
- 1CCF-CSP真题《202303-2 垦田计划》思路+python,c++满分题解_csp202303-2
- 2Linux下修改密码复杂度
- 3Android 在线查看、修改 Settings 等值的方法_settings.global.getint
- 4Vue的生命周期-销毁阶段_vue 销毁
- 5Linux常用操作命令_linux操作命令
- 6C语言:指针,指针与数组_09-01-03 结构体指针分数 5入门作者 于延单位 哈尔滨师范大学分析以下代码,理解结
- 7[计算机毕设]基于java+web的校园二手平台系统设计与实现(项目报告+答辩PPT+源代码+数据库)_基于java毕业设计源代码加论文加答辩模板和答辩ppt
- 8Python安装和导入cv库_python import cv
- 9SpringBoot2.7.x 添加防止表单重复提交
- 10Android界面设计 购房贷款计算器界面设计_android:java已知购房贷款界面如图4所示。请为界面中相应视图组件添加上事件处理
编译原理———词法分析器
赞
踩
1、目的
设计并实现一个包含预处理功能的词法分析程序,加深对编译中词法分析过程的理解。
2、实现功能:词法分析
输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。其中,
syn为单词种别码。
Token为存放的单词自身字符串。
Sum为整型常量。
具体实现时,可以将单词的二元组用结构进行处理。
3、待分析的C语言子集的词法(可以自行扩充,也可以按照C语言的词法定义)
1)关键字
main if then while do static int double struct break else long switch case typedef char return const float short continue for void default sizeof do
所有的关键字都是小写。
2)运算符和界符
+ - * / : := < <> <= > >= = ; ( ) #
3)其他标记ID和NUM
通过以下正规式定义其他标记:
ID→letter(letter|digit)*
NUM→digit digit*
letter→a|…|z|A|…|Z
digit→0|…|9…
4)空格由空白、制表符和换行符组成
空格一般用来分隔ID、NUM、专用符号和关键字,词法分析阶段通常被忽略。
4、各种单词符号对应的种别码
表1 各种单词符号的种别码
单词符号 种别码 单词符号 种别码
main 1 ; 41
if 2 ( 42
then 3 ) 43
while 4 int 7
do 5 double 8
static 6 struct 9
ID 25 break 10
NUM 26 else 11
+ 27 long 12
- 28 switch 13
* 29 case 14
/ 30 typedef 15
: 31 char 16
:= 32 return 17
< 33 const 18
<> 34 float 19
<= 35 short 20
> 36 continue 21
>= 37 for 22
= 38 void 23
default 39 sizeof 24
# 0
5、此法分析程序主要思想:采用模块设计
算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到的单词符号的第一个字符的种类,拼出相应的单词符号。算法执行流程图如下:
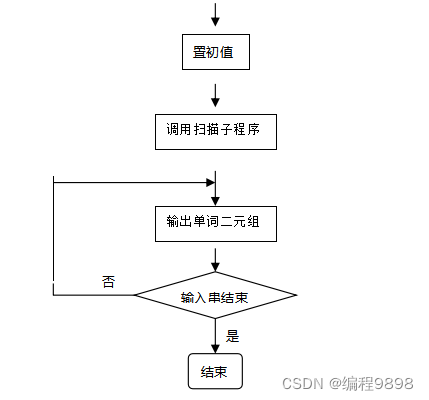
1、关键字表初值
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下:
char *rwtab[27]={“main”,”if”,”then”,”while”,”do”,” static”,”int”,” double”,”struct”,”break”,”else”,”long”,”switch”,”case”,”typedef”,”char”,”return”,”const”,”float”,”short”,”continue”,”for”,”void”,”default”,”sizeof”,”do”};
(2) 程序中需要用到的主要变量:syn,token和sum。
2、 扫描子程序的算法思想
首先设置三个变量:token用来存放构成单词符号的字符串;sum用来存放整型单词;syn用来存放单词符号的种别编码。扫描子程序主要部分流程如图所示。
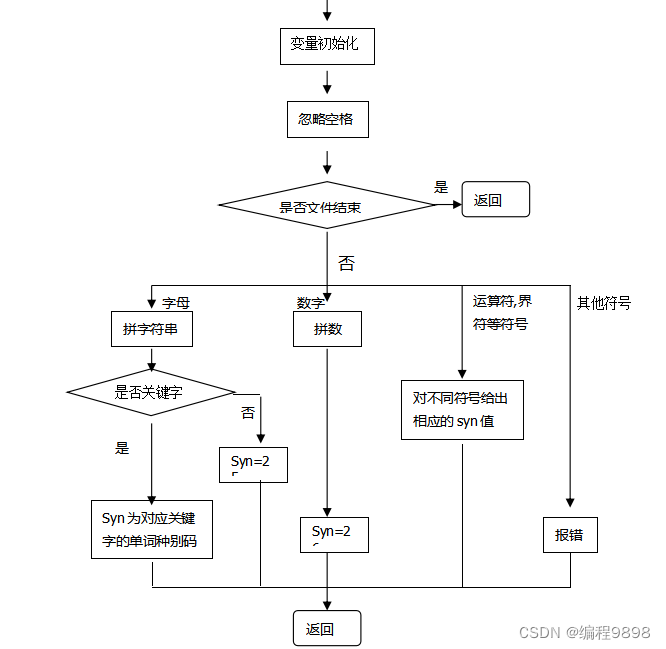
3、设计步骤
(1)首先把一个源程序代码分为五类单词符号:关键字、分隔符(界符)、标识符、数字常量和汉字。
(2)设计程序,把关键字和界符存到一个二维数组里,每次取出一个单词,然后判断是哪一类符号,并写入文件。在设计程序之前,我们得把待分析代码写入一个文本文件,然后在读到内存存到一个数组里。对该数组进行分析
(3)对不符合标识符定义的,也写入文件。
流程图如下:

存放关键字表:

存放运算符表(在分析之前直接将其赋值):
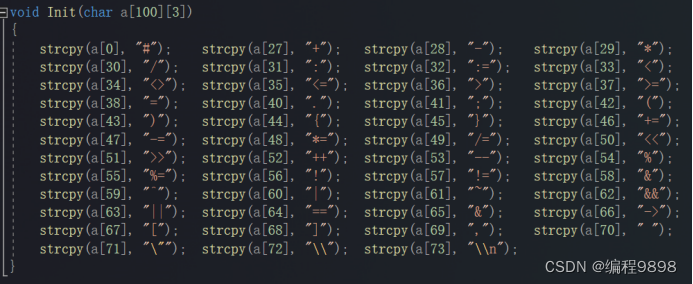
主要函数模块:具体函数代码不再展示

其中主函数如下:
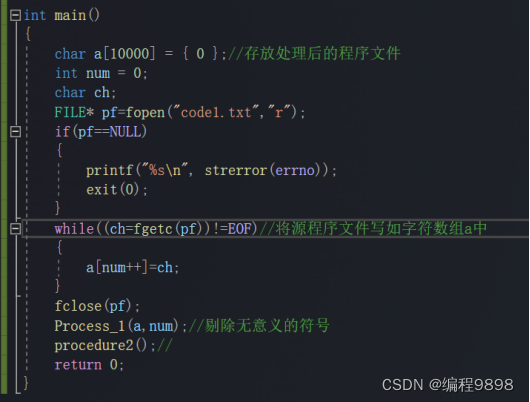
完整源码文件:访问我的百度网盘
http://链接:https://pan.baidu.com/s/1aGcXKAcfI5uOqCWCdTBEFA?pwd=8080 提取码:8080
测试代码:
(1)、

(2)、

(3)、

(4)、

其中code1.txt测试没有复杂的隔离符和汉字, 主要测试预处理程序
code2.txt测试没有复杂的隔离符但有汉字 测试对汉字的处理
code3.txt测试有复杂的隔离符且有汉字 测试复杂的隔离符
(前面三项都是测试整形的数据)
code4.txt测试代码中含有浮点型数据。
运行结果:由于输出项比较多,只截取部分图
(1)、
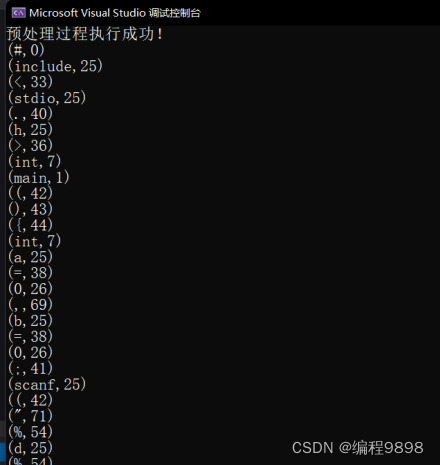
(2)、

