
- 1阿里云企业IPv6部署方案_公有云saas应用ipv6适配
- 2Drive&Act:用于自动驾驶汽车细粒度驾驶员行为识别的多模态数据集_auc distracted driver dataset
- 3Python数据分析与展示(三)--Matplotlib库_导入matplotlib库
- 4java 可变参数
- 5网康 NS-ASG安全网关存在远程命令执行漏洞 复现_奇安信网康科技防火墙远程命令执行漏洞
- 6单片机6路抢答器c语言程序,基于51单片机的六路抢答器程序
- 7.分享10个最新的Web前端框架_前端2024最新的框架
- 8JAVA程序猿推荐看的15本书_错过了是你损失
- 9网康NS-NGFW防火墙远程RCE 漏洞复现_/directdata/direct/router
- 10云端技术驾驭DAY12——Pod调度策略、Pod标签管理、Pod资源配额与限额、全局资源配额与限额策略
Redis 常见面试题_redis面试题
赞
踩
1. 认识Redis
Redis是一个开源的内存数据结构存储,Redis是一个基于内存的数据库,对数据的读写都在内存中完成,因此数据读写速度非常快,常用于缓存,分布式锁等,MySQL的表数据都存储在 t_order.ibd,MySQL的表结构存储在 t_order.frm。Redis提供了多种数据类型来支持不同的业务场景。比如String,Hash,Set,Zset,Bitmaps等。
Redis与Memcached 有什么区别
相同点:都是基于内存的数据库,都被当作缓存使用
都有过期策略
两者的性能都很高
不同点:
Redis 支持多种不同的数据类型,而Mencached 只支持一种
Redis支持数据的持久化,可以将内存的数据保存在磁盘中,重启的时候可以加载出来使用。Memcached则不支持数据的持久化,服务器重启之后,数据则会变没。
Redis原生支持集群模式,Memcached则不支持。
Redis支持发布订阅,Lua脚本,事务等功能。
为什么采用Redis作为MySQL的缓存?
因为Redis具有高性能和高并发两种特性。
要想读写磁盘的数据,就需要将磁盘的数据读入内存,从内存中读取数据。
2. Redis 数据结构
常见的五种数据类型:String,Hash,Set,Zset,List
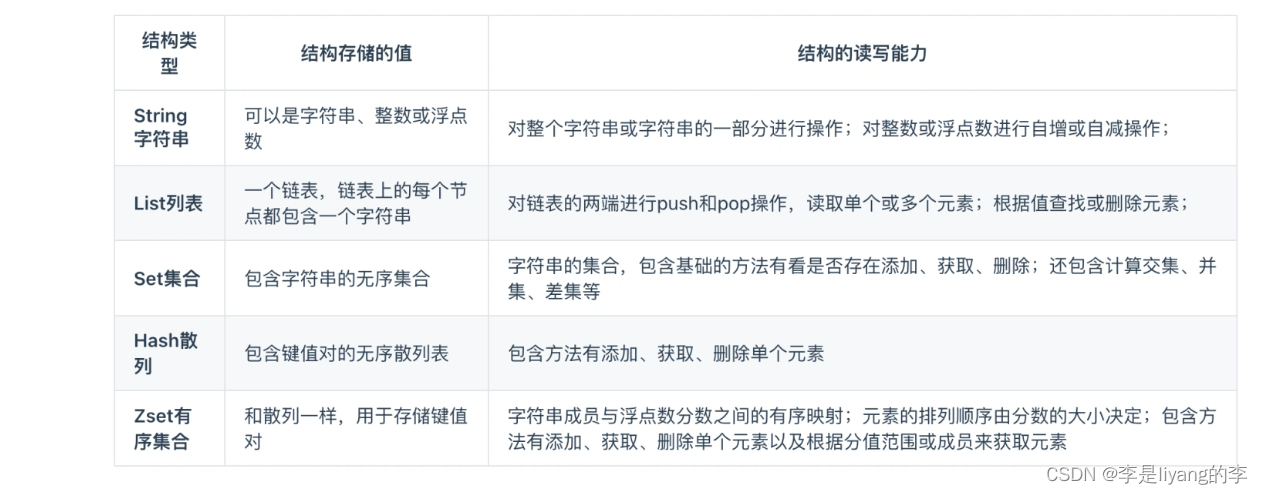
随着Redis新版本的发布,有支持以下四种方式:Bitmap,Hyperloglog,GEO,Stream
五种数据类型的应用场景:
String:缓存对象,常规计数,分布式锁,共享Session信息
List:消息队列(有两个问题 1. 生产者需要自行生产全局唯一Id,不能以消费组的形式消费数据)
Hash:缓存对象,购物车等
Set:聚合计算(交叉行为)例如点赞,共同关注等
Zset:排序场景,例如排行榜,电话和姓名排序。
BitMap:二值状态统计的场景,例如签到,判断用户登录状态等。、
Hyperloglog:海量数据技术的统计场景,
GEO:存储地理位置信息的场景,比如滴滴叫车
Stream:消息对列。
数据类型的内部实现:
String:
底层数据结构实现采用SDS(简单动态字符串),它比C 字符串有以下优点:
它不仅可以保存文本数据,还可以保存二进制数据(图片,音频,视频,压缩文件等)。因为SDS采用len 属性值来判断字符串是否结束。而不是像C字符串采用空字符串判断字符串是否结束。
SDS获取字符串长度的时间是O(1) ,因为C 字符串不会记录自身长度,所以获取时间为O(n),而SDS可以通过len属性的值来获取字符串长度,所以为O(1).
