
YOLO系列(YOLOv1-YOLOv5)算法详细介绍和总结
赞
踩
YOLO系列(YOLOv1-YOLOv5)算法详细介绍和总结
前言
本文对YOLO系列网络进行了介绍,也是站在了“巨人”的肩膀上,将YOLO系列网络进行了总结。
YOLOv1
YOLOv1思想
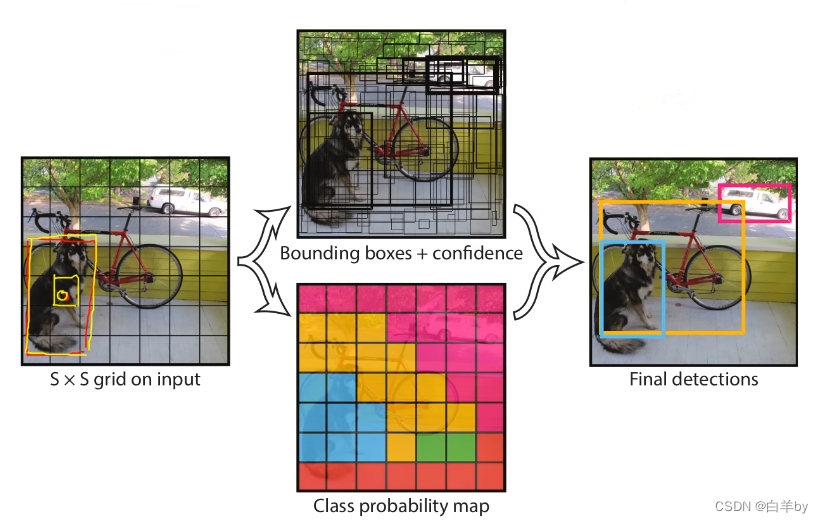
如上图所示,将一幅图像分成SxS个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
每个网格要预测B个bounding box,每个bounding box除了要预测位置之外,还要附带预测一个confidence值。每个网格还要预测c个类别的分数。
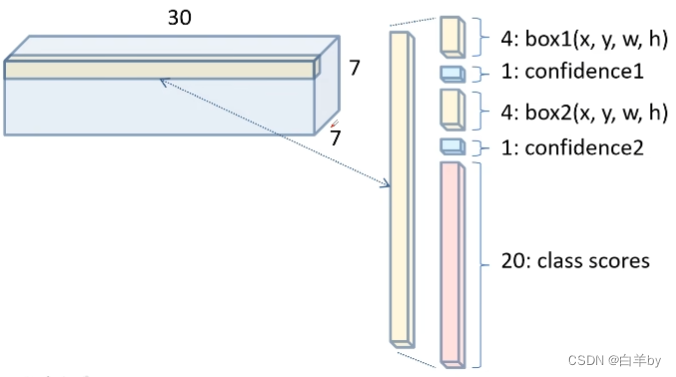
通过正向传播特征提取网络最后输出7x7、深度为30的特征矩阵,我们可以单独看延深度方向的一行向量(图中浅黄色),由于深度为30,所以这个向量有30个数值,将数值进一步拆分,因为每一个网格需要预测两个bounding box,每个bounding box预测5个数值,每个数值包括四个坐标信息和一个confidence,同时还包括20个类别分数。
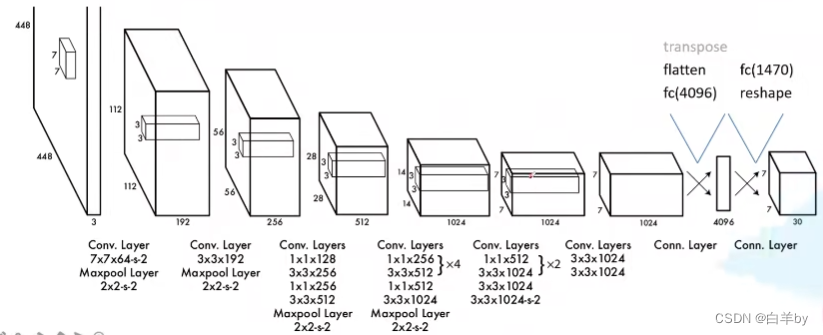
YOLOv1网络结构
YOLOv1的损失函数
YOLOv1的损失包含三部分:bounding box损失、confidence损失和classes损失。在计算损失时主要都是用的误差平方和求解

YOLOv1的问题
- 对一些群体性的小目标检测结果比较差
- 当目标出现新的尺寸和配置时目标检测结果比较差
- 定位不准确
YOLOv2
YOLOv2在YOLOv1的基础上做了如下尝试

1. Batch Normalization
