
- 1电脑整蛊关机html代码,恶搞关机的脚本小程序 -电脑资料
- 2markdown编辑数学公式整理_markdown 估计
- 3HTML简单音乐播放器_html音乐播放器代码
- 4正则表达式Pattern.DOTALL、(?s)、Pattern.MULTILINE、(?m)、后向引用$1,去除单行注释、去除多行注释、去除空行
- 5android百度导航实现,Android 集成百度地图实现设备定位
- 6[Linux 驱动] -- Linux USB 驱动开发(三)---- 编写USB驱动程序_usb_class_driver
- 7卫星时钟服务器、NTP时钟服务器、GPS北斗网络时钟系统
- 8Mac用户如何安装并配置eclipse,如何使用eclipse_mac. eclipse 怎么添加到应用列表
- 9html+css notes (ongoing 20/4/12)_ongoing超突变
- 10Android 正则表达式,Pattern,Matcher基本使用
零一万物API开放平台出场!通用Chat多模态通通开放,还有200K超长上下文版本...
赞
踩
克雷西 衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
3月,国内外模型公司动作频频。国产大模型独角兽“五小虎”之一零一万物也有诸多新动作。
这不,前脚刚发布高性能向量数据库,零一万物又立马正式发布了自己的API开放平台,
共为开发者提供三个版本的模型:
Yi-34B-Chat-0205:支持通用聊天、问答、对话、写作、翻译等功能。
Yi-34B-Chat-200K:200K上下文,多文档阅读理解、超长知识库构建小能手。
Yi-VL-Plus:多模态模型,支持文本、视觉多模态输入,中文图表体验超过GPT-4V。

去年11月,零一万物就正式开源发布了首款预训练大模型Yi-34B,当时的模型已经能处理200K上下文窗口,约等同于20万字文本。这次开放API平台,在Yi-34B的基础上,有什么新亮点?
要说有什么独特之处,我愿以五个“更”来概括。
分别是覆盖更大的参数量、更强的多模态、更专业的代码/数学推理模型、更快的推理速度、更低的推理成本。
并且!
Yi大模型API开放平台兼容OpenAI的API,可以随心快速丝滑切换。
更多详情,一起来看——
200K上下文窗口+多模态能力
此次API开放,最亮眼的地方一共有两点。
首先是200K的超长上下文窗口,可以一口气处理约30万个中英文字符,相对于读完整本《哈利·波特与魔法石》小说。
在大海捞针测试中,Yi-34B-Chat-200K取得了几乎全绿的成绩,准确率高达99.8%。
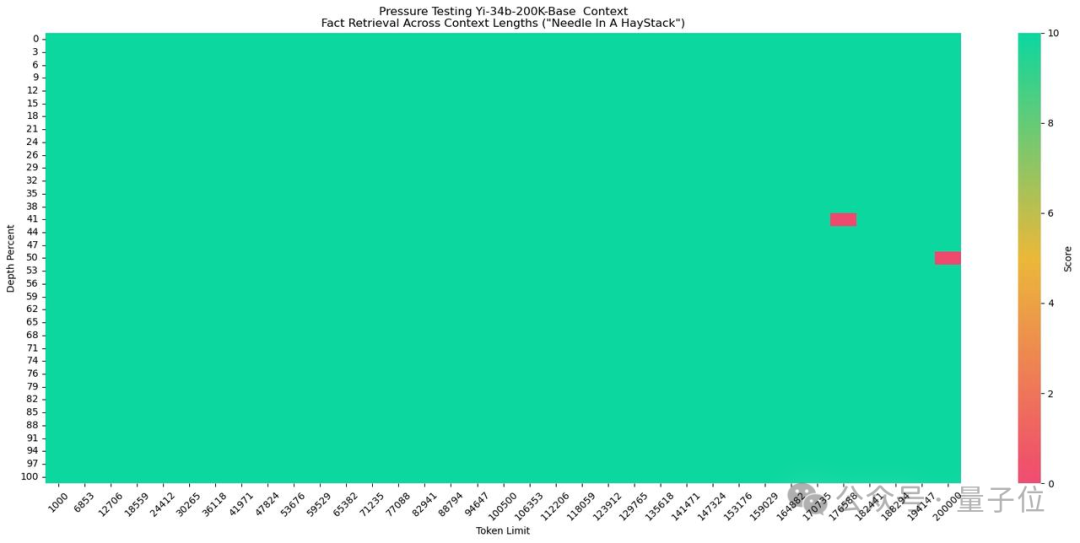
实际测试中,篇幅近两百页、总字数19万的《三体》第一部,Yi很快就能读完并给出总结。

