
- 1鸿蒙HarmonyOS实战-Stage模型(概述和组件配置)_鸿蒙 stage模式
- 2stm32学习——串口通信中的奇偶校验位
- 3215. 数组中的第K个最大元素 Python_数组中的第k个最大元素 知乎 python
- 4【学习笔记】(尾附:read_excel()参数表)解决:TypeError: read_excel() got an unexpected keyword argument ‘index‘_read_excel() got an unexpected keyword argument 'i
- 5AI应用新时代的起点,亚马逊云科技加速大模型应用_亚马逊在ai上的应用
- 6huggingface的tokenizer解读_oserror: can't load tokenizer for 'lmsys/vicuna-7b
- 7基于matlab模拟相关干涉仪测向方法_干涉仪测向算法matlab
- 8Android 13.0 屏蔽FallbackHome机制去掉android正在启动直接进入默认Launcher功能实现_为什么不编译launcher3 就无法fallbackhome
- 9华为畅享9PlusLog_istopisfullscreen mfocusedwindow or attrs is null
- 10PHP使用DOM XML操作XML[总结]
腾讯云ES RAG最佳实践:向量+文本混合搜索的相关性调优
赞
踩
| 导语 腾讯云ES近期上线的8.8.1版本,提供了强大的云端AI增强能力,支持在统一技术栈中完成文本+向量的混合搜索,实现自然语言处理以及与大模型的集成,本文将从向量检索的优势与局限性介绍出发,说明混合搜索的原理、优势及其必要性,并通过效果演示为大家呈现腾讯云ES混合搜索的强大能力。
引言
我们在上一篇文章《腾讯云ES RAG最佳实践:百行代码轻松实现ES帮助文档的智能问答》中给大家介绍了如何通过一个完整的搜索解决方案来快速实现 RAG ,其重点落在效率上 —— 完整而便捷的解决方案套件,使我们整个RAG的构建和上线过程事半功倍。而本文,我们则将重点落在搜索效果上,如何适配各种情况(不同的用户搜索习惯以及可能的缺陷数据),并达到最优效果。
就像之前说的,真正地理解什么是RAG并不容易,实现RAG就更难。现状是大多数时候用户会简单地把实现RAG理解为在企业中加入一个向量数据库。但RAG是一个复杂的概念,它不仅仅是一个向量数据库,实现RAG需要对业务场景有深入的理解,并且需要进行大量的数据处理和算法优化,用户的行为的理解和反馈也是最终效果达成的重要关键。因此,我们需要的更多的是一个混合搜索解决方案,而非仅仅向量搜索。
