- 1【时间】 js 根据已知的时间,判断是否是 前天,昨天,今天,明天,后天_js判断今天明天后天
- 2华为畅享6s可以升级鸿蒙,【华为畅享6S评测】华为畅享6S评测:颜值高又好用的千元机就是它了-中关村在线...
- 3运行速度终于变快了!优化VMD参数,五种适应度函数任意切换,最小包络熵、样本熵、信息熵、排列熵、排列熵/互信息熵...
- 4Macbook(苹果电脑) VSCode 创建简单c++程序 配置C++开发环境_mac做c++开发
- 5基于rk3568平台 rk809 codec的介绍
- 6sysbench的用法_sysbench可以设置table name吗
- 7两篇论文被ECML PKDD DC09接收_ecml-pkdd(ccf b类)论文被哪里收集
- 8flutter获取地理定位:geolocator依赖详细用法_flutter geolocator
- 9【自然语言处理】ChatGPT 相关核心算法_chatgpt核心算法
- 10OS系统下 使用MAMP站点配置详解_mamp 导出配置
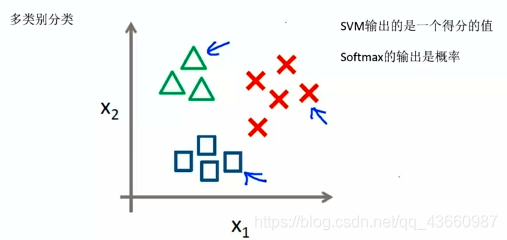
Softmax分类器及最优化_softmax 优化
赞
踩
1,基本内容
将线性分类得到的得分值转化为概率值,进行多分类,在SVM中的输出是得分值,Softmax的输出是概率。
2,Sigmoid函数
