
- 1【Unity入门】声音组件AudioSource简介 及实现声音的近大远小_audioclip 音量大小
- 2通过命令查看linux 密码,linux查看用户密码(linux查看用户密码命令)
- 3vsCode配置用户代码片段(react)_vscode react代码片段
- 4ESP32 web 对接华为云平台--MQTT协议
- 5基于python的旅游推荐系统_基于python开发一个旅游推荐系统
- 6Python爬虫http基本原理#2
- 7【python】代码实现计算天数倒计时_python倒数日
- 802-认识python爬虫_网络爬虫属于大数据的什么阶段
- 9TCP/UDP端口连接测试_udp端口测试命令
- 10云服务器4核8G够用吗?云服务器4核8G12M能干什么?_云服务器4核8g大概什么价格
MachineLearning 1. 主成分分析(PCA)_proportion var
赞
踩

关注公众号,桓峰基因
桓峰基因
生物信息分析,SCI文章撰写及生物信息基础知识学习:R语言学习,perl基础编程,linux系统命令,Python遇见更好的你
67篇原创内容
公众号
前言
生信分析就是数据挖掘,其过程中经常会遇到的情况是有很多特征可以用,这是一件好事,但是有的时候数据中存在很多冗余情况,也就是说数据存在相关性或者共线性。在这种情况下对于分析带来了很多麻烦。不必要的特征太多会造成模型的过于复杂,共线性相关性会造成模型的不稳定,即数据微小的变化会造成模型结果很大的变化。主成分分析是解决这种问题的一个工具。
原理
主成分分析法的定义
主成分分析(Principal Component Analysis,PCA)是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
在实际课题中,为了全面分析问题,往往提出很多与此有关的变量(或因素),因为每个变量都在不同程度上反映这个课题的某些信息。主成分分析首先是由K.皮尔森(Karl Pearson)对非随机变量引入的,尔后H.霍特林将此方法推广到随机向量的情形。信息的大小通常用离差平方和或方差来衡量。
主成分分析法的基本原理
主成分分析法是一种降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的p 个正交方向,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。主成分分析的原理是设法将原来变量重新组合成一组新的相互无关的几个综合变量,同时根据实际需要从中可以取出几个较少的总和变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上处理降维的一种方法。主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标。最经典的做法就是用F1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即Va(rF1)越大,表示F1包含的信息越多。因此在所有的线性组合中选取的F1应该是方差最大的,故称F1为第一主成分。如果第一主成分不足以代表原来P个指标的信息,再考虑选取F2即选第二个线性组合,为了有效地反映原来信息,F1已有的信息就不需要再出现在F2中,用数学语言表达就是要求Cov(F1,F2)=0,则称F2为第二主成分,依此类推可以构造出第三、第四,……,第P个主成分。
主成分分析主要作用
1.主成分分析能降低所研究的数据空间的维数。即用研究m维的Y空间代替p维的X空间(m<p),而低维的Y空间代替高维的x空间所损失的信息很少。即:使只有一个主成分Yl(即 m=1)时,这个Yl仍是使用全部X变量(p个)得到的。例如要计算Yl的均值也得使用全部x的均值。在所选的前m个主成分中,如果某个Xi的系数全部近似于零的话,就可以把这个Xi删除,这也是一种删除多余变量的方法。