通过使用Batch Normalization对模型的训练收敛具有很大帮助,同时减少了正则化处理,在MAP值上达到2%的提升,还可以移除dropout操作。
2. High Resolution Classifier
在YOLOv1中训练分类器时使用的是224x244的输入,而在 YOLOv2中作者采用了448x448的尺寸作为输入,论文总表明,采用更大的分辨率作为输入可以得到MAP值4%的提升。
3. Convolutional With Anchor Boxes
在YOLOv1中时直接预测边界框的中心坐标、宽度和高度,使用这种方式定位效果比较差,所以在YOLOv2中作者采用anchor进行目标框的预测,采用anchor也可以使网络更容易的去学习和收敛。
4. Dimension Clusters
根据训练集中的标注框采用K-means算法聚类得到先验框。
5. Direct location prediction
直接是使用anchor进行预测时发现,在训练模型的时候训练不稳定,通过观察发现大部分不稳定因素来自中心坐标的预测部分导致,所以作者提出采用如下anchor预测方式。
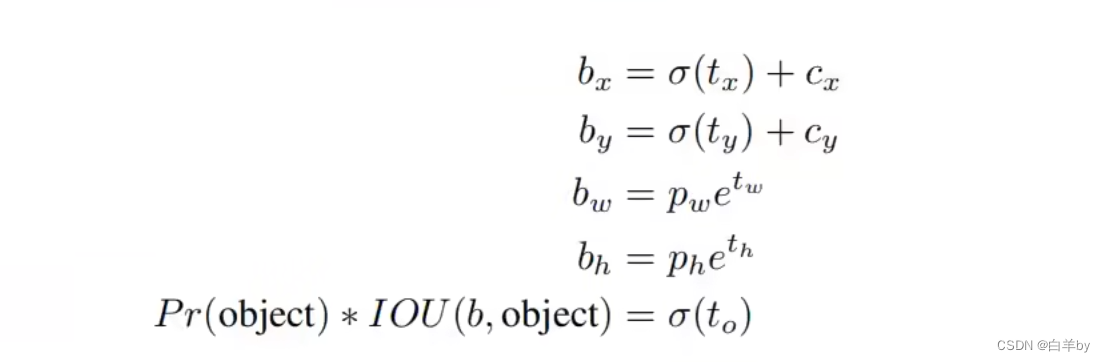
6. Fine-Grained Features
底层的特征信息会包含更多的特征细节,这些细节是在检测小目标时所需要的,所以将高层信息和低层信息进行融合。
7. Multi-Scale Training
为了提高网络的鲁棒性,使用不同的图像尺寸作为输入进行训练。每迭代10个batch就随机选择网络的输入尺寸,由于YOLOv2中的特征图缩放因子为32,所以网络中所用的特征图都是32的整数倍(320、352…609)。
Backbone:Darknet-19