向量检索的优势和局限性
我们知道,向量检索是一种基于向量空间模型的检索方法,它可以将文本转换为数学上的向量,然后通过计算向量之间的相似度,来实现文本的匹配和检索。向量检索的原理和流程大致如下:
首先,需要对文本进行预处理,比如主干提取,chunk,map等,以便将文本转化为适合词嵌入模型处理的大小,并将分块与原文档建立连接关系。
然后,需要对文本进行向量化,即将分块文本表示为一个高维的数值向量,这可以通过一些词嵌入模型来实现,比如Word2Vec、GloVe、BERT等。
最后,需要对查询语句进行向量化,即将查询语句表示为一个高维的数值向量,这可以通过与文档相同的文档嵌入模型来实现,或者通过一些特殊的查询嵌入模型来实现,比如Q-BERT、Q-Transformer等。
在得到了文档和查询语句的向量表示后,就可以通过计算它们之间的相似度,来实现文本的匹配和检索,这可以通过一些相似度度量来实现,比如余弦相似度、欧氏距离、曼哈顿距离等。注意,这里可以是和多个向量字段进行相似性计算,最终合并结果,并且一个文档可能会有多个分块,分块的向量相似性得分需要加权以比较文档的总体得分。
一、向量搜索的优势
它可以处理自然语言中的复杂和模糊的表达方式,例如同义词,近义词,语言变体等。
它可以捕捉文本之间的语义关系,例如上下位关系,因果关系,相似关系等。
它可以支持多语言和跨语言的搜索,即用一种语言查询另一种语言的文档。
它可以支持多模态和跨模态的搜索,即用文本查询图像或视频等非文本类型的文档。
二、向量搜索的局限性
向量搜索在自然语言中的理解能力来自于深度学习模型,而非向量索引和向量相似性计算。
需要大量的计算资源和存储空间来训练和部署深度学习模型。
需要大量的标注数据来训练深度学习模型。如果数据质量不高或不足以覆盖所有可能的场景,模型可能无法泛化到新的数据上。
需要定期更新深度学习模型以适应数据和用户行为的变化。如果模型过时或不准确,可能会影响搜索结果的质量和用户满意度。
它需要考虑向量的维度和稠密程度,以选择合适的索引和查询方法。如果向量维度过高或过低,或者向量分布不均匀,可能会影响搜索效率和准确度。
向量搜索的实施和维护成本较高,涉及大量的计算资源和专业知识。对于一些资源有限的应用场景,这可能不是一个可行的选择。
在短文本搜索的场景中,向量搜索可能会面临语义理解的挑战。虽然向量搜索可以对查询进行语义分析,但当涉及到短文本时,语义的表示和理解可能不够准确,导致结果的相关性不佳。
向量搜索以词嵌入的方式表示数据,在搜索的透明性和可解释性上对人类有天然的障碍,人类即无法轻易理解两个嵌入到底第为何相似,也难以知道应该具体如何修改特征,以提升相关性。
