
【论文精读1】MemSum: 基于历史决策的多步长文本抽取式摘要方法_memsum: extractive summarization of long documents
赞
踩
前言
论文分享 来自2022ACL的长文本抽取式摘要方法论文,作者来自蘇黎世聯邦理工學院 (ETH Zürich),引用数13
MemSum: Extractive Summarization of Long Documents Using Multi-Step Episodic Markov Decision Processes 代码地址MemSum
自动文本摘要抽取可以分为抽取式(extractive)和抽象性式(abstractive),抽取式方法将摘要抽取任务看成是一个二分类任务,给定 N N N个句子,从中选择 M ( M < = N ) M(M<=N) M(M<=N)个句子作为文本的摘要。
抽取式摘要可以分为两个步骤,1)句子打分,2)句子选择。在句子选择阶段,可以通过3种方式选择句子,i)根据分数给句子标签为0和1,选择标签为1的句子,ii)将句子按照分数进行排序,选择Top-k的句子作为摘要,iii)以剩余句子归一化后的分数作为可能性分布进行依次不放回采样
论文表明,上述传统方法计算句子分数的时候,通常没有根据当前已抽取的句子摘要进行更新,丢失了抽取历史知识(the knowledge of extraction history)。论文指出,现有抽取模型不根据历史抽取信息会更倾向于将一些可能重复的高ROUGE指标的句子重复选择,最终造成整体的指标下降。
论文将摘要抽取看作是多步情景马尔可夫决策过程(multi-step episodic Markov Decision Process),其与single-step的区别在于是否在每一步会更新状态,single-step根据输入一次输出所有句子分数,而multi-step在每一个时间节点,根据历史的抽取信息,更新剩余其他句子的分数。在NeuSum论文中,已经提出使用历史抽取信息,但是只能抽取固定数量的句子,这可能是次优的,论文在此基础上增加了终止机制(stop mechanism),可以抽取任意长度的句子,同时增加了对历史抽取信息的量化评判。
模型
模型的整体框架如下
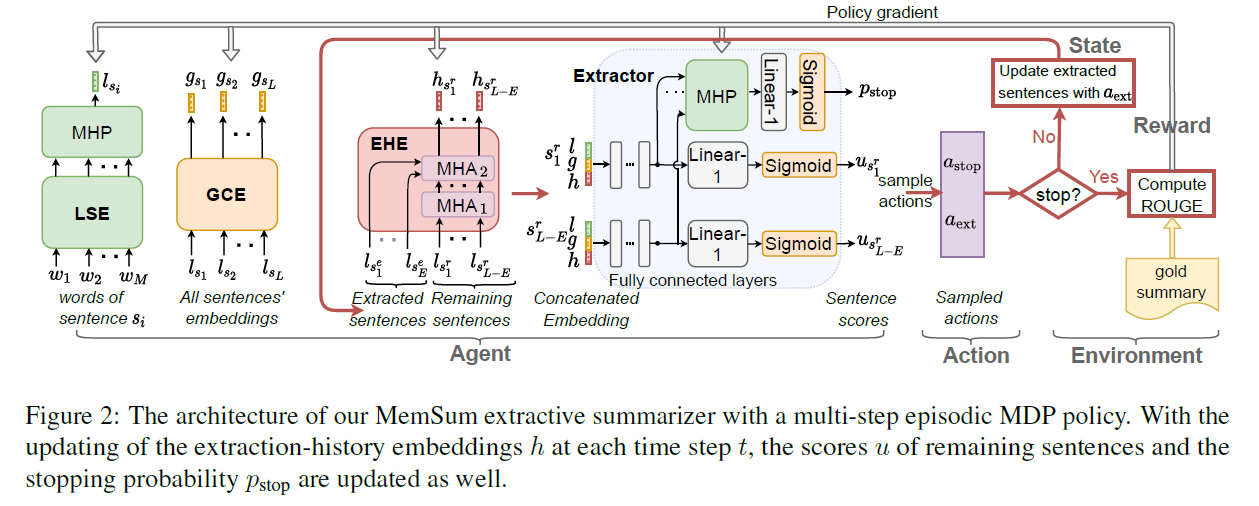