表达式(值域为[0,1]):
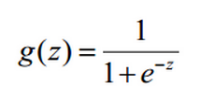
函数图像:
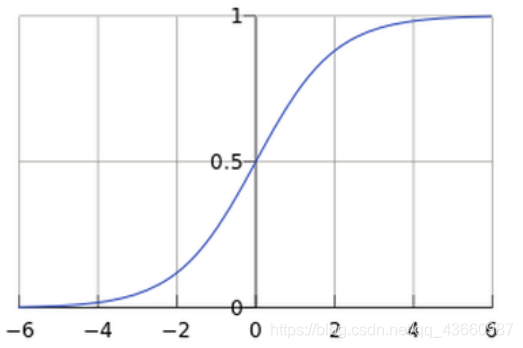
Sigmoid函数可将任意实数映射到概率值[0,1]区间上,实现根据概率值的大小进行分类。
3,Softmax的输出
softmax 函数:其输入值是一个向量,向量中元素为任意实数的评分值,输出一个向量,其中每个元素值在0到1之间,且所有元素之和为1(归一化的分类概率:):
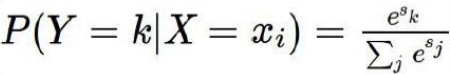
损失函数:交叉熵损失(cross-entropy loss)
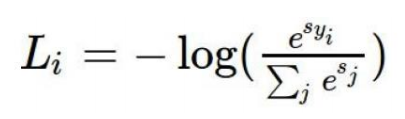
其中
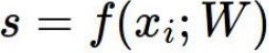
还以上述猫的分类为例进行计算:
 幂操作可以将相对大的值映射为更大的值,将负数映射为非常小的数,Li为损失函数值(对正确类别的概率值计算其损失值)
幂操作可以将相对大的值映射为更大的值,将负数映射为非常小的数,Li为损失函数值(对正确类别的概率值计算其损失值)
4,SVM和Softmax的损失函数对比
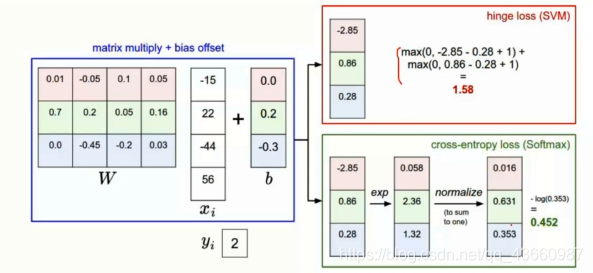