Redis的API 是安全的,拼接字符串不会造成缓冲区溢出。
List:
采用双向链表或者压缩列表实现,
当链表中的元素个数小于512个,每个元素的值小于64字节。Redis会使用压缩列表来作为List的底层结构,如果不满足上述条件,则采用双向链表作为底层结构。
Hash:
当Hash中的元素个数小于512个,每个元素的值小于64字节,Redis会使用压缩链表来作为Hash的底层数据结构。如果不满足上述条件,则采用双Hash表。
Set
如果Set集合中的数据小于512个,则采用整数集合的形式来作为Set的底层结构
否则使用哈希表
Zset
入锅集合中的数据小于128个,每个数据的值得大小小于64字节,则采用压缩列表得形式
否则使用跳表
Redis 的线程模型
Redis是单线程吗?
Redis是单线程指的是 接收客户端请求-—》解析请求—》进行数据读写—》发送数据给客户端---》 这个过程是由一个线程(主线程)来完成的。Redis并不是单线程的,在Redis启动时,会启动后台线程。

Redis的持久化
Redis是如何实现数据不丢失的?
Redis的数据读写都是在内存中,所以读写效率很高。但是当Redis重启时,内存中的数据就会丢失。那么为了保证内存中的数据不会丢失,Redis实现了持久化机制。这个机制会把数据保存到磁盘,防止数据丢失。
一共由三种方式:
AOF 日志:每执行一条写操作命令,就把该命令以追加的方式写入另一个文件中
RDB快照:将某一时刻的数据,以二进制的形式写入磁盘
混合持久化机制:集合了AOF和RDB的优点
AOF 日志:
Redis每执行一条命令,就会将命令以追加的形式写入到一个文件中。Redis重启时,会读取该文件记录的命令。然后逐一执行命令的方式来恢复数据。

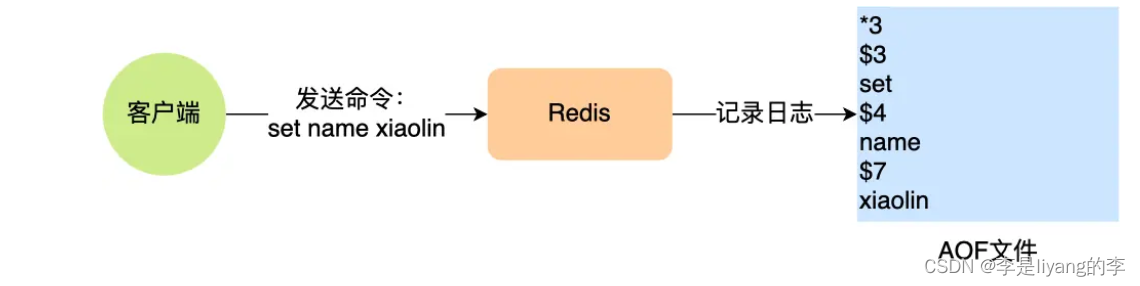
先执行写操作,后将该命令计入到AOF日志中。
两个好处:
1)避免额外的检查开销,当先执行写操作时,该命令已经被检查过了,没有问题然后被计入到AOF日志中。如果先将命令计入到AOF日志。则还需要再检查一次。
2)不会阻塞当前写操作的执行:因为当写操作执行成功之后,才将命令计入到AOF日志。
两个风险:
1)当执行完写命令后,还未将命令写入AOF 日志,发生服务器宕机。数据就由丢失的风险。
2)可能会阻塞其他操作。虽然执行完写命令后,将数据计入到AOF日志中,但是可能会阻塞后续其他操作。
AOF写回策略:
过程图

Redis在执行完写操作后,会将命令追加到server.aof_buf 缓冲区
然后通过write() 调用来将aof_buf 缓冲区的数据放到AOF 文件中。此时数据并没有写入到硬盘。而是将数据存到了内核缓冲区page cache。等待内核将数据写入到硬盘
具体内核缓冲区的数据什么时候写入到硬盘由内核决定
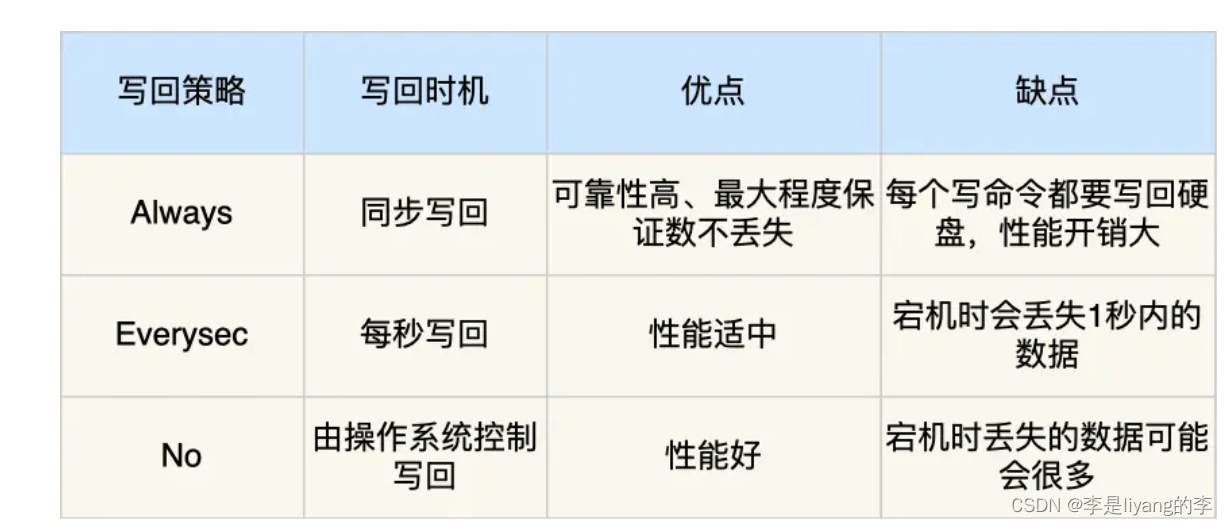
Redis写回硬盘策略:
always : 总是,每次执行完写命令,就将内核缓冲区的数据写入到硬盘。
Everysec:每秒
No:不由Reids决定何时写回硬盘,而是由操作系统决定。
当AOF文件过大时,会触发AOF重写机制。当AOF文件的大小超过所设阈值时,就会触发AOF重写机制,来压缩AOF文件。
AOF重写机制就是在重写时,读取数据库中所有的键值对,然后将每一个键值对用一个命令来记录到新的AOF文件中。等到记录完毕,将新的AOF文件替换掉旧的AOF文件。
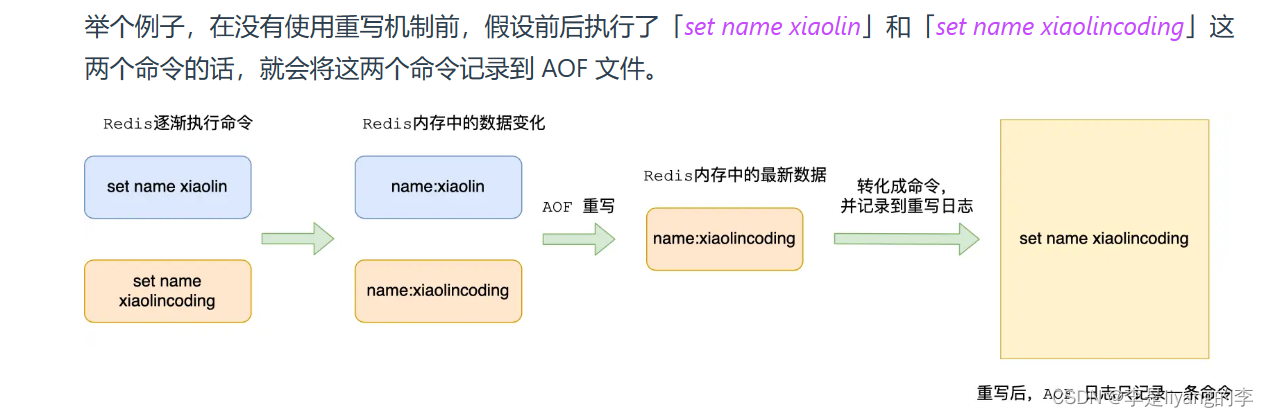
在使用重写机制后,就会读取name最新的键值对,然后用一条命令来存储到新的AOF文件中。这样就压缩了AOF文件的大小。
重写AOF日志的过程是怎样的?
重写AOF日志过程是由后台子进程 bgrewriteaof 来完成的。这样做有两个好处:
1)子进程在进行重写期间,主进程可以继续处理请求,从而避免阻塞主进程。
2)子进程带有主进程的数据副本。如果采用线程的形式,多线程之间会修改共享数据。需要通过来保证线程安全。会降低性能。而使用子进程时,由于是父子进程,父子进程之间可以共享数据。但是只能以只读的形式。父子进程任意一方修改了共享数据,就会发生写时复制。于是父子进程就会有独立的数据副本,就不需要加锁。
触发重写机制后,主进程就会创建子进程。此时父子进程共享内存数据。重写子进程只会对这个内存数据进行只读。子进程会读取数据库的所有键值对,并以一条命令的形式保存到AOF文件中。
但是在子进程重写过程中,主进程依然可以正常处理命令。 但是,在重写AOF日志中,如果主进程已经修改了存在的key-value,就会发生写时复制。那么key-value在AOF文件中的数据与数据库中的数据就会不一致。
为了解决以上问题,Redis设置了一个AOF重写缓冲区。这个缓冲过去在创建子进程bgrewriteaof 开始使用。
在重写AOF日志时,当Redis执行一个命令之后,就会将该命令写入到AOF文件和AOF重写缓冲区。
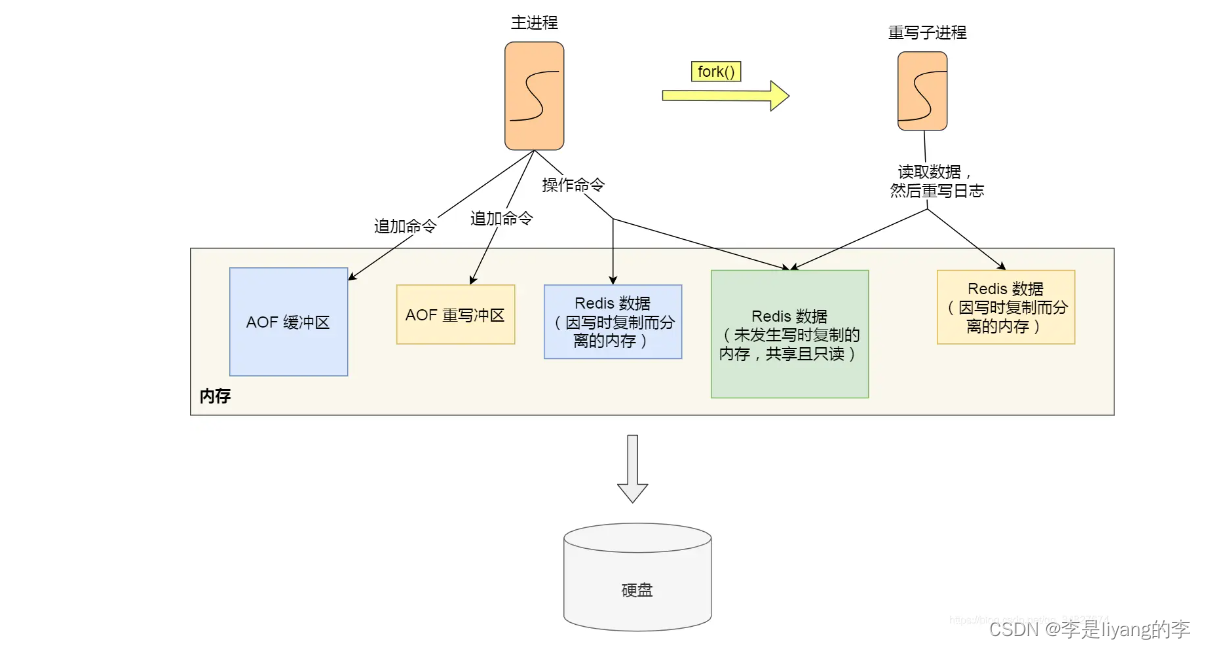
在重写子进程重写期间,主进程会有以下工作:
执行客户端发来的请求
将执行后的命令追加到AOF重写缓冲区