embedding模型的修改、调优、再训练对于大多数的开发团队来说,门槛太高,ROI也充满了不确定性。
一句话总结,就是向量搜索看起来很好,但是实现起来过于复杂,并且向量搜索要能实现准确的搜索,对于用户也有要求。
三、向量搜索无法达成效果的案例
以我们在上篇文章提到的《腾讯云ES RAG最佳实践:百行代码轻松实现ES帮助文档的智能问答》作为例子。我们看看如果只使用向量搜索在某些场景中会获得什么样的反效果:当我们知道腾讯云有提供特有的高性价比机型,星星海机型时,我们想知道腾讯云ES有没有采用这种机型。但用户又不想输入长长的一串句子时,如果我们只搜索 “星星海”,我们会看到向量搜索无法找到正确的结果:
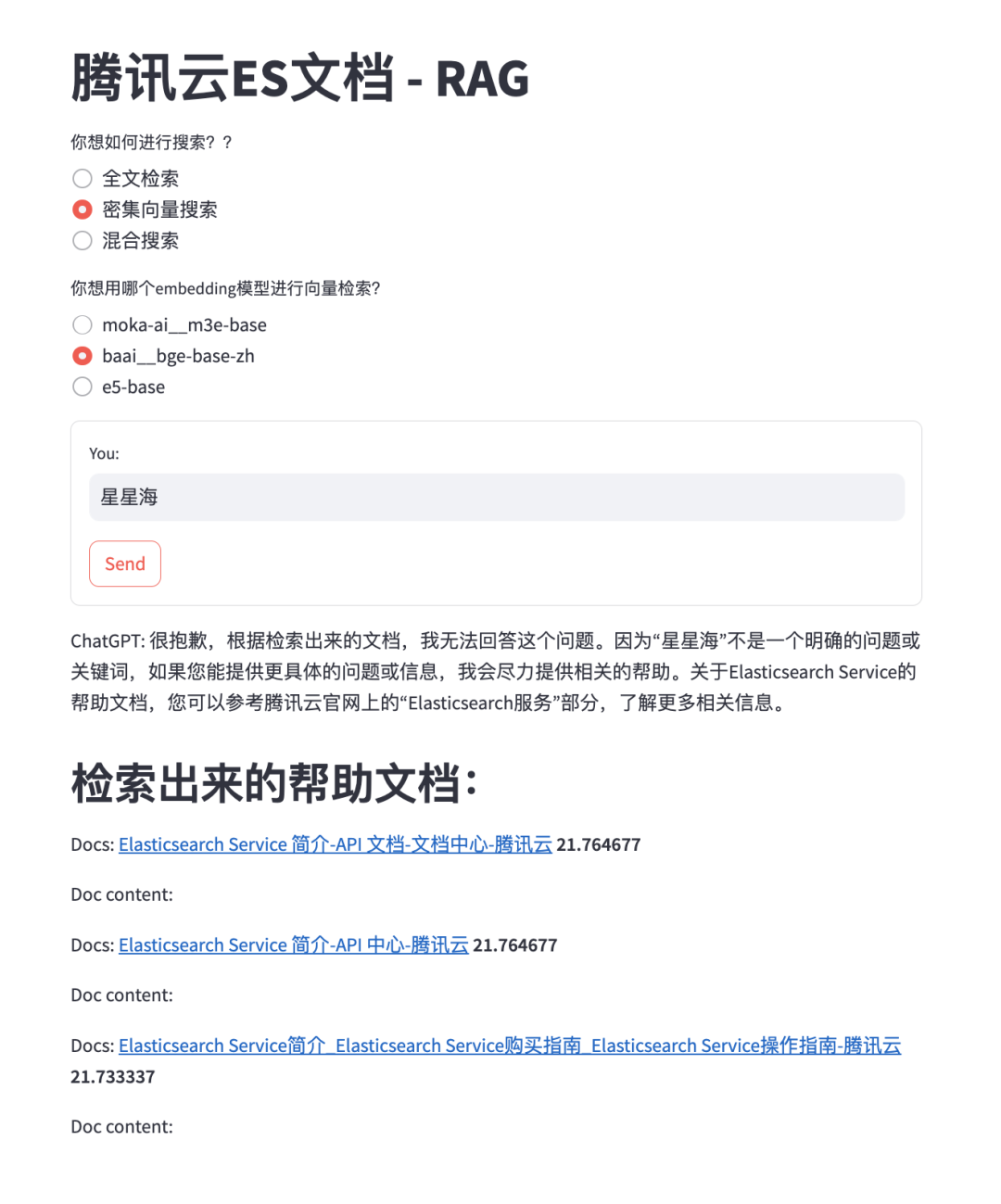
图一
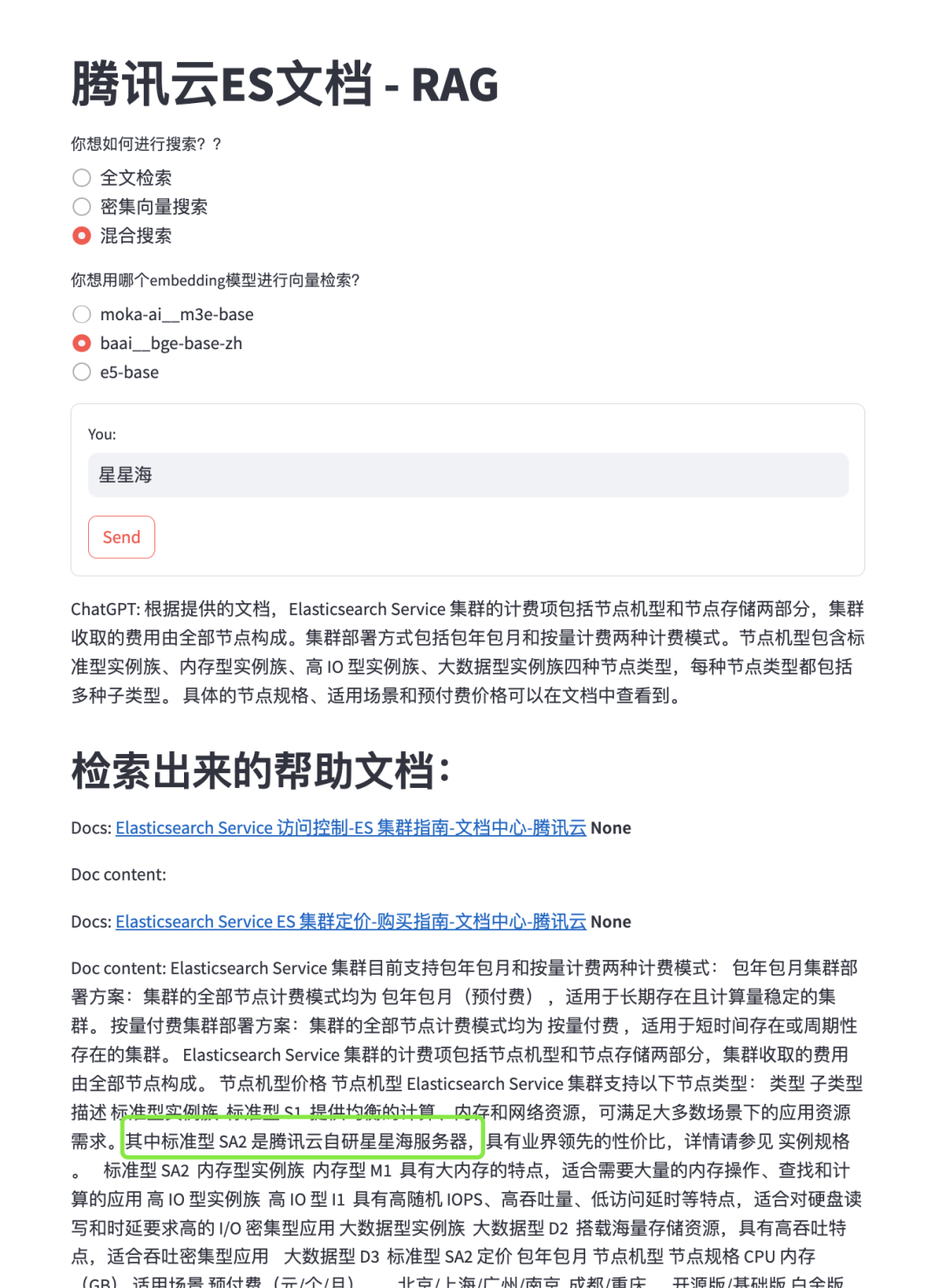
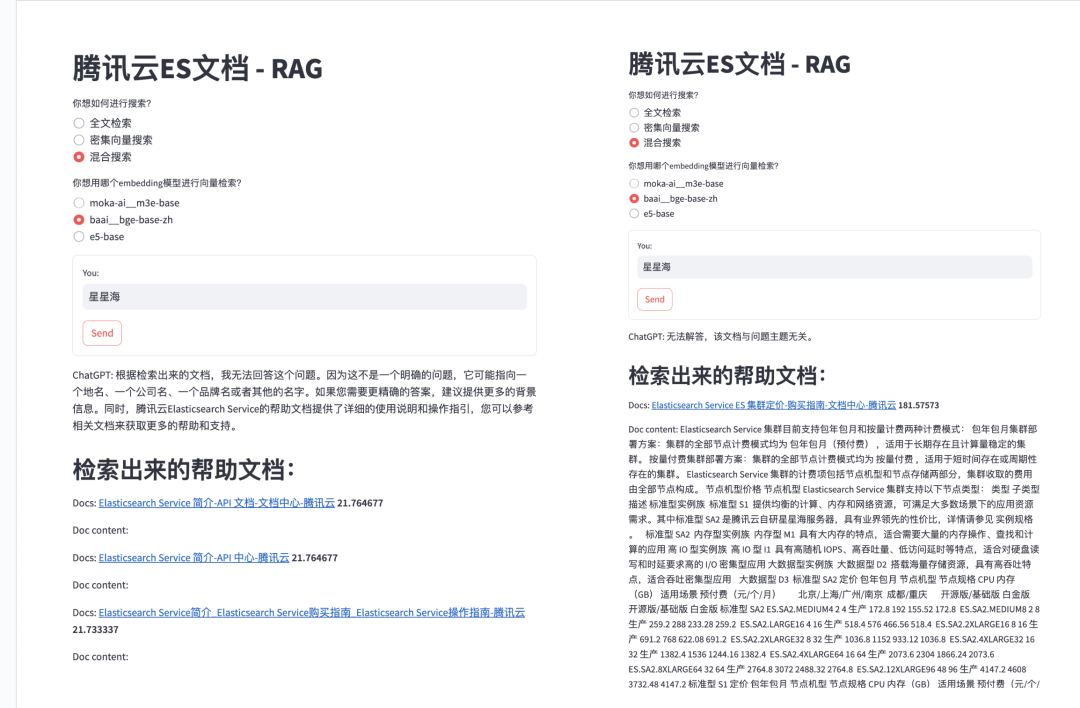
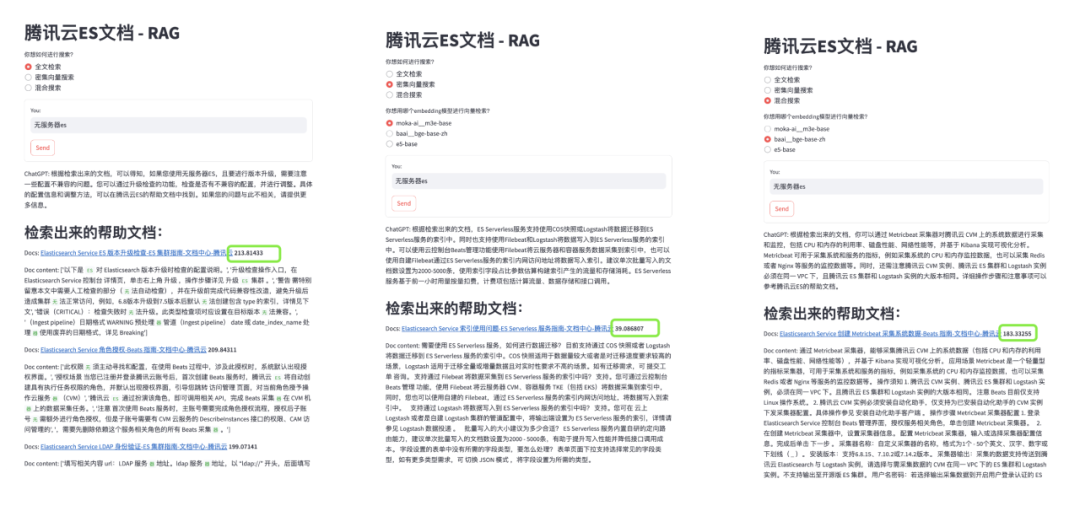
这是因为向量检索是基于词向量的相似度计算,而词向量是通过大量的文本数据训练出来的,它们往往包含了一些语义和语境的信息。如果查询语句太短,比如只有一个ID、一个哈希码或者一个产品名称,那么它们的词向量可能无法反映出它们的真实含义,也无法和其他相关的文档进行有效的匹配。这样就会导致向量检索的结果不准确,甚至出现一些完全不相关的内容。类似的,如果我们查询“8XLARGE64”,“99.9%”,这样的一些关键字时,向量搜索会得出一些毫不相干的内容,以至于让背后的大模型毫无用武之地,甚至可能被误导,而在这方面,全文检索则可以轻松胜任:

图二
为了解决这个问题,我们可以采用一些方法,比如:
增加查询语句的长度,比如在ID、哈希码或产品名称后面加上一些描述性的词语,或者使用一些常见的问题作为查询语句,这样可以增加查询语句的语义信息,提高向量检索的效果。
使用一些特殊的符号或标记,比如在ID、哈希码或产品名称前后加上双引号,或者使用一些特定的字段名,这样可以告诉向量检索系统,这些词语是需要精确匹配的,而不是基于相似度的。
结合关键词检索,比如在向量检索的结果中,再使用关键词检索的方法,对查询语句和文档进行文本匹配和过滤,这样可以排除一些不相关的内容,提高检索的准确性。
这些方法都可以在一定程度上改善向量检索在处理简短的查询语句时的问题,但是它们也有一些缺点,比如:
增加查询语句的长度,可能会增加用户的输入成本,而且用户可能不知道如何扩展查询语句,或者扩展后的查询语句可能不符合用户的真实意图。
使用特殊的符号或标记,可能会增加用户的学习成本,而且用户可能不熟悉这些符号或标记的用法,或者忘记使用它们,导致检索效果不佳。
结合关键词检索,可能会降低检索的效率,而且关键词检索也有一些局限性,比如无法处理语义相似但文本不同的情况,或者无法处理模糊、错别字等情况。
因此,我们需要一种更好的方法,来解决向量检索在处理简短的查询语句时的问题,这就是混合搜索的优势所在。混合搜索可以结合向量检索和关键词检索的优点,实现更快速、更精准、更多样的检索结果。在下一部分,我们将详细介绍混合搜索的原理和优势。
混合搜索的原理和优势
混合搜索是一种结合向量检索和关键词检索的检索方法,它可以利用向量检索的高效性和关键词检索的灵活性,实现更快速、更精准、更多样的检索结果。混合搜索的原理和优势如下:
混合搜索的原理是,首先使用双路召回的方式对用户的查询进行检索。分别对查询语句和文档进行向量化和相似度计算以及基于分词的全文检索。两个查询并行执行,而返回的结果,再根据特定的逻辑进行合并和排序(比如加权平均、排序融合等),最终,得到一个最终的检索结果集合。
混合搜索的优势是,它可以克服向量检索和关键词检索各自的局限性,实现以下几个方面的提升:
更精准的检索结果。混合搜索可以同时利用关键词检索和向量搜索对数据进行查询,提高检索的准确性和可信度。
更多样的检索结果。混合搜索可以利用向量检索的多样性,返回多种不同的检索结果,而不是只返回一种最匹配的结果,这可以提供更多的选择和信息,满足不同的用户查询需求和偏好。
更复杂的查询需求。混合搜索可以利用关键词检索的逻辑运算、排序、过滤等功能,实现更复杂的查询需求,比如包含多个条件、多个字段、多个排序规则等的查询,这可以提高检索的功能和灵活性。
更可解释的检索结果。混合搜索可以利用关键词检索的文本匹配和高亮显示,实现更可解释的检索结果,比如显示查询语句和文档的匹配程度、匹配位置、匹配内容等,这可以提高用户对检索结果的理解和满意度。
图三
一、实现混合搜索时需要考虑的因素
要做好混合搜索,在项目评估的时候需要注意以下方面:
更多的系统资源和设计成本。混合搜索需要同时使用向量检索和关键词检索的方法,这会增加系统的资源消耗和复杂度,也会增加系统的设计和维护的成本和难度。
一些向量检索和关键词检索的不一致性和冲突性。混合搜索需要对向量检索和关键词检索的结果进行合并和排序,这可能会出现一些不一致性和冲突性,比如两种检索方式返回的结果不同,或者两种检索方式的相似度或匹配度不同,或者两种检索方式的排序规则不同,这可能会影响检索结果的质量和可信度。
有效的过滤,可以使得搜索更加高效。
二、按需动态且灵活的选择搜索方式
