
- 1卷积神经网络算法解读
- 2qtcreator安装及配置
- 3vue3中报错ReferenceError: require is not defined_vue3 referenceerror: require is not defined
- 4MATLAB|【免费】高比例可再生能源电力系统的调峰成本量化与分摊模型
- 5油猴脚本编写_油猴脚本greay fork
- 6应届毕业生就业选择,考公还是进大厂?体制内就是最佳选择?_考公和去大厂
- 7matlab曲线拟合_matlab 拟合曲线方程
- 8油猴脚本开发,之如何添加html和css_油猴添加 css
- 9ATT&CK框架现有的14个战术进行了详细介绍_attck(三)之attck的十四个战术
- 10使用yolov5训练自己数据集并通过flask部署yolov5_yolov5 flask部署
【三维分割】SAGA:Segment Any 3D Gaussians_seg-any-gaussians代码运行
赞
踩
系列文章目录
代码:https://jumpat.github.io/SAGA.
论文:https://jumpat.github.io/SAGA/SAGA_paper.pdf
来源:上海交大和华为研究院
摘要
交互式三维分割技术在三维场景理解和操作中具有重要意义,是一项值得关注的任务。然而,现有的方法在实现细粒度、多粒度分割或争夺大量计算开销方面面临挑战,抑制了实时交互。在本文中,我们引入了分段任意三维gasssin(SAGA),一种新的三维交互分割方法,无缝地将二维分割模型与三维高斯Splatting(3DGS)相结合。SAGA通过设计良好的对比训练,有效地将分割模型生成的多粒度二维分割结果嵌入到三维高斯点特征中。实验评估展现了竞争力的性能。此外,SAGA可以在几毫秒内完成3D分割,还实现了多粒度分割,并适应各种提示,包括点、涂鸦和2D mask。
一、前言
三维交互式分割由于其在场景操作、自动标记和虚拟现实等领域的潜在应用,引起了研究者的广泛关注。以往的方法 [13,25,46,47 Decomposing nerf、 Neural feature fusion fields等] 主要是通过训练特征场,将二维视觉特征提升到三维空间中,以模拟由自监督视觉模型[4,39]提取的多视图二维特征。然后利用三维特征相似性来测量两个点是否属于同一对象。这种方法由于其简单的分割管道而快速,但代价是粗糙的分割粒度,因为缺乏解析嵌入在特征中的信息的机制(例如,分割解码器)。相比之下,另一种范式[5:Segment anything in 3d with nerfs] 通过将多视图细粒度的二维分割结果直接投影到三维掩模网格上,将二维分割基础模型提升到三维模型。虽然这种方法可以产生精确的分割结果,但由于需要多次执行基础模型和渲染,其大量的时间开销限制了交互性。
以上讨论揭示了现有范式在实现效率和准确性方面的困境,并指出了限制现有范式性能的两个因素。首先,以往方法采用的隐式辐射场[5,13]阻碍了有效分割:必须遍历三维空间才能检索一个三维对象。其次,二维分割解码器的利用,分割质量高,但效率低。
