
- 1iOS代码质量要求_图片压缩(iOS)
- 2可解释性AI:打开人工智能决策的黑盒子
- 3从软件哲学角度谈 Amazon SageMaker(第一讲)
- 4学习之路指南:GitHub 教程与指南精选手册一
- 5幻兽帕鲁更新教程_幻兽帕鲁linux服务器更新
- 6大型语言模型 (LLM)全解读_llm大型语言模型
- 7pythonnext方法_【Python魔术方法】迭代器(__iter__和__next__)
- 8anaconda、pip及jupyter常见使用_error displaying widget: model not found
- 9基于Python爬虫淘宝水果销售数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 10wps中xlsx格式自动变为xlsm且打开空白_xlsm文件打开空白
《万字长文带你解读AIGC》系列之入门篇_aigc工作流程 csdn
赞
踩
0. 导读
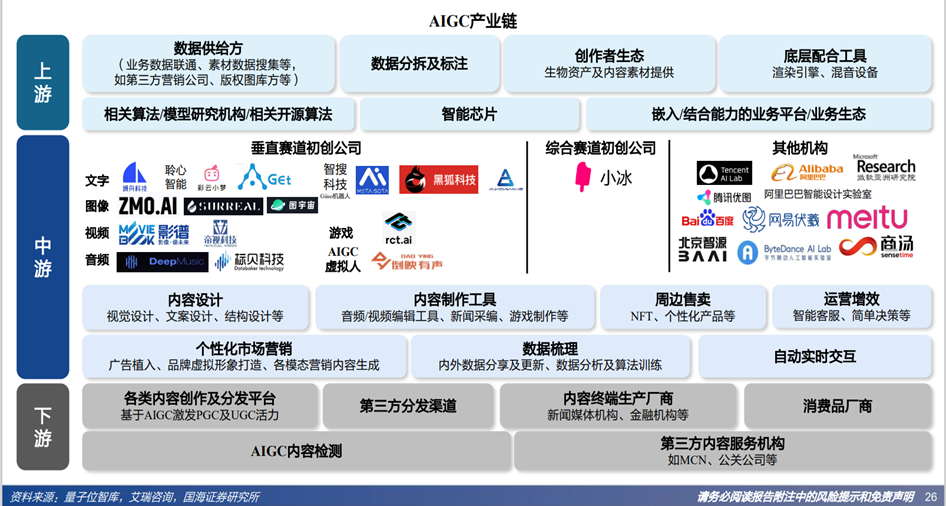
随着ChatGPT的病毒式传播,生成式人工智能(AIGC, a.k.a AI-generated content)因其分析和创造文本、图像、视频以及其他方面的出众能力而俨然成为当下最火热的投资赛道,没有之一。在如此铺天盖地的信息轰炸下,每个人似乎难以置身事外,我们几乎不可能错过从某个角度瞥见AIGC的机会。
值得注意的是,在人工智能从纯分析过渡到创造的时代,ChatGPT及其最新的语言模型GPT-4,只是众多AIGC任务中的一个工具而已。在对ChatGPT的能力印象深刻的同时,很多人都在想它的局限性:GPT-5或其他未来的GPT变体能否帮助ChatGPT统一所有的AIGC任务,实现多样化的内容创作?为了回答这个问题,需要对现有的AIGC任务进行全面审查。
因此,本文将通过提供对AIGC从技术到应用的初步了解,来及时填补这一空白。现代生成式AI极度依赖于各种技术基础,从模型架构和自监督预训练到生成式建模方法(如GAN和Diffusion)。在介绍了基本技术之后,这项工作主要是根据各种AIGC任务的输出类型(包括文本、图像、视频、3D内容等)来研究其技术发展,这描绘了ChatGPT的全部未来潜力。此外,我们总结了它们在一些主流行业的重要应用,如教育和创意内容。最后,我们将集中讨论目前面临的挑战,并对生成式AI在不久的将来可能的发展进行了相关的展望。
1. 引言
这段时间,以ChatGPT和Midjourney为代表的 AIGC 工具迅速占领头条,充分表明人工智能的新时代即将到来。在这种铺天盖地的媒体报道下,哪怕是个普通人都有很多机会可以一睹AIGC的风采。然而,这些报道中的内容往往是偏颇的,有时甚至是误导的。此外,在对ChatGPT的强大能力印象深刻的同时,许多人也在想象它的极限。
就在近期,OpenAI发布了GPT-4,与之前的变体GPT-3.5相比,它展示了显著的性能改进以及多模态生成能力,如图像理解。被AIGC驱动的GPT-4的强大能力所打动,许多人想知道它的极限,即GPT-X是否能帮助下一代ChatGPT统一所有AIGC任务?