而使用 腾讯云 ES,会给我们的用户提供更多的灵活性。通过在单一接口中,随时按需地使用全文检索,向量检索,混合检索,做到 “按需使用”。比如,通过如下函数的定义,我们可以随时根据动态条件确定如何进行搜索,而无需进行代码的改动:
- # Search ElasticSearch index and return body and URL of the result
- def search(es, embedding_model, query_text, search_mode):
- source_fields = ["body_content", "url", "title"]
- query = None
- knn = []
- highlight = None
- rank = None
- if search_mode in ["全文检索","混合搜索"]:
- query = {
- "multi_match": {
- "query": query_text,
- "fields": ["body_content^2","title","headings"],
- "boost": 1,
- "type": "most_fields",
- "analyzer": "ik_max_word"
- }
- }
- if search_mode in ["密集向量搜索", "混合搜索"]:
- knn = [{
- "field": "ml.inference.headings_embeddings.predicted_value",
- "query_vector_builder": {
- "text_embedding": {
- "model_id": embedding_model,
- "model_text": query_text
- }
- },
- "k": 5,
- "num_candidates": 10,
- "boost": 24
- }, {
- "field": "ml.inference.body_content_embeddings.predicted_value",
- "query_vector_builder": {
- "text_embedding": {
- "model_id": embedding_model,
- "model_text": query_text
- }
- },
- "k": 5,
- "num_candidates": 10,
- "boost": 24
- },
- ]
- if search_mode == "全文检索":
- highlight= {
- "pre_tags": ["`"],
- "post_tags": ["`"],
- "fields": {