三维高斯Splatting(3DGS)具有高质量和实时渲染的能力:它采用一组三维彩色高斯分布来表示三维场景。这些高斯分布的平均值表示它们在三维空间中的位置,因此3DGS可以看作是一种点云,它有助于绕过巨大的、通常是空的三维空间的广泛处理,并提供了丰富的显式三维先验。有了这种点云状结构,3DGS不仅实现了高效渲染,而且成为分割任务的理想候选。
在3DGS的基础上,我们提出了Segment Any 3D GAussians (SAGA):将二维分割模型(即SAM)的细粒度分割能力提取为三维高斯模型,专注于将二维视觉特征提升到3D,并实现细粒度的3D分割。此外,它还避免了二维分割模型的多次推理。蒸馏使用SAM自动提取mask,训练高斯分布的三维特征来实现的。在推理过程中,使用输入提示生成一组查询,然后使用输入提示通过有效的特征匹配,检索期望的高斯。方法可以在毫秒内实现细粒度的3D分割,并支持各种提示,包括点、涂鸦和mask。
二、相关工作
1.基于提示的二维分割
受NLP任务和最近计算机视觉进展的启发,SAM能够返回给定指定图像中分割目标的输入提示的分割掩码。一个类似于SAM的模型是SEEM [55],也显示了令人印象深刻的开放词汇表分割能力。在他们之前,与提示二维分割最密切相关的任务是交互式图像分割,这已经被许多研究探索。
2.将2D视觉基础模型提升到3D
最近,二维视觉基础模型经历了强劲的增长。相比之下,三维视觉基础模型还没有看到类似的发展,这主要是由于数据的缺乏。获取和注释3D数据明显比其他2D数据更具挑战性。为了解决这个问题,研究人员试图将2D基础模型提升到3D [8,16,20,22,28,38,51,53]。一个值得注意的尝试是LERF [22],它训练了视觉-语言模型的一个特征场(即CLIP [39])和辐射场。这种范式有助于基于语言提示在辐射场中定位对象,但在精确的3D分割方面表现不佳,特别是当面对多个语义相似的对象时。其余的方法主要关注点云。通过利用摄像机姿态将三维点云与二维多视图图像关联起来,可以将二维基础模型提取的特征投影到三维点云上。这种集成类似于LERF,但与基于辐射场的方法相比,数据采集成本更高。
3.辐射场中的三维分割
受NeRF成功的启发,许多研究探索了其中的三维分割。Zhi等人[54]提出了SemanticNeRF,证明了NeRF在语义传播和细化方面的潜力。NVOS [40]引入了一种交互式的方法,通过训练一个轻量级的多层感知,使用定制设计的3D特征,从NeRF中选择三维对象(MLP)。通过使用2D自监督模型,如N3F [47],DFF [25],LERF [22]和ISRF [13],通过训练额外的特征场输出2D特征图,这些特征域可以模仿不同的2D特征图,将2D视觉特征提升到3D。NeRF-SOS [9]用对应蒸馏损失[17]将2D特征相似性提炼为3D特征。在这些基于二维视觉特征的方法中,可以通过比较嵌入在特征域中的三维特征来实现三维分割,这似乎是有效的。然而,由于仅依赖于欧几里得距离或余弦距离时,高维视觉特征中嵌入的信息无法得到充分利用,因此这类方法的分割质量受到了限制。还有一些其他的实例分割和语义分割方法[2,12,19,30,35,44,48,52]结合辐射场。
与我们的SAGA最密切相关的两种方法是ISRF [13]和SA3D [5]。前者遵循训练一个特征场来模拟多视图二维视觉特征的范式。因此,它很难区分具有相似语义的不同的对象(特别是对象的部分)。后者迭代查询SAM得到二维分割结果,并将其投影到mask网格上进行三维分割。其具有良好的分割质量,但分割管道复杂,导致时间消耗高,抑制了与用户的交互。