对于hinge loss,当错误类别的得分与正确类别的得分相近时并不能准确的评估模型的效果(损失值接近于0,但模型的分类效果并不好),故不采用此类损失函数。
5,最优化:
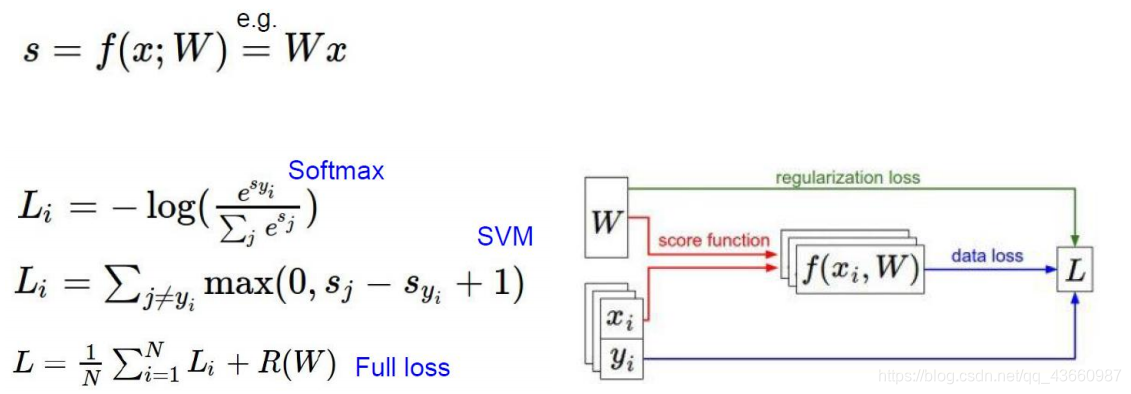 输入数据和一组权重参数组合得到一组得分值,最终得到Loss值,这一系列过程称为前向传播过程。通过Loss值更新权重参数,可以有反向传播的算法实现
输入数据和一组权重参数组合得到一组得分值,最终得到Loss值,这一系列过程称为前向传播过程。通过Loss值更新权重参数,可以有反向传播的算法实现
5.1 梯度下降(以最快的速度到达最低点)
梯度公式:
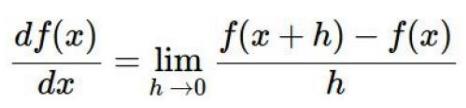
梯度下降代码实现:
 Bachsize(从原始数据中取出一批数据)通常是2的整数倍(32,64,128),考虑计算机的负载量,一般越大越好。step_size为学习率(不易过大)。
Bachsize(从原始数据中取出一批数据)通常是2的整数倍(32,64,128),考虑计算机的负载量,一般越大越好。step_size为学习率(不易过大)。
训练网络时的LOSS值视化结果:
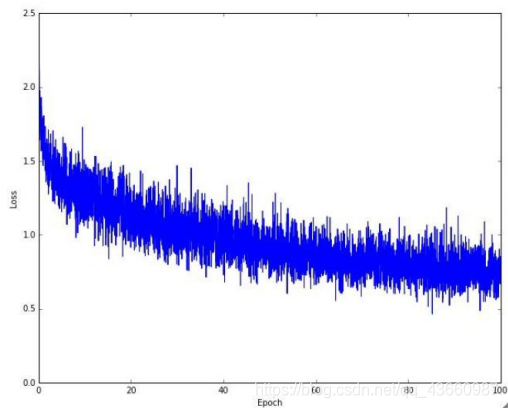 局部有波动,但整体有向下趋势,说明该网络可取。(epoch是指将整个数据全部处理一遍,一次迭代是指只完成Bachsize大小的数据量处理)