将执行后的命令追加到AOF缓冲区
当子进程完成重写工作后(扫描数据库中的所有键值对,逐一将数据库中的键值对转化为命令存入AOF文件中)会向主进程发送一条信号。
当主进程收到信号后,会调用一个函数处理这个信号。它主要做一下两个工作:
1. 将AOF重写缓冲区的所有内容追加到新的AOF文件中,使得新旧两个AOF文件数据保持一致。
2. 新的AOF文件进行改名,并覆盖旧的AOF文件。
信号函数执行之后,主进程就会运行啦
RDB快照是如何实现的?
AOF日志存储的是操作命令,而RDB存储的是实际的数据。
RDB做快照时会阻塞线程吗?
Redis提供了两个命令save 和 bgsave 来生成RDB文件。它们的区别在于是否在主线程执行。
save:执行了save命令,就会在主线程生成RDB文件,可能会阻塞主线程.
bgsave:执行了bgsave命令,就会创建一个子进程来生成RDB文件,这样可以避免主线程的阻塞。
RDB快照是全量快照。每次执行快照,就会把内存中的所有数据存入到磁盘中,这个任务十分巨大,执行太频繁,可能会对Redis性能造成影响。
RDB在执行快照时,数据能修改吗?
在执行 bgsave Redis仍然可以执行数据修改操作。原因就在于写时复制技术。
执行bgsave过程中,会通过fork 创建子进程,此时子进程是和主进程共享内存数据。因为创建子进程时,会复制主进程的页表,但是页表指向的物理地址还是同一个。
如果主进程执行读操作,则主进程和子进程互不影响。
如果主进程执行写操作,则被修改的数据会复制一份副本,然后bgsave子进程沪江副本数据写入到RDB文件中。在这个过程中,主进程仍然可以修改原来的数据。
为什么会有混合持久化?
RDB的优点是数据恢复速度快,但是恢复的频率不好把握。频率太低,丢失的数据会变多,频率变快,会影响Redis的性能。
AOF日志的优点是丢失数据少,但是恢复速度不快。
为了集成两者的优点,采用混合使用AOF和内存快照。也叫混合持久化。既保证了Redis重启速度,又降低了数据丢失风险。
混合持久化工作在AOF重写过程中,当开启了混合持久化,在AOF子进程重写日志时,fork创建出来的子进程会先将于主进程共享的内存数据以RDB的形式写入到AOF文件中,然后后面主进程的操作命令会写入到AOF重写缓冲区,重写缓冲区的增量命令会以AOF的格式写入到AOF文件中。写入完成后会将新的含有RDB格式和AOF格式的AOF文件替换掉旧的AOF文件。

混合持久化的优点是 前面时RDB格式的文件,加载的速度会很快,而后面以AOF的形式,可以丢失更少的数据。

Redis集群
Redis如何实现服务高可用?