三、Methodology
1. 3D Gaussian Splatting (3DGS)
作为辐射场的最新发展进展,3DGS [21]使用可训练的三维高斯分布来表示三维场景,并提出了一种有效的可微栅格化渲染和训练算法。给定一个具有摄像机姿态的多视图二维图像的训练数据集I,3DGS学习一组三维彩色高斯 G = {g1,g2,…,gN },其中N表示场景中的三维高斯数。每个高斯分布的平均值表示其在三维空间中的位置,协方差表示尺度。因此,3DGS可以看作是一种点云。给定一个特定的相机姿态,3DGS将三维高斯投影到二维,然后通过混合一组重叠于像素的有序高斯N来计算一个像素的颜色C:
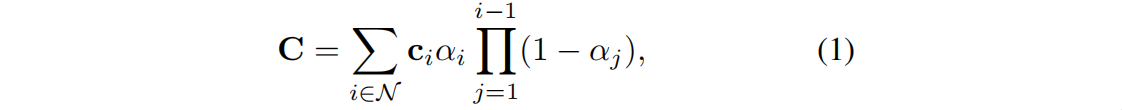
其中 ci 是每个高斯分布的颜色,α 是通过计算一个具有协方差Σ的二维高斯分布乘以一个学习到的每高斯不透明度得到。从公式(1)开始我们可以学习栅格化过程的线性性:像素渲染的颜色,是所涉及的高斯分布的加权和。这种特性确保了三维特征与二维渲染特性的对齐。
SAM 以一幅图像 I 和一组提示P作为输入,并输出相应的二维分割掩码M,即:
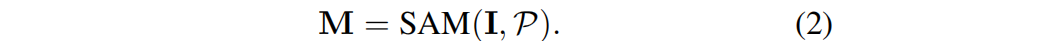
2. 整体框架
如图2所示,给定一个预先训练的3DGS模型G及其训练集,我们首先使用SAM的encoder,提取每个图像I∈RH×W的二维特征 :FISAM∈RCsam×H×W 和一组多粒度掩码 MISAM;然后根据提取的mask,训练每个高斯G的低维特征 fg∈RC,来聚合交叉视图一致的多粒度分割信息((C表示特征维度,大小默认为32)。为了进一步提高特征的紧致性,我们从提取的掩模中得到 point-wise的 correspondences,并将其提取为特征(即相关性损失)。
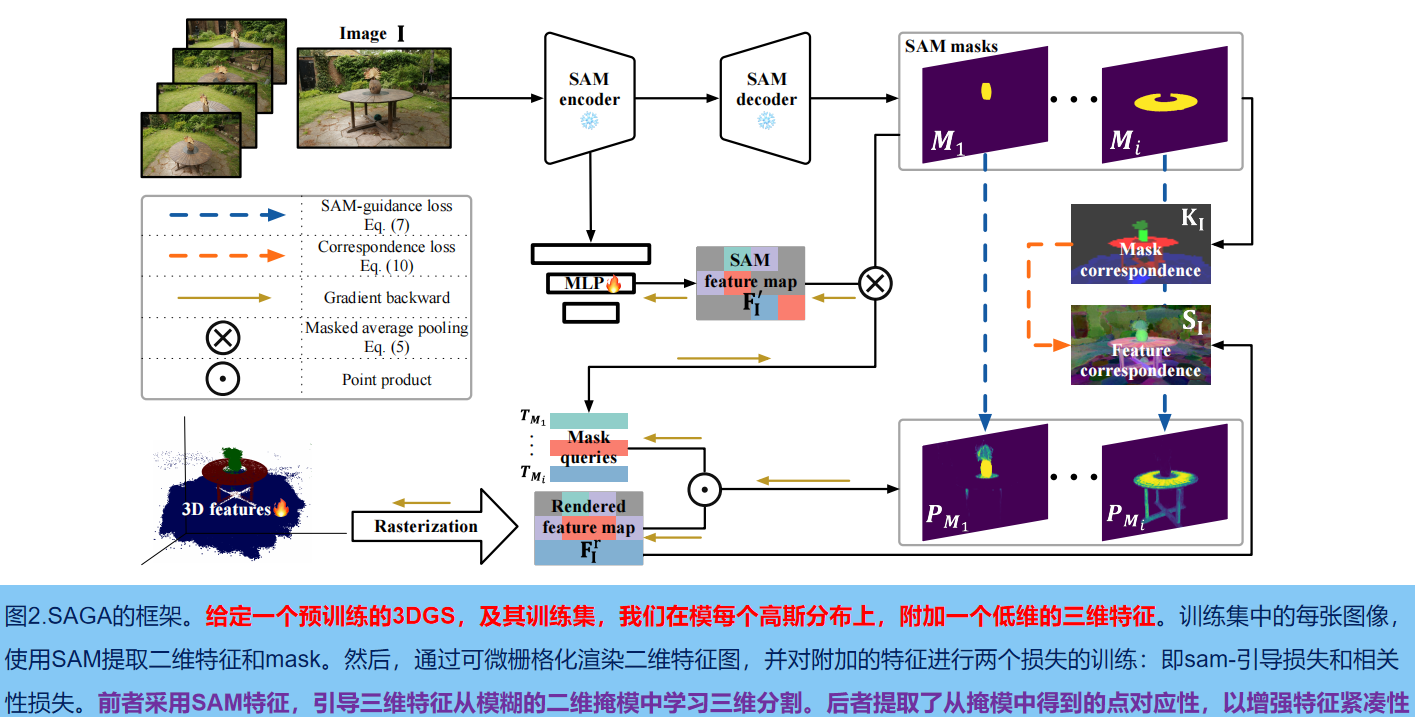
推理阶段,对于摄像机pose v2 的特定视图,根据输入提示p,生成一组查询Q, 然后利用这些查询,与学习到的特征进行有效的特征匹配,检索相应目标的三维高斯分布。此外,我们还引入了一种高效的后处理操作,利用3DGS的点云样结构提供的强三维先验来细化检索到的三维高斯分布。
3. 训练高斯特征
具有pose v的训练图像I,使用预训练的 3DGS模型 g 渲染相应的特征图 F:
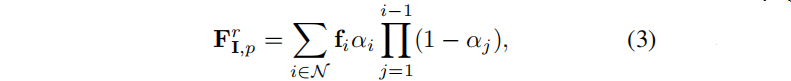
其中,N是有重叠的有序高斯分布集合。训练阶段,除了新附加的特征,冻结三维高斯G的所有其他属性(如均值、协方差和不透明度)。
3.1 SAM-guidance Loss
通过SAM自动提取的二维掩模MI是复杂和混乱的(即,三维空间中的一个点可以被分割为不同视图上的不同对象/部分)。这种模糊的监督信号对从头开始训练3D特征提出了巨大的挑战。为了解决这个问题 ,我们使用SAM生成的特性作为指导。如图2所示:用MLP φ ,将SAM特征投影到与三维特征相同的低维空间:
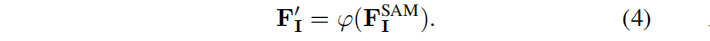