- "body_content": {}
- }
- }
- if search_mode == "混合搜索":
- rank = {
- "rrf":{
- "window_size": 5,
- "rank_constant": 2
- }
- }
- resp = es.search(
- index="search-tencent-es-doc",
- fields=source_fields,
- query=query,
- knn=knn,
- highlight = highlight,
- rank = rank,
- size=3,
- source=False)
- return resp

图四
三、对多路召回的结果进行有效的组合和排序
而当向量检索和关键词检索的结果出现不一致和冲突时,腾讯云ES也提供了多种手段方便我们对结果进行调试。目前,ES提供了比如:线性加权总和和基于结果倒数的融合排序(RRF)两种方式。这两种方式均可以在函数中方便修改,如上面提供的代码样例中:
线性加权总和:query: "boost":1 ; knn: "boost": 24
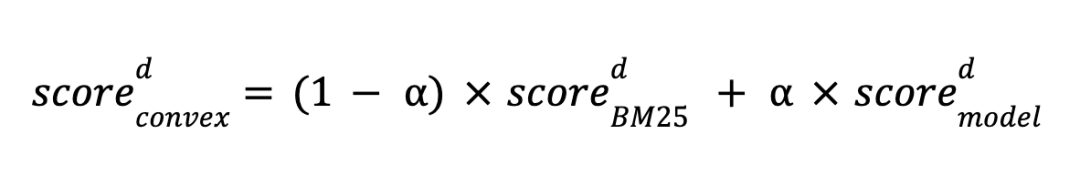
RRF:rank={"rrf":{"window_size":5,"rank_constant":2}}
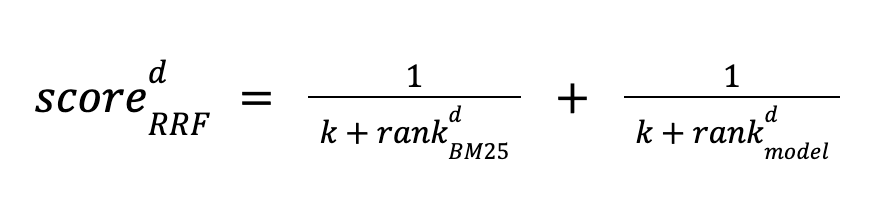
当我们在使用的过程中发现全文检索的检索结果更重要的时候,我们可以适当的调整参数,以下是query: "boost":1与query: "boost":24 的区别:
图五
当然,通过权重打分的调整并不是银弹。很多时候,因为相关性打分方式的不同,不同的搜索方式会产生区别很大的相关性分数,单一的权重很难照顾各种场景,因为提升了全文检索的权重,使得我们无法回答语义检索相关的问题:
图六
因此,我们还提供一种无需根据相关性打分而进行结果有效融合和排序的方式 —— /RRF/。在使用了RRF之后,结果不再包含相关性的得分,而是根据多路召回中文档的排名进行融合:

图七
四、对搜索条件进行过滤
除了排序之外,过滤也是混合搜索或者向量检索中一个非常重要的能力,排除一些不符合条件的文档,既能够让我们的查询更高效,也能够让最终的结果更准确。而 ES 相比其他的数据库,更容易实现这一点,具体原因参见《Elasticsearch 中的向量搜索:设计背后的基本原理》一文。比如,通过定义一个非空字符串的过滤器(这里需要注意的是,ES 的企业搜索功能,在创建索引的时候为每个重要的字段创建了各种调优所需的字段类型,使得我们能够在上面进行过滤,比如这里的 body_content.enum ,就是应用自动创建的 keyword 类型):
我们可以将向量搜索时可能匹配上的异常文档(比如这里的 body_content为空字符串的文档)给过滤掉:
- if search_mode in ["密集向量搜索", "混合搜索"]:
- knn = [{
- "field": "ml.inference.headings_embeddings.predicted_value",
- "query_vector_builder": {
- "text_embedding": {
- "model_id": embedding_model,
- "model_text": query_text
- }
- },
- "k": 5,
- "num_candidates": 10,
- "boost": 24,
- "filter": body_content_filter
- }, {
- "field": "ml.inference.body_content_embeddings.predicted_value",
- "query_vector_builder": {
- "text_embedding": {
- "model_id": embedding_model,
- "model_text": query_text
- }
- },
- "k": 5,
- "num_candidates": 10,
- "boost": 24,
- "filter": body_content_filter
- },
- ]

图八
总结
在拥有完善解决方案的前提下,构建 RAG 应用相对来说是容易的。但调试检索的相关性则更需要对搜索相关经验和能力的加持。值得庆幸的是,在这方面,ES 仍然走在了最前面,通过提供最完善和最丰富的查询和排序的调优能力,以及可以广泛获取的社区支持,甚至是生成式大模型在公共数据集上对 ES 能力的学习,我们可以非常方便地从各种渠道获得帮助,以对查询进行调优,这一点,对于我们的技术选型至关重要,也对最终项目的成败至关重要。
不仅仅是玩票性质的应用开发,对于规模更大的企业级生产环境来说,腾讯云ES能够带来更高的效能和更稳定的表现。多年的历程使得腾讯云ES经过了千锤百炼的考验,成为一个值得信赖的平台。
在未来,我们将继续优化腾讯云ES,以满足企业级生产环境的更多需求,并为用户提供更好的使用体验。我们将不断努力,为人工智能助手的开发和应用带来更多创新和便利。
有时候,好的选择,大于用力。
推荐阅读



关注腾讯云大数据公众号
邀您探索数据的无限可能

点击阅读原文,了解更多资讯
↓↓↓

