么构成模型的三个部分(模型假设、评价函数和优化算法)是如何支撑机器学习流程的呢?如图4 所示:

图4:机器执行学习的框架
• 模型假设:世界上的可能关系千千万,漫无目标的试探YYYXXX之间的关系显然是十分低效的。因此假设空间先圈定了一个模型能够表达的关系可能,如蓝色圆圈所示。机器还会进一步在假设圈定的圆圈内寻找最优的YYYXXX关系,即确定参数WWW。
• 评价函数:寻找最优之前,需要先定义什么是最优,即评价一个YYY~XXX关系的好坏的指标。通常衡量该关系是否能很好的拟合现有观测样本,将拟合的误差最小作为优化目标。
• 优化算法:设置了评价指标后,就可以在假设圈定的范围内,将使得评价指标最优(损失函数最小/最拟合已有观测样本)的YYY~XXX关系找出来,这个寻找的方法即为优化算法。最笨的优化算法即按照参数的可能,穷举每一个可能取值来计算损失函数,保留使得损失函数最小的参数作为最终结果。
从上述过程可以得出,机器学习的过程与牛顿第二定律的学习过程基本一致,都分为假设、评价和优化三个阶段:
- 假设:通过观察加速度aaa和作用力FFF的观测数据,假设aaa和FFF是线性关系,即a=w⋅Fa = w \cdot Fa=w⋅F。
- 评价:对已知观测数据上的拟合效果好,即w⋅Fw \cdot Fw⋅F计算的结果,要和观测的aaa尽量接近。
- 优化:在参数www的所有可能取值中,发现w=1/mw=1/mw=1/m可使得评价最好(最拟合观测样本)。
机器执行学习的框架体现了其学习的本质是“参数估计”(Learning is parameter estimation)。在此基础上,许多看起来完全不一样的问题都可以使用同样的框架进行学习,如科学定律、图像识别、机器翻译和自动问答等,它们的学习目标都是拟合一个“大公式”,如 图5 所示。

图5:机器学习就是拟合一个“大公式”
他们的学习目标都是拟合一个“大公式”,公式中有很多可学习参数,机器学习的过程就是不断更新这些可学习参数。假定fff是最终期望的"公式"函数,ggg是当前公式所拟合的函数。那么,机器学习的目的就是让假设ggg更加逼近期望目标fff。
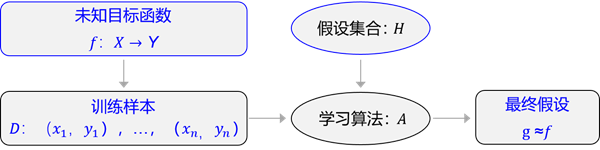
图6:使用数据去计算假设g去逼近目标f
深度学习
机器学习算法理论在上个世纪90年代发展成熟,在许多领域都取得了成功应用。但平静的日子只延续到2010年左右,随着大数据的涌现和计算机算力提升,深度学习模型异军突起,极大改变了机器学习的应用格局。今天,多数机器学习任务都可以使用深度学习模型解决,尤其在语音、计算机视觉和自然语言处理等领域,深度学习模型的效果比传统机器学习算法有显著提升。
那么相比传统的机器学习算法,深度学习做出了哪些改进呢?其实两者在理论结构上是一致的,即:模型假设、评价函数和优化算法,其根本差别在于假设的复杂度,如 图6 所示。

图7:深度学习的模型复杂度难以想象
不是所有的任务都像牛顿第二定律那样简单直观。对于 图7 中的美女照片,人脑可以接收到五颜六色的光学信号,能用极快的速度反应出这张图片是一位美女,而且是程序员喜欢的类型。但对计算机而言,只能接收到一个数字矩阵,对于美女这种高级的语义概念,从像素到高级语义概念中间要经历的信息变换的复杂性是难以想象的!这种变换已经无法用数学公式表达,因此研究者们借鉴了人脑神经元的结构,设计出神经网络的模型。
神经网络的基本概念
人工神经网络包括多个神经网络层,如卷积层、全连接层、LSTM等,每一层又包括很多神经元,超过三层的非线性神经网络都可以被称为深度神经网络。通俗的讲,深度学习的模型可以视为是输入到输出的映射函数,如图像到高级语义(美女)的映射,足够深的神经网络理论上可以拟合任何复杂的函数。因此神经网络非常适合学习样本数据的内在规律和表示层次,对文字、图像和语音任务有很好的适用性。因为这几个领域的任务是人工智能的基础模块,所以深度学习被称为实现人工智能的基础也就不足为奇了。
神经网络结构如 图8 所示。