然后对于MISAM 中提取的每个掩码 M,经过平均池化操作,得到一个相应的查询TM∈RC:
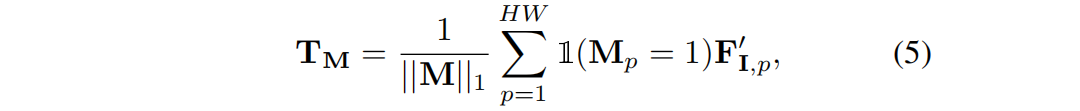
其中,'空心1’为 指示函数。然后使用TM 通过softmaxed 来分割渲染的特征图FIr:
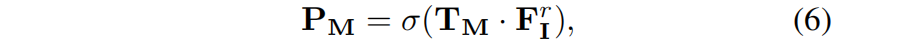
其中,σ表示元素级的sigmoid 函数。SAM-guidance损失定义为:分割结果 PM 与相应的SAM提取的掩模M之间的二值交叉熵:
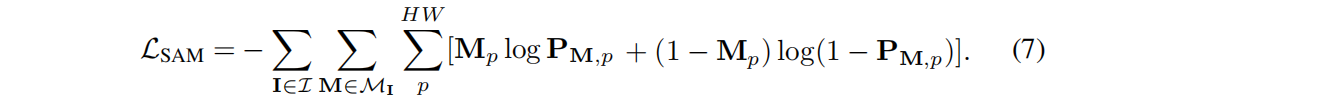
3.2 Correspondence Loss
在实践中,我们发现sam引导损失的学习特征不够紧凑,降低了基于不同提示的分割质量(参考Sec.4的消融研究)。受先前的对比对应蒸馏方法[9,17]的启发,我们引入了Correspondence 损失来解决这个问题。
如前所述,对于训练集I中每个高度为H、宽度为W的图像I,用SAM提取一组掩模MI 。考虑到I中的两个像素p1,p2,它们可能属于MI 中的许多mask。 设 MIp1 、MIp2 分别表示像素点p1、p2 所属的mask。如果其IoU较大,那么像素特征应该相似。因此,mask的相关系数 KI(p1、p2) :
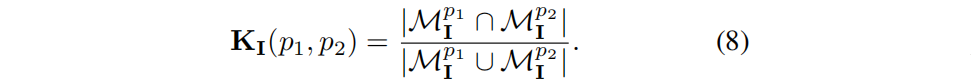
像素p1、p2 之间的特征相关性 SI(p1,p2) 被定义为它们渲染特征之间的余弦相似度:
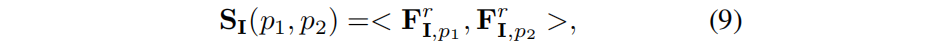
correspondence loss(如果两个像素从来不属于同一个部分, 通过将KI 中的0值设置为−1来降低特征相似性。):
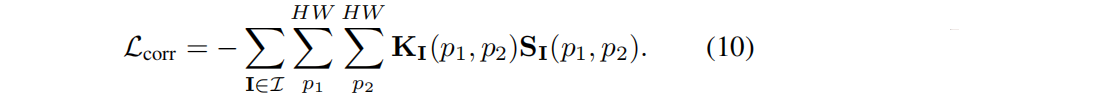
4. Inference
虽然训练是在渲染的特征图上进行的, 但光栅格化操作的线性度(公式3)确保了三维空间中的特征与图像平面上的渲染特征对齐。因此,可以用2D渲染特征,来实现三维高斯的分割。这一特点使SAGA具有与各种提示的兼容性。此外,我们还引入了一种有效的基于3DGS提供的3D先验后处理算法。
4.1 基于点的提示
对于特定视图v的渲染特征图 Fvr ,直接检索对应的特征,来生成对正负样本点的查询。设Qvp 和Qvn 分别表示Np 个正查询和负查询。 对于三维高斯g,其positive score Sgp 定义为其特征与正查询之间的最大余弦相似度,即 max{ < fg, Qp > |Qp∈Qvp}。同样,负分数Sgn 被定义为 max{ < fg, Qn > |Qn∈Qvn}。只有当 Sgp > Sgn 时,三维高斯才属于目标 Gt。为了进一步过滤掉噪声高斯分布,将自适应阈值τ设置为正分数,即g∈Gt 仅当Sgp > τ。τ被设为最大positive分数的平均值。请注意,这种过滤可能会导致许多FN样本(正样本未识别到),但可以通过4.5节中的后处理来解决。
4.2 基于Mask 和 Scribble(涂鸦)的提示
简单地将密集的提示,视为多个点将导致巨大的GPU内存开销。因此,我们使用K-means算法,从密集的提示中提取正负查询:Qvp 和Qvn。根据经验,Kmeans的集群数量为5(可以根据目标对象的复杂性进行调整)。