2.有时可通过因子负荷aij的结论,弄清X变量间的某些关系。
3.多维数据的一种图形表示方法。我们知道当维数大于3时便不能画出几何图形,多元统计研究的问题大都多于3个变量。要把研究的问题用图形表示出来是不可能的。然而,经过主成分分析后,我们可以选取前两个主成分或其中某两个主成分,根据主成分的得分,画出n个样品在二维平面上的分布况,由图形可直观地看出各样品在主分量中的地位,进而还可以对样本进行分类处理,可以由图形发现远离大多数样本点的离群点。
4.由主成分分析法构造回归模型。即把各主成分作为新自变量代替原来自变量x做回归分析。
5.用主成分分析筛选回归变量。回归变量的选择有着重的实际意义,为了使模型本身易于做结构分析、控制和预报,好从原始变量所构成的子集合中选择最佳变量,构成最佳变量集合。用主成分分析筛选变量,可以用较少的计算量来选择量,获得选择最佳变量子集合的效果。
进行主成分分析主要步骤
-
指标数据标准化;
-
指标之间的相关性判定;
-
确定主成分个数m;
-
主成分Fi表达式;
-
主成分Fi命名。

实例解析
这里主要讲一下psych软件包中的函数使用,以及在分析时的一般过程,如下:
- 数据预处理。PCA和EFA都根据观测变量间的相关性来推导结果。用户可以输入原始数据矩阵或者相关系数矩阵到principal()和fa()函数中。若输入初始数据,相关系数矩阵将会被自动计算,在计算前请确保数据中没有缺失值;
2.选择因子模型。判断是PCA(数据降维)还是EFA(发现潜在结构)更符合你的研究目标。如果选择EFA方法,你还需要选择一种估计因子模型的方法(如最大似然估计);
3.判断要选择的主成分/因子数目;
4.选择主成分/因子;
-
旋转主成分/因子;
-
解释结果;
7.计算主成分或因子得分。
1. 软件安装
主要使用psych中的函数,安装并加载该软件包,如下:
if (!require(psych)) {
install.packages("psych")
}
## Warning: 程辑包'psych'是用R版本4.1.3 来建造的
if (!require(car)) {
install.packages("car")
}
if (!require(ElemStatLearn)) {
install.packages("ElemStatLearn")
}
library(psych)
library(ElemStatLearn)
library(car)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2. 数据读取
然这个数据集比较小,只有97个观测共9个变量,但通过与传统技术比较,足以让我们掌握正则化技术。斯坦福大学医疗中心提供了97个病人的前列腺特异性抗原(PSA)数据,这些病人均接受前列腺根治切除术。我们的目标是,通过临床检测提供的数据建立一个预测模型预测患者术后PSA水平。对于患者在手术后能够恢复到什么程度, PSA水平可能是一个较为有效的预后指标。手术之后,医生会在各个时间区间检查患者的PSA水平,并通过各种公式确定患者是否康复。术前预测模型和术后数据(这里没有提供)互相配合,就可能提高前列腺癌诊疗水平,改善其预后。如下所示:
lcavol:肿瘤体积的对数值;
lweight:前列腺重量的对数值;
age:患者年龄(以年计);
bph:良性前列腺增生(BPH)量的对数值,非癌症性质的前列腺增生;
svi:精囊是否受侵,一个指标变量,表示癌细胞是否已经透过前列腺壁侵入精囊腺(1—是, 0—否);
lcp:包膜穿透度的对数值,表示癌细胞扩散到前列腺包膜之外的程度;
leason:患者的Gleason评分;由病理学家进行活体检查后给出(2—10) ,表示癌细胞的变异程度—评分越高,程度越危险;
pgg45:Gleason评分为4或5所占的百分比;
lpsa:PSA值的对数值,响应变量;
rain:一个逻辑向量(TRUE或FALSE,用来区分训练数据和测试数据)。
data(prostate)
str(prostate)