要想实现Redis服务高可用,一定要从Redis多服务节点考虑,比如Redis的主从复制,哨兵模式,切片集群等。
主从复制
将从前一台的服务器数据,同步数据到其他几个服务器。即一主多从的模式,主从服务器之间采用读写分离模式。
主服务器可以进行读写操作,且写操作之后,会将命令同步到从服务器。而从服务器一般是只读,并执行主服务器发送过来的命令。
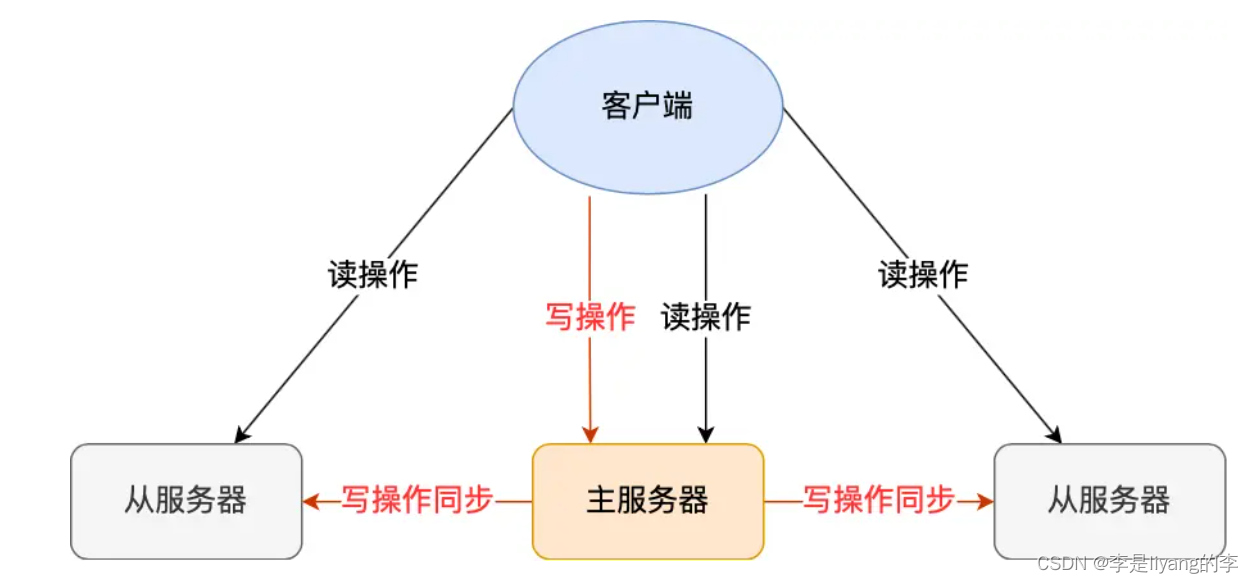
也就是说数据只能在主服务器上修改,然后将最新的数据同步到从服务器。这样使得主从服务器数据保持一致性。
但是,主从服务器之间的命令复制是异步进行的,所以无法实现强一致性。
当主服务器接收到新命令后,就会将命令发送给从服务器,但是,当主服务器完成命令之后,不会等待从服务器返回执行结果。会直接向客户端返回结果。如果此时从服务器还未执行发送过来的命令,那么主从服务之间数据也就不一致了。
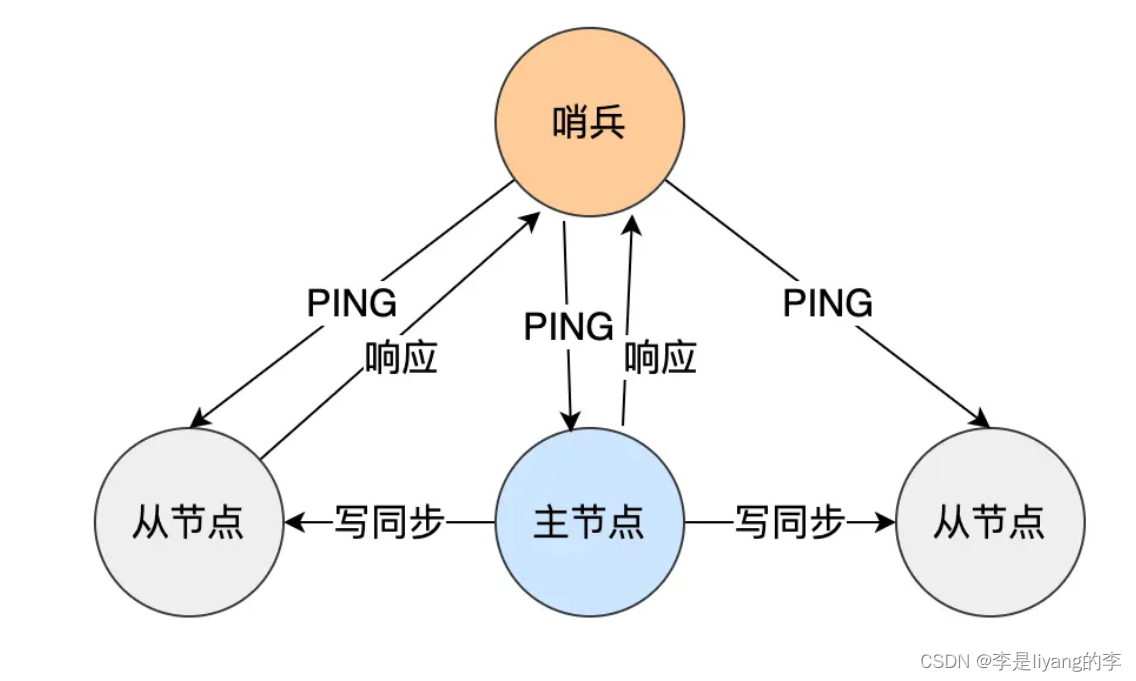
哨兵模式
在使用主从服务器服务时,当主从服务器进行故障宕机的时候,需要手动恢复,这时候就需要哨兵模式。因为哨兵模式可以监控故障节点,并且提供主从节点转移故障的功能
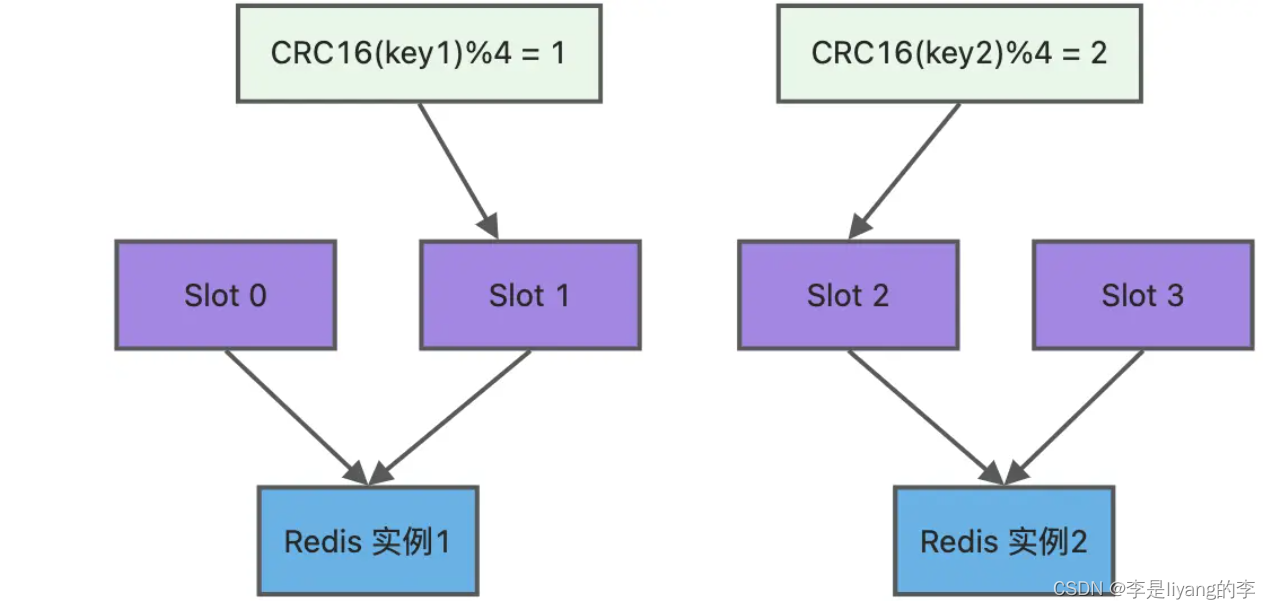
切片集群模式
当Redis上的缓存数据量大到一台服务器无法缓存时,需要使用Redis切片集群,他将数据分配到不同的服务器之上,以此来降低系统对主节点的依赖,从而提高Redis的读写性能。
集群脑裂导致数据丢失怎么办
脑裂
脑裂就是一个主服务器和多个从服务器。当主服务器因为网络原因暂时挂掉,这时它与所有的从根节点失联啦。但是此时主节点和客户端之间的网络是正常的。这个客户端并不知道主服务器与从节点失联,仍然继续向主节点发送数据。而此时哨兵发现了主节点与所有的从节点失联,于是它又选出一个从节点来作为主节点。当这时主节点的网络恢复后,发现有了一个主节点,于是自动降为从节点,与此同时,该旧主节点的数据被清除,新主节点的数据被同步到旧主节点。但是,在旧主节点失联期间时,客户端传输的数据也就丢失了。这就是集群脑裂造成的问题。