4.3 基于SAM 的提示
前面的提示将从渲染的特征映射中获得。由于SAM-guidance loss,我们可以直接使用低维SAM特征 F’v 来生成查询:首先将prompt 输入SAM,生成准确的二维分割结果 Mvref。利用这个二维掩码,我们首先获得一个具有掩码平均池的查询Qmask,并利用该查询对二维渲染的特征映射Fvr 进行分割,得到一个临时的二维分割掩模 Mvtemp,然后与 Mvref 进行比较。如果两者的交集占据了Mvref的大部分(默认90%),则接受Qvmask 作为查询。否则,我们使用K-means算法从掩码内的低维SAM特征F’v 中提取另一组查询 Qvkmeans 。采用这种策略是因为分割目标可能包含许多组件,而这些组件不能通过简单地应用掩蔽平均池来捕获。
在获得查询集QvSAM = {Qvmask } 或 QvSAM =Qvkmeans 之后,后续过程与之前提示符的方法相同。我们使用点积而不是余弦相似度作为分割的度量,以适应sam引导损失。对于三维高斯g,其positive score Sgp 为通过以下查询计算的最大点积:
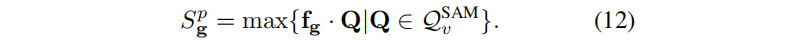
如果positive score 大于另一个自适应阈值τSAM,则三维高斯g属于分割目标Gt,这是所有分数的平均值和标准差的和。
5. 基于三维先验的后处理
3D高斯的初始分割 Gt 存在两个主要问题: (i)存在多余的噪声高斯问题,(ii)目标的遗漏。为了解决这个问题,我们使用了传统的点云分割技术,包括统计滤波和区域增长。对于基于点和涂鸦提示的分割,采用统计滤波过滤噪声高斯分布。对于掩码提示和基于sam的提示,将二维掩码投影到 Gt上,得到一组经过验证的高斯函数,并投影到G上,排除不需要的高斯函数。所得到的有效高斯函数可以作为区域增长算法的种子。最后,采用基于球查询的区域增长方法从原始模型G中检索目标所需的所有高斯函数。
4.1 Statistical Filtering 统计过滤
两个高斯分布之间的距离可以表示它们是否属于同一目标。统计滤波首先使用|-最近邻(KNN)算法来计算分割结果Gt中每个高斯分布的最近 G t \sqrt{Gt} Gt 高斯分布的平均距离。随后,我们计算了Gt 中所有高斯分布的这些平均距离的 平均值(µ)和标准差(σ)。然后我们去除平均距离超过µ+σ的高斯分布,得到Gt’。
4.2 基于区域增长的过滤
来自掩码提示或基于sam的提示的2D掩码可以作为准确定位目标的先验:首先,将mask投影到粗的高斯结果 Gt 上,得到一个高斯子集,记为Gc。随后,对于Gc 内的每个高斯g,计算子集中最近的邻居的欧氏距离 dg:
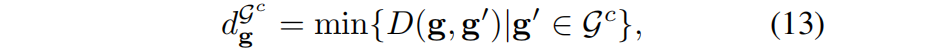
式中,D()表示欧式距离。然后,迭代地在粗的高斯结果 Gt 中加入相邻的高斯(距离小于集合Gc 中观的最大最近邻距离)。该距离形式化为 :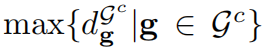
请注意,尽管点提示和涂鸦提示也可以粗略地定位目标,但基于它们增长的区域是耗时的。因此,我们只在有mask时使用。
4.3 基于Ball Query的增长
