
热门标签
热门文章
- 1详细讲解:C语言删除数组中的某一值的所有元素_c语言在一个数组中删除一个制定的数
- 25.8 最小均方误差(维纳)滤波_均方差滤波算法
- 3Notepad++快捷键及使用技巧_c:\windows\notepad.exe,快捷键为
+ + 。 - 4[Swift]LeetCode336. 回文对 | Palindrome Pairs
- 5五种方式:普通人如何通过利用AI绘画实现副业变现?居然这么简单,有手就行(内附详细操作流程)_学ai副业怎么变现
- 6【uniapp】自定义底部tabbar,根据权限显示不同名称或者不同个数的tabbar及部分出现的问题 (cv可用)_uniapptabbar自定义问题
- 7mysql 锁 会话_MySql锁的深入理解
- 8vue3 Element-plus 的配置(按需引入,完整引入)_element-plus 组件引入方式
- 9关于Unity Physics.CheckBox的使用方法_unity physic.checkbox
- 10el-table表格下方多一条线的问题_el-table下边框线不全
当前位置: article > 正文
ChatGPT与GPT3详细架构研究,语言模型背后的详细直觉和方法_gpt架构
作者:凡人多烦事01 | 2024-02-17 21:56:18
赞
踩
gpt架构
Transformers正在席卷 NLP 世界,因为它是理解上下文的强大引擎。这些令人难以置信的模型正在打破多项 NLP 记录并推动最先进的技术发展。它们被用于许多应用程序,如机器语言翻译、NER、摘要、会话聊天机器人,甚至用于支持更好的搜索引擎。在我最近关于 Transformers 的帖子- Attention is all you need中,我们介绍了有关 Transformers 的详细直觉和方法。在这篇文章中,我们将重点介绍GPT 3架构和最新聊天 GPT LM 架构的直觉和方法。
GPT 3 语言模型
GPT-3 (Generative Pre-trained Transformer 3) 是一种由 OpenAI 创建的语言模型。1750 亿参数的深度学习模型能够生成类似人类的文本,并在具有数千亿字的大型文本数据集上进行训练。
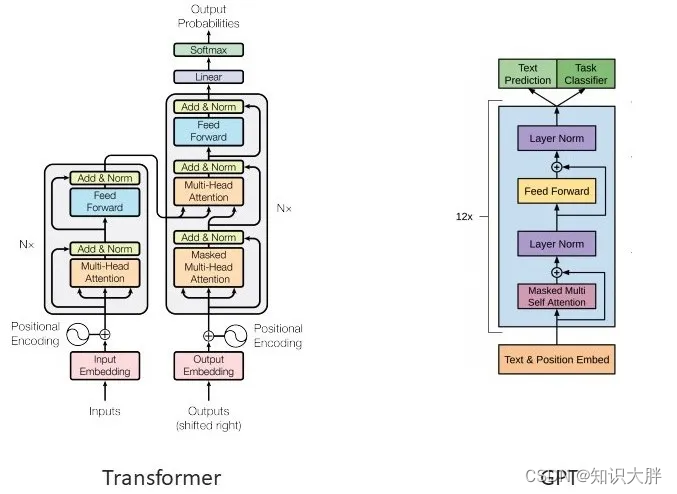
GPT 使用未修改的 Transformer 解码器,只是它缺少编码器注意力部分。我们可以在上图中直观地看到这一点。GPT、GPT2、GPT 3 是使用 transformer 解码器块构建的。另一方面,BERT 使用变压器编码器块。GPT-3 使用庞大的互联网文本数据集进行训练——总共 570GB。发布时是最大的神经网络,有 1750 亿个参数(100x GPT-2)。GPT-3 有 96 个注意力块,每个注意力块包含 96 个注意力头
GPT3 的实际工作原理——预训练
GPT-3 使用与
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/101619
推荐阅读
相关标签