传统人工智能的目标主要是进行分类或回归(Classification or Regression)。此类模型可归纳为判别式AI,因此传统人工智能也经常被称为分析性人工智能。相比之下,生成式AI通过创造新的内容来进行区分。然而,这种技术往往也要求模型在生成新内容之前首先理解一些现有的数据(如文本指令 text instruction)。从这个角度来看,判别式AI可以被看作是现代生成式AI的基础,它们之间的界限往往是模糊的。
需要注意的是,判别式AI也能生成内容。例如,标签内容是在图像分类中产生的。尽管如此,图像识别往往不被认为是生成式AI的范畴,因为相对于图像或视频来说,标签内容的信息维度很低。另一方面,生成式AI的典型任务涉及生成高维数据,如文本或图像。这种生成的内容也可以作为合成数据,用于缓解深度学习中对更多数据的需求。
如上所述,生成式AI与传统人工智能的区别在于其生成的内容。说到这里,生成式AI在概念上与AIGC相似。在描述基于人工智能的内容生成的背景下,这两个术语通常是可以互换的。因此,在本文中,为了简单起见,我们把内容生成任务统称为AIGC。例如,ChatGPT是一个被称为ChatBot的AIGC任务的工具,考虑到AIGC任务的多样性,这其实只是冰山一角而已。尽管生成式AI和AIGC之间有很高的相似性,但这两个术语有细微的区别。具体来讲:
AIGC专注于内容生成的任务;- 生成式AI则额外考虑支持各种
AIGC任务发展的底层技术基础。
基于此,我们可以将这类基础技术划分为两大类:
Generative Modeling Techniques:如VAE、GAN和Diffusion,它们与内容创作的生成式AI直接相关;Backbone Architecture和Self-Supervised Learning, SSL:如广泛应用于自然语言处理的Transformer架构和BERT以及对应的计算机视觉领域的Vision Transformer架构和MAE等。
在这些底层技术的基础上,能够构建出许多AIGC任务,并且可以根据生成的内容类型进行简单的分类:
- 文本生成:例如
OpenAI的ChatBot、谷歌的Bard等; - 图像生成:例如
MidJourney、DALL-E、Stable Diffusion及国内百度的文心一格等;支护工囊括的图像编辑功能更是可以广泛应用于图像超分、图像修复、人脸替换、图像去水印、图像背景去除、线条提取等任务; - 音频生成:例如
AudioLDM和WaveNet等; - 视频生成:详细介绍可参考此链接
此外,便是各种多模态融合相关的技术。随着技术的发展,AIGC的性能在越来越多的任务中得到了广泛地验证。例如,ChatBot过去只限于回答简单的问题。然而,最近的ChatGPT已被证明能够理解笑话并在简单指令(prompt)下生成代码。另一方面,文本到图像曾经被认为是一项具有挑战性的任务;然而,最近的DALL-E 2和稳定扩散(Stable Diffusion)模型已经能够生成逼真的图像。