过滤后的分割输出G’t ,可能缺少目标的所有高斯。为了解决这个问题,我们使用球查询算法从所有高斯G中检索所有所需的高斯。具体地说,这是通过检查半径为r的球形邻域来实现的。位于G中这些球形边界内的高斯分布随后被聚合成最终的分割结果 Gs。半径r设为G’t 中的最大的最近邻距离:

四、实验
1.数据集
定量实验,使用 Neural Volumetric Object Selection(NVOS),SPIn-NeRF [33]数据集。NVOS 数据集基于LLFF数据集,其中包括几个前向的场景。对于每个场景,NVOS数据集提供了一个带有涂鸦的参考视图和一个带有2D分割掩码注释的目标视图。类似地,SPIn-NeRF [33]数据集也基于广泛使用的NeRF数据集[11,24,26,31,32]手动注释了一些数据。此外,我们还使用SA3D对LERF-小雕像场景中的一些对象进行了标注,以证明SAGA在效率和分割质量方面的更好的权衡。
定性分析,使用了LLFF 、MIP-360、T&T数据集和LERF数据集。
2.定量实验
NVOS:遵循SA3D [5]来处理NVOS数据集提供的涂鸦,以满足SAM的要求。如表1所示,SAGA与之前的SOTA SA3D相同,并且明显优于之前的基于特征模仿的方法(ISRF和SGISRF),这证明了其细粒度的分割能力。
SPIn-NeRF:遵循SPIn-NeRF进行评估,它指定了一个具有二维地面真值mask的视图,并将该掩模传播到其他视图,以检查掩模的准确性。此操作可以看作是一种掩码提示。结果如表2所示。MVSeg采用视频分割方法[4]对多视图图像进行分割,SA3D自动查询训练视图上渲染图像的二维分割基础模型。这两者都需要多次提出一个二维分割模型。值得注意的是,SAGA在近千分之一的时间内表现出与它们相当的性能。请注意,轻微的退化是由3DGS学习到的次优几何形状引起的。
与SA3D的比较。基于LERF-futtes场景运行SA3D,为许多对象获得一组注释。随后,我们使用SAGA来分割相同的对象,并检查每个对象的IoU和时间成本。结果如表3所示,我们还提供了与SA3D进行比较的可视化结果。值得注意的是,受SA3D巨大的GPU内存成本的限制,SAGA的训练分辨率要高得多。这表明SAGA可以在更短的时间内获得更高质量的3D资产。即使考虑到训练时间(每个场景约10分钟),SAGA中每个对象的平均分割时间也远小于SA3D。

3.定性实验

4. 失败案例
表2中,与之前的方法相比,SAGA表现出次优性能。这是因为LLFF-room场景的分割失败,揭示了SAGA的局限性。我们在图4中显示了彩色高斯函数的平均值,这可以看作是一种点云。SAGA容易受到3DGS模型的几何重建不足的影响。如红框所示,表的高斯数明显稀疏,其中代表表表面的高斯数漂浮在实际表面下面。更糟糕的是,椅子上的高斯人和桌子上的人很接近。这些问题不仅阻碍了鉴别性三维特征的学习,而且影响了后处理的有效性。我们认为,提高3DGS模型的几何保真度可以改善这一问题。

d
\sqrt{d}
d
1
0.24
\frac {1}{0.24}
0.241
x
ˉ
\bar{x}
xˉ
x
^
\hat{x}
x^
x
~
\tilde{x}
x~
ϵ
\epsilon
ϵ
- 1
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。