图8:神经网络结构示意图
• 神经元: 神经网络中每个节点称为神经元,由两部分组成:
o 加权和:将所有输入加权求和。
o 非线性变换(激活函数):加权和的结果经过一个非线性函数变换,让神经元计算具备非线性的能力。
• 多层连接: 大量这样的节点按照不同的层次排布,形成多层的结构连接起来,即称为神经网络。
• 前向计算: 从输入计算输出的过程,顺序从网络前至后。
• 计算图: 以图形化的方式展现神经网络的计算逻辑又称为计算图。也可以将神经网络的计算图以公式的方式表达,如下:
Y=f3(f2(f1(w1⋅x1+w2⋅x2+w3⋅x3+b)+…)…)…)Y =f_3 ( f_2 ( f_1 ( w_1\cdot x_1+w_2\cdot x_2+w_3\cdot x_3+b ) + … ) … ) … )Y=f3(f2(f1(w1⋅x1+w2⋅x2+w3⋅x3+b)+…)…)…)
由此可见,神经网络并没有那么神秘,它的本质是一个含有很多参数的“大公式”。如果大家感觉这些概念仍过于抽象,理解的不够透彻,先不用着急,后续会以实践案例的方式,再次介绍这些概念。
深度学习的发展历程
那么如何设计神经网络呢?下一章会以“房价预测”为例,演示使用Python实现神经网络模型的细节。在此之前,先回顾下深度学习的悠久历史。
神经网络思想的提出已经是75年前的事情了,现今的神经网络和深度学习的设计理论是一步步趋于完善的。在这漫长的发展岁月中,一些取得关键突破的闪光时刻,值得这些深度学习爱好者们铭记,如 图9 所示。

图9:深度学习发展历程
• 1940年代:首次提出神经元的结构,但权重是不可学的。
• 50-60年代:提出权重学习理论,神经元结构趋于完善,开启了神经网络的第一个黄金时代。
• 1969年:提出异或问题(人们惊讶的发现神经网络模型连简单的异或问题也无法解决,对其的期望从云端跌落到谷底),神经网络模型进入了被束之高阁的黑暗时代。
• 1986年:新提出的多层神经网络解决了异或问题,但随着90年代后理论更完备并且实践效果更好的SVM等机器学习模型的兴起,神经网络并未得到重视。
• 2010年左右:深度学习进入真正兴起时期。随着神经网络模型改进的技术在语音和计算机视觉任务上大放异彩,也逐渐被证明在更多的任务,如自然语言处理以及海量数据的任务上更加有效。至此,神经网络模型重新焕发生机,并有了一个更加响亮的名字:深度学习。
为何神经网络到2010年后才焕发生机呢?这与深度学习成功所依赖的先决条件:大数据涌现、硬件发展和算法优化有关。
• 大数据是神经网络发展的有效前提。神经网络和深度学习是非常强大的模型,需要足够量级的训练数据。时至今日,之所以很多传统机器学习算法和人工特征依然是足够有效的方案,原因在于很多场景下没有足够的标记数据来支撑深度学习。深度学习的能力特别像科学家阿基米德的豪言壮语:“给我一根足够长的杠杆,我能撬动地球!”。深度学习也可以发出类似的豪言:“给我足够多的数据,我能够学习任何复杂的关系”。但在现实中,足够长的杠杆与足够多的数据一样,往往只能是一种美好的愿景。直到近些年,各行业IT化程度提高,累积的数据量爆发式地增长,才使得应用深度学习模型成为可能。
• 依靠硬件的发展和算法的优化。现阶段,依靠更强大的计算机、GPU、autoencoder预训练和并行计算等技术,深度学习在模型训练上的困难已经被逐渐克服。其中,数据量和硬件是更主要的原因。没有前两者,科学家们想优化算法都无从进行。
深度学习的研究和应用蓬勃发展
早在1998年,一些科学家就已经使用神经网络模型识别手写数字图像了。但深度学习在计算机视觉应用上的兴起,还是在2012年ImageNet比赛上,使用AlexNet做图像分类。如果比较下1998年和2012年的模型,会发现两者在网络结构上非常类似,仅在细节上有所优化。在这十四年间,计算性能的大幅提升和数据量的爆发式增长,促使模型完成了从“简单的数字识别”到“复杂的图像分类”的跨越。
虽然历史悠久,但深度学习在今天依然在蓬勃发展,一方面基础研究快速发展,另一方面工业实践层出不穷。基于深度学习的顶级会议ICLR(International Conference on Learning Representations)统计,深度学习相关的论文数量呈逐年递增的状态,如 图10 所示。同时,不仅仅是深度学习会议,与数据和模型技术相关的会议ICML和KDD,专注视觉的CVPR和专注自然语言处理的EMNLP等国际会议的大量论文均涉及着深度学习技术。该领域和相关领域的研究方兴未艾,技术仍在不断创新突破中。