其主要由3个部分组成,LSE(局部句子编码器),GCE(全局上下文编码器)和EHE(抽取历史编码器),LSE的输出为GCE的输入,GCE的输出为EHE的输入,EHE的输出为剩余句子的隐层向量,其和GCE的输出以及LSE的输出进行级联后分别输入MHP(multi-head pooling network)和全连接层得到停止概率和句子得分,根据停止概率与停止阈值的比较,选择是否将得分最高的句子作为抽取句子,在停止概率大于停止阈值后,将从第一次抽取到最后一次抽取的累计奖励作为指标对LSE,GCE,EHE和MHP网络进行更新。
论文优化的目标为最大化目标函数,我们希望
R
0
R_0
R0越大越好
J
(
θ
)
=
E
π
θ
[
R
0
]
J(\theta)=\mathbb{E}_{\pi_\theta}[R_0]
J(θ)=Eπθ[R0]
每一步的reward计算公式由ROUGE-1,ROUGE-2和ROUGE-L的均值构成
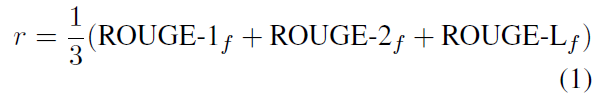
从第一步到终止的reward计算公式为
R
t
=
∑
k
=
t
+
1
T
r
k
R_t=\sum_{k=t+1}^T r_k
Rt=k=t+1∑Trk
根据强化学习算法,梯度下降的公式可以表达为
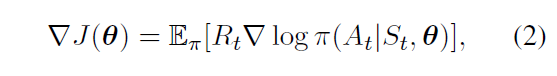
其中
π
(
A
t
∣
S
t
,
θ
)
\pi(A_t|S_t,\theta)
π(At∣St,θ)代表在时间t下,给定参数
θ
\theta
θ和状态
S
t
S_t
St的情况下,策略
π
\pi
π给出的行为
A
t
A_t
At的可能性,其可以表示为
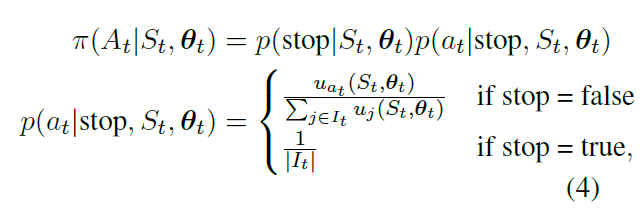
策略
π
\pi
π的行为可能性为当前步伐下停止的可能性乘以行为的可能性,行为的可能性有两种情况,第一当决策为终止时,行为的可能性为剩余所有句子的平均可能性,当决策不为终止时,行为的可能性为归一后的概率
在给定学习率的情况下,参数更新如下
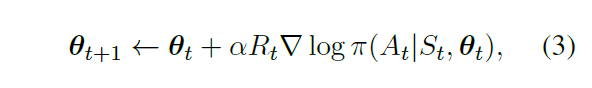
LSE模块和GCE模块均为LSTM结构,EHE为多层transformer解码器结构,目的为将历史抽取信息融入到剩余未抽取的句子中,根据历史抽取信息进行重新打分,这里我有一个疑惑,论文是如何精准控制模型根据历史信息,不去抽取冗余句子,当然结果表明对于减少冗余的效果很好。
整体的实现流程伪代码:

对于给定文本和摘要,首先采用LSE编码局部句子向量,然后根据局部句子向量采用GCE编码全局句子向量,在文本中采样高ROUGE的场景,这个场景存在多个,每个场景选择的句子可能是不同的,但是ROUGE的数值是差不多的,其中
S
t
S_t
St代表句子3种编码的级联,
s
a
t
s_{a_t}
sat代表选择抽取的句子
a
t
a_t
at,
A
s
t
o
p
A_stop
Astop代表停止,r代表最终的ROUGE,在每一步,EHE和Extractor输出根据历史抽取信息进行调整的剩余句子的得分,根据得分按照公式4计算行为可能性,然后进行梯度下降。为了获得更加简短的摘要,最后的奖励乘以了长度系数
1
/
(
T
+
1
)
1/(T+1)
1/(T+1),即
R
t
≡
r
T
+
1
R_t\equiv \frac{r}{T+1}
Rt≡T+1r
实验
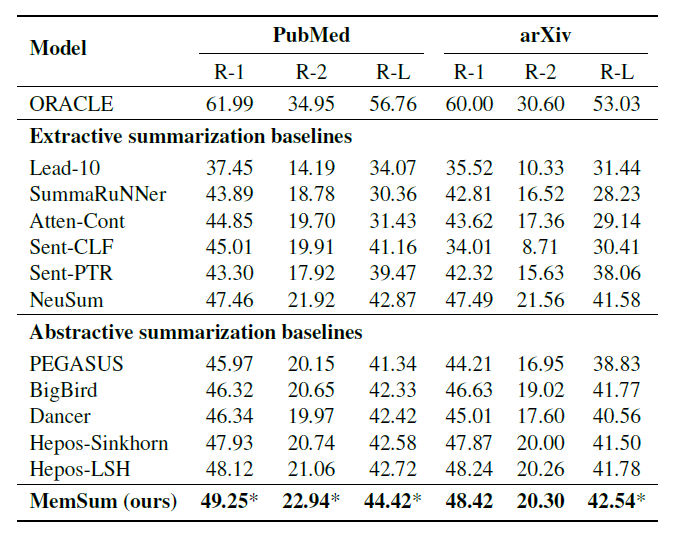
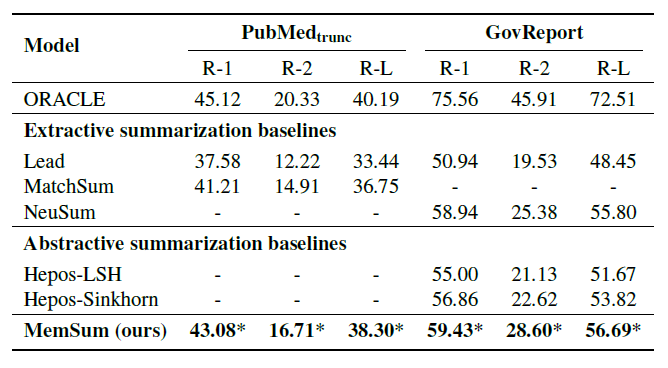
作者给出了在4个数据集,PubMed, arXiv,
P
u
b
M
e
d
t
r
u
n
c
PubMed_trunc
PubMedtrunc和Gov Report上的实验结果,可以发现在PubMed,Gov Report和arXiv数据集上,MemSum都要比最好的摘要抽取方法NeuSum和摘要生成方法Hepos-LSH要好上1-2个点,同时可以看到Gov Report的GOUGE分数要明显高于其他数据集,这归因于政府数据的摘要为了保证其忠诚性,很难用其他摘要性语句进行概括,大部分保留了其原文的原因,从下方例子可以看出,真实摘要和抽取式摘要在文字重叠部分要明显多于摘要式方法

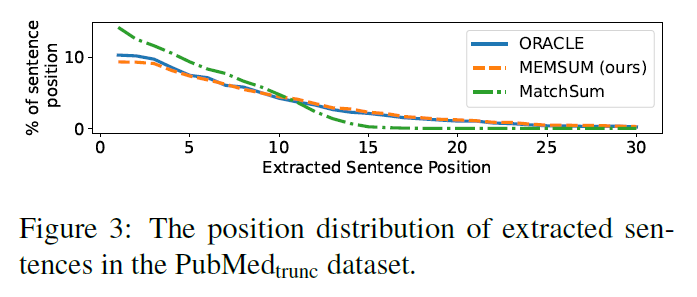
作者还给出了MatchSUm,ORACLE和MEMSUM在
P
u
b
M
e
d
t
r
u
n
c
PubMed_trunc
PubMedtrunc数据集上抽取的句子位置的分布图,ORACLE是采用贪婪算法抽取得到的最优ROUGE分数的摘要,MatchSUM是使用Bert预训练模型的抽取式方法,可以发现MEMSUM的曲线与ORACLE很像,MatchSum的曲线在句子15后为0,归因于Bert只能编码前512个字符
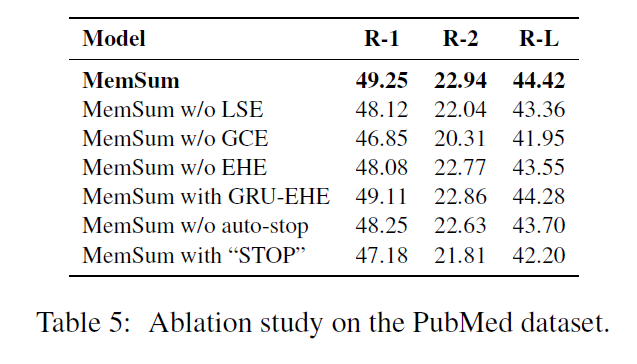
作者做了LSE,GCE和EHE模块的消融实验,并且增加了使用GRU的EHE模块,不使用stop停止,增加“STOP”字段,抽取到“STOP”就停止的方法,可以发现,GCE上下文模块的重要性要高于LSE,作者指出这与Extractive Summarization of Long Documents by Combining Global and Local Context的结论是相反的,EHE有效但是与GRU还是attention结构没很大的关系,stop是有效的,但是如果增加特殊的“STOP”字段则会影响模型过早的停止抽取
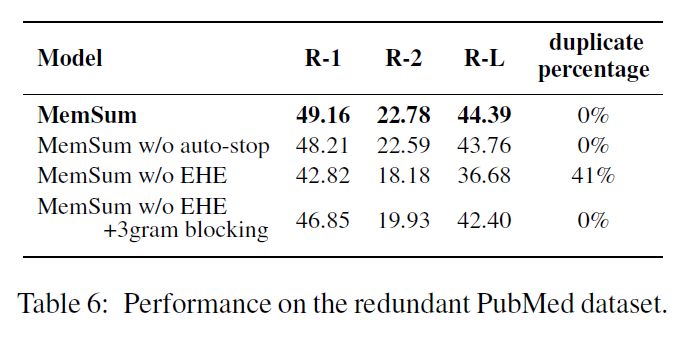
为了证明历史抽取信息能够避免重复抽取的假设,作者构建了一个冗余句子数据集,对PubMed数据集的每一个句子进行重复,例如原始文章为
s
1
,
s
2
,
.
.
.
,
s
n
s_1,s_2,...,s_n
s1,s2,...,sn,构建的冗余句子数据集为
s
1
,
s
1
,
s
2
,
s
2
,
.
.
.
,
s
n
,
s
n
s_1,s_1,s_2,s_2,...,s_n,s_n
s1,s1,s2,s2,...,sn,sn,摘要保持不变,通过在这种冗余句子数据集上进行训练,没有历史抽取信息的模型重复率达到了41%,说明历史抽取信息能够有效的避免历史抽取的冗余,这种完全重复的方法简单有效的可以证明有去冗余的效果。采用Text Summarization with Pretrained Encoders中判断当前句子是否有3-gram重复的句子将其跳过的策略可以有效地避免冗余,但是其ROUGE score远远低于EHE模块
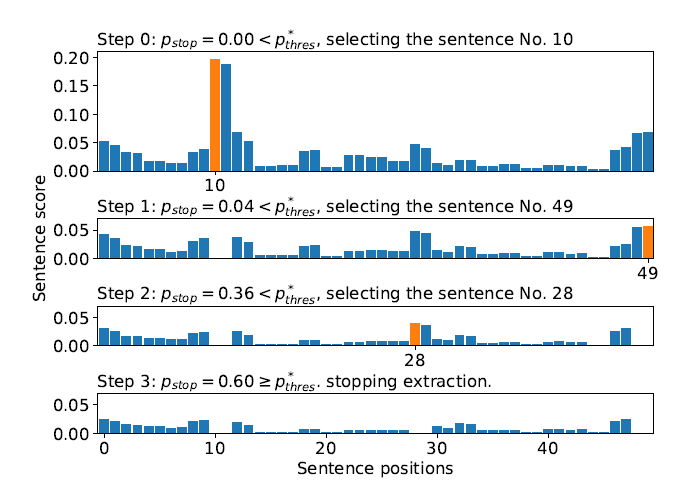
作者通过分步操作来解释了为什么MemSum可以去冗余,在第0步的时候,Memsum抽取了分数最高的句子10,在第1步的时候,冗余句子11的分数降为了0,后续的48,49和28,29都是同样的现象,说明了MemSum避免冗余比较了剩余句子和已抽取句子的相似度而非简单的记忆位置
作者在附录还给出了摘要抽取时间,最优stop阈值的选择方法,如何构建高GOUGE场景的方法等
总结与思考
作者给出了一种基于历史抽取信息的多步场景长文本抽取式摘要方法,不使用预训练模型,可以有效的应用于实际场景中,有几个点可以思考,1、作者认为去冗余和决定是否停止与位置信息的相关性很小,几乎可以忽略。2、完全重复的句子比较是否过于简单,3、作者给出的可重复性方法值得借鉴