(3)、
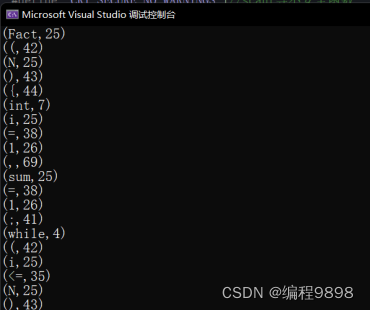
(4)、
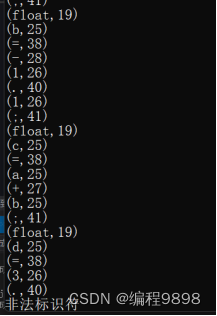
6、遇到的问题及解决过程
(1)字符分类问题:因为实验要求给的界符并不多,我自己添加了更多的界符,界符存储问题,开始是想用一个一维数组来存储,但是像“+=”这样的界符是得用两个字符来存储的。故最后选用二维数组存储界符。关键字也是选用二维数组来存储,在这里存储界符和关键字的时候为了和它的种别码对应起来,采用哈希存储思想,就是它的下标就是它的种别码。最后将字符分为4类,另外由于实验要求没有对库函数的处理,我在此给它处理为标识符。
(2)汉字问题:实验要求没有说对汉字的处理,这里我作了处理,但是对连续的汉字进行处理。开始由于编译器采用UTF-8(BOM)编码方式,这个是没什么问题的,但是写入文件却是乱码,我又把编译器编码方式改为GBK,但是还是乱码,最后通过我一步一步试探,返现是待分析程序的文本文件的编码方式不对,不能是UTF-8,然后我把该文本文件的编码由UTF-8改为ANSI。这样就解决了汉字问题。一开始我是没有考虑汉字问题的,但是后面我一但考虑汉字以后,对我的字母和数字判断产生了不小副作用,但是通过我一步步调试,这个过程非常麻烦而且浪费时间,不过最终我还是解决了汉字问题。
(3)预处理问题:总的来说,这个过程问题不是很大,我所遇到的问题就是考虑不全,在去掉注释的时候只考虑了“//”,而没有考虑”/*……*/这种注释,后面又做了修改。
(4)文件处理问题:这个就是C语言的一些处理文件函数忘记了,通过简单的复习,然后再经过运用,这个其实不算什么难问题。就是知识储备问题。
(5)浮点数和正负数识别问题,一开始写的时候只识别了整数,而且不包括正负数。这个看似简单的问题,在修改的时候却是相当的麻烦,比如那个“+”号,它可以处理为运算符,但是又可以认为是属于正数的一部分。不过最后经过反复调试和修改也总算解决了。
心得:
编译原理这门课本来就是一门非常抽象的课程,而且比较难,第一部分是词法分析。虽然用文字描述起来就几句话的事,但是编程实现真的是一个复杂的事情。这也让我深刻了解到高级语言到低级语言转化的复杂性,光词法分析这个阶段就很复杂,那中间代码产生那些,还与具体的计算机指令集,寄存器,内存分配什么的都有关系,看来会写编译程序的程序员的水平是真的高。这次试验我花费最多的时间就是调试部分了,因为程序经不起测试,每当换一个新的代码测试,就会暴露出问题,而且改了以后可能又会对之前测试的代码又有影响。总的说来就是程序总的设计阶段没做好,在做之前就得把大多数可能想好。不然中途心血来潮突然来一个别的问题没考虑到,再修改就是一件非常麻烦的事情。在调试过程中,我对调试技巧有了一定的提升,并且对编译原理这门课的重要性有了一个更深的认识。再后面的两次实验中,继续实验,争取写出一个健壮性好的程序。