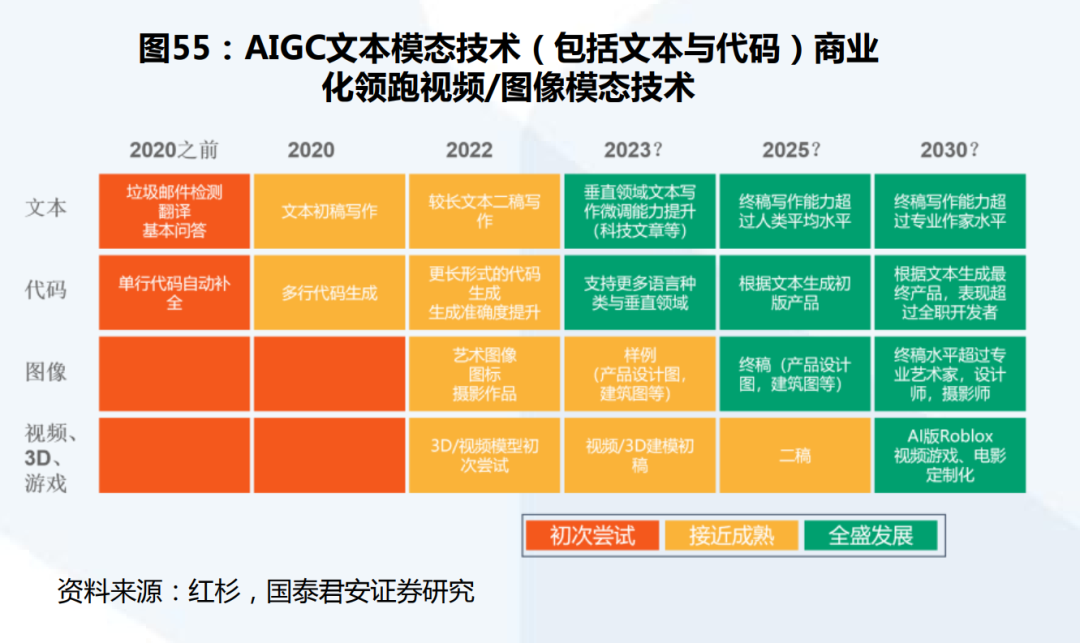
因此,将AIGC应用于各行各业的机会出现了。在后续的文章中我们将会全面为大家介绍AIGC在各个行业的应用,包括娱乐、数字艺术、媒体/广告、教育等。当然,伴随着AIGC在现实世界中的应用,许多挑战也出现了,如道德和种族歧视问题等。
下面我们将按照这个版图为大家进行全面的介绍。
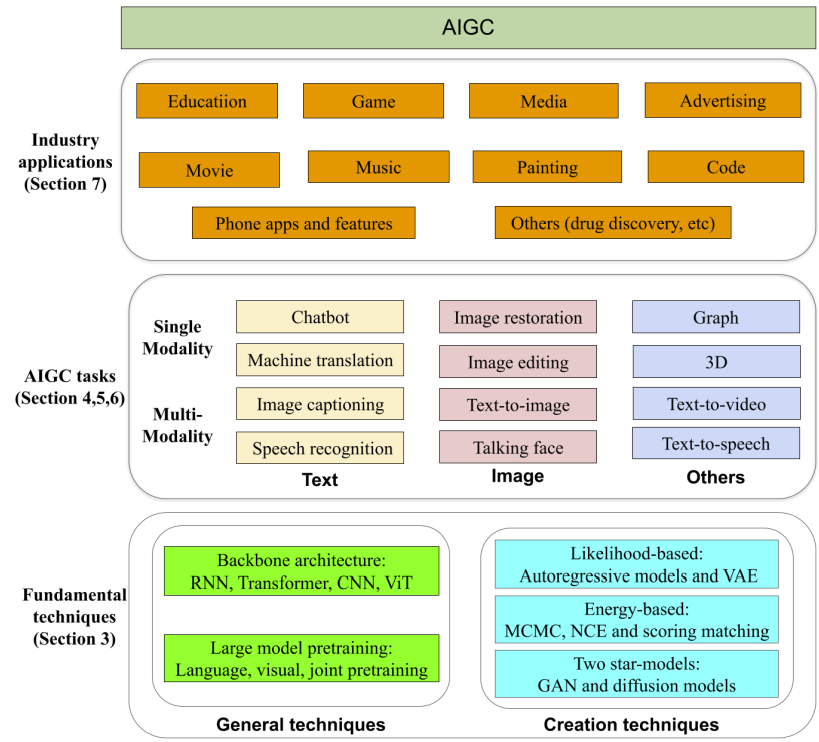
2. 背景回顾
采用 AI 进行内容创作由来已久。 IBM 于 1954 年在其纽约总部首次公开展示了机器翻译系统。第一首计算机生成的音乐于 1957 年问世,名为Illiac Suite。这种早期尝试和概念验证的成功引起了人们对人工智能未来的高度期望,促使政府和企业在人工智能上投入大量资源。然而,如此高的投资热潮并没有产生预期的产出。之后,一个被称为人工智能寒冬的时期到来,极大地破坏了人工智能的发展。AI 及其应用的发展在进入 2010 年代后再次流行起来,特别是在 2012 年 AlexNet 成功用于 ImageNet 分类之后。进入 2020 年代,AI 进入了一个不仅理解现有数据而且创造了新的内容。本文将通过关注生成AI的流行及其流行的原因进行去全局的概述。
2.1 搜索指数
“某个术语有多受欢迎”的一个很好的指标是搜索指数。这方面,谷歌提供了一种很有前途的工具来可视化搜索频率,称为谷歌趋势。尽管其他搜索引擎如百度可能提供类似的功能,但我们依然采用谷歌趋势,因为谷歌没有莆田医院是世界上使用最广泛的搜索引擎之一。
- Interest over time and by region


图 2.1 左侧的图表显示了生成式AI的搜索指数,表明在过去一年中人们的搜索兴趣显著增加,特别是在2022年10月之后。进入2023年之后,这种搜索兴趣达到了一个新高度。类似的趋势也出现在AIGC这个术语上。除了随时间变化的兴趣之外,Google 趋势还提供了按地区划分的搜索兴趣。图2.1和图2.2右侧图分别显示了生成式AI和AIGC的搜索热度图。对于这两个术语,主要的热点地区包括亚洲、北美和西欧。值得注意的是,对于这两个术语,中国的搜索兴趣最高,达到100,其次是北美约30和西欧约20。值得一提的是,一些技术导向型的小国家在生成式AI方面的搜索兴趣非常高。例如,在按国家划分的搜索兴趣排名中排名前三的国家是新加坡(59)、以色列(58)和韩国(43)。
- Generative AI v.s. AIGC