图10:深度学习相关论文数量逐年攀升
另一方面,以深度学习为基础的人工智能技术,在升级改造众多的传统行业领域,存在极其广阔的应用场景。图11 选自艾瑞咨询的研究报告,人工智能技术不仅可在众多行业中落地应用(广度),在部分行业(如安防)已经实现了市场化变现和高速增长(深度),为社会贡献了巨大的经济价值。

图11:以深度学习为基础的AI技术在各行业广泛应用
深度学习改变了AI应用的研发模式
实现了端到端的学习
深度学习改变了很多领域算法的实现模式。在深度学习兴起之前,很多领域建模的思路是投入大量精力做特征工程,将专家对某个领域的“人工理解”沉淀成特征表达,然后使用简单模型完成任务(如分类或回归)。而在数据充足的情况下,深度学习模型可以实现端到端的学习,即不需要专门做特征工程,将原始的特征输入模型中,模型可同时完成特征提取和分类任务,如 图12 所示。

图12:深度学习实现了端到端的学习
以计算机视觉任务为例,特征工程是诸多图像科学家基于人类对视觉理论的理解,设计出来的一系列提取特征的计算步骤,典型如SIFT特征。在2010年之前的计算机视觉领域,人们普遍使用SIFT一类特征+SVM一类的简单浅层模型完成建模任务。
说明:
SIFT特征由David Lowe在1999年提出,在2004年加以完善。SIFT特征是基于物体上的一些局部外观的兴趣点而与影像的大小和旋转无关。对于光线、噪声、微视角改变的容忍度也相当高。基于这些特性,它们是高度显著而且相对容易撷取,在母数庞大的特征数据库中,很容易辨识物体而且鲜有误认。使用SIFT特征描述对于部分物体遮蔽的侦测率也相当高,甚至只需要3个以上的SIFT物体特征就足以计算出位置与方位。在现今的电脑硬件速度下和小型的特征数据库条件下,辨识速度可接近即时运算。SIFT特征的信息量大,适合在海量数据库中快速准确匹配。
实现了深度学习框架标准化
除了应用广泛的特点外,深度学习还推动人工智能进入工业大生产阶段,算法的通用性导致标准化、自动化和模块化的框架产生,如 图13 所示。

图13:深度学习模型具有通用性特点
在此之前,不同流派的机器学习算法理论和实现均不同,导致每个算法均要独立实现,如随机森林和支撑向量机(SVM)。但在深度学习框架下,不同模型的算法结构有较大的通用性,如常用于计算机视觉的卷积神经网络模型(CNN)和常用于自然语言处理的长期短期记忆模型(LSTM),都可以分为组网模块、梯度下降的优化模块和预测模块等。这使得抽象出统一的框架成为了可能,并大大降低了编写建模代码的成本。一些相对通用的模块,如网络基础算子的实现、各种优化算法等都可以由框架实现。建模者只需要关注数据处理,配置组网的方式,以及用少量代码串起训练和预测的流程即可。
在深度学习框架出现之前,机器学习工程师处于手工业作坊生产的时代。为了完成建模,工程师需要储备大量数学知识,并为特征工程工作积累大量行业知识。每个模型是极其个性化的,建模者如同手工业者一样,将自己的积累形成模型的“个性化签名”。而今,“深度学习工程师”进入了工业化大生产时代。只要掌握深度学习必要但少量的理论知识,掌握Python编程,即可在深度学习框架上实现非常有效的模型,甚至与该领域最领先的模型不相上下。建模这个被“老科学家”们长期把持的建模领域面临着颠覆,也是新入行者的机遇。

图14:深度学习工程师处于工业化大生产时代,“老科学家”长期积累的优势不再牢固
人生天地之间,若白驹过隙,忽然而已,每个人都希望留下自己的足迹。为何要学习深度学习技术,以及如何通过这本书来学习呢?一方面,深度学习的应用前景广阔,是极好的发展方向和职业选择。另一方面,本文会使用国产的深度学习框架飞桨(PaddlePaddle)来编写实践案例,基于框架的编程让深度学习变得易学易用。