而且细节关注到位,能从故事中提取出主要角色信息和他们的事迹,然后直接用表格的形式呈现在我们面前。
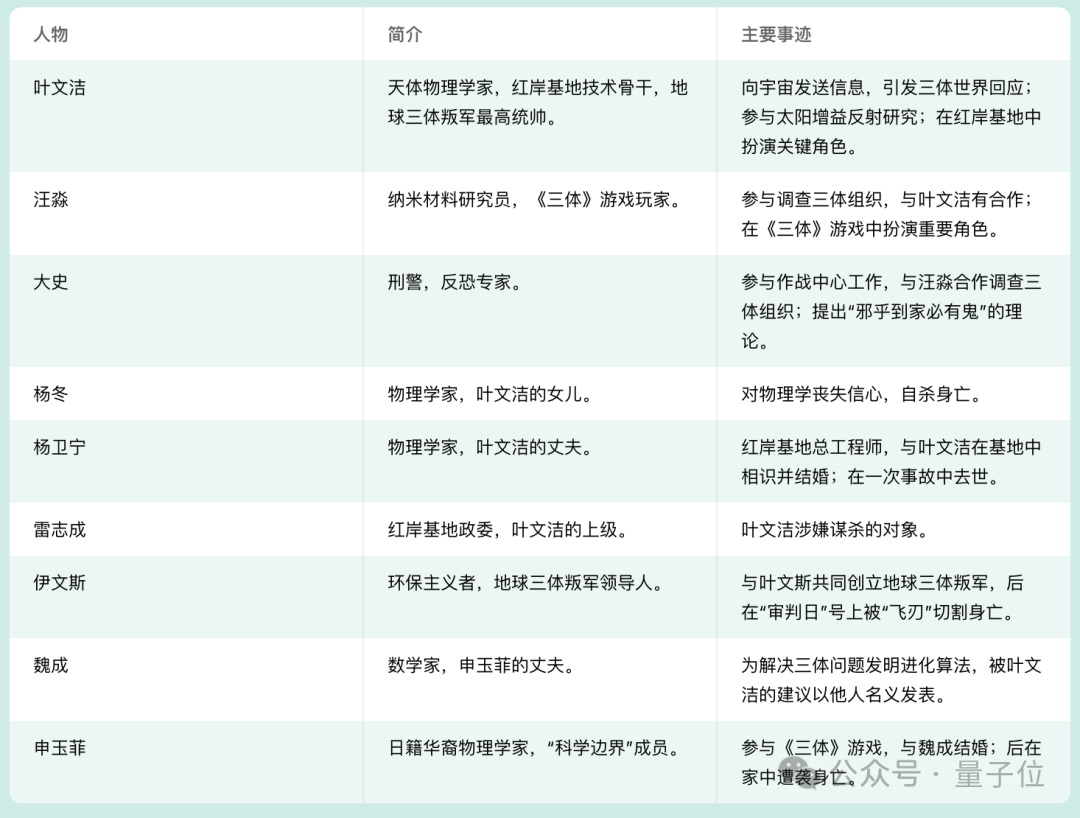
我们又补充追问了十个细节问题,答案分散在整部小说的各个位置,结果Yi全部答对。

另一大亮点,是Yi-VL-Plus强大的多模态能力。
多模态版本中,在保持LLM通用知识、推理等能力的前提下,图片内中文、符号识别能力大幅增强,体验超过了GPT-4V。
而且图片输入分辨率也提高到了1024×1024分辨率,并专门针对图表、截屏等生产力场景进行了优化。
比如下面这张图来自一篇文献综述,列举了课题相关论文中被引量最高的10篇。

Yi-VL-Plus准确地找到了目标文献,并准确识别出了文章标题,遇到“嗪”这种不常见的专业文字也没掉链子。
再看看GPT-4V这边,则是主打一个已读乱回,给出的文章标题不知道来自何处。

而除了识读图表和文字,Yi-VL-Plus还支持学习专业知识并立即用于图像的解读。
比如早期体验过的开发者教给模型一些心理学知识后,Yi-VL-Plus就能根据孩子的铅笔画展开一些基本的分析。
并且,模型给出的分析获得了专业人士的认可,给出了“较准确”的评价。
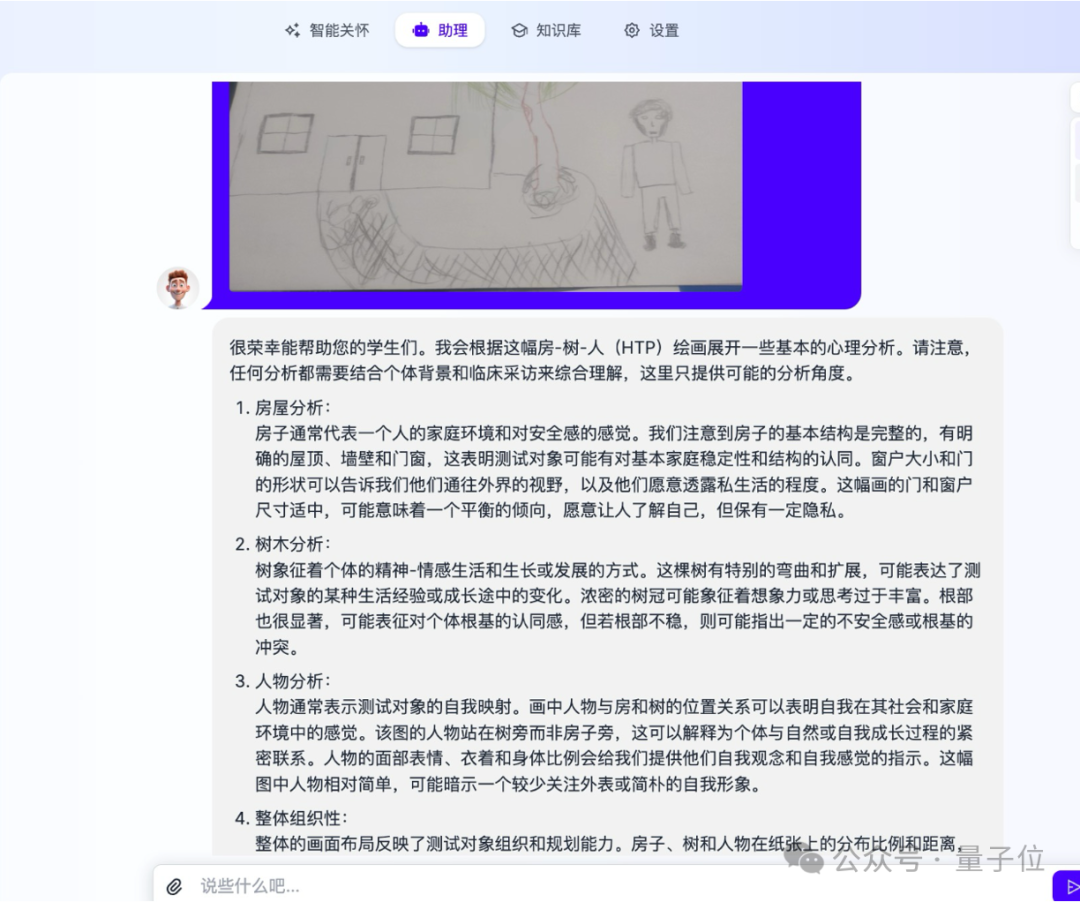
△开发者星云爱店CTO大董提供的测试资料,文图数据均脱敏
总之,凭借强大的长文本和多模态处理能力,无论是在to B还是to C场景,Yi都能构建出高效的大模型应用。
举个例子
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