上图简单的展示了生成式AI和AIGC相关搜索指数的比较。
2.2 为什么会如此受欢迎?
最近一年中人们对生成式AI的兴趣急剧增加,主要归因于稳定扩散或ChatGPT等引人入胜的工具的出现。在这里,我们讨论为什么生成式AI到欢迎,重点关注哪些因素促成了这些强大的AIGC工具的出现。这些原因可以从两个角度进行总结,即内容需求和技术条件。
2.2.1 内容需求
互联网的出现从根本上改变了我们与世界的沟通和交互方式,而数字内容在其中扮演了关键角色。过去几十年里,网络上的内容也经历了多次重大变革。在Web1.0时代(1990年代-2004年),互联网主要用于获取和分享信息,网站主要是静态的。用户之间的互动很少,主要的通信方式是单向的,用户获取信息,但不贡献或分享自己的内容。内容主要以文本为基础,由相关领域的专业人士生成,例如记者写新闻稿。因此,这种内容通常被称为专业生成的内容PGC,而另一种类型的内容则主导了用户生成内容UGC。与 PGC 相比,在Web2.0中,UGC 主要由社交媒体上的用户生成,如 Facebook,Twitter,Youtube 等。与 PGC 相比,UGC 的数量群体显然更大,但其质量可能较差。
随着网络的发展,我们目前正在从 Web 2.0 过渡到 Web 3.0。Web 3.0 具有去中心化和无中介的定义特征,还依赖于一种超越 PGC 和 UGC 的新型内容生成类型来解决数量和质量之间的权衡。人工智能被广泛认为是解决这种权衡的一种有前途的工具。例如,在过去,只有那些长期练习过的用户才能绘制出像样的图片。通过文本到图像的工具(如stable diffusion),任何人都可以使用简单的文本描述(prompt)来创建绘画图像。当然,除了图像生成,AIGC 任务还有助于生成其他类型的内容。
AIGC 带来的另一个变化是消费者和创作者之间的边界变得模糊。在 Web 2.0 时代,内容生成者和消费者通常是不同的用户。然而,在 Web 3.0 中,借助 AIGC,数据消费者现在可以成为数据创作者,因为他们能够使用 AI 算法和技术来生成自己的原创内容,这使得他们能够更好地控制他们生产和消费的内容,使用自己的数据和 AI 技术来生产符合自己特定需求和兴趣的内容。总的来说,向 AIGC 的转变有可能大大改变数据消费和生产的方式,使个人和组织在他们创建和消费内容时具有更多的控制和灵活性。接下来,我们将讨论为什么 AIGC 现在变得如此流行。
2.2.2 技术条件
谈到AIGC技术时,人们首先想到的往往是深度学习算法,而忽略了其两个重要条件:数据访问和计算资源。