Darknet-19包含19个卷积层,6个池化和一个Softmax。
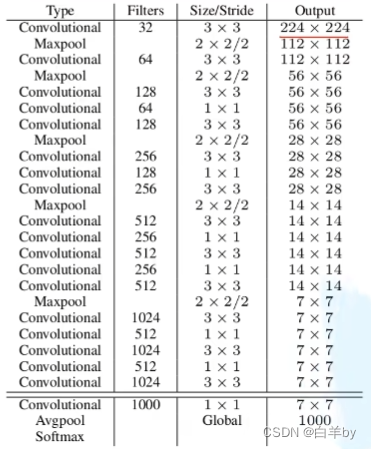
YOLOv2模型框架
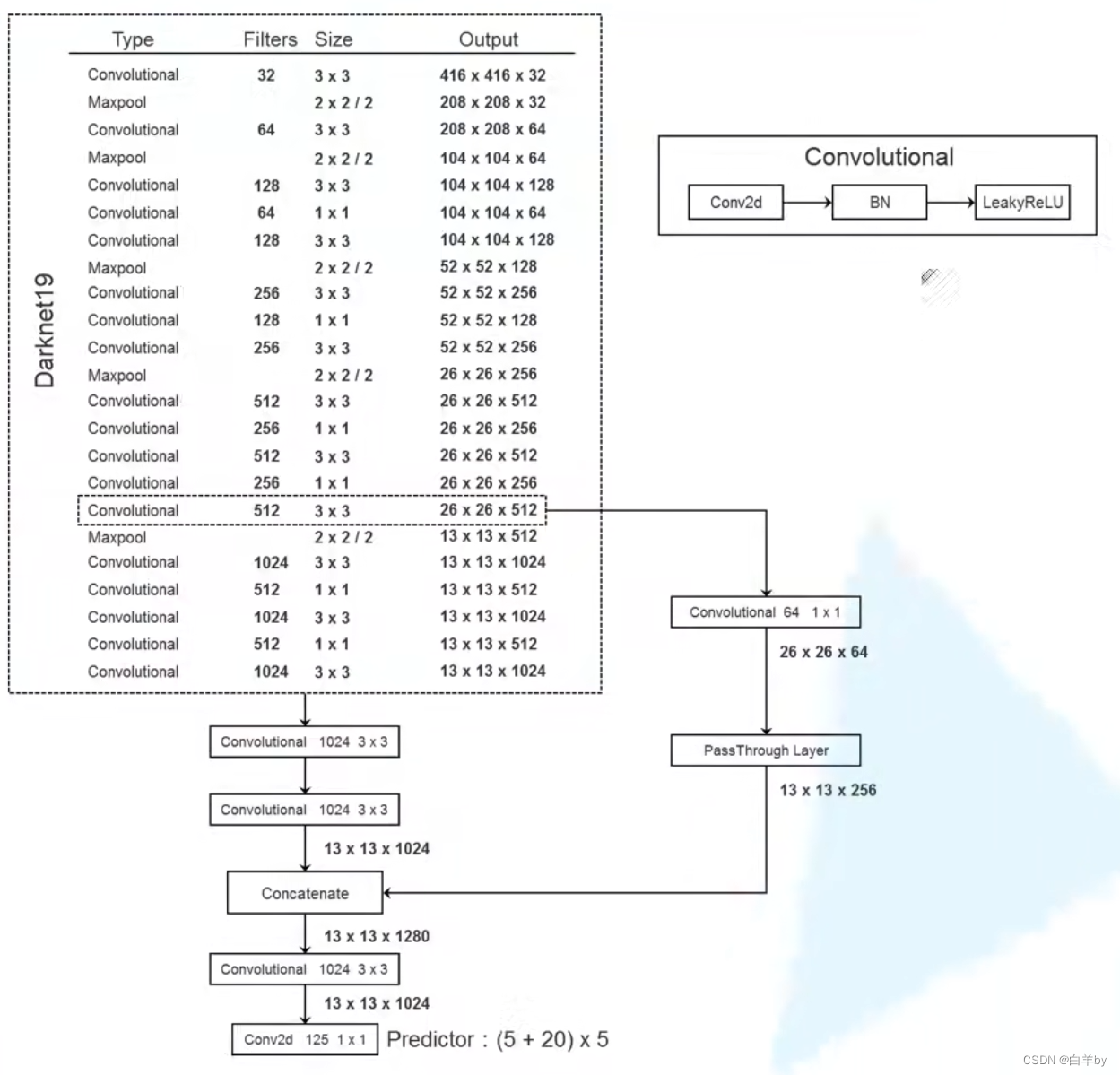
通过移除最后一个卷积层来修改这个网络进行检测,而是添加三个 3 x 3 卷积层,每个卷积层有 1024 个过滤器,然后是最终的 1 x 1 卷积层,其中包含我们需要检测的输出数量。 对于 VOC,我们预测 5 个框,每个框有 5 个坐标,每个框有 20 个类,因此使用125 个卷积核。 我们还从最后的 3 × 3 × 512 层到倒数第二个卷积层添加了一个特征融合层,以便模型可以使用细粒度特征。
YOLOv3
Backbone:Darknet53
YOLOv3在YOLOv2的基础上改进了backbone,YOLOv3的backbone如图
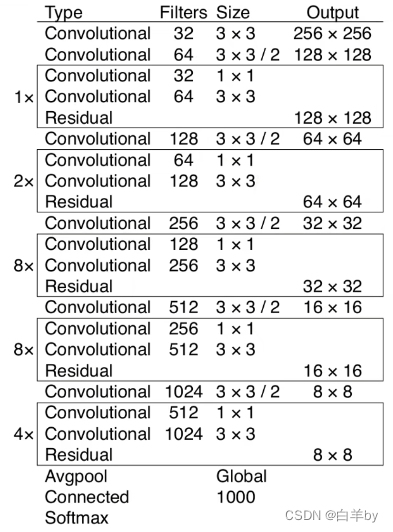
YOLOv3采用darknet-53作为backbone,其中53表示有53层卷积层,darknet-53并没有卷积层。
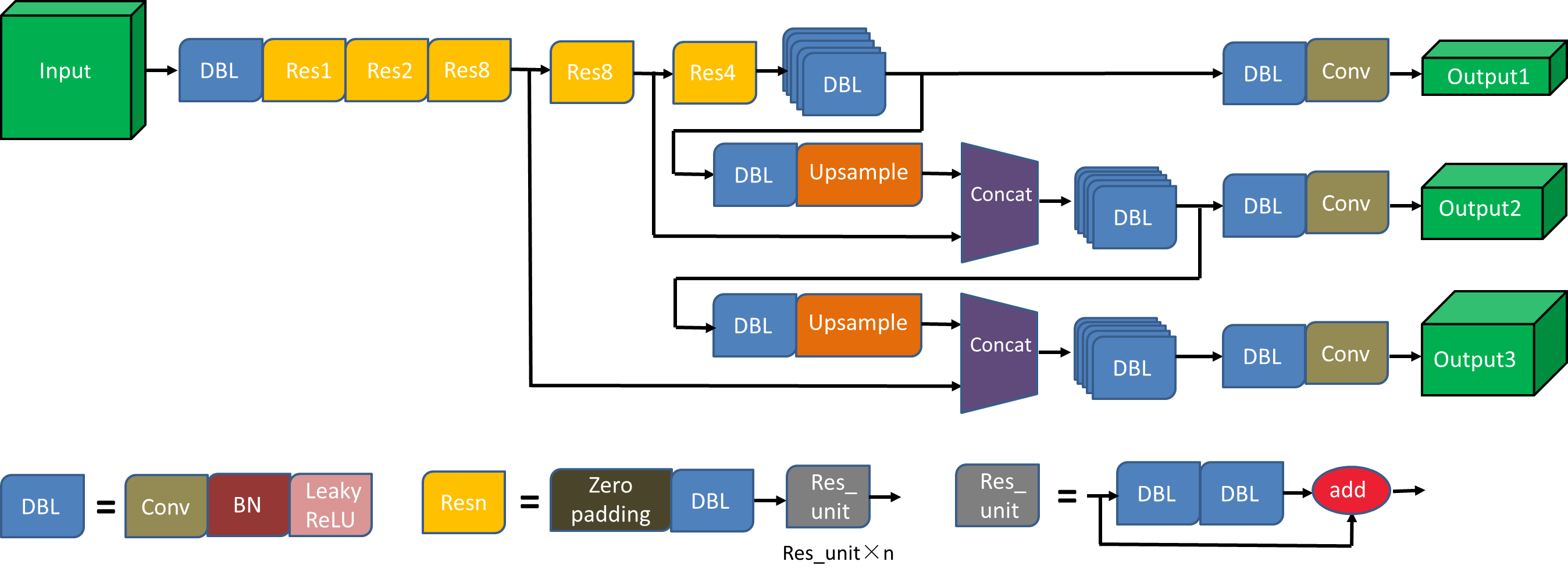
YOLOv3网络框架
目标边界框的预测
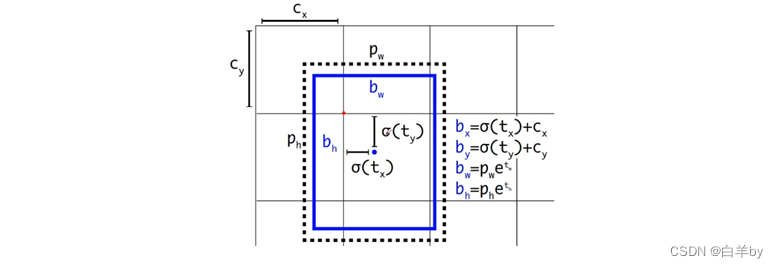
YOLOv3中的anchor机制和YOLOv2是一样的,但是与SSD和Faster RCNN不一样的是,SSD和Faster RCNN预测的有关目标中心点的参数是相对于anchor而言的,但是在YOLOv3中预测的有关目标中心点的参数相对于cell左上角点而言。
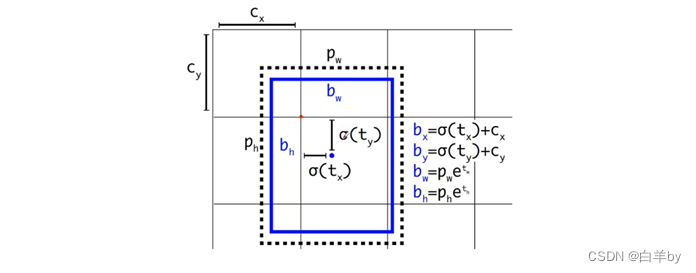
图中虚线对应的矩形框就是anchor,我们只需要关注anchor的宽度P_w和高度P_h两个参数,蓝色矩形框是网络最终预测的目标位置和大小。需要注意的是由于Sigmoid函数结果是0~1之间,所以最终预测的b_x、b_y也是在0和1之间,所以Sigmoid函数将预测的边界框中心点限制当前cell之间,从而加框网络收敛。
正负样本的匹配
针对每一个bounding box 都会分配一个bounding box prior,即针对每一个ground truth 都会分配一个正样本,一张图像中有几个ground truth就有几个正样本,分配原则其实也很简单,就是将与ground truth重合程度最大的bounding box prior作为正样本,如果与ground truth重合程度不是最大的但是又超过了某个阈值的bounding box prior,就直接丢弃,将最后剩下的样本作为负样本。
YOLOv3损失函数
YOLOv3的损失包括三部分:置信度损失、分类损失和定位损失。

置信度损失为二值交叉熵损失
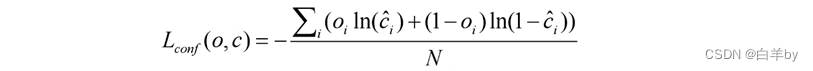
其中o_i表示预测目标边界框与真实目标边界框的IOU,c为预测值,c_hat为c通过Sigmoid函数得到的预测置信度,N为正负样本个数。
类别损失同样采用的是二值交叉熵损失
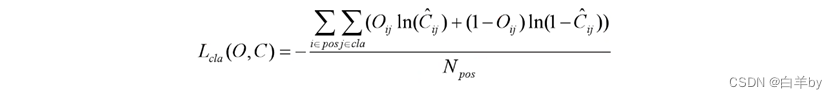
其中o_ij表示预测目标边界框i中是否存在第j类目标,C_ij为预测值,C_ij_hat为C_ij通过Sigmoid函数得到的目标概率,N_pos为正样本个数。
定位损失

YOLOv4
YOLOv4网络结构
- Backbone:CSPDarknet53
- Neck:SPP,PAN
- Head:YOLOv3
优化策略
- Eliminate grid sensitivity
