
热门标签
热门文章
- 1SST-EmotionNet: 基于空-谱-时的注意力三维稠密网络脑电情感识别_metaemotionnet: spatial-spectral-temporal based at
- 2antd踩坑记录之upload上传_为何 filelist 受控时,上传不在列表中的文件不会触发 onchange 后续的 status
- 3打开ms office相关软件如Visio, 发生闪退 ,打不开,无反应问题_visio安装助手打不开
- 4使用 TensorFlow 2.0 实现高水准的自然语言处理_tensorfolw 自然语言处理demo
- 5NLP与GPT联合碰撞:大模型与小模型联合发力_gpt和nlp
- 6npm ERR! code EACCES npm ERR! syscall mkdir
- 7Keras Dense层详解
- 8快速搭建美团外卖(第三方)微信小程序(附精选源码32套,涵盖商城团购等)_外卖小程序源码
- 9CNN模型之VGGNet_%20%20vgcnnb
- 10【动手学深度学习-pytorch】8.5 循环神经网络的从零开始实现
当前位置: article > 正文
RASA实战三:训练数据准备和domain文件_rasa3 实战
作者:凡人多烦事01 | 2024-03-31 07:03:24
赞
踩
rasa3 实战
训练数据主要分为三大块,nlu,rule, story,存放在data目录下
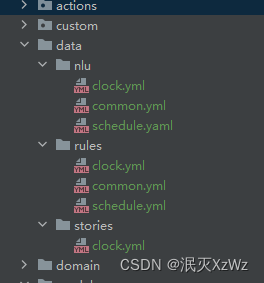
nlu
NLU(自然语言理解)的目标是从用户消息中提取结构化信息。这通常包括用户的意图和他们的消息包含的任何实体。您可以向训练数据添加额外的信息,如正则表达式和查找表,以帮助模型正确识别意图和实体。
nlu里的数据内容如下:

RULE
规则是一种训练数据,用于训练助理的对话管理模型。规则描述了应该始终遵循相同路径的简短对话片段。可以简单理解为是基于规则的对话模板
data/rules/clock.yml
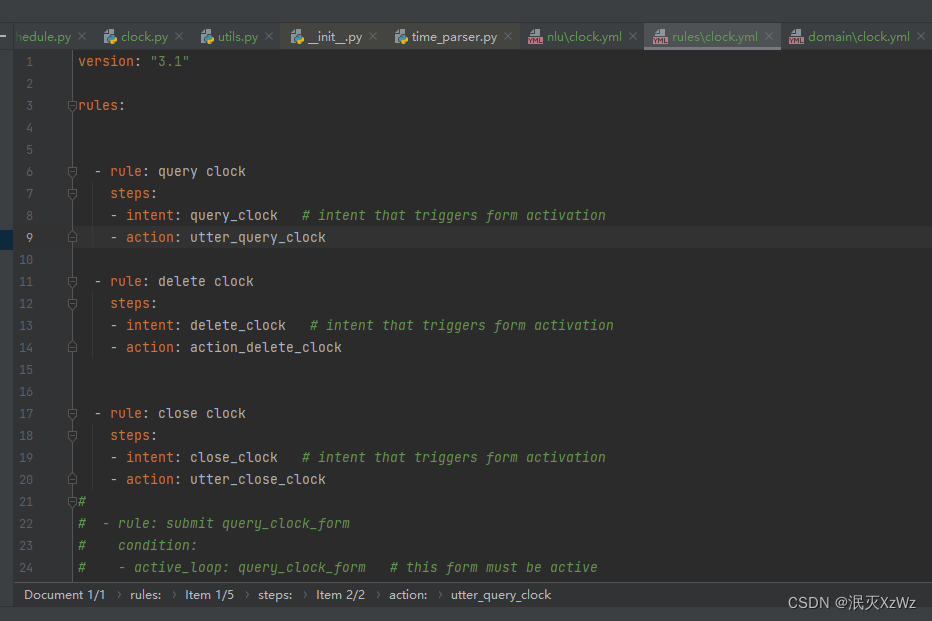
这里拿第一个rule简单介绍一下什么意思,第一个rule是 query clock,是用户查询闹钟的逻辑,这个rule的意思是,当检测到用户的意图是query_clock(查询闹钟),执行对应的action为utter_query_clock
story
故事是一种训练数据,用于训练助理的对话管理模型。故事可以用来训练模型,使其能够归纳出看不见的对话路径。(上面说了rule可以理解为基于规则的对话,story刚好和他相反,story定义的是正常的对话逻辑,不是强制性的,让模型去学习,自己判断怎么根据用户的意图作出对应的回答,因为闹钟这个技能比较简单,所以就没有用到story数据)
domain
domain定义了您的助手工作的范围。它指定了你的机器人应该知道的意图、实体、插槽、响应、表单和动作。它还定义了会话会话的配置。
domain/clock.yml

我们在NLU里定义的意图,实体,槽位,和自定义action,都需要写进domain文件里
推荐阅读

相关标签