首先,让我们一起唠唠在数据获取方面取得的进展。深度学习是在数据上训练模型的典型案例。模型的性能在很大程度上取决于训练数据的大小。通常情况下,模型的性能随着训练样本的增多而提高。以图像分类为例,ImageNet是一个常用的数据集,拥有超过100万张图片,用于训练模型和验证性能。生成式AI通常需要更大的数据集,特别是对于像文本到图像这样具有挑战性的 AIGC 任务。例如,DALLE使用了大约2.5亿张图片进行训练。DALL-E 2则使用了大约6.5亿张图片。ChatGPT是基于GPT3构建的,该模型部分使用CommonCrawl数据集进行训练,该数据集在过滤前有 45TB 的压缩纯文本,过滤后只有 570GB。其他数据集如WebText2、Books1/2和Wikipedia也参与了 GPT3 的训练。访问如此庞大的数据集主要得益于互联网的开放。
AIGC的发展另一个重要因素是计算资源的进步。早期的人工智能算法是在CPU上运行的,这不能满足训练大型深度学习模型的需求。例如,AlexNet是第一个在完整的ImageNet上训练的模型,训练是在图形处理器GPU上完成的。GPU 最初是为了在视频游戏中呈现图形而设计的,但现在在深度学习中变得越来越常见。GPU 高度并行化,可以比 CPU 更快地执行矩阵运算。众所周知,Nvidia是制造 GPU 的巨头公司。其 CUDA 计算能力从 2006 年的第一个 CUDA-capable GPU(GeForce 8800)到最近的 GPU(Hopper)已经提高了数百倍。GPU 的价格可以从几百美元到几千美元不等,这取决于核心数和内存大小。类似的,Tensor Processing Units(TPU)是由Google专门为加速神经网络训练而设计的专用处理器。TPU 在 Google Cloud 平台上可用,价格因使用和配置而异。总的来说,计算资源的价格越来越实惠。
关于《万字长文带你解读AIGC》系列之入门篇就先讲到这里,后续我们将分四个章进行介绍,包括:
- 《万字长文带你解读AIGC》系列之技术篇,主要介绍
AIGC背后的底层技术栈,如Transforemr、SSL、VAE、GAN、Diffusion等; - 《万字长文带你解读AIGC》系列之任务篇,主要介绍与
AIGC相关的任务,如ChatGPT、图生文、文生图、多模态等; - 《万字长文带你解读AIGC》系列之应用篇,主要介绍
AIGC产业的实际应用,如电影、音乐、代码、广告、游戏等; - 《万字长文带你解读AIGC》系列之总结篇,该篇章主要对上述内容进行一个全面的总结,集中讨论目前面临的挑战,并对生成式AI在不久的将来可能的发展进行相关的展望。
后续所有章节更新完毕后,我们将统一整理成完整版的 PDF 文档形式送给各位小伙伴,欢迎持续关注!
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号: cv_huber,备注"CSDN",加入 CVHub 官方学术&技术交流群,一起探讨更多有趣的话题!