- Mosaic data augmentation
- IoU threshold(match posotive samples)
- Optimizered Anchors
- CIOU
Backbone:CSPDarknet53
YOLOv4使用的CSPDarknet53相比YOLOv3的Darknet53添加了CSP结构,如图

添加CSP可以提高CNN学习的能力,移除计算瓶颈,降低显存的使用。
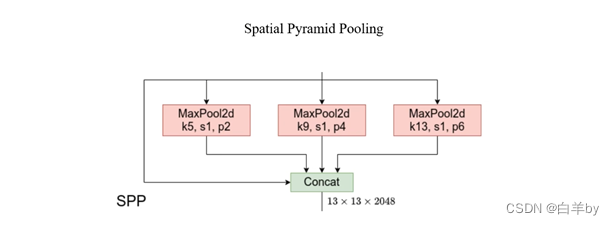
Neck:SPP
SPP模块经输入的特征层依次输入kernel为5x5、9x9和13x13的最大池化下采样层,且stride都是1,通过padding操作后输出尺寸和通道数和输出完全一样,然后将三个最大池化后的输出和原输入进行拼接。
Neck:PAN
(a)中在backbone提取的特征图上构建特征金字塔,即FPN模块,FPN模块将高层的语义信息通过上采样与低层的 语义信息融合,(b)中的过程正好相反,将低层的特征图通过下采样再与高层的特征图融合,而(a)和(b)共同构成了PAN模块。
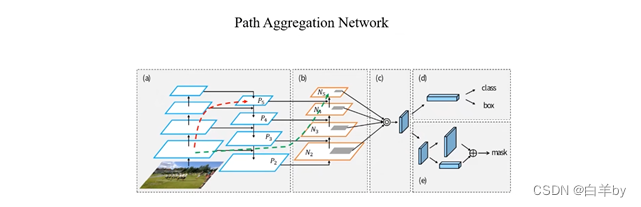
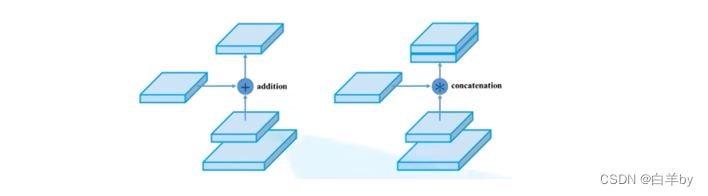
还要注意的是,原始的PAN模块特征图的融合使用的是add策略,在YOLOv4中使用concate策略,将两个特征图在深度方向进行拼接
优化策略—Eliminate grid sensitivity
首先回忆一下YOLOv3如何进行目标边界框预测的,CNN网络计算每个cell中的每个anchor预测目标边界框回归参数以及针对每个类别的score分数,其中sigmoid函数将anchor中心点的位置限制在一个cell内部,这就会面临一个问题,就是如果目标框的中心点在cell的边界时sigmoid函数将不再适用,为了解决这个问题,YOLOv4在原来公式的基础上加了一个缩放因子scale。
YOLOv4改进后的预测目标边界框回归参数公式如下

目前主流的选择scale为2,则公式对应如下
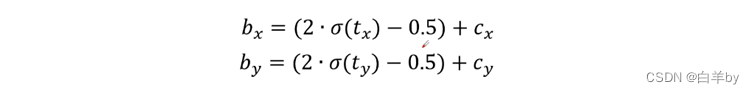
优化策略—Mosaic data augmentation
在输入网络进行训练时,将四张不同的图片按一定的规则拼接在一起,这样在做具有以下优势:
- 增加数据的多样性
- 增加目标个数
- BN能一次性统计多张图片的参数

优化策略—IoU threshold(match posotive samples)
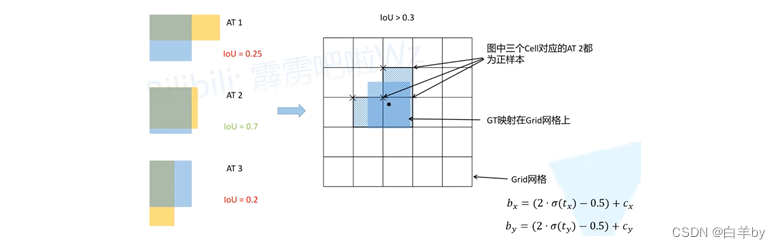
将每一个GT和anchor temple进行匹配,针对每一个检测层都对应3
个不同的模板AT1、AT2和AT3,将每一个GT和anchor左上角对其计算IoU,并将IoU大于阈值的anchor作为正样本。
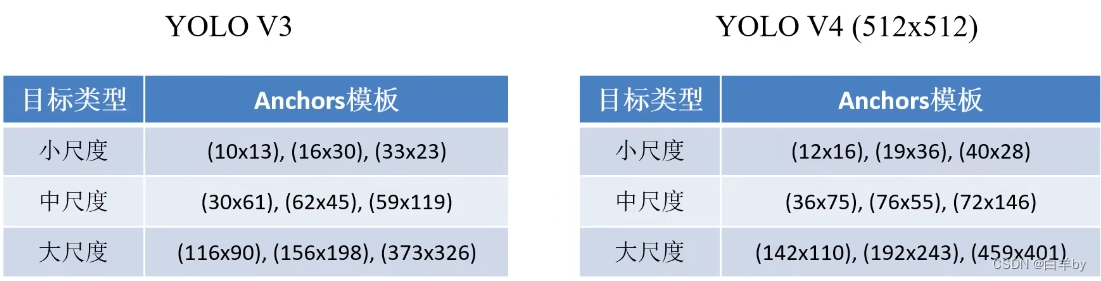
优化策略—Optimizered Anchors
YOLOv4用的YOLOv3不同
优化策略—CIOU

YOLOv5
YOLOv5网络结构
- Backbone: New CSP-Darknet53
- Neck: SPPF, New CSP-PAN
- Head : YOLOv3 Head
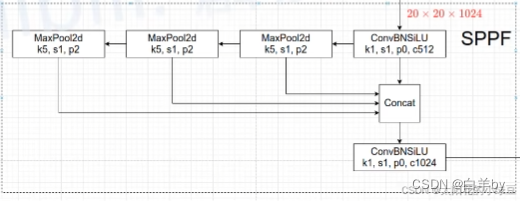
SPPF
SPPF中依次将输入串联通过3个5x5的最大池化层,然后再与书瑞进行拼接,为什么要这么做呢,因为将两个5x5的池化层进行串联等价于使用一个9x9的最大池化,而使用3个5x5的最大池化又等价于一个13x13的最大池化,但是使用SPPF比SPP效率更高。
YOLOv5中的数据增强策略
- Mosaic(图像拼接)
- Copy paste(将不同图像中的目标进行负值和粘贴)
- Random affine(随机仿射变换:旋转、平移等)
- MixUp(将两张图片按一定透明程度混合成一张图片)
- Albumentations(滤波、直方图均衡化以及改变图片质量等等)
- Augment HSV(调整图像色度、透明度和饱和度)
- Random horizontal flip(水平翻转)
YOLOv5训练策略
- Multi-scale training(0.5~1.5x)(多尺度训练)
- AutoAnchor(For training custom data)(重新生成anchor)
- Warmup and Cosine LR scheduler(学习率的调整)
- EMA(Exponential Moving Average)Mixed precision(将学习变量添加一个动量)
- Mixed precision(混合精度训练)
- Evolve hyper-parameters
YOLOv5损失函数
YOLOv5的损失由三部分组成:
- Classes loss,分类损失,采用的是BCE loss(二值交叉熵损失),注意只计算正样本的分类损失。
- objectness loss,obj损失,采用的依然是BCE loss,注意这里的obj指的是网络预测的目标边界框与GT
Box的CIoU。这里计算的是所有样本的obj损失。 - Location loss,定位损失,采用的是CIoU loss,注意只计算正样本的定位损失。
本文参考:https://blog.csdn.net/qq_37541097?type=blog