解决方案
当主节点发现从节点下线,或者通讯超时的总量小于阈值时,禁止主服务器读写数据。直接把错误返回给客户端。
在Redis的配置文件中有两个参数可以设置:
min-saves-to-write x,主节点必须要有至少X个从节点连接,如果小于这个数,禁止主节点进行读写数据。
min-saves-to-log x, 主从复制和同步的延迟不能超过X 秒,如果超过,进制读写数据。
我们可以搭配使用,比如,主服务器连接的从库至少要有N个,和主库进行主从复制时ACK消息延迟不能超过T秒,否则,禁止主节点读取数据。
Redis过期删除和内存淘汰策略。
Redis使用的过期删除策略是什么?
Redis对Key设置对应的过期时间,Redis将Key和对应的过期时间都存到了过期字典上面。就是说过期字典上面保存了所有Key的过期时间。
挡我们查询一个Key时,需要有以下两部分:
1. 如果不在过期字典中,则正常读取键值。
2. 如果在过期字典中,就会获取该Key的过期时间,并与当前系统时间进行比对,如果比系统时间大,则没有过期。否则,就是过期。
Redis使用的过期策略一般是惰性删除+定期删除
惰性删除:
不主动删除过期键,每次从数据库访问·Key时,都检测Key是否过期,如果过期则删除该Key。
优点:
每次访问时,才会检测Key过期不过期,所以系统只用了很少的资源,因此惰性删除对CPU访问时间很友好。
缺点:
不访问就不会检查是否过期,所占用的内存资源不会释放。造成内存空间浪费。
定期删除:
每隔一段时间从过期字典中抽取一部分Key检查,并删除其中过期的Key。

定期删除策略的优点:
通过限制删除操作执行的时长和频率,来减少删除操作对CPU的影响。同时也能删除一部分过期的Key,增加了内存空间。
定期删除策略的缺点:
难以确定删除操作执行的时长和频率,如果过高,则对CPU有影响,如果过低,则和惰性删除一样。
所以一般选择二者搭配使用。
Redis持久化时,对过期键是如何处理的?
来看一下过期键在RDB格式和AOF文件下的状态:
在RDB格式下,分为RDB文件生成阶段和文件加载阶段:
RDB文件生成阶段:从内存状态持久化到RDB文件生成状态,会对Key进行过期间检查,过期的键不会被保存到新的RDB文件中
RDB加载状态:RDB加载阶段,要看是在主服务器还是从服务器
在主服务器上:在载入RDB文件时,会对文件中保存的Key进行检查,如果过期。则不会被保存到数据库中。所以过期键对在主服务器上加载的RDB文件没有影响。
在从服务器上:无论是否过期。都会被存入到从数据库,但是在主从服务器进行数据同步时,从服务器数据会被清空,所以也不会有影响。
AOF文件,AOF文件写入阶段和AOF重写阶段:
AOF文件写入阶段:当某个过期间未被删除。,那么AOF文件会保存此过期键。当此过期键被删除之后,Redis 会追加一条DELETE命令来存到AOF文件中,显式的删除该过期键。
AOF重写阶段:执行AOF重写时,已过期的键不会被保存。不会被重写到新的AOF文件中。
Redis主从模式下,对过期键如何处理?
从库不会进行过期扫描,从库对于过期键的处理是被动的,当主服务器删除一条过期键时,会在AOF文件中追加一条del指令,该指令会被同步到所有从库,从库通过执行这条指令来删除过期键。
Redis内存满了会发生什么?
当Redis 的运行内存达到某个阈值时,就会触发内存淘汰机制,那个阈值就是我们设置的最大运行内存·。
Redis的内存淘汰策略:
1. 不进行内存淘汰,直接向客户端返回错误。
2. 在设置了过期时间的数据范围内淘汰
随即淘汰设置了过期时间的键值
优先淘汰更早过期的键值
淘汰所有设置了过期时间的键值中,最久未使用的键值
淘汰所有设置了过期时间的键值,最少使用的键值。
在所有数据中淘汰:
随机淘汰任意键值
在所有数据中,淘汰最久未使用的键值
在所有数据中,淘汰最少使用的键值。
Redis缓存设计?
如何避免缓存击穿,缓存穿透。缓存雪崩?
避免缓存雪崩
为了保证Redis中的数据与数据库中的数据的一致性,会给在Redis中的数据设置过期时间,当缓存过了过期时间,用户需要访问的数据不在缓存中,缓存会重新生成,因此需要重新访问数据库。并将数据库中的数据更新到Redis缓存中。但是,当大量的缓存在同一时间失效,如果此时有大量的请求来访问,此时无法在缓存中处理,于是请求全部转到数据库中,导致数据库的压力增大,可能会出现数据库宕机。导致一系列连锁反应,可能导致系统崩溃,这就是缓存雪崩。
两种解决方案:
1. 将缓存失效时间打散。(在原有的缓存失效时间的基础上加一个随机值,这样就不会导致缓存的过期时间重复)
2. 设置缓存不过期(通过后台服务 来更新缓存数据)
如何避免缓存击穿?
有些数据比如秒杀商品属于热点数据。当热点数据缓存过期,就会有大量的请求来到数据库,数据库很容易被高并发请求击垮,这就叫缓存击穿。
两种解决方案:
1. 设置互斥锁方案,保证同一时间只能有一个业务线程请求缓存,未能获取互斥锁的请求,要么等待互斥锁释放后重新读取缓存,要么就返回空值 或者默认值。
2. 不给热点数据设置过期时间。或者在热点数据快要过期前,提前通知后台线程更新缓存并重新设置过期时间。
如何避免缓存穿透?
当在缓存和数据库中,都不存在要访问的数据。导致大量请求一直访问数据库,可能会导致数据库宕机。
两种可能实现:
业务误操作。缓存中的数据和数据库中的数据都被误操作删除。
黑客恶意访问大量未存在的数据。
解决方式:
非法请求限制:在API入口判断请求参数是否合理,
设置空值和默认值
使用布隆过滤器来快速判断数据是否存在。避免通过查询数据库在判断数据是否存在。
如何设置一个缓存策略,可以动态缓存热点数据?
通过数据最新访问时间排名,并过滤掉不常访问的数据,只留下经常访问的数据。
常见的缓存更新策略:
一般采用旁路缓存策略。
旁路缓存策略:
应用程序可以与数据库,缓存直接交互。并负责对缓存的维护。该策略也可以被分为写策略和读策略。
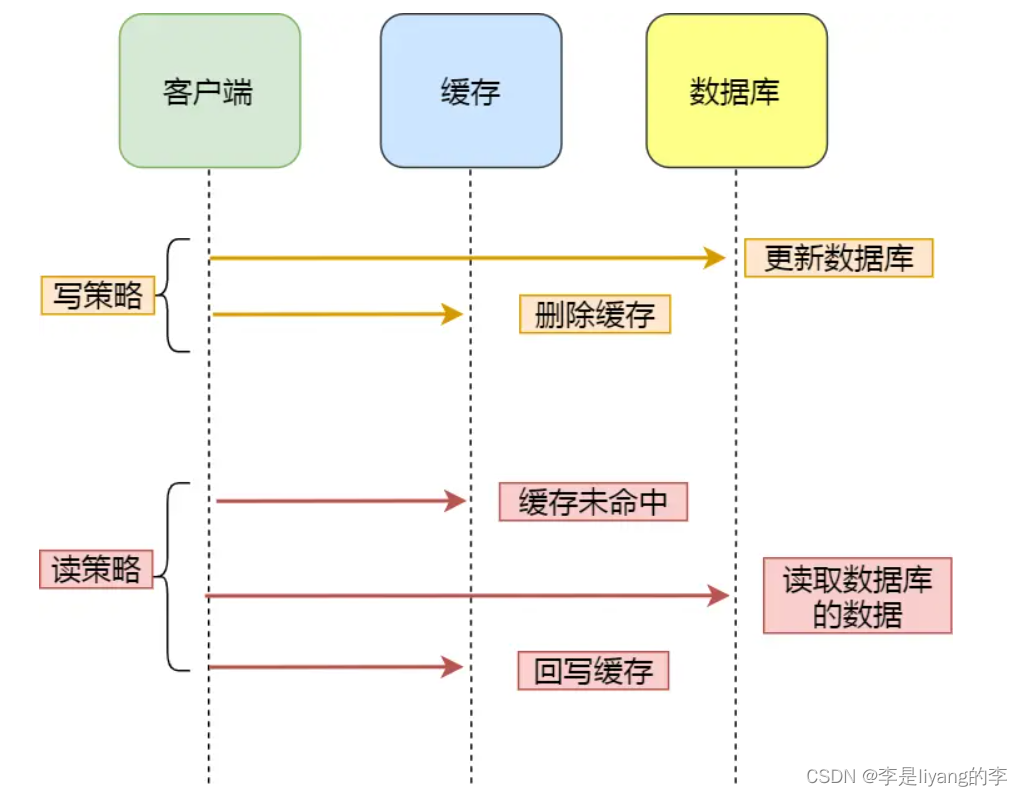
写策略:先更新数据库数据,再更新缓存中的数据。
读策略:如果请求的数据命中了缓存,则直接返回数据,如果没有命中,则直接访问数据库中的数据,并将数据写入到缓存中,返回给客户端。
Redis实战
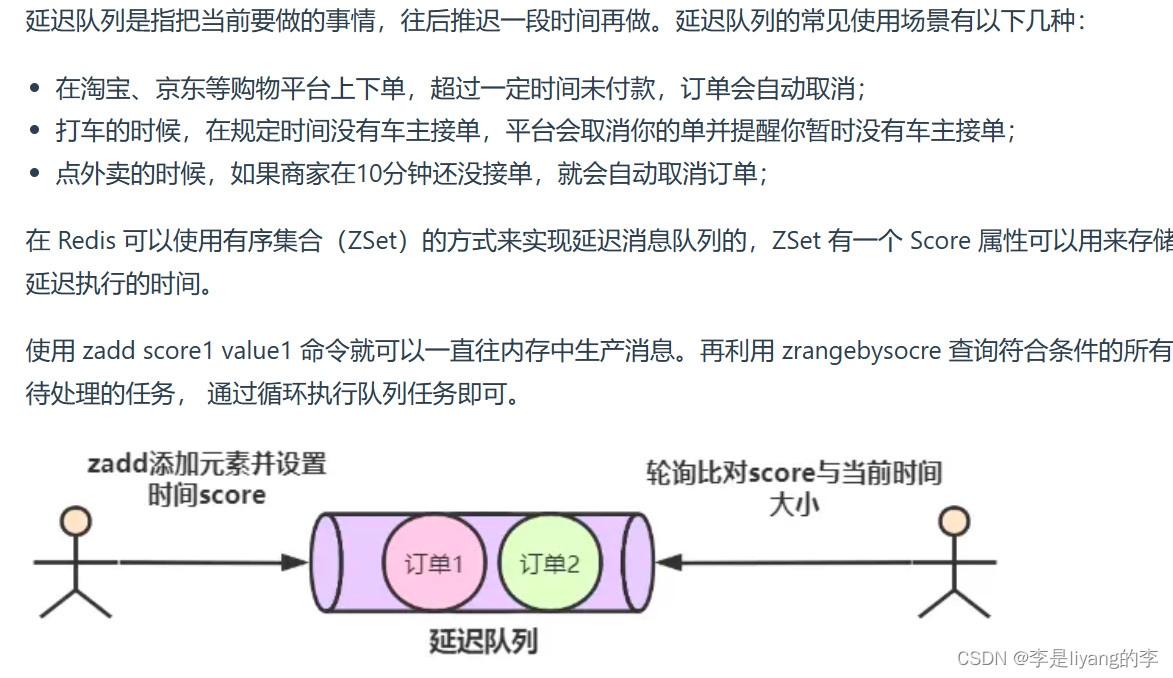
Redis如何实现延迟队列?
使用有序集合Zset来实现
Redis的大key如何处理?
大Key指的是Key对应的value值很大:
String类型的值大于10kb
Hash,List,Set,ZSet,元素的类型个数超过5000个
会造成什么影响?
1. 客户端超时阻塞
2. 引发网络阻塞
3. 阻塞工作线程
4. 内存分布不均、