局部有波动,但整体有向下趋势,说明该网络可取。(epoch是指将整个数据全部处理一遍,一次迭代是指只完成Bachsize大小的数据量处理)
5.2 反向传播
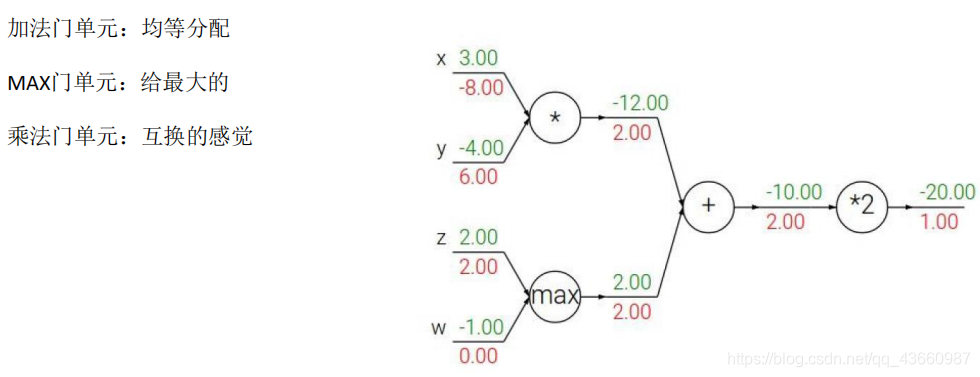
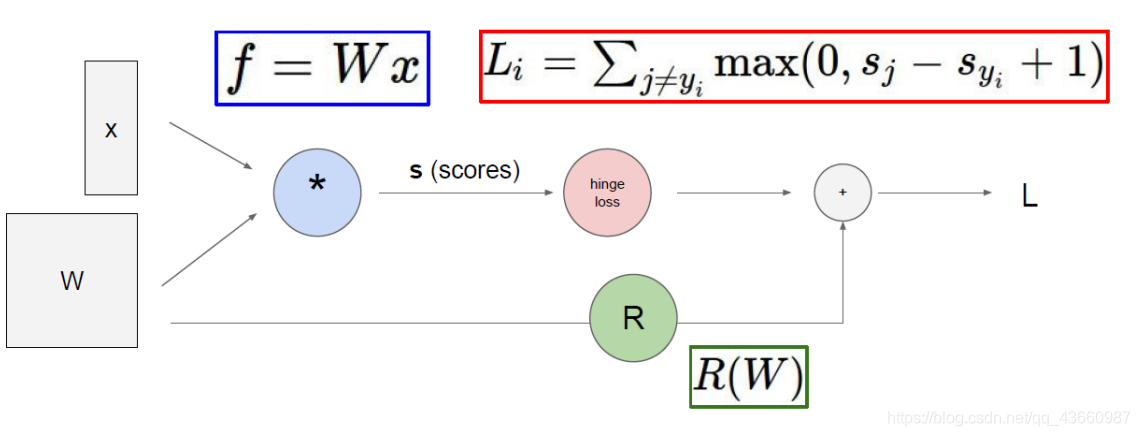 上图为前向传播,反过来由L更新W称为反向传播,举例说明如下:
上图为前向传播,反过来由L更新W称为反向传播,举例说明如下:
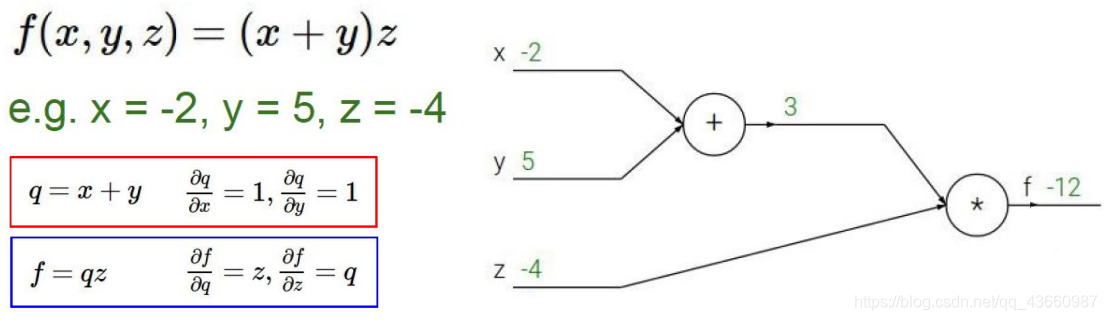 假设有x,y,z三个样本点,经过一系列操作得到一个损失值f,现在需要分别计算样本点对应的权重参数对f的贡献是多少(求偏导)
假设有x,y,z三个样本点,经过一系列操作得到一个损失值f,现在需要分别计算样本点对应的权重参数对f的贡献是多少(求偏导)
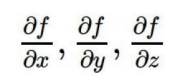
链式法则:
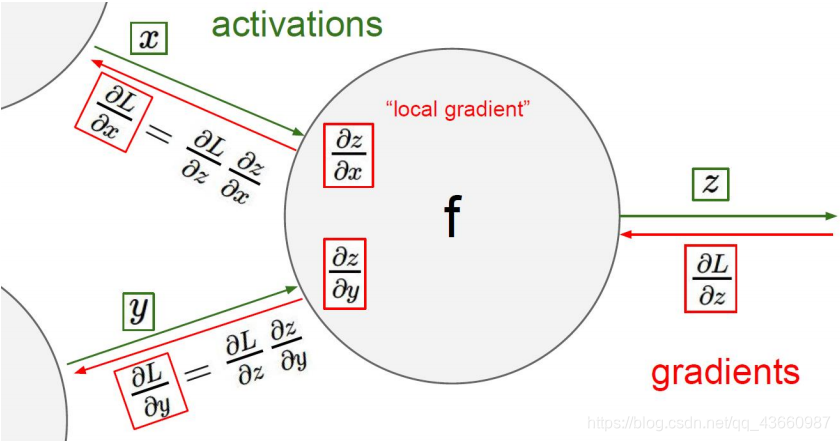
比较复杂函数反向传播过程如下:
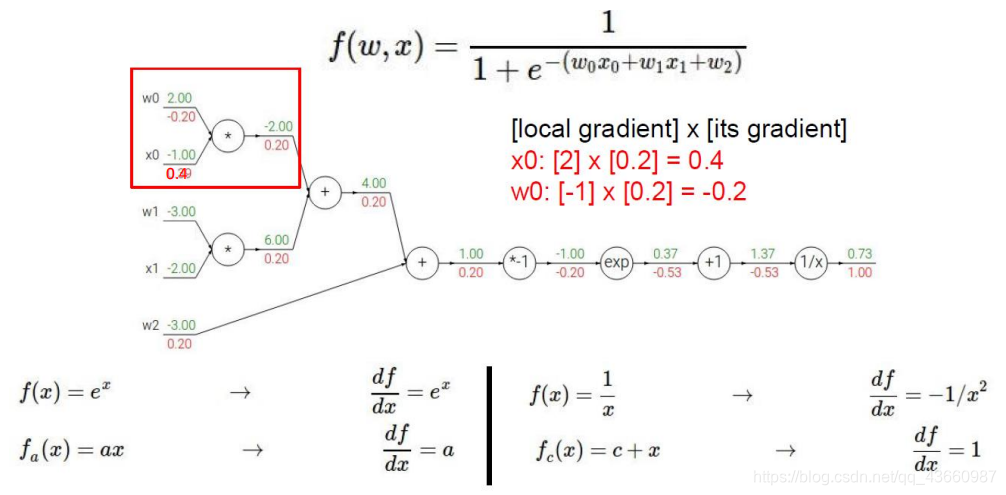 简化方式:
简化方式:
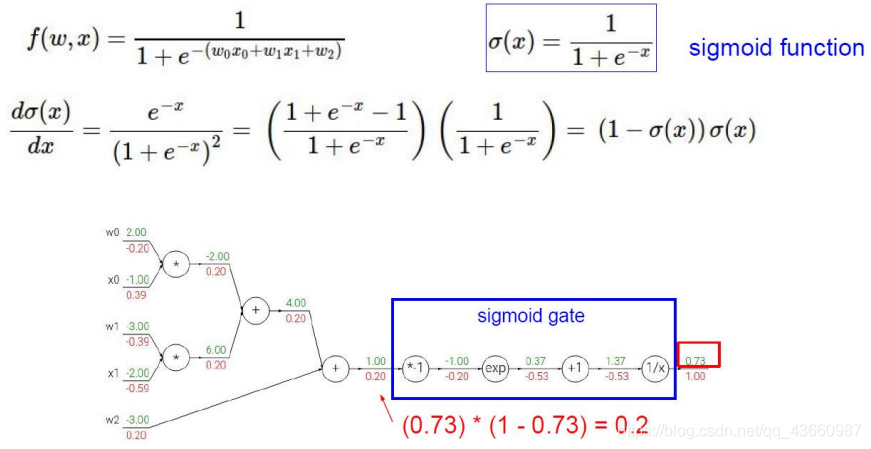
门单元的含义: