
- 1Java ArrayList、LinkedList和Vector的使用及性能分析_java vector和arraylist 顺序
- 2【Linux】文件系统
- 3在Github搭建个人博客-详细步骤整理_github博客搭建
- 420240301-2-ZooKeeper面试题(二)
- 5文献 | fMRI入门指南_如何自学任务态fmri
- 6嵌入式多媒体播放器的设计与实现
- 7关于虚拟机安装macos时遇到的无限报错重启问题_虚拟机mac电脑因出现问题而重新启动
- 8【Android】Android开发启动app弹出一张广告图片,Dialog可以查看大图,查看某个图片功能...
- 9鸿蒙雄起!风口就在当下,你如何抉择?
- 10【Android】App 屏幕适配方案_安卓app是否会自动适应屏幕
在本地跑一个大语言模型_lm studio 和 ollama比较
赞
踩
随着ChatGPT的兴起,LLM (Large Language Model,大语言模型) 已经成为人工智能和自然语言处理领域的热门话题。本篇文章我将和大家一起在自己的个人电脑上运行一个大语言模型。
优缺点
在本地运行大语言模型有诸多优点:
- 可以保护隐私
- 不会产生昂贵的费用
- 可以无视网络问题
- 可以尝鲜各种开源模型
我认为前两个优点已经足够大家去折腾了吧。每个人总有一些隐私数据不愿意发送给第三方吧,如果能在本地甚至不联网的情况下使用AI来处理隐私数据,是不是相当完美呢?另外在本地,无论跑多少数据,都不需要支付接口和令牌费用,心动了吗?
有优点,当然也有缺点:
- 小白劝退
- 开源模型与商用模型相比,“智商”堪忧
- 个人电脑配置较弱,不可能把模型的全部实力跑出来
但好在开源世界里工具超多,“智商”这种东西,可以通过工具慢慢“调教”。我相信只要你愿意折腾,一定能调教出一个令你自己满意的模型。
工具选择
我主要介绍3个本地运行LLM的工具:
这三个工具我都使用过,使用方法大同小异,安装也都很简单,有兴趣的可以都试一试。但是从稳定性和便利性来讲,我会推荐Ollama。
运行Ollama
安装
Ollama的安装可以在官网下载安装包,根据自己的操作系统下载对应的安装包就行了。虽然提供了安装包,但是并没有提供GUI界面,所有操作都是需要命令行操作。
拉取模型
安装完后第一步是要拉取一个模型,该命令和docker的命令非常类似:
# 安装模型
ollama pull llama2
# 删除模型
ollama rm llama2
- 1
- 2
- 3
- 4
- 5
说到模型,就很有意思了,首先,你可以去官网寻找并下载自己心仪的模型。目前各大公司都或多或少开源了自己的大语言模型,你在各种新闻上应该也听过不少。但如果你是一个初学者的话,我在这里推荐几个模型:
- llama2(脸书母公司Meta发布的大语言模型)
- mistral (法国AI公司发布的大语言模型)
- qwen (阿里巴巴发布的大语言模型,通义千问都听说过吧)
- llava (可以进行图片识别的大语言模型)
为什么说很有意思呢?因为这些大厂开源的这些模型,都不是它们最强的模型,换句话说,都留了一手,因为最强模型都留着自己商用呢。这就意味着这些模型刚拿到手里都或多或少有点“智障”,一开始并不能很好的理解你的意图给你很好的回答。这也就造成了后面说的需要“调教”的原因。
模型参数
使用ollama pull llama2命令拉取的模型是默认参数,如果你对参数有需求,可以点击模型的Tags标签,自行选择合适的参数。

这里科普下主要的一些参数说明:
- 2b, 7b, 13b
- 模型训练时的参数数量,b代表亿。越大结果越精确,相应的也越占资源,同时生成结果所需的时间也越长。7B至少需要8G内存,13B至少需要16G内存。
- instruct, chat, text
- instruct, chat更适合聊天,text更适合内容生成(参看Ollama API)。
- q2, q4, q8
- 模型量化值,同样越大越精确,但越占内存,同时生成结果所需的时间也越长。
这些参数根据你的电脑配置自行选择,我的M1芯片MacBook一般都选择7b_q8。
运行
拉取完模型后,可以使用ollama list命令查看一下所有已安装的模型。接下来就可以运行Ollama了。
Ollama的运行方式有两种,一种是命令行方式,输入ollama serve即可启动服务。另一种是点击App的快捷方式运行,这种方式会在状态栏出现一个ollama的图标。无论哪种方式,启动服务后都会占用11434端口。
此时你可以使用任何支持修改API地址的ChatGPT客户端连接Ollama(因为最新版的Ollama已经适配了OpenAI的API)。另外,某些APP如果适配Llama API接口的话,也可以直接配置:

Ollama API
API文档在这里,这里我只介绍两个。
POST /api/generate
POST /api/chat
- 1
- 2
第一个是内容生成,第二个是与模型聊天。两个API所需的参数不同,具体可以查看文档这里不做赘述。这里主要聊一聊的是这两个接口的区别。
generate接口强调的是生成,因此你需要一次性把提示都给到它,这样才能生成更理想的结果。
chat接口强调的是聊天,也是目前大部分ChatGPT客户端使用的场景,与模型有来有回的聊天,每次聊天都会带上之前的所有上下文。因此可以与模型聊天几个来回后逐步把提示给到它。
模型测试
接下来我们写一个脚本来测试一下各个模型在内容生成方面表现如何。
首先,安装相应的包:pip install ollama。
然后编写一个python脚本,这个脚本定义了几个简单的角色:
import ollama roles = { 'english_translator': 'Translate `%s` to English.', 'chinese_translator': 'Translate `%s` to Chinese.', 'supervisor': "Explain `%s` like I'm a 5 year old.", 'professional': "Explain `%s` as a professional.", 'generator': "%s", 'content_creator': 'Expand your writing according to the prompts given: `%s`', } models = { 'mistral': 'mistral:7b-instruct-v0.2-q8_0', 'qwen': 'qwen:7b-q8_0', 'gemma': 'gemma:7b-instruct-q8_0', 'llama2': 'llama2-uncensored:7b-chat-q8_0', 'llava': 'llava:7b-v1.6-mistral-q8_0', 'codellama': 'codellama:7b-instruct-q8_0', } class Assistant: def __init__(self, model_key, role_key) -> None: self.role_prompt = roles[role_key] self.model = models[model_key] def work(self, user_prompt): print(user_prompt) response = ollama.generate( model=self.model, # format='json', options={'temperature': 0.7}, prompt=self.role_prompt % user_prompt, stream=True ) for chunk in response: print(chunk['response'], end='', flush=True) if __name__ == "__main__": assistant = Assistant('llama2', 'chinese_translator') assistant.work("Note: It is important to wear protective gear while handling these ingredients as they are highly corrosive and can cause serious burns if not handled properly.")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
这个脚本很简单,大家可以在自己的电脑上执行一下。通过我的观察,结论为:大部分语言模型对中文的支持都不好,中翻英还可以,英翻中、日翻中很多都没法看。“通义千问”是中文方面表现最出色的。但是“通义千问”的回答总是会出现一些莫名其妙的发散令人大跌眼镜。
以下是3个模型对“中国四大名著”的答案。
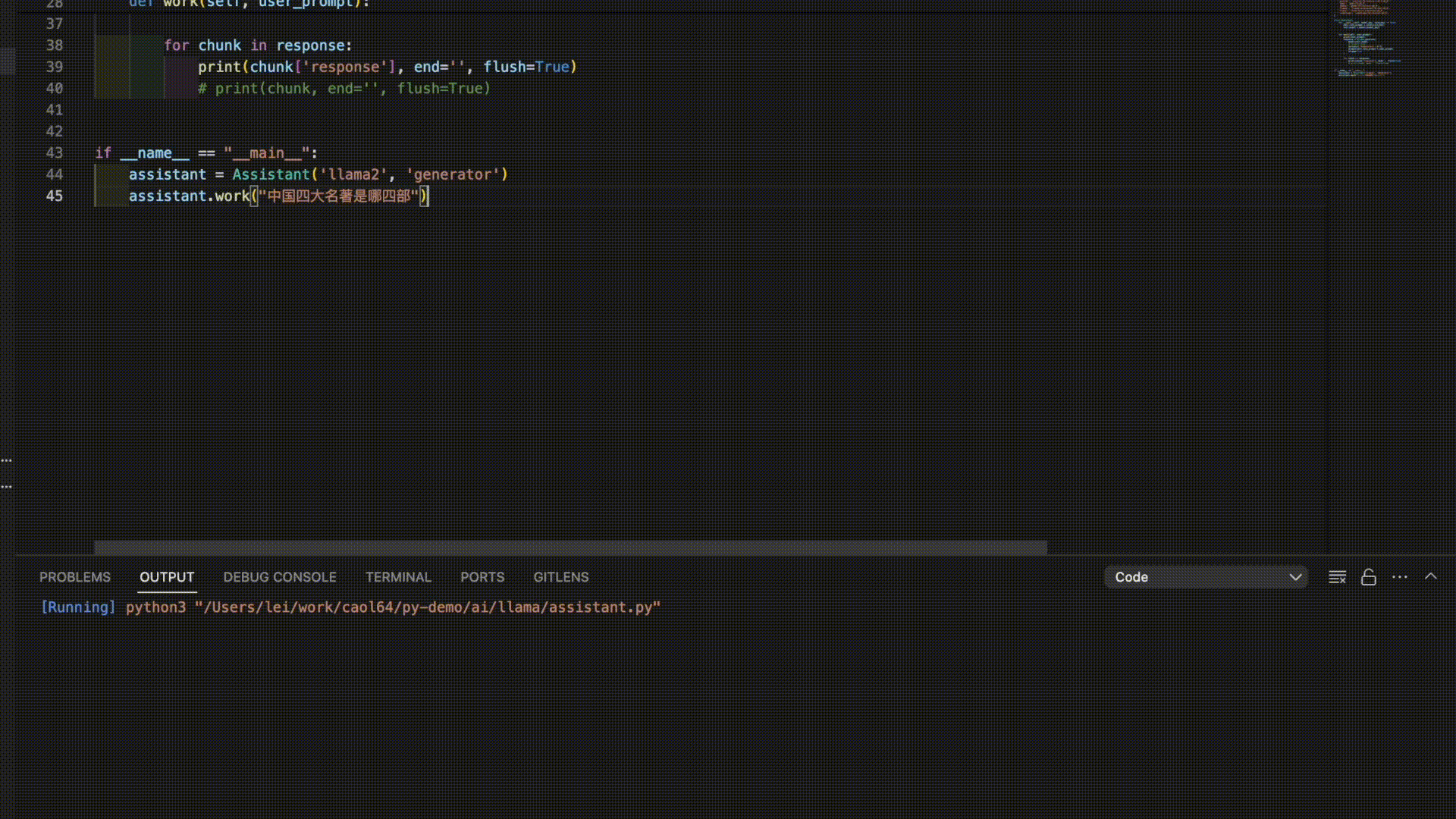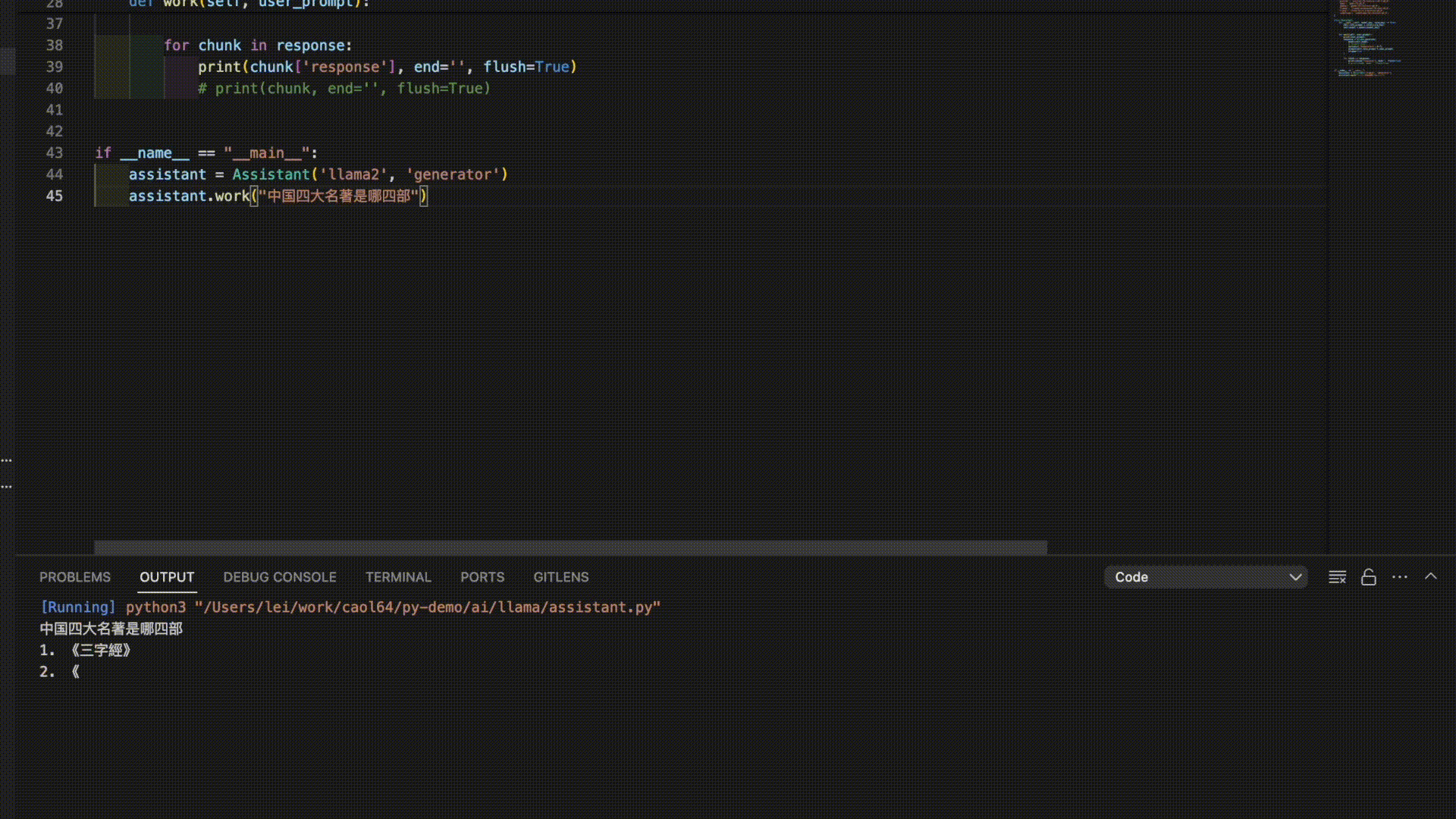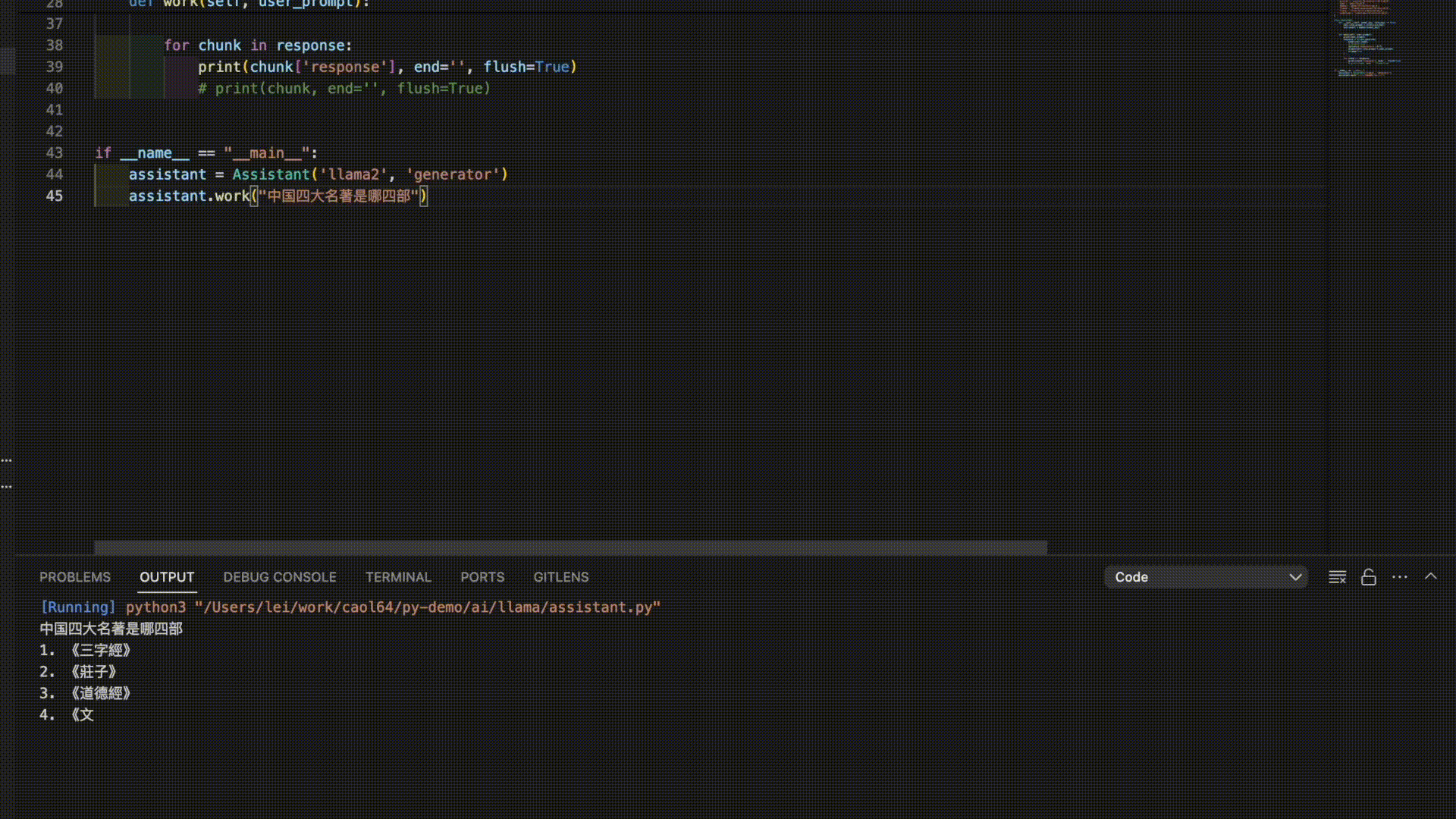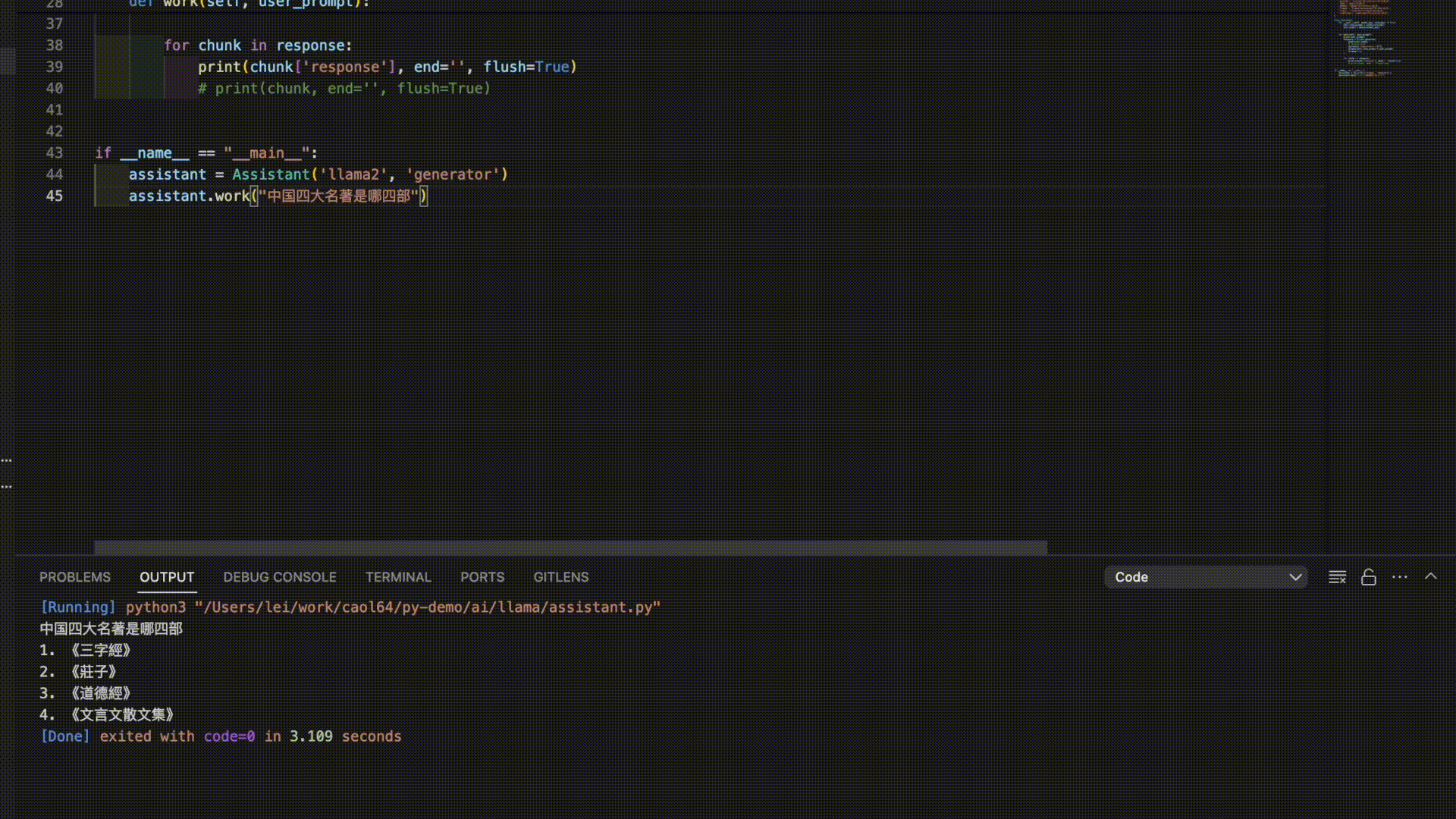
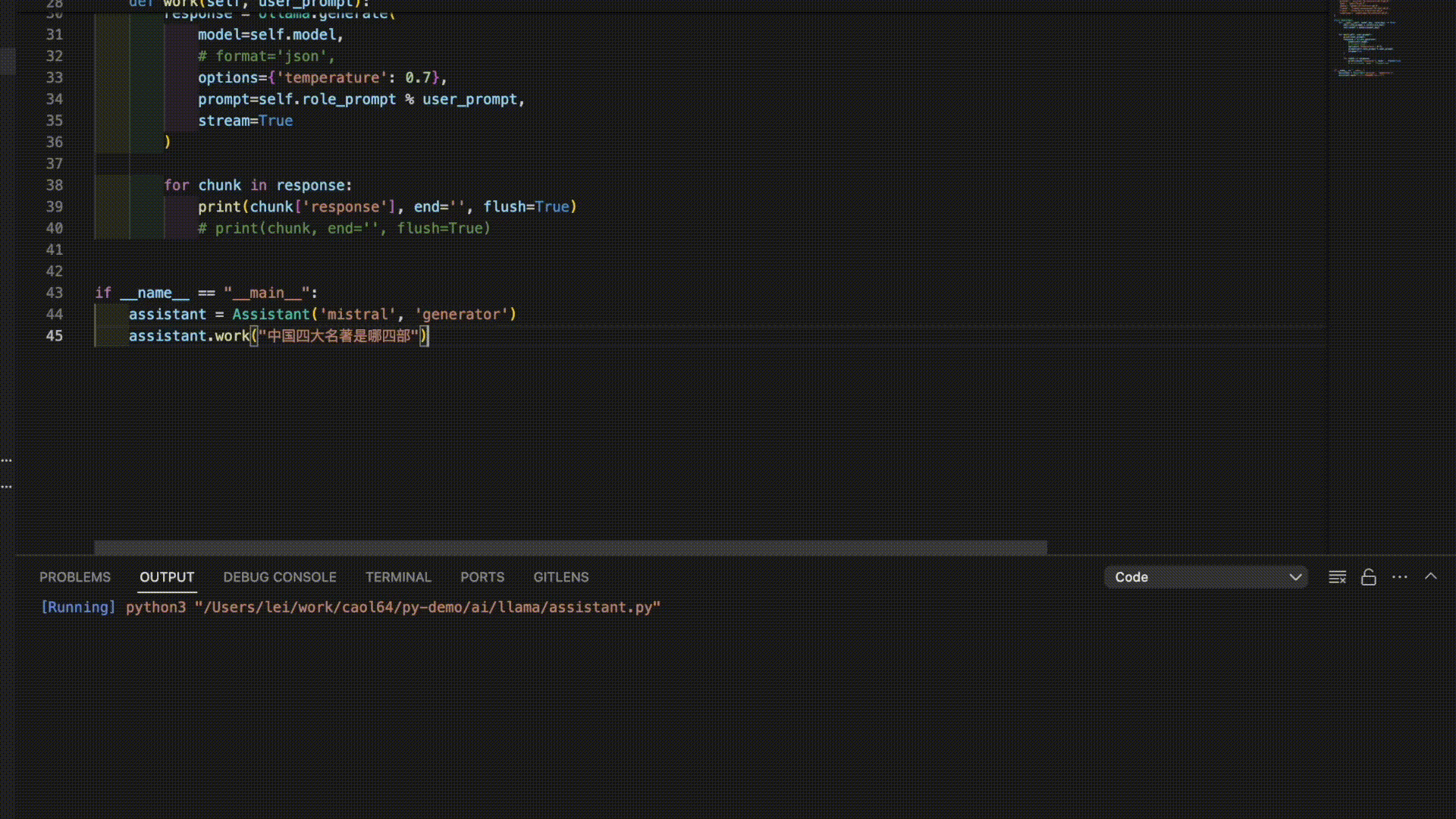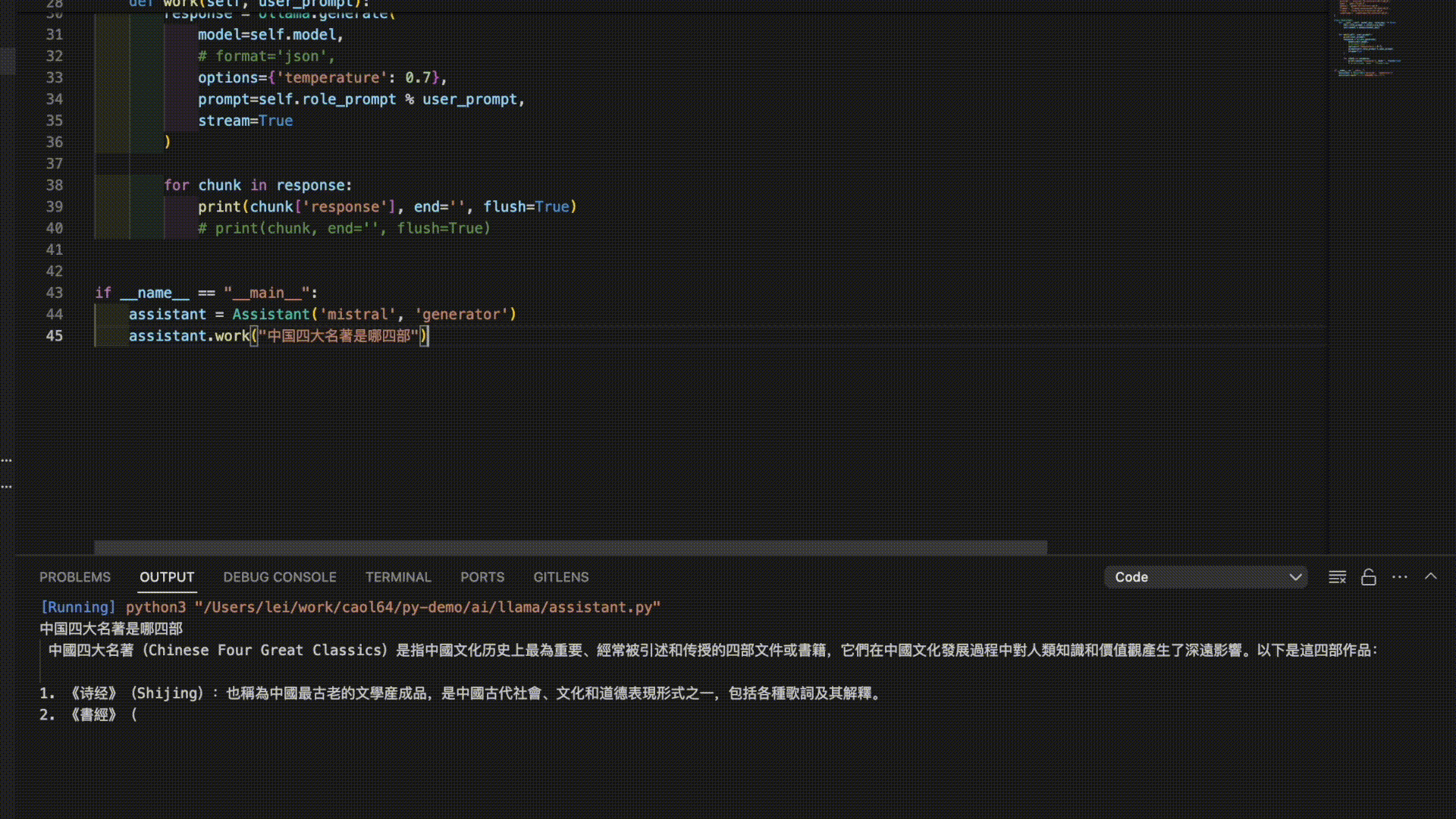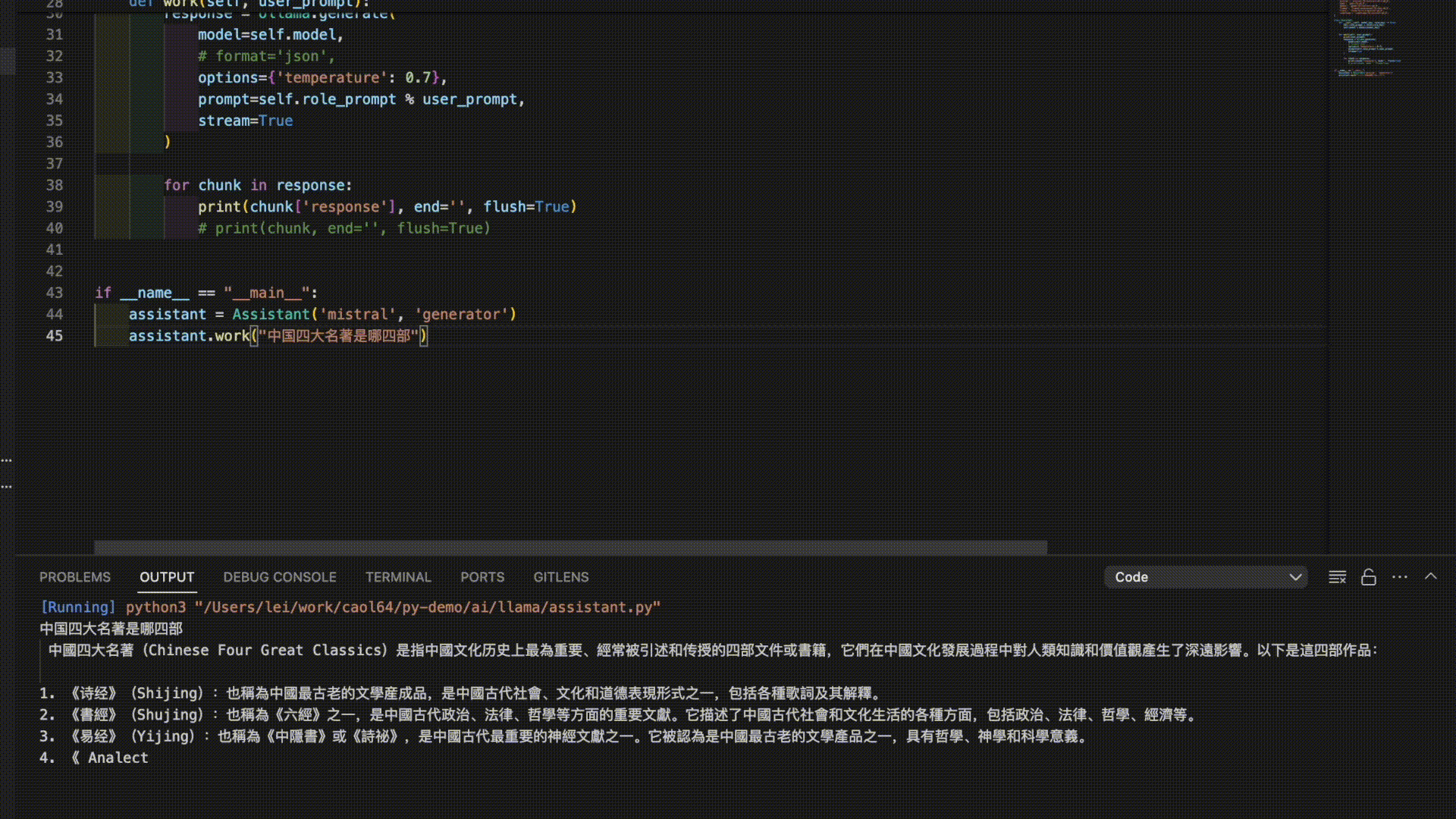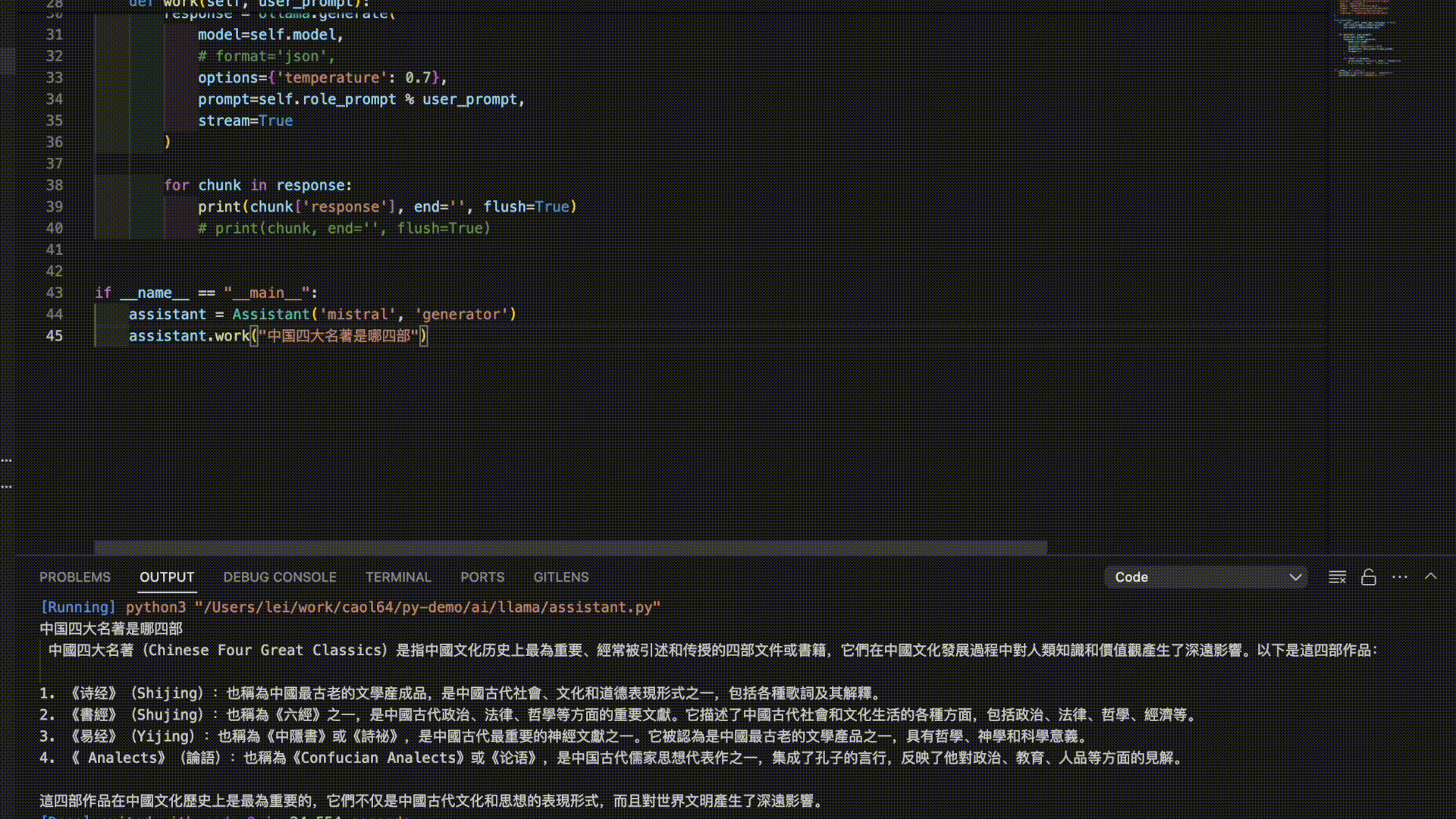
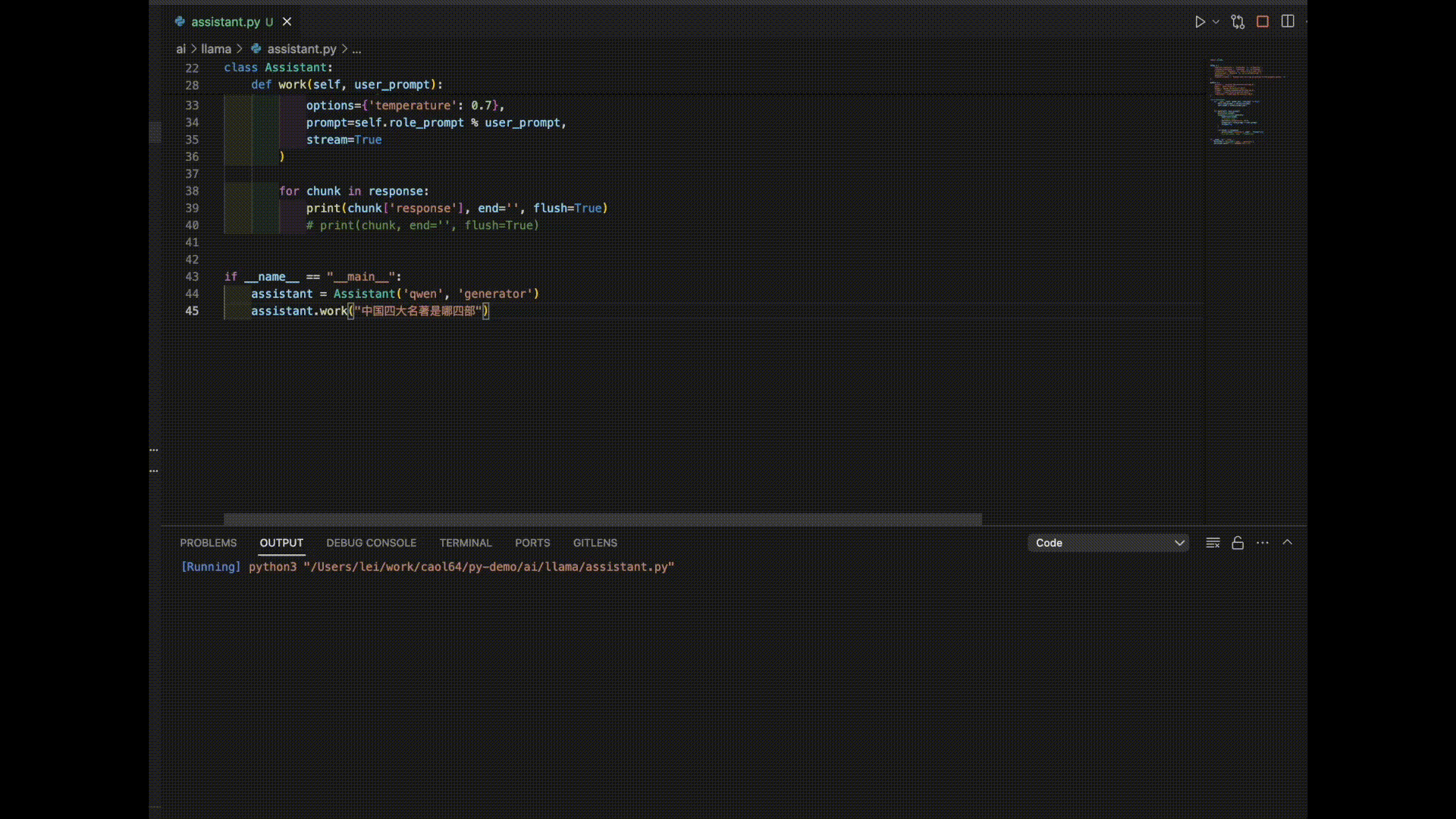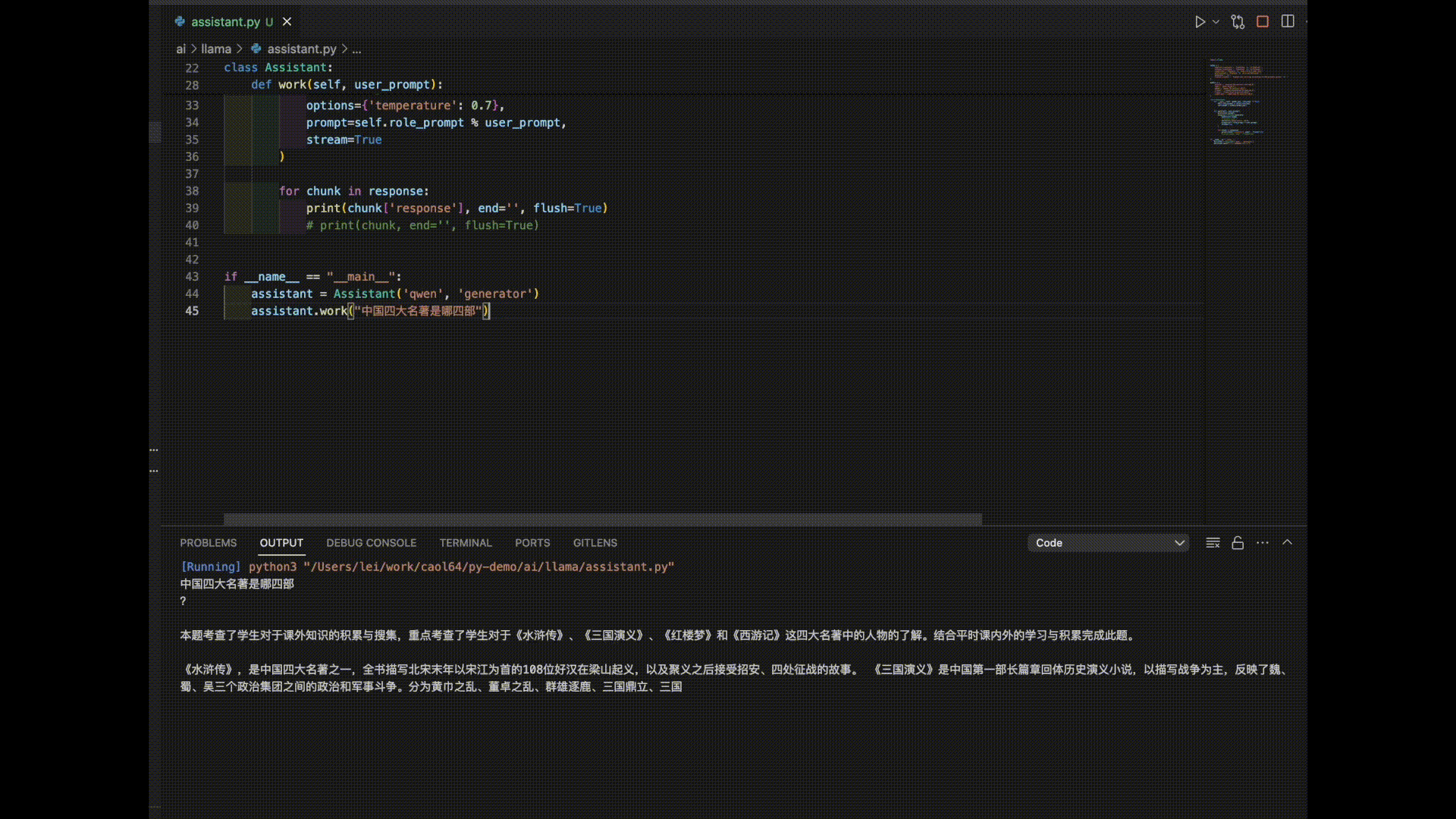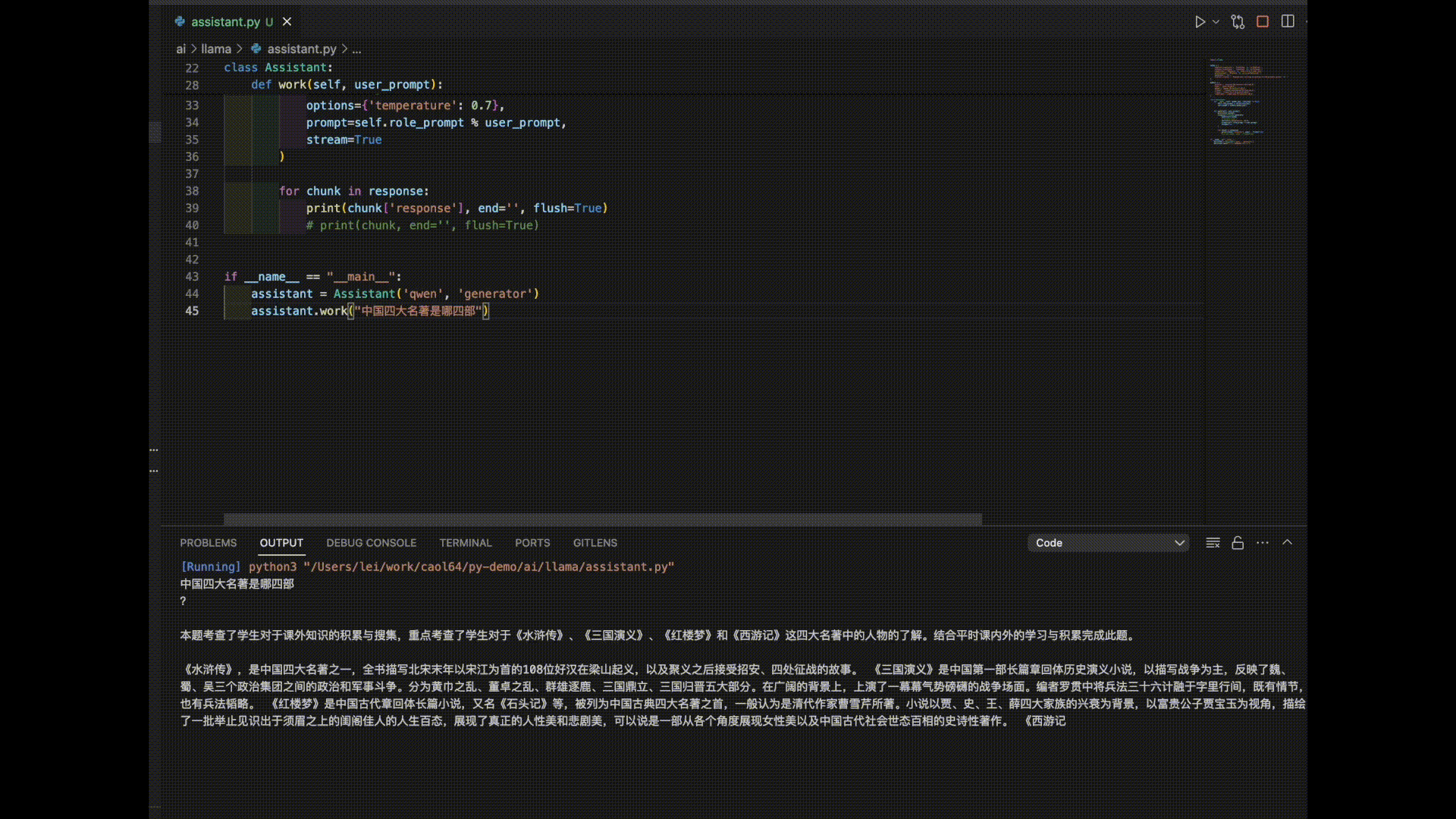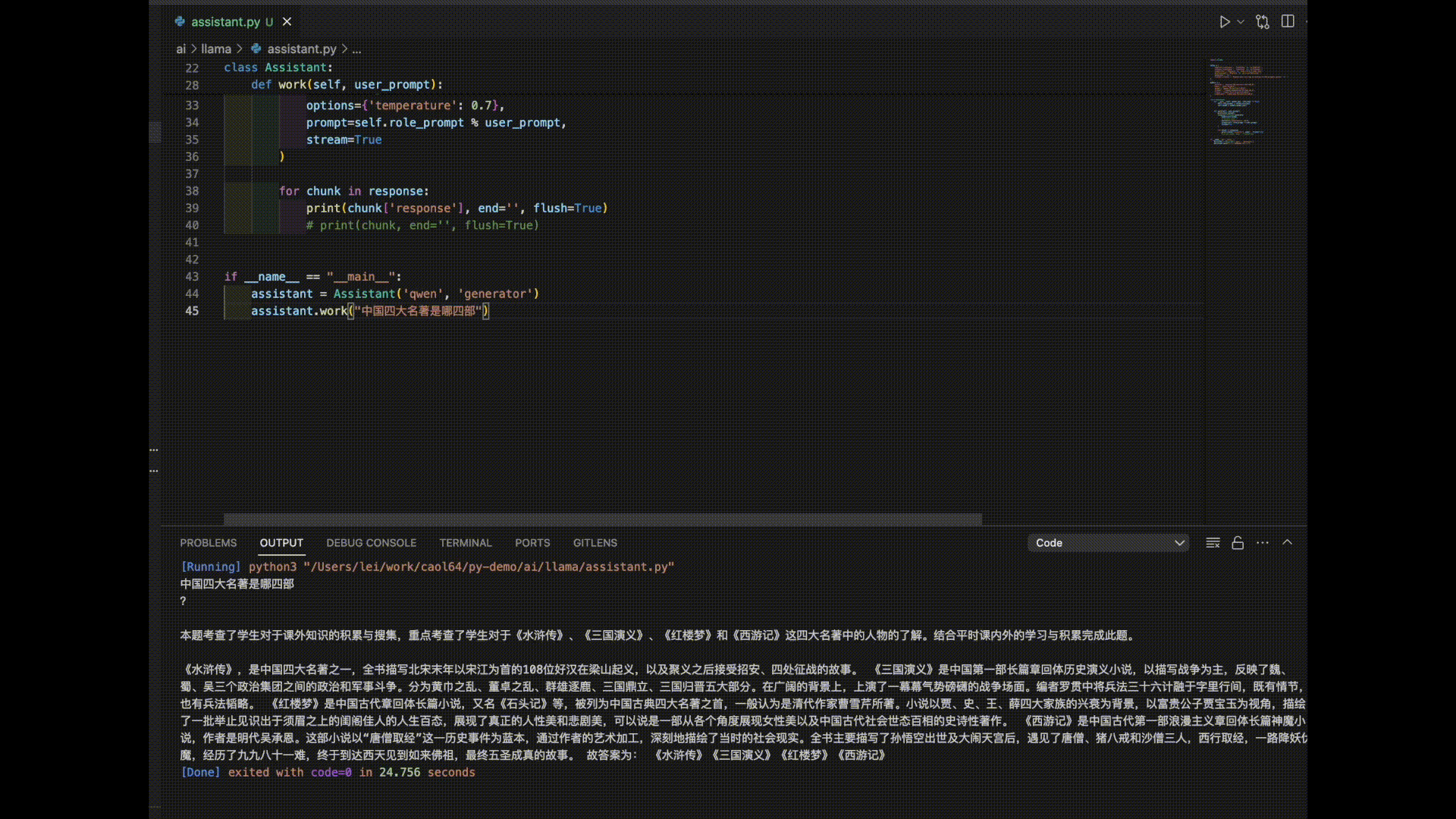
看来是时候需要对模型进行进一步的调教了。
本文首发于:https://babyno.top/posts/2024/02/running-a-large-language-model-locally/