## 'data.frame': 97 obs. of 10 variables:
## $ lcavol : num -0.58 -0.994 -0.511 -1.204 0.751 ...
## $ lweight: num 2.77 3.32 2.69 3.28 3.43 ...
## $ age : int 50 58 74 58 62 50 64 58 47 63 ...
## $ lbph : num -1.39 -1.39 -1.39 -1.39 -1.39 ...
## $ svi : int 0 0 0 0 0 0 0 0 0 0 ...
## $ lcp : num -1.39 -1.39 -1.39 -1.39 -1.39 ...
## $ gleason: int 6 6 7 6 6 6 6 6 6 6 ...
## $ pgg45 : int 0 0 20 0 0 0 0 0 0 0 ...
## $ lpsa : num -0.431 -0.163 -0.163 -0.163 0.372 ...
## $ train : logi TRUE TRUE TRUE TRUE TRUE TRUE ...
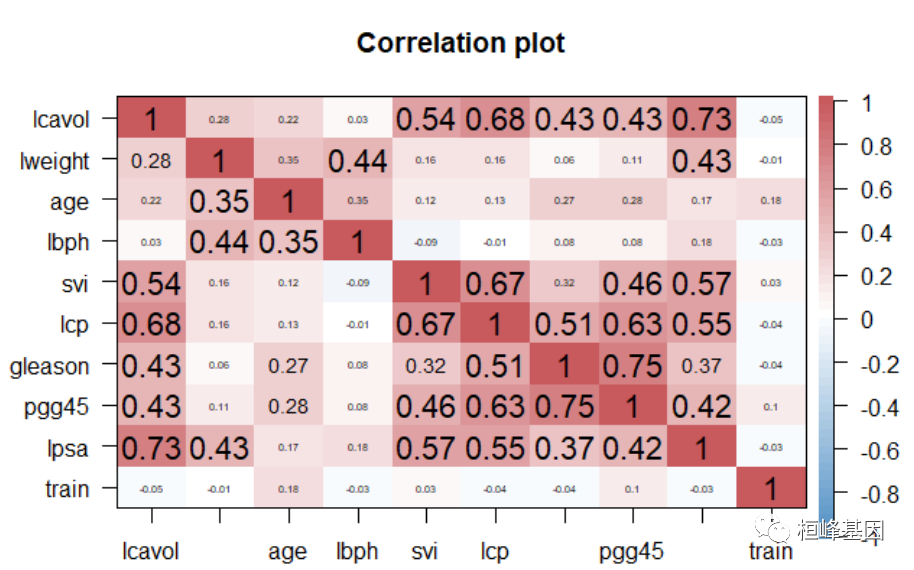
corPlot(prostate, gr = colorRampPalette(c("#2171B5", "white", "#B52127")))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3. 构建Logisitc回归模型
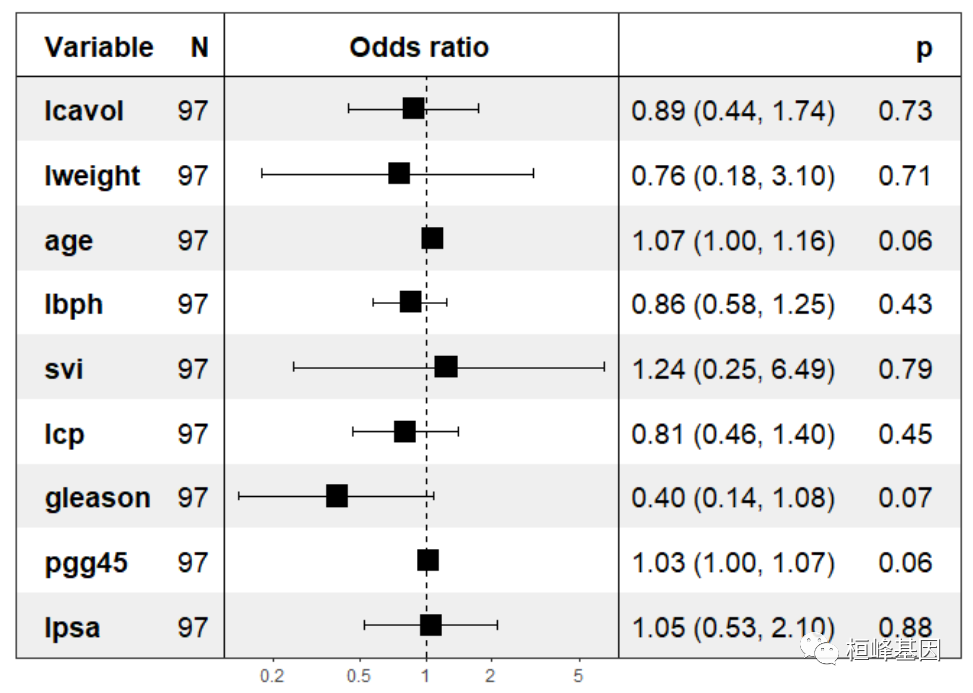
首先我们先利用所有的变量构建Logisitc回归模型,train为因变量,其他为自变量,构建模型。计算线性、广义线性和其他回归模型的方差膨胀和广义方差膨胀因子(vif和gvif),我们看下自变量之间的线性关系,发现线性均大于2,说明变量之间的关系非常紧密,如下
fit <- glm(train ~ ., family = binomial(link = "logit"), data = prostate) summary(fit) ## ## Call: ## glm(formula = train ~ ., family = binomial(link = "logit"), data = prostate) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -1.9957 -1.1059 0.6743 0.8467 1.4434 ## ## Coefficients: ## Estimate Std. Error z value Pr(>|z|) ## (Intercept) 2.86104 4.29240 0.667 0.5051 ## lcavol -0.11984 0.34452 -0.348 0.7280 ## lweight -0.27024 0.71907 -0.376 0.7071 ## age 0.07015 0.03662 1.915 0.0554 . ## lbph -0.15435 0.19585 -0.788 0.4306 ## svi 0.21798 0.82065 0.266 0.7905 ## lcp -0.21210 0.27918 -0.760 0.4474 ## gleason -0.92305 0.51668 -1.787 0.0740 . ## pgg45 0.02997 0.01567 1.913 0.0558 . ## lpsa 0.05286 0.34889 0.152 0.8796 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## (Dispersion parameter for binomial family taken to be 1) ## ## Null deviance: 119.99 on 96 degrees of freedom ## Residual deviance: 110.07 on 87 degrees of freedom ## AIC: 130.07 ## ## Number of Fisher Scoring iterations: 4 vif(fit) ## lcavol lweight age lbph svi lcp gleason pgg45 ## 3.043623 1.716716 1.456603 1.512082 2.003681 2.833653 2.710155 3.151257 ## lpsa ## 2.876862 forestmodel::forest_model(fit)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
4. PCA分析
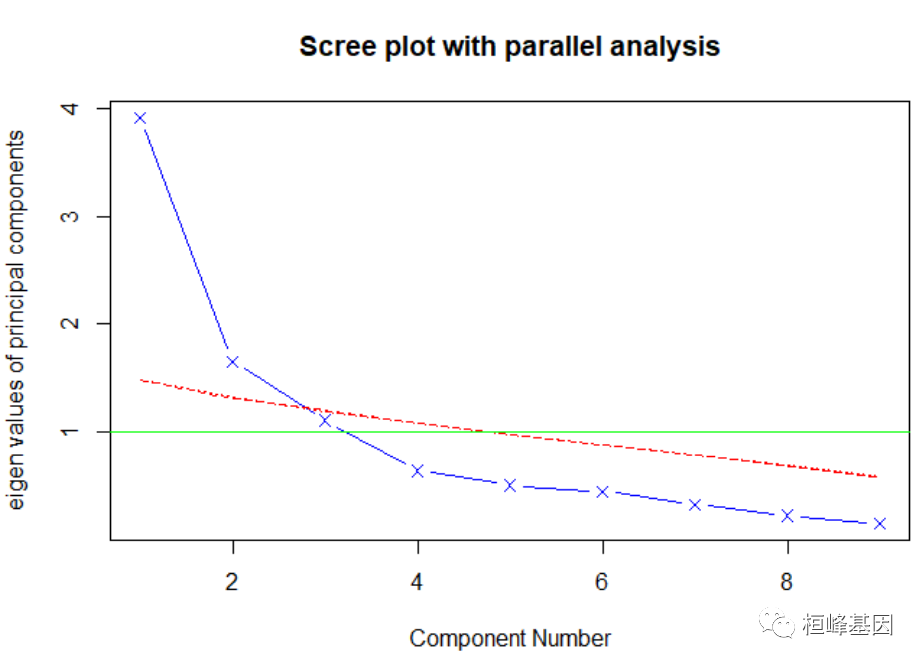
我们发现结果并不显著,那么我们需要对变量进行降维,也就是挑选对因变量起到更重要的变量,于是我们通过PCA分析来获得主成分,通过迭代的方式获得碎石图,首先判断主成分的数目,这里使用Cattell碎石检验,表示了特征值与主成数目的关系。一般的原则是:要保留的主成分的个数的特征值要大于1且大于平行分析的特征值,我们看到大于1的为3个特征,如下:
fa.parallel(prostate[, -10], fa = "pc", n.iter = 100, show.legend = FALSE, main = "Scree plot with parallel analysis") #判断主成分个数
## Parallel analysis suggests that the number of factors = NA and the number of components = 2
abline(h = 1, lwd = 1, col = "green")
- 1
- 2
- 3
- 4
principal()函数可以根据原始数据矩阵或者相关系数矩阵做主成分分析,其中:
1.r是相关系数矩阵或原始数据矩阵;
2.nfactors设定主成分数(默认为1);
3.rotate指定旋转的方法(默认最大方差旋转(varimax);
4.scores设定是否需要计算主成分得分(默认不需要)
获取前列腺癌的变量的主成分,从结果上可以看出RC1主要成分为lpsa,RC2主要成分为lbph,RC3主成分为gleason,如下:
pc <- principal(prostate[, -10], nfactors = 3, rotate = "none") pc ## Principal Components Analysis ## Call: principal(r = prostate[, -10], nfactors = 3, rotate = "none") ## Standardized loadings (pattern matrix) based upon correlation matrix ## PC1 PC2 PC3 h2 u2 com ## lcavol 0.81 -0.08 -0.28 0.75 0.25 1.3 ## lweight 0.40 0.70 -0.33 0.75 0.25 2.1 ## age 0.38 0.57 0.37 0.60 0.40 2.5 ## lbph 0.18 0.80 0.12 0.68 0.32 1.1 ## svi 0.73 -0.28 -0.28 0.68 0.32 1.6 ## lcp 0.83 -0.27 -0.06 0.77 0.23 1.2 ## gleason 0.69 -0.14 0.56 0.82 0.18 2.0 ## pgg45 0.77 -0.16 0.47 0.83 0.17 1.8 ## lpsa 0.79 0.09 -0.39 0.79 0.21 1.5 ## ## PC1 PC2 PC3 ## SS loadings 3.91 1.66 1.11 ## Proportion Var 0.43 0.18 0.12 ## Cumulative Var 0.43 0.62 0.74 ## Proportion Explained 0.59 0.25 0.17 ## Cumulative Proportion 0.59 0.83 1.00 ## ## Mean item complexity = 1.7 ## Test of the hypothesis that 3 components are sufficient. ## ## The root mean square of the residuals (RMSR) is 0.08 ## with the empirical chi square 40.91 with prob < 5.1e-05 ## ## Fit based upon off diagonal values = 0.96
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
由输出结果可知,第一主成分在5个观测变量上的载荷均较大,第二主成分lweight,lbph,这量个变量上载荷较大,第三个主成分影响都不大,载荷相对较小,但相差不大。两主成分解释了该数据的73%,但该结果并不便于解释三个主成分。因此,考虑进行主成分旋转。
rc <- principal(prostate[, -10], nfactors = 3, rotate = "varimax", score = TRUE) rc ## Principal Components Analysis ## Call: principal(r = prostate[, -10], nfactors = 3, rotate = "varimax", ## scores = TRUE) ## Standardized loadings (pattern matrix) based upon correlation matrix ## RC1 RC3 RC2 h2 u2 com ## lcavol 0.82 0.23 0.12 0.75 0.25 1.2 ## lweight 0.38 -0.18 0.76 0.75 0.25 1.6 ## age -0.01 0.40 0.67 0.60 0.40 1.6 ## lbph -0.07 0.04 0.82 0.68 0.32 1.0 ## svi 0.79 0.23 -0.10 0.68 0.32 1.2 ## lcp 0.75 0.46 -0.05 0.77 0.23 1.7 ## gleason 0.25 0.87 0.07 0.82 0.18 1.2 ## pgg45 0.36 0.83 0.07 0.83 0.17 1.4 ## lpsa 0.84 0.10 0.27 0.79 0.21 1.2 ## ## RC1 RC3 RC2 ## SS loadings 2.91 1.97 1.80 ## Proportion Var 0.32 0.22 0.20 ## Cumulative Var 0.32 0.54 0.74 ## Proportion Explained 0.44 0.30 0.27 ## Cumulative Proportion 0.44 0.73 1.00 ## ## Mean item complexity = 1.4 ## Test of the hypothesis that 3 components are sufficient. ## ## The root mean square of the residuals (RMSR) is 0.08 ## with the empirical chi square 40.91 with prob < 5.1e-05 ## ## Fit based upon off diagonal values = 0.96
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
模型构建
主成分分析完成,我们改用三个主成分的结果构造Logistic回归模型,再次看下膨胀因子都已经在1这个水平上了,但是构建的模型并不是很适合,比较之前的LASSO回归,这种情况选择后者更好些,如下:
newdata <- data.frame(prostate, rc$scores) head(newdata) ## lcavol lweight age lbph svi lcp gleason pgg45 lpsa ## 1 -0.5798185 2.769459 50 -1.386294 0 -1.386294 6 0 -0.4307829 ## 2 -0.9942523 3.319626 58 -1.386294 0 -1.386294 6 0 -0.1625189 ## 3 -0.5108256 2.691243 74 -1.386294 0 -1.386294 7 20 -0.1625189 ## 4 -1.2039728 3.282789 58 -1.386294 0 -1.386294 6 0 -0.1625189 ## 5 0.7514161 3.432373 62 -1.386294 0 -1.386294 6 0 0.3715636 ## 6 -1.0498221 3.228826 50 -1.386294 0 -1.386294 6 0 0.7654678 ## train RC1 RC3 RC2 ## 1 TRUE -1.4885513 -0.3812754 -2.0498849 ## 2 TRUE -1.4810035 -0.4569587 -1.0922377 ## 3 TRUE -2.2297727 1.5210898 -0.9234636 ## 4 TRUE -1.5529117 -0.4196166 -1.1270163 ## 5 TRUE -0.8927156 -0.5944523 -0.7497934 ## 6 TRUE -1.0589794 -0.8250678 -1.5131640 fitness <- glm(train ~ RC1 + RC2 + RC3, family = binomial(link = "logit"), data = newdata) summary(fitness) ## ## Call: ## glm(formula = train ~ RC1 + RC2 + RC3, family = binomial(link = "logit"), ## data = newdata) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -1.7195 -1.4258 0.8082 0.8841 1.1148 ## ## Coefficients: ## Estimate Std. Error z value Pr(>|z|) ## (Intercept) 0.81359 0.22177 3.669 0.000244 *** ## RC1 -0.12319 0.21787 -0.565 0.571772 ## RC2 0.09409 0.22203 0.424 0.671714 ## RC3 0.17378 0.23189 0.749 0.453616 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## (Dispersion parameter for binomial family taken to be 1) ## ## Null deviance: 119.99 on 96 degrees of freedom ## Residual deviance: 118.90 on 93 degrees of freedom ## AIC: 126.9 ## ## Number of Fisher Scoring iterations: 4 vif(fitness) ## RC1 RC2 RC3 ## 1.000359 1.000444 1.000274
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
结果解读
输出结果中,第一部分中PC1,PC2和PC3为两个主成分在各观测变量上的载荷,即观测变量与主成分的相关系数:
1.h2是主成分公因子方差,即主成分对每个变量的方差解释度;
2.u2是成分唯一性,即方差无法被主成分解释的比例,u2+h2=1。
第二部分是对于两个主成分的说明:
1.SS loadings 是两主成分的特征值;
2.Proportion Var 是方差比例,即各主成分对数据的解释程度;
3.Cumulative Var 是累计方差比例。
References:
-
Revelle, W. (in preparation) An Introduction to Psychometric Theory with applications in R. Springer.
-
Revelle, W. and Condon, D.M. (2019) Reliability from alpha to omega: A tutorial. Psychological Assessment, 31, 12, 1395-1411.

